IT入门知识第九部分《人工智能》(9/10)
正在走向自律 2024-07-27 11:01:01 阅读 62
1.引言
在当今数字化时代,人工智能(AI)和机器学习(ML)已成为推动技术革新的关键力量。它们不仅改变了我们与机器的互动方式,还极大地拓展了解决问题的可能性。本文将深入探讨人工智能和机器学习的基础,并分析它们在自然语言处理、计算机视觉和数据挖掘等应用领域的实际影响。

2.人工智能基础
2.1人工智能的定义
人工智能,简称AI,是计算机科学的一个分支,它致力于创建能够执行通常需要人类智能的任务的系统。这些任务包括语言理解、学习、推理、规划、感知、运动和操作。
人工智能(AI)是计算机科学的一个分支,它旨在创建能够执行通常需要人类智能的任务的系统。这些系统能够模仿人类的学习方式、决策过程和解决问题的能力。AI的范围非常广泛,从简单的问题解答到复杂的数据分析和预测建模。
关键特征
学习:AI系统能够从经验中学习,并随着时间的推移提高性能。推理:它们能够进行逻辑推理,解决复杂问题。自我修正:AI能够识别错误并进行自我修正以改进决策过程。感知:通过视觉、听觉和其他感官输入,AI可以解释和理解周围环境。语言理解:AI可以处理和理解自然语言,使机器能够与人类进行交流。
主要领域
机器学习:AI的一个核心领域,侧重于算法和统计模型,使计算机能够从数据中学习。自然语言处理:使计算机能够理解、解释和生成人类语言。计算机视觉:使计算机能够“看到”并理解图像和视频中的内容。机器人学:集成AI技术,使机器人能够执行复杂任务。
2.2人工智能的发展历程
人工智能的研究始于20世纪40年代和50年代,自那时以来,它经历了多次发展和衰退周期,被称为“AI春天”和“AI冬天”。近年来,随着计算能力的提升和数据量的增加,AI技术取得了显著进步。
人工智能的研究起源于20世纪中叶,其发展可以概括为以下几个阶段:
早期探索(1950s-1960s)
1950年,图灵提出了著名的“图灵测试”,作为判断机器是否具有智能的标准。1956年,在达特茅斯会议上,"人工智能"一词被首次提出,标志着AI作为一个研究领域的诞生。
第一次AI春天(1960s-1970s)
研究者们在问题求解、逻辑推理等方面取得了初步成功。出现了一些早期的AI程序,如通用问题求解器(GPS)和LISP语言。
第一次AI冬天(1970s-1980s)
由于计算能力的限制和对AI能力的过度乐观预期,AI研究遭遇了资金短缺和进展缓慢。
知识时代(1980s-1990s)
专家系统的出现,将人类专家的知识编码到计算机程序中,解决了特定领域的问题。
第二次AI春天(1990s-2000s)
机器学习算法,特别是支持向量机(SVM)和随机森林等,开始在复杂任务中取得成功。
深度学习和大数据时代(2010s-现在)
深度学习的出现和计算能力的飞跃推动了AI技术的快速发展。大数据的可用性为训练复杂的AI模型提供了丰富的资源。
3.机器学习基础
3.1机器学习的定义
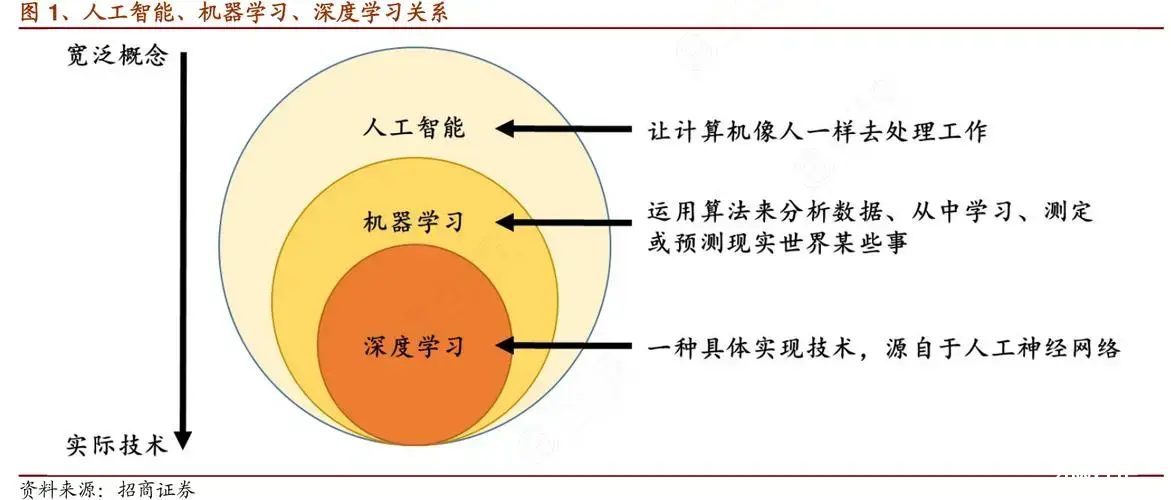
机器学习是AI的一个子集,它使计算机系统能够从数据中学习并改进,而无需进行明确的编程。机器学习算法通过分析大量数据来发现模式和关系,从而做出预测或决策。
机器学习是人工智能的一个核心子集,它侧重于开发算法和统计模型,使计算机系统能够从数据中学习并做出预测或决策。这种学习过程不需要对计算机进行明确的编程,而是让计算机通过数据本身获得知识和规则。
核心概念
数据驱动:机器学习模型依赖大量数据来提取信息。特征选择:识别数据中最重要的特征以供算法使用。模型训练:使用数据集来训练算法,使其能够识别模式。泛化能力:模型对新数据做出准确预测的能力。
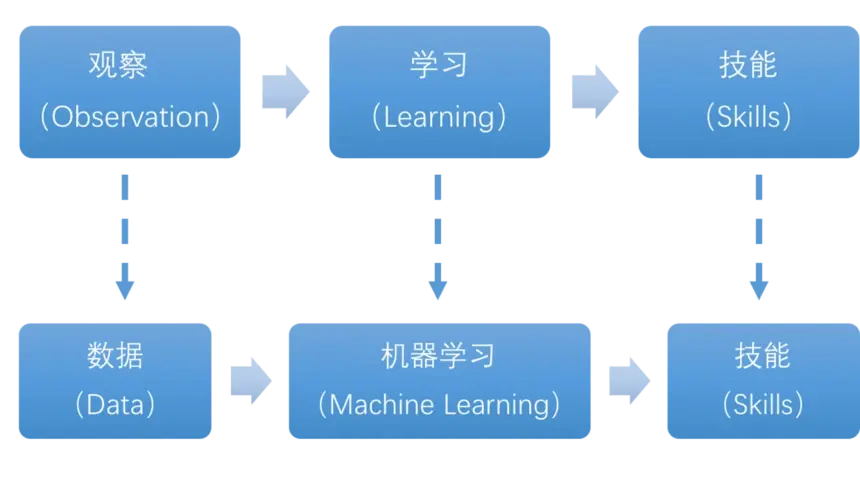
机器学习的过程
数据预处理:清洗、规范化和转换原始数据,使其适合模型训练。选择模型:根据问题的性质选择适当的机器学习算法。训练模型:使用训练数据集来训练选定的模型。评估模型:评估模型的性能,确保其准确性和泛化能力。参数调优:优化模型参数以提高预测精度。模型部署:将训练好的模型应用于实际问题或生产环境。
3.2机器学习的主要类型
监督学习(Supervised Learning)
定义:监督学习算法从带有标签的训练数据中学习,以便对新的、未见过的数据进行分类或预测。应用:图像识别、语音识别、医疗诊断等。常见算法:线性回归、逻辑回归、支持向量机(SVM)、决策树、神经网络等。
无监督学习(Unsupervised Learning)
定义:无监督学习算法处理没有标签的数据,试图发现数据中的结构和模式。应用:市场细分、社交网络分析、异常检测等。常见算法:聚类分析(如K-means、层次聚类)、主成分分析(PCA)、自编码器等。
半监督学习(Semi-supervised Learning)
定义:半监督学习结合了监督学习和无监督学习的特点,使用少量标记数据和大量未标记数据进行训练。应用:当获取大量标记数据成本较高或不可行时,如文本分类、图像识别等。方法:自训练模型、伪标签方法等。
强化学习(Reinforcement Learning)
定义:强化学习算法通过与环境的交互来学习,目标是最大化某种累积奖励。应用:游戏玩家、机器人导航、资源管理等。核心概念:智能体、环境、状态、动作、奖励等。常见算法:Q学习、SARSA、深度Q网络(DQN)、策略梯度方法等。
4.应用领域
4.1 自然语言处理(NLP)
自然语言处理是AI中的一个领域,它涉及到使计算机能够理解、解释和生成人类语言。NLP的应用包括:
机器翻译:自动将一种语言翻译成另一种语言。情感分析:识别文本中的情感倾向,如积极、消极或中性。语音识别:将语音转换为文本,广泛应用于智能助手和自动字幕生成。聊天机器人:通过自然语言与用户进行交互的程序。
4.2 计算机视觉
计算机视觉是使机器能够“看”和理解视觉世界的AI领域。它涉及到图像识别、物体检测和场景重建等任务,广泛应用于:
自动驾驶汽车:使用视觉系统来识别道路、交通信号和其他车辆。医疗成像:分析X射线、MRI和其他图像,以辅助诊断。安全监控:监控摄像头的视频流,以检测异常行为或事件。
4.3 数据挖掘
数据挖掘是从大量数据中通过算法搜索模式的过程。它结合了AI、机器学习和统计学的技术,用于:
市场分析:分析消费者行为,预测市场趋势。风险管理:识别潜在的风险和欺诈行为。个性化推荐:根据用户的历史行为推荐产品或服务。
5.深度学习与AI的未来
深度学习是机器学习的一个子领域,它使用类似于人脑的神经网络结构来学习复杂的模式。深度学习在图像和语音识别、游戏和机器人等领域取得了突破性进展。
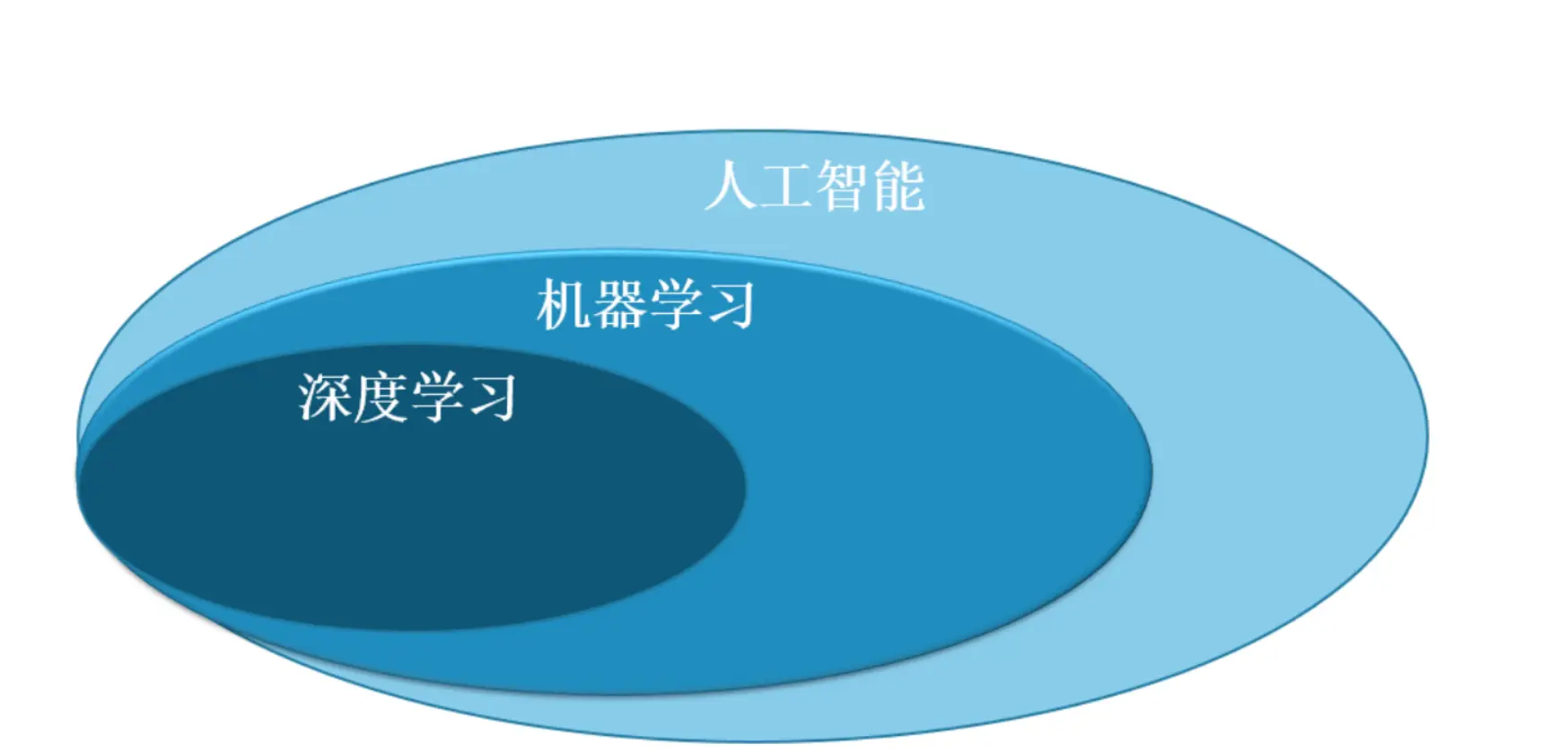
5.1深度学习的概念
神经网络
深度学习的核心是人工神经网络(ANN),一种受人脑结构启发的数学模型。这些网络由多层节点(或称为神经元)组成,每层之间通过加权连接相互传递信息。
深度
“深度”一词指的是神经网络的层数。深层网络能够学习更复杂的数据表示,每一层都可能捕捉到数据的不同特征。
激活函数
激活函数决定了神经网络节点的输出方式,常见的激活函数包括ReLU、sigmoid和tanh等。
损失函数
损失函数衡量模型预测与实际结果之间的差异,常见的损失函数有均方误差和交叉熵等。
优化算法
优化算法用于调整网络的权重和偏置,以最小化损失函数。常用的优化算法包括梯度下降、Adam和RMSprop等。
5.2深度学习的发展历程
早期研究
深度学习的起源可以追溯到20世纪40-50年代,但早期的研究受到计算能力的限制。
突破性进展
2006年,Geoffrey Hinton和其他研究者提出了深度信念网络(DBN),标志着深度学习的重大突破。
大规模应用
随着计算资源的增加和大数据的可用性,深度学习开始在多个领域取得成功。
当前趋势
深度学习正不断进步,包括新的网络架构、优化算法和学习理论的发展。
5.3挑战与机遇
尽管AI和ML为社会带来了巨大的潜力,但它们也带来了挑战,包括隐私问题、就业影响和伦理问题。为了确保AI的积极发展,需要制定相应的政策、法规和伦理准则。

6.代码案例
在人工智能、机器学习和深度学习领域,代码案例通常涉及不同的库和框架,如Python的<code>scikit-learn、TensorFlow、Keras和PyTorch。以下是一些基础的代码示例,展示如何使用这些技术解决不同类型的问题。
1. 机器学习 - 线性回归(使用scikit-learn)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
# 示例数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 2, 3, 4, 5])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
predictions = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error: {mse}")
2. 深度学习 - 简单神经网络(使用TensorFlow和Keras)
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 创建顺序模型
model = Sequential([
Dense(10, activation='relu', input_shape=(8,)), # 输入层code>
Dense(10, activation='relu'), # 隐藏层code>
Dense(1) # 输出层
])
# 编译模型
model.compile(optimizer='adam', loss='mse')code>
# 假设有以下特征和目标数据
import numpy as np
X = np.random.random((1000, 8))
y = np.random.random((1000, 1))
# 训练模型
model.fit(X, y, epochs=10)
# 预测
predictions = model.predict(X[:10])
print(predictions)
3. 自然语言处理 - 文本分类(使用TensorFlow和Keras)
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, GlobalAveragePooling1D, Dense
# 示例文本数据和标签
texts = ["I love AI", "Machine learning is fun", "Deep learning is great"]
labels = [1, 1, 0] # 假设1是正面,0是负面
# 文本预处理
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences, maxlen=5)
# 创建模型
model = Sequential([
Embedding(100, 16, input_length=5),
GlobalAveragePooling1D(),
Dense(24, activation='relu'),code>
Dense(1, activation='sigmoid')code>
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])code>
# 训练模型
model.fit(padded_sequences, labels, epochs=10)
# 预测
predictions = model.predict(padded_sequences)
print(predictions)
4. 计算机视觉 - 图像分类(使用TensorFlow和Keras)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 创建卷积神经网络模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),code>
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),code>
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),code>
Flatten(),
Dense(512, activation='relu'),code>
Dense(10, activation='softmax') # 假设有10个类别code>
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])code>
# 假设有训练数据和标签
# X_train, y_train = ...
# 训练模型
# model.fit(X_train, y_train, epochs=10, batch_size=32)
# 注意:实际使用中,你需要提供实际的图像数据和标签来训练模型。
请注意,这些示例仅用于展示基本概念,实际应用中需要更复杂的数据预处理、模型调优和评估步骤。此外,深度学习模型通常需要GPU加速来处理大量的计算任务。
6.结论
人工智能和机器学习正在快速发展,它们有潜力解决一些最紧迫的全球问题,从医疗保健到环境保护。随着技术的不断进步,我们有责任确保AI的发展是负责任的、可持续的,并为所有人带来利益。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。