从零开始学机器学习——了解分类算法
cnblogs 2024-10-14 09:13:00 阅读 68
分类算法
首先给大家介绍一个很好用的学习地址:https://cloudstudio.net/columns
分类算法是监督学习的一种重要方法,它与回归算法在许多方面有相似之处。监督学习的核心目标是利用已有的数据集进行预测,无论是数值型数据还是类别型数据。具体而言,分类算法主要用于将输入数据归类为不同的类别,通常可以分为两大类:二元分类和多元分类。
理解这一过程其实并不复杂,举例来讲如何将一系列邮件区分为正常邮件与垃圾邮件。这一原理在我们生活中也随处可见,比如分类垃圾箱的使用。无论是邮件的分类还是垃圾的处理,最终的结果都是在于对不同类型的内容进行明确的定性区分。
尽管这个问题看起来比较简单,但我有一个疑问:在我们之前学习回归算法的过程中,曾经讲解过逻辑回归。为什么逻辑回归被归类为分类算法,而不是回归算法呢?
逻辑回归:回归 VS 分类
尽管名字中带有“回归”二字,逻辑回归实际上执行的是分类任务。因此,它被归类为一种分类算法。
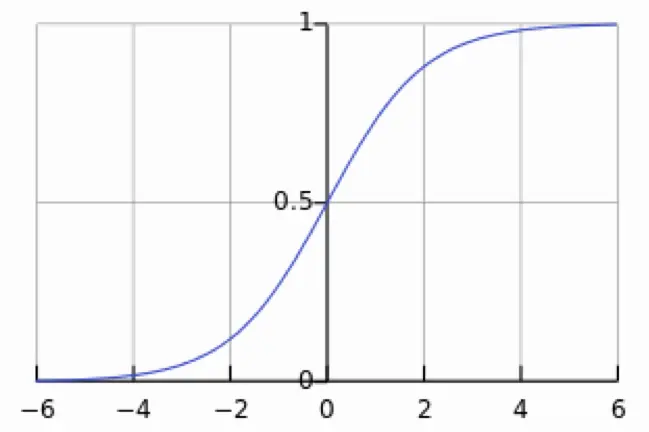
我们在讲解逻辑回归时,是有讲解到一个数学知识点的,一个Sigmoid 函数,再来复习一下,这个函数有几个特点,sigmoid 可以将数据压缩到[0, 1]之间,它经过一个重要的点(0, 0.5)。这样,将输出压缩到[0,1]之间,0.5作为阈值,大于0.5作为一类,小于0.5作为另一类。
当然了逻辑回归通常也有多元分类。这里就不在赘述了。
今天,我们将通过一个官方示例进行详细讲解。这个示例涉及分析一系列原材料,以判断这些原材料可以用来制作哪种国家的菜肴。显然,这是一个多元分类问题,因为涉及的国家种类非常多。
准备数据
接下来,我们将重点讲解今天的主要任务,即数据准备。在经过前面关于回归的章节后,我们已经掌握了数据清洗的基本步骤,包括读取文件数据、删除多余字段和去除空值数据这三个主要环节。
今天,我们仍然会遵循这些步骤,但我们的目标将侧重于数据的平衡性。因为在实际数据集中,某些类别可能存在过多的样本,而另一些类别则可能样本较少,这种不平衡现象会对后续的预测分类产生显著的偏差。
因此,我们将特别关注如何对数据进行合理的平衡处理,以提高模型的预测性能。
导入数据
我们将继续使用官方提供的数据示例进行导入。
<code>import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
from imblearn.over_sampling import SMOTE
df = pd.read_csv('../data/cuisines.csv')
df.head()

在这里,我们展示了几行数据样本,其中用0和1表示某道菜使用了哪些原料。具体来说,0表示未使用该原料,而1表示使用了该原料。由于数据集中包含的原料数量大约有384个,为了简洁起见,对中间部分的数据进行了折叠显示。
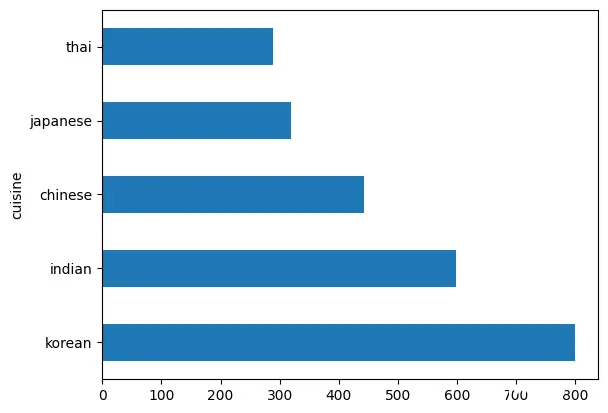
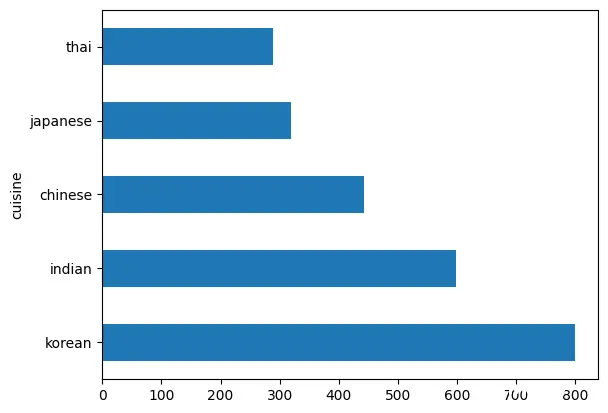
接下来,我们将演示数据集中存在的不平衡情况。由于我们的主要关注点是不同国家菜肴的出现概率,因此确保每个国家的数据尽可能一致是至关重要的。接下来,让我们查看目前的数据分布情况。
<code>df.cuisine.value_counts().plot.barh()
由于国家数据存储在“cuisine”列中,因此我们只需对该列的值进行统计即可,具体情况如图所示:
去除数据
因为我们需要保留所有列的数据,每一列都对我们的分析具有重要意义,因此在进行数据平衡之前,我们需要先去除一些无用的行数据。为什么有些行数据没用呢?
在某些菜肴中使用了米饭这一原材料,但由于米饭在数据中无法有效区分不同菜肴,每个地区都会使用大米作为基本原材料,导致难以准确预测菜肴的所属国家。因此,为了提高模型的预测准确性,我们需要先删除这些容易引起混淆的行数据。
之后,再检查每个国家的数据是否平衡,以确保模型能够更好地学习和区分不同国家的菜肴。
<code>def create_ingredient_df(df):
ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value')
ingredient_df = ingredient_df[(ingredient_df.T != 0).any()]
ingredient_df = ingredient_df.sort_values(by='value', ascending=False,code>
inplace=False)
return ingredient_df
为此单独封装了一个函数,接下来我来详细解释一下这个函数的设计和实现。
这个函数的主要目的是接收一个 DataFrame df 作为输入参数,并处理该 DataFrame,以创建一个新的 DataFrame ingredient_df,其中包含各类食材的出现频率。
在具体的业务逻辑中,函数的处理过程较为复杂。首先,它将输入的行列进行转换,删除那些无用的国家和序号信息。接下来,函数会对剩余的每一行食材进行求和操作,以计算出各个食材的总出现频率。最后,它会筛选出频率不为零的食材,并按照频率进行排序,最终返回处理后的 DataFrame ingredient_df。
接下来,我们需要逐一检查每个国家的菜肴,识别出使用相同原料的重复行,并且这些原料的使用频率还相对较高。
thai_ingredient_df = create_ingredient_df(thai_df)
thai_ingredient_df.head(10).plot.barh()
japanese_ingredient_df = create_ingredient_df(japanese_df)
japanese_ingredient_df.head(10).plot.barh()
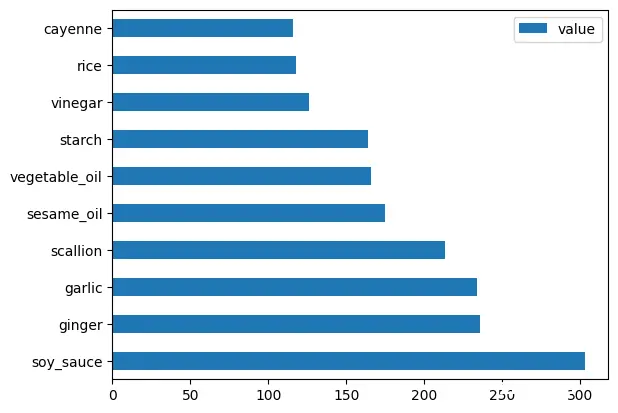
chinese_ingredient_df = create_ingredient_df(chinese_df)
chinese_ingredient_df.head(10).plot.barh()
indian_ingredient_df = create_ingredient_df(indian_df)
indian_ingredient_df.head(10).plot.barh()
korean_ingredient_df = create_ingredient_df(korean_df)
korean_ingredient_df.head(10).plot.barh()
通过这种方式,我们能够直观地查看和分析数据。为了便于理解和比较,我们将重点展示两个图表,其他图表则请自行查看和分析。
中国菜肴用到的原料数量排行:
印度菜肴用到的原料数量排行:
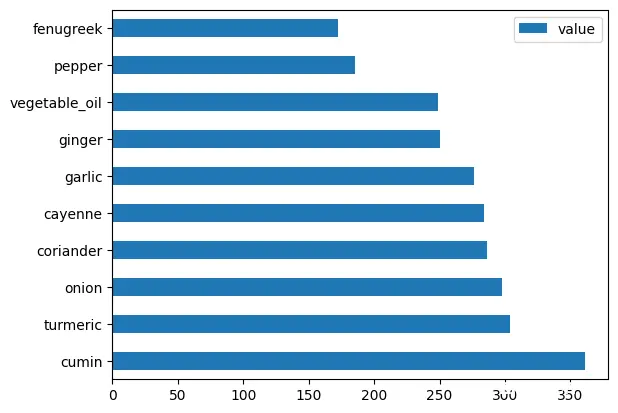
在数据处理过程中,我们注意到“garlic”(大蒜)和“ginger”(生姜)在数据集中频繁出现。因此,为了避免这些高频食材对分析结果的干扰,我们决定去除包含这些食材的菜肴。
此外,通过对其他国家菜肴的对比分析,我们发现“rice”(米饭)也是一个高重复度的原料。为了确保分析的准确性和多样性,我们最终决定从数据集中去除包含这三类原料(大蒜、生姜和米饭)的菜肴。
<code>feature_df= df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1)
labels_df = df.cuisine #.unique()
feature_df.head()
接下来,我们可以看下当前的数据分布情况,发现其仍然存在不平衡的问题。
平衡数据
这里介绍一个新方法——SMOTE(Synthetic Minority Over-sampling Technique)
SMOTE是一种常用于机器学习中的技术,特别是在处理分类问题时,当数据集中的某个类别样本数量远少于其他类别时,可以采用此方法。换句话来讲就是根据输入数据的特征去造假数据而已。目的就是解决数据不平衡问题。
<code>oversample = SMOTE()
transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)
造完数据后,将城市标签数据和原料数据合并:
transformed_df = pd.concat([transformed_label_df,transformed_feature_df],axis=1, join='outer')code>
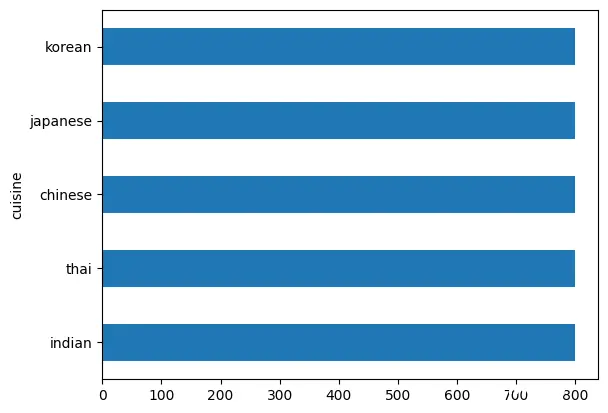
最后我们的数据分布则会更加平衡,这样对于机器训练来说也有一定好处:
transformed_df.cuisine.value_counts().plot.barh()
数据准备工作已全部完成,接下来我们将在下一章节深入探讨如何利用这些数据构建一个有效的模型。
总结
分类算法在数据科学和机器学习的领域中扮演着至关重要的角色,它不仅帮助我们从复杂的数据中提取出有意义的信息,还使我们能够在实际应用中做出更准确的决策。
通过对文本进行深入探讨,我们不仅理解了分类算法的核心逻辑,还通过一系列系统化的操作对数据进行了有效的清洗和均衡处理,从而为后续分析奠定了坚实的基础。
下一步,我们将基于本章节经过清洗处理的数据,进行模型的构建与优化。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。