速度起飞!AI大模型用OpenVINO优化响应速度的小妙招
英特尔开发人员专区 2024-06-15 17:31:02 阅读 76
作者:周兆靖 , 英特尔高级应用工程师
1. 本文目的
一般来说,开发者在启动基于OpenVINO™的AI应用进行深度学习模型推理的时候,特别是在推理大模型的时候,往往会发现从程序启动到完成初次推理所消耗的时间(称之为初次推理的响应时间)会比常规一次推理要长一些, 这是因为在启动第一次推理之前,OpenVINO™ Runtime的工作流程是需要先读取模型文件,之后编译模型文件,完成后才开始模型推理。这就导致了用户启动AI大模型应用后,拿到首次推理结果的时间相对比较长,用户体验不佳,AI应用初次推理过长的响应时间也随之成为了大模型应用需要解决的痛点之一。本文将会介绍OpenVINO™提供缩短初次推理响应时间的优化选项,同时对不同的推理硬件进行对比,目的是让开发者使用OpenVINO™部署AI推理时,能够更熟悉针对初次模型推理响应的优化方法,并将这些优化策略合理地部署在自己AI大模型应用中。
2. 优化推理响应的策略

我们先梳理一下基于OpenVINO™工具套件构建应用程序的整体思路,总体的流程是这样的:
图1:OpenVINO™应用推理准备阶段流程图
首先需要创建一个Core对象,然后需要管理当前系统下的可用设备使用read_model() 读取Intermediate Representation(IR)到ov::Model 的对象中确定模型的输入和输出格式,模型运行的执行精度、数据通道的排列顺序、图像的大小或颜色格式,将需要的配置文件加载传递到设备中在特定的硬件设备下编译网络并加载模型到设备中:使用ov::Core::compile_model()的方式完成操作准备input tensor作为模型输入执行推理,最终获得结果
通过以上的流程图,我们可以很清晰的知道在AI程序在第一次执行推理前,还有这么多的准备步骤需要完成 。如果我们要去做模型初次推理响应的优化,从以往的经验可以得知:由于读取模型和编译网络模型这两步会产生很大的计算量,因此会消耗比较多的时间,所以我们也会重点优化这两个步骤,来减少推理响应耗费的时间。其次,对于相同的模型来说,基于OpenVINO™的AI推理在CPU上的响应速度往往会比GPU上快得多,不同的推理设备也会对模型初次推理响应产生影响。接下来,我们将介绍一些比较常用的优化策略。
优化策略一:使用模型缓存减少模型编译时间
在模型推理之前,程序会执行读取模型和编译模型的操作,这些操作实际上是在对推理硬件设备进行特定优化并且完成深度神经网络(DNN)在当前设备的编译操作,编译完成之后方可运行推理。为了减少应用程序启动时的延迟,不论在CPU还是在GPU中,在任何推理设置情况下,你都可以使用“Model Cache”的方式来优化第一次推理的响应时间,以减少程序启动时的延迟。

图2:Cache Model优化流程示意图
如上图所示,应用“Cache Model”之后,在编译模型阶段,可以大幅降低这一阶段所消耗的时间。模型缓存是OpenVINO™工具套件自带的一个功能,它在完成编译模型网络之后,可以自动导出已编译好的模型,将这个缓存模型放置在特定的文件目录下,程序会在指定的文件目录下生成一个大小和模型bin文件差不多的Blob文件作为缓存文件,下一次启动程序是可以直接读取Blob缓存模型进行模型复用,这个操作也可以在应用启动阶段显著减少模型编译时间,加快推理程序启动的响应速度,这是最推荐大家去使用的策略因为不受它可以不受任何其他条件所影响。
在某些特定情况下,若应用程序不需要每次都调整模型的输入和输出,甚至可以在代码中省略read_model()这一步,直接使用compile_model()编译模型,这样能达到一个最快的推理响应速度。
使用”Cache Model”的方式如下,只需要指定一个保存缓存模型的文件夹路径,即可使用这个功能:
compiled_model = core.compile_model(model=model,config={ "CACHE_DIR":"PATH to folder to save cache model"})
优化策略二:在PERFORMANCE_HINT中选择Latency模式
若在应用中设定多推理线程的话,势必会同时拉起非常多的推理线程,这样会导致推理设备的初始负载非常大,虽然可以得到比较大的图像推理吞吐量,但是初次推理延迟也会同样变得非常大。所以如果对于推理响应比较敏感的开发者,需要在推理程序中只拉起一个推理线程,设置单一推理流,一个batch,就能达到推理延迟最小化,初次推理响应最快化。当然,更多的时候开发者也需要权衡线程数和推理延迟之间的关系,线程数越大,随之推理延迟就越大,所以在有些实际开发过程中需要牺牲一点响应时间来换取更大的吞吐量。
如果说追求最快的推理响应,可以设置PERFORMANCE_HINT的参数为“latency”模式,这样会自动选择相应的推理参数,以达到最快推理响应速度,Python语言的使用方法如下:
compiled_model = core.compile_model(model=model,{"PERFORMANCE_HINT": "LATENCY"}
优化策略三:优先选择CPU硬件进行推理
在使用OpenVINO™进行AI推理时,同样的模型,不同的推理硬件会带来不一样的推理响应结果。英特尔GPU编译网络消耗的时间会比CPU大得多,所以在AI推理应用的第一步——设备管理阶段,开发者需要在设备的选择与推理的启动时间去做衡量。
若AI应用的需求选择单独CPU或者GPU去做推理,在推理响应要求高的场景下,可以优先选择使CPU进行AI推理,因为CPU的推理响应速度更快。
优化策略四:GPU推理时应用AUTO Plugin
在上一个优化策略中,我们知道CPU在推理响应上是会比GPU快的,那么当我们在使用GPU推理时,能不能将CPU推理加到GPU开始推理之前,以获得最快的推理响应速度呢?答案是可以的,并且OpenVINO™将这个功能做成了一个单独的Plugin。当你选择使用 AUTO Plugin指定CPU和GPU并进行模型推理时,AUTO Plugin将会默认同时在CPU和GPU上编译模型网络并开始推理,以填补GPU编译网络的这段时间空白。
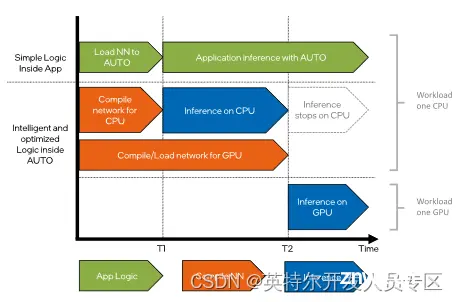
图3:AUTO Pugin工作流程分解示意图
由上图可以很清晰地看到CPU的推理工作在GPU完成模型编译后停止,AUTO Plugin充分利用了这段空闲时间并且也不会产生过多的内存占用。特别是针对GPU的推理时候,虽然没有直接缩短编译网络的时间,但是通过CPU推理的前置组合加入,当GPU开始推理时,AUTO Plugin会将CPU中的推理任务转移到GPU设备继续进行。这样,对于编译模型速度比较慢的设备,例如使用AUTO Plugin部署AI应用到GPU中,这个应用在启动推理初始阶段的延迟将会变得非常低,接近于CPU推理的响应速度。在OpenVINO™中使用AUTO Plugin的方法也十分简单,只需要在compile_model()函数中,指定device_name=”AUTO:CPU,GPU”就可以实现了,例如下方所示是Python语言的使用方法:
compiled_model = core.compile_model(model=model, device_name="AUTO:CPU,GPU")
优化策略五:权衡是否使用NNCF量化的低精度模型
由于FP32全精度模型需要运算量相对比较大,很多开发者会将模型量化成低精度模型之后进行部署,这样由于模型计算量的减少,所以模型推理速度会快很多。但是,如果使用OpenVINO™提供的Neural Network Compression Framework(NNCF)工具对IR模型进行量化,会导致低精度模型推理响应变慢,这是由于NNCF的压缩原理就是给原始模型插入很多Fake Quantized层来转换精度,低精度IR模型网络里是包含非常多的Fake Quantized层,在编译模型阶段,新插入的这些层将消耗很多时间进行全精度到低精度的计算转换。

图4:NNCF量化IR模型示意图
所以在启动量化模型推理前的编译模型阶段,会消耗比原来全精度模型更多的时间。开发者需要权衡量化带来的模型响应变慢和推理速度之间的平衡。
优化策略六:将ONNX模型转换为IR模型进行推理
由于OpenVINO™是可以直接支持ONNX模型进行推理的,所以有一部分的开发者会选择直接使用ONNX格式的模型进行推理。由于ONNX模型转成IR模型的过程中,会涉及模型层融合和裁剪的相关操作,IR的网络层数肯定是比原来的ONNX模型要少的,再加上OpenVINO™ Runtime会针对IR文件的读取做优化,所以同一个原始模型下,用IR模型推理比ONNX模型推理的响应是要快的。所以建议开发者将ONNX格式模型转换为IR格式模型进行推理以获得更快的模型推理响应。
优化策略七:大模型推理使用最新版本的OpenVINO™工具套件
由于大模型的火热,目前OpenVINO™每个版本都会针对大模型进行特定优化,若开发者使用的是比较新的大模型,我们建议大家使用最新版本的OpenVINO™工具套件以获得大模型的最优推理响应和推理效果的的支持。
优化策略八:模型映射
为了降低第一次推理的延迟,在读取模型阶段,我们可以将原本的模型读取替换为模型映射进入内存中以降低模型读取延迟,这是OpenVINO™提供的mmap功能。
在默认设置中,这个功能是被打开的,也就是说OpenVINO™是默认使用mmap读取模型的。但是需要注意的是,模型映射在少数一些使用场景下是会导致读取模型延迟增加的,就比如模型如果位于可移动存储或者网络驱动器上就有可能导致模型推理延迟增加,这个时候你可以选择禁用模型映射功能,例如在C++的代码中进行设置ov::enable_mmap(false)就可以了。
3.模型推理响应测试
我们将在如下环境下进行模型推理测试:
OS: Ubuntu 20.04 LTS 64bit
OpenVINO™版本号: 2023.2
CPU型号 :英特尔® 酷睿™ i7-11700T 处理器
GPU型号:Intel® Arc™ A770 16GB
i915 驱动版本: 23.8.20_PSB_230810.22
3.1Resnet-50推理应用测试
测试脚本为测试运行一张图片推理的推理脚本,将脚本启动至第一帧推理完成的时间作为实验数据,以模拟实际应用启动的场景,推理线程数为1,基准测试为运行模型为FP32精度的Resnet-50 Pytorch版本模型,模型较小,测试结果如下:

本文所有测试均在基准环境下控制单一优化策略变量完成测试。
我们从测试结果中可以发现,首先,OpenVINO™版本和模型映射对Resnet-50推理响应的影响差别不大,CPU的推理响应速度确实是会比GPU更快。在GPU推理时应用了AUTO Plugin确实将推理的响应速度提升到了CPU的水准,这是CPU和GPU协同工作得到的结果。在应用模型缓存这个功能后,不论是CPU还是GPU,模型进行第一次推理的时间都显著加快了,这个功能确实可以非常快速地提升AI推理程序的响应速度。当模型替换为NNCF量化后的模型,AI应用响应会变得更慢。
在这个场景下,优化策略七(新版本OV)和八(模型映射)效果就微乎其微了,所以在这种小模型AI应用场景,我们推荐考虑使用优化策略一(Model Cache),三(CPU优先),四(AUTO plugin)和五(权衡NNCF的低精度模型)来加快模型的初次推理响应速度。
3.2Transfomer大模型推理响应测试
使用一个Open Model Zoo里比较经典的模型语言模型GPT-2进行测试,测试命令如下
$benchmark_app -m “model_path” -d “device_name” -hint latency
测试结果如下所示:

从图标的测试结果来看模型缓
存在对于CPU推理编译模型加速还是很明显的,对于GPU来说就没那么明显了。当测试使用多线程的“throughput”模式虽然吞吐量变大,但是编译模型的时间也会加长。若使用ONNX模型,在读取模型和编译模型阶段都会比使用IR格式模型慢的多。
所以在这种场景下,推荐开发者使用优化策略一(模型缓存),优化策略二(Latency Mode)和优化策略六(ONNX转IR)进行部署。
3.3 Text-to-Image大模型推理响应测试
由于Resnet-50的模型体积比较小,参数权重文件也仅有110MB的大小。模型编译的时间和模型的大小也有直接的关系,所以接下来我们将会测试一个体积稍微大一点的模型。Stable Diffusion的文生图工作流程中,Unet模型发挥了至关重要的作用,它负责将随机生成的原始图片,一步步修改校准为最后符合文字意思的图片。可想而知,这项工作需要的参数网络是相当大的,这同时也反映在Unet模型快接近于3GB的庞大体积上。所以,现在我们需要测试一些Unet模型在不同OpenVINO™版本下,在初次推理阶段的差异。测试Unet模型在读取模型和编译模型阶段所消耗的时间,测试命令如下:
$benchmark_app -m “model_path” -d “device_name” -hint latency
实验结果如下表:

实验数据均为10次测试取平均值。
关于OpenVINO™版本对于模型推理响应的影响,在Resnet-50中并不明显,原因是该模型相对比较经典,这两个版本对其的优化方法保持一致。但是由于近期大模型的火热,OpenVINO™在2023版本中对大模型的支持是不断在优化的,CPU或者GPU运行推理在读取模型这一步的行动上,新版本就比老版本快了很多。在编译模型这步,CPU在OpenVINO™新版本相较于老版本也是快2倍多。并且,在GPU做推理的时候使用模型缓存的话,也能提升模型推理的响应速度。也可以看到这个模型在CPU中推理若应用模型缓存功能,得到的提升不明显,甚至还会更糟糕。
所以当模型缓存能够起到作用的情况下,推荐优先使用优化策略一(模型缓存)尽量使用模型缓存来优化大模型推理响应。并且推荐使用最新的OpenVINO™工具套件来运行大模型的推理。
4.总结
在AI应用的日益普遍的今天,各种模型层出不穷,越来越多的AI模型被应用在了各行各业。OpenVINO™工具套件作为英特尔为开发者提供的推理部署加速软件,可以很方便地被部署到包括了医疗,零售,交通或者工业场景中。无论是主流的视觉模型像YOLO系列,或者说最近火热的大模型像刚才展示的Stable Diffusion或者GPT,ChatGLM这样的大语言模型可以很轻松地使用OpenVINO™部署到英特尔的硬件上进行AI推理。在运行这些AI推理应用的时候,往往会涉及到对推理启动时间的考量,特别是对于某些需要实时反馈的AI应用来说,初次推理的响应时间就会变得尤为重要,AI程序的开发者也会去优化相关的代码程序,让AI推理的响应时间更短,让整个应用完成第一次推理的时间更快。
本文介绍了在使用OpenVINO™工具套件部署AI推理时,如何利用OpenVINO™提供的多种方式去优化程序启动初次推理的响应时间,包括了使用AUTO Plugin,使用模型缓存或者说使用mmap方式读取模型。并且,充分分析了不同模型精度对模型初次推理响应时间的影响,由NNCF量化得到的IR模型会因为其模型结构中包含许多FakeQuantized层,使得模型网络编译的时间会比全精度FP32或半精度FP16的模型花的时间更多。当然,低精度模型的推理速度会比全精度模型的推理速度快的多,至于怎么去取舍推理速度和初次推理响应速度,也是需要AI应用程序开发者进行平衡的问题。
最后,在分析新老版本对模型初次推理响应速度的实验里,我们发现像Resnet-50这些问世比较久的经典模型,OpenVINO™对它们的优化策略是一致的,所以新旧版本对其推理结果影响不大。但是对于Stable Diffusion这样的大模型来说,由于OpenVINO™ 2023.0以后的每个小版本都会对大模型进行相关的优化,所以在新旧版本对比中,新版本的OpenVINO™在推理Stable Diffusion的模型的时候,不论是读取模型还是推理模型方面,速度都做了相应的优化,比老版本快的多得多。若是在GPU中推理Stable Diffusion,使用模型缓存还能得到较于原本更快的初次推理响应速度。总的来说,如果有需要基于OpenVINO™做一些大模型的推理部署,建议开发者们选择最新版本的OpenVINO™工具套件进行使用,以获得最新的优化以及模型支持。
5.参考资料
AUTO Plugin:Automatic Device Selection — OpenVINO™ documentation
Model Cache: Model Caching Overview — OpenVINO™ documentation
NNCF: Model Optimization Guide — OpenVINO™ documentation
Performance Mode: High-level Performance Hints — OpenVINO™ documentation
把FIL的定义解释一下 [QD1]
可以删掉 [QD2]
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。