Vitis AI 进阶认知(量化过程详解)
hi94 2024-09-12 08:01:04 阅读 72
1. 简介
想象一下,你有一个非常聪明的机器人朋友,它可以帮你做很多事情,比如预测天气。但是,这个机器人的大脑(我们可以把它想象成一个神经网络模型)需要很多能量和空间来思考(也就是进行计算和存储数据)。现在,如果我们想让这个机器人更小巧,更省电,还能快速做出预测,我们就需要采用一些特殂的技巧。
这时,Vitis AI 量化器就像一个魔法工具,它可以帮助机器人的大脑变得更高效。原来,机器人的大脑用一种非常详细(32位浮点)的方式来记住信息,这种方式虽然精确,但是需要很多空间和能量。Vitis AI 量化器通过一种叫做“量化”的魔法,把这些详细的信息转换成更简单(8位整数)的形式。这样做虽然会让信息变得不那么精确,但是我们可以通过一些技巧,让机器人的预测能力几乎不受影响。
这个魔法包括几个步骤:
自定义操作检查:先检查一下机器人的大脑里是否有些特殊的思考方式是我们需要特别注意的。量化:用魔法把复杂的信息变成简单的形式。校准:调整一下这个简化后的大脑,确保它还能准确地做出预测。微调:进一步调整和优化,让机器人的大脑运行得更顺畅。模型转换:最后,把这个优化后的大脑转换成一种特殊的格式,这样它就可以更容易地被部署到不同的地方,比如小巧的设备上。
通过这个过程,机器人的大脑变得更小,更省电,而且还能快速做出准确的预测。这样,我们就可以把这个聪明的机器人带到更多的地方去,让它帮助更多的人。
不止 Vitis AI,PyTorch 与 TensorFlow 也原生支持量化,本文也将涉及。
2. 原理解释
2.1 实用方法参考
Practical Quantization in PyTorch | PyTorch Quantization is a cheap and easy way to make your DNN run faster and with lower memory requirements. PyTorch offers a few different approaches to quantize your model. In this blog post, we’ll lay a (quick) foundation of quantization in deep learning, and then take a look at how each technique looks like in practice. Finally we’ll end with recommendations from the literature for using quantization in your workflows.

https://pytorch.org/blog/quantization-in-practice/#calibration文章介绍在 PyTorch 中进行量化的实用方法。主要内容:
1. 量化基础:量化的基本概念和其在深度学习中的应用。
2. 映射函数和量化参数:将浮点数值映射到整数空间,以及相关的量化参数(如缩放因子和零点)。
3. 校准:详细说明了选择输入剪切范围的过程,即校准。PyTorch 默认使用记录运行时的最小值和最大值的方法。
4. 量化方案:比较了仿射量化和对称量化方案的优缺点。
2.2 校准
校准(Calibration)的目的是为了确定量化过程中所需的缩放因子(scale factor)和零点(zero point),以便将浮点数转换为整数表示。
在静态量化(Static Quantization)中,校准通常通过以下步骤进行:
1. 收集统计数据:将一部分训练数据(校准数据)输入到模型中,收集每一层的激活值的统计数据。这些统计数据用于确定每一层的动态范围。
2. 计算缩放因子和零点:根据收集到的统计数据,计算每一层的缩放因子和零点。常见的方法包括使用最小-最大范围(Min-Max Range)和直方图(Histogram)方法。
3. 应用量化参数:将计算得到的缩放因子和零点应用到模型中,使其能够在推理时使用整数运算。
2.3 剪枝
剪枝(Pruning) 是一种减少神经网络模型复杂度的技术。它的主要目的是通过移除对模型预测影响较小的参数(如权重和神经元),来简化模型结构。以下是剪枝的一些关键点:
1. 移除不重要的参数:在训练过程中,有些参数对模型的预测结果影响很小。剪枝通过识别并移除这些不重要的参数,来减少模型的复杂度。
2. 保持模型大小和延迟:尽管剪枝移除了部分参数,剪枝后的模型在磁盘上的存储大小和运行时的延迟通常保持不变。这是因为剪枝主要是优化模型的内部结构,而不是改变模型的整体架构。
3. 提高压缩效率:剪枝后的模型可以更有效地进行压缩。这意味着在传输和存储模型时,可以减少所需的带宽和存储空间。
4. 减少下载大小:由于剪枝后的模型更容易压缩,因此在下载模型时,所需的下载大小会减少。这对于在带宽有限的环境中部署模型非常有用。
2.4 静态量化
PyTorch中,称为静态量化(static quantization)(权重量化、激活量化、训练后需要校准)
Tensor Flow中,称为训练后整数量化(Post-training integer quantization)(是一种将 32 位浮点数(例如权重和激活输出)转换为最接近的 8 位定点数的优化策略。)
2.5 动态量化
PyTorch中,称为动态量化(dynamic quantization)(通过以浮点形式读取/存储的激活进行量化的权重并进行量化以进行计算)
Tensor Flow中,称为训练后动态范围量化(Post-training dynamic range quantization)(权重提前量化,但激活在推理过程中动态量化。)
2.6 量化感知训练
量化感知训练(QAT,Quantization-Aware Training)是一种特殊的神经网络训练方法,它在训练过程中就考虑到了模型最终会被量化(即权重和激活值会被转换成较低精度格式,如8位整数)的事实。通过这种方式,QAT旨在训练出一个在量化后仍能保持高性能的模型。关键点:
1. 在传统训练过程中,模型通常在浮点数(如32位浮点数)环境下进行训练和优化。然而,当模型被量化(为了部署在资源受限的设备上)时,模型的性能可能会因为精度损失而下降。为了缓解这个问题,QAT采用了一种在训练过程中就模拟量化效果的方法。
2. 模拟量化:在训练过程中,QAT通过在前向传播和反向传播时模拟权重和激活值的量化效果,使模型“意识到”其将在低精度环境中运行。这意味着模型的训练不仅要考虑如何最小化误差,还要学会在量化带来的限制条件下保持性能。
3. 微调和优化:通过这种训练方式,模型可以在量化的约束下学习到更鲁棒的特征表示。此外,训练过程中还可以对量化操作进行微调和优化,比如调整量化参数(比如量化的比例因子),以进一步减小量化带来的误差。
4. 减少性能损失:最终,通过QAT训练的模型在被量化到低精度格式后,其性能损失会比传统训练后直接量化的模型小很多。这意味着可以在保持较高预测精度的同时,享受量化带来的好处(如模型尺寸更小,推理速度更快,功耗更低)。
3. Vitis AI 量化流程
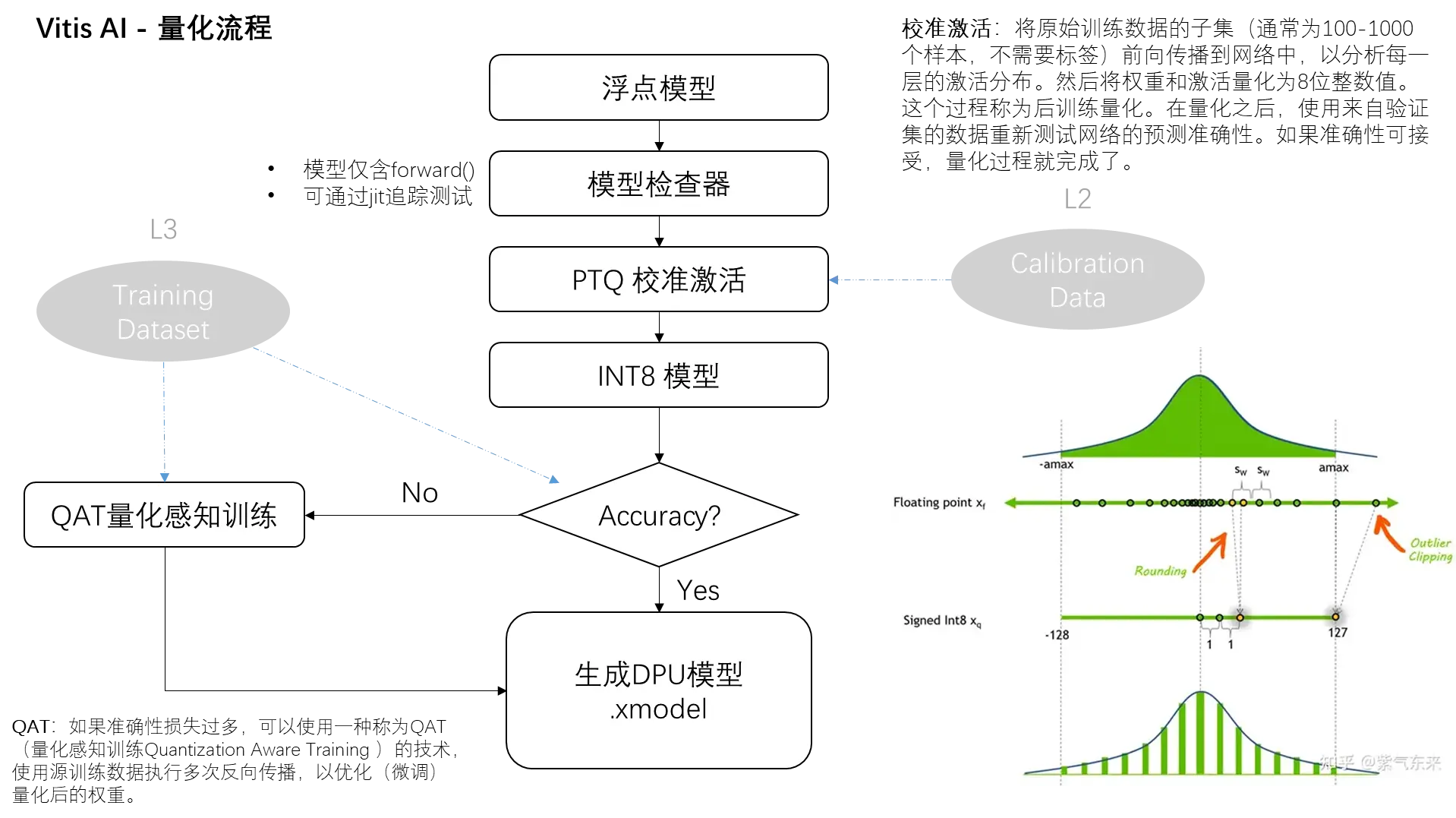
3.1 校准激活
Vitis AI 的校准激活过程包括:
1. 选择数据样本:从原始的训练数据中挑选出一个子集,包含100到1000个样本即可,而且不需要样本的标签(也就是说,我们不需要知道这些数据的正确答案是什么)。这个子集的目的是帮助我们理解模型在处理不同数据时的行为模式。
2. 前向传播:将这个数据子集通过神经网络进行前向传播。
3. 分析激活分布:当数据通过网络前向传播时,工具会分析网络中每一层的“激活分布”。激活分布基本上是指,在数据通过网络层时,神经元输出值的分布情况。
4. 量化权重和激活:有了关于激活分布的信息,工具就可以开始将权重和激活值从32位浮点数转换为8位整数值,即量化。
3.2 量化校准配置
3.2.1 配置文件及说明
量化校准配置文件的目录在 config_file = "./configs/mix_precision_config.json"
| 配置名 | 解释 | 选项 |
| convert_relu6_to_relu | 是否将ReLU6转换为ReLU | true、false |
| include_cle | 是否使用跨层均衡(cross layer equalization) | true、false |
| include_bias_corr | 是否使用偏差校正 | true、false |
| keep_first_last_layer_accuracy | 是否跳过对第一层和最后一层进行量化(未启用) | FALSE |
| keep_add_layer_accuracy | 是否跳过对"add"层进行量化(未启用) | FALSE |
| target_device | 部署量化模型的设备 | DPU、CPU、GPU |
| quantizable_data_type | 模型中要进行量化的张量类型 | |
| datatype | 用于量化的数据类型 | int、bfloat16、float16、float32 |
| bit_width | 用于量化的比特宽度 | |
| method | 用于校准量化的方法 | maxmin、percentile、entropy、mse、diffs |
| round_mode | 量化过程中的舍入方法 | half_even、half_up、half_down、std_round |
| symmetry | 是否使用对称量化 | true、false |
| per_channel | 是否使用通道级别的量化 | true、false |
| signed | 是否使用有符号量化 | true、false |
| narrow_range | 是否对有符号量化使用对称整数范围 | true、false |
| scale_type | 量化过程中使用的尺度类型 | float、poweroftwo |
| calib_statistic_method | 如果使用多批次数据获得不同的尺度,用于选择一个最优尺度的方法 | modal、max、mean、median |
3.2.2 全局量化设置
1. convert_relu6_to_relu: 是否将 relu6 转换为 relu。relu6 激活函数的输出范围是[0, 6],而 relu 的输出范围是[0, +∞)。relu 比 relu6 有更高的模型精度。
2. include_cle: 是否使用跨层均衡(cross layer equalization)。跨层均衡在保持模型输出不变的情况下,调整相邻层之间的权重和偏置,使得量化后的模型更加稳定和鲁棒。
3. include_bias_corr: 是否使用偏置校正(bias correction)。偏置校正根据量化前后的权重和激活值的变化,对偏置进行微调,以减少量化误差,提高模型精度。
4. keep_first_last_layer_accuracy: 否保持第一层和最后一层的精度。第一层和最后一层通常对模型性能影响较大,如果在量化过程中损失了精度,可能会导致模型输出质量下降。这个配置可以选择是否对第一层和最后一层使用更高的位宽或者更精细的量化方法,以保持它们的精度。
5. keep_add_layer_accuracy: 否保持 add 层的精度。add 层是指在残差网络(ResNet)等模型中,将两个分支相加的层。这些层通常对模型性能影响较大,如果在量化过程中损失了精度,可能会导致模型输出质量下降。这个配置可以选择是否对 add 层使用更高的位宽或者更精细的量化方法,以保持它们的精度。
6. target_device: 这个配置是用来指定部署量化后模型的目标设备,选项有DPU, CPU, GPU。
7. quantizable_data_type: 这个配置是用来指定需要被量化的张量类型。比如"input", "weights", "bias", "activation”。
3.2.3 局部量化设置
1. bit_width: 指定量化时使用的位宽,KV260 中的 DPU 使用 8bit 量化。
2. method: 指定校准过程中使用的方法:maxmin, percentile, entropy, mse, diffs。
MaxMin:使用校准数据的最大值和最小值来确定范围。这是最简单的方法,但容易受到异常值的影响;Percentile:基于数据的分位数来确定范围,通常使用 99.9% 分位数来避免异常值的影响;Entropy:使用信息熵(如 KL 散度)来最小化原始浮点值和量化值之间的信息损失。这种方法可以最大化保留信息,但计算复杂度较高;MSE(Mean Squared Error):通过最小化原始值和量化值之间的均方误差来确定范围。这种方法在保留模型精度方面表现良好;Diffs:基于数据的差异来确定范围,具体实现可能因工具而异;
3. round_mode: 指定量化过程中使用的舍入方法:half_even, half_up, half_down, std_round。舍入方法是指在将浮点数转换为整数时,如何处理小数部分。不同的舍入方法有不同的效果:
half_even 四舍六入五取偶,可以减少舍入误差的累积half_up 远离零的四舍五入,可以保持数值的大小half_down 五舍六入,可以减少数值的大小std_round 标准的四舍五入,可以保持数值的大小
4. symmetry: 是否使用对称量化。对称量化是指在量化过程中,使用相同的比例因子和零点来表示正负数值。对称量化可以简化计算过程,提高运算效率。DPU 应当使用对称量化。
5. per_channel: 是否使用逐通道量化。启用后,将对张量的每个维度(通道)采用不同的参数进行量化,而不是对所有张量采用相同的方式和相同的参数进行量化。这可以减少将张量转换为量化值时的误差,因为异常值只会影响它所在的通道,而不是整个张量。
6. signed: 是否使用有符号量化。
7. narrow_range: 是否使用对称整数范围来表示有符号量化。在8位有符号量化中:
使用对称整数范围,则表示范围为[-127, 127]不使用对称整数范围,则表示范围为[-128, 127]
8. scale_type: 指定在量化过程中使用的比例因子类型:float, power_of_two。
float,使用浮点数来表示比例因子,可以更精确地表示比例因子,提高模型精度;power_of_two,使用2的幂次方来表示比例因子,可以更简单地计算比例因子,提高运算效率。
9. calib_statistic_method: 如果多批次数据的分布不一致,那么需要用一种统计方法来确定最优的比例。不同的比例会影响量化后的模型精度和性能。这里提供了四种方法:
modal(模态):选择出现次数最多的比例作为最优比例。max(最大值):选择所有批次中最大的比例作为最优比例。mean(平均值):计算所有批次的比例的平均值作为最优比例。median(中值):排序所有批次的比例,选择中间位置的比例作为最优比例。
3.3 quantization 函数
使用 PyTorch 框架和 Vitis AI 量化工具(通过 pytorch_nndct 模块)的一个示例:
<code># 创建量化器对象,并获取量化模型
from pytorch_nndct.apis import torch_quantizer
quantizer = torch_quantizer(
quant_mode, model, (dummy_input), device=device, quant_config_file=config_file, target=target)
quant_model = quantizer.quant_model
loss_fn = torch.nn.CrossEntropyLoss().to(device)
val_loader, _ = load_data(…)
if finetune == True:
ft_loader, _ = load_data(…)
if quant_mode == 'calib':
quantizer.fast_finetune(evaluate, (quant_model, ft_loader, loss_fn))
elif quant_mode == 'test':
quantizer.load_ft_param()
acc1_gen, acc5_gen, loss_gen = evaluate(quant_model, val_loader, loss_fn)
if quant_mode == 'calib':
quantizer.export_quant_config()
if deploy:
quantizer.export_torch_script()
quantizer.export_onnx_model()
quantizer.export_xmodel()
代码功能:
1. 创建量化器对象:使用 torch_quantizer 函数创建一个量化器对象,这个对象用于管理模型的量化过程。这里需要指定量化模式(quant_mode),可以是 calib(校函量化模式)或 test(测试量化模型性能模式),模型本身,一个虚拟输入(dummy_input)用于模型推理,以及其他配置如设备(device),量化配置文件(quant_config_file)和目标平台(target)。
2. 获取量化模型:通过量化器对象的 quant_model 属性获取量化后的模型。这个模型将用于后续的校准、微调和评估。
3. 加载数据:加载验证数据集(val_loader),如果需要微调(finetune 为 True),也会加载微调数据集(ft_loader)。
4. 微调和校准:如果设置了微调,根据量化模式执行相应的操作。在 calib 模式下,使用fast_finetune 方法进行快速微调,以优化模型的量化参数;在 test 模式下,使用 load_ft_param 方法加载已经微调过的参数。
5. 评估量化模型性能:使用 evaluate 函数评估量化模型在验证数据集上的性能,包括准确率(acc1_gen 和 acc5_gen)和损失(loss_gen)。
6. 导出量化配置和模型:如果是 calib 模式,使用 export_quant_config 方法导出量化配置。此外,如果设置了部署(deploy为True),则会导出用于部署的模型:
Torch Script(export_torch_script)ONNX模型(export_onnx_model)Xilinx特定的xmodel(export_xmodel)
4. PyTorch 量化流程
4.1 PyTorch
Quantization — PyTorch 2.4 documentation
https://pytorch.org/docs/stable/quantization.html
PyTorch 提供三种量化模式:
Eager Mode Quantization,Eager 模式量化,用户需要进行融合并手动指定量化和反量化发生的位置,而且它仅支持模块而不支持函数。FX Graph Mode Quantization,FX 图模式量化,自动化量化工作流程,但需要模型兼容 FX 图模式量化。PyTorch 2 Export Quantization,PyTorch 2 导出量化,新的全图模式量化工作流程,提供更好的程序捕获解决方案。
建议首先使用 PyTorch 2 Export Quantization,如果效果不好,用户可以尝试 eager 模式量化。
4.2 量化过程
<code>float_model(Python) Example Input
\ /
\ /
—-------------------------------------------------------code>
| export |
—-------------------------------------------------------
|
FX Graph in ATen Backend Specific Quantizer
| /
—--------------------------------------------------------
| prepare_pt2e |
—--------------------------------------------------------
|
Calibrate/Train
|
—--------------------------------------------------------
| convert_pt2e |
—--------------------------------------------------------
|
Quantized Model
|
—--------------------------------------------------------
| Lowering |
—--------------------------------------------------------
|
Executorch, Inductor or <Other Backends>
示例代码:
import torch
from torch._export import capture_pre_autograd_graph
# 构建示例模型
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(5, 10)
def forward(self, x):
return self.linear(x)
example_inputs = (torch.randn(1, 5),)
m = M().eval()
# 第1步:程序捕获
# 注意:这个API将来会更新为torch.export API,但捕获的结果应该基本保持不变
m = capture_pre_autograd_graph(m, *example_inputs)
# 我们得到了一个包含aten操作的模型
# 第2步:量化
from torch.ao.quantization.quantize_pt2e import (
prepare_pt2e,
convert_pt2e,
)
from torch.ao.quantization.quantizer import (
XNNPACKQuantizer,
get_symmetric_quantization_config,
)
# 后端开发者将编写自己的量化器,并暴露方法,允许用户表达他们希望如何量化模型
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
m = prepare_pt2e(m, quantizer)
# 省略校准
m = convert_pt2e(m)
# 我们有了一个在可能的情况下使用整数计算的包含aten操作的模型
5. TensorFlow 量化流程
Post-training quantization
https://www.tensorflow.org/lite/performance/post_training_quantization这篇文章介绍了 TensorFlow Lite 中的后训练量化技术。主要内容包括:
动态范围量化:这种方法在转换时将权重从浮点量化为整数,提供 8 位精度,减少内存使用并加快计算速度。全整数量化:这种方法需要一个代表性数据集来校准模型中的所有浮点张量,进一步减少延迟和内存使用,并与仅支持整数的硬件设备兼容。Float16 量化:这种方法将模型大小减半,并提供 GPU 加速。
Quantization aware training
https://www.tensorflow.org/model_optimization/guide/quantization/training
这篇文章介绍了 TensorFlow 中的量化感知训练(Quantization Aware Training, QAT)。
概述:QAT 通过在训练期间模拟量化误差,创建一个在推理时实际量化的模型。部署优势:量化模型在部署时可以显著减少模型大小(通常缩小 4 倍)和推理延迟(通常提高 1.5 到 4 倍)。API 兼容性:支持 Keras 的 Sequential 和 Functional 模型,适用于 TensorFlow 2.x 版本。硬件加速:默认配置与 EdgeTPU、NNAPI 和 TFLite 等硬件加速器兼容。
6. 总结
在当今技术快速发展的时代,我们追求的不仅是智能设备的高性能,同时也强调其能效和便携性。Vitis AI量化器便是在这样的背景下应运而生的一个工具,它通过将神经网络模型的数据精度从32位浮点数降低到8位整数,极大地缩减了模型的体积和计算需求,而通过精心设计的校准和微调过程,又能确保模型的预测准确性基本不受影响。这一过程不仅包括了校准激活、量化感知训练等关键步骤,还提供了详细的量化校准配置和实用的量化函数,以适应不同的部署需求。通过这种方式,Vitis AI量化器使得深度学习模型能够更加轻松地被部署到资源受限的设备上,无论是在移动设备、嵌入式系统还是其他平台,都能够实现快速、高效的智能计算,为用户带来更加丰富和流畅的体验。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。