国庆假期看了一系列图像分割Unet、DeepLabv3+改进期刊论文,总结了一些改进创新的技巧
芒果汁没有芒果 2024-06-23 09:01:02 阅读 92
关于图像分割方面的论文改进
目前深度学习 图像处理 主流方向的模型基本都做到了很高的精度,你能想到的方法,基本上前人都做过了,并且还做得很好,因此越往后论文越来越难发,创新点越来越难找。
尤其是DeepLabv3+ 和 Unet 系列模型🔥🔥🔥,热度很高,也是改进频率很高的一个模型。
文章目录
一、创新思路🌟1.无事生非法2.后浪推前浪法3.推陈出新法4.出奇制胜法说明 二、部分期刊论文创新点总结🌟共性以及特点 三、部分中/英文期刊论文创新点🌟一种基于注意力机制的轻量级航空电力线分割算法基于CBAM注意力机制的U-Net桥梁裂缝识别与特征计算方法研究通过多光谱卫星图像和改进的 UNet++ 检测虫害森林破坏基于全局信息和U-Net的火灾烟雾图像多尺度语义分割Swin Transformer Embedding UNet for Remote Sensing Image Semantic SegmentationRes2-Unet, a New Deep Architecture for Building Detection From High Spatial Resolution ImagesCD-TransUNet:使用 L 波段 SAR 图像检测城市建筑物变化的混合变压器网络使用 DeepLabV3+ 模型对荔枝枝进行语义分割改进DeepLabV3+的高效语义分割用于场景分割的改进DeepLabV3+算法一种轻量级的DeepLabv3+遥感影像建筑物提取方法 四、总结创新常见思路技巧🌟刨根问底法声东击西法移花接木法
那如何寻找自己的创新点呢?如何在前人的基础上改进呢?然后,重点是如何发?
下面将提供几种总结思路。给出一些讨论以供参考:
一、创新思路🌟
1.无事生非法
在原始的数据集上加一些噪声,例如随机遮挡,或者调整饱和度亮度什么的,主要是根据具体的任务来增加噪声或扰动,不可乱来。如果它的精度下降的厉害,那你的思路就来了,如何在有遮挡或有噪声或其他什么情况下,保证模型的精度。用顶会的模型去尝试一个新场景的数据集,因为它原来的模型很可能是过拟合的。如果在新场景下精度下降的厉害,思路又有了,如何提升模型的泛化能力,实现在新场景下的高精度。2.后浪推前浪法
思考一下它存在的问题,例如模型太大,推理速度太慢,训练时间太长,收敛速度慢等。一般来说这存在一个问题,其他问题也是连带着的。如果存在以上的问题,你就可以思考如何去提高推理速度,或者在尽可能不降低精度的情况下,大幅度减少参数量或者计算量,或者加快收敛速度。考虑一下模型是否太复杂,例如:人工设计的地方太多,后处理太多,需要调参的地方太多。基于这些情况,你可以考虑如何设计一个end-to-end模型,在设计过程中,肯定会出现训练效果不好的情况,这时候需要自己去设计一些新的处理方法,这个方法就是你的创新。3.推陈出新法
替换一些新的结构,引入一些其它方向的技术,例如transformer,特征金字塔技术等。这方面主要是要多关注一些相关技术,前沿技术,各个方向的内容建议多关注一些。4.出奇制胜法
尝试去做一些特定的检测或者识别。通用的模型往往为了保证泛化能力,检测识别多个类,而导致每个类的识别精度都不会很高。因此你可以考虑只去检测或识别某一个特定的类。以行为识别为例,一些通用的模型可以识别几十个动作,但你可以专门做跌倒检测。在这种情况下你可以加很多先验知识在模型中,例如多任务学习。换句话来说,你的模型就是专门针对跌倒设计的,因此往往精度可以更高。说明
以下部分节选了部分英文期刊论文,对期刊里面Abstract部分的创新点高亮了,来看看共性,可以看出一些特点
很多论文的 idea 都属于比较常见的 模块组合,不算很难。
适合想快速发表普通期刊论文的同学阅读🚀,如果想发的是SCI顶刊或者CCFB以上顶会可以忽略这篇~
注:为了便于快速浏览,以下英文论文的标题 和 Abstract 部分,均将英文翻译为中文
二、部分期刊论文创新点总结🌟
共性以及特点
2-4个不等创新点基于 Unet 和 deeplabv3+ 的不少创新点并不是特别复杂和Transformer(ViT)结合的 不少改进基本上都是在 Unet 和 deeplabv3+ 框架上小改,小幅改进应用在私有数据集 或者 垂直领域数据集添加注意力机制(CBAM、SE、SA等)使用各种卷积模块(eg: Ghostbottleneck)使用其他loss函数使用 ResNeSt、densenet等网络使用swin等transformer使用各种改进的金字塔池化一般级别论文基本都是不同模块进行组合、级别高一点的期刊论文 就需要自己改一些特有的结构,有自己的亮点 三、部分中/英文期刊论文创新点🌟
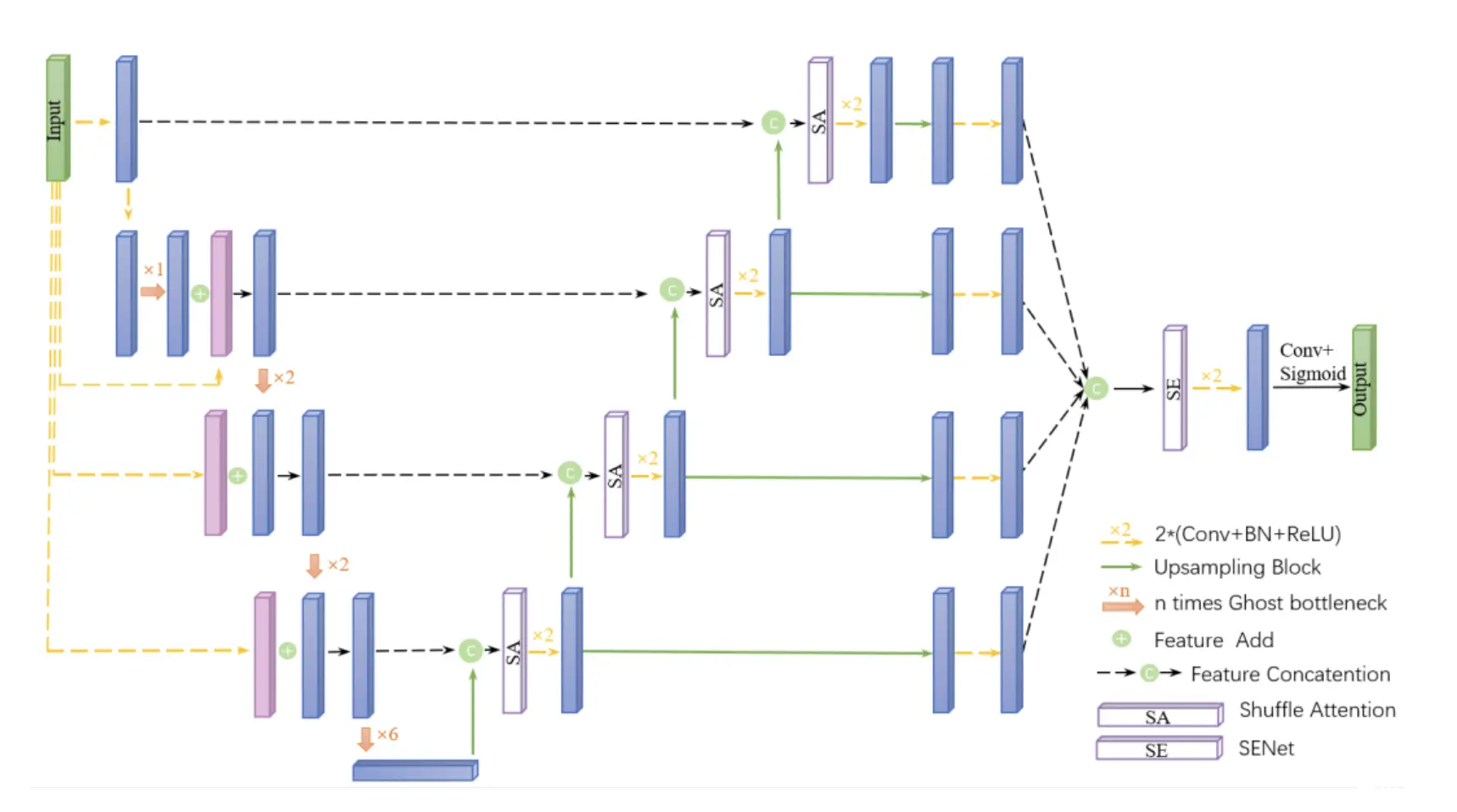
一种基于注意力机制的轻量级航空电力线分割算法
Abstract
电力线分段对于保障无人机在智能电力线巡检中的安全稳定运行非常重要。虽然基于深度学习的电力线分割算法取得了一些进展,但由于航拍电力线图像背景复杂多变、电力线目标小,加上现有的分割模型,要实现准确的电力线分割仍然相当困难。太大,不适合边缘部署。本文提出了一种轻量级的电力线分割算法——G-UNets。该算法使用了 Lei Yang 等人的改进 U-Net。(2022)作为基础网络(Y-UNet)。编码器部分结合传统卷积和Ghostbottleneck进行特征提取,采用多尺度输入融合策略减少信息丢失。在保证分割精度的同时,显着减少Y-UNet参数量;在解码阶段引入参数较少的Shuffle Attention(SA),提高模型分割精度;同时,为了进一步缓解正负样本分布不平衡对分割精度的影响,构建了融合Focal loss和Dice loss的加权混合损失函数。实验结果表明,G-UNets算法的参数数量仅为Y-UNet的26.55%左右,F1-Score和IoU值均超过Y-UNet,分别达到89.24%和82.98%,分别。G-UNets可以在保证模型准确性的同时大大减少网络参数的数量,
论文创新改进点
传统卷积和Ghostbottleneck
多尺度输入融合策略
Shuffle Attention(SA)注意力机制
融合Focal loss和Dice loss的加权混合损失函数
结构
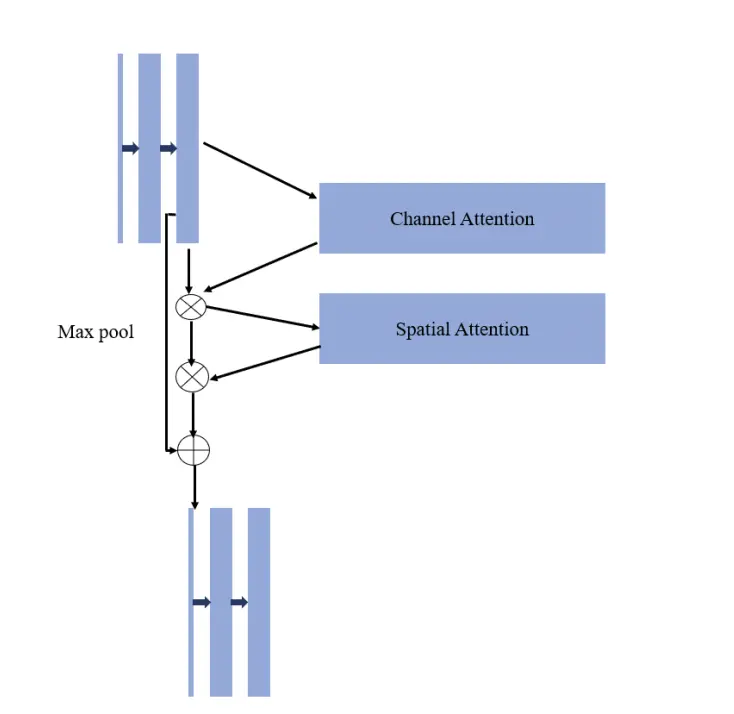
基于CBAM注意力机制的U-Net桥梁裂缝识别与特征计算方法研究
Abstract
桥梁裂缝检测是评估桥梁是否可以安全使用的重要部分。人工巡检和验桥车辆的方法存在效率低、影响道路通行等缺点。我们对桥梁裂缝检测方法进行了深入研究,提出了一种针对Unet的桥梁裂缝识别算法,称为CBAM-Unet算法。CBAM(卷积块注意模块)是一个轻量级的卷积注意模块,它结合了通道注意模块(CAM)和空间注意模块(SAM),它们分别在通道和空间上使用注意机制。CBAM考虑了桥梁裂缝的特点。使用注意机制时,表达浅层特征信息的能力增强,使识别的裂缝更加完整和准确。实验结果表明,该算法对裂纹识别的准确率可达92.66%。我们使用高斯模糊、Otsu和内侧骨架化算法来实现图像的后处理,得到内侧骨架图。提出了一种基于骨架化图像的裂纹特征测量算法,完成了裂纹最大宽度和长度的测量,误差分别为1-6%和1-8%,满足检测标准。我们提出的桥梁裂缝特征提取算法CBAM-Unet能够有效地完成裂缝识别任务,得到的图像分割精度和参数计算符合标准和要求。该方法大大提高了检测效率和准确率
论文创新改进点
CBAM(卷积块注意模块)
结构
Unet
通过多光谱卫星图像和改进的 UNet++ 检测虫害森林破坏
Abstract
植物病虫害是对农林生产和森林生态系统的主要生物威胁。通过卫星图像监测森林病虫害对制定预防和控制策略至关重要。先前利用深度学习监测卫星图像中虫害危害的研究采用 RGB 图像,而未使用多光谱图像和植被指数。多光谱图像和植被指数包含丰富的植物健康检测信息,可以提高害虫危害检测的精度。该研究的目的是通过将多光谱、植被指数和 RGB 信息结合到深度学习中来进一步改进森林害虫侵扰区域分割。我们还提出了一种基于 UNet++ 和注意机制模块的新图像分割方法,用于检测 Sentinel-2 图像中树皮甲虫和白杨潜叶虫引起的森林损害。采用ResNeSt101作为特征提取主干,在解码阶段引入注意机制scSE模块,提高图像分割结果。我们使用 Sentinel-2 图像生成数据集,该数据集基于加拿大不列颠哥伦比亚省 (BC) 的森林、土地、自然资源运营和农村发展部 (FLNRORD) 在空中概览调查 (AOS) 期间收集的森林健康损害数据2020 年。数据集包含 11 个原始 Sentinel-2 波段和 13 个植被指数。实验结果证实了植被指数和多光谱数据对增强分割效果的意义。
论文创新改进点
ResNeSt101
注意机制scSE模块
结构
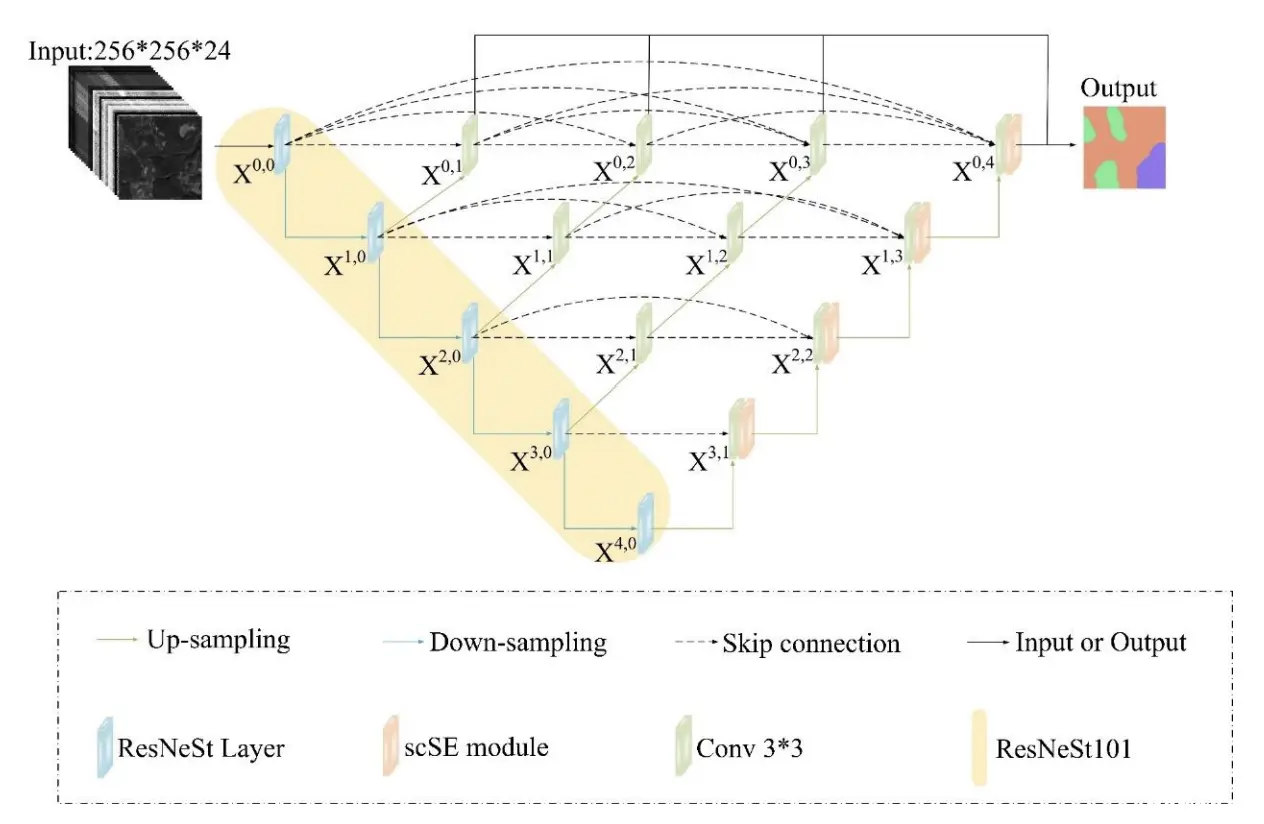
基于全局信息和U-Net的火灾烟雾图像多尺度语义分割
Abstract
烟雾是半透明且不规则的,导致背景和烟雾之间的混合非常复杂。稀薄或细小的烟雾在视觉上不显眼,其边界往往模糊不清。因此,从图像中完全分割烟雾是一项非常困难的任务。针对上述问题,提出了一种基于全局信息和U-Net的火灾烟雾多尺度语义分割。该算法采用多尺度残差组注意力(MRGA)结合U-Net提取多尺度烟雾特征,增强对小尺度烟雾的感知。编码器 Transformer 用于提取全局信息,并提高图像边缘稀薄烟雾的准确性。最后,该算法在烟雾数据集上进行了测试,达到了 91.83% mIoU。与现有的分割算法相比,mIoU提升 2.87%,mPA提升 3.42%。因此,它是一种准确度较高的火灾烟雾分割算法。
结构
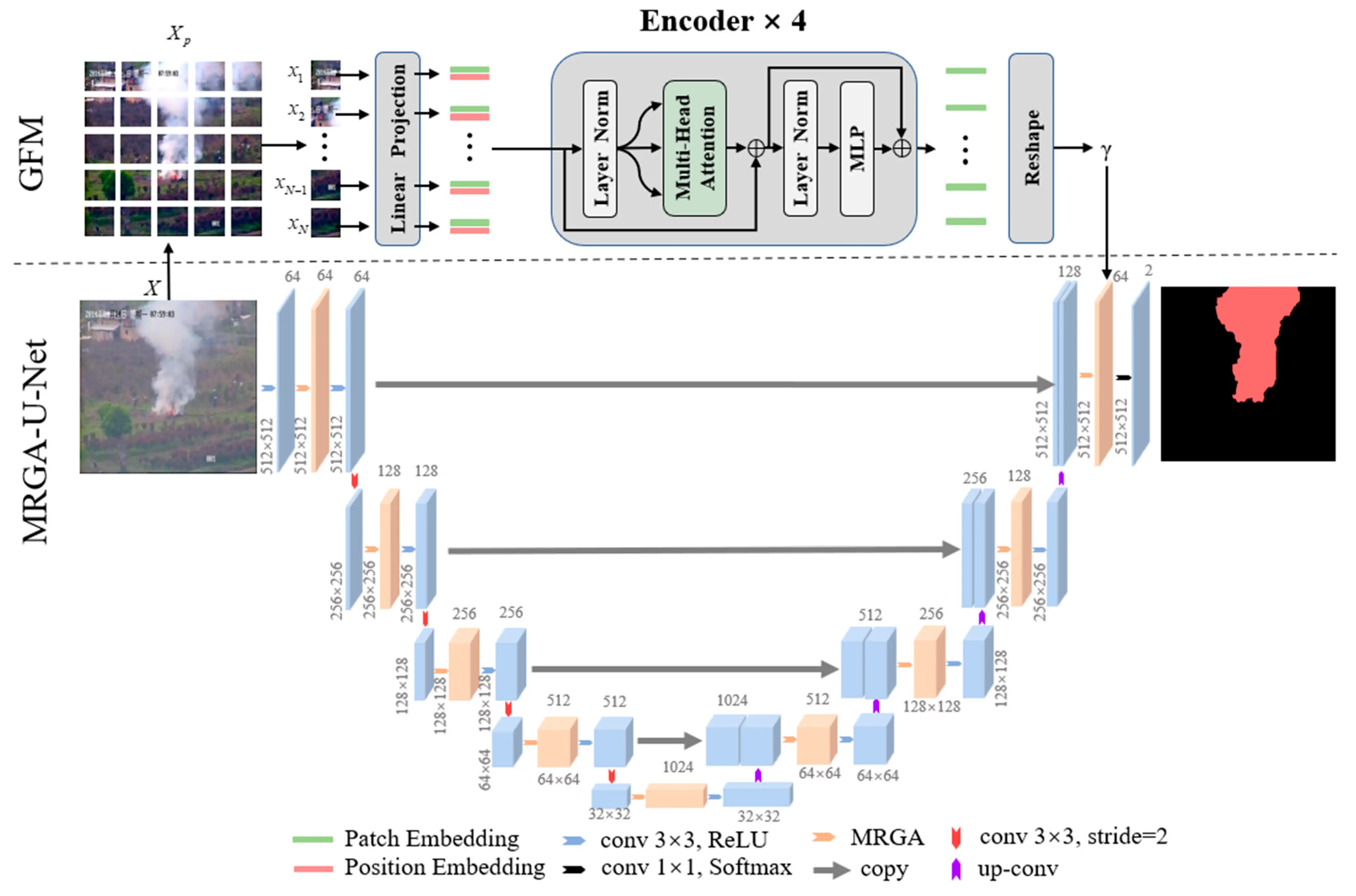
Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation
https://ieeexplore.ieee.org/document/9686686
Global context information is essential for the semantic segmentation of remote sensing (RS) images. However, most existing methods rely on a convolutional neural network (CNN), which is challenging to directly obtain the global context due to the locality of the convolution operation. Inspired by the Swin transformer with powerful global modeling capabilities, we propose a novel semantic segmentation framework for RS images called ST-U-shaped network (UNet), which embeds the Swin transformer into the classical CNN-based UNet. ST-UNet constitutes a novel dual encoder structure of the Swin transformer and CNN in parallel. First, we propose a spatial interaction module (SIM), which encodes spatial information in the Swin transformer block by establishing pixel-level correlation to enhance the feature representation ability of occluded objects. Second, we construct a feature compression module (FCM) to reduce the loss of detailed information and condense more small-scale features in patch token downsampling of the Swin transformer, which improves the segmentation accuracy of small-scale ground objects. Finally, as a bridge between dual encoders, a relational aggregation module (RAM) is designed to integrate global dependencies from the Swin transformer into the features from CNN hierarchically. Our ST-UNet brings significant improvement on the ISPRS-Vaihingen and Potsdam datasets, respectively.
The code will be available at https://github.com/XinnHe/ST-UNet .
论文创新点
ST-UNet constitutes a novel dual encoder structure of the Swin transformer and CNN in parallel
spatial interaction module (SIM)
feature compression module (FCM)
a relational aggregation module (RAM)
Res2-Unet, a New Deep Architecture for Building Detection From High Spatial Resolution Images
Abstract
Accurate large-scale building detection is significant in monitoring urban development, map updating, change detection, and digital city establishment. However, due to the complicated details of background objects in high spatial resolution remotely sensed images, the models proposed in building detection are still not performing satisfactorily. Particularly, such issue lies in the small buildings, which are easily to be omitted, and the pixels in the bounding area of each building instance can be especially confusing with the background objects. Aiming to deal with such problem, we propose Res2-Unet to employ multi-scale learning at a granular level, rather than the commonly used layer-wise feature learning, to enlarge the scale of receptive fields of each bottleneck layer. It replaces the widely used 3 × 3 convolution on n-channel feature maps with a set of smaller groups, which are organized in a hierarchical structure to enlarge the scale-variability. The general framework is an end-to-end learning network, taking a typical semantic segmentation network structure with encoders to encode the input image into feature maps and decoders to decode the feature maps into binary segmented result image. Moreover, to enhance the building boundary generation ability of our model, a boundary loss function is proposed to improve the detection performance. The proposed framework is evaluated on three public datasets, Massachusetts building dataset, WHU East Asia Satellite dataset and WHU Aerial building dataset. It is compared with the published performances and has achieved the state-of-the-art accuracies. That verifies the robustness of the proposed framework.
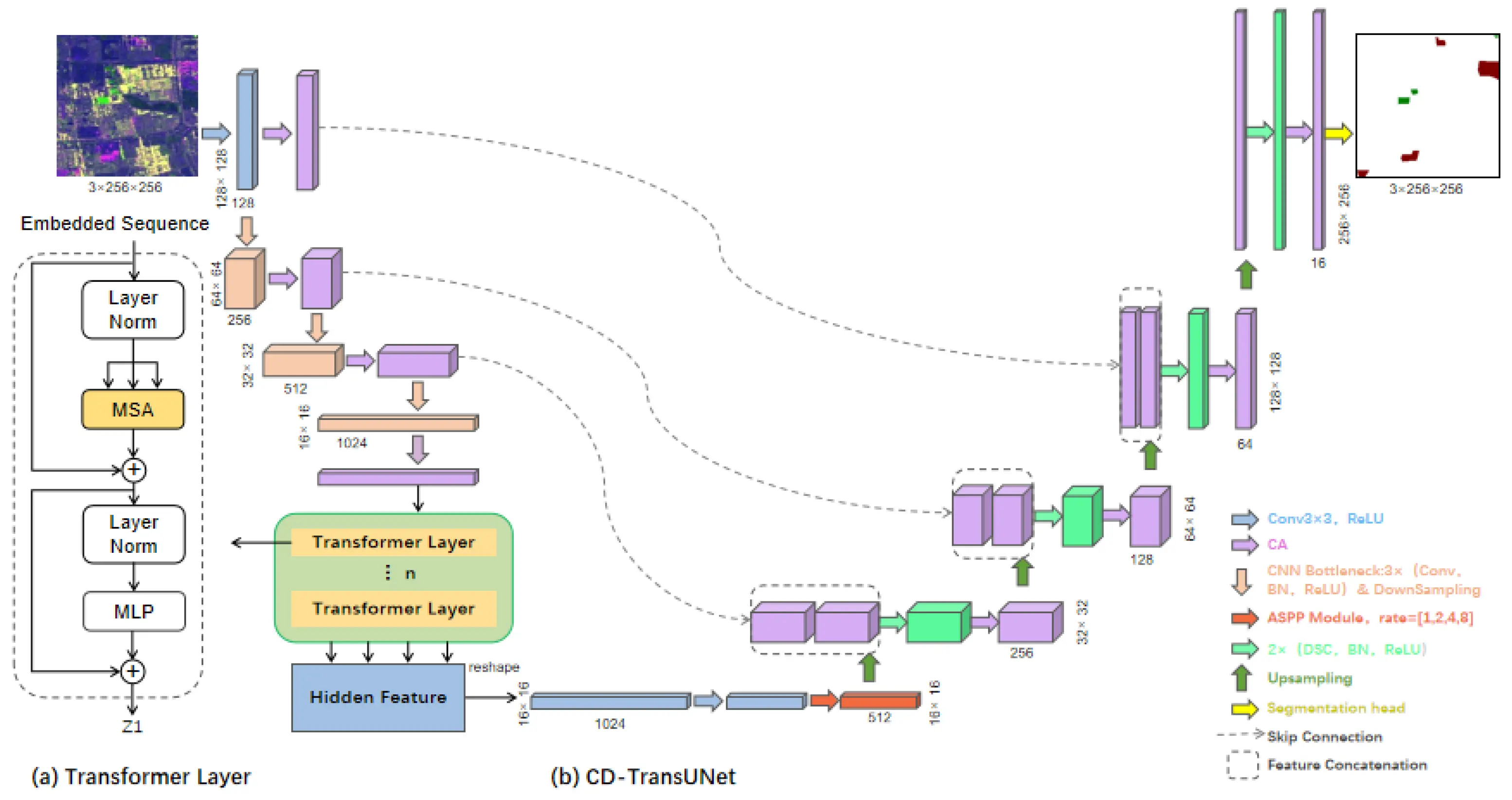
CD-TransUNet:使用 L 波段 SAR 图像检测城市建筑物变化的混合变压器网络
Abstract
城市建筑物的变化检测是目前遥感研究领域的热点,在城市规划、灾害评估和地表动态监测中发挥着至关重要的作用。 SAR图像与传统光学图像相比具有独特的特点,主要包括图像信息丰富、数据量大。然而,目前大多数用于建筑物变化检测的SAR图像都存在漏检小建筑物和边缘分割不佳的问题。因此,本文提出了一种基于深度学习的变化建筑物检测的新方法,我们称之为 CD-TransUNet。需要注意的是,CD-TransUNet 是一个端到端的编解码混合 Transformer 模型,它结合了 UNet 和 Transformer。此外,为了提高特征提取的精度并降低计算复杂度,CD-TransUNet 集成了坐标注意(CA)、多孔空间金字塔池(ASPP)和深度可分离卷积(DSC)。此外,通过将差分图像发送到输入层,CD-TransUNet 可以更专注于构建大规模的变化,而忽略其他土地类型的变化。最后,我们使用一对 ALOS-2(L-band) 采集验证了所提方法的有效性,从其他基线模型获得的对比实验结果表明,CD-TransUNet 的精度要高得多,Kappa值可以达到0.795。此外,低漏报和准确的建筑物边缘反映了所提出的方法更适合建筑物变化的检测任务。
论文创新改进点
坐标注意(CA)注意力机制
多孔空间金字塔池(ASPP)
深度可分离卷积(DSC)
结构
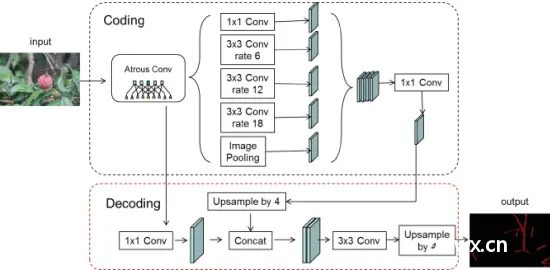
使用 DeepLabV3+ 模型对荔枝枝进行语义分割
https://ieeexplore.ieee.org/document/9186684
Abstract
荔枝采摘时常采用夹剪枝条的方式,枝条很小,很容易被采摘机器人损坏。因此,荔枝枝条的检测尤为重要。本文提出了一种基于全卷积神经网络的语义分割算法,对荔枝枝进行语义分割。首先,DeepLabV3+语义分割模型与Xception深度可分离卷积特征相结合。其次,利用迁移学习和数据增强来加速收敛,提高模型的鲁棒性。第三,采用编解码结构,减少网络参数的数量。解码结构使用上采样和浅层特征进行融合,并分配相同的权重以确保浅层特征语义和深层特征语义均匀分布。第四,使用atrous spatial pyramid pooling,我们可以在不增加权重参数数量的情况下更好地提取语义像素位置信息。最后,使用不同大小的空洞卷积来保证小目标的预测精度。实验结果表明,使用 Xception_65 特征提取网络的 DeepLabV3+ 模型获得了最好的结果,达到了 0.765 的平均交集比(MIoU),比原始 DeepLabV3+ 模型的 0.621 的 MIoU 提高了 0.144。同时,使用Xception_65网络的DeepLabV3+模型具有更强的鲁棒性,在检测精度上远超PSPNet_101和ICNet。上述结果表明,所提出的模型产生了更好的检测结果。可为抓手采摘机器人寻找果枝提供有力的技术支持,为农业自动化中的目标检测识别问题提供新的解决方案。
结构
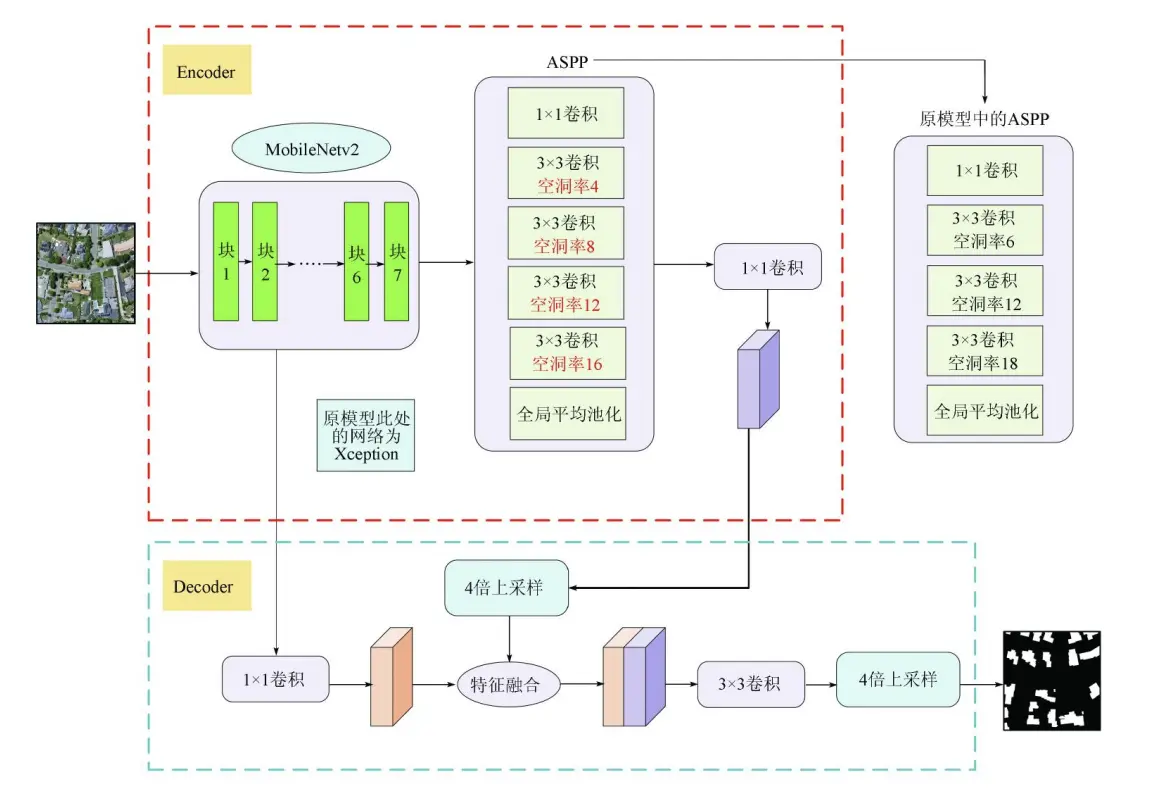
改进DeepLabV3+的高效语义分割
Abstract
针对目前高精度的语义分割模型普遍存在计算复杂度高、占用内存大,难以在硬件存储和计算力有限的嵌入式平台部署的问题,从网络的参数量、计算量和性能3个方面综合考虑,提出一种基于改进DeepLabV3+的高效语义分割模型.该模型以MobileNetV2为骨干网络,在空洞空间金字塔池化(AS-PP)模块中并联混合带状池化(MSP),以获取密集的上下文信息;在解码部分引入有效通道注意力(ECA)模块,以恢复更清晰的目标边界;将深度可分离卷积应用到ASPP模块和解码器中用于压缩模型.在PASCAL VOC 2012数据集上的实验中,该模型的网络参数量为4.5×106,浮点计算量为11.13 GFLOPs,平均交并比为72.07%,在计算效率和分割精度之间达到了良好的均衡.
论文创新改进点
MobileNetV2
空洞空间金字塔池化(AS-PP)模块
混合带状池化(MSP)
有效通道注意力(ECA)
深度可分离卷积
结构
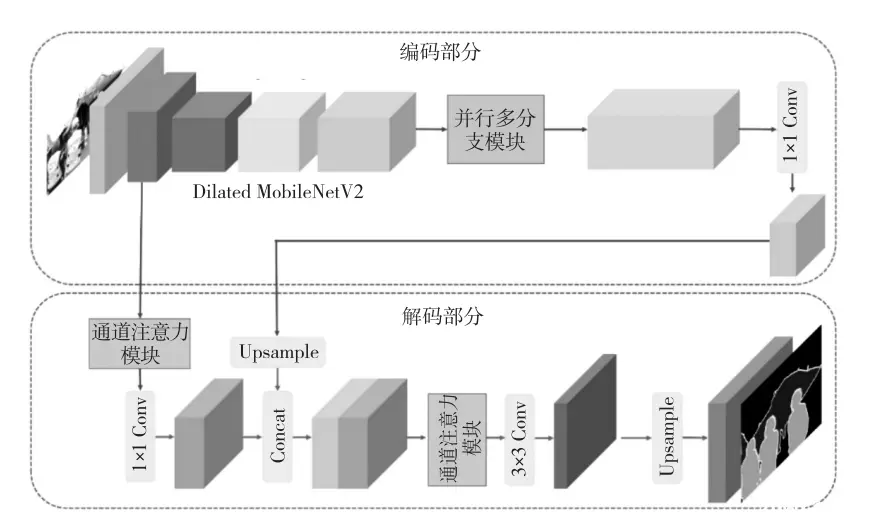
用于场景分割的改进DeepLabV3+算法
Abstract
为了提升室外场景下语义分割的精度,提出一种改进的DeepLabV3+神经网络分割算法.其主干部分采用分组的ResNest网络,使各类目标训练权重占比不同,以密集连接的方式改进空洞空间卷积金字塔池化(ASPP)模块,在不牺牲特征空间分辨率的同时扩大感受野,并且提升特征复用效率.解码端融合编码端提取的3种不同尺度的低层语义特征,以恢复在降采样过程中丢失的空间信息.实验结果表明,在CityScape数据集的检测中,该算法不仅提高了目标的分割准确率,而且对全场景理解和细节处理能力均有明显提升.
论文创新改进点
ResNest网络
DenseNet 网络密集连接的方式
结构
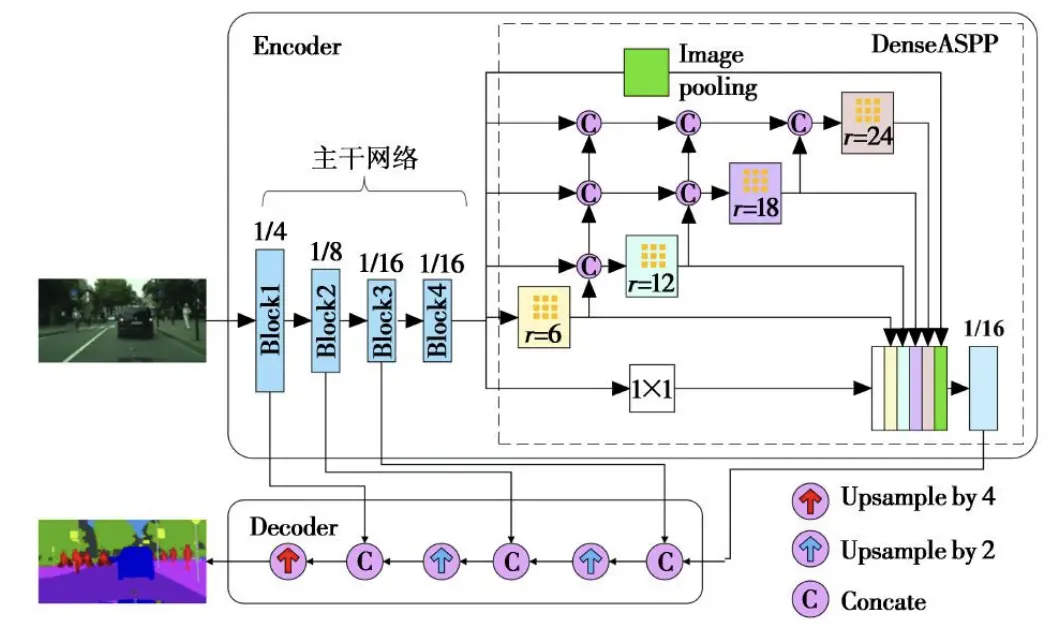
一种轻量级的DeepLabv3+遥感影像建筑物提取方法
Abstract
快速从遥感影像中提取出具有较高精度的建筑物是遥感智能化应用服务的重要研究内容之一.针对Deep-Lab模型对遥感影像建筑物边缘分割不精确、分割大尺度目标存在孔洞现象、网络参数量大等问题,提出一种轻量级DeepLabv3+模型的遥感影像建筑物提取方法.该方法使用轻量级网络MobileNetv2替换DeepLabv3+的主干网络Xception,从而减少参数量、提高训练速度;对空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)的空洞率进行优化组合,提高多尺度语义特征提取效果.改进的模型在WHU和Massachusetts数据集上进行验证实验,结果表明,在WHU数据集中得到的交并比和F1分数分别为82.37%和92.89%,比DeepLabv3+分别提高2.71百分点和2.14百分点,在Massachusetts数据集中的交并比和F1分数比DeepLabv3+分别提高2.04百分点和2.32百分点,训练参数量和训练时间减少,建筑物提取精度得到有效提高,能够满足快速提取高精度建筑物的要求.
结构
四、总结创新常见思路技巧🌟
刨根问底法
此种方法最为直接,即知其然也要知其所以然。如果你提的小改进使得结果变好了,那结果变好的原因是什么?什么条件下结果能变好、什么条件下不能?提出的改进是否对领域内同类方法是通用的?这一系列问题均可以进行进一步的实验和论证。你看,这样你的文章不就丰富了嘛。这也是对领域很重要的贡献。移情别恋法:不在主流任务/会议期刊/数据集上做,而是换一个任务/数据集/应用,因此投到相应的会议或期刊上。这么一来,相当于你是做应用、而不是做算法的,只要写的好,就很有可能被接受。当然,前提是该领域确实存在此问题。无中生有是不可取的,反而会弄巧成拙。写作时一定要结合应用背景来写,突出对领域的贡献。
声东击西法
虽然实际上你就做了一点点提升和小创新,但你千万不能这么老实地说呀。而是说,你对这个A + B的两个模块背后所代表的两大思想进行了深入的分析,然后各种画图、做实验、提供结果,说明他们各自的局限,然后你再提自己的改进。这样的好处是你的视角就不是简单地发一篇paper,而是站在整个领域方法论的角度来说你的担忧。这种东西大家往往比较喜欢看、而且往往看题目和摘要就觉得非常厉害了。这类文章如果分析的好,其价值便不再是所提出的某个改进点,而是对领域全面而深刻的分析。
移花接木法
不说你提点,甚至你不提点都是可以的。怎么做呢?很简单,你就针对你做的改进点,再发散一下,设计更大量的实验来对所有方法进行验证。所以这篇paper通篇没有提出任何方法,全是实验。然后你来一通分析(分析结果也大多是大家知道的东西)。但这不重要啊,重要的是你做了实验验证了这些结论。典型代表:Google家的各种财大气粗做几千个实验得出大家都知道的结论的paper,比如最近ICLR’22这篇:Exploring the Limits of Large Scale Pre-training
代码
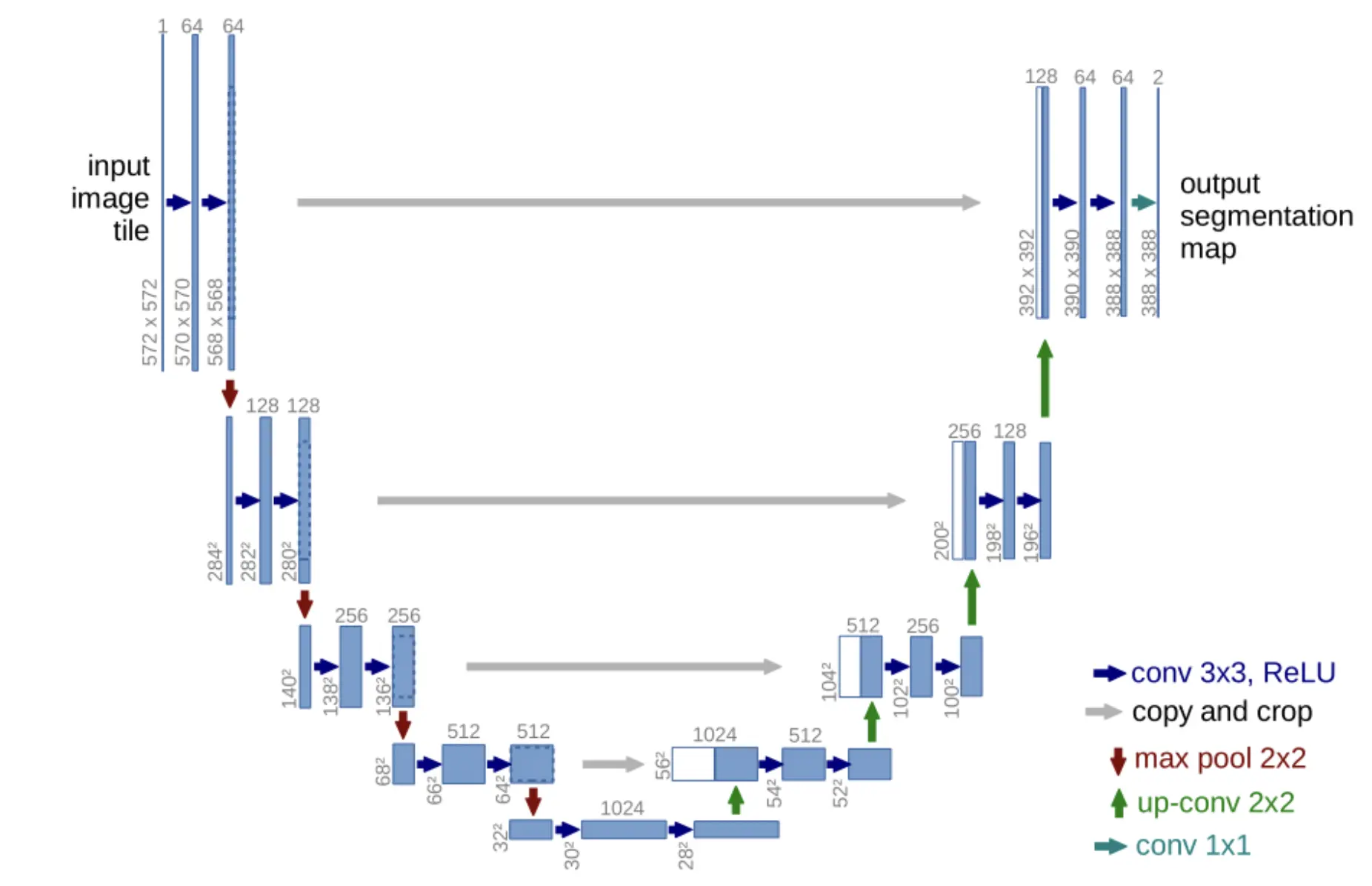
import numpy as np import osimport skimage.io as ioimport skimage.transform as transimport numpy as npfrom keras.models import *from keras.layers import *from keras.optimizers import *from keras.callbacks import ModelCheckpoint, LearningRateSchedulerfrom keras import backend as kerasdef unet(pretrained_weights = None,input_size = (256,256,1)): inputs = Input(input_size) conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs) conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1) conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2) conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3) pool3 = MaxPooling2D(pool_size=(2, 2))(conv3) conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3) conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4) drop4 = Dropout(0.5)(conv4) pool4 = MaxPooling2D(pool_size=(2, 2))(drop4) conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4) conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5) drop5 = Dropout(0.5)(conv5) up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5)) merge6 = concatenate([drop4,up6], axis = 3) conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6) conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6) up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6)) merge7 = concatenate([conv3,up7], axis = 3) conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7) conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7) up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7)) merge8 = concatenate([conv2,up8], axis = 3) conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8) conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8) up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8)) merge9 = concatenate([conv1,up9], axis = 3) conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9) conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9) conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9) conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9) model = Model(input = inputs, output = conv10) model.compile(optimizer = Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy']) #model.summary() if(pretrained_weights): model.load_weights(pretrained_weights) return model
deeplabv3+
import torch.nn as nnfrom torch.nn import functional as Fimport torchimport numpy as npfrom models.resnet import resnet101from inplace_abn import InPlaceABNSyncclass ASPP(nn.Module): def __init__(self, in_channel): super(ASPP, self).__init__() self.pool = nn.AdaptiveAvgPool2d((1,1)) self.conv1 = nn.Conv2d(in_channel, 256, kernel_size=1, padding=0, dilation=1, bias=False) self.bn1 = InPlaceABNSync(256) self.conv2 = nn.Conv2d(in_channel, 256, kernel_size=1, padding=0, dilation=1, bias=False) self.bn2 = InPlaceABNSync(256) self.conv3 = nn.Conv2d(in_channel, 256, kernel_size=3, padding=6, dilation=6, bias=False) self.bn3 = InPlaceABNSync(256) self.conv4 = nn.Conv2d(in_channel, 256, kernel_size=3, padding=12, dilation=12, bias=False) self.bn4 = InPlaceABNSync(256) self.conv5 = nn.Conv2d(in_channel, 256, kernel_size=3, padding=18, dilation=18, bias=False) self.bn5 = InPlaceABNSync(256) self.conv6 = nn.Conv2d(256 * 5, 256, kernel_size=1, padding=0, dilation=1, bias=False) self.bn6 = InPlaceABNSync(256) self.relu = nn.ReLU(inplace=False) self.drop = nn.Dropout2d(0.5) def forward(self, x): batch, _, h, w = x.size() if batch > 1: x1 = self.relu(self.bn1(self.conv1(self.pool(x)))) else: x1 = self.relu(self.conv1(self.pool(x))) x1 = F.interpolate(x1, size=(h, w), mode='bilinear') x2 = self.relu(self.bn2(self.conv2(x))) x3 = self.relu(self.bn3(self.conv3(x))) x4 = self.relu(self.bn4(self.conv5(x))) x5 = self.relu(self.bn5(self.conv5(x))) x = torch.cat((x1, x2, x3, x4, x5), 1) x = self.drop(self.relu(self.bn6(self.conv6(x)))) return x class DeepLabV3Plus(nn.Module): def __init__(self, num_classes=19, os=16): super(DeepLabV3Plus, self).__init__() self.resnet = resnet101(os=os, pretrained=True) self.aspp = ASPP(2048) self.conv1 = nn.Conv2d(256, 48, kernel_size=1, padding=0) self.bn1 = InPlaceABNSync(48) self.relu = nn.ReLU(inplace=False) self.conv2 = nn.Conv2d(304, 256, kernel_size=3, padding=1) self.bn2 = InPlaceABNSync(256) self.conv3 = nn.Conv2d(256, num_classes, kernel_size=1, padding=0) def forward(self, x): x, low_level_feature = self.resnet(x) x = self.aspp(x) low_level_feature = self.relu(self.bn1(self.conv1(low_level_feature))) x = F.interpolate(x, size=low_level_feature.size()[2:], mode='bilinear') x = torch.cat((x, low_level_feature), dim=1) x = self.relu(self.bn2(self.conv2(x))) x = self.conv3(x) return x
知乎参考链接
zhihu.com/question/528654768/answer/2452424449
zhihu.com/question/36757207/answer/2153876227
上一篇: 值得收藏!2024年人工智能顶级会议投稿信息汇总(机器学习领域)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。