小模型竞争开始:Mistral AI与NVIDIA联手推出Mistral NeMo模型
CodeMicheal 2024-08-06 12:31:02 阅读 77
在最近,大模型的发展如期进行时,在原先比较小众的小模型领域,各家AI大厂开始了竞争,这场竞争由OpenAI发起,他们推出了GPT-4o mini来代替GPT-3.5模型,让GPT-3系列全面退役(期待开源);接下来hugging face又推出了自家的SmoLLM,在接下来,就是本文章的主角——Mistral-NeMo的出场。
基础介绍
这次Mistral和NVIDIA联合推出的Mistral- NeMo拥有120亿的训练参数和128K的上下文窗口,所以它的推理、世界知识和编码准确性在其尺寸类别中是最先进的。而且Mistral-NeMo还是基于标准架构的,所以Mistral-NeMo的兼容性很高,而且可以在任何使用Mistral-7B的系统中置换。
下表比较了 Mistral NeMo 基础模型与两个最近的开源预训练模型 Gemma 2 9B 和 Llama 3 8B 的准确性。
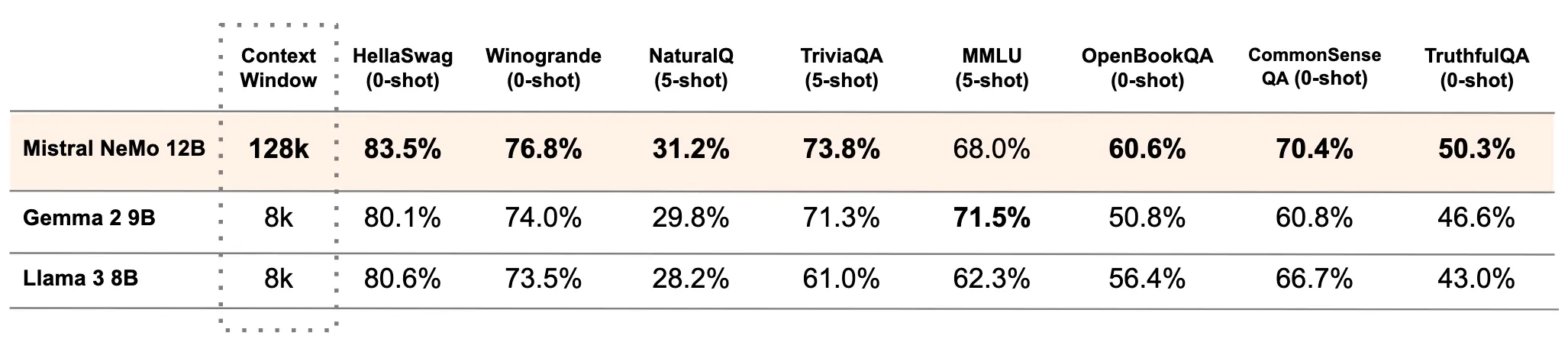
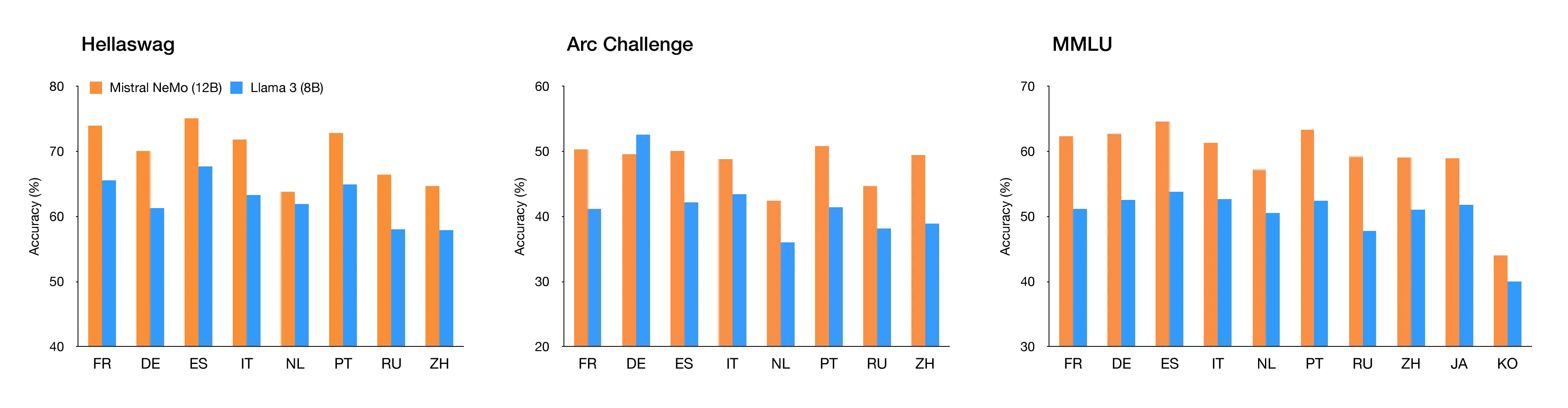
最新的Mistral NeMo还支持全球的多数语言,包括英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语,而且非常强大。
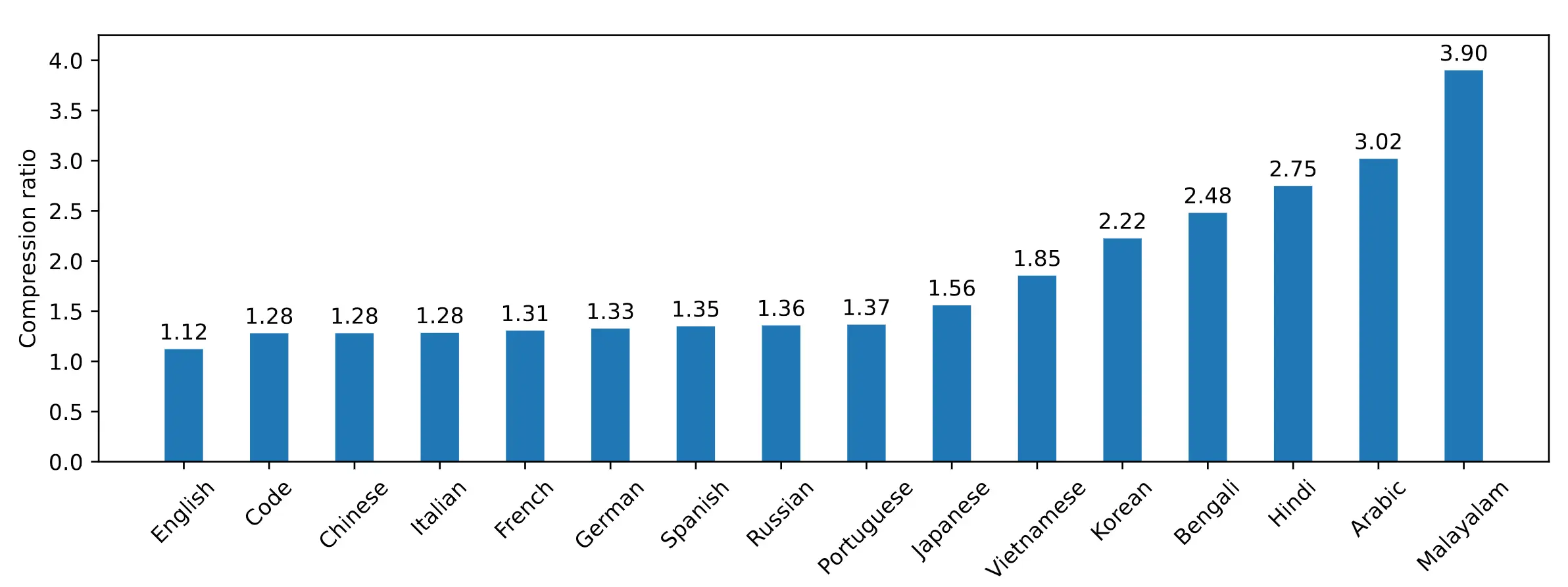
技术细节:Tekken,一个更高效的分词器
Mistral NeMo 使用基于 Tiktoken 的新分词器 Tekken,该分词器在 100 多种语言上进行了训练,并且比以前 Mistral 模型中使用的 SentencePiece 分词器更有效地压缩自然语言文本和源代码。特别是,它在压缩源代码(中文、意大利语、法语、德语、西班牙语和俄语)方面的效率提高了 ~30%。它在压缩韩语和阿拉伯语方面的效率也分别提高了 2 倍和 3 倍。与 Llama 3 分词器相比,Tekken 被证明更擅长压缩大约 85% 的所有语言的文本。
还记得上文:大模型集体翻车:大模型的推理原理 - yjhcode吗?更高效的分词器也是提高正确率的方法之一!
技术细节:指令微调

Mistral Nemo进行了高级微调和对齐阶段,所以它在遵循指令、推理和多回合对话以及生成代码方面都优于Llama 3 8B和Mistral 7B
部署:面向企业和个人
Mistral NeMo 在 Apache 2.0 许可下发布,该许可促进创新并支持更广泛的 AI 社区,是一个拥有 120 亿参数的模型。此外,该模型使用 FP8 数据格式进行模型推理,从而减小内存大小并加快部署速度,而不会降低准确性。
这意味着该模型可以更好地学习任务并更有效地处理各种场景,使其成为企业用例的理想选择。
Mistral NeMo 打包为 NVIDIA NIM 推理微服务,使用 NVIDIA TensorRT-LLM 引擎提供性能优化推理。
这种容器化格式允许在任何地方轻松部署,为各种应用程序提供更大的灵活性。
因此,模型可以在几分钟内部署到任何地方,而不是几天。
NIM 采用属于 NVIDIA AI Enterprise 的企业级软件,具有专用的功能分支、严格的验证流程以及企业级的安全性和支持。
它包括全面的支持、直接联系 NVIDIA AI 专家和定义的服务级别协议,可提供可靠且一致的性能。
开放模式许可证允许企业将 Mistral NeMo 无缝集成到商业应用程序中。
Mistral NeMo NIM 专为安装单个 NVIDIA L40S、NVIDIA GeForce RTX 4090 或 NVIDIA RTX 4500 GPU 的内存而设计,可提供高效率、低计算成本以及增强的安全性和隐私性。
也就是说,单张4090就可以跑(是训练,不是推理)!
高级模型开发和定制
Mistral AI 和 NVIDIA 工程师的综合专业知识优化了 Mistral NeMo 的训练和推理。
该模型采用 Mistral AI 的专业知识进行训练,尤其是在多语言、代码和多轮内容方面,受益于 NVIDIA 全栈的加速训练。
它旨在实现最佳性能,利用高效的模型并行技术、可扩展性和与 Megatron-LM 的混合精度。
该模型使用 NVIDIA NeMo 的一部分 Megatron-LM 进行训练,该 DGX Cloud 上有 3,072 个 H100 80GB Tensor Core GPU,由 NVIDIA AI 架构组成,包括加速计算、网络结构和软件,以提高训练效率。
可用性和部署
Mistral NeMo 可以灵活地在云、数据中心或 RTX 工作站等任何地方运行,随时准备彻底改变各种平台上的 AI 应用程序。
立即通过 ai.nvidia.com 体验 Mistral NeMo 作为 NVIDIA NIM,可下载的 NIM 即将推出。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。