20240718 每日AI必读资讯
程序员的店小二 2024-07-27 11:31:03 阅读 73

大模型集体失智!9.11和9.9哪个大,几乎全翻车了
- AI处理常识性问题能力受限,9.11>9.8数学难题暴露了AI短板。
- 训练数据偏差、浮点精度问题和上下文理解不足是AI在数值比较任务上可能遇到的困难。
- 改进AI需优化训练数据、Prompt设计、数值处理准确性和逻辑推理能力,以提高处理常识性问题的能力。
🔗大模型集体失智!9.11和9.9哪个大,几乎全翻车了-CSDN博客


又一个AI搜索引擎诞生:Exa AI
- 称要做真正的 AI 搜索引擎取代Google
- 与传统搜索引擎不同的是,Exa 的搜索引擎专为AI模型设计。
- 使用向量数据库和嵌入模型(embedding models)技术,训练模型来预测下一个相关链接,而不是下一个词。这个方法使Exa能够处理链接数据集,从而提供与众不同的搜索结果。
- Exa使用端到端的Transformer模型来过滤互联网信息,根据查询的实际意义而非关键词进行筛选。
🔗网站: https://exa.ai/


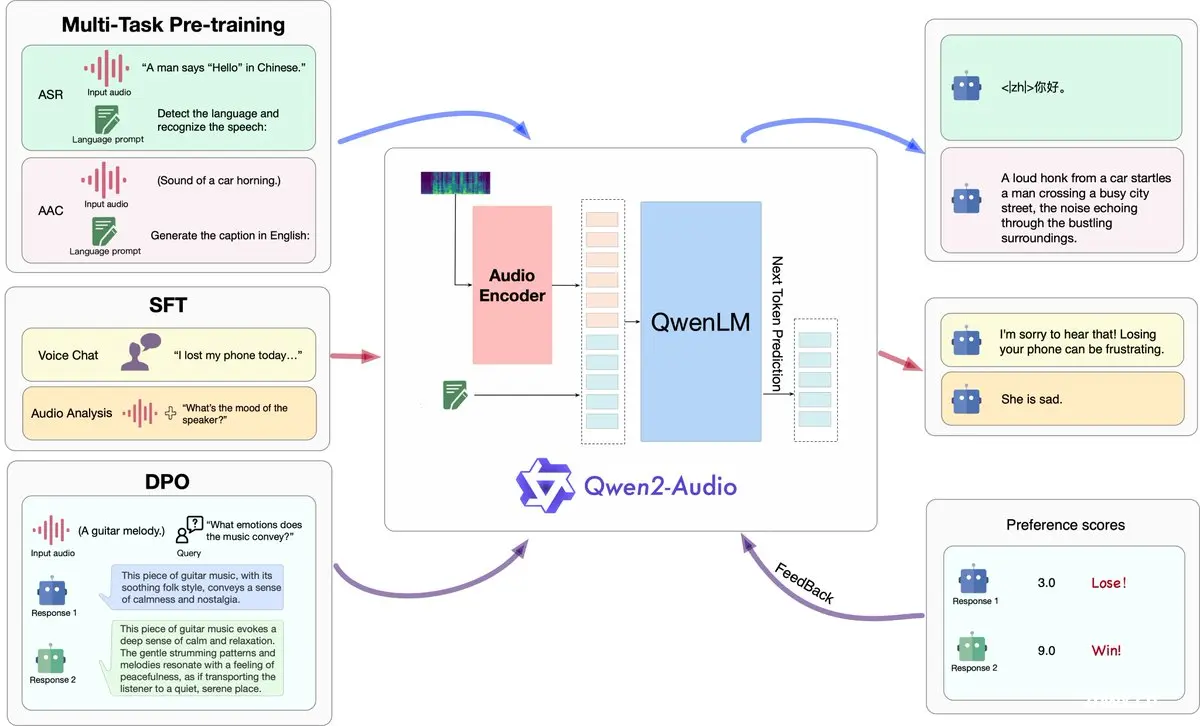
阿里巴巴发布语音模型:Qwen2-Audio
- 可与模型直接语音对话以及分析转录各种声音
- Qwen2-Audio可以通过语音聊天和音频分析两种方式与用户互动。在语音聊天模式下,用户可以与模型进行直接的语音对话,在音频分析模式下,用户可以上传音频文件进行转录分析等。
- Qwen2-Audio 能够识别语音中的情感,如愤怒、快乐、悲伤等。
- 用户无需区分语音聊天和音频分析模式,模型能够智能识别并在实际使用中无缝切换两种模式。
- Qwen2-Audio的模型架构由音频编码器和大语言模型组成:音频编码器基于Whisper-large-v3模型;基础组件是Qwen-7B
🔗GitHub:https://github.com/QwenLM/Qwen2-Audio
🔗论文:https://arxiv.org/pdf/2407.10759

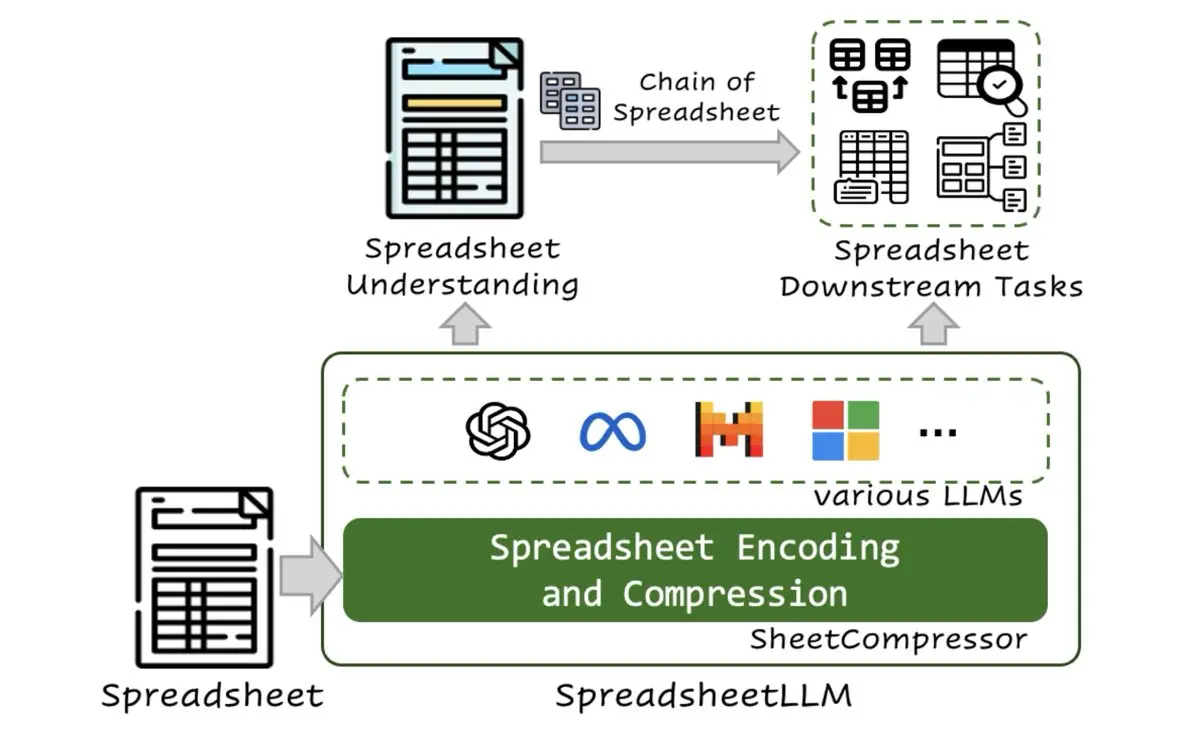
微软团队研究出新方法:可以让大语言模型更好地理解和处理电子表格数据
- 该方法显著提高了模型在电子表格表格检测和问答任务中的性能,同时大大减少了处理所需的计算资源。
- 在电子表格表格检测任务中的性能相比基础方法提高了25.6%,并且在F1评分上达到了78.9%,超过了现有最好的模型12.3%。
- SPREADSHEETLLM主要通过三个主要步骤来实现:
结构锚点压缩:识别并保留表格边界的重要行和列,删除不重要的重复行和列,从而减少数据量。
倒排索引翻译:将电子表格中的相同数据合并,减少重复数据,优化数据结构。
数据格式聚合:根据单元格的数据格式,将相同格式的数据聚合在一起,进一步减少数据量。

Mistral发布了2个7B小模型:CodestralMamba 7B和Mathstral 7B
- Codestral Mamba超越了DeepSeek QwenCode,成为小于10B参数的最佳模型,并且可以与Codestral22B竞争,并且支持256K的上下文。
- 与传统的Transformer模型不同,Mamba模型在处理时间上更高效,并且可以处理无限长度的输入序列。用户可以免费使用、修改和分发该模型,适用于各种代码相关的应用场景。
🔗官方介绍:https://mistral.ai/news/codestral-mamba/
🔗模型下载:https://huggingface.co/mistralai/mamba-codestral-7B-v0.1
🔗模型下载:https://huggingface.co/mistralai/mathstral-7B-v0.1
🔗详情:MathΣtral | Mistral AI | Frontier AI in your hands


可在手机运行!Hugging Face推小语言模型SmolLM
- 高效性能: SmolLM模型在低计算资源下表现出色,保护用户隐私。
- 丰富数据: 使用高质量的SmolLM-Corpus数据集,确保模型学习到多样知识。
- 多种应用: 适用于手机、笔记本等设备,灵活运行,满足不同需求。
🔗 https://huggingface.co/blog/smollm

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。