python进阶——人工智能视觉识别
淼学派对 2024-10-03 09:31:01 阅读 92
大家好,我是csdn的博主:lqj_本人
这是我的个人博客主页:lqj_本人的博客_CSDN博客-微信小程序,前端,vue领域博主lqj_本人擅长微信小程序,前端,vue,等方面的知识
https://blog.csdn.net/lbcyllqj?spm=1000.2115.3001.5343
哔哩哔哩欢迎关注:小淼前端
小淼前端的个人空间_哔哩哔哩_bilibili
本篇文章主要讲述python的安装以及pycharm解释器的配置流程,本篇文章已经成功收录到我们python专栏中:https://blog.csdn.net/lbcyllqj/category_12089557.html
https://blog.csdn.net/lbcyllqj/category_12089557.html


前言
python在人工智能方面可以毫不客气的说,比其他的所有语言都要有优势,因为python的背后有一个非常强大的资源库来支撑着python运作。
opencv库
opencv是最经典的python视觉库,它里面包含了很多种视觉的识别类型供开发者们使用。
opencv库的下载
我们可以在我们的pycharm里面输入以下代码进行下载,但这里我们下载的是阉割版的。
<code>pip install opencv-python
当我们的pycharm下载完成之后,我们呢还需要在opencv的官网进行下载:
首页 - OpenCV
然后我们选择(如下图所示):
进入之后,我们就可以看到opencv相对应的版本了:
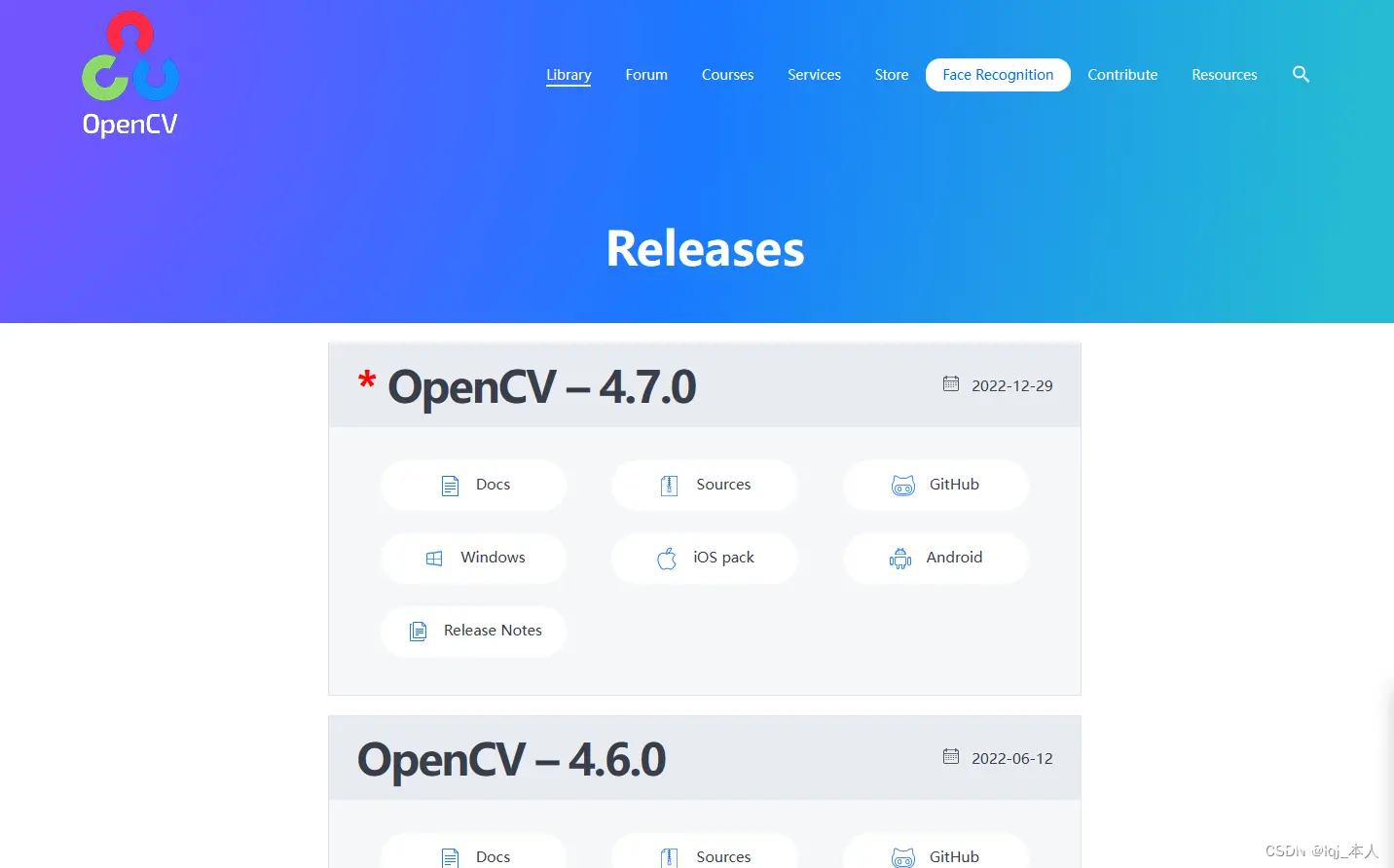
然后,我们选择自己使用的系统进行下载并安装即可(仅安装即可,opencv不用环境配置!只需要记住安装在哪里,当我们使用的时候直接调取我们的安装目录就可以!)
当安装完成之后,我们就可以看到安装路径下的这些文件:
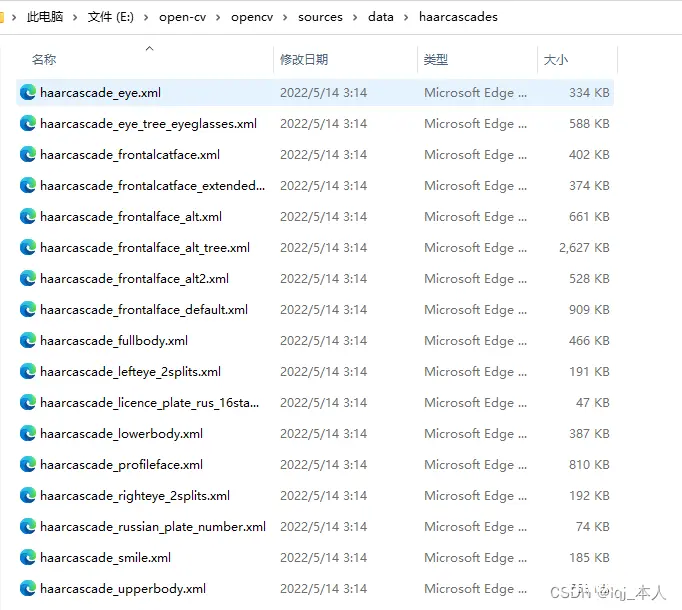
里面包含眼睛识别,面部识别等一些强大的识别算法!
人脸检测报警系统(可用于:家用监控;人脸门禁;人脸打卡签到等)
这里我将本功能分为了三个py文件来展开描述:
抓取人脸功能模块
首先,导入cv库
<code>import cv2
然后调取我们的摄像头(0代表本机摄像头,其他代表外接摄像头)
cap = cv2.VideoCapture(0)
用while来判断是否为开启状态:
while(cap.isOpened()):
得到每一帧的图片进行赋值:
ret_flag,Vshow = cap.read()
调用控制键盘函数,控制判断按键:
k = cv2.waitKey(1) & 0xFF
使用imshow函数显示拍摄图像:
cv2.imshow('ceshi',Vshow)
键盘监听,按s键进行保存:
if k == ord('s'):
保存拍摄图像的格式,打印提示文字:
cv2.imwrite('E:/tupian/'+str(num)+'.name'+'.jpg',Vshow)
print('保存成功'+str(num)+".jpg")
print("-------------------------")
num += 1
释放摄像头与内存:
#释放摄像头
cap.release()
#释放内存
cv2.destroyAllWindows()
完整代码:
import cv2
cap = cv2.VideoCapture(0)
falg = 1
num = 1
while(cap.isOpened()):#检测是否在开启状态
ret_flag,Vshow = cap.read()#得到每一帧的图像
k = cv2.waitKey(1) & 0xFF#判断按键
cv2.imshow('ceshi',Vshow)#显示图像
if k == ord('s'):#按s键保存
cv2.imwrite('E:/tupian/'+str(num)+'.name'+'.jpg',Vshow)
print('保存成功'+str(num)+".jpg")
print("-------------------------")
num += 1
elif k == ord(' '):#退出
break
#释放摄像头
cap.release()
#释放内存
cv2.destroyAllWindows()
录入人脸功能模块
在写这个功能模块之前,我们要在pycharm中或cmd中的本文件根目录下使用命令行,安装face模块使用函数:
pip install opencv-contrib-python
导入第三方库:
import os
import cv2
from PIL import Image
import numpy as np
存储人脸数据:
facesSamples=[]
存储姓名数据:
ids=[]
存储图片信息:
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
加载分类器(就是我们上面讲到的在opencv官网下载的库,我们只需要调取安装目录就可以):
face_detector = cv2.CascadeClassifier('E:/open-cv/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml')
遍历列表中的图片:
for imagePath in imagePaths:
将打开的图片灰度化:
PIL_img = Image.open(imagePath).convert('L')
将图片转化为数组:
img_numpy = np.array(PIL_img,'uint8')
获取图片人脸特征:
faces = face_detector.detectMultiScale(img_numpy)
获取每一张拍摄图片的id与姓名:
id = int(os.path.split(imagePath)[1].split('.')[0])
做判断,预防拍摄无面容图片:
for x,y,w,h in faces:
ids.append(id)
facesSamples.append(img_numpy[y:y+h,x:x+w])
打印面部特征与id,并返回数据:
print('id',id)
print('fs:',facesSamples)
return facesSamples,ids
调用图片路径(有第一步抓取人脸后按s键保存到'E:/tupian/'路径下的图片):
path = 'E:/tupian/'
获取图像数组和id标签数组和姓名:
faces,ids=getImageAndLabels(path)
加载识别器:
recognizer = cv2.face.LBPHFaceRecognizer_create()
训练数据:
recognizer.train(faces,np.array(ids))
保存面部特征到文件夹(创建一个文件夹,用于存放读取的面部信息):
recognizer.write('tupian/tupian.yml')
完整代码:
import os
import cv2
from PIL import Image
import numpy as np
def getImageAndLabels(path):
#储存人脸数据
facesSamples=[]
#储存姓名数据
ids=[]
#储存图片信息
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#加载分类器
face_detector = cv2.CascadeClassifier('E:/open-cv/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml')
#遍历列表中的图片
for imagePath in imagePaths:
#打开图片,灰度化PIL有九种不同的模式:1,L,P,RGB,RGBA,CMYK,YCbCr,I,F
PIL_img = Image.open(imagePath).convert('L')
#将图像转化为数组,以黑白深浅
img_numpy = np.array(PIL_img,'uint8')
#获取图片人脸特征
faces = face_detector.detectMultiScale(img_numpy)
#获取每一张图片的id和姓名
id = int(os.path.split(imagePath)[1].split('.')[0])
#预防无面容照片
for x,y,w,h in faces:
ids.append(id)
facesSamples.append(img_numpy[y:y+h,x:x+w])
#打印面部特征和id
print('id',id)
print('fs:',facesSamples)
return facesSamples,ids
if __name__ == '__main__':
#图片路径
path = 'E:/tupian/'
#获取图像数组和id标签数组和姓名
faces,ids=getImageAndLabels(path)
#加载识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
#训练
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('tupian/tupian.yml')
人脸识别功能模块
导入第三方库:
import cv2
import os
加载训练过的数据文件:
recogizer = cv2.face.LBPHFaceRecognizer_create()
加载保存过的面部信息:
recogizer.read('tupian/tupian.yml')
定义名称数组:
names=[]
识别全局变量定义:
warningtime = 0
识别视频中人脸模块:
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度
face_detector=cv2.CascadeClassifier('E:/open-cv/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml')
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80:
global warningtime
warningtime += 1
if warningtime > 100:
# warning()
warningtime = 0
cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv2.imshow('result',img)
导入存储的图片名字标签:
def name():
path = 'E:/tupian/'
# names = []
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
加载监控或已保存下来的视频:
cap=cv2.VideoCapture('1.mp4')
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv2.waitKey(10):
break
释放内存与视频:
cv2.destroyAllWindows()
cap.release()
完整代码:
import cv2
import os
#加载训练数据文件
recogizer = cv2.face.LBPHFaceRecognizer_create()
#加载数据
recogizer.read('tupian/tupian.yml')
#名称
names=[]
#报警全局变量
warningtime = 0
#准备识别的图片
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度
face_detector=cv2.CascadeClassifier('E:/open-cv/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml')
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80:
global warningtime
warningtime += 1
if warningtime > 100:
# warning()
warningtime = 0
cv2.putText(img, 'unkonw', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv2.imshow('result',img)
#名字标签
def name():
path = 'E:/tupian/'
# names = []
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
#加载视频
cap=cv2.VideoCapture('1.mp4')
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv2.waitKey(10):
break
#释放内存+视频
cv2.destroyAllWindows()
cap.release()
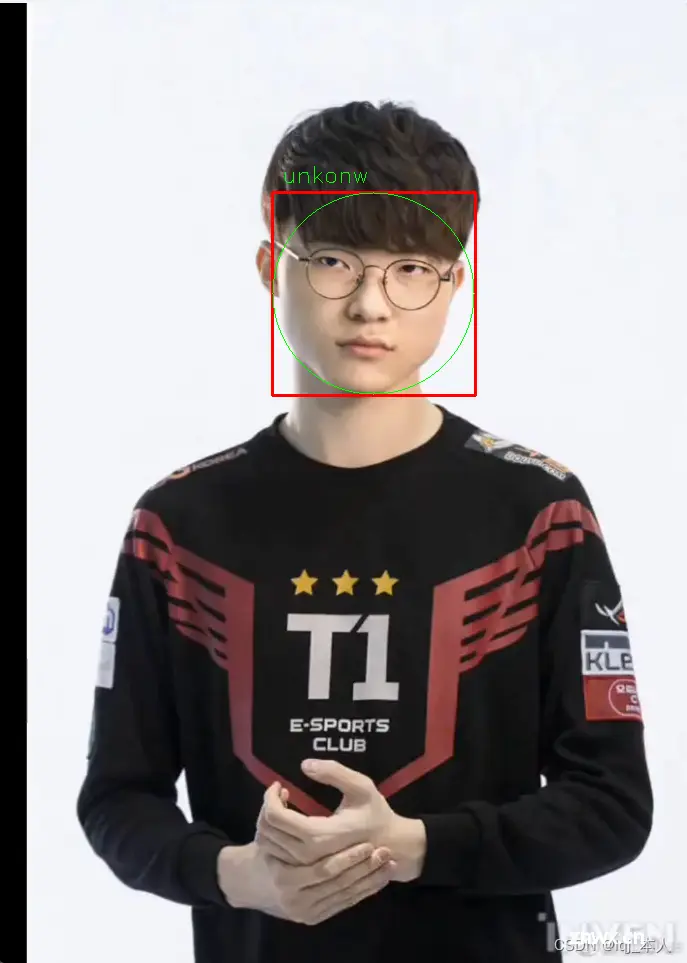
最终显示效果:
录入过的面部信息就会显示录入的姓名(如下面的LQJ),未录入过的面部信息就会显示unkonw(不知道的状态)。

上一篇: valorant(无畏契约)Ai瞄准、cf(穿越火线)Ai瞄准以及各类的fps游戏Ai识别所使用的通用技术分享(python版本)
下一篇: 2024 年最值得尝试的 8 个 AI 开源大模型
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。