GPU介绍和入门知识整理
跑步去兜风 2024-09-14 13:31:01 阅读 95
以下是作者看了N多篇文章总结合成的文档,希望能帮助小白们入坑GPU!!!!!
接下来会不断更新AI相关的GPGPU设计
关注博主不迷路
CPU介绍
CPU(Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
CPU与内部存储器(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。CPU主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。简单来说就是:计算单元、控制单元和存储单元。CPU遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。
因为CPU的架构中需要大量的空间去放置存储单元和控制单元,相比之下计算单元只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
GPU介绍
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。显卡是电脑进行数模信号转换的设备,承担输出显示图形的任务。具体来说,显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来,同时显卡还是有图像处理能力,可协助CPU工作,提高整体的运行速度。在科学计算中,显卡被称为显示加速卡。
随着显卡的迅速发展,GPU这个概念由NVIDIA公司于1999年提出。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。集成显卡和独立显卡都是有GPU的。
GPU和显卡有什么关系?
GPU是显卡上的核心处理芯片,显卡上除了GPU,还包括显存、电路板和BIOS固件等。由于GPU在显卡上十分重要,所以时常用GPU代指显卡。
显卡也叫显示适配器,分为独立显卡和集成显卡。独立显卡由GPU、显存和接口电路组成;集成显卡和CPU共用风扇和缓存,没有独立显存,而是使用主板上的内存。

GPU作用:
GPU(Graphics Processing Unit):一种可进行绘图运算工作的专用微处理器。GPU 能够生成 2D/3D 的图形图像和视频,从而能够支持基于窗口的操作系统、图形用户界面、视频游戏、可视化图像应用和视频播放。GPU 具有非常强的并行计算能力。
那么像素是如何绘制在屏幕上的?计算机将存储在内存中的形状转换成实际绘制在屏幕上的对应的过程称为 渲染。渲染过程中最常用的技术就是光栅化。
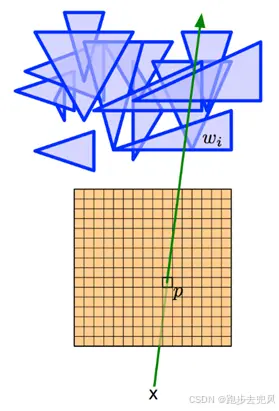
关于光栅化的概念,以下图为例,假如有一道绿光与存储在内存中的一堆三角形中的某一个在三维空间坐标中存在相交的关系。那么这些处于相交位置的像素都会被绘制到屏幕上。当然这些三角形在三维空间中的前后关系也会以遮挡或部分遮挡的形式在屏幕上呈现出来。一句话总结:光栅化就是将数据转化成可见像素的过程。GPU 则是执行转换过程的硬件部件。由于这个过程涉及到屏幕上的每一个像素,所以 GPU 被设计成了一个高度并行化的硬件部件。
GPU 历史
GPU 还未出现前,PC 上的图形操作是由 视频图形阵列(VGA,Video Graphics Array) 控制器完成。VGA 控制器由连接到一定容量的DRAM上的存储控制器和显示产生器构成。1997 年,VGA 控制器开始具备一些 3D 加速功能,包括用于 三角形生成、光栅化、纹理贴图 和 阴影。2000 年,一个单片处图形处理器继承了传统高端工作站图形流水线的几乎每一个细节。因此诞生了一个新的术语 GPU 用来表示图形设备已经变成了一个处理器。
随着时间的推移,GPU 的可编程能力愈发强大,其作为可编程处理器取代了固定功能的专用逻辑,同时保持了基本的 3D 图形流水线组织。
近年来,GPU 增加了处理器指令和存储器硬件,以支持通用编程语言,并创立了一种编程环境,从而允许使用熟悉的语言(包括 C/C++)对 GPU 进行编程。
如今,GPU 及其相关驱动实现了图形处理中的 OpenGL 和 DirectX 模型,从而允许开发者能够轻易地操作硬件。OpenGL 严格来说并不是常规意义上的 API,而是一个第三方标准(由 khronos 组织制定并维护),其严格定义了每个函数该如何执行,以及它们的输出值。至于每个函数内部具体是如何实现的,则由 OpenGL 库的开发者自行决定。实际 OpenGL 库的开发者通常是显卡的生产商。DirectX 则是由 Microsoft 提供一套第三方标准。
图形API和着色语言
什么是OpenGL/DirectX?
图像编程接口(图形API),是对GPU硬件的抽象,其地位类似C语言,属于GPU编程的中低层。几乎所有GPU都既可以和OpenGL合作也可以和DirectX合作。
什么是API?
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
OpenGL和DirectX的区别?
OpenGL是纯粹的图形API;DirectX是多种API的集合体,其中DirectX包含图形API——Direct3D和Direct2D。
DirectX支持Windows和Xbox;OpenGL支持Windows、MacOC、Linux等更多平台,在Android、IOS上允许使用OpenGL的简化版本OpenGL ES。
OpenGL相对来说易上手门槛低;DirectX难上手门槛高。OpenGL渲染效率相对低,特性少DirectX相对效率高,特性多。如DirectX12提供了底层API,允许用户一定程度上绕过显卡驱动之间操纵底层硬件。
二者在图形学领域一样重要。OpenGL在各种领域都吃香,包括许多专业领域如特效和CG建模软件。DirectX在游戏中更通用。
GPU 图形渲染流水线:
GPU 图形渲染流水线的主要工作可以被划分为两个部分:
把 3D 坐标转换为 2D 坐标把 2D 坐标转变为实际的有颜色的像素
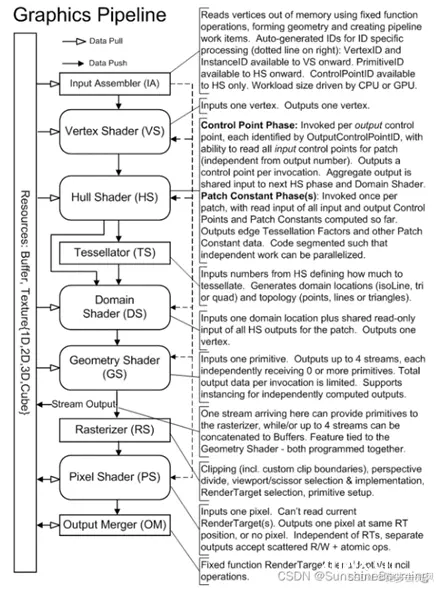
GPU 图形渲染流水线的具体实现可分为六个阶段,如下图所示。
顶点着色器(Vertex Shader)
形状装配(Shape Assembly),又称 图元装配
几何着色器(Geometry Shader)
光栅化(Rasterization)
片段着色器(Fragment Shader)
测试与混合(Tests and Blending)
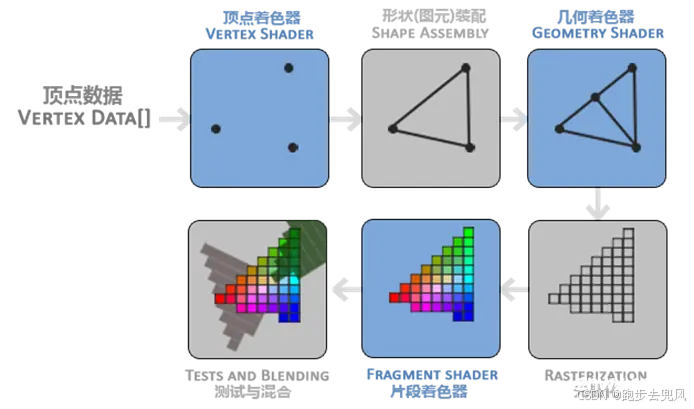
顶点着色器。该阶段的输入是 顶点数据(Vertex Data) 数据,比如以数组的形式传递 3 个 3D 坐标用来表示一个三角形。顶点数据是一系列顶点的集合。顶点着色器主要的目的是把 3D 坐标转为另一种 3D 坐标,同时顶点着色器可以对顶点属性进行一些基本处理。形状(图元)装配。该阶段将顶点着色器输出的所有顶点作为输入,并将所有的点装配成指定图元的形状。图中则是一个三角形。图元(Primitive) 用于表示如何渲染顶点数据,如:点、线、三角形。几何着色器。该阶段把图元形式的一系列顶点的集合作为输入,它可以通过产生新顶点构造出新的(或是其它的)图元来生成其他形状。例子中,它生成了另一个三角形。光栅化。该阶段会把图元映射为最终屏幕上相应的像素,生成片段。片段(Fragment) 是渲染一个像素所需要的所有数据。片段着色器。该阶段首先会对输入的片段进行 裁切(Clipping)。裁切会丢弃超出视图以外的所有像素,用来提升执行效率。测试与混合。该阶段会检测片段的对应的深度值(z 坐标),判断这个像素位于其它物体的前面还是后面,决定是否应该丢弃。此外,该阶段还会检查 alpha 值( alpha 值定义了一个物体的透明度),从而对物体进行混合。因此,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
关于混合,GPU 采用如下公式进行计算,并得出最后的颜色。
R = S + D * (1 - Sa)
关于公式的含义,假设有两个像素 S(source) 和 D(destination),S 在 z 轴方向相对靠前(在上面),D 在 z 轴方向相对靠后(在下面),那么最终的颜色值就是 S(上面像素) 的颜色 + D(下面像素) 的颜色 * (1 - S(上面像素) 颜色的透明度)。
上述流水线以绘制一个三角形为进行介绍,可以为每个顶点添加颜色来增加图形的细节,从而创建图像。但是,如果让图形看上去更加真实,需要足够多的顶点和颜色,相应也会产生更大的开销。为了提高生产效率和执行效率,开发者经常会使用 纹理(Texture) 来表现细节。纹理是一个 2D 图片(甚至也有 1D 和 3D 的纹理)。纹理一般可以直接作为图形渲染流水线的第五阶段的输入。
最后,我们还需要知道上述阶段中的着色器事实上是一些程序,它们运行在 GPU 中成千上万的小处理器核中。这些着色器允许开发者进行配置,从而可以高效地控制图形渲染流水线中的特定部分。由于它们运行在 GPU 中,因此可以降低 CPU 的负荷。着色器可以使用多种语言编写,OpenGL 提供了 GLSL(OpenGL Shading Language) 着色器语言。
上面是比较好理解的一种过程,下面还有一种比较官方的介绍过程:
Graphic Pipeline
1.1 什么是Pipeline?
DirectX12中的Pipeline主要分为2类,Graphic Pipeline和Compute Pipeline
其中Graphic Pipeline的定义如下:A graphics pipeline is the sequential flow of data inputs and outputs as the GPU renders frames。展开来说,就是DirectX12会将渲染画面的整个流程,划分成若干个Stage,每个Stage负责固定的功能,那么一整个流程就概括起来就是一条Pipeline(流水线)。
开始GPU只专门用来渲染图形,后来又发展出了专用的计算GPU,DirectX12定义了另一套Pipeline就是Compute Pipeline,这条Pipeline只包含运算模块CS(Compute Shader)。
下面是微软官网给出的Graphic pipeline的详细流程图,比起上述的更加详细。
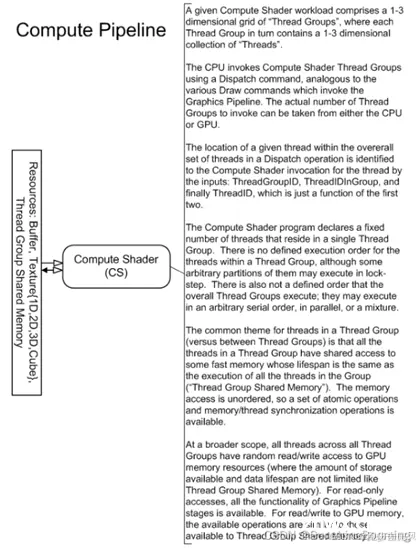
以上是GPU在渲染的逻辑过程的一个介绍,接下来是针对GPU内部硬件架构进行一个介绍:
GPU内部硬件架构介绍
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。显卡是电脑进行数模信号转换的设备,承担输出显示图形的任务。具体来说,显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来,同时显卡还是有图像处理能力,可协助CPU工作,提高整体的运行速度。在科学计算中,显卡被称为显示加速卡。
原始的显卡一般都是集成在主板上,只完成最基本的信号输出工作,并不用来处理数据。显卡也分为独立显卡和集成显卡。一般而言,同期推出的独立显卡的性能和速度要比集成显卡好、快。

CPU与GPU
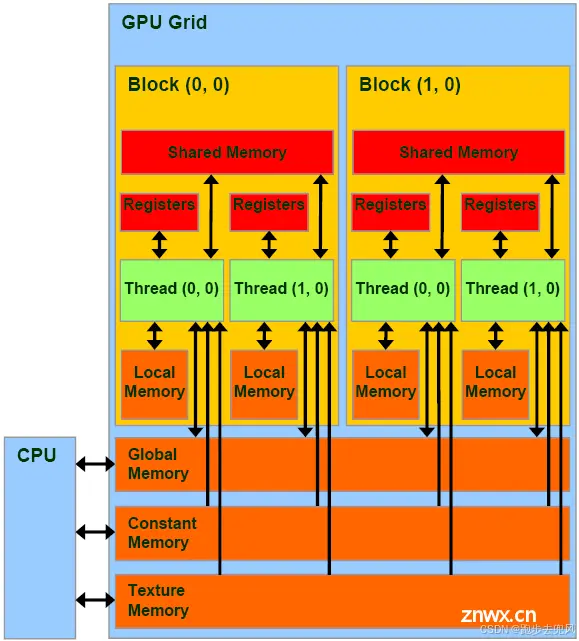
在没有GPU之前,基本上所有的任务都是交给CPU来做的。有GPU之后,二者就进行了分工,CPU负责逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务(大规模计算任务)。GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。

GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。GPU无论发展得多快,都只能是替CPU分担工作,而不是取代CPU。
从硬件角度细分GPU中的内部架构:
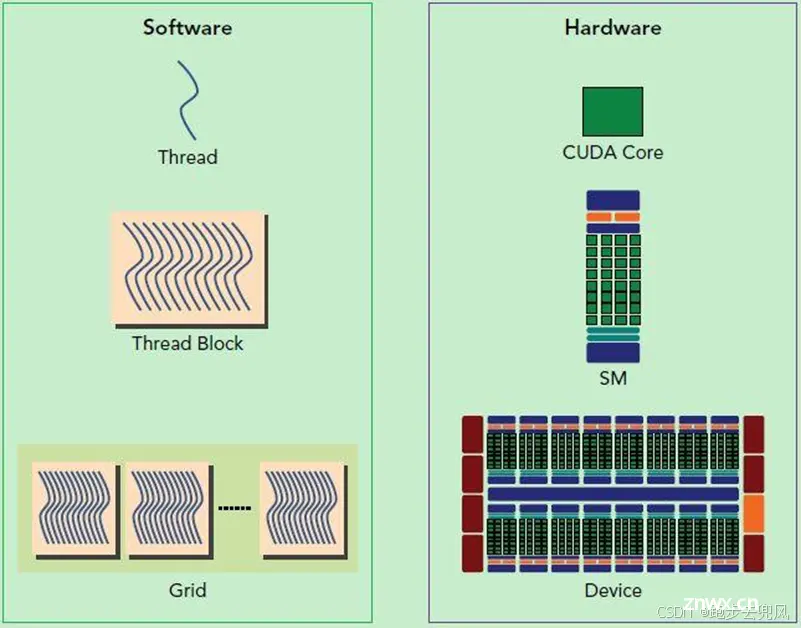
SP (Streaming Processor)是GPU中的最小计算单元core可以称为CUDA core,多个SP构成 SM (Streaming MultiProcessor) ,然后多个SM构成 GPC(Graphic Processing Cluster)。
流处理器(Streaming Processor ,SP)
SP 是GPU最基本的处理单元,也称为CUDA core。每个SM中包含几十或者上百个CUDA核心,依据GPU架构而不同。我们所说的几百核心GPU中这个几百指的就是SP的数量(图三中深蓝色的框)。SP只运行一个线程,每个SP都有自己的寄存器集(图二中浅灰色的框,同时也就是2.2.3中的Register File)。
GPU的CUDA core只相当于CPU处理器中的执行单元,负责执行指令进行运算,并不包含控制单元(2.2.2中的Warp Scheduler相当于控制单元)。
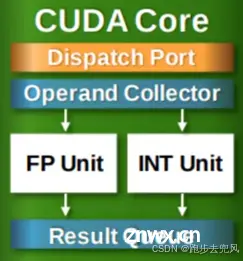
SP 内部包括承接控制单元指令的Dispatch Port、Operand Collector,以及浮点计算单元FP Unit、整数计算单元Int Unit,另外还包括计算结果队列。当然还有Compare、Logic、Branch等。相当于微型CPU。
具体的指令和任务都是在SP上处理的。GPU之所以可以进行并行计算,也就是在GPU的体系结构中可以实现很多个SP同时做处理。这个并行计算是通过单指令多线程 (Single Instruction Multiple Threads,SIMT)实现的。现在SP的术语已经有点弱化了,而是直接使用thread来代替。一个SP对应一个thread。
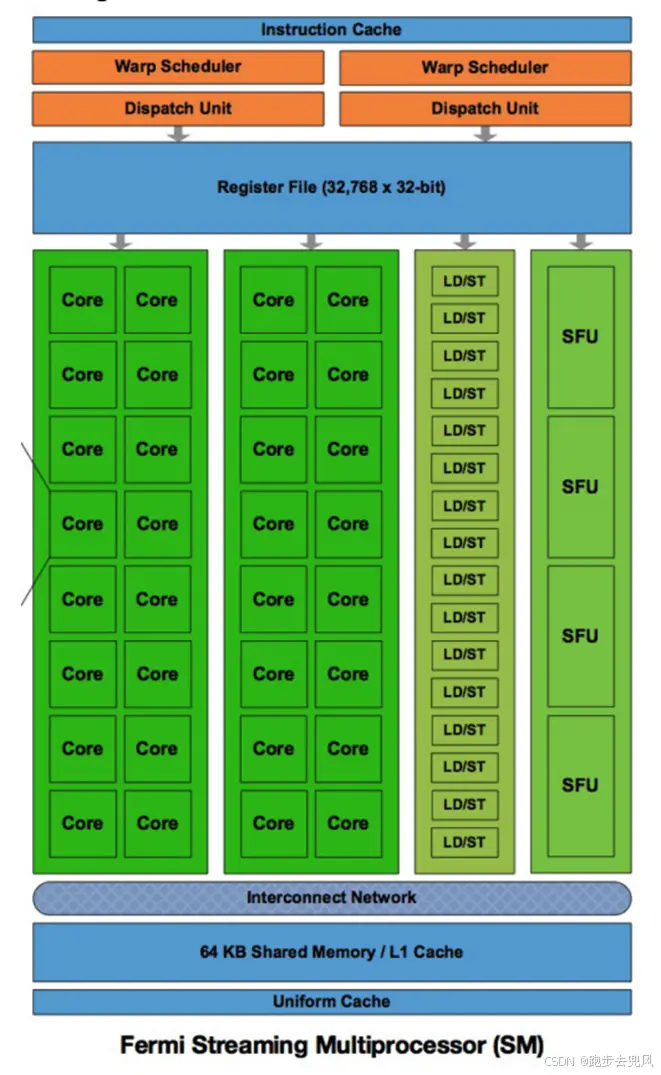
SM(Streaming MultiProcessor):
一个SM由多个CUDA core组成,每个SM根据GPU架构不同有不同数量的CUDA core,Pascal架构中一个SM有128个CUDA core。
一个SM通常拥有一块专用于缓存Shader指令的L1 Cache,若干线程资源调度器,一个寄存器池,一块可被Compute Pipeline访问的共享内存(Shared Memory),一块专用于贴图缓存的L1 Cache,若干浮点数运算核心(Core),若干超越函数的计算单元(SFU),若干读写单元(Load/Store)。
SM的构成:
流处理器SP(Streaming Processor),
特殊运算单元(SFU),
共享内存(shared memory),
寄存器文件(Register File)
调度器(Warp Scheduler)等。
register和shared memory是稀缺资源,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。

SM中的任务主要由SP承担,SM中SP的数量一般为32个,有时也有16或64个SP组成的SM。进行辅助计算的还有SFU(Special Function Units,特殊数学运算单元),它们用于进行三角函数和指对数等运算。
SM由Warp Scheduler(束管理器)驱动,束管理器会将指令移交给Dispatch Unit(指令分派单元),由于SM中每束处理的事务具有相似性,这个单元会从指令缓存新的读取指令,并一次性向整束的所有流处理器发送同一个指令。这种通过一条指令驱动若干线程的特性被称为SIMT(Single Instruction Multiple Thread,单指令多线程),在这个框架下,指令分派单元可以读取一条指令,然后向多个SP分派不同的参数,以让它们在不同的寄存器地址进行读写。
SM中一般配有一个多边形引擎(Polymorph Engine)。这个引擎的作用是实现属性装配、顶点拉取、曲面细分、裁剪和光栅化等渲染流水线中的固定步骤。
每个SM中具有一个足够大的寄存器,一般能达到128KB。所有SP共用这个寄存器中的空间,所以如果单个线程需要的寄存器空间过大,可能使每束的最多线程数减少,影响并行性。
L1缓存是开始时用于储存顶点数据的缓存,在顶点处理阶段结束后,SM会将处理结果送到SM外的L2缓存中。多边形将在SM外进行光栅化,然后将生成的片元重新分发到SM中,这时L1缓存中储存的就是片元数据了。
一个显卡上可能有10~20个SM,一般显卡厂商将若干SM的组合称为一个GPC(Graphic Processor Cluster,图形处理簇),每个簇可以处理一批(batch)顶点或片元。在有GPC结构的显卡上,L2缓存一般位于GPC中,而对于没有GPC结构的显卡,L2一般位于显存旁或显存中。
从软件执行角度上划分GPU的任务:
GPU执行程序的最小单元为thread。
thread: 一个CUDA的并行程序会被以许多个thread来执行。block: 数个thread会被群组成一个block,同一个block中的thread可以同步,也可以通过 shared memory进行通信。grid: 多个block则会再构成grid。warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
从软件上看,SM更像一个独立的CPU core。SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。
GPU中每个sm都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行。当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,同一个block中的threads必然在同一个SM中并行(SIMT)执行。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread。
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident thread最多只有 SM*warp个。
Warp
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
一个CUDA core可以执行一个thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由warp scheduler负责调度。尽管warp中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为GPU规定warp中所有线程在同一周期执行相同的指令,warp发散会导致性能下降。一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。
每个block的warp数量可以由下面的公式计算获得:
WarpRerBlock =ceil( ThreadsPerBlock/ WarpsSize)
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。由于warp的大小一般为32,所以block所含的thread的大小一般要设置为32的倍数。
显卡的储存结构:
寄存器、共享内存、L1缓存、L2缓存、纹理缓存、常量缓存、全局内存(显存)

显卡中的物理储存器按存取速度的大小从快到慢依次有:寄存器、共享内存、L1缓存、L2缓存、纹理缓存、常量缓存、全局内存(显存)。
寄存器位于SM中,访问速度是1个时间周期,SP运行时可以随意的读和写寄存器。在指令分派单元的控制下,每个线程都会获得自己的寄存器空间,
共享内存和L1缓存都位于SM中,它们都可以被SM中的所有SP共用。L1缓存重点存放顶点和片元数据,而共享内存重点存放材质参数、光照、摄像机等常量数据。共享内存和L1缓存的访问速度都低于32个时间周期。
L1缓存和L2缓存重点用于顶点和片元数据的交换。L2缓存位于SM之外,它的访问速度相对L1较慢,大致需要32至64个时间周期,但由于大量SM会共用一个L2缓存,L2缓存的吞吐量是数个L1缓存的总和。在有些显卡设计中,L2缓存还可以作为纹理缓存和常量缓存的新一层缓存,供其它显卡硬件使用。
纹理缓存和常量缓存是显卡上重要的缓存类型,它们都是显存的直接缓存,访问延迟在400个时间周期以上,如果出现未命中,要等待访问显存的话,这个延迟甚至很可能超过1000个时间周期。
全局内存也就是显存,它的数据直接来自CPU总线。显卡驱动会在GPU流水线空闲时将任务数据从GPU缓冲区导入显存。显存的访问延迟在500个时间周期以上,显卡的访问一般在纹理缓存和常量缓存缺失时才会发生。但存在一种高吞吐GPU结构,使用更大量的GPU而减少了缓存的层数,这种结构中显存可能直接被共享内存访问,通过高吞吐量与高带宽来缓解缓存层级少带来的性能缺陷。
什么是显卡驱动?
一个应用程序向显卡接口发送渲染命令,这些接口会依次向显卡驱动发送渲染命令。显卡驱动的地位类似于C语言编译器,可以将OpenGL或DirectX的函数调用翻译成GPU能读取的机器指令,即二进制文件。显卡驱动同时也负责把纹理等数据转换成GPU支持的格式。
工作流程:
1. 程序在图形API中创建一个drawcall。之后经过一些验证后到达驱动,然后用GPU可读的编码格式将指令插入到Pushbuffer(推送缓存)。这个阶段会产生许多跟CPU侧相关的瓶颈,这就是为什么程序员用好API以及所用技术能充分利用上现代GPU的性能十分重要。
2. 经过一段时间或者直接的“刷新”调用后驱动上已经缓存了足够多的工作到Pushbuffer并将它发送给GPU进行处理(以及一些操作系统的参与)。GPU的主接口(Host Interface)获取到经过前端(Front End)处理的指令。
3. 之后我们开始在基元分配器(Primitive Distributor)中开始分配的工作。在这里会对索引缓冲中的序列进行处理,并且批量生成之后我们会将其发送给多个GPC上的三角形。
4. 在GPC中,SM中的多边形变形引擎(Poly Morph Engine)负责根据三角形序列获取顶点数据(Vertex Fetch)。
5. 获取到数据后,SM内部就会调度32线程的warp然后开始进行顶点处理工作。
6. SM的warp调度器会根据顺序为整个warp分发指令。每个线程锁步(lock -step)地运算每个指令,如果线程不应该主动执行,则可以单独屏蔽掉。需要这种屏蔽的原因有许多。比如如果当前的指令是一个if-true分支的一部分并且具体运算结果是false,或者当一个循环条件的终止条件在一个线程时刚好满足而不是另外一个线程中时。所以一个有许多分支结构的shader会显著地增加在warp中所有线程上所消耗的时间。线程不能单独推进到下一步,只有作为整个warp的时候才行,虽然warp也是互相独立的。
7. warp指令可能会一次性完成,也可能会耗费几个发送回合。SM通常比进行基本数学运算具有更少的加载/存储单位。
8. 由于一些指令处理会比其他的消耗跟多的时间,特别是内存加载,因此warp调度程序可能只是切换到另一个不等待内存的warp。这就是GPU克服内存延迟的关键概念,GPU只是简单地切换活动的线程组。为了保证切换足够快速,所有被调度器管理的线程都在寄存器堆(register-file)中有自己的寄存器。shader程序所需要的寄存器越多,线程/warp所有用的空间就越少。而我们可以用于切换的warp越少,我们在等待指令完成(最重要的是内存获取)的过程中所能做的工作就越少。(因为正在获取内存的warp不会用来做其他工作,所以只能跳转到空闲的warp上)
‘
图形学基础概念梳理
计算机图形学重点概念介绍如下。
1.像素(Pixel):数字成像中的像素是全点可寻址显示设备中最小的可寻址元素。像素通常被认为是数字图像中最小的单个分量,通常用作测量单位。
2.矢量(Vector):图形是一种使用多边形的技术,平面图形由有限的直线段链封闭一个循环,来表示图像。矢量图形具有固有的放大能力,仅取决于渲染设备的能力。
3.光栅/栅格(Raster):即图像(或位图图像),用于表示实际图像内容的矩阵数据结构。光栅图形受分辨率限制,无法在没有明显质量损失的情况下放大。
4.光栅化/栅格化(Rasterization):将矢量图形格式的图像转换为由像素组成的光栅图像,以便在视频显示器上输出或以位图格式存储的过程。
5.纹理(Texture):物体表面的数字化表达方式。除了颜色和透明度等二维特性外,纹理还包含反射性等三维特性。定义良好的纹理对于逼真的三维图像表示非常重要。
6.纹理映射(Texture Mapping):在任何二维或三维对象周围包裹预定义纹理的过程。通过这个过程,数字图像和对象可获得高水平的细节。
7.纹理元(Texel):纹理空间的基本单位。纹理由纹素数组表示,就像图片由像素数组表示一样。
8.顶点(Vertex):一种数据结构,通过将对象的角正确定义为二维或三维空间中点的位置来描述对象的位置。
9.几何原语(Primitives):在计算机图形学中是系统可以处理的最简单的几何对象。常见的二维基元集包括线、点、三角形和多边形,而所有其他几何元素都是从这些基元构建的。在三维中,正确定位的三角形或多边形可以用作基元来模拟更复杂的形式。
10.混合(Blending):将两个或多个图像按像素和权重组合以创建新图片的过程。
11.片段(Fragment):生成单像素图元所必需的数据。该数据可能包括光栅位置、颜色或纹理坐标。
12.插值(Interpolation):在计算机图形学中,是在两个已知参考点之间生成中间值以给出连续性和平滑过渡的外观的过程。计算机图形和动画中使用了几种不同的插值技术,例如线性、双线性、样条和多项式插值。
13.图形管道(Graphics Pipeline):一个抽象序列,结合了通用光栅化实现的基本操作了解图形学基础概念, 有助于了解GPU的工作机理. 当然, 不理解也没太大关系, 因为后面, 你会发现 GPU 功能的使用,是套路化的。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。