牛「码」时代的到来:AI助力程序员在1024节实现技术突破
一键难忘 2024-10-24 12:01:01 阅读 54

1024程序员节|多写牛「码」,不做牛马!
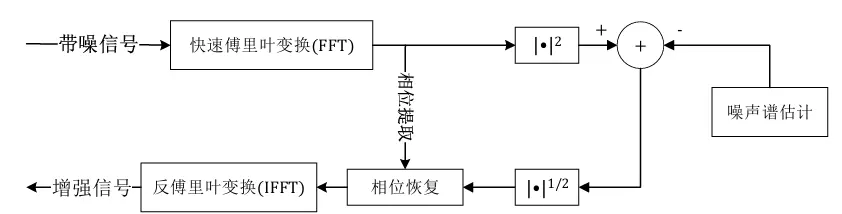
在程序员的世界里,数字1024不仅是二进制的象征,更是我们技术人心中最熟悉的“整数”。每年的10月24日,程序员们都会以此为契机,回顾过去一年的成长与收获。今年的1024程序员节,我们迎来了AI技术的蓬勃发展,深刻影响着我们编程的方式、思维和未来。

一、借势AI,写出牛「码」
随着AI技术的不断进步,特别是文生视频模型Sora和音频能力强大的GPT-4o的发布,我们的开发工作迎来了前所未有的变革。作为一名开发者,我深刻感受到了AI在提升工作效率方面的巨大潜力。通过使用GPT-4o进行代码生成与优化,我不仅能够更快地完成任务,还能在解决复杂问题时获得新的思路和灵感。
例如,在我最近的一个项目中,我们需要实现一个实时音频处理系统。起初,我花费了大量时间在文档和示例代码中查找解决方案。然而,当我决定借助GPT-4o时,事情变得截然不同。我通过简单的描述,得到了一个完整的代码框架,并在此基础上进行了调整和优化。这次经历让我认识到,AI不仅可以提升我们的工作效率,还能帮助我们在技术的海洋中找到方向,如下我特意将自己的需求和根据GPT-4o的代码来码了一篇原创技术文章,如下。
实时音频处理系统的实现
在实现实时音频处理系统时,我们首先需要选择一个合适的音频库。在这个示例中,我使用了Python的<code>pyaudio库来捕捉和处理音频流,同时结合numpy库进行音频数据的处理。
以下是我通过GPT-4o生成的基本代码框架:
1. 安装所需库
确保你已经安装了<code>pyaudio和numpy库。如果尚未安装,可以使用以下命令:
pip install pyaudio numpy
2. 实时音频处理代码
以下是实现实时音频处理的完整代码示例:
import pyaudio
import numpy as np
# 设置音频参数
FORMAT = pyaudio.paInt16 # 音频格式
CHANNELS = 1 # 单声道
RATE = 44100 # 采样率
CHUNK = 1024 # 每个音频块的大小
# 创建PyAudio对象
p = pyaudio.PyAudio()
# 打开音频流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始音频处理...")
try:
while True:
# 从音频流读取数据
data = stream.read(CHUNK)
# 将字节数据转换为numpy数组
audio_data = np.frombuffer(data, dtype=np.int16)
# 进行简单的音频处理,这里以计算音频的均方根(RMS)为例
rms = np.sqrt(np.mean(np.square(audio_data)))
print(f"当前音频均方根值: { rms:.2f}")
except KeyboardInterrupt:
print("停止音频处理...")
finally:
# 停止和关闭流
stream.stop_stream()
stream.close()
p.terminate()
3. 代码分析
在这个示例中,我们首先导入了pyaudio和numpy库,并设置了音频参数。然后,通过PyAudio对象打开一个输入音频流。在循环中,我们不断读取音频数据,并使用numpy对其进行处理。在这个例子中,我们计算了音频信号的均方根值(RMS),这可以帮助我们了解音频的强度。
4. 扩展功能
这段代码可以作为实时音频处理的基础,接下来你可以根据项目需求扩展更多功能,例如:
添加音频效果(如混响、回声等)。将处理后的音频保存到文件。实现实时音频可视化。
通过借助GPT-4o,我能够快速生成代码框架并进行必要的调整,大大提高了开发效率。这次实时音频处理系统的开发,不仅让我体会到AI的强大,还让我在实践中增强了对音频处理的理解。
二、年度牛「码」实战案例
在过去的一年中,我最引以为傲的项目是一款基于机器学习的图像识别应用。在项目初期,我们面临着数据集不足、模型准确率低等问题。经过反复尝试和调整,我决定利用开源社区的资源,借助一些已有的深度学习框架,快速构建和训练模型。
最终,我们的应用成功上线,得到了用户的积极反馈。这让我意识到,通过开源贡献和社区合作,我们不仅能够突破技术瓶颈,还能在实际应用中实现技术的价值。这次经历让我体会到“轻舟已过万重山”的成就感,也让我更加坚定了在开发道路上不断探索的决心。
下文是我当时根据项目代码来创作的一篇原创技术博文,如下。
基于机器学习的图像识别应用实现
在这款图像识别应用的开发过程中,我们采用了TensorFlow和Keras这两个流行的深度学习框架。通过利用它们强大的功能和社区支持,我们能够快速构建和训练图像分类模型。
1. 数据准备
为了提高模型的准确率,我们从Kaggle等开源平台上获取了公开数据集,同时利用数据增强技术来扩展我们的训练集。我们使用<code>ImageDataGenerator来进行数据增强,增加图像的多样性。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 创建数据增强生成器
train_datagen = ImageDataGenerator(
rescale=1./255, # 归一化
rotation_range=40, # 随机旋转
width_shift_range=0.2, # 水平平移
height_shift_range=0.2, # 垂直平移
shear_range=0.2, # 剪切
zoom_range=0.2, # 缩放
horizontal_flip=True, # 随机翻转
fill_mode='nearest' # 填充策略code>
)
# 生成训练集
train_generator = train_datagen.flow_from_directory(
'data/train', # 训练集目录
target_size=(150, 150), # 目标图像大小
batch_size=32,
class_mode='binary' # 二分类code>
)
2. 模型构建
在构建模型时,我们选择使用卷积神经网络(CNN),因为它在图像分类任务中表现良好。以下是我们构建的模型示例:
from tensorflow.keras import layers, models
# 构建卷积神经网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),code>
layers.MaxPooling2D(2, 2),
layers.Conv2D(64, (3, 3), activation='relu'),code>
layers.MaxPooling2D(2, 2),
layers.Conv2D(128, (3, 3), activation='relu'),code>
layers.MaxPooling2D(2, 2),
layers.Conv2D(128, (3, 3), activation='relu'),code>
layers.MaxPooling2D(2, 2),
layers.Flatten(),
layers.Dense(512, activation='relu'),code>
layers.Dense(1, activation='sigmoid') # 二分类code>
])
# 编译模型
model.compile(loss='binary_crossentropy',code>
optimizer='adam',code>
metrics=['accuracy'])
3. 模型训练
使用准备好的数据生成器,我们开始训练模型。训练过程中的准确率和损失值将实时输出,以帮助我们监控模型的表现。
# 训练模型
history = model.fit(
train_generator,
steps_per_epoch=100, # 每个epoch的步数
epochs=15, # 训练的epoch数量
verbose=1
)
4. 结果评估
训练完成后,我们可以使用测试数据集对模型进行评估。我们还可以利用可视化工具展示训练过程中的准确率和损失变化。
import matplotlib.pyplot as plt
# 绘制训练过程中的准确率和损失
plt.plot(history.history['accuracy'], label='训练准确率')code>
plt.plot(history.history['loss'], label='训练损失')code>
plt.title('模型训练过程')
plt.xlabel('Epoch')
plt.ylabel('准确率/损失')
plt.legend()
plt.show()

通过这一项目,我不仅增强了对机器学习的理解,更重要的是我学会了如何有效利用开源资源来解决实际问题。我们的图像识别应用成功上线后,用户反馈非常积极,证明了我们所做的努力是值得的。
在未来的工作中,我希望能够将这款应用扩展到更多的场景中,比如实时视频监控、人脸识别等。通过不断探索和实践,我们可以将技术的价值发挥到极致,创造出更多有意义的项目。
三、不做牛马,「编程人生」也能易如反掌
在这不断变化的技术环境中,如何轻松拿捏编程人生,成为了我思考的重点。作为开发者,我们不仅需要保持技术的更新,还要关注职业生涯的规划。我意识到,建立一个良好的学习习惯、积极参与社区活动是保持竞争力的关键。
我开始定期参加技术分享会,与同行交流经验。同时,我还在业余时间学习新的编程语言和框架,以便在未来的项目中应用。通过这些努力,我不仅提升了自己的技术水平,还拓宽了视野,发现了更多可能性。
建立良好的学习习惯与职业规划
在我的职业生涯中,我深刻体会到持续学习和自我提升的重要性。作为开发者,面对快速变化的技术环境,良好的学习习惯和职业规划可以帮助我们在竞争中脱颖而出。以下是一些我总结的有效策略,供大家参考。
1. 制定学习计划
首先,制定一个明确的学习计划至关重要。无论是学习新的编程语言、框架还是算法,提前规划可以帮助我们高效利用时间。建议每周至少花费几个小时进行学习,结合在线课程、书籍和实战项目。比如,我最近学习了<code>Go语言,计划通过完成一个小项目来巩固所学知识。
学习计划示例
第一周:了解Go语言基础语法,完成相关在线课程。第二周:实现一个简单的RESTful API,应用HTTP包和路由处理。第三周:学习并实现数据持久化,使用Gorm进行数据库操作。第四周:优化代码结构,并尝试使用Go的并发特性进行性能提升。
2. 积极参与开源项目
参与开源项目不仅能够提高技术能力,还能增强团队合作和沟通能力。通过贡献代码和撰写文档,我们可以与全球开发者建立联系,并从他们的反馈中学习。在GitHub上寻找感兴趣的项目,或者尝试为一些小型项目提供bug修复或功能扩展,这些都能为自己的简历增添亮点。
3. 参加技术分享与交流活动
如前所述,定期参加技术分享会是提升自身能力的重要途径。在这些活动中,我们不仅能学习到新技术,还能结识志同道合的朋友。建议寻找本地的技术社区或参加线上技术大会,分享自己的经验,同时吸收他人的见解。
4. 积累项目经验
在实践中学习是提升编程能力的最佳方式。我建议每位开发者都可以尝试完成一些个人项目。这些项目可以是应用程序、网站或工具,旨在解决某个具体问题。通过项目实践,我们可以在真实场景中应用所学知识,发现自己的不足并加以改进。
项目示例
图像处理工具:利用Python和OpenCV库,开发一个图像滤镜应用,支持用户自定义滤镜效果。个人博客系统:使用Flask或Django框架,构建一个简单的个人博客网站,支持Markdown格式的文章发布和评论功能。实时天气查询应用:利用API获取天气数据,开发一个前端应用,展示用户所在城市的实时天气信息。
5. 不断拥抱新技术
随着AI、区块链等新兴技术的兴起,我们应该保持开放的心态,主动学习这些技术。参加相关的在线课程、研讨会,或通过阅读专业书籍和文献,保持对新技术的敏感性。例如,我最近开始研究TensorFlow,希望将其应用于机器学习项目中。
6. 职业生涯规划
最后,职业生涯的规划同样重要。明确自己的职业目标,例如希望成为技术专家、项目经理或创业者,制定相应的成长路径。根据目标,选择适合的学习内容、项目经验和社交网络。
在职业生涯的不同阶段,我们也可以考虑更换公司、岗位或技术领域,寻找适合自己的发展机会。通过积极的自我反思和规划,我们能够把握职业生涯的主动权。
在这个技术不断演变的时代,作为开发者,我们要保持学习的热情与探索的勇气。建立良好的学习习惯、积极参与社区、不断提升技能,将为我们的职业生涯带来更多机遇。让我们一起拥抱变化,努力让编程人生变得更加精彩

寄语
1024程序员节是一个值得我们庆祝的日子。在这个特别的时刻,让我们共同回顾过去的成就与挑战,展望未来的无限可能。愿我们在技术的道路上,继续多写牛「码」,不做牛马,以更大的热情和勇气迎接下一个十年!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。