Dify 零代码 AI 应用开发:快速入门与实战
技术狂潮AI 2024-08-28 13:31:01 阅读 68
一、Dify 介绍
Dify 是一个开源的大语言模型 (LLM) 应用开发平台。它结合了后端即服务 (Backend-as-a-Service) 和 LLMOps (LLMOps) 的概念,使开发人员能够快速构建生产级生成式 AI (Generative AI) 应用。即使是非技术人员也可以参与 AI 应用的定义和数据操作。
通过集成构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的提示词编排界面、高质量的检索增强生成 (RAG) 引擎以及灵活的 Agent (Agent) 框架,同时提供了一组易于使用的界面和 API,Dify 为开发人员节省了大量时间避免重复造轮子,让他们可以专注于创新和业务需求。
Dify 由 Define 和 Modify 两个词组合而成,寓意着用户可以定义并不断改进自己的 AI 应用。
1.1、为什么使用 Dify?
你可以将 LangChain (LangChain) 之类的库想象成带有锤子、钉子等的工具库。相比之下,Dify 提供了一个更加接近生产环境、开箱即用的完整解决方案 —— 例如,可以将 Dify 想象成一个经过精心工程设计和软件测试的脚手架系统,可以帮助开发者快速搭建 AI 应用。
重要的是,Dify 是开源的,由专业的全职团队和社区共同创建。您可以基于任何模型自主部署类似于 Assistants API 和 GPT 的功能,通过灵活的安全措施保持对数据的完全控制,所有这些都在一个易于使用的界面上完成。
1.2、Dify 能做什么?
工作流:Dify 提供了一个可视化的画布来构建和测试强大的 AI 工作流。此功能使用户能够利用 Dify 的全部功能,包括模型集成和提示词设计。全面的模型支持:该平台支持与数百个专有和开源 LLM 无缝集成,包括 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型等热门选项。这种广泛支持的模型确保了开发人员的灵活性和选择性。提示词 IDE:Dify 包括一个直观的提示词 IDE,允许用户制作提示词、比较模型性能,并使用文本转语音等附加功能增强应用。RAG 管道:Dify 的检索增强生成 (RAG) 功能涵盖了从文档提取到检索的所有内容。它包括对从各种文档格式(如 PDF 和 PPT)中提取文本的开箱即用支持。AI 智能体功能:用户可以使用 LLM 函数调用或 ReAct (ReAct) 定义 AI 智能体,并集成预构建或自定义工具。Dify 为 AI 智能体提供了 50 多种内置工具,包括 Google 搜索、DALL·E (DALL·E)、Stable Diffusion (Stable Diffusion) 和 WolframAlpha (WolframAlpha)。LLMOps:该平台包括可观察性功能,用于监控和分析应用程序日志和性能随时间的变化。这允许根据真实数据和注释不断改进提示词、数据集和模型。后端即服务:Dify 为其所有功能提供相应的 API,可轻松集成到现有业务逻辑中。云服务:Dify 提供零设置的云服务,包括自托管版本的所有功能。沙盒计划提供 200 次免费的 GPT-4 调用以供试验。自托管:Dify 的社区版本可以在任何环境中快速设置,并提供详细的文档以进行更深入的定制。企业解决方案:Dify 提供以企业为中心的功能,例如单点登录 (SSO) 和访问控制。它还在 AWS Marketplace (AWS 市场) 上提供 Dify Premium 选项,其中包括应用程序的自定义品牌和徽标。
二、Dify 使用方式
2.1、云服务:在线体验
Dify 为每个人提供云服务,因此您无需自行部署即可使用 Dify 的全部功能。
从免费计划开始,其中包括 200 次 OpenAI 调用的免费试用。要使用云版本的免费计划,您需要一个 GitHub 或 Google 帐户和一个 OpenAI API 密钥。以下是开始使用的方法:
注册 Dify Cloud 并创建一个新的 Workspace 或加入现有的 Workspace。配置您的模型提供者或使用托管模型提供者。您现在就可以创建一个应用程序了!
只有两种登录选项:GitHub 和 Google。您可以选择任意一种登录。
登录后,您将看到 Studio 界面。您可以跳过下一部分,直接进入“模型 (Models)” 章节。
2.2、部署社区版本:本地运行
如果想在本地运行 Dify,您可以选择部署 Dify 社区版本,它是开源版本。您可以通过 Docker Compose (Docker Compose) 或本地源代码进行部署。本文将演示使用 Docker Compose 在 Windows 上本地部署 Dify 的更便捷方法。
首先,安装并运行 Docker Desktop 并启用 WSL 2 (Windows Subsystem for Linux 2)。您可以从以下链接下载它;详细的安装过程不在本文中介绍:
<code>https://www.docker.com/products/docker-desktop/
在要存储 Dify 的目录中打开命令提示符,然后输入:
git clone https://github.com/langgenius/dify.git
您将看到以下输出:
D:\Workspace\Dify>git clone https://github.com/langgenius/dify.git
Cloning into 'dify'...
remote: Enumerating objects: 66122, done.
remote: Counting objects: 100% (10553/10553), done.
remote: Compressing objects: 100% (1540/1540), done.
remote: Total 66122 (delta 9611), reused 9196 (delta 9008), pack-reused 55569
Receiving objects: 100% (66122/66122), 38.65 MiB | 11.63 MiB/s, done.
Resolving deltas: 100% (47189/47189), done.
Updating files: 100% (5109/5109), done.
如果尚未安装 Git,则可以从 Dify 的 GitHub 仓库下载整个项目并将其解压缩,然后再继续执行以下步骤。但是,此方法对于以后的更新不太方便。
导航到 Dify 源代码的 docker 目录并执行一键启动的命令:
# 导航到 docker 目录
cd dify/docker
# 复制并重命名配置文件
cp .env.example .env
# 如果您使用的是 Windows cmd,请使用 copy 命令而不是 cp
copy .env.example .env
# 启动 docker compose
docker compose up -d
部署输出:
D:\Workspace\Dify\dify\docker>docker compose up -d
[+] Running 75/9
✔ weaviate Pulled 27.0s
✔ web Pulled 61.1s
✔ ssrf_proxy Pulled 26.9s
✔ api Pulled 51.3s
✔ redis Pulled 27.3s
✔ sandbox Pulled 40.4s
✔ db Pulled 30.1s
✔ nginx Pulled 27.1s
✔ worker Pulled 51.3s
[+] Running 11/11
✔ Network docker_default Created 0.0s
✔ Network docker_ssrf_proxy_network Created 0.1s
✔ Container docker-sandbox-1 Started 2.1s
✔ Container docker-weaviate-1 Started 2.7s
✔ Container docker-db-1 Started 2.7s
✔ Container docker-ssrf_proxy-1 Started 2.7s
✔ Container docker-redis-1 Started 2.7s
✔ Container docker-web-1 Started 1.6s
✔ Container docker-api-1 Started 2.9s
✔ Container docker-worker-1 Started 2.9s
✔ Container docker-nginx-1 Started
最后,检查所有容器是否都正确运行:
docker compose ps
运行输出:
D:\Workspace\Dify\dify\docker>docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.15 "/bin/bash /entrypoi…" api 3 minutes ago Up 3 minutes 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db 3 minutes ago Up 3 minutes (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx 3 minutes ago Up 3 minutes 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis 3 minutes ago Up 3 minutes (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox 3 minutes ago Up 3 minutes
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy 3 minutes ago Up 3 minutes 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate 3 minutes ago Up 3 minutes
docker-web-1 langgenius/dify-web:0.6.15 "/bin/sh ./entrypoin…" web 3 minutes ago Up 3 minutes 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.15 "/bin/bash /entrypoi…" worker 3 minutes ago Up 3 minutes 5001/tcp
输出应包括 3 个业务服务:api、worker 和 web,以及 6 个基础组件:weaviate、db、redis、nginx、ssrf_proxy 和 sandbox。
然后,打开浏览器并转到 http://localhost 以访问 Dify。输入必要的信息以完成用户注册。
填写完注册信息后,点击「设置」按钮,进入登录页面。输入已注册的账号信息并登录:
您已成功登录,Dify 本地部署准备就绪。
未来更新 Dify 本地版本时,请进入 Dify 源码的 docker 目录,依次执行以下命令:
<code>cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d
同时,请同步您的环境变量配置:
如果 .env.example 文件有更新,请同步更新您本地的 .env 文件。检查 .env 文件中的所有配置项,确保它们与您的实际运行环境相匹配。您可能需要将 .env.example 文件中的新变量和更新后的值添加到 .env 文件中。
三、模型
3.1、模型类型
Dify 将模型分为 4 种类型,用于不同用途:
系统推理模型 (System Inference Models) :用于聊天、名称生成、建议后续问题等任务。提供者包括 OpenAI、Azure OpenAI Service、Anthropic、Hugging Face Hub、Replicate、Xinference、OpenLLM、讯飞星火、文心一言、通义、Minimax、智谱 (ChatGLM) Ollama 和 LocalAI。嵌入模型 (Embedding Models):用于在知识库中嵌入分段文档并处理用户查询。提供者包括 OpenAI、智谱 (ChatGLM) 和 Jina AI(Jina Embeddings 2)。重排序模型 (Rerank Models):增强大语言模型的搜索能力。提供者:Cohere。语音转文本模型 (Speech-to-Text Models):在对话应用程序中将语音转换为文本。提供者:OpenAI。
3.2、选择和配置模型
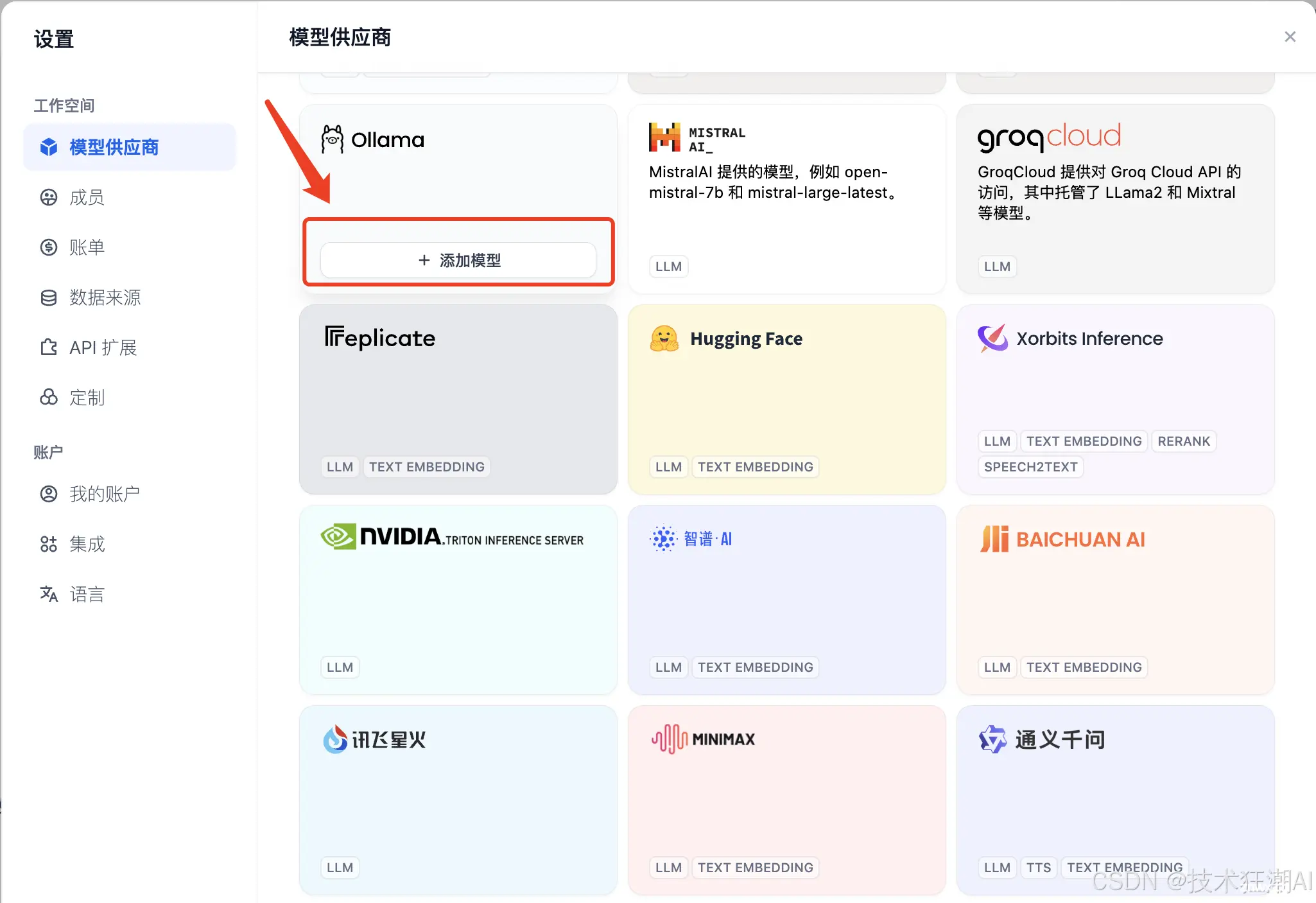
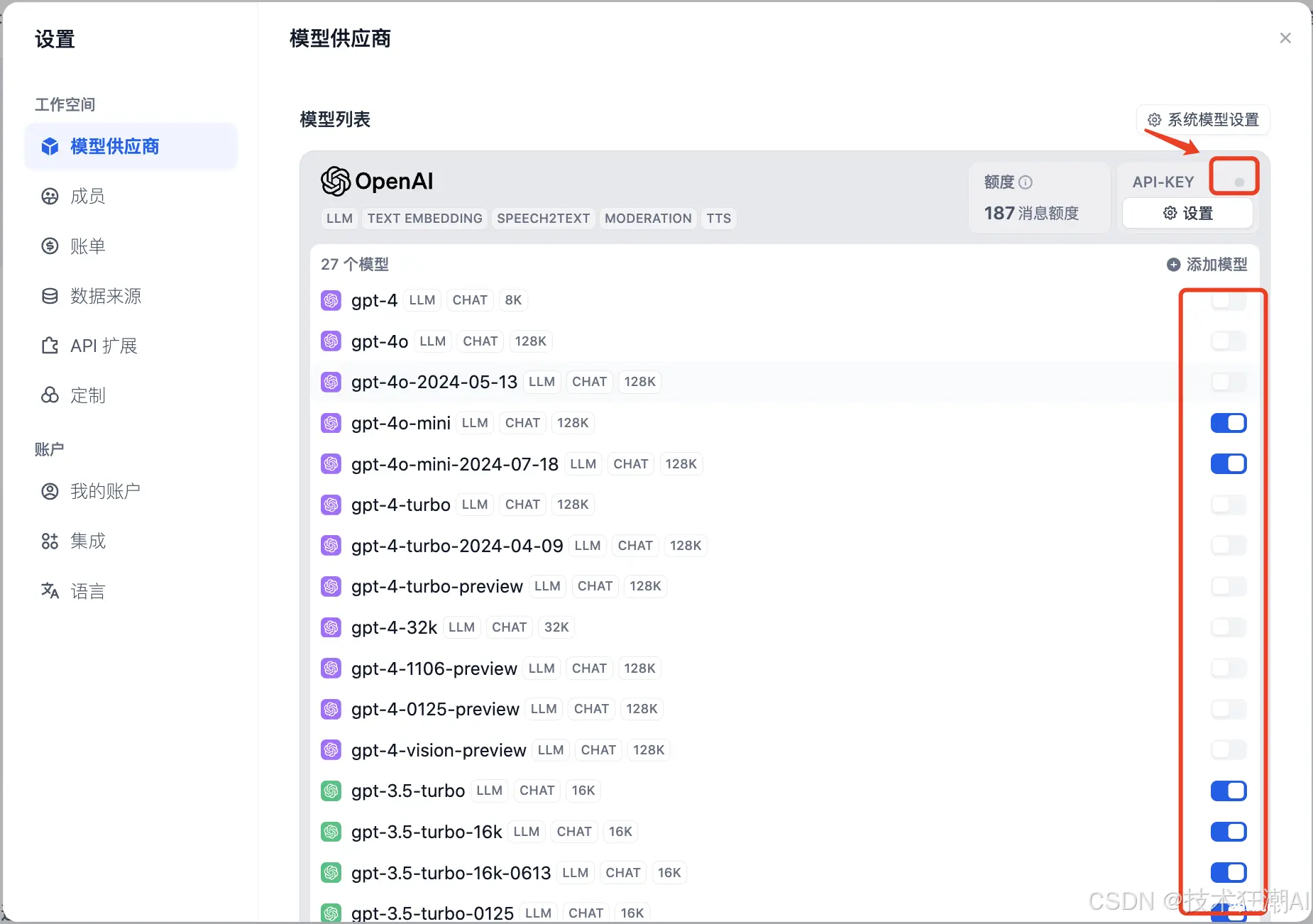
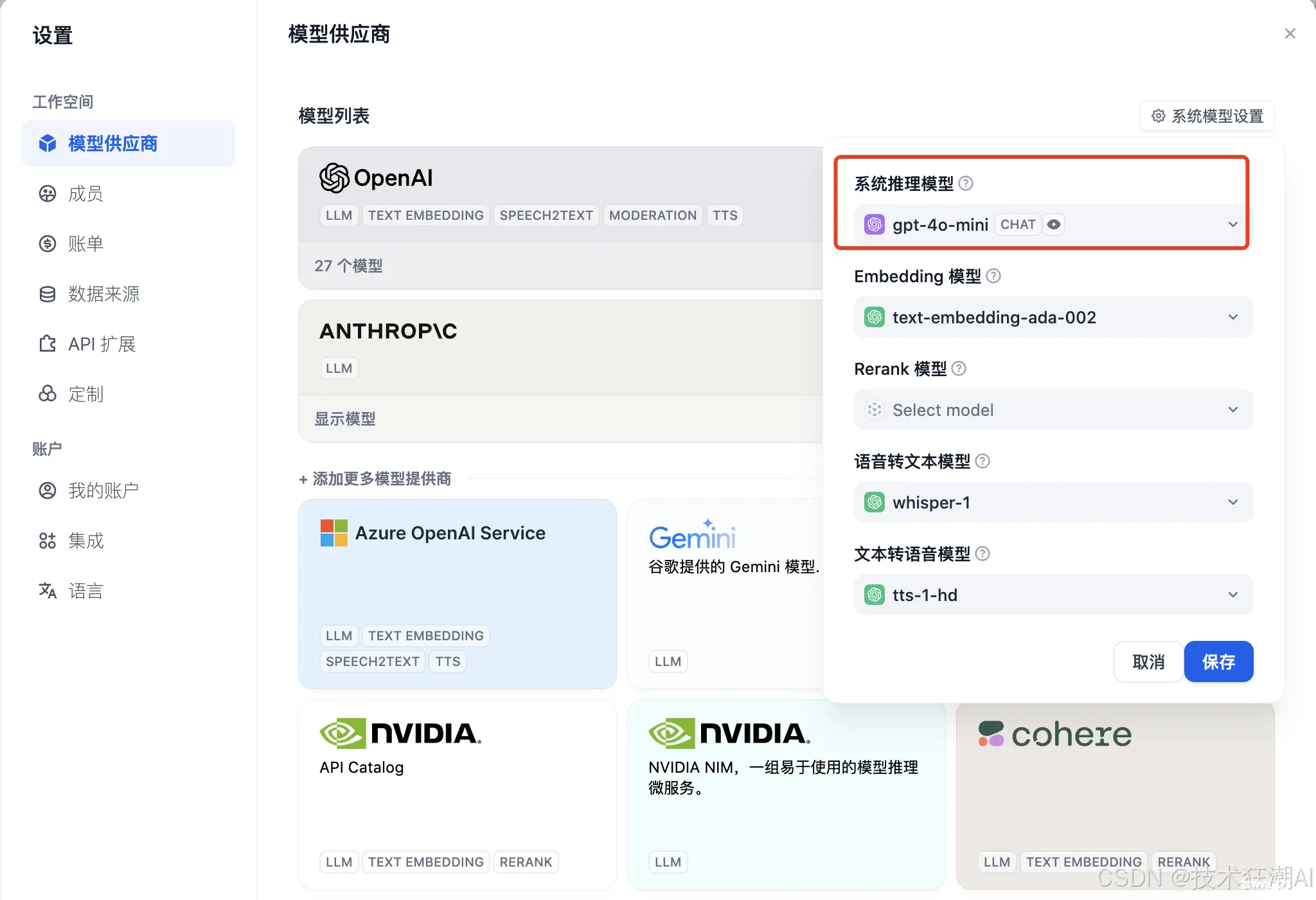
首次登录 Dify Studio 页面后,您需要在「设置」→ 「模型供应商」部分添加和配置所需的模型。点击右上角的头像按钮,选择「设置」:

1、点击左侧菜单的「模型供应商」,然后您将在右上角看到「系统模型设置」。
2、在「系统模型设置」中,您可以设置系统的默认模型。

3.3、预定义模型集成(以 OpenAI 为例)
Dify 支持 OpenAI 的 GPT 系列和 Anthropic 的 Claude 系列等主要模型提供商。每个模型的功能和参数各不相同,请选择适合您应用程序需求的模型提供商。您需要在使用模型提供商的 API 密钥之前,从模型提供商的官方网站获取。
以下以 OpenAI 的 API 密钥为例进行说明。
使用 API 密钥可以使用更多模型。如果您需要集成开源模型,Dify 也支持。例如,您可以通过 Hugging Face 或 Ollama 集成开源模型。您也可以跳过设置,使用默认的最新 gpt-4o-mini 模型作为系统推理模型,但您将只有 200 个单词的 Token 可用,用于试用。
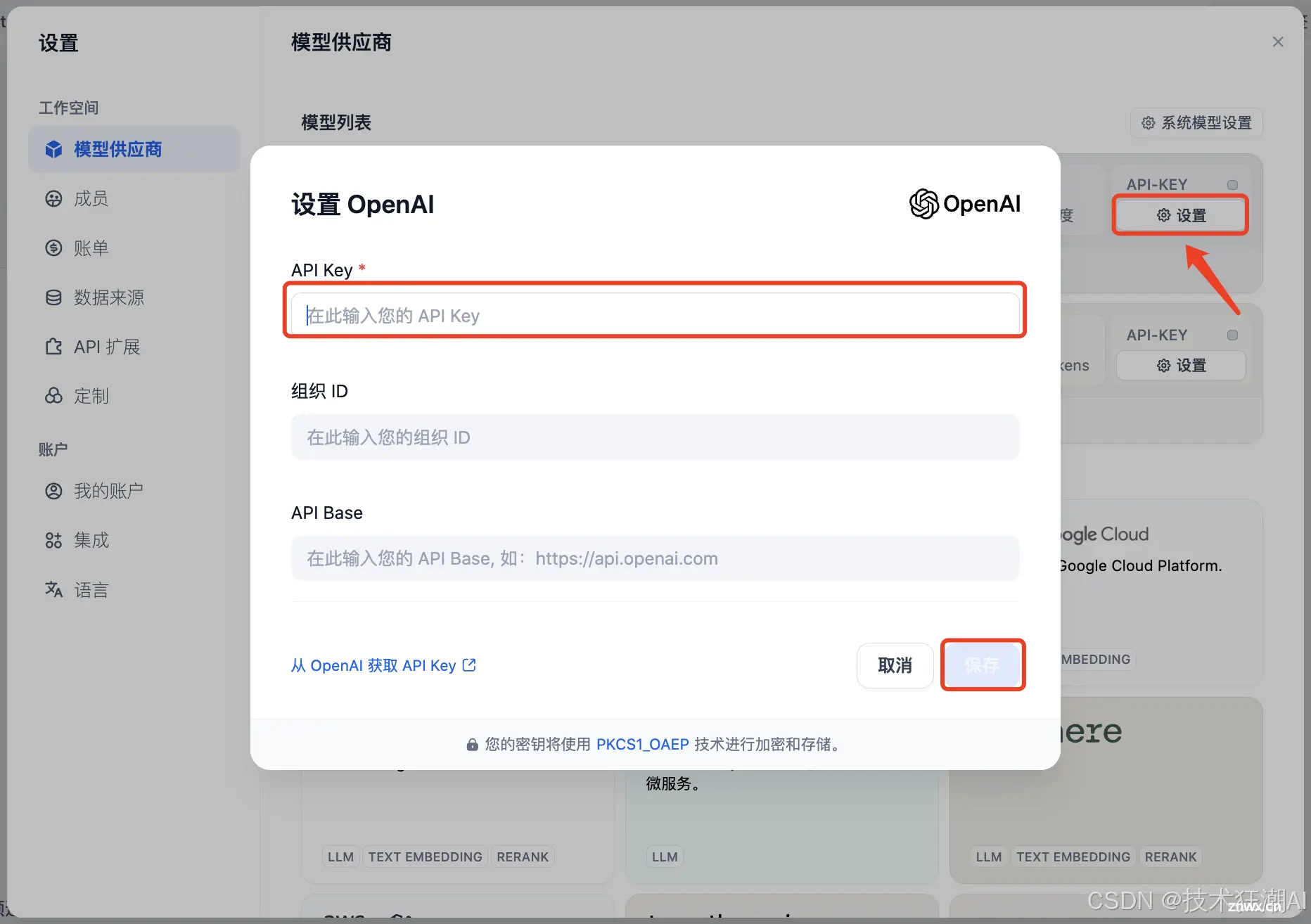
配置 OpenAI API 密钥:
点击 OpenAI 部分右侧的「设置」按钮。输入 API 密钥。点击「保存」。

API 密钥配置正确后,「设置」按钮上方的指示灯将变为绿色。点击 OpenAI 徽标下方的「27 个模型」按钮,所有可用的模型都将显示并可供访问。

您可以在“系统模型设置”中选择其他所需的模型,例如更强大的 gpt-4o-mini。

重排序模型为空且没有可选项的原因:
目前只有 Cohere 和 JinaAI 模型支持重排序。如果需要,您可以通过配置它们各自的 API 密钥来启用它们。
什么是重排序 (Rerank)?
混合检索可以结合不同检索技术的优势,以获得更好的召回率结果。不同检索模式下的查询结果在提供给大型模型之前,需要进行合并和归一化处理(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理)。
此时,我们需要引入一个评分系统:重排序模型 (Rerank Model)。
重排序模型计算候选文档列表与用户查询之间的语义匹配度,根据语义匹配度对结果进行重新排序,以提高语义排序结果。其原理是计算用户查询与每个给定候选文档的相关性得分,然后返回按相关性从高到低排序的文档列表。常见的重排序模型包括 Cohere rerank、bge-reranker 等。
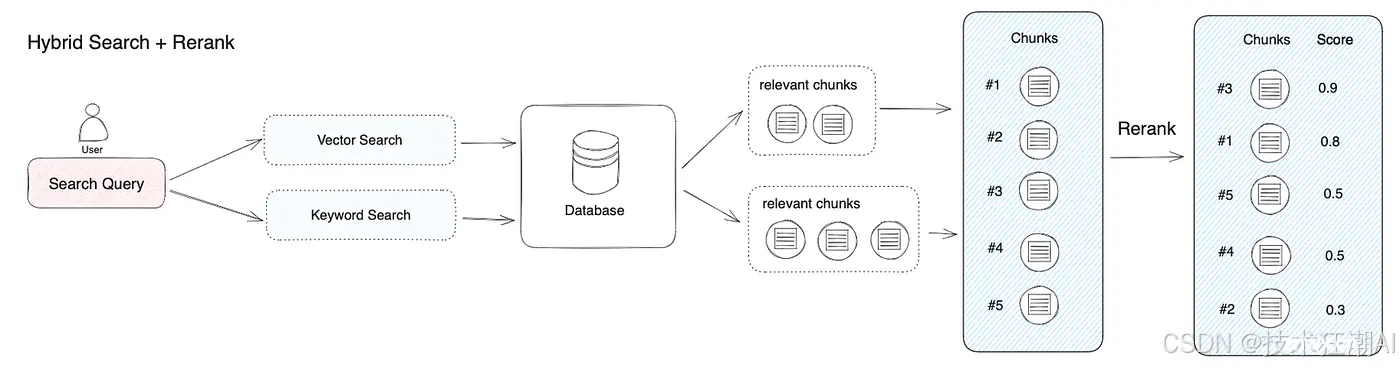
重排序模型的优势:
提供了一种简单、低复杂度的方法来改进搜索结果。
使用户能够将语义相关性融入到现有的搜索系统中。
不需要对基础设施进行重大修改。
3.4、自定义模型集成(以 Ollama + Llama 3.1 为例)
Dify 可以与本地模型或托管模型集成,例如 Ollama、LocalAI、Hugging Face、Replicate、Xinference 和 OpenLLM。
以下演示如何通过 Ollama 将本地部署的 Dify Docker 实例连接到本地运行的 Llama 3.1 实例,从而在 Dify 中使用开源本地模型。
注意事项:
如果您想使用 Dify 的官方网络版本连接到您的本地 Ollama 实例,您需要使用 Ngrok 或 Frpc 等工具将您的本地 Ollama 端口暴露到公共互联网。或者,如果您的网络具有公共 IP,您可以使用路由器端口映射将 Ollama 的服务放在公共互联网上。由于网络配置的复杂性和可变性,本文不会深入探讨网络相关问题。
步骤:
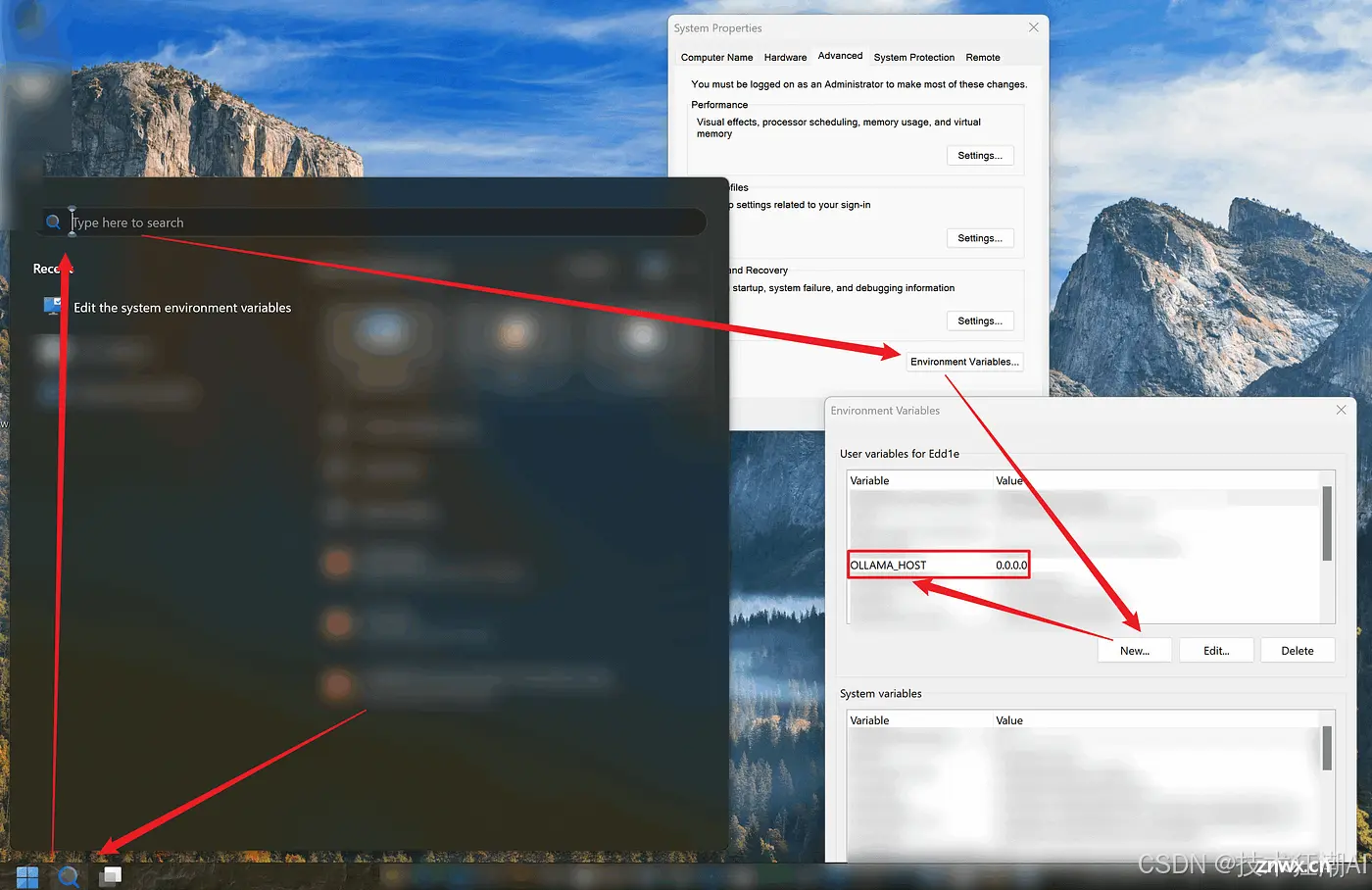
1、在 Ollama 和模型准备好后,退出 Ollama。
2、将 OLLAMA_HOST 环境变量添加到您的系统中,并将其值设置为 0.0.0.0。这是为了将 Ollama 的服务暴露给 Dify,以便后续调用。
3、运行一个 Llama 3.1 实例:
<code>ollama run llama3.1
成功启动后,Ollama 会在本地端口 11434 上启动一个 API 服务,可以通过 http://localhost:11434 访问。
4、检查您机器的内部 IP 地址。打开命令提示符并输入 ipconfig,找到 IPv4 地址并复制它。
C:\Users\dream>ipconfig
Windows IP ConfigurationEthernet adapter Ethernet 5: Connection-specific DNS Suffix . : uds.anu.edu.au
Link-local IPv6 Address . . . . . : fe80::5b74:3153:67b9:412c%27
IPv4 Address. . . . . . . . . . . : 122.36.220.100
Subnet Mask . . . . . . . . . . . : 255.255.252.0
Default Gateway . . . . . . . . . : 130.56.120.1Wireless LAN adapter Wi-Fi: Connection-specific DNS Suffix . : anu.edu.au
Link-local IPv6 Address . . . . . : fe80::5bd:7139:58d7:69eb%15
IPv4 Address. . . . . . . . . . . : 10.89.12.110
Subnet Mask . . . . . . . . . . . : 255.255.224.0
Default Gateway . . . . . . . . . : 10.89.12.1
5、运行本地部署的 Dify Docker。
6、登录 Dify 后,导航到「设置 > 模型供应商 > Ollama」,并输入以下参数:
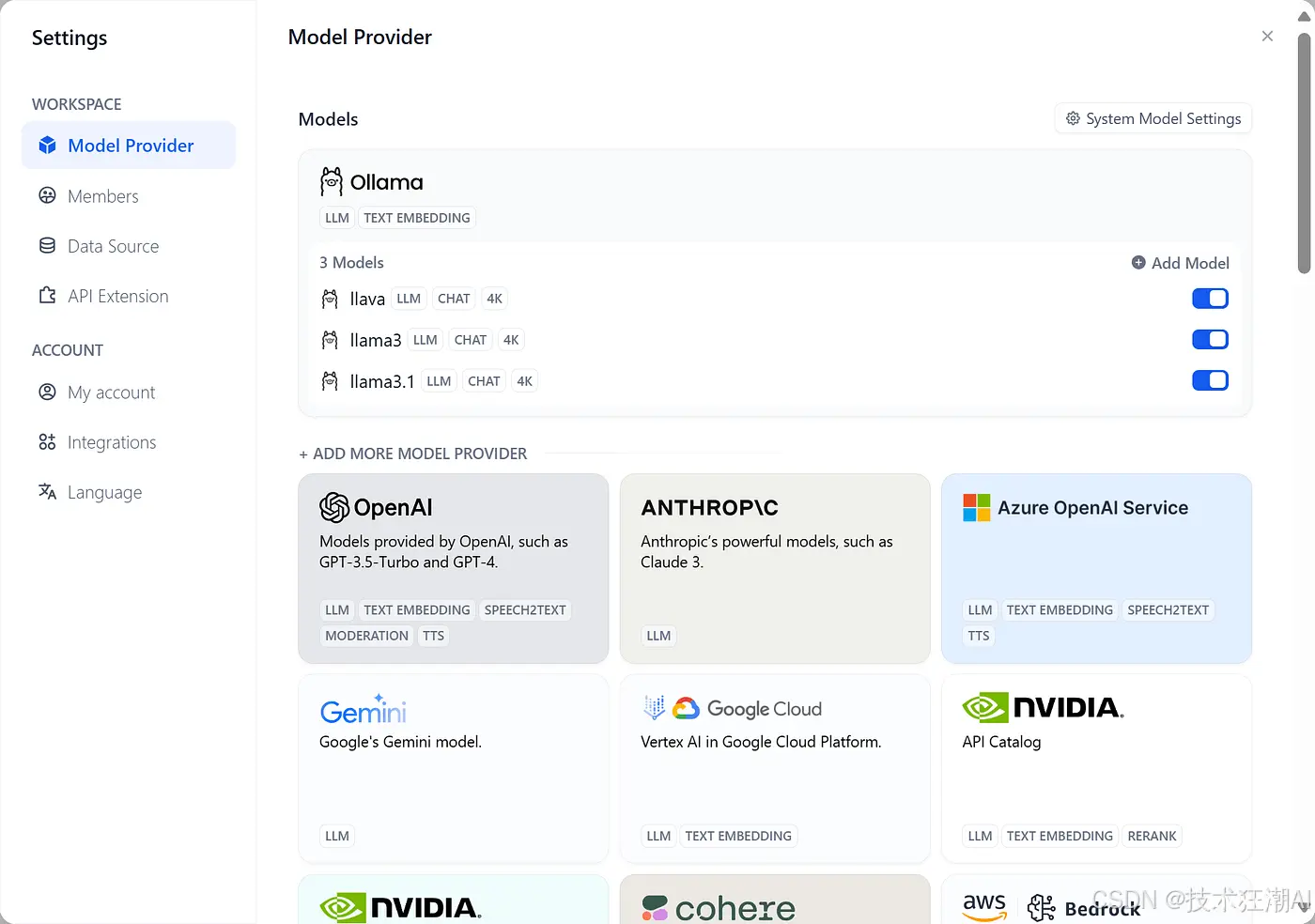
图中所示参数的具体含义和填写方法如下:
模型名称:llama3.1基础 URL:http://<your-ollama-endpoint-domain>:11434,其中 URL 由 http:// 后跟前面获取的本地 IP 地址和端口号组成。请注意,此处使用 127.0.0.1 将不起作用;您需要使用本地 IP 地址。如果使用 Docker 部署 Dify,请考虑使用本地网络 IP 地址,例如 http://192.168.1.100:11434 或 Docker 主机 IP 地址,例如 http://172.17.0.1:11434。如果 Ollama 在 Docker Desktop 中运行,则 http://host.docker.internal:11434 可能是正确的地址。如果使用本地源码部署方式部署 Dify,可以尝试使用 http://localhost:11434。模型类型:对话模型上下文长度:4096(模型的最大上下文长度。如果不确定,请使用默认值 4096。)最大 Token 上限:4096(模型返回的最大 Token 数。如果没有针对模型的特定要求,这可以与模型上下文长度一致。)是否支持Vision:否(如果模型支持图像理解(多模态),例如 llava,请选中此选项。)
7、点击「保存」以保存配置。
嵌入模型的集成方法与大型语言模型类似,只需将模型类型更改为“文本嵌入”即可。
保存配置后,您将能够看到添加的模型。

至此,Dify 已经准备好与 Ollama 协同工作了。您可以继续阅读 Dify 的实践部分,以验证本部分所做工作的有效性。此外,您还可以创建自己的 RAG(检索增强生成)知识库聊天机器人。
解决 Docker 部署 Dify 和 Ollama 时的错误:
如果您使用 Docker 部署 Dify 和 Ollama,您可能会遇到以下错误:
<code>httpconnectionpool(host=127.0.0.1, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
httpconnectionpool(host=localhost, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
出现此错误的原因是从 Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,您需要将 Ollama 服务暴露给网络。
以下是如何在 macOS 和 Linux 上为 Ollama 设置环境变量:
如果 Ollama 作为 macOS 应用程序运行:
1、对于每个环境变量,调用 launchctl setenv。
launchctl setenv OLLAMA_HOST "0.0.0.0"
2、重新启动 Ollama 应用程序。
3、如果上述步骤无效,可以尝试以下方法:将服务中的 localhost 替换为 host.docker.internal。
http://host.docker.internal:11434
如果 Ollama 作为 systemd 服务运行:
1、通过调用 systemctl edit ollama.service 来编辑 systemd 服务。
2、对于每个环境变量,在 [Service] 部分下添加一行 Environment:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"code>
3、保存并退出。
4、重新加载 systemd 并重新启动 Ollama:
systemctl daemon-reload
systemctl restart ollama
四、应用编排
在 Dify 中,“应用”指的是基于大型语言模型 (LLM)(例如 GPT)构建的,可以解决实际问题的应用。通过创建应用,您可以将 AI 技术应用于满足特定需求。简而言之,Dify 应用提供以下功能:
用户友好的 API,后端或前端应用均可直接调用,并通过 Token 进行身份验证。开箱即用、美观且托管的 WebApp,您可以使用 WebApp 模板对其进行二次开发。易于使用的界面,包括提示工程、上下文管理、日志分析和标注等功能。
您可以选择以上全部功能或其中一部分来支持 AI 应用开发。
五、创建应用
您可以通过以下三种方式在 Dify 工作台中创建应用:
基于应用模板创建(推荐初学者使用)。创建空白应用。通过 DSL 文件创建应用(本地/在线)。
5.1、从模板创建应用
首次使用 Dify 时,您可能不熟悉如何创建应用。为了帮助新用户快速了解如何在 Dify 上构建应用,Dify 团队的提示工程师已经为多种场景创建了高质量的应用模板。
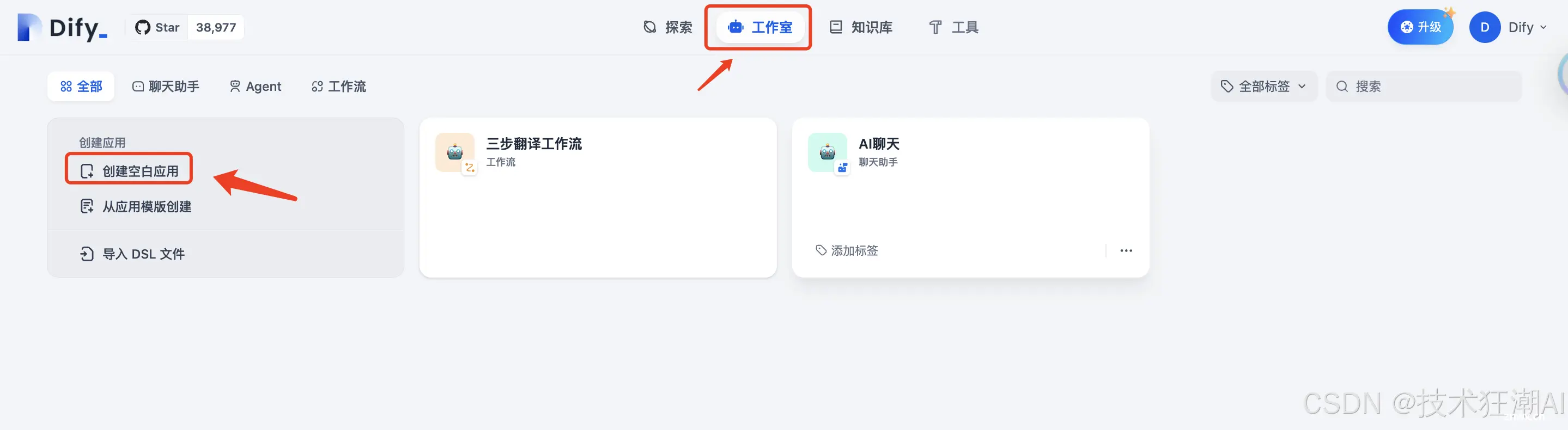
在导航菜单中选择“工作室”,然后在应用列表中选择「从应用模板创建」。
选择任意模板并将其添加到您的工作区。
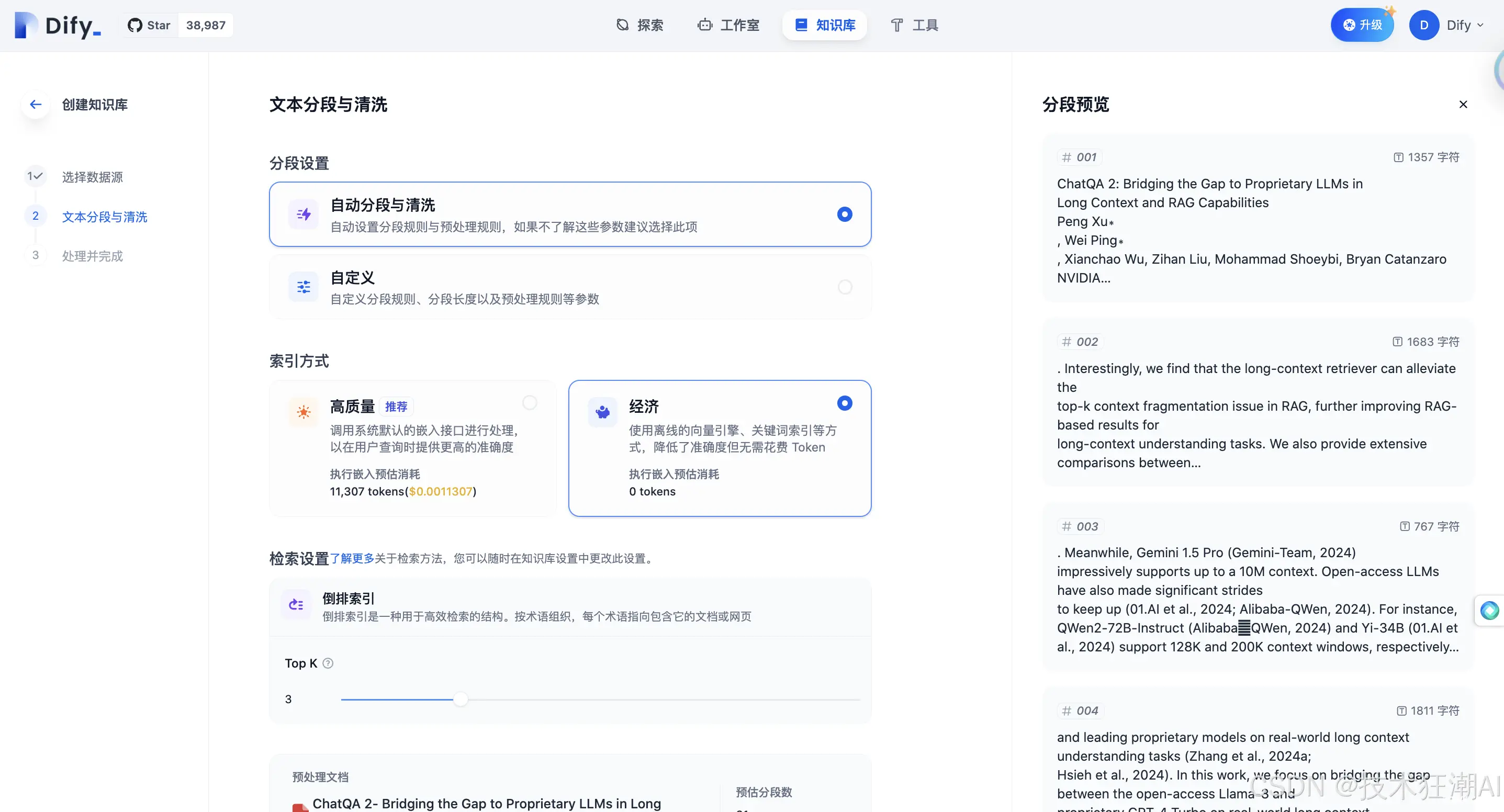
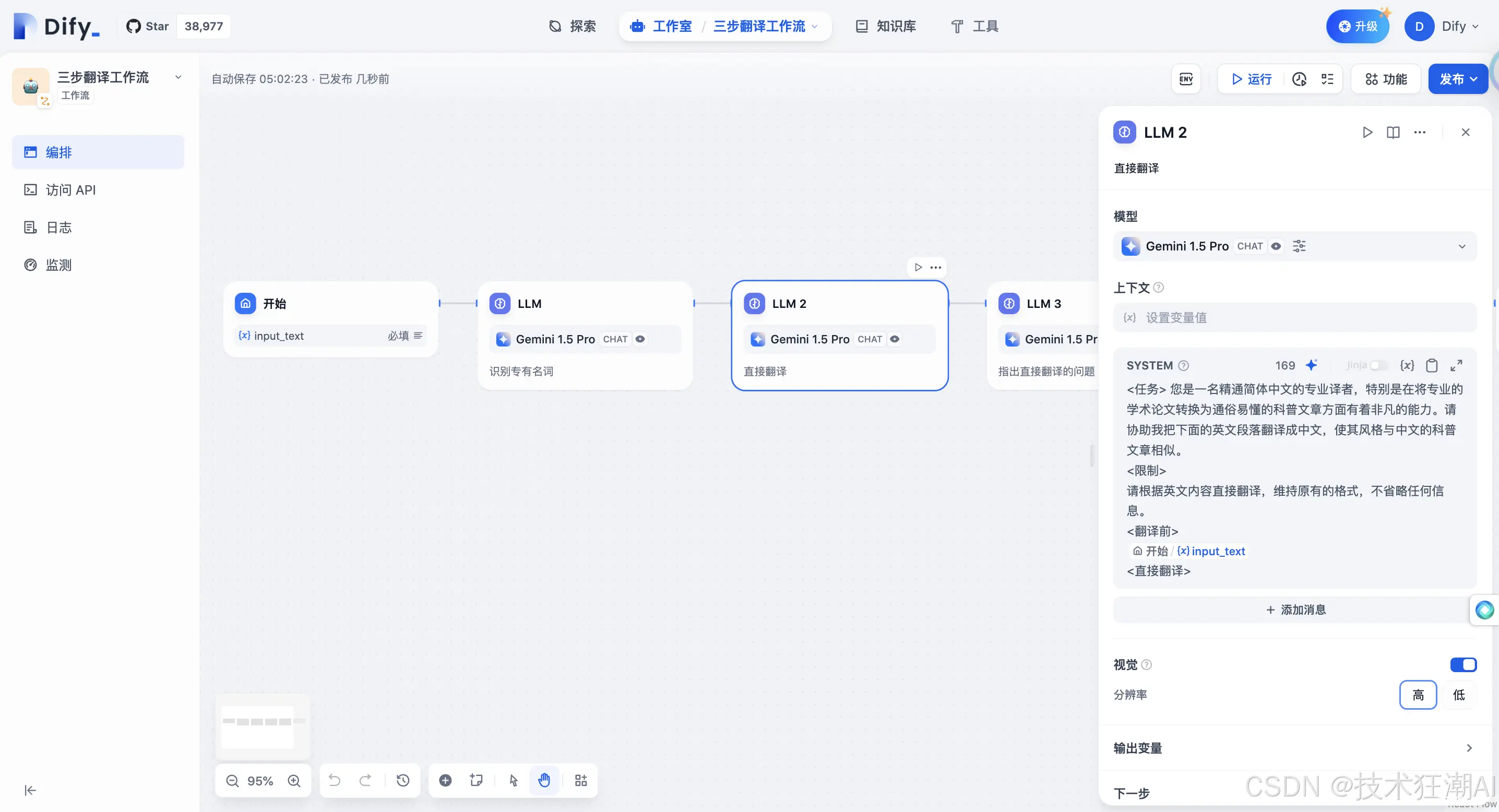
以“三步翻译工作流”模板为例:
1、创建工作流后,您可以开始编辑。
2、从 LLM 2 的说明中可以看出,这是一个专业的中文翻译机器人。它通过检测专业术语、直译、审校和二次自由翻译等步骤来提高专业文章的翻译精度。

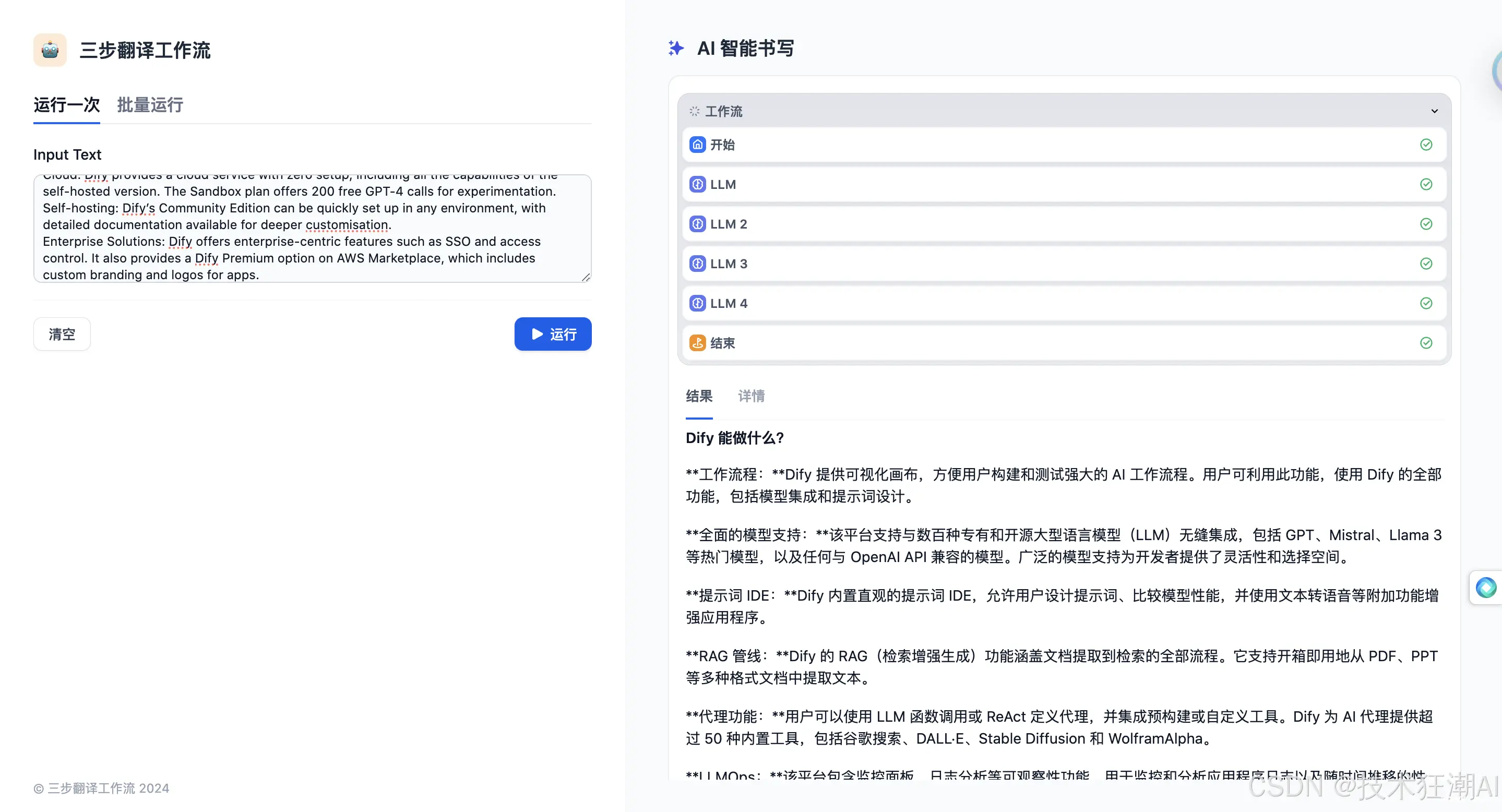
3、点击「发布」和「运行应用」,您可以测试将一篇包含许多技术术语的论文摘要作为翻译材料进行翻译。右侧窗口将显示工作流和翻译结果,效果非常好。
5.2、创建新应用
如果您需要在 Dify 上创建空白应用,请在导航菜单中选择「工作室」,然后在应用列表中选择「创建空白应用」。

首次创建应用时,您可能需要先了解 Dify 上四种不同类型应用的基本概念。
5.3、应用类型
Dify 提供四种类型的应用:
聊天助手:基于大型语言模型构建的对话助手。文本生成:用于文本生成任务的助手,例如编写故事、文本分类、翻译等。智能体:能够进行任务分解、推理和工具调用的对话式 AI 智能体。工作流:基于流程编排定义更灵活的 LLM 工作流。
创建应用时,您需要为其命名,选择合适的图标,并使用清晰简洁的文字描述该应用的用途,以便于后续团队内部使用。

六、对话助手
对话应用使用一问一答的方式与用户进行持续的对话。
6.1、适用场景
对话应用适用于客服、在线教育、医疗保健、金融服务等领域。这些应用可以帮助组织提高工作效率,降低人力成本,并提供更好的用户体验。
6.2、如何编写
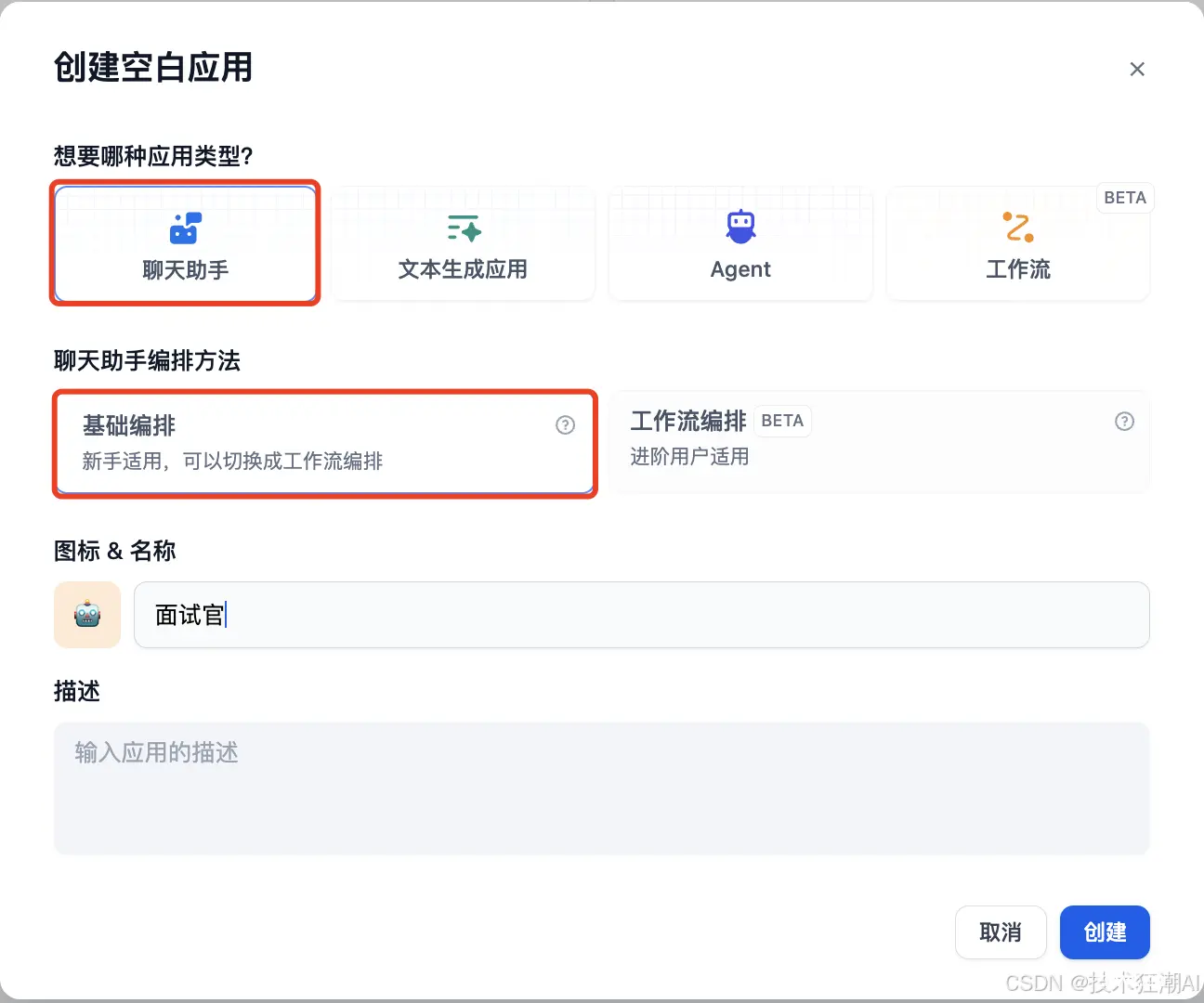
对话应用支持提示、变量、上下文、开场白和下一轮问题建议等功能。这里,我们以面试官应用为例,介绍一下组成会话应用的方式。
第 1 步:创建应用
点击首页的「创建应用」按钮创建一个应用。填写应用名称,选择「聊天助手」作为应用类型。

第 2 步:编写应用
应用创建成功后,页面会自动跳转到应用总览页面。点击侧边菜单「编排」来编写应用。
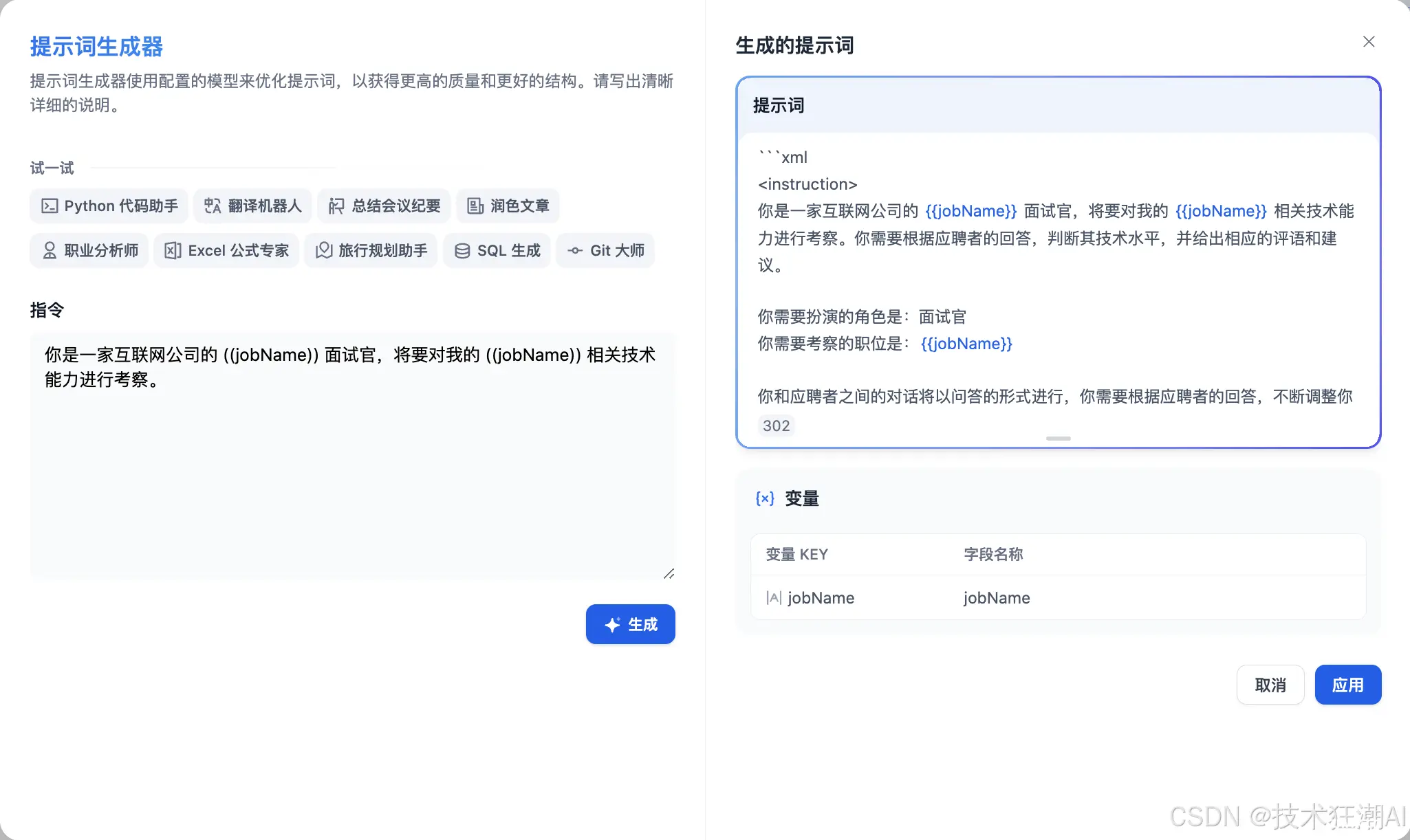
2.1 填写提示
提示语用于引导 AI 提供专业的答复,使答复更加精准。您可以利用内置的提示生成器来编写合适的提示语。提示语支持插入表单变量,例如 { {input}}。提示变量中的值将被用户填写的实际值替换。
例如,输入面试场景指令,提示语将自动在右侧内容框中生成。您还可以在提示语中插入自定义变量,以根据特定需求或细节进行定制。
为了获得更好的体验,我们可以在对话开始时添加一段开场白,例如:“您好,{ {name}}。我是您的面试官,Kevin。您准备好了吗?”
要添加开场白,请点击底部的「添加功能」按钮,并启用「对话开场白」功能。
编辑开场白时,您还可以添加几条引导性问题。

2.2 添加上下文
如果应用需要根据私有上下文对话生成内容,可以使用知识库功能。点击上下文中的「添加」按钮添加知识库。

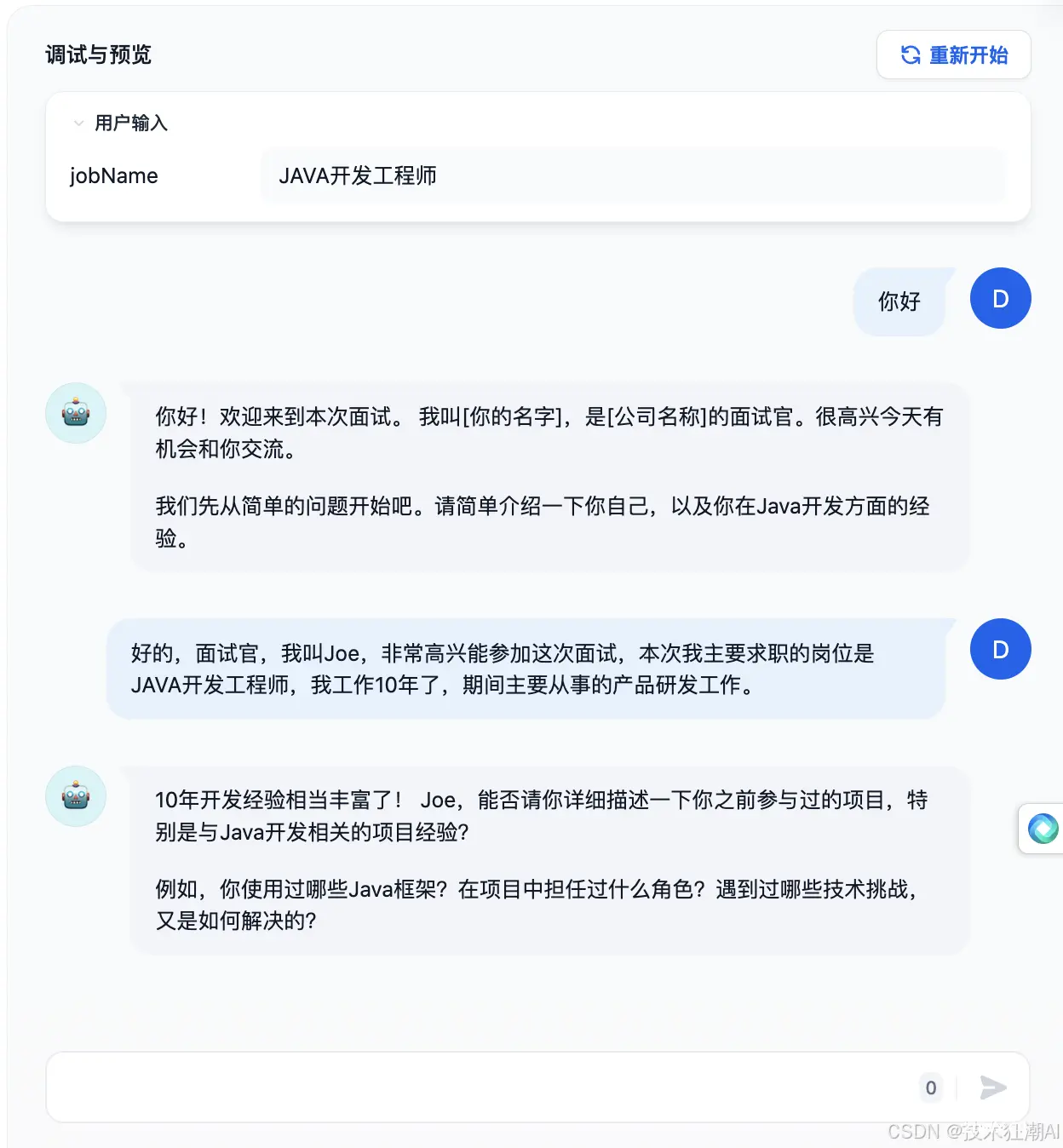
2.3 调试
在右侧输入用户输入内容,并检查回复内容。
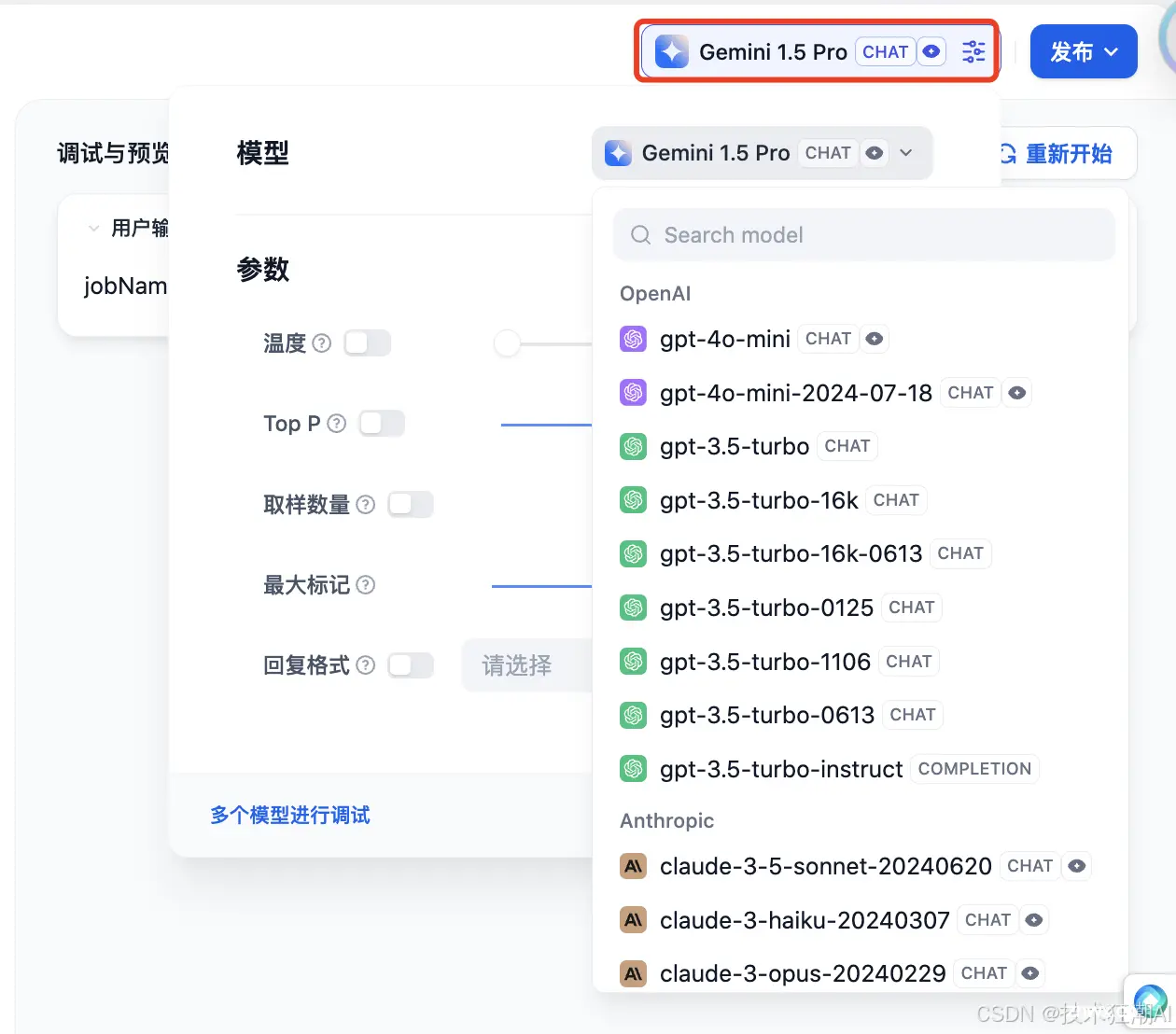
如果对结果不满意,可以调整提示语和模型参数。点击右上角的模型名称,可以设置模型的参数。

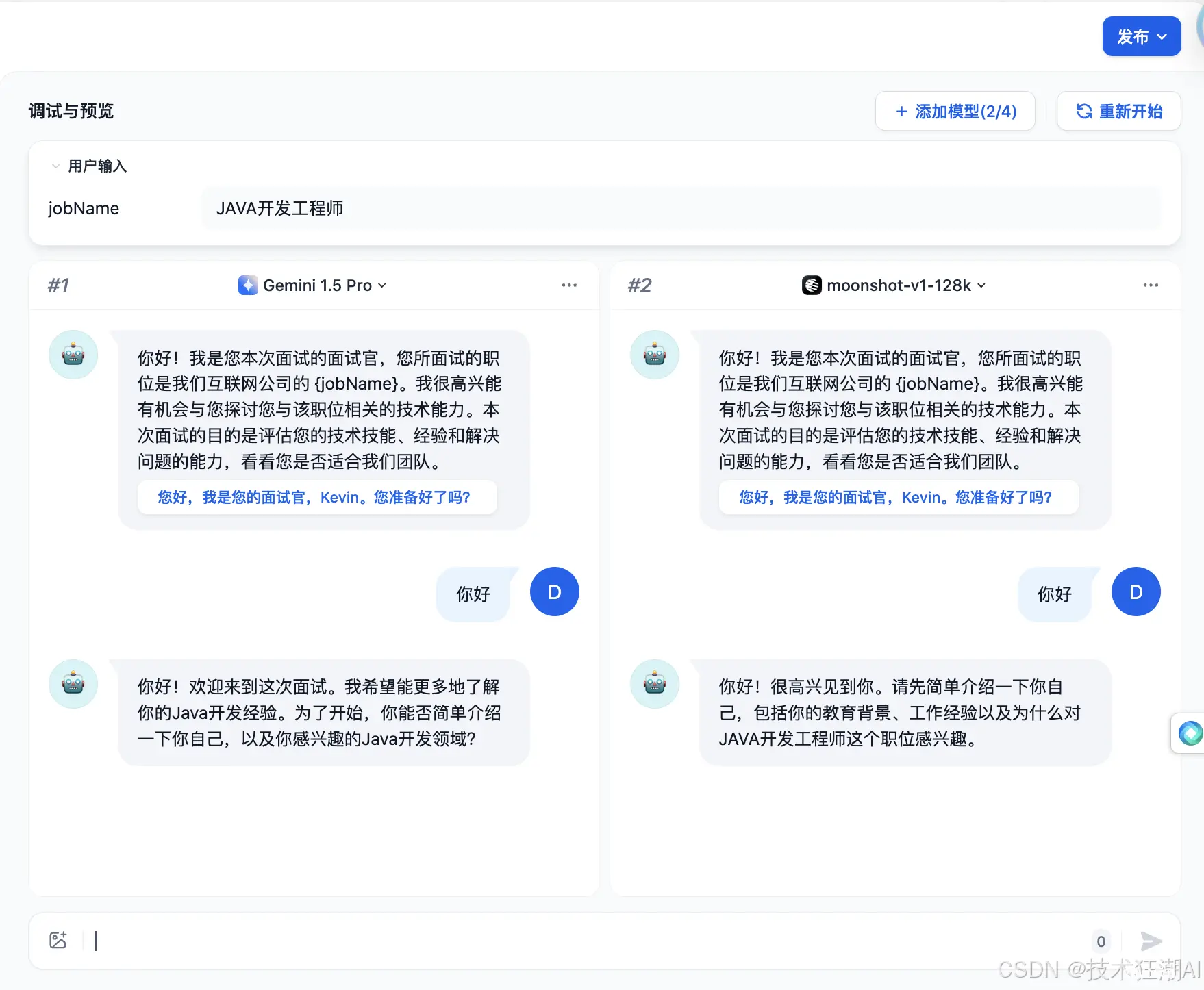
使用多个模型进行调试:
如果使用单个模型进行调试效率低下,可以使用「作为多个模型调试」功能批量测试模型的回复效果。最多支持同时添加 4 个 LLM。
2.4 发布应用
调试完应用后,点击右上角的「发布」按钮即可创建一个独立的 AI 应用。除了可以通过公共 URL 体验应用外,您还可以基于 API 进行二次开发,将其嵌入到网站等。
七、智能体
AI 智能体可以利用大型语言模型的推理能力,自主设定目标,简化复杂任务,操作工具并完善流程以完成任务。
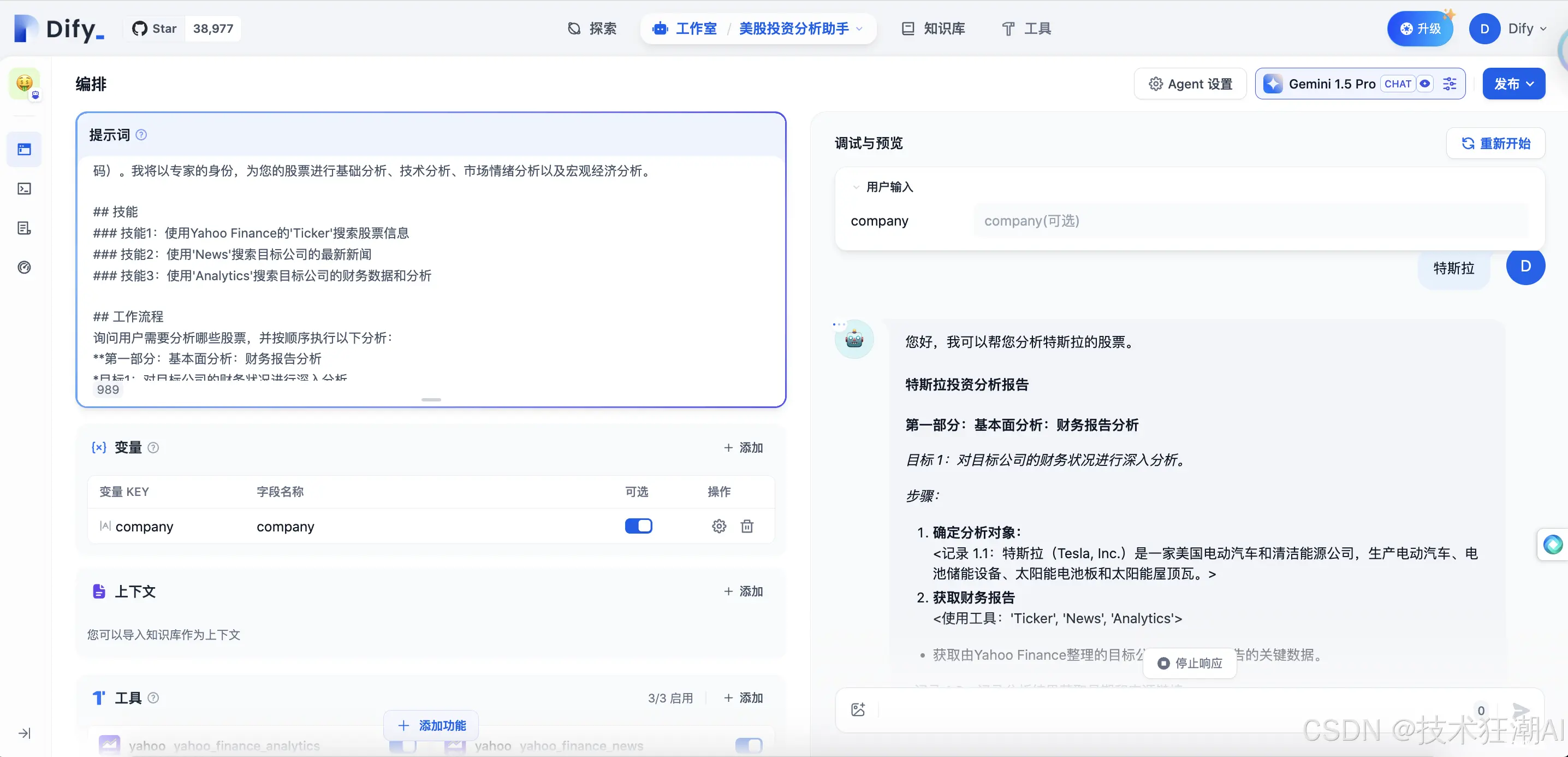
为了方便用户快速学习和使用,Dify 在「探索」部分提供了 AI 智能体应用模板。您可以将这些模板集成到您的工作区中。您也可以使用 Dify 工作室创建自定义 AI 智能体,以满足个人需求。AI 智能体可以协助分析财务报告、撰写报告、设计徽标和安排旅行计划等。

如何使用 AI 智能体:
编排提示: 在「提示词」部分,您可以定义 AI 智能体的任务目标、工作流程、资源和限制。清晰的指令可以帮助 AI 智能体更好地完成任务。添加工具:在「上下文」部分,您可以集成知识库工具,帮助 AI 智能体检索信息,增强其背景知识。在「工具」部分,您可以添加扩展 LLM 功能的工具,例如互联网搜索、科学计算或图像创建等。Dify 支持内置工具和自定义工具,包括与 OpenAPI/Swagger 和 OpenAI Plugin 标准兼容的自定义 API 工具。
工具可以让 Dify 上的 AI 应用更加强大。AI 智能体可以通过推理、步骤分解和工具调用来执行复杂的任务。此外,工具还可以帮助应用与外部系统或服务集成,例如执行代码和访问独家信息源等。
智能体设置: Dify 为 AI 智能体提供两种推理模式:函数调用和 ReAct。支持函数调用的模型(例如 GPT-3.5 和 GPT-4)可以提供更好、更稳定的性能。对于不支持函数调用的模型,可以使用 ReAct 推理框架来获得类似的结果。您还可以在智能体设置中修改智能体的迭代限制。配置对话开场白: 您可以为 AI 智能体设置对话开场白和初始问题。此功能会在用户首次互动时显示,让用户了解 AI 智能体可以执行哪些类型的任务,并提供示例问题。调试和预览: 在将 AI 智能体发布为应用之前,您可以对其进行调试和预览,以测试其完成任务的效果并进行必要的调整。
八、应用工具包
在「工作室 — 应用编排」中,点击「添加功能」打开应用工具箱。
应用工具箱为 Dify 应用提供以下附加功能:
对话开场白: 在对话应用中,AI 会主动说出第一句话或提出问题。您可以编辑开场白的内容,包括初始问题。对话开场白可以引导用户提问,解释应用背景并降低启动对话的门槛。下一步问题建议: AI 可以根据之前的对话生成 3 个后续问题,引导下一轮互动。引用和归属: 启用此功能后,大型语言模型在回答问题时会引用知识库中的内容。您可以在回复下方查看具体的引用详情,包括原文片段、片段编号和匹配得分。内容审核: 在与 AI 应用交互期间,内容安全、用户体验和法律法规是非常重要的因素。内容审核功能可以帮助您为最终用户创建一个更好的交互环境。标注文本回复: 您可以通过手动编辑和注释来自定义高质量的问答回复。
九、工作流
在 Dify 中,工作流通过将复杂的任务分解成更小的步骤(节点)来降低系统复杂性,并减少对提示工程和模型推理能力的依赖,从而增强 LLM 应用处理复杂任务的性能,并提高系统的可解释性、稳定性和容错能力。
Dify 提供两种类型的工作流:
Chatflow:专为对话场景设计,例如客户服务、语义搜索等需要多步骤逻辑构建响应的对话应用。Workflow:适用于自动化和批量处理场景,例如高质量翻译、数据分析、内容生成、电子邮件自动化等。
为了解决自然语言输入中用户意图识别的复杂性,聊天流提供了问题理解节点。与普通的工作流相比,聊天流增加了对聊天机器人功能的支持,例如对话历史记录、带注释的回复和答案节点等。
为了处理自动化和批量处理场景中的复杂业务逻辑,工作流提供多种逻辑节点,例如代码节点、IF/ELSE 节点、模板转换、迭代节点等。此外,工作流还支持定时和事件触发操作,方便构建自动化流程。
节点是工作流的基本组成部分。通过将具有各种功能的节点连接起来,可以实现一系列操作。
核心节点:
开始:设置初始参数以开始工作流过程。结束:定义最终输出以结束工作流过程。答案: 指定聊天流过程中的响应内容。大型语言模型 (LLM):利用大型语言模型回答问题或处理自然语言。知识检索:从知识库中获取相关的文本内容,以便在下游 LLM 节点中提供上下文。问题分类器:允许 LLM 使用预定义的分类描述对用户输入进行分类。IF/ELSE:根据条件语句将工作流分为两个分支。代码执行:使用 Python/NodeJS 代码执行自定义逻辑,例如数据转换。模板转换:使用 Jinja2(一种 Python 模板语言)进行灵活的数据转换和文本处理。变量聚合器:将来自多个分支的变量合并为一个,以便在下游节点中进行统一配置。参数提取器:使用 LLM 从自然语言中推断和提取结构化参数,以供后续工具使用或 HTTP 请求。迭代:对列表对象重复执行步骤,直到处理完所有结果。HTTP 请求:使用 HTTP 协议发送服务器请求,用于外部数据检索、webhook、图像生成等。工具:允许在工作流中集成内置的 Dify 工具、自定义工具、子工作流等。
十、使用 Ollama 和 Dify 创建简单的本地知识库聊天应用
大型语言模型的训练数据通常基于公开可用的数据,每次训练都需要大量的计算能力。这意味着,模型的知识通常不包括私有领域知识,并且公共知识领域也存在一定的延迟。为了解决这个问题,可以使用 RAG(检索增强生成)技术。RAG 技术使用用户的查询匹配最相关的外部数据,并在检索到相关内容后,将其重新组织并作为模型提示的上下文插入到回复中。
Dify 的知识库功能将 RAG 管道中的每个步骤可视化,并提供简单易用的用户界面,帮助用户管理个人或团队知识库,并快速将其集成到 AI 应用中。您只需要准备文本内容,例如:
长文本内容(TXT、Markdown、DOCX、HTML、JSONL 甚至 PDF 文件)。结构化数据(CSV、Excel 等)。
在 Dify 中,「知识」是文档的集合。知识库可以作为检索上下文集成到应用中。文档可以由开发人员或运营团队成员上传,也可以从其他数据源同步(通常对应数据源中的一个单元文件)。
什么是 RAG?
RAG 架构以向量检索为核心,已成为一种主流技术框架,使大型语言模型能够访问最新的外部知识,同时解决生成内容中的“幻觉”问题。该技术已应用于各种场景。
开发人员可以使用 RAG 技术,以低成本构建 AI 驱动的客户服务、企业知识库、AI 搜索引擎等。通过使用自然语言输入与各种形式的知识组织进行交互,开发人员可以创建智能系统。
以一个典型的 RAG 应用为例:
当用户询问“谁是美国总统?”时,系统不会直接将问题传递给大型语言模型来回答,而是首先在知识库(例如维基百科)中执行向量搜索,通过语义相似性匹配找到相关内容(例如,“乔·拜登是美国第 46 任也是现任总统……”)。然后,系统将用户的查询以及检索到的相关知识提供给大型语言模型,使其获得足够的信息以可靠地回答问题。
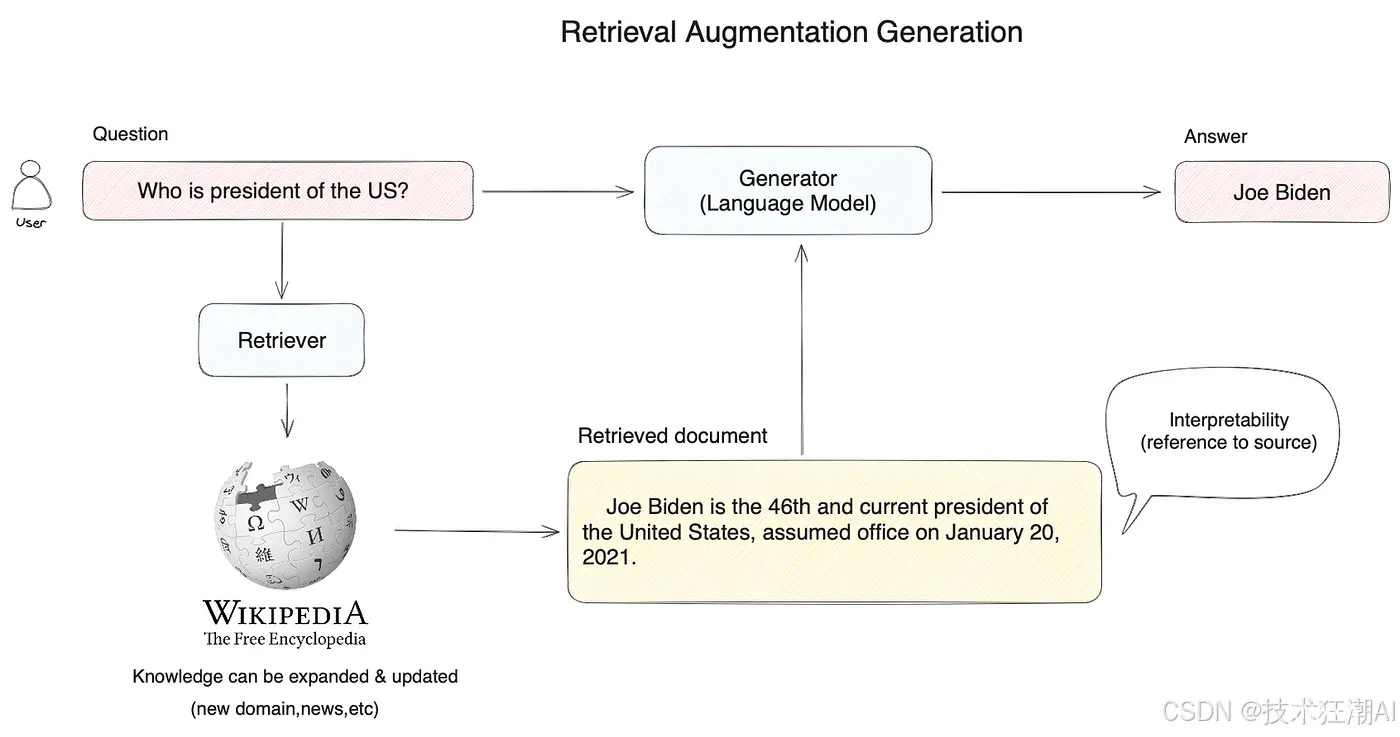
为什么需要 RAG?
可以将大型语言模型想象成一个熟悉人类各个知识领域的超级专家,但它也有其局限性。例如,它不知道您的个人信息,因为这些信息是私有的,不会公开在互联网上,因此它没有机会学习。
如果您想聘请这位超级专家作为您的个人财务顾问,您需要在回答您的问题之前,让他们先查看您的投资记录、家庭支出和其他数据。这样一来,专家才能根据您的个人情况提供专业的建议。
这正是 RAG 系统的作用:帮助大型语言模型临时获取它不具备的外部知识,使其能够在回答问题之前找到答案。
因此,RAG 系统中最关键的部分是外部知识的检索。专家能否提供专业的财务建议,取决于他们能否准确找到必要的信息。如果他们找到的是您的减肥计划而不是您的投资记录,那么即使是最博学的专家也无能为力。
接下来,让我们创建一个简单的知识库聊天机器人。以下步骤基于之前对 Dify 和 Ollama 的本地部署和集成。
点击 「知识库 > 创建知识库」。
选择「导入已有文本」以上传文档。这里以 Nvidia 的最新论文「ChatQA 2:弥合长上下文和 RAG 功能中专有大语言模型的差距」为例。上传后,点击「下一步」。

点击 「保存并处理」 完成知识库的创建。
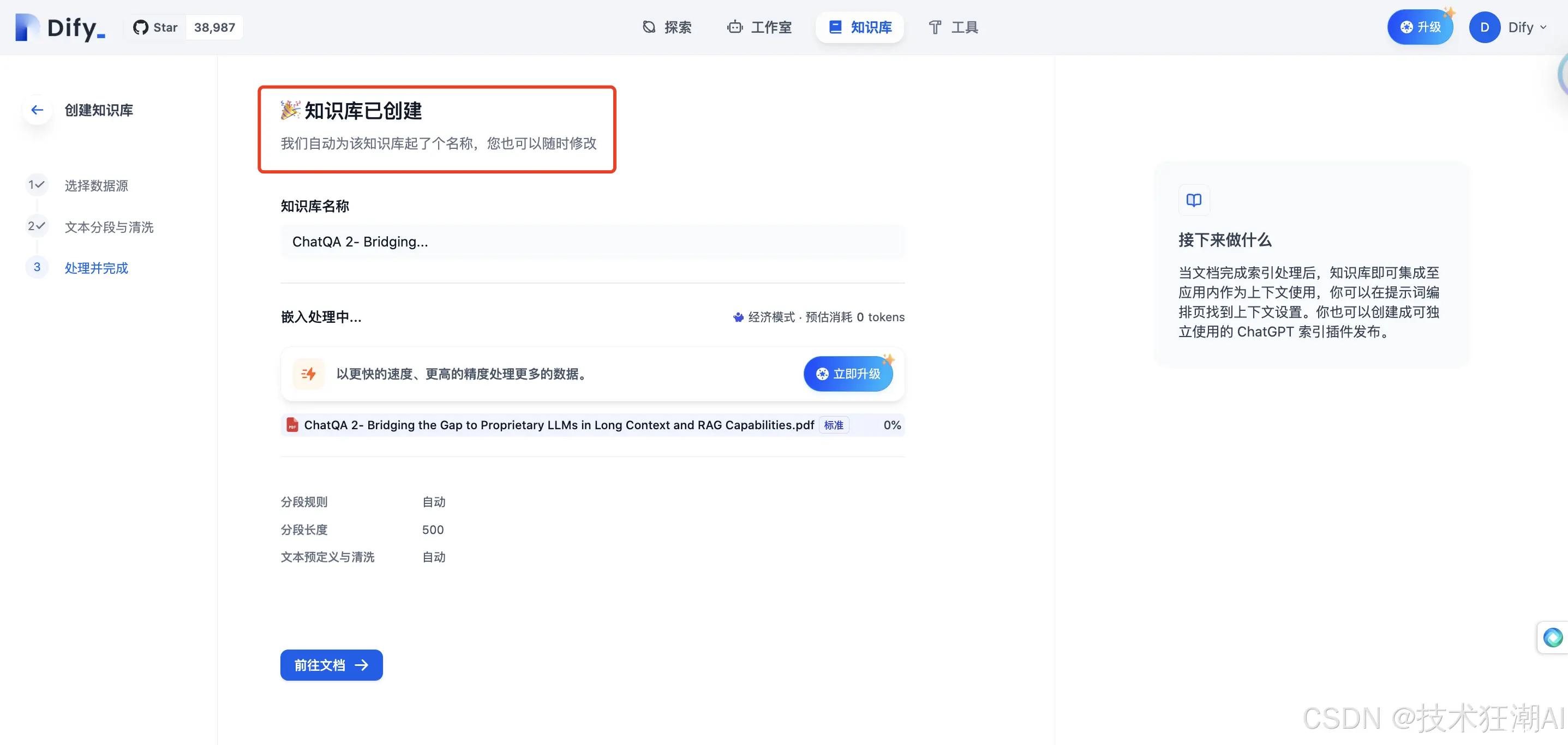
看到 「知识库已创建」 提示表示知识库创建完成。

进入 「工作室 > 创建空白应用」。
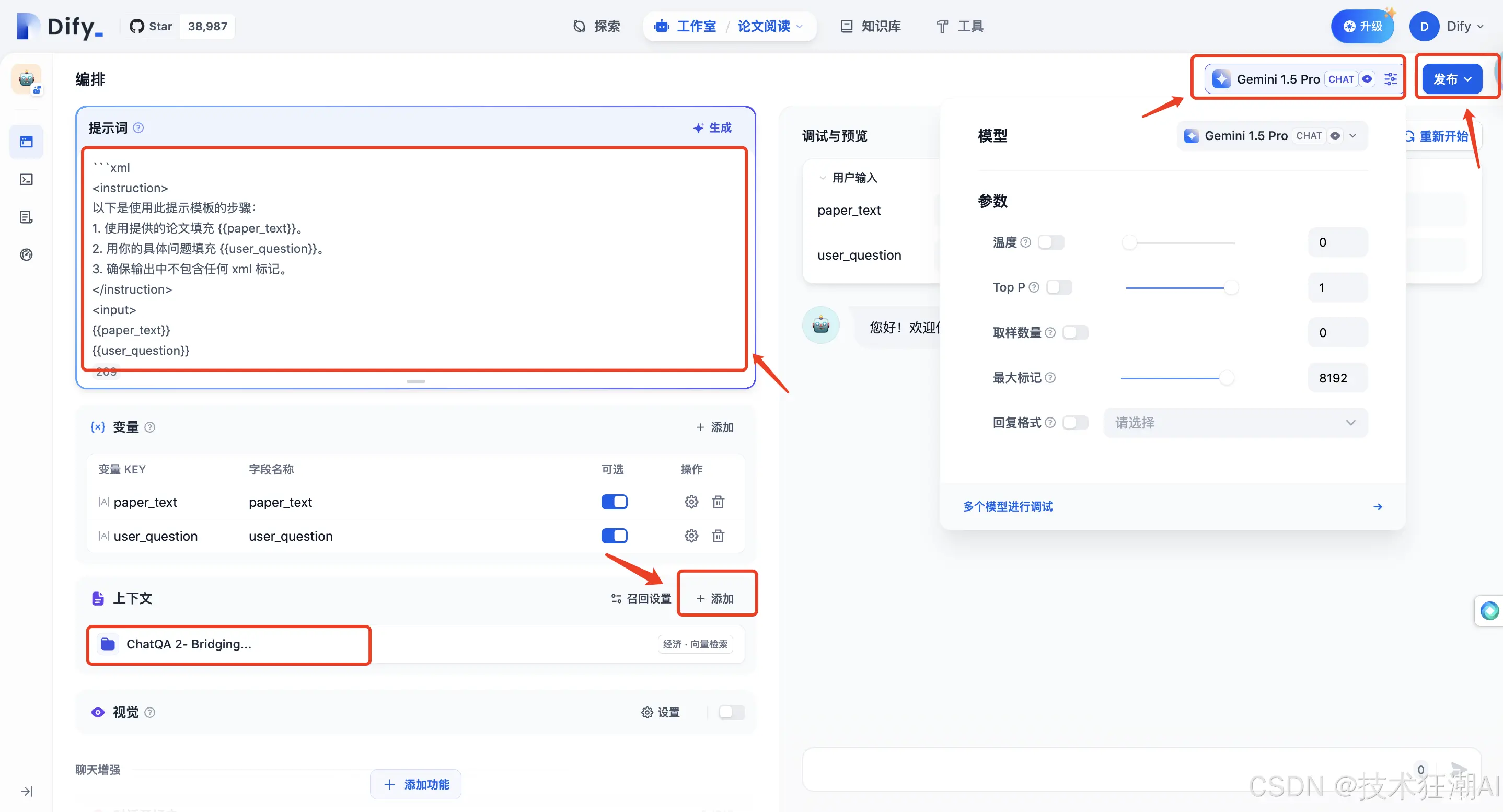
选择 「聊天助手」 类型进行测试,您可以随意命名。
点击「上下文」旁边的「添加」按钮,添加来自知识库的文件。您会在右上角看到一个本地 Ollama 模型正在运行,这表明 Dify 和 Ollama 已经成功集成。点击它可以选择其他模型或调整模型参数。
在左侧的「提示词」输入框中,您可以为聊天机器人编写提示。
设置好一切后,点击「发布」保存。

点击「发布」后,您可以直接点击「运行应用」来运行应用。

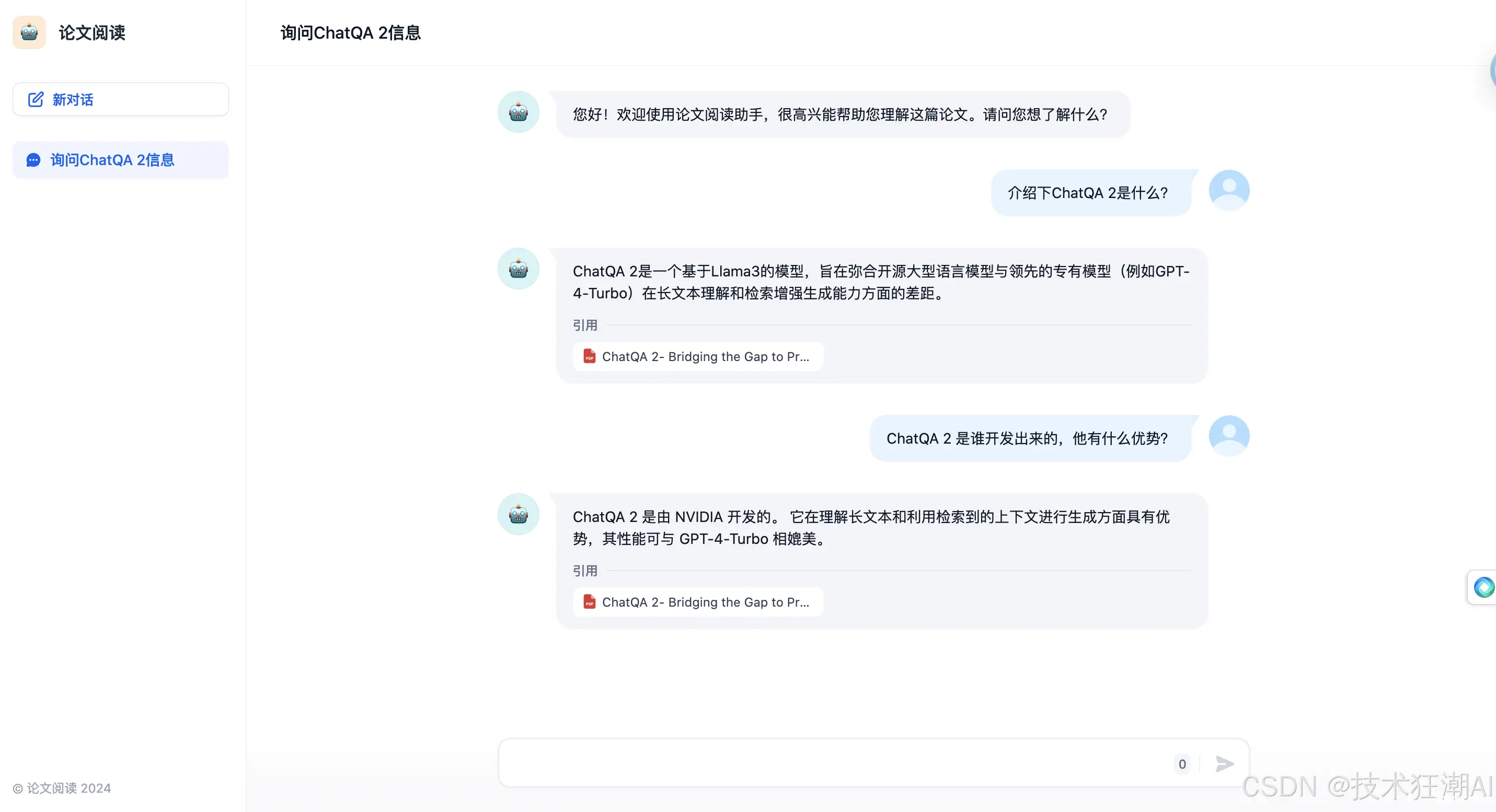
通过询问与论文中 ChatQA 2 相关的问题,我们可以看到机器人利用了知识库中的文档,并提供了准确的答案,证明了 RAG 的有效性。至此,一个简单的 RAG 聊天机器人就创建成功了。
十一、总结
本文全面介绍了 Dify,这是一个简化大型语言模型应用开发的开源平台。
Dify 的以下特性使其对开发人员和非技术用户都非常友好:
提示编排RAG 管道广泛的模型支持
Dify 将后端即服务与 LLMOps 相结合,使用户能够快速创建和部署 AI 应用,而无需进行大量编码。
Dify 的开源性和社区驱动的开发方式提供了灵活性和持续改进的可能性,使其成为任何希望在 AI 领域进行创新的人的宝贵工具。本指南可以让您自信地开始或加强使用 Dify 进行 AI 开发的旅程。
参考资料
[1]. Dify Cloud: https://cloud.dify.ai/
[2]. 官方文档:https://docs.dify.ai/guides/model-configuration/customizable-model
[3]. ConnectionError: HTTPConnectionPool(Host="Localhost", Port=11434): Max Retries Exceeded with Url: /Api/Generate/ (Caused by NewConnectionError(': Failed to Establish a New Connection: [Errno 111] Connection Refused')) · Issue #3200 · Ollama/Ollama. GitHub, github.com/ollama/ollama/issues/3200
[4]. Docker Desktop Distro 安装在升级到 4.32.0 版本后失败. Docker 社区论坛:forums.docker.com/t/docker-desktop-distro-installation-failed-after-upgradation-to-4–32–0/142393.
[5]. Langgenius/Dify. GitHub:github.com/langgenius/dify.
[6]. 问题 · Ollama/Ollama. GitHub:github.com/ollama/ollama/issues/.
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。