从零开始学机器学习——准备和可视化数据
cnblogs 2024-09-30 09:13:00 阅读 88
首先给大家介绍一个很好用的学习地址:https://cloudstudio.net/columns
数据准备-清洗
在进行机器学习的第一步——准备数据,为了方便起见,我已经提前下载好了所需的文件。
https://files.cnblogs.com/files/guoxiaoyu/US-pumpkins.zip?t=1726642760&download=true
在大多数情况下,我们很少能够获得完全符合规范的数据集。因此,通常第一步是对数据进行清洗。就以今天的数据为例,让我给大家打开看一下,了解它的具体格式是怎样的。
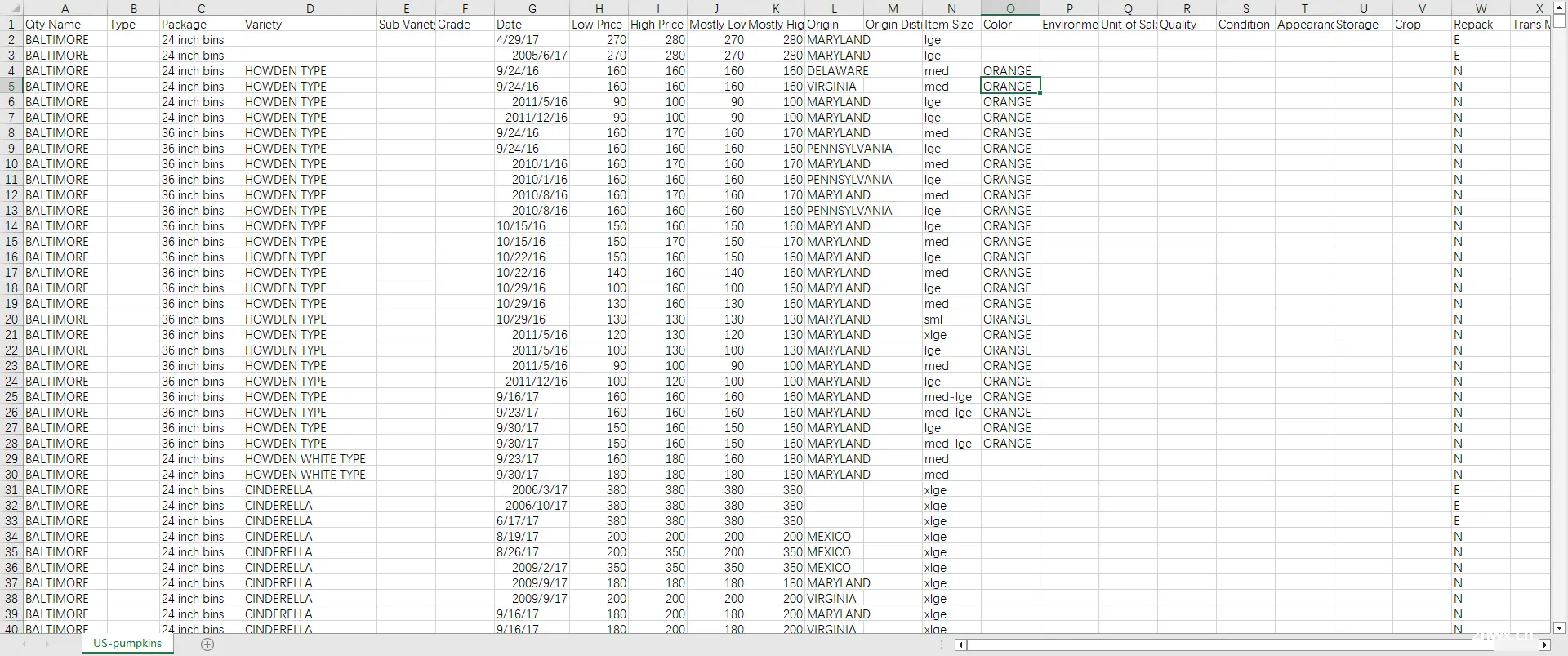
无论从哪个角度来看,这些数据都并非十分理想。它确实包含了大量信息,因此今天我们将以月份为主要维度,来统计南瓜每月的平均价格。这样做的话,我们基本上可以放弃许多其他字段。
开始解析
我们的目标是获取每月南瓜的平均价格,因此我们需要关注的字段包括月份和价格。手动删除不必要的字段,再让Python进行解析,这样的做法显得太繁琐和低效了。因此,今天我们将介绍一个非常实用的工具包:Pandas,它能够简化这一过程。
Pandas学习地址:https://pandas.pydata.org/
<code>import pandas as pd
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
print(pumpkins.head())
print(pumpkins.tail())
这里可以自行打印下前5行信息和后5行信息。
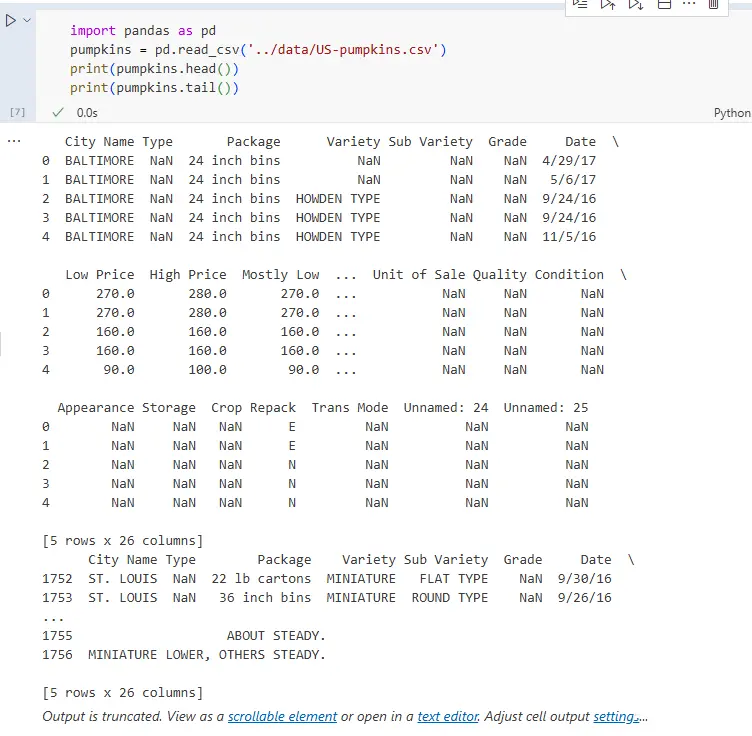
这里的数据列很多,我们需要删除那些不必要的列,只保留我们需要的月份和价格数据。
<code>new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date']
pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
print(pumpkins.isnull().sum())
注意,我们的文件中并没有"Month"这一列,这是我们后续需要用到的重要数据。另外,还有一个"Package"字段,表示称重方式,因为不同的蔬菜可能有不同的称重方式。
通常情况下,我们购买东西时按照公斤(kg)为单位称重进行结算。然而,商家有时为了促销可能会以整个南瓜的方式出售,这种称重方式的不统一是很常见的。我们需要确保只保留统一的称重方式数据。
字段解析
我们首先来计算比较简单的日期,只获取月份而不考虑年份。尽管这样做可能会导致最终数据的不准确性,因为每年各种因素会导致价格浮动很大,但暂且不考虑这些复杂因素,先处理最简单的情况。
month = pd.DatetimeIndex(pumpkins['Date']).month
print(month)
接下来我们处理价格,我们将只考虑每个菜品的最高价和最低价,然后计算它们的平均值。
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2
print(price)
现在我们来处理称重方式。针对美国地区的称重方式,我们无需过多关注细节,直接使用已经设定好的公式即可。而对于国内地区,则需要根据数据特征进行截取和调整。
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9)
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
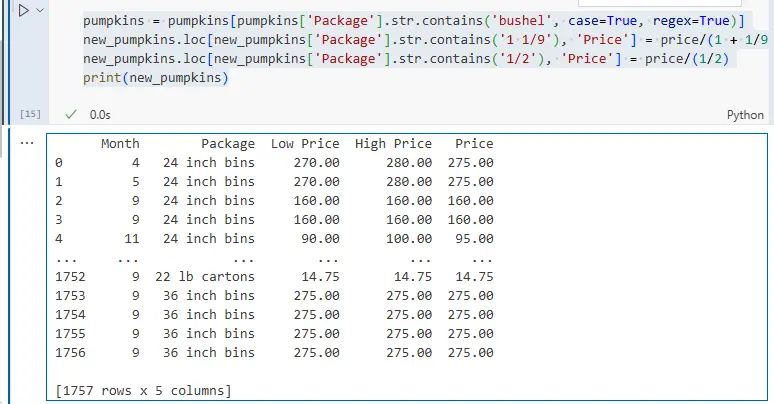
print(new_pumpkins)
效果如下:
数据可视化
我们将使用数据可视化库 Matplotlib 来呈现我们的数据分析结果。Matplotlib 是一个强大的工具,能够帮助我们创建各种类型的图表,以便更直观地展示数据趋势和关系。
Matplotlib入门学习地址是:https://matplotlib.org/
<code>import matplotlib.pyplot as plt
price = new_pumpkins.Price
month = new_pumpkins.Month
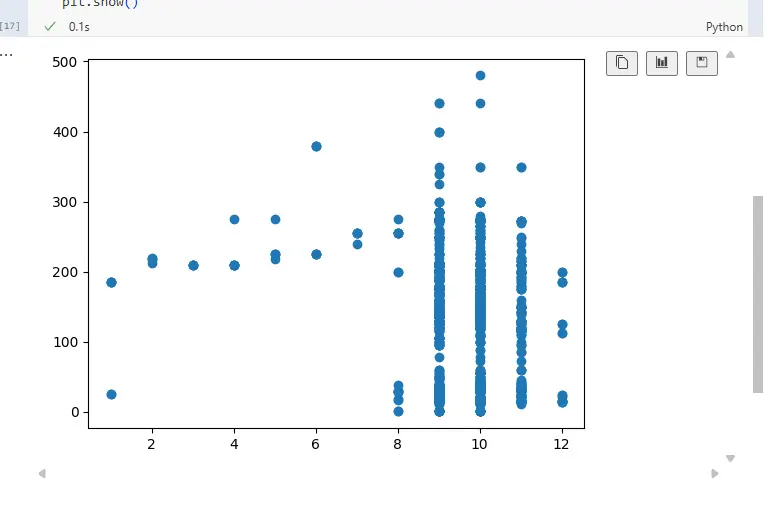
plt.scatter(month, price)
plt.show()
在这里,我们简单地将价格和月份数据显示在了 x 轴和 y 轴上,并没有特别复杂的图表设计。
我们来优化下代码:
<code>new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar')code>
plt.ylabel("Pumpkin Price")
我来解释一下:groupby方法被用来按照Month列对数据进行分组,这意味着所有具有相同月份的数据会被归为一组。
接下来,['Price'].mean()是对每个分组内的Price列计算平均值。这样,我们就得到了每个月的南瓜平均价格。
最后,.plot(kind='bar')是将计算出的平均价格数据绘制成条形图。这里的kind='bar'指定了绘图类型为条形图,它会显示每个月的平均价格,并且每个月份会对应一个条形。
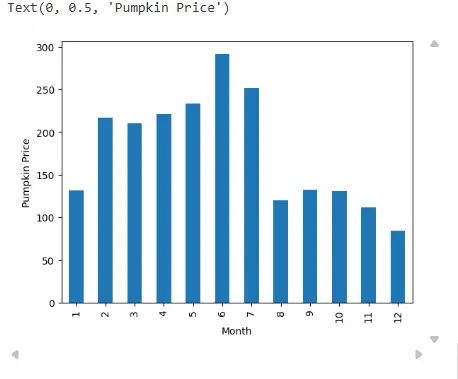
当然,数据可视化并不局限于 Matplotlib,还有许多其他依赖库可供选择,你可以根据个人喜好和需求选择适合的工具。
总结
看起来,确实我们的数据处理工作已经基本完成了。
然而,在文章中我还提到了一个重要的观点:这种方法并不能充分解释具体问题的原因。这是因为我们只是在理想条件下计算价格,而没有考虑到年份、天气以及称重等因素的影响。尽管如此,我们已经确定了数据准备的大致流程。
现在需要做的是自行决定如何维护这一流程,确保数据的清晰性和准确性。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。