“RISCV+AI”观察报告
KGback 2024-10-02 16:01:04 阅读 52
概述
设计方案
主要有两种设计方案。
RISCV核+ASIC
RISCV核是标准的基于RISCV指令集的CPU设计,ASIC部分通常是基于RISCV自带的向量扩展指令集构建的向量处理器,或是自定义的矩阵计算单元。
根据CPU+AI ASIC部件的接口可以分为紧耦合和松耦合的设计1。
CPU+AI AISC紧耦合设计
紧耦合设计最大的特征是软件对硬件透明,具体设计时以CPU主干为骨架,将AI计算单元集成在CPU内部,共享PC(程序计数器)、寄存器堆等流水线单元,仅在执行单元部分增加了矩阵或向量单元,适用于低功耗场景
将加速部件作为Core流水线的执行部件,通过自定义的指令来控制部件,这种方式有如下优势:
1)普通指令核自定义指令共享软件栈,软件设计更加简单
2)比较容易升级
3)逻辑设计比AISC IP设计与集成工作量更小
4)通过自定义的设计工具,该设计方案可以减少投入市场时间
强互操作的设计
这种场景设计下的CPU流水段和执行部件有很强的互操作性,具体表现可以是:
自定义寄存器,通过自定义load/store指令将数据在寄存器和内存间交互
玄铁C907 矩阵计算扩展
采用传统向量计算的AI增强技术带来的性能提升难以匹配高速发展的应用需求,这也使得各CPU厂商的研究目光从向量计算逐渐转向矩阵计算。相比于向量计算,矩阵计算能够达到更高的数据复用度,从而有效降低带宽需求,并且由于数据搬运等的减少在能效上也具备优势2。
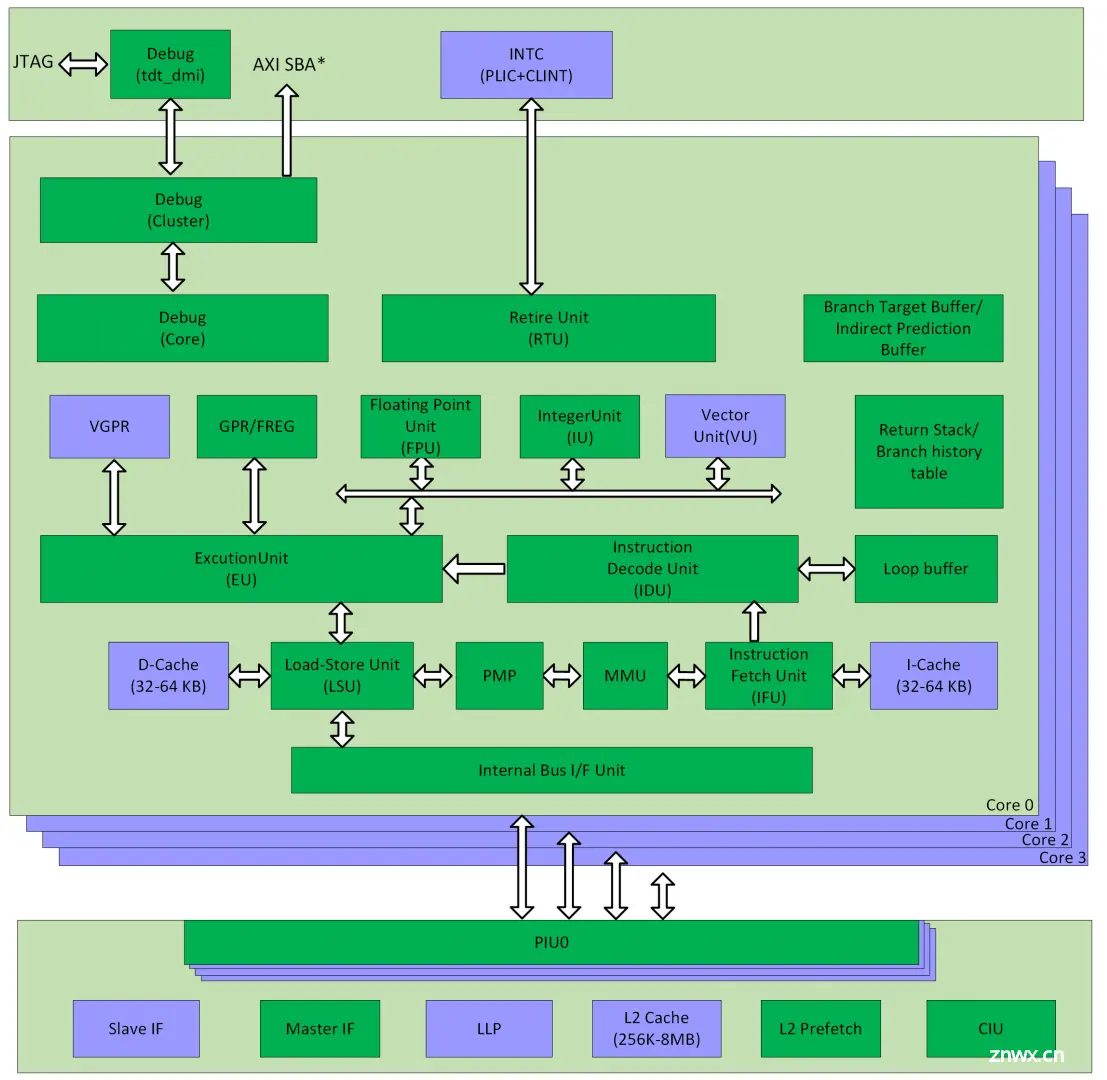
2021年发布的玄铁C907是一款RISC-V架构低成本计算增强的多核处理器,采用9级部分双发顺序流水线架构,主要应用于视觉终端、人机交互、网通无线等领域。玄铁C907首次搭载了玄铁Matrix扩展,提供面向AI的浮点/整型矩阵计算能力。
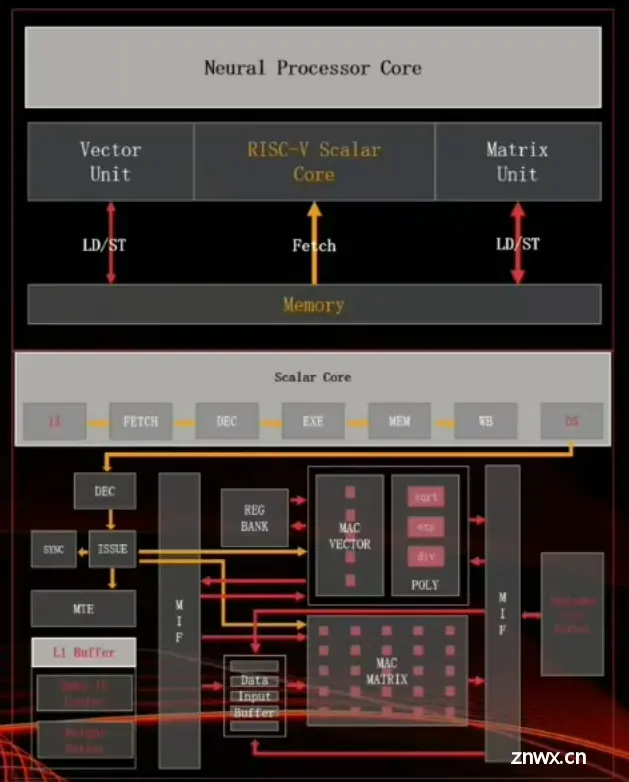
C907 核内子系统主要包含:指令提取单元(IFU)、指令执行单元(IEU)、矢量浮点执行单元(VFPU)、矩阵执行单元(MPU)、存储载入单元(LSU)、虚拟内存管理单元(MMU)和物理内存保护单元(PMP)。
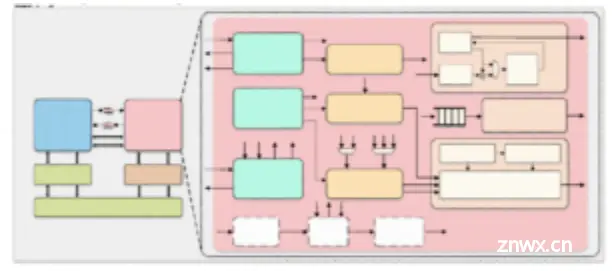
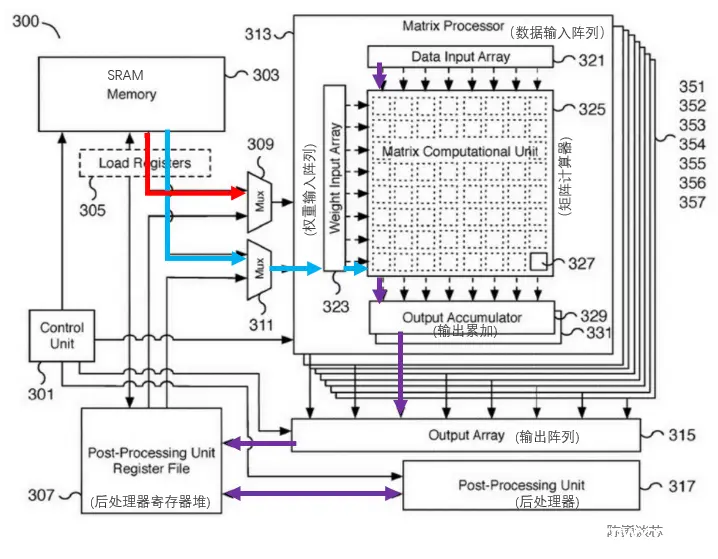
自定义的矩阵扩展指令集(MME,Matrix-Multiply Extension)
将矩阵加速部件集成到CPU流水线中,通过矩阵计算扩展指令执行。
玄铁MME设计过程中借鉴RISC-V矢量扩展指令集的设计思路及实现方式,在编程模型上支持算力的弹性可扩展,通过不同的硬件实现参数选择能够实现单指令矩阵乘法峰值算力从0.5Tops到32Tops的覆盖。
玄铁MME扩展了8个二维矩阵寄存器,推荐采用4个寄存器作为累加寄存器使用存储中间C结果,A/B操作数各占用2个矩阵寄存器,使得A/B操作数的数据复用度均为2以降低访存带宽需求。
矩阵加速部件的设计玄铁团队给出了两种实现方案(复用向量寄存器以及采用单独的矩阵寄存器)的对比:
Jiang Zhao@XUANTIE: Architectures for Matrix Extension in CPU
最终仍然采用了单独的矩阵寄存器方案,原因如下3:
独立的编程模型更符合市场的需求独立的矩阵扩展对开发者更友好,开发者无需考虑寄存器复用带来的影响分离的架构在硬件电路上更容易实现独立的编程模型能够辅助芯片的热设计
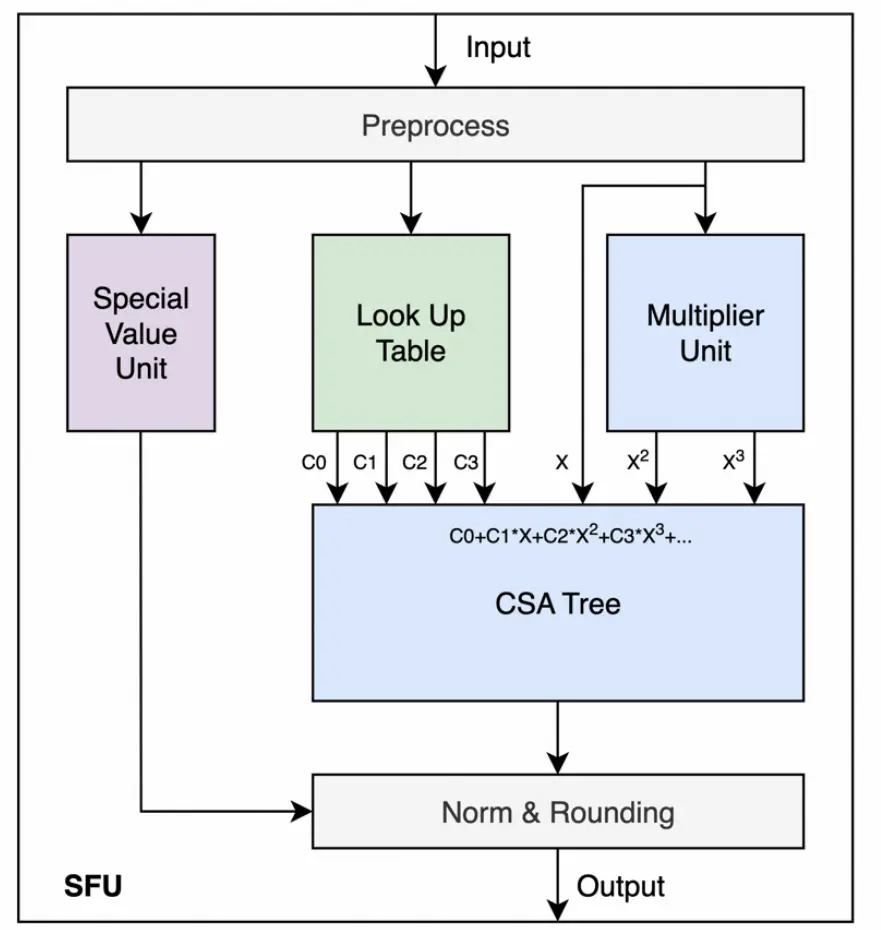
玄铁SFU(Special Function Unit)向量扩展指令
该指令集针对神经网络中的激活函数等特殊函数(比如SIGMOID、TANH、SOFTMAX和GELU等)的计算作加速。
这些激活函数通常借助指数函数及相应多项式组合进行计算。早在1999年,Schraudolph[1]就提出了一种指数函数的快速近似计算方法,只需要通过一次乘法和一次加法运算便可以得到指数运算的结果,但是对于FP32数据来说,其精度只能精确到小数点后6位。目前常用的指数函数的近似计算方法,是利用泰勒展开进行计算,例如玄铁团队的csi-nn2计算库[2]和sleef计算库[3]均采用七阶泰勒展开的近似计算方式,其优势是可以得到较为精确的结果,但也存在计算较为复杂且延迟高的不足。Andes团队支持指数函数运算的硬件加速,采用七阶泰勒展开的计算方式,使用多个乘累加单元进行并行计算。尽管该硬件加速方案实现了较低的计算延迟,但是多个乘累加单元也显著增加了硬件资源的消耗4。
SFU的硬件架构

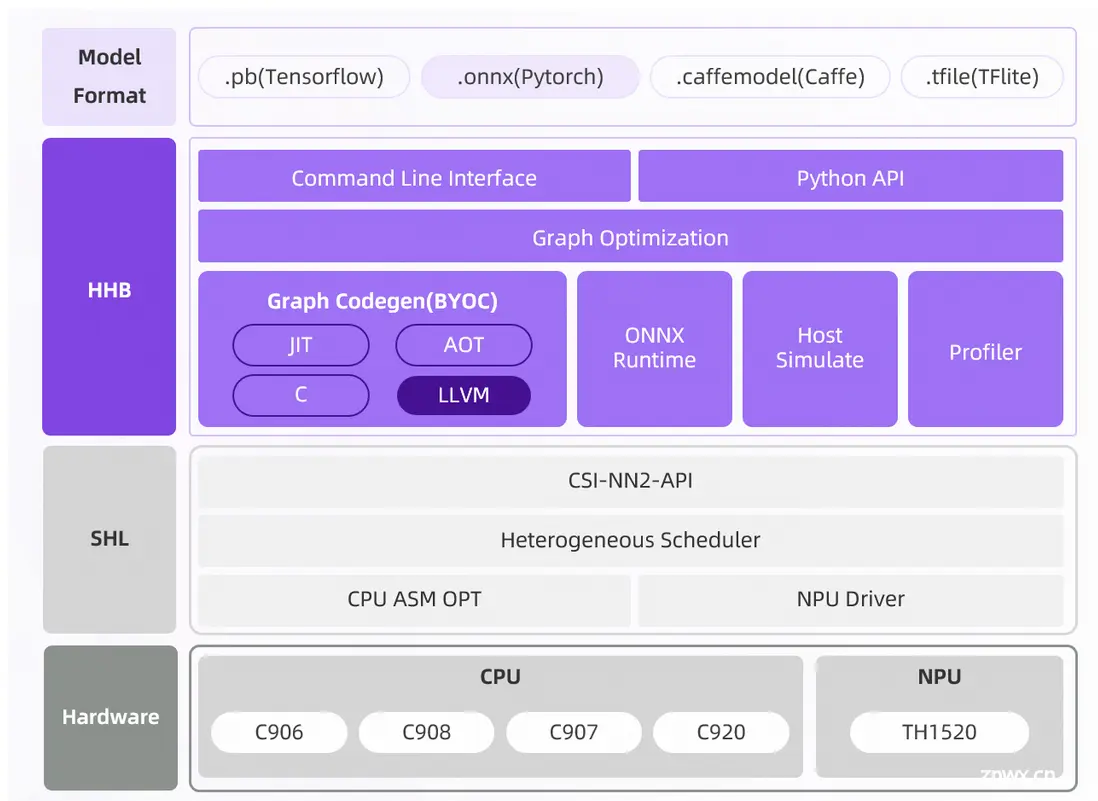
神经网络模型部署工具集(HHB,Heterogeneous Honey Badger tools collection)
包括编译优化、性能分析、过程调试、结果模拟等一系列部署时所需的工具,支持包括玄铁C907矩阵扩展引擎在内的玄铁CPU系列处理器。
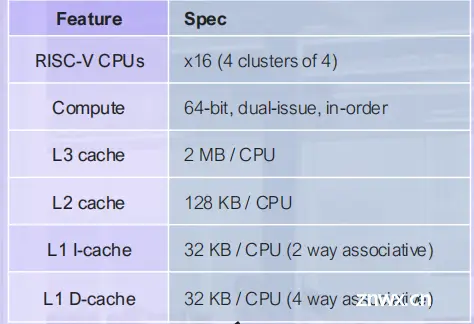
PPA
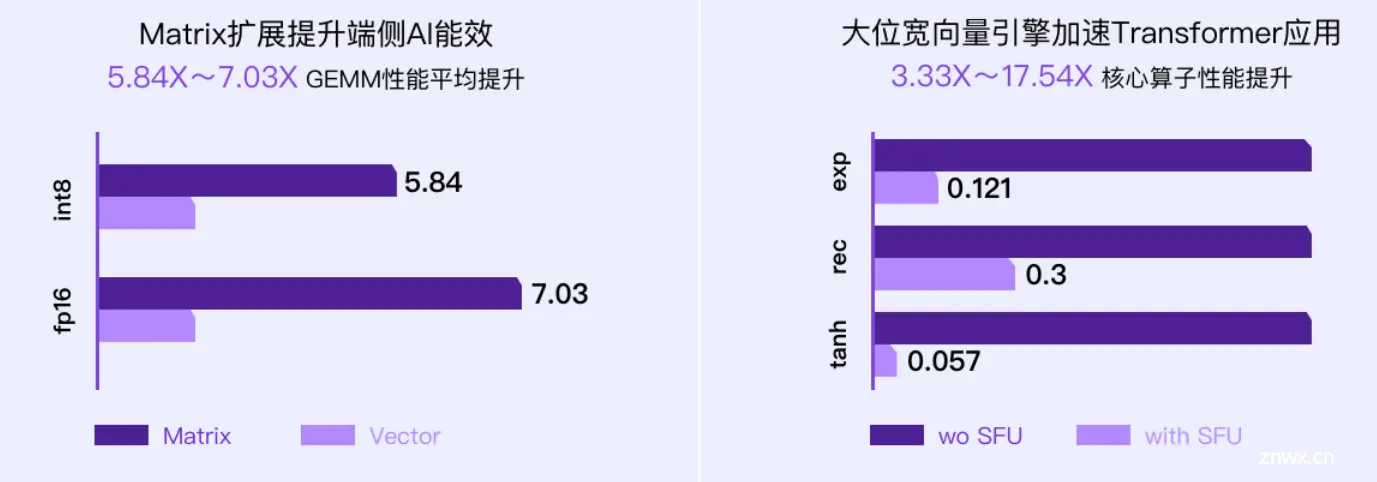
矩阵计算扩展指令的加速
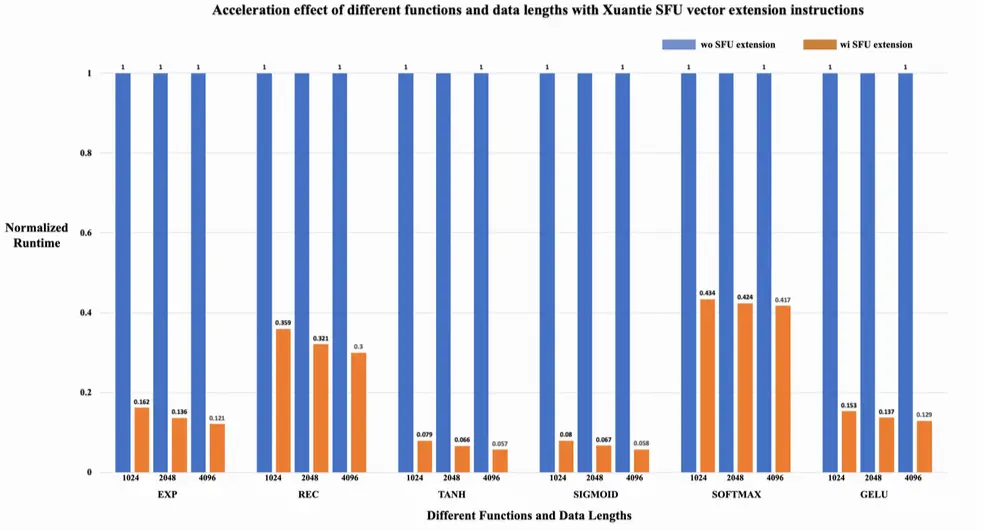
SFU扩展指令集的加速效果4
对于EXP函数运算,计算时间减少80%以上;对于REC函数运算,计算时间减少60%以上;对于TANH函数运算,计算时间减少90%以上;对于SIGMOID函数运算,计算时间减少90%以上;对于SOFTMAX函数运算,计算时间减少90%以上;对于GELU函数运算,计算时间减少80%以上。
玄铁C906/908/910/920 向量计算扩展
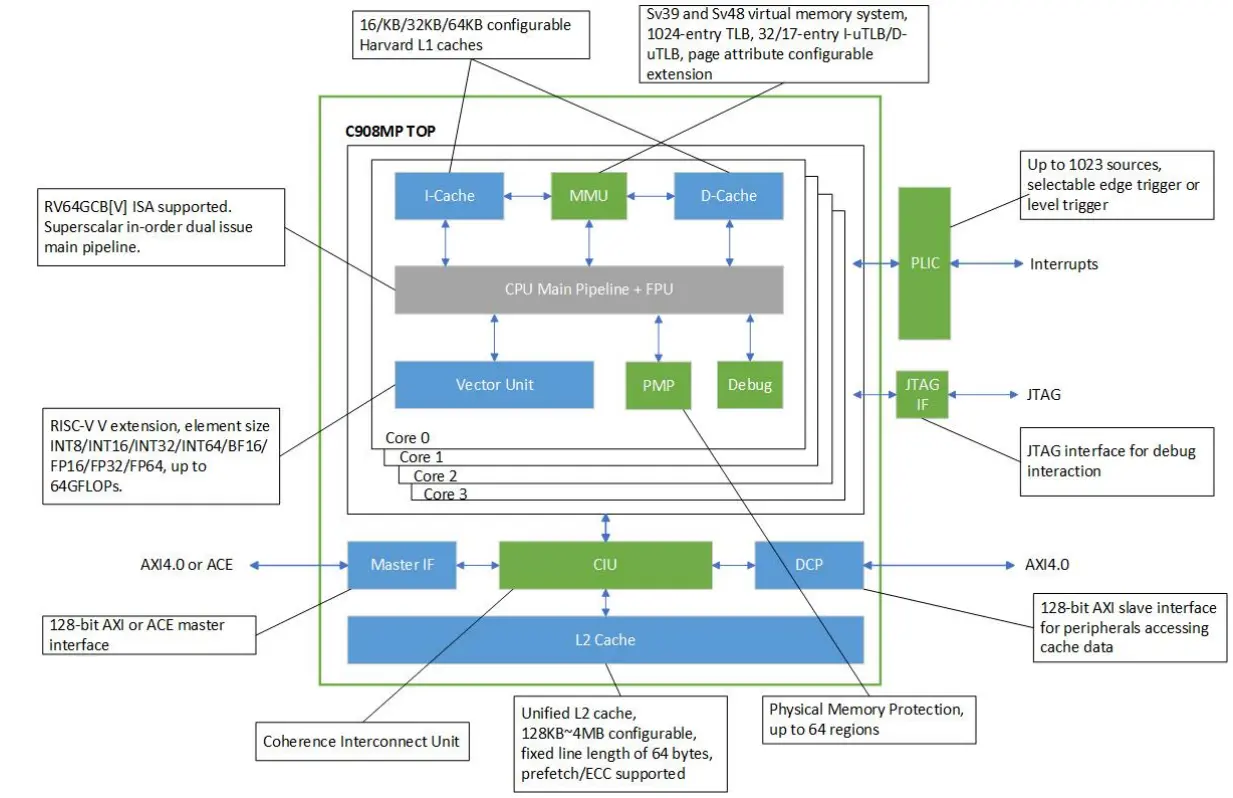
C908架构图
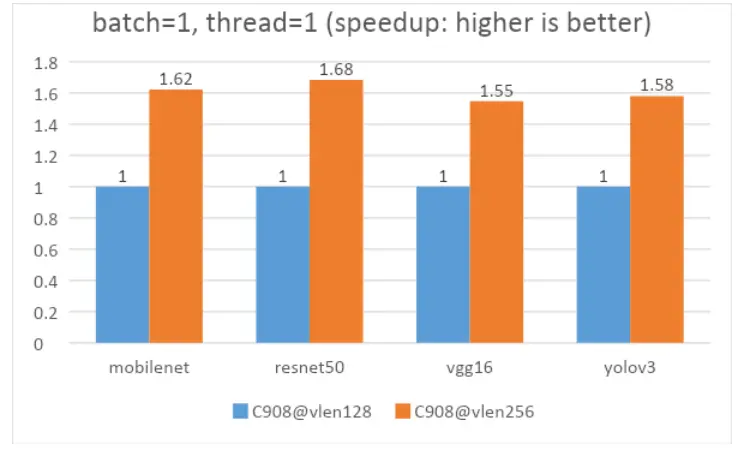
2022年发布的玄铁C908是一款兼容RISC-V架构的64位高能效处理器,支持同构多核架构,支持多cluster,每个cluster支持1~4个C908核心,User模式支持RV64及RV32模式。采用9级双发按序流水线,典型工作频率>2GHz,通过指令融合技术进一步提升流水线效率,实现了卓越的能效比。兼容RVA22标准,同时兼容RISC-V最新Vector1.0标准以进一步提升AI算力。
如图为C908的架构图:
C920架构图
2021年发布的C920MP 是基于 RISC-V 指令架构的 64 位高性能多核心处理器,主要面向对性能要求严格的边缘计算领域,如边缘服务器、边缘计算卡、高端机器视觉、高端视频监控、自动驾驶、移动智能终端、5G 基站等。C920MP 采用同构多核架构,支持 1~4 个 C920 核心可配置。每个 C920 核心采用自主设计的微体系结构,并重点针对性能进行优化,引入 3 译码 8 执行的超标量架构和多通道的数据预取等高性能技术。
如图为C920微体系结构图:
C908核微架构参考:
XuanTie C908: High-performance RISC-V Processor Catered to AIoT Industry
官方网站C908
PPA
与C906性能对比:
XuanTie C908 Accelerates AI with Software and Hardware Fusion
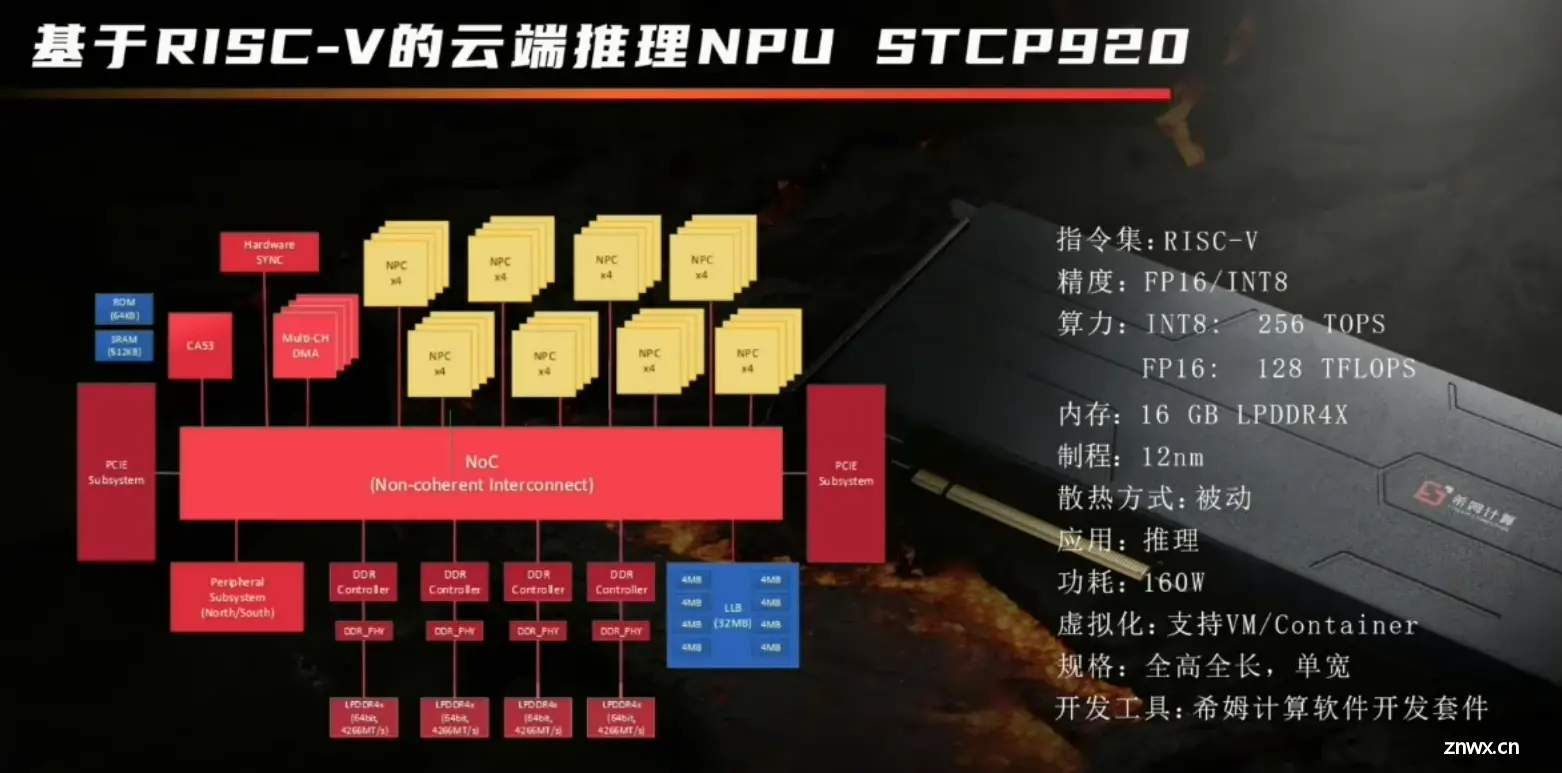
希姆计算 STCP920
32个加速计算核通过NoC组成的加速卡。
32个NPC(神经网络处理核)
芯片架构
NPC架构
基于RVV的向量执行单元+自行设计的矩阵计算单元。
希姆计算@玄铁开发者日:云端AI计算的RISC-V DSA架构
2024 RISC-V 中国峰会@B站:基于 RISC-V 云端推理 NPU 的大模型应用实践 - 王得科 (广州希姆半导体 研发副总裁)
弱操作性的设计
弱操作性的设计中指令与执行部件的交互较少,通常用作控制作用,包括:
加速部件的访存操作通过DMA控制器经外部总线接口访问
CPU+AI AISC松耦合设计
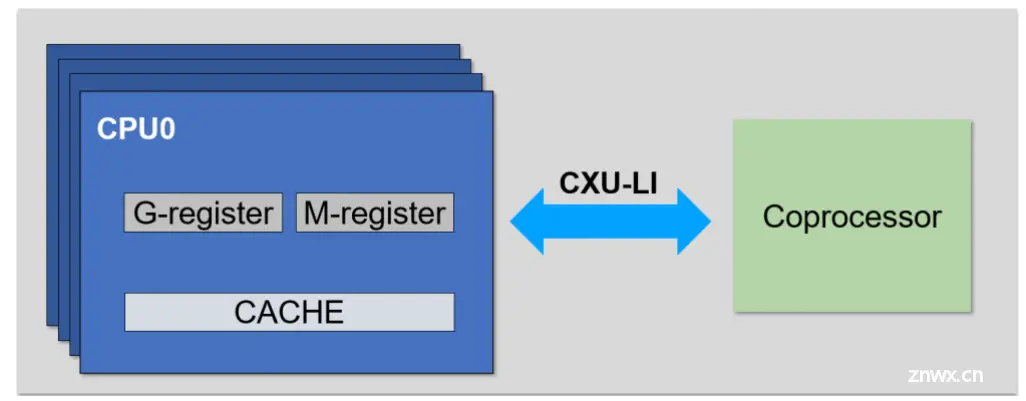
松耦合最大的特征是AI计算单元外挂在CPU上,有自己独立的流水线、寄存器堆、缓存等。它是“协处理器”,可以接收来自一个或多个CPU的指令,异步地执行不同CPU提交过来的任务。协处理器扩展一般连接到主处理器的外设总线上,通过总线读写来控制加速运算,因此需要大量的软件工作,然而由于总线接入了各种设备,其工作频率较低,因此协处理器与内核的数据传输性能也会降低5。
和CPU直连的协处理器设计
在高性能场景,为了解决总线频率过低的问题,提高协处理器的工作效率,需要一个与内核直接交互的桥梁将扩展的协处理器与内核完美耦合,例如ROCC接口、EAI 接口等,这种直连的方式可以有效地提升性能。
玄铁C910 DSA
复旦大学韩军教授在2022 CNCC会议上发布了基于玄铁C910的DSA设计,玄铁团队以此构建了基于Xuantie C910的 DSA 接口。

韩军@XUANTIE: The First DSA Agile Development on Open Xuantie RISC-V processor
XuanTie DSA tool kit
辅助用户设计自定义指令集,以及是否满足设计的性能目标,工具将会负责指令编码,工具链和SDK,同时构建验证环境
XuanTie DSA design in RISC-V
通过轻量化协议接口连接
接口协议本身无需软件驱动,通过AXI、互连网络等连接,对AI加速部件的控制需要驱动适配。
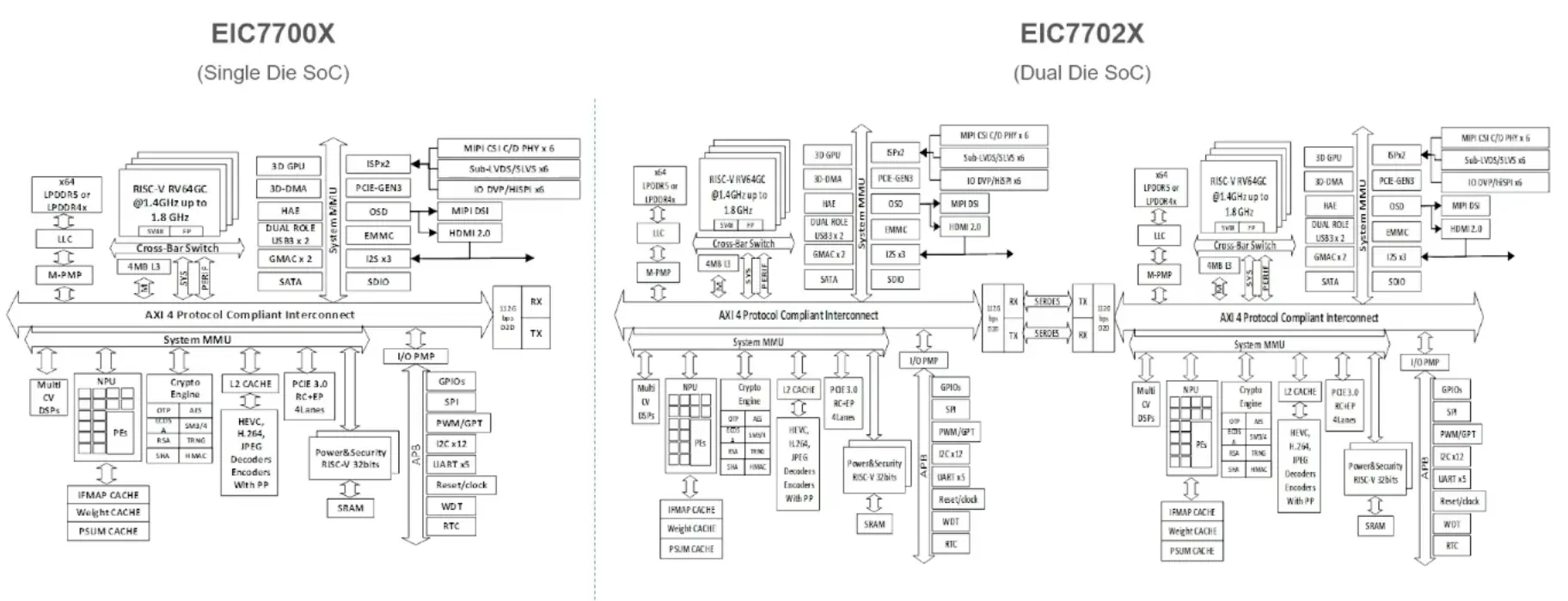
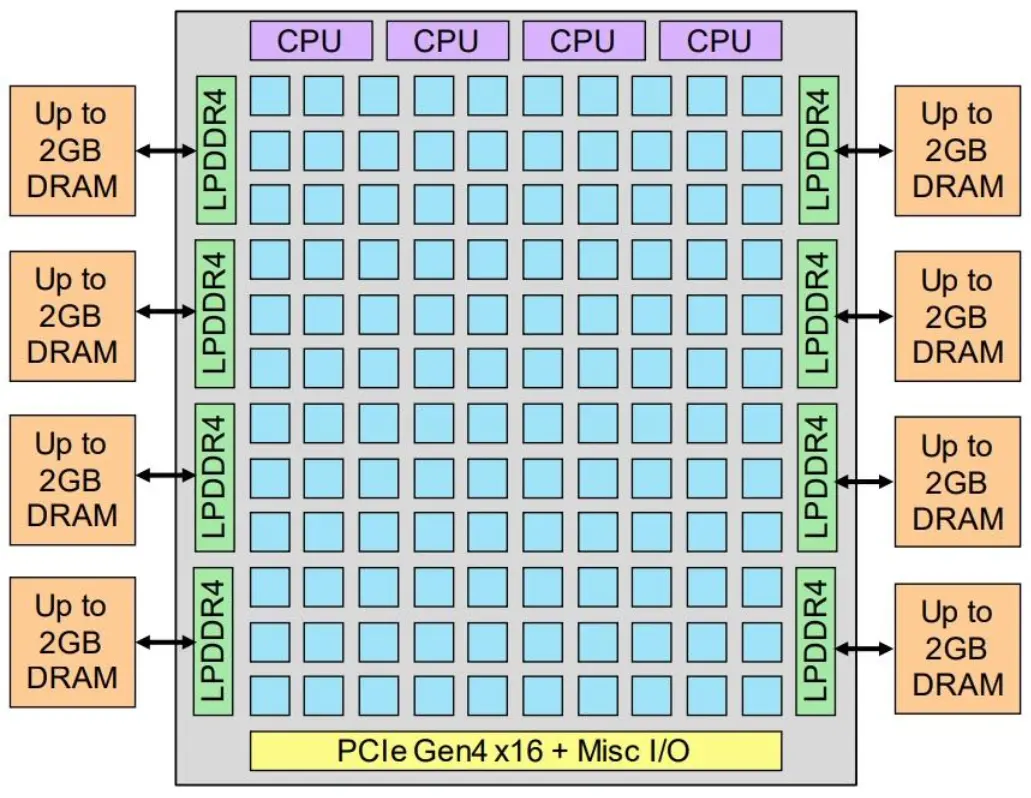
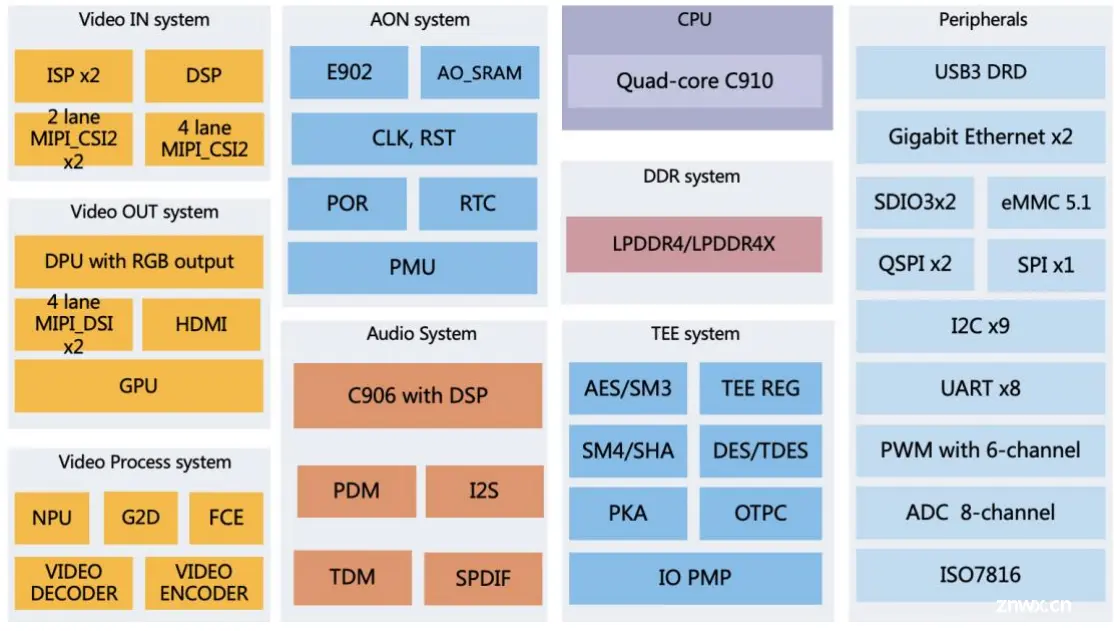
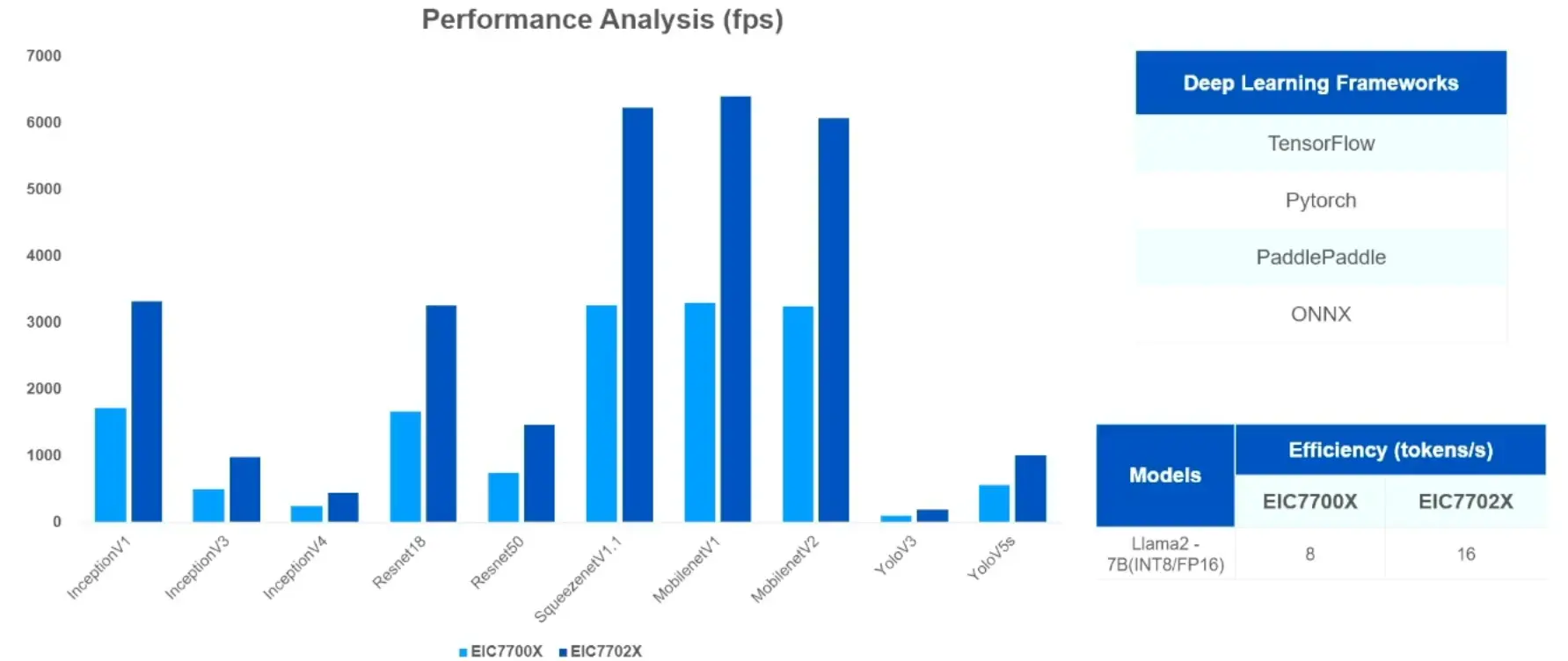
奕斯伟 EIC7702X
2024年上半年流片成功,两个EIC7702 Die通过先进封装技术连在一起,每个DIE采用RISC-V核+NPU+GPU的计算架构。
CPU采用SiFive P550NPU算力 40 TOPS@INT8,20TOPS@INT16, 20FLOPS@FP6
图片来源于2024年8月第四届滴水湖中国RISC-V产业论坛奕斯伟报告67:
官网产品手册
AI加速卡应用
PPA
玄铁 TH1520
曳影 1520 是一款低功耗、高性能、高安全、多模态感知和多媒体 AP 能力的边缘端 AI 处理器芯片8。搭载wujian 600 SoC平台,基于多核异构架构,集成 RISC-V 指令架构的四核 C910 和单核C906 处理器。通过C910的向量扩展和独立NPU实现神经网络的协同计算加速。
NN部署:How to Deploy a Neural Network on TH1520
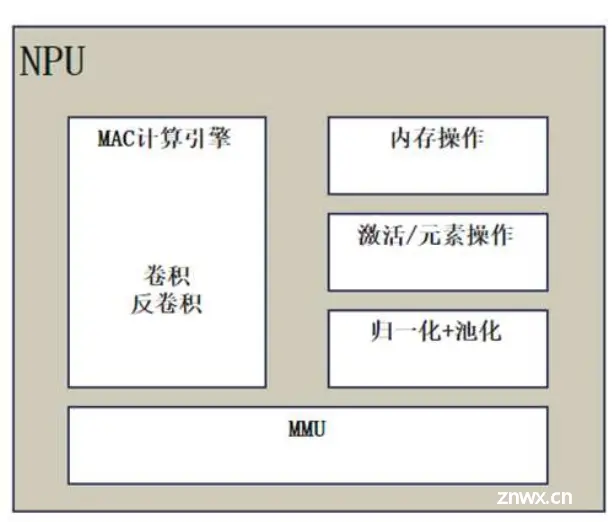
NPU架构
4TOPS@INT8支持 CNN,RNN,DNN 等,支持卷积、激活、单元操作(加法、乘法、最大值、最小值)、池化(最小值、最大值、平均值)、归一化、反卷积无损权重数据压缩,最小化 DDR 带宽需求,降低功耗支持混合量化,支持低精度位深度的权重和激活数据,可以独立分层控制,4~16 位互操作性支持片上缓存,存储网络中间层数据,可与 GPU 芯片内交互数据,减小网络运行对 DDR 带宽需求,NPU 不用时,缓存可共享给其它核使用
基于RISCV轻量化Core集成的众核处理器
采用大量的轻量化RISCV核构建SIMD、MIMD,或者SIMT的设计,AI加速计算本身由这些RISCV架构的众核处理器完成。
Celerity
5个RISCV Rocket大core+16x31个RISCV Vanila-5小core+AI计算专用模块小core集群采用mesh网络连接,Vanilla结构简洁易用,采用了RV32IM指令集,5级流水线,有序发射
专用计算模块则由专门用于AI计算的**二值神经网络(Binarized Neural Network,BNN)**核心组成。该BNN核心可直接支持13.4M大小的9层模型(包括一层定点卷积层,6层二值卷积层与2层全连接层)。专用级功能单一,却具有最高的能效9。

官方链接
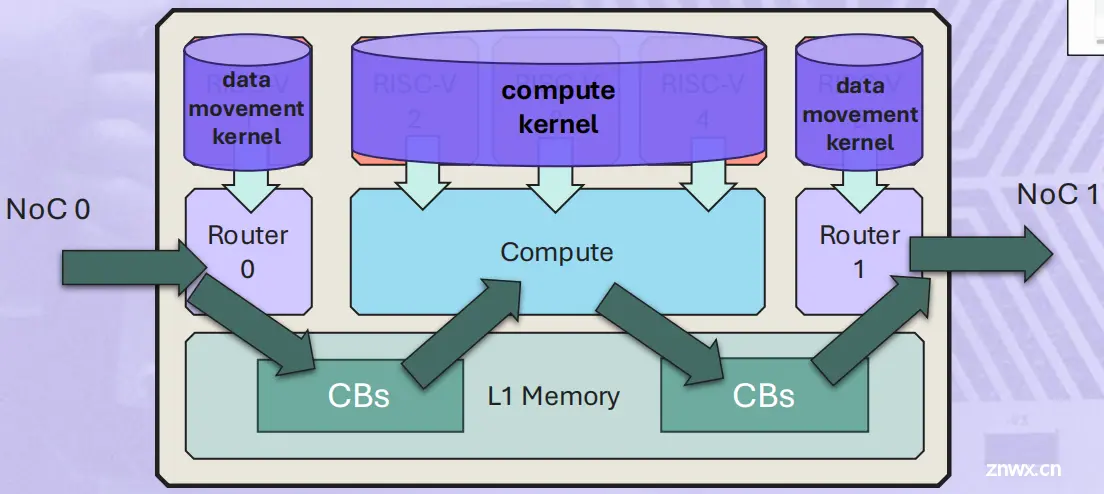
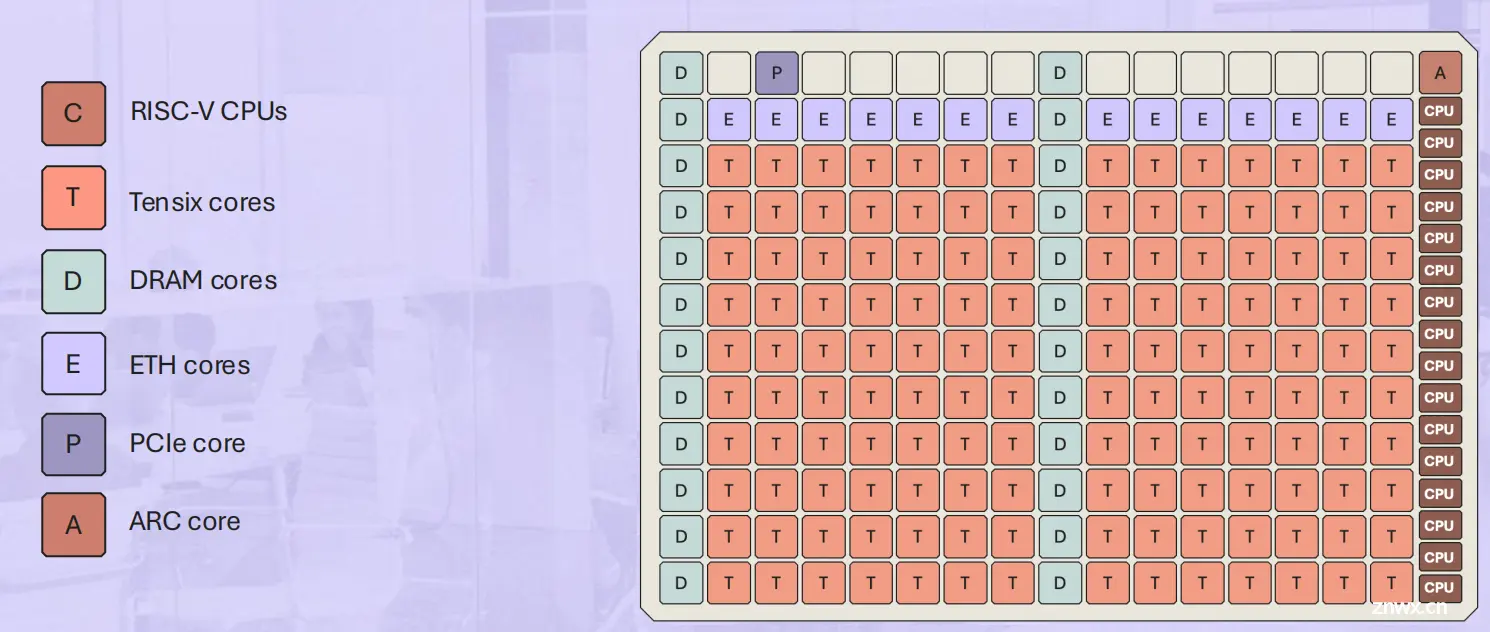
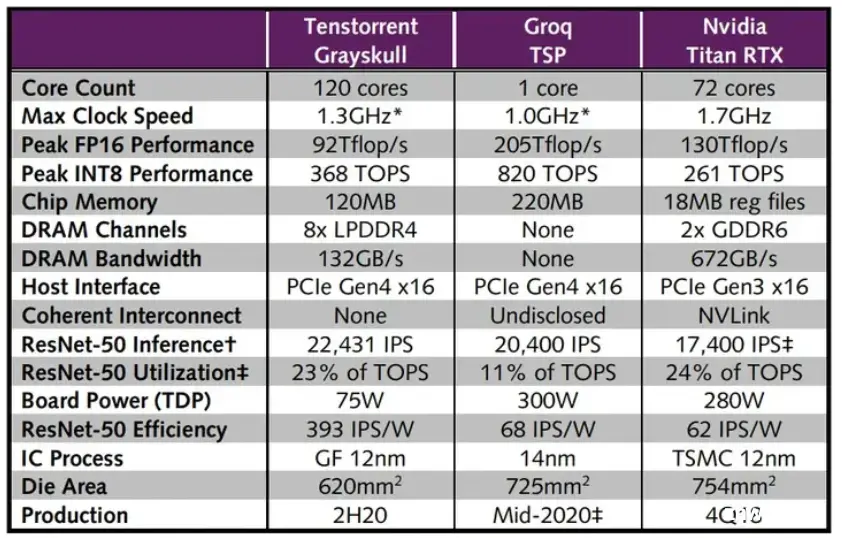
Tenstorrent Grayskull
发布于2021年高性能的AI 加速器设计,基于RISCV架构的Tensix Core构建
120个Tensix Core12nm276 TOPS @FP8368 TOPS@INT8100 GB/s LPDDR4Gen4x16
芯片架构
120个Tensix Core通过2D torus互连,四个Synopsys ARC CPU来管理这120个小核的工作10。
PPA

Tenstorrent Wormhole
发布于2022年可扩展的基于网络互连的AI处理器
80 Tensix+ Cores12nm328 TFLOPS@FP8336 GB/s GDDR6Gen4x1616x100 Gbps Ethernet
Tenstorrent Blackhole
发布于2023年的异构的专用的AI计算机
140 Tensix++ Cores6nm745 TFLOPS@FP8512 GB/s GDDR6Gen5x1610x400 Gbps Ethernet16 RISC-V CPU cores
芯片架构
总共752个Baby RISCV小核,16个RISCV大核
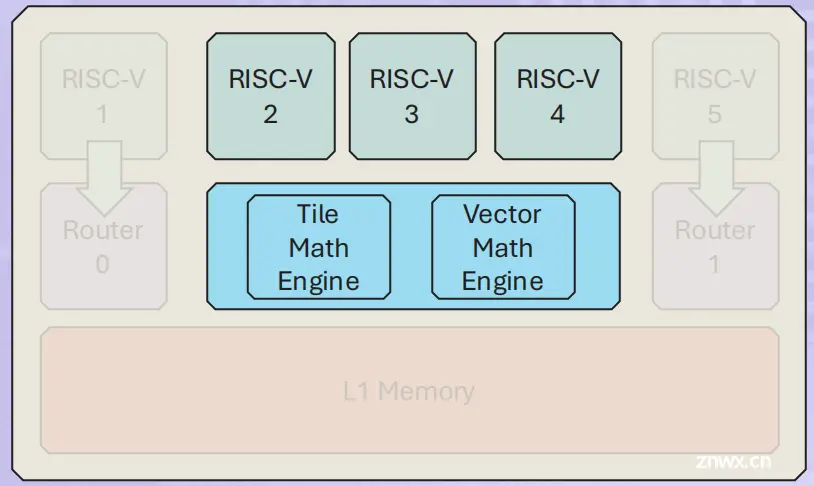
Tensix核架构
包含5个Baby RISCV核,每个都兼容32bit RISCV指令集。
5个核负责的功能如下:
compute部件包括Tile Math计算引擎和Vector Math计算引擎
Baby RISCV核架构

RISCV大核架构
每个核64 位、双发射、顺序执行,这些核排列在四个集群中。
这些Big RISC-V CPU内核足够强大,可以用作运行 Linux 的设备端主机,负责小核内存管理、片外通信和数据处理
Tesla D1
D1 芯片是数据中心级别用于AI训练的产品。
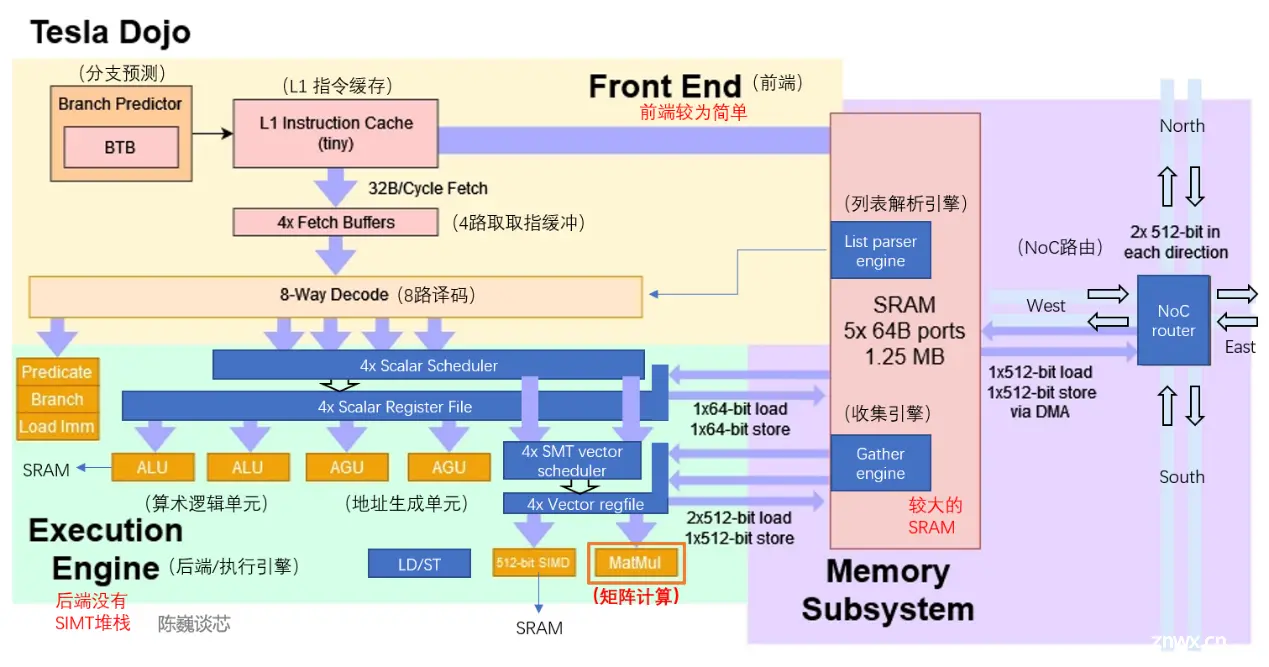
每个Dojo核心是带有向量计算/矩阵计算能力的处理器,具有完整的取指、译码、执行部件。Dojo核心具有类似CPU的 风格,似乎比GPU更能适应不同的算法和分支代码。D1的指令集类似于 RISC-V,处理器运行在2GHz,具有4组8x8矩阵乘法计算单元。同时具有一组自定义向量指令,专注于加速AI计算11。
D1架构
由台积电制造,采用7纳米制造工艺,拥有500亿个晶体管,芯片面积为645mm²每个D1处理器由 18 x 20 的Dojo核心拼接构成362 TFLOPS
Dojo架构
SIMD主要负责激活等特殊功能计算和数据的累加。
矩阵计算单元是Dojo的主要算力原件,负责二维矩阵计算,进而实现卷积、Transformer等计算。
矩阵计算单元

PPA
Dojo的PPA如下图所示:
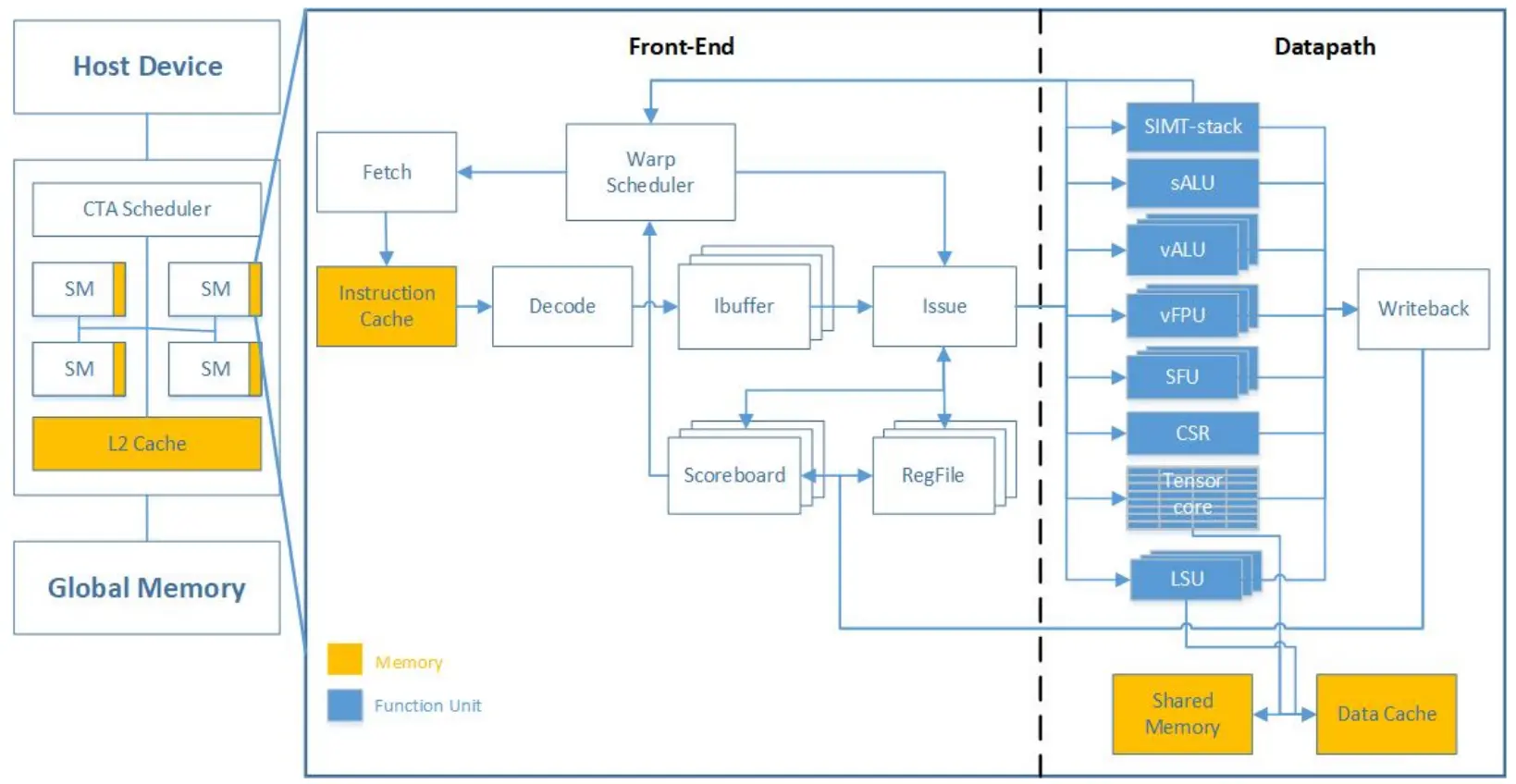
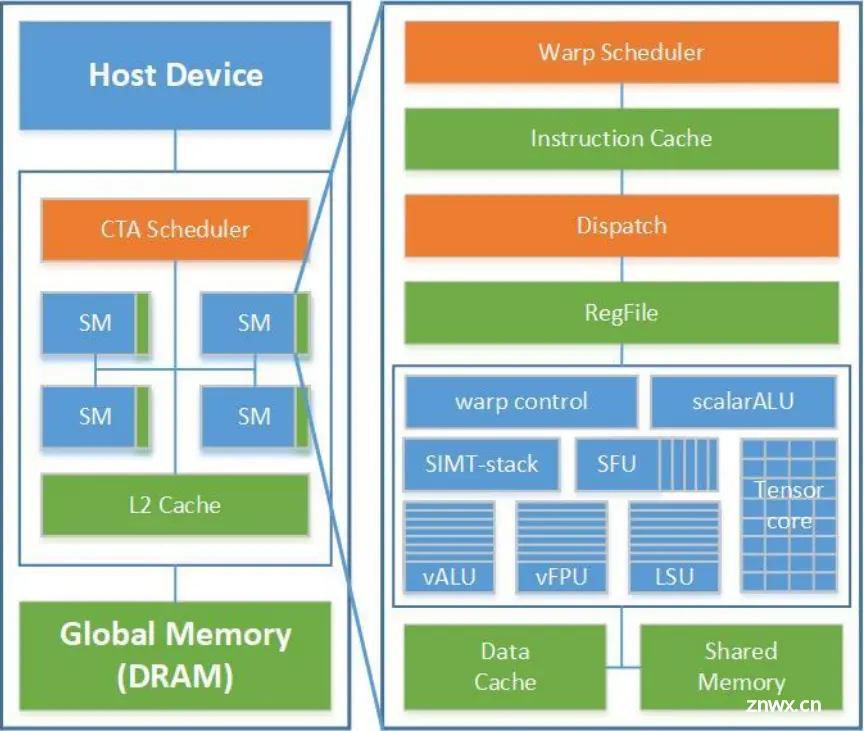
清华“乘影”GPGPU
硬件、模拟器均已开源每个SM可视为一个支持多warp调度的RISC-V向量处理器每个warp可视为一段RVV程序,经由取指、译码、发射,执行后写回寄存器支持多线程束调度的向量处理器, 计算任务的启动、分配、执行

官网
Github链接
参考文献
第四届滴水湖中国RISC-V产业论坛谢涛“万物智联时代RISC-V+AI之路”报告 ↩︎
XUANTIE:玄铁矩阵扩展 提升核心算力加速AI计算 ↩︎
Qiu Jing@XuanTie: Matrix Multiply Extension Instructions ↩︎
XUANTIE:玄铁SFU向量扩展指令 加速AI计算的新路径 ↩︎ ↩︎
XUANTIE: 玄铁协处理器接口方案 实现高效协同计算的桥梁 ↩︎
奕斯伟:高性能AI芯片EIC7702X已成功流片,亮相第四届滴水湖中国RISC-V产业论坛 ↩︎
B站:第四届滴水湖中国RISC-V产业论坛——奕斯伟计算路向峰演讲 ↩︎
XUANTIE: TH1520技术手册 ↩︎
陈巍@CSDN:RISC-V AI芯片Celerity史上最详细解读(上)(附开源地址) ↩︎
陈宇飞@知乎:新AI芯片介绍(3):tenstorrent ↩︎
陈巍@知乎:特斯拉Dojo芯片架构全面分析(超越GPGPU?) ↩︎
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。