如何高效优雅的完成一次机器学习服务部署?一文详解部署难点以及实战案例
CSDN 2024-08-01 09:31:01 阅读 84
伴随着ChatGPT的大火,很多人也逐渐认识到人工智能正在逐步由底层建筑上升到交互服务,其实在没有兴起ChatGPT时,人工智能技术就已经发展的比较成熟了。像是现在机器学习以及深度学习都已经普及在各大高校社区了,而且市场上已经有非常多的目标识别、图像检测等计算机视觉落地项目,可以说这是人工智能发展最为迅速的十年,受到ChatGPT的冲击,将来人工智能的速度只会只增不减。
尽管人工智能技术已经比较成熟,但机器学习服务的落地仍然存在一些限制,如数据安全性、模型可解释性、部署成本等问题。为了摆脱这些限制,人工智能从底层建筑到交互服务的转变是必然的。随着ChatGPT等技术的出现,人工智能正在逐步实现智能交互,使得机器学习服务得以更加灵活、高效、安全地落地。在这个过程中,需要采用新的技术和方法,如联邦学习、深度强化学习、解释性机器学习等,以解决当前机器学习服务落地面临的问题,并推动人工智能技术更快地发展和普及。
当然以上这些处理方法,并没有字面上写的那样简单就能实现,完完整整落地一个机器学习的项目比我们想的要困难得多,而且我们若想持久保持模型迭代以及保证模型准确性的稳定性和灵活性,代价就会很高。倘若我们必须要快速落地一个机器学习人工智能项目,我们要了解现需要面对什么样的限制以及困境,以及如何应对它们。
最近受邀参与了亚马逊云科技【云上探索实验室】活动,利用基于Amazon SageMaker完全托管的机器学习服务高效的完成一次机器学习服务部署-贷款违约数据训练 XGBoost 二进制分类模型,在Amazon SageMaker上实验进行的非常顺利且该平台功能俱全便捷,训练迭代模型也十分快捷,适用场景广泛,很值得机器学习工程师一用。https://dev.amazoncloud.cn/experience?trk=cndc-detail&sc_medium=corecontent&sc_campaign=product&sc_channel=csdn
一、如何摆脱机器学习服务的落地限制
一般来说完成机器学习服务部署需要遵循以下几个步骤,以确保高效优雅地完成:
确认模型需求:首先,需要明确模型的需求和目标,比如要解决什么问题,需要哪些数据和特征,以及模型需要达到的性能指标等。数据预处理:对数据进行预处理和清洗,以确保数据质量和一致性,同时进行特征工程,提取有意义的特征。模型选择和训练:选择适当的机器学习模型,并使用训练数据集对模型进行训练和调优,以获得最佳性能。模型评估和验证:使用测试数据集对模型进行评估和验证,确保模型具有良好的泛化能力和鲁棒性。模型部署:选择合适的部署平台和技术,将训练好的模型部署到生产环境中,以实现对外提供服务的能力。

1.1困境分析
那么就以上述基础服务部署流程来看,有五点是必须也是容易注意到的问题:
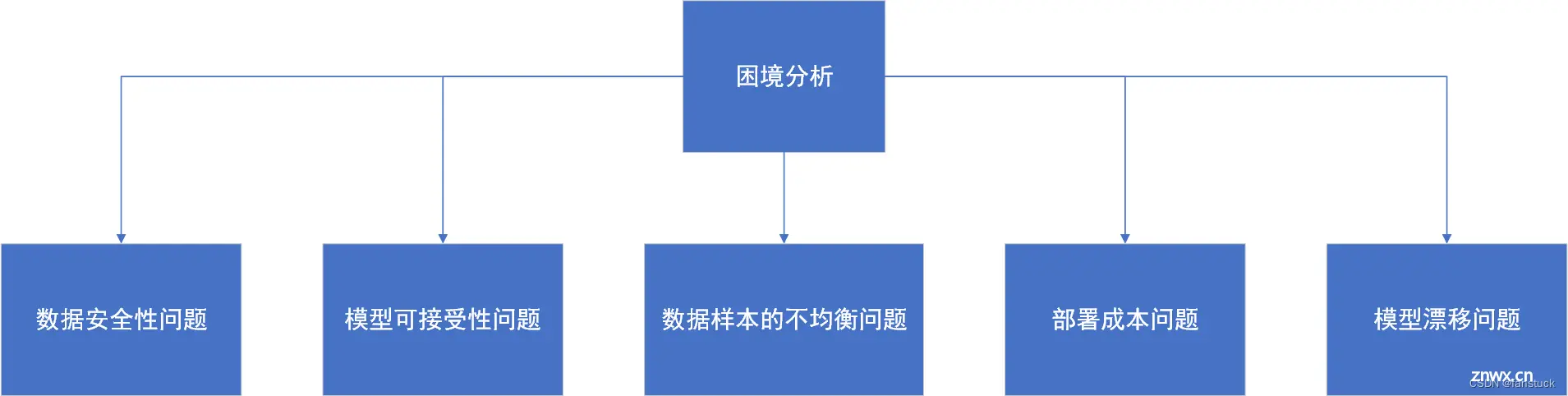
数据安全性问题:机器学习模型的性能和效果与数据质量和数量直接相关。然而,这些数据往往涉及个人隐私和商业机密等敏感信息,因此,数据安全成为了一个很大的限制。如何在数据共享和数据隐私之间找到平衡是一个难题。模型可解释性问题:机器学习模型往往是一种黑盒子,难以解释其推理过程和结果。这使得机器学习在金融、医疗等关键领域的应用受到质疑,对于一些决策敏感的场景,解释性机器学习显得尤为重要。部署成本问题:机器学习模型的部署和维护成本通常比较高,需要有专业的工程师和系统来支持,这使得很多中小企业无法享受机器学习的好处,限制了机器学习在各行各业的应用。数据样本的不均衡问题:在机器学习中,数据样本的不均衡会导致模型训练出现偏差,影响模型的效果和稳定性。同时,如果训练数据不具有代表性,也会导致模型的泛化能力不足。模型漂移问题:随着时间推移,机器学习模型的性能和效果会逐渐下降,需要进行重新训练和更新。同时,模型在生产环境中的表现和测试集中可能会有所不同,需要不断地进行监控和调整。
1.1.1数据安全性问题
数据安全性问题是机器学习服务落地的一个重要限制。数据作为机器学习模型的基石,模型的质量和效果往往直接受数据质量和数量的影响。同时,由于很多数据涉及到个人隐私和商业机密等敏感信息,因此,数据的安全性就显得尤为重要。
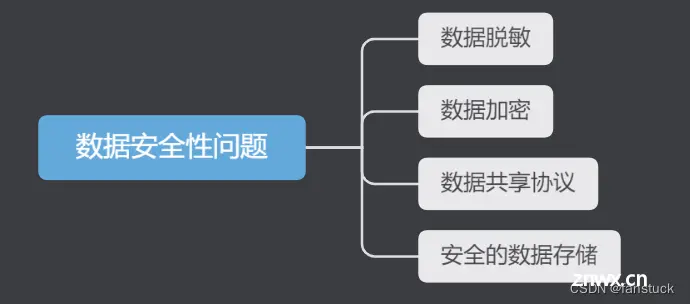
解决数据安全性问题的方法有以下几种:
数据脱敏:数据脱敏是一种常见的数据保护方法,它通过修改或删除个人身份信息、敏感数据等方法,保护原始数据的隐私性。例如,可以对数据进行匿名化处理、脱敏处理等方法。数据加密:数据加密是一种将原始数据转换为密文的方法,从而保护数据的隐私性。例如,可以使用对称加密、非对称加密等方法对数据进行加密保护,以确保数据传输和存储的安全性。数据共享协议:数据共享协议是一种规范数据共享行为的方法,通过制定数据共享协议,确保数据使用方仅在特定的条件下使用和访问数据。例如,可以制定访问和使用权限、数据使用场景等方面的规定,从而保护数据的隐私性。安全的数据存储:安全的数据存储是保障数据安全的一种关键手段,它需要确保数据存储的安全性、完整性和可用性。例如,可以采用数据备份、数据恢复、数据加密等技术手段,从而确保数据在存储和传输过程中的安全性。
1.1.2模型可解释性问题
模型可解释性问题是指在机器学习模型的应用过程中,用户或客户无法理解或解释模型的决策过程和结果,从而降低了模型的可信度和可接受性。
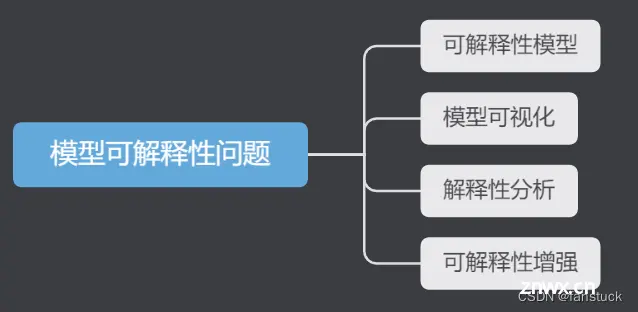
解决模型可解释性问题的方法有以下几种:
可解释性模型:选择可解释性较好的模型是解决模型可解释性问题的一个有效方法。例如,决策树、线性回归等模型在预测过程中可以直接展示决策路径和权重,便于理解和解释。模型可视化:通过可视化的方式展示模型的决策过程和结果,使用户和客户能够更好地理解模型的决策依据。例如,可以使用热力图、散点图、柱状图等方式展示模型的特征重要性、预测结果等信息。解释性分析:通过分析模型的预测结果和特征,寻找模型的决策规律和影响因素,从而解释模型的决策过程和结果。例如,可以使用特征重要性分析、决策边界分析等方法解释模型的决策规律。可解释性增强:通过在模型训练过程中增加可解释性的约束条件,强制模型学习可解释性较好的决策规律和特征。例如,可以使用局部线性近似、约束优化等方法增强模型的可解释性。
1.1.3部署成本问题
部署成本问题是指在机器学习模型的部署过程中,需要投入大量的时间和资源来完成部署,从而增加了部署的成本和难度。
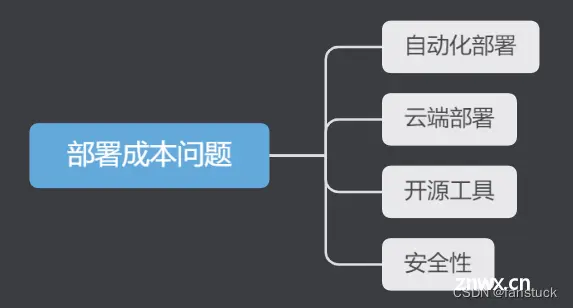
解决部署成本问题的方法有以下几种:
自动化部署:采用自动化部署技术可以大幅度降低部署的成本和难度。例如,可以使用容器技术(如Docker)来实现自动化部署,将模型和依赖项打包成容器,快速部署到生产环境中。云端部署:将模型部署到云端平台上,可以充分利用云端平台的资源和服务,同时降低部署的成本和难度。例如,可以使用AWS云端平台提供的机器学习服务,快速部署和调用模型。开源工具:利用开源工具可以大幅度降低部署的成本和难度。例如,可以使用TensorFlow Serving、Kubeflow等开源工具,快速搭建机器学习模型服务。安全性:在部署机器学习模型时,需要考虑到安全性问题,防止模型被攻击或滥用。例如,可以使用加密技术、访问控制、监控等方式保证模型的安全性。
1.1.4数据样本的不均衡问题
数据样本的不均衡问题是指在机器学习训练数据中,不同类别的数据样本数量不平衡,导致机器学习模型在预测时对于少数类别的数据表现较差的问题。
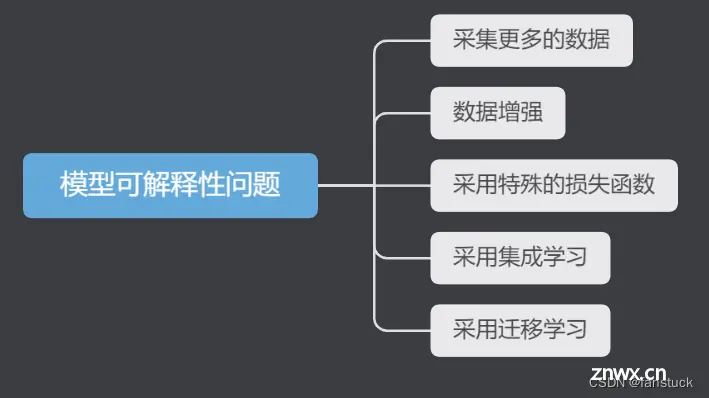
解决数据样本不均衡问题的方法有以下几种:
采集更多的数据:通过增加少数类别的数据数量来平衡训练数据集的类别分布,从而提高模型对于少数类别的识别能力。数据增强:通过对于原始数据进行一些变换,如旋转、平移、裁剪等,来增加数据样本的多样性,从而提高模型对于少数类别的泛化能力。采用特殊的损失函数:采用一些特殊的损失函数,如Focal Loss、Class Balanced Loss等,来调整训练样本的权重,从而使得模型更加关注少数类别的数据。采用集成学习:采用集成学习的方式,如Bagging、Boosting等,将多个模型的预测结果进行整合,从而提高模型对于少数类别的识别能力。采用迁移学习:采用迁移学习的方式,将预训练好的模型迁移到新的任务上,从而提高模型对于少数类别的识别能力。
1.1.5模型漂移问题
模型漂移问题指的是当训练好的机器学习模型在应用阶段的数据分布发生变化时,模型的预测性能下降的问题。这种情况下,模型需要不断地进行更新和重新训练,以保证其在新的数据分布上的预测性能。
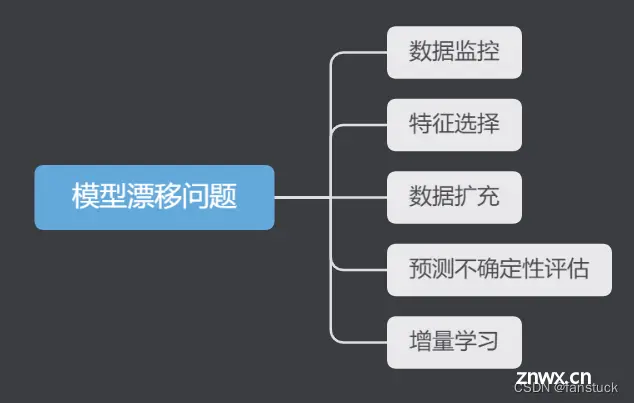
解决模型漂移问题的方法有以下几种:
数据监控:在应用阶段对数据进行监控,当发现数据分布发生变化时,及时调整模型。特征选择:选择更加稳定的特征,减少模型对于不稳定特征的依赖,以减少模型漂移的风险。数据扩充:通过对数据进行扩充,增加数据的多样性和数量,使得模型更加鲁棒。预测不确定性评估:在应用阶段对模型的预测结果进行不确定性评估,当模型的不确定性超出一定阈值时,及时重新训练模型。增量学习:通过增量学习的方法,让模型能够不断地从新的数据中进行学习,从而减少模型漂移的风险。
那么就现在来说,我们了解了一般的机器学习服务搭建流程,也清楚了我们将会面临什么样的困难,当然也知晓了对于这些困难我们可以用何种方法去应对它们,但是要是在短期内快速启动机器学习服务还是相当困难,于是如何探索能够解决上述问题以及能够实现一站式开发的平台成为了快速搭建机器学习服务的首要问题。
1.2高效探索
那么一个高可用机器学习服务部署平台,需要以下几种特质:
模型训练和优化:提供可靠的、可扩展的、高效的机器学习算法和计算资源,帮助用户进行模型训练和优化。模型部署:提供可扩展的、高性能的模型部署环境,支持实时和批量推理,并能够自动缩放和调整部署资源以满足流量需求。模型管理和监控:支持模型版本控制、自动化部署和回滚,提供实时的性能和健康监控,以及异常检测和自动修复功能。数据管理和预处理:提供数据集管理、数据清洗和预处理工具,支持自动化特征工程和数据增强。安全和隐私保护:提供安全的数据存储和传输、访问控制和认证、数据加密和脱敏、以及隐私保护和法规合规功能。集成和扩展性:提供开放的API和SDK,支持与第三方系统的集成,以及可扩展的架构和模块化的组件。用户界面和交互体验:提供用户友好的界面和交互体验,支持可视化的数据分析和模型调试,以及自动化的任务调度和流程管理。
其实市面上已经有比较成熟的机器学习平台了,那么我们就根据Amazon SageMaker平台来探索机器学习服务应该如何落地。
二、探索高效实现部署捷径-基于Amazon SageMaker完全托管的机器学习服务
Amazon SageMaker是亚马逊AWS提供的一项机器学习服务,它提供了一整套完整的机器学习流程,包括数据预处理、模型构建、训练、调优、部署等一系列功能。通过Amazon SageMaker,开发人员和数据科学家可以更轻松地构建、训练和部署机器学习模型,并快速将其应用于生产环境中。

Amazon SageMaker还具有自动模型调整功能,它可以通过自动调整超参数,最大限度地提高模型的准确性。此外,SageMaker还提供了与其他AWS服务集成的功能,如Amazon S3、Amazon Athena、Amazon Redshift和AWS Lambda,从而为用户提供完整的数据处理和存储解决方案。
2.1Amazon SageMaker 的工作原理
Amazon SageMaker 的工作原理其工作原理可以概括为以下几个步骤:
数据准备:用户可以将数据集上传到Amazon S3或使用Amazon Athena从其他数据存储中获取数据。用户还可以使用Amazon SageMaker提供的预处理功能进行数据清洗和转换。模型设计和训练:用户可以使用Amazon SageMaker内置的算法或自定义算法来训练模型。用户可以选择使用单个实例或多个实例进行分布式训练。在训练期间,Amazon SageMaker会自动调整实例数量,以确保高效地利用计算资源。模型优化:用户可以使用Amazon SageMaker提供的超参数优化功能来寻找最佳的超参数组合,以提高模型性能。模型部署:用户可以选择将模型部署为RESTful API或使用Amazon SageMaker托管的推理实例。用户还可以使用AWS Lambda或Amazon ECS等其他服务将模型集成到应用程序中。监控和管理:用户可以使用Amazon CloudWatch监控模型的性能和健康状况,并根据需要对模型进行调整和优化。Amazon SageMaker还提供了自动化功能,如自动缩放和故障转移,以确保模型的高可用性和稳定性。
2.2高效完成一次机器学习服务部署-贷款违约数据训练 XGBoost 二进制分类模型
以金融风控中的个人信贷为背景,根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。
XGBoost在各种数据挖掘、预测和分类任务中取得了极高的准确率和性能。是目前应用最广泛的机器学习算法之一。可以说,XGBoost的快速发展和广泛应用,推动了机器学习算法的进一步发展和优化,为人工智能技术的普及和应用打下了坚实的基础。
XGBoost的全程为eXtreme Gradient Boosting,即极度梯度提升树。
XGBoost本质上仍然属于GBDT算法,但在算法精度、速度和泛化能力上均要优于传统的GBDT算法。
从算法速度上来看,XGBoost使用了加权分位树sketch和稀疏感知算法这两个技巧,通过缓存优化和模型并行来提高算法速度;从算法泛化能力上来看,通过对损失函数加入正则化项、加性模型中设置缩减率和列抽样等方法,来防止模型过拟合。XGBoost根据结构分数的增益情况计算出来选择哪个特征作为 分割点,而某个特征的重要性就是它在所有树中出现的次数之和。 也就是说一个属性越多的被用来在模型中构建决策树,它的重要性就相对越高。那么我们就用贷款违约数据训练 XGBoost 二进制分类模型来实现对贷款违约的预测。
1.分布式训练
Amazon SageMaker内置算法对于XGBoost的支持非常好,可以直接通过Amazon SageMaker的参数来设置所有的XGBoost的超参。

那么我们选定超参数(非最优):
hyperparameters = {'alpha': 0.0,
'colsample_bylevel': 0.4083530569296091,
'colsample_bytree': 0.8040025839325579,
'eta': 0.11764087266272522,
'gamma': 0.43319156621549954,
'lambda': 37.547406128070286,
'max_delta_step': 10,
'max_depth': 6,
'min_child_weight': 5.076838893848415,
'num_round': 100, # Not tuned: kept fixed
'subsample': 0.8915771964367318,
'num_class': 10, # Not tuned: defined by Fashion MNIST
'objective': 'multi:softmax' # Not tuned: defined by Fashion MNIST
}
2.数据预处理
使用Amazon SageMaker内置的算法我们基本不会自己实现算法代码,而只是通过调用Amazon SageMaker的SDK或者API来实现模型训练,因此数据的读取逻辑完全是由内置算法本身来实现的。Amazon SageMaker内有封装好ShardByS3Key数据集分片。
分片的数量至少要大于或等于将来要运行实例的数量,我们要使用ShardByS3Key是S3前缀做Shard的方式对数据集进行切片并分配给不同的训练实例使用。使用SageMaker ShardByS3Key的方式进行数据集切片实际在API调用时比较简单,加入一个参数 distribution='ShardedByS3Key’即可:
train_input = TrainingInput(train_url, content_type=content_type, distribution='ShardedByS3Key')
3.训练XGBoost模型
使用SageMaker中内置算法实现分布式训练很容易:
data = pd.read_csv("贷款数据.csv")
# construct a SageMaker estimator that calls the xgboost-container
estimator = sagemaker.estimator.Estimator(image_uri=xgboost_container,
hyperparameters=hyperparameters,
role=sagemaker.get_execution_role(),
instance_count=2,
instance_type='ml.m5.xlarge',
volume_size=5, # 5 GB
output_path=output_path)
# execute the XGBoost training job
estimator.fit({'train': data, 'validation': validation_input})
可以通过混淆矩阵和准确率、召回率和F1值来进行判断:
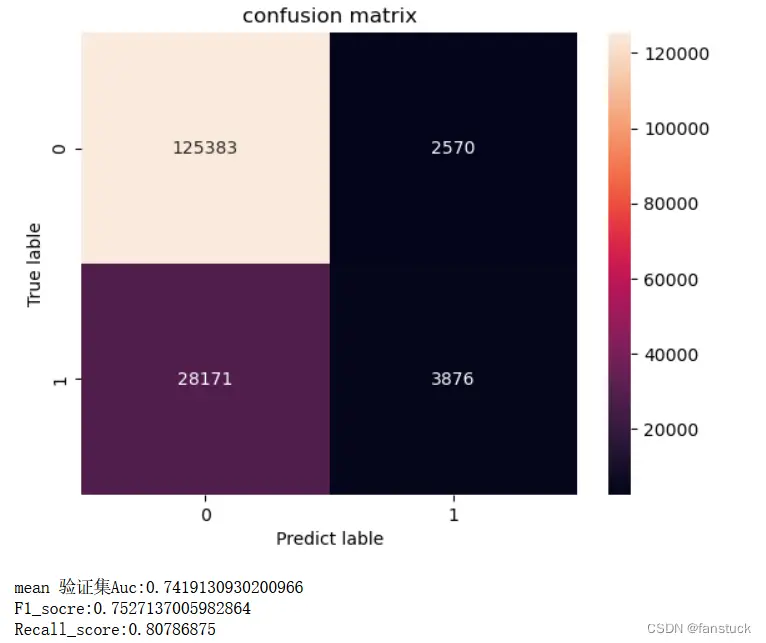
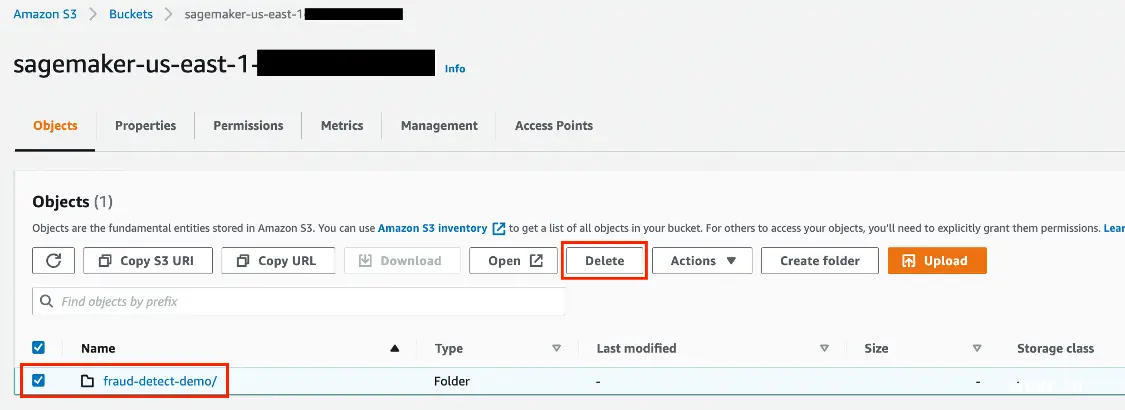
4.清理资源
最后一定要记得清理资源,以免产生意外费用。
三、总结
在Amazon SageMaker使用贷款违约数据训练XGBoost 二进制分类模型的过程可以总结为以下步骤:
数据准备:从公共数据集中获取数据,并进行数据清洗和特征工程处理,将数据转化为适合机器学习算法处理的格式。创建SageMaker Notebook实例:通过AWS Management Console或AWS SDK创建SageMaker Notebook实例,并连接到实例。编写代码:在Notebook中编写代码,使用Amazon SageMaker提供的XGBoost算法和数据输入通道,加载并处理数据,训练并评估模型。模型调优:通过调整模型的参数和超参数,优化模型性能。部署模型:通过Amazon SageMaker提供的部署服务,将训练好的模型部署到线上环境,可以使用API接口进行预测。模型监控:通过Amazon SageMaker提供的监控功能,对模型进行实时监控和报警,及时发现模型性能下降或异常情况。模型更新和重训练:当数据集有变化或者模型性能不佳时,可以通过Amazon SageMaker提供的自动化工具对模型进行更新和重训练,保持模型的准确性和可用性。
通过使用Amazon SageMaker,用户可以更加高效地完成机器学习模型的训练、部署和管理,大大降低了机器学习应用的开发和维护成本,同时提高了模型的可用性和性能。
从上述实践可以看出,Amazon SageMaker提供了一个非常强大的机器学习平台,可以帮助我们快速构建、训练和部署机器学习模型。使用Amazon SageMaker时,我们可以使用多种常用机器学习框架,包括TensorFlow、PyTorch和Scikit-Learn等,同时也支持自定义算法。
在这个实践中,我们使用了贷款违约数据,训练了一个XGBoost二进制分类模型,并使用Amazon SageMaker的批量推理功能,批量处理了测试数据并得出了预测结果。整个过程相对来说比较简单,尤其是使用SageMaker Studio提供的Notebook和Autopilot功能,能够让我们快速构建和训练模型。
r时,我们可以使用多种常用机器学习框架,包括TensorFlow、PyTorch和Scikit-Learn等,同时也支持自定义算法。
在这个实践中,我们使用了贷款违约数据,训练了一个XGBoost二进制分类模型,并使用Amazon SageMaker的批量推理功能,批量处理了测试数据并得出了预测结果。整个过程相对来说比较简单,尤其是使用SageMaker Studio提供的Notebook和Autopilot功能,能够让我们快速构建和训练模型。
总之,Amazon SageMaker是一个非常强大和灵活的机器学习平台,能够帮助我们快速构建、训练和部署机器学习模型,同时也需要我们在使用过程中注意一些问题,保障数据安全和合理使用。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。