AI模型:windows本地运行下载安装ollama运行llama3、llama2、Google CodeGemma、gemma等可离线运行数据模型【自留记录】
搬砖的前端 2024-06-20 08:01:02 阅读 89
AI模型:windows本地运行下载安装ollama运行llama3、llama2、Google CodeGemma、gemma等可离线运行数据模型【自留记录】
CodeGemma 没法直接运行,需要中间软件。下载安装ollama后,使用ollama运行CodeGemma等AI模型。
类似 前端本地需要安装 node.js 才可能跑vue、react项目
1、下载 ollama:
官网下载:https://ollama.com/download,很慢,原因不解释。
阿里云盘下载:https://www.alipan.com/s/jiwVVjc7eYb 提取码: ft90
百度云盘下载:https://pan.baidu.com/s/1o1OcY0FkycxMpZ7Ho8_5oA?pwd=8cft 提取码:8cft
2、安装
运行 OllamaSetup.exe ,安装过程不能选择自定义文件夹
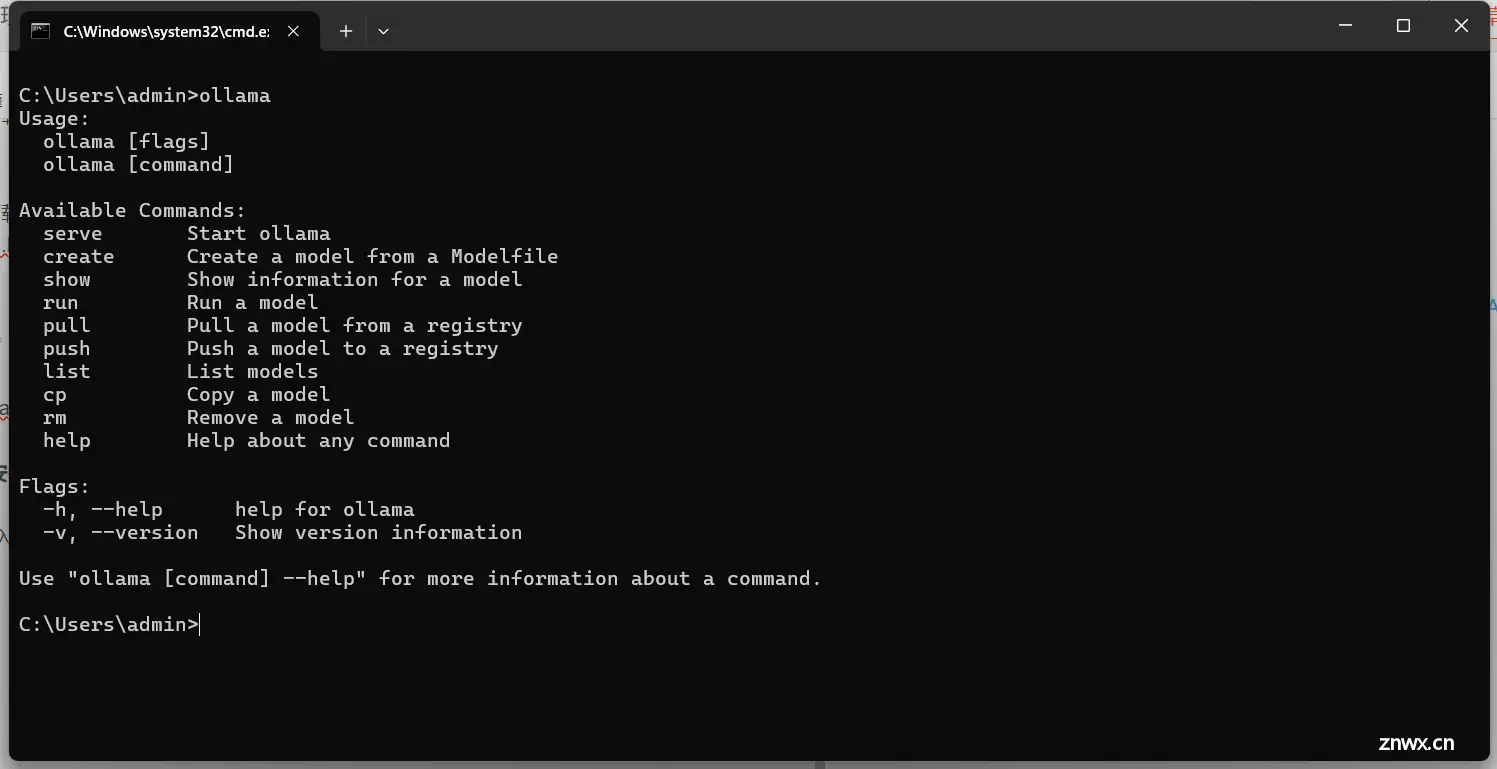
3、测试安装是否成功
win + R 输入 cmd ,回车输入:ollama
4、修改模型文件地址 (非必须)
ollama模型默认安装地址在C:\Users<用户名>.ollama
因为模型较大,所以我们需要在环境变量内设置模型的安装位置,如下进行设置
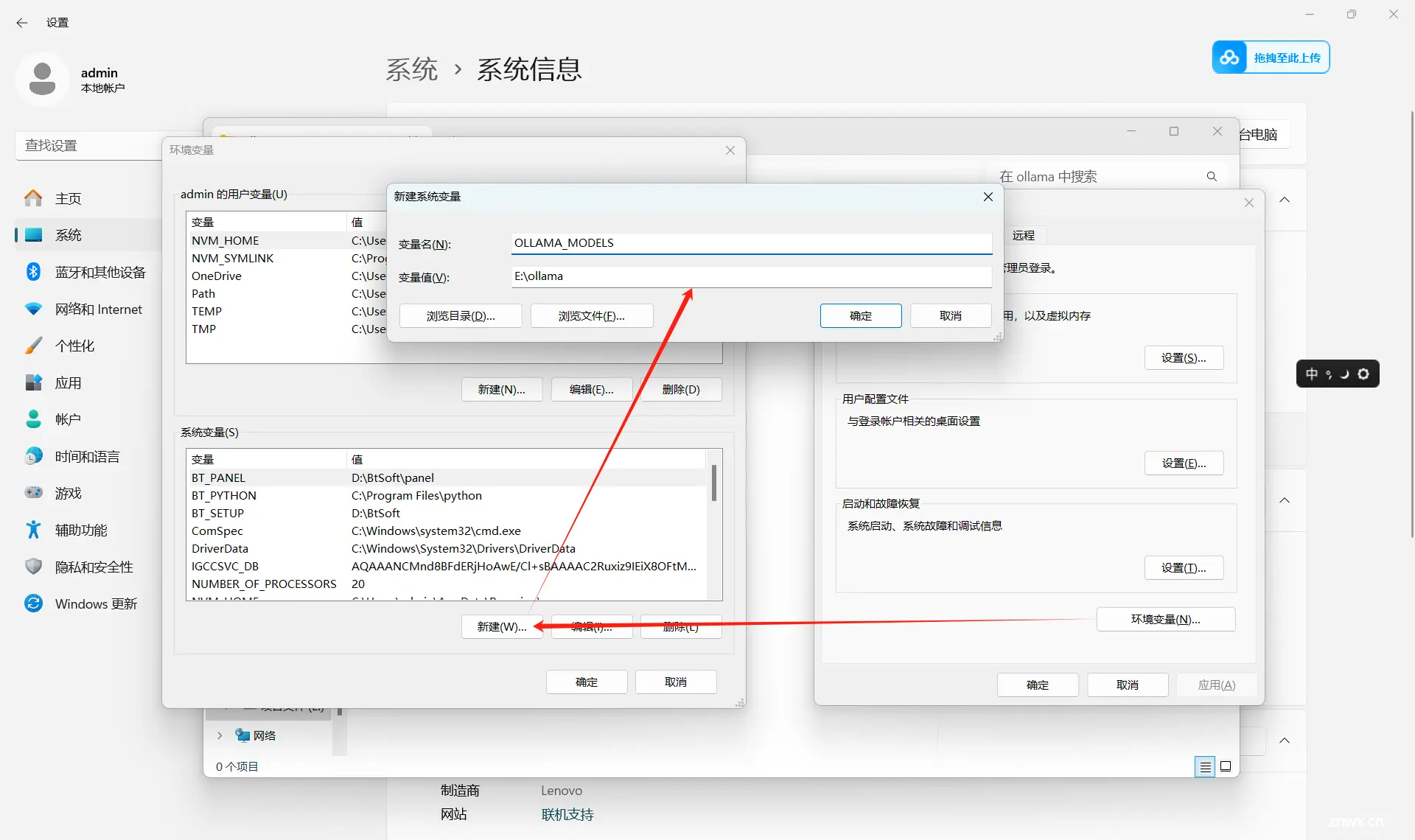
变量名: OLLAMA_MODELS
变量值: E:\ollama(根据自己打算存放的地址自行填写)
5、官网下载安装模型
本文依 codegemma为例,如果使用其他模型一样的操作。
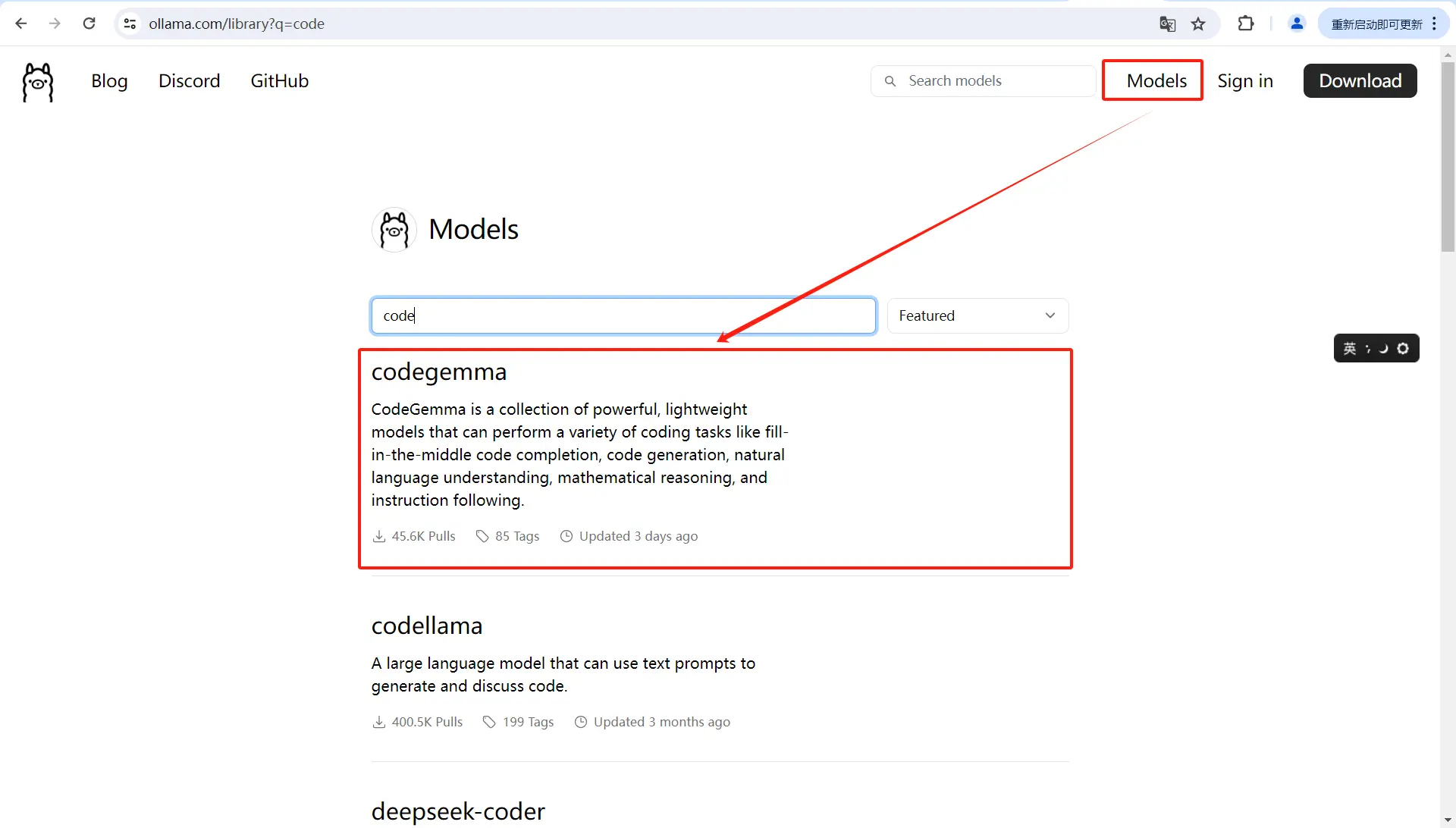
选择对应模型
2b: 最低配,有点SB。不智能,不推荐
命令:ollama run codegemma:2b
7b: 内存8G以上,建议16G电脑上这个版本更好一点,碾压2b版本。预计占用1.5G内存,CPU要求高,低压U估计压不住,时间太长
命令:ollama run codegemma:7b
7b全量: 说是更智能,没体验。建议16G或者32G电脑上这个版本,cpu要求更高
命令:ollama run codegemma:7b-code-fp16
带instruct: 能够理解自然语言输入,并根据指令生成相应的代码。
带code: 预训练的模型,专门用于代码补全和根据代码前缀和/或后缀生成代码。
带2b: 最新的预训练模型,提供了最多两倍更快的代码自动补全功能。它的目标是提高代码补全的速度和效率。就是回复的有点拉胯。
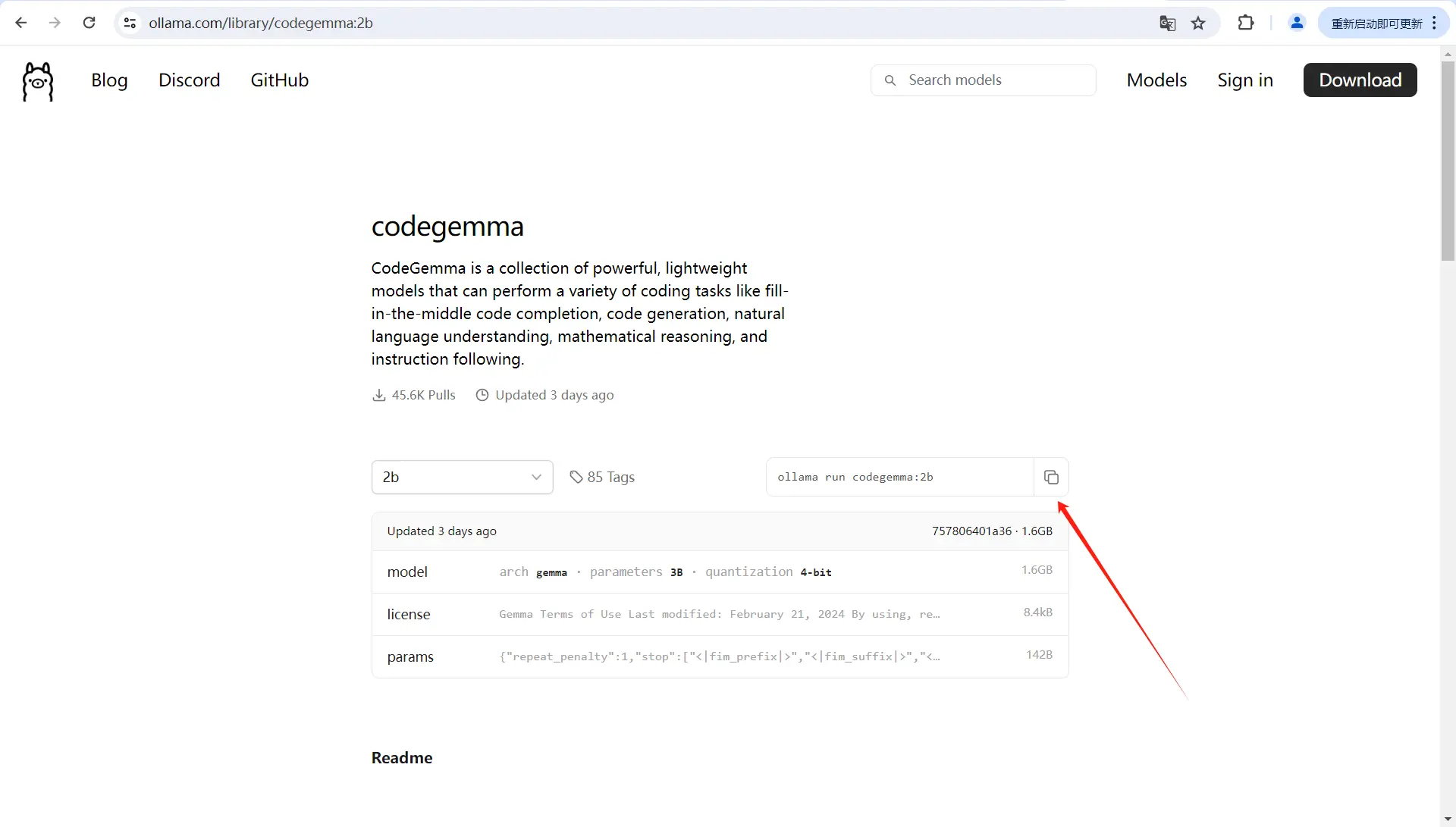
点击复制按钮
6、命令行粘贴回车运行
Ctrl + V 即可
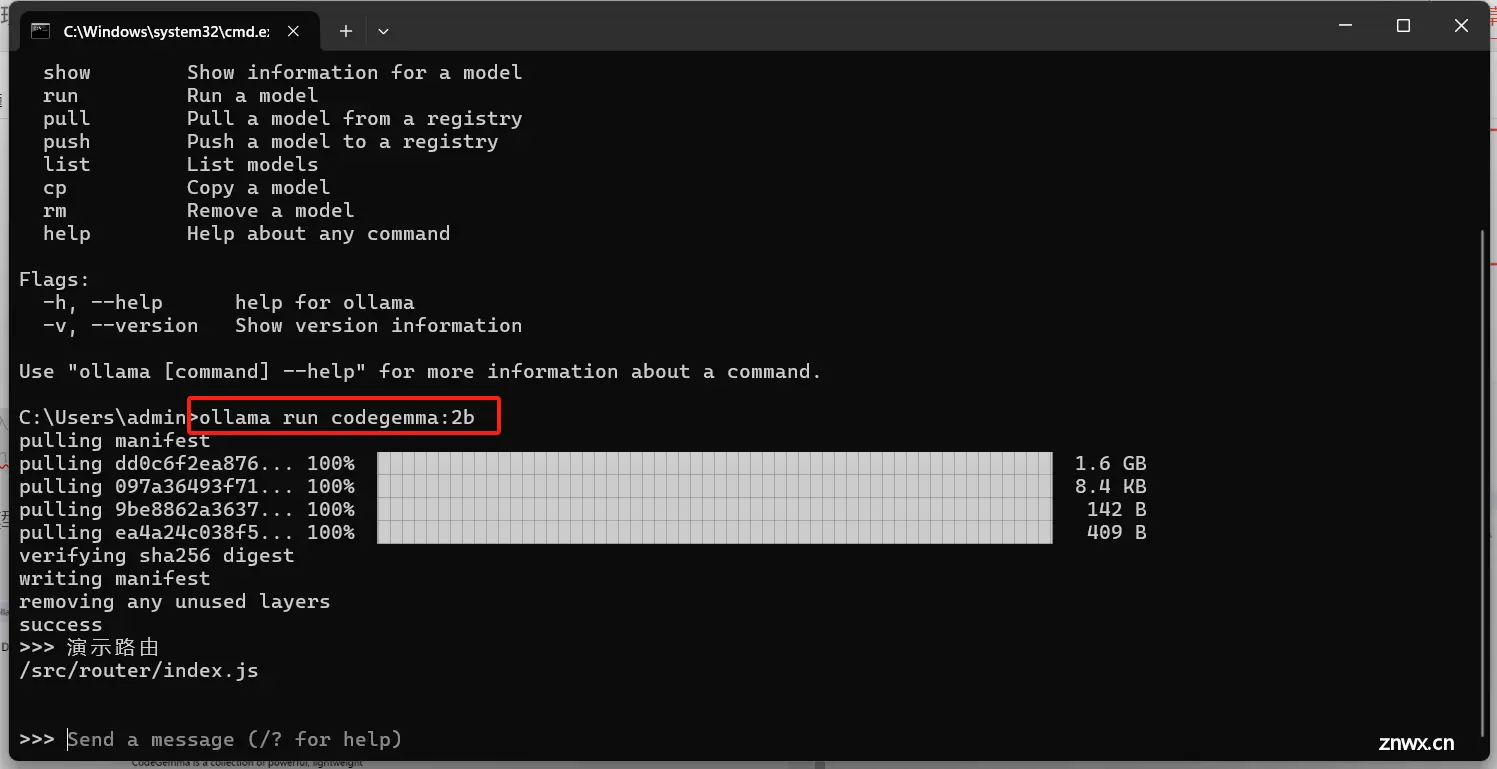
输入问答问题即可测试运行
7、API接口调用:
由于实际使用命令行问答很不方便,改造成api调用。都是 POST 接口
/ai/generate:结果一起返回,等待时间较长
/ai/chat:对话模式,有一点结果就立马输出
详细api文档说明:https://github.com/ollama/ollama/blob/main/docs/api.md?plain=1
支持json数据返回、图片问答、row数据等
模板案例:
axios.post(`http://localhost:11434/api/generate`, { model: "codegemma:7b", prompt: "正则匹配大陆手机号码是否正确", format: "json", stream: false, // options: { // num_keep: 15, // seed: 42, // num_predict: 100, // top_k: 20, // top_p: 0.9, // tfs_z: 0.5, // typical_p: 0.7, // repeat_last_n: 33, // temperature: 0.8, // repeat_penalty: 1.2, // presence_penalty: 1.5, // frequency_penalty: 1.0, // mirostat: 1, // mirostat_tau: 0.8, // mirostat_eta: 0.6, // penalize_newline: true, // // stop: ["\n", "user:"], // numa: false, // num_ctx: 1024, // num_batch: 2, // num_gqa: 1, // num_gpu: 1, // main_gpu: 0, // low_vram: false, // f16_kv: true, // vocab_only: false, // use_mmap: true, // use_mlock: false, // rope_frequency_base: 1.1, // rope_frequency_scale: 0.8, // num_thread: 8, // }, });
| 参数名称 | 是否必填 | 说明 |
|---|---|---|
| model | 是 | 访问的模型名称 |
| prompt | 是 | 问题内容 |
| stream | 否 | 默认值:true,返回数据流。设置false,则返回对象数据 |
| format | 否 | 返回响应的格式。当前唯一接受的值是json |
| keep_alive | 否 | 控制模型在请求后加载到内存中的时间(默认值:“5m”) |
| options | 否 | 额外的模型参数 |
| images | 否 | 图片数组 |
| role | 否 | 角色身份。支持参数:system, user or assistant |
| 其他… | 自己看 |
options 参数说明
参考文档:https://github.com/ollama/ollama/blob/main/docs/modelfile.md#valid-parameters-and-values
8、调用测试
入参:
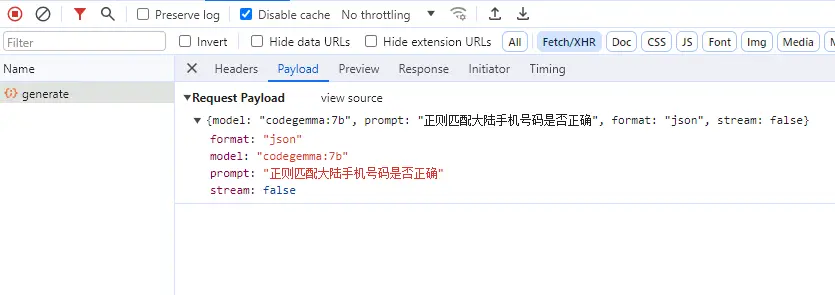
输出:
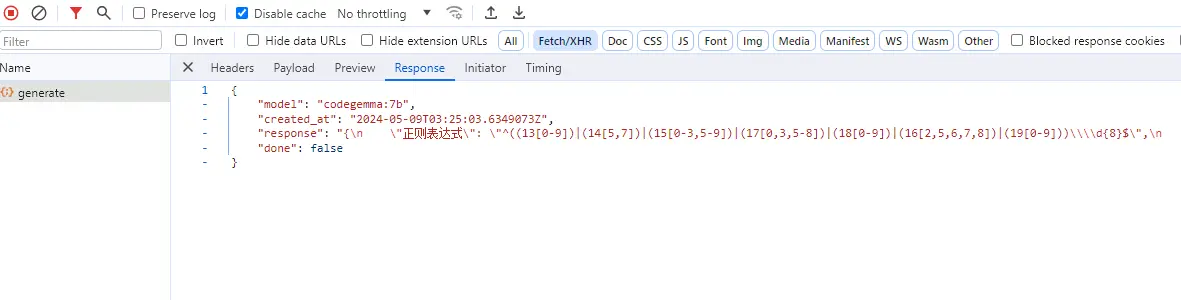
设备说明:
测试模型:codegemma:7b
CPU:i7-13700H(问答时占用很高)
内存:32G(实际占用1.5G样子,没啥压力)
时间:7B回复简单问题,问答模式响应时间5-10秒样子。对象返回1.5-2分钟(设置options中:mirostat_eta: 0.1 则用时短一点,但是回答内容也会减少,设置GPU加速,能在30秒内)。受限没有使用GPU速度较慢
备注:
1、如果运行失败。电脑重启在 命令行 重新粘贴命令
安装WebUi等可以查看:
参考文档地址:https://blog.csdn.net/qq_39583774/article/details/136592951
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。