【论文+中文文生图】Kolors:快手可图绘画模型实测(24.07.06开源)
曾小蛙 2024-08-23 10:31:02 阅读 73
代码:https://github.com/Kwai-Kolors/Kolors | 权重
论文原文:Kolors: Effective Training of Diffusion Model for Photorealistic Text-to-Image Synthesis
快手在线使用平台:https://kolors.kuaishou.com/
comfyui推理:https://github.com/kijai/ComfyUI-KwaiKolorsWrapper
一、Kolors简介 (=U-net + chatGLM3文本编码 + CogVLM打标 + 数十亿图像文本对预训练+数百万高质量图片微调)
Kolors(2.6B模型参数),这是一种基于SDXL的 U-Net 架构的潜在扩散模型(latent diffusion model),通过中英文模型chatGLM3 (General Language Model, GLM)文本编码。训练时由多模态 CogVLM 生成的细粒度文本标题。Kolors 在理解复杂语义方面表现出色,特别是涉及多个实体时,并展示了卓越的文本渲染能力。(其中chatGLM 支持256token, 而sdxl是77)
Kolors 通过两个不同的阶段进行训练:
1.概念学习阶段:包含数十亿图像-文本对的大规模数据集中获取全面的知识和概念。该阶段的数据来源于公共数据集(如 LAION DataComp,JourneyDB 以及专有数据集。
2. 质量改进阶段:数百万张机器+人工挑选。
Kolors 生成的高质量样本展示了它在英文和中文文本渲染、精确提示依从性、细致的细节渲染以及在广泛的风格和分辨率下优越的图像质量方面的出色能力
官方支持的风格


comfyui实测 (3090ti约20秒)
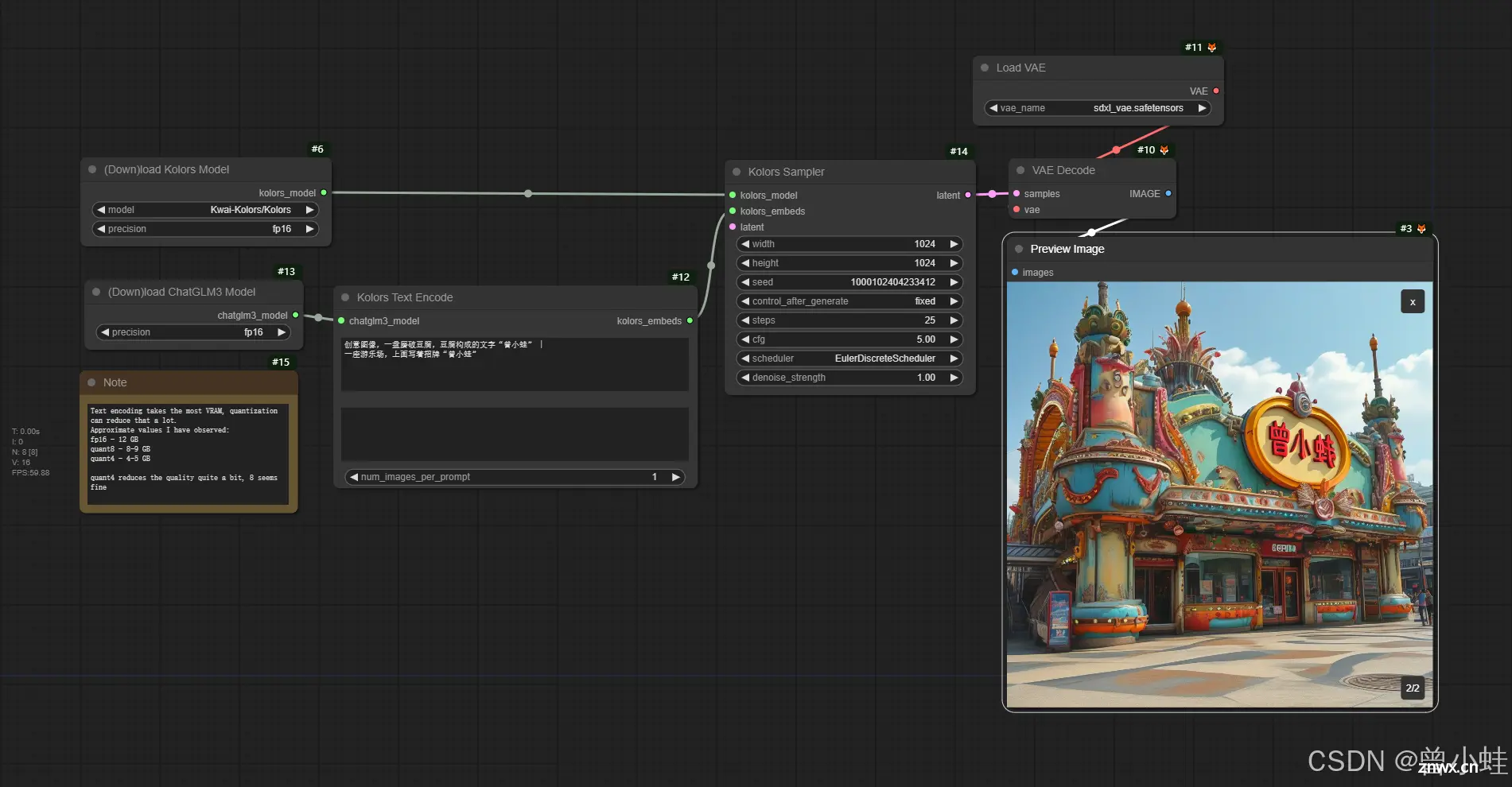
二、部分论文原文
摘要
介绍了 Kolors,一种用于文本生成图像(text-to-image synthesis)的潜在扩散模型(latent diffusion model),其特点是对英语和中文的深刻理解以及令人印象深刻的逼真度。Kolors 的开发有三个关键见解。首先,不同于 Imagen 和 Stable Diffusion 3 中使用的大型语言模型 T5,Kolors 建立在通用语言模型(General Language Model,GLM)之上,增强了其对英语和中文的理解能力。此外,我们采用多模态大型语言模型(multimodal large language model)对广泛的训练数据集进行重新描述,以便细化文本理解。这些策略显著提高了 Kolors 理解复杂语义的能力,特别是涉及多个实体时,并使其具备先进的文本渲染能力。
其次,我们将 Kolors 的训练分为两个阶段:知识广泛的概念学习阶段和使用精心策划的高美学数据进行的质量改进阶段。此外,我们探讨了噪声调度(noise schedule)的关键作用,并引入了一种新的调度方法以优化高分辨率图像生成。这些策略共同提高了生成的高分辨率图像的视觉吸引力。
最后,我们提出了一个类别平衡的基准 KolorsPrompts,用于指导 Kolors 的训练和评估。结果表明,即使使用常见的 U-Net 主干网络,Kolors 在人类评估中表现出色,超越了现有的开源模型,并在视觉吸引力方面达到了 Midjourney-v6 的水平。我们将发布 Kolors 的代码和权重,希望能为未来的视觉生成领域的研究和应用带来益处。
1 引言
基于扩散的文本生成图像(T2I,text-to-image)生成模型已成为人工智能和计算机视觉领域的焦点。之前的方法,如 Stability AI 的 SDXL [27],谷歌的 Imagen [34],以及 Meta 的 Emu [6],都是基于 U-Net [33] 架构,在文本生成图像任务中取得了显著进展。最近,一些基于 Transformer 的模型,如 PixArt-α [5] 和 Stable Diffusion 3 [9],展示了前所未有的图像生成质量。然而,这些模型目前无法直接解释中文提示,从而限制了它们从中文文本生成图像的适用性。可以直接中文题词模型: 包括 AltDiffusion [45],PAI-Diffusion [39],Taiyi-XL [42] 和 Hunyuan-DiT [19]。这些方法仍依赖于 CLIP 进行中文文本编码。然而,这些模型在中文文本遵循和图像美学质量方面仍有很大改进空间。
在本报告中,我们介绍了 Kolors,这是一种在潜在空间中结合经典 U-Net 架构 [27] 和通用语言模型(GLM)[8] 的扩散模型,用于文本生成图像。通过将 GLM 与多模态大型语言模型生成的细粒度标题相结合,Kolors 展现了对英语和中文的高级理解以及其卓越的文本渲染能力。由于精心设计的两阶段训练策略,Kolors 展现了其出色的逼真能力。在我们的 KolorsPrompts 基准上的人类评估证实,Kolors 在视觉吸引力方面表现出色。我们将发布 Kolors 的代码和模型权重,旨在将其确立为主流的扩散模型。本文的主要贡献总结如下:
基于中国的大语言模型ChatGLM3-base对文本进行编码,语义理解能力增强:
特别是对多个物体(multiple entities)描述的语义
文字渲染(书写的效果)
Kolors 使用两阶段方法进行训练,其中包括概念学习阶段(concept learning phase)、使用广泛知识和质量改进阶段,利用精心策划的高美学数据(high aesthetic data)。此外,我们引入了一种新的调度(schedule)来优化高分辨率图像生成。这些策略有效地提高了生成的高分辨率图像的视觉吸引力(visual appeal)。
在相同题词 KolorsPrompts、Kolors 的综合人工评估中,Kolors 都优于大多数开源和封闭源模型,包Stable Diffusion 3、DALL-E 3 和 Playground-v2.5,并展示了与 Midjourney-v6 相当的性能
2.方法
对于主干模型,我们严格遵守(strictly adhere)**SDXL**中使用的U-Net结构
2.1 增强对文本理解正确性(中文+深层语意)(Faithfulness)
2.1.1 使用大语言模型作为文本编码器 (Text Encoder)
表1 经典的图像生成模型,所采用的文本编码器

CLIP 只支持77 个标记(token),由于 CLIP 中英文文本编码器的局限性,大多数文本到图像生成模型在中文提示方面遇到了困难。HunyuanDiT 通过使用双语 CLIP 和多语言 T5 编码器来生成中文文本到图像来解决这个问题。然而,中文文本训练语料库占多语言 T5 数据集的不到 2%,双语 CLIP 生成的文本嵌入仍然不足以处理复杂的文本提示。
为了解决这些限制,我们选择通用语言模型 (GLM) 作为 Kolors 中的文本编码器。GLM 是一种基于自回归空白填充目标的双语(英文和中文)预训练语言模型,在自然语言理解和生成任务中都显着优于 BERT 和 T5。我们假设预训练的 ChatGLM3-6B-Base 模型更适合文本表示,而经过人类偏好对齐训练的聊天模型 ChatGLM3-6B 在文本渲染方面表现出色。
因此,在 Kolors 中,我们利用开源 ChatGLM3-6B-Base 作为文本编码器,该文本编码器经过超过 1.4 万亿双语标记的预训练,为中文语言理解提供了强大的能力。
我们直接将 ChatGLM3 的文本长度设置为 256,以进行详细的复杂文本理解。请注意,由于 ChatGLM3 的长文本处理能力,很容易支持长文本。和 SDXL 一样,ChatGLM3 模型的倒数第二层(penultimate)输出用于文本表示(text representation)。
2.1.2 使用多模态图文大模型对图片进行详细描述用于训练
Improved Detailed Caption with Multimodal Large Language Model
训练的文本图像对通常来源于互联网,随附的图像标题不可避免地带有噪声且不准确。DALL-E 3 通过使用专门的图像标题生成器重新描述训练数据集来解决这个问题。为增强 Kolors 的提示遵循能力,我们采用与 DALL-E 3 类似的方法,使用多模态大型语言模型(MLLM)重新描述文本图像对。
建议一个标准,并用5个具备中文输出能力的多模态模型,输出描述
LLaVA1.5 [ 22 ], CogAgent [ 14 ], and CogVLM,InternLM-XComposer-7B,以及GPT4-V,
然后人工打分在5个方面打分:
长度(Length): 对图像描述文本长度
完整性(Completeness):确保文本描述涵盖图像中的所有重要元素
相关性(Correlation):确保文本描述与图像内容高度相关
幻想(Hallucination):文本中提及但图像中不存在的细节或实体的比例
主观性(Subjectivity):文本偏离描述图像视觉内容而传达主观印象的程度
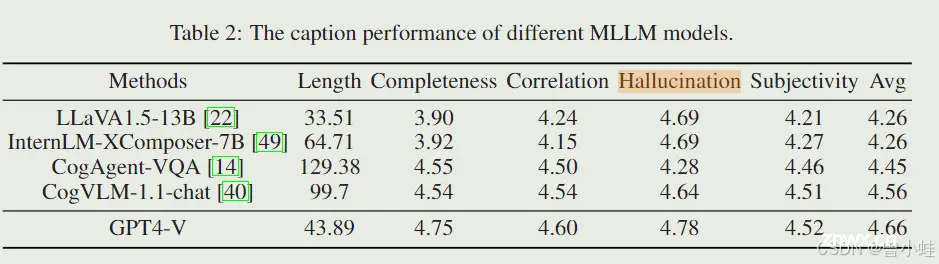
我们选择了五个知名的 MLLM 模型,并雇用了十名评估员评估 500 张图像。值得注意的是,LLaVA1.5 [22]、CogAgent [14] 和 CogVLM [40] 支持中文文本。然而,我们发现生成的中文标题不如英文标题。因此,我们首先生成英文图像标题,然后将其翻译成中文。相比之下,我们直接使用 InternLM-XComposer-7B [49] 和 GPT-4V 的中文提示。
五个模型的标题性能总结如表2所示。显然,GPT-4V 的性能最高。然而,使用 GPT-4V 处理数亿张图像的成本和时间消耗过高。在剩下的四个开源模型中,LLaVA1.5 和 InternLM-XComposer 在完整性和相关性方面显著逊色于 CogAgent-VQA 和 CogVLM-1.1-chat,表明详细描述的质量较低。此外,CogVLM-1.1-chat 生成的标题在幻想和主观性方面表现出较少的问题。基于这些评估,我们选择了最先进的视觉语言模型 CogVLM-1.1-chat 生成我们庞大训练数据集的合成详细标题。考虑到 MLLM 可能无法识别其知识库中不存在的图像中特定概念,我们采用 50% 原始文本和 50% 合成标题的比例。这与 Stable Diffusion 3 的配置一致。
通过利用细粒度的合成标题,Kolors 展现了对复杂中文文本的强大遵循能力。如图2所示,我们展示了不同文本编码器在复杂提示上的 Kolors 结果。我们观察到,使用 GLM 的 Kolors 在多个主题和详细属性方面表现良好,而使用 CLIP 的 Kolors 未能生成顶部提示中的小贩和电话,并且在底部提示中存在颜色混淆。

2.1.3 增强中文文本渲染能力
文本渲染一直是文本生成图像领域的一个挑战问题。先进方法如 DALL-E 3 [3] 和 Stable Diffusion 3 [9] 在渲染英文文本方面展示了优异的能力。然而,当前模型在准确渲染中文文本方面遇到了显著挑战。造成这些困难的根本原因如下:
中文字符集庞大且这些字符的纹理复杂,使得渲染中文文本比英文更具挑战性。
缺乏包含中文文本及相关图像的足够训练数据,导致模型训练和拟合能力不足。
为解决这个问题,我们从两个角度进行处理。首先,对于中文语料库,我们选择了 50,000 个最常用词,并通过数据合成构建了数千万对图像-文本对的训练数据集。为确保有效学习,这些合成数据仅在概念学习阶段使用。其次,为增强生成图像的逼真度,我们利用 OCR 和多模态语言模型为真实世界的图像(如海报和场景文本)生成新的描述,从而获得大约数百万个样本。
我们观察到,虽然训练数据集中初始的合成数据缺乏真实感,但在将真实数据和高质量文本图像纳入训练过程后,生成的文本图像的真实感显著提高。即使某些字符仅在合成数据中出现,这种增强也很明显。更多可视化示例见图3。
通过系统性地通过集成合成和真实世界数据解决训练数据的局限性,我们的方法显著提升了中文文本渲染的质量,为中文文本图像生成的新进展铺平了道路。

2.2 提高视觉吸引力(Visual Appeal)
尽管潜在扩散模型(Latent Diffusion Models, LDMs)已被普通用户和专业设计师广泛采用,但其图像生成质量通常需要额外的后处理步骤,如图像放大(image upscaling)和面部修复(face restoration)。提高 LDMs 的图像生成质量仍然是一个重大挑战。在这项工作中,我们通过改进数据和训练方法来解决这个问题。
2.2.1 高质量数据(High Quality Data)
概念学习阶段(数十亿图像-文本对)
概念学习阶段(concept learning phase)模型主要从包含数十亿图像-文本对的大规模数据集中获取全面的知识和概念。
该阶段的数据来源于公共数据集(如 LAION ,DataComp,JourneyDB 以及专有数据集
质量改进阶段 (数百万张第5级高美学图像)
先对数据集应用传统的过滤器(如分辨率、OCR 准确性、面部数量、清晰度和美学评分),将其减少到大约数千万张图像
然后,这些图像被手动标注,并将标注分为五个不同的级别。为了减轻主观偏见,每张图像被标注三次,最终的级别通过投票过程确定。不同级别图像的特征如下:
第1级:内容被视为不安全,包括色情、暴力、血腥或恐怖的图像。
第2级:显示出人工合成痕迹的图像,如存在标志、水印、黑白边框、拼接图像等。
第3级:参数错误的图像,如模糊、过曝、欠曝或缺乏明确主体的图像。
第4级:平淡无奇的照片,类似于没有经过太多考虑拍摄的快照。
第5级:具有
高美学价值的照片,意味着图像不仅应具有适当的曝光、对比度、色调平衡和色彩饱和度,还应传达一种叙事感。
2.2.2 在高分辨率下训练(Training on High Resolutions)
扩散模型在高分辨率下通常表现不佳,因为在前向扩散过程中图像未能充分扰动。如图4所示,当按照 SDXL [27] 提供的调度添加噪声时,低分辨率图像在终端阶段几乎完全变为纯噪声,而高分辨率图像倾向于保留低频分量。由于模型在推理过程中必须从纯高斯噪声开始,这种差异可能导致高分辨率下训练和推理之间的不一致。最近的研究[20, 15]提出了方法来解决这个问题。
在 Kolors 中,我们采用基于 DDPM 的训练方法,以 ε 预测目标。在概念学习的低分辨率训练阶段,我们使用与 SDXL [27] 相同的噪声调度。在高分辨率训练阶段,我们引入了一种新调度方法,将步数从原来的 1000 步延长到 1100 步,使模型能够实现更低的终端信噪比。此外,我们调整了 β 值以保持 αt 曲线的形状,其中 αt 决定了 xt = √αtx0 + √1− αtε。如图5所示,我们的 αt 轨迹完全覆盖了基础调度的轨迹,而其他方法的轨迹显示出显著的偏差。这表明,从低分辨率中使用的基础调度过渡时,与其他调度相比,新调度的适应和学习难度较低。
如图6所示,通过结合高质量训练数据和优化的高分辨率训练技术,生成图像的质量得到了显著提升。

此外,为使模型生成不同纵横比的图像,我们在训练过程中采用了 NovelAI 的分桶采样方法[25]。为了节省训练资源,此策略仅在高分辨率训练阶段应用。不同分辨率图像的示例见图1和图9。
3. 评估(Evaluations)
为了准确评估 Kolors 的生成能力,我们建立了三个基本评估指标。首先,我们引入了一个新的基准 KolorsPrompts,这是一组涵盖多个类别和不同挑战的提示集。然后,我们基于 KolorsPrompts 进行全面的人类偏好评估。此外,我们计算了两个自动评估指标:(a)多维偏好评分(Multi-dimensional Preference Score, MPS)[50] 和(b)著名的图像质量评估指标 FID。我们将 Kolors 与现有的开源模型和市场上的专有系统进行了比较。
3.1 KolorsPrompts
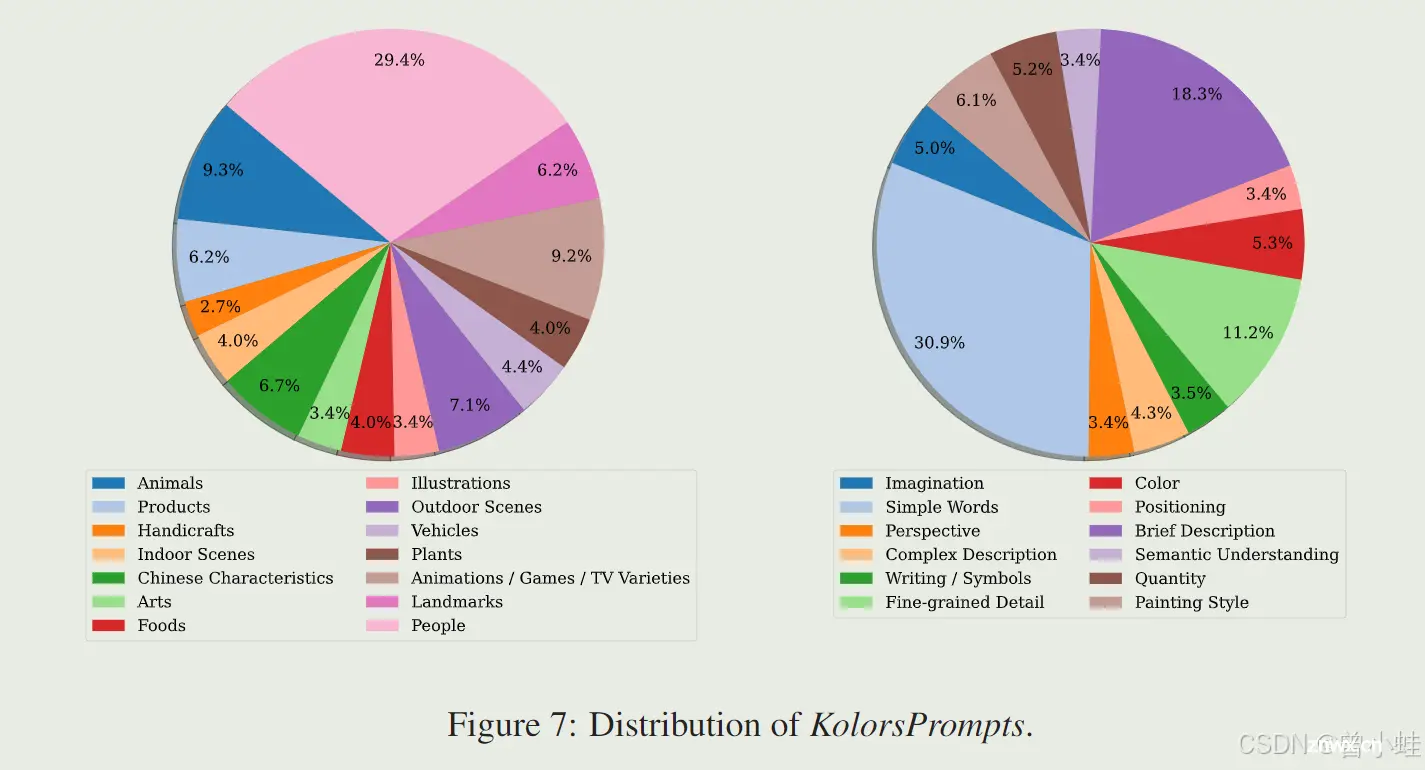
为了全面评估文本生成图像模型,我们引入了一个整体基准 KolorsPrompts。具体而言,KolorsPrompts 包含了从公共数据集中获得的千余个提示,包括 PartiPrompts [47] 和 ViLG-300 [10],以及一些专有提示。KolorsPrompts 包括了 14 个常见的现实世界场景(如人物、食物、动物、艺术等)。此外,我们根据提示的特征将 KolorsPrompts 分为 12 个不同的挑战。每个提示都提供了中文和英文版本。
KolorsPrompts 的分布详见图7。类别和挑战的分布设置反映了实际使用情况。图的左侧展示了 KolorsPrompts 的类别分布,其中人物类别占比最大,为 29.4%。右侧展示了挑战的分布,简单词语(Simple words)最为常见,占比 30.9%。
3.2 人类评估(Human Evaluation)
我们提供了三个评估指标来评估模型的表现:
视觉吸引力(Visual Appeal)。视觉吸引力指生成图像的整体美学质量,涵盖颜色、形状、纹理和构图等各种视觉元素,以创建令人愉悦和引人入胜的外观。在此评估中,我们向用户展示使用相同提示生成的不同模型的图像,而不显示相应的文本描述。这种方法使用户能够专注于图像的视觉吸引力。每个评估者对一幅图像评分,评分范围为 1 到 5 分,其中 5 分表示完美,1 分表示最低质量。
文本忠实度(Text Faithfulness)。文本忠实度衡量生成图像与其相应提示的匹配程度。评估者被要求忽略图像质量,只关注文本描述与图像之间的相关性。评分范围为 1 到 5 分。
整体满意度(Overall Satisfaction)。整体满意度代表对图像的整体评估。在此评估中,提示和图像一起显示。评估者根据图像质量、视觉吸引力和提示与图像之间的匹配程度进行评估,评分范围为 1 到 5 分。
评估的模型每个提示生成四幅图像。我们邀请了约 50 名专业评审员根据指定的指南评估每幅图像五次。图像的最终评分为这五次评估的平均分。因此,每幅图像获得三个不同的评分,分别是视觉吸引力、文本忠实度和整体满意度。所有图像均以 1024×1024 像素的分辨率呈现。
考虑到手动评估的高成本,我们的人类评估主要集中在当前最先进的文本生成图像模型上,包括 Adobe Firefly、DALL-E 3 [3]、Stable Diffusion 3 [9]、Midjourney-v5、Midjourney-v6 和 Playground-v2.5 [18]。为确保比较模型的最佳性能,我们为这些模型提供英文提示,而 Kolors 则接受中文提示。详细结果见图8。Kolors 在整体满意度方面达到了最高,与 Midjourney-v6 等专有模型相当。特别是 Kolors 在视觉吸引力方面展示了显著优势。Kolors 生成的图像示例见图9。
3.3 自动评估基准(Automatic Evaluation Benchmark)
3.3.1 多维人类偏好评分(Multi-Dimensional Human Preference Score, MPS)
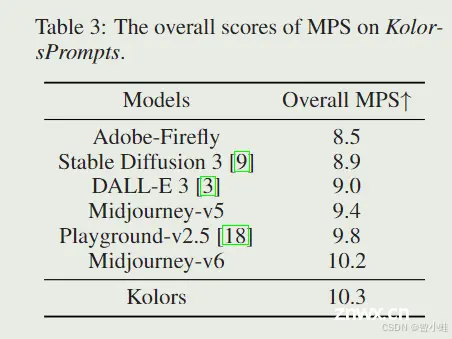
当前对文本生成图像模型的评估指标主要依赖于单一度量(如 FID,CLIP Score [28]),这些度量无法充分捕捉人类偏好。多维人类偏好评分(Multi-dimensional Human Preference Score, MPS)[50] 被提出用于从多维人类偏好评估文本生成图像模型,并在文本生成图像评估中展示了其有效性。因此,我们使用 MPS 在 KolorsPrompts 基准上评估上述文本生成图像模型。
MPS 的结果如表 3 所示。可以看出,Kolors 达到了最高性能,与人类评估一致。这种一致性表明 KolorsPrompts 基准上的人类偏好与 MPS 分数之间有很强的相关性。
3.3.2 MS-COCO 数据集上的保真度评估(Fidelity Assessment on COCO Dataset)
我们还使用文本生成图像任务的标准评估指标,即 MS-COCO 256×256 [21] 验证数据集上的零样本 FID-30K,评估 Kolors。表 4 显示了 Kolors 与其他现有模型的比较。Kolors 达到了略高的 FID 分数,这可能不被视为一个高度竞争的结果。然而,我们认为 FID 可能不是评估图像质量的完全适用的指标,因为更高的分数并不一定与生成图像的优越性相关。
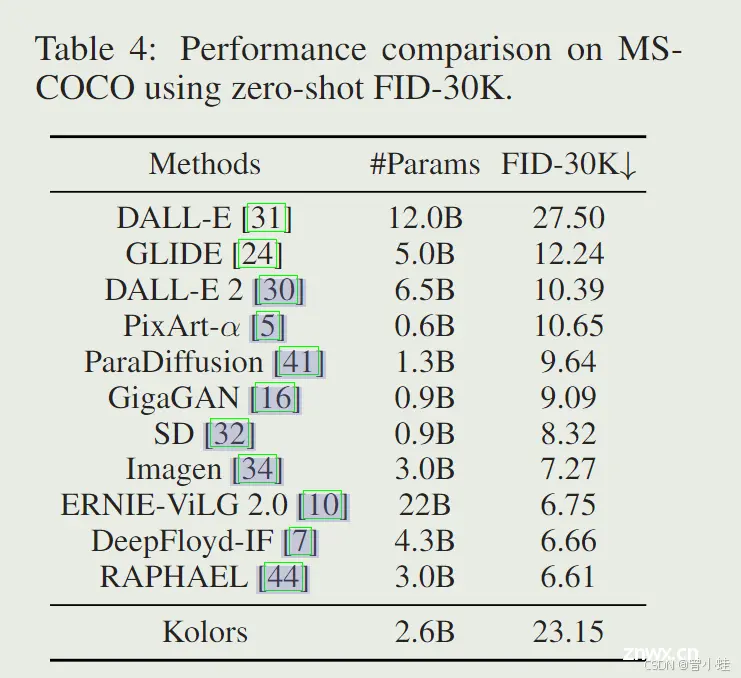
众多研究[5, 7, 27, 17, 50]表明,COCO 上的零样本 FID 与视觉美学呈负相关,文本生成图像模型的生成性能更准确地通过人类评估而非统计指标评估。这些发现强调了需要一个与真实人类偏好一致的自动评估系统,如 MPS [21]。
4 结论(Conclusions)
在这项工作中,我们介绍了 Kolors,这是一种基于经典 U-Net 架构[27]的潜在扩散模型(latent diffusion model)。通过利用通用语言模型(General Language Model, GLM)和由 CogVLM 生成的细粒度标题,Kolors 在理解复杂语义方面表现出色,特别是涉及多个实体时,并展示了卓越的文本渲染能力。此外,Kolors 通过两个不同的阶段进行训练:概念学习阶段(concept learning phase)和质量改进阶段(quality improvement phase)。通过使用高美学数据并引入一种新的调度方法进行高分辨率图像生成,生成的高分辨率图像的视觉吸引力显著提高。此外,我们提出了一个新的类别平衡基准 KolorsPrompts,以全面评估文本生成图像模型。Kolors 在人类评估中表现出色,超越了大多数开源和专有模型,如 Stable Diffusion 3、Playground-v2.5 和 DALL-E 3,并展示了与 Midjourney-v6 相当的表现。
我们很高兴宣布公开发布 Kolors 的模型权重和代码。在未来的工作中,我们计划逐步发布 Kolors 的各种应用和插件,包括 ControlNet [48]、IP-Adapter [46] 和 LCM [23] 等。此外,我们还打算基于 Transformer 架构[26]发布一个新的专有扩散模型。我们希望 Kolors 能推动文本生成图像社区的发展,并致力于为开源生态系统做出重大贡献。
其他生成示例


上一篇: “You tried to access openai.ChatCompletion, but this is no longer supported in openai>=1.0.0“
下一篇: CUDA11.8+cudnn9.2.1 win10安装教程
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。