【Intel黑客松大赛】基于OpenVINO™ Model Optimizer + ChatGLM-6B + P-Tuning微调的AI新闻小助手
中杯可乐多加冰 2024-09-12 09:01:02 阅读 70
随着人工智能技术的飞速发展,自然语言处理(NLP)领域迎来了前所未有的变革,而大语言模型(Large Language Model, LLM)作为这一变革的核心驱动力,正逐步成为连接人类语言与机器智能的桥梁。
LLM通过海量文本数据的学习,掌握了丰富的语言知识、上下文理解能力以及生成高质量文本的能力,为智能教学、智能客服、虚拟助手等多个领域的应用提供了强大的技术支持和无限可能。

将OpenVINO™ Model Optimizer、ChatGLM-6B以及P-Tuning微调技术相结合,然后借助阿里云ECS云服务器g8i实例,可以构建出一个高效、灵活且性能优异的AI新闻小助手。
该助手能够利用优化后的ChatGLM-6B模型快速生成新闻报道,同时借助OpenVINO™的跨平台特性和性能优化能力,确保在不同硬件平台上都能稳定运行。此外,通过P-Tuning微调技术,AI新闻小助手能够不断适应新的数据集和任务需求,提升新闻报道的准确性和多样性,而阿里云ECS云服务器g8i实例提供的英特尔® 至强® 可扩展平台为模型提供了坚实的算力底座。
本次Intel黑客松大赛主题刚好也是基于大语言模型(LLM)的创新应用开发,这里记录一下开发过程。
一、原理简介
1.1、ChatGLM-6B简介
2022年8月,清华背景的智谱AI基于GLM框架,凭借其强大的语言理解和生成能力、轻量级的参数量以及开源的特性,已经成为在学术界和工业界引起了广泛关注。

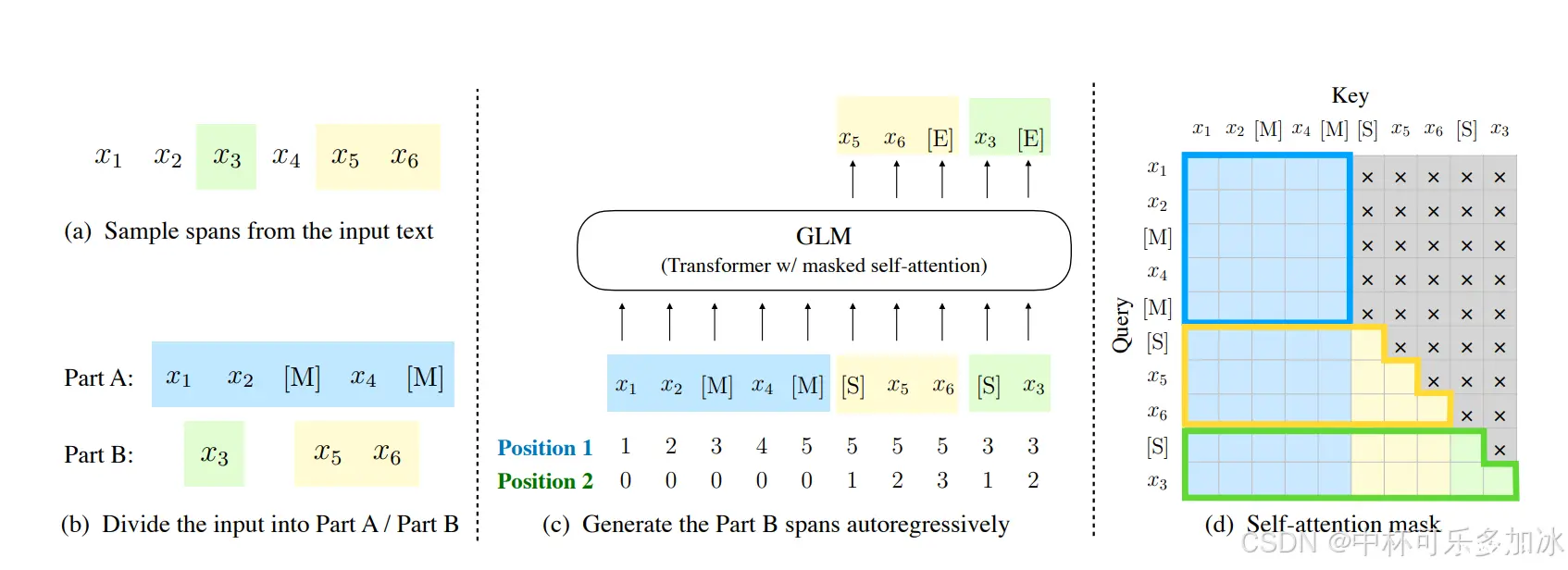
自回归填空预训练:在预训练阶段,模型会学习如何基于部分遮盖的文本来预测被遮盖的内容。这种预训练方式使得模型能够捕捉文本中的长距离依赖关系。2D位置编码:为了解决自回归填空任务中的位置信息编码问题,GLM引入了二维位置编码。每个token都会被赋予两个位置id,一个表示在原始文本中的位置,另一个表示在遮盖跨度内的相对位置。这种编码方式使得模型在生成文本时不会预先知道遮盖跨度的长度,从而更好地适应下游任务。模型架构的优化:GLM在Transformer架构的基础上进行了一些优化,比如调整层归一化和残差连接的顺序,使用单个线性层进行token预测,以及替换ReLU激活函数为GeLU。
1.2、基于 P-Tuningv2的微调方法
之前的Prompt Tuning和P-Tuning缺乏模型参数规模和任务通用性,缺少深度提示优化。而P-Tuning v2是一个用于改进预训练语言模型(Pre-trained Language Model,PLM)偏见的方法。
P-Tuning v2通过在输入词嵌入序列中插入可训练的连续提示(embeddings)来调整模型。这些提示是在训练过程中唯一更新的部分,而预训练模型的其他参数保持冻结。与传统的仅在输入层插入提示的方法不同,P-Tuning v2在预训练模型的多个层次(每一层的输入)中插入提示。这样做增加了可训练参数的数量,使得模型能够更直接地影响预测结果,从而提高了性能。
二、基于ChatGLM-6B + P-Tuning v2的新闻助手
2.1、下载ChatGLM2-6B模型
首先,我们需要从Hugging Face平台下载ChatGLM2-6B预训练模型。该模型由ChatGLM团队发布,可以通过Transformer库进行推理,但不支持Optimum的部署方式(类似Llama2)。因此,我们需要从Transformer库中提取ChatGLM2的PyTorch模型对象,并将其序列化以便进一步处理
2.2、基于ChatGLM-6B + P-Tuning v2微调
官方给出的数据处理格式为:
<code>{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
{“content”:“”,“summary”:“”}形式,这里面可以处理自己的数据集成这种格式,如果是新闻助手那么content就是原新闻,summary就是对应新闻解析。用以上数据格式创建自己的train.json和dev.json文件,指定数据文件夹路径后期微调需要改成自己的路径名称。修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。
训练时需要指定 --history_column 为数据中聊天历史的 key(在此例子中是 history),将自动把聊天历史拼接。要注意超过输入长度 max_source_length 的内容会被截断。其中参数:
“add_bias_linear”: false: 表示是否在线性层中添加偏置项。
“add_qkv_bias”: true: 表示是否在注意力机制的查询(Q)、键(K)和值(V)计算中添加偏置项。
“apply_query_key_layer_scaling”: true: 表示是否对注意力机制中的查询和键进行缩放处理。
“apply_residual_connection_post_layernorm”: false: 表示是否在层归一化后应用残差连接。
“architectures”: [“ChatGLMModel”]: 表示该配置用于的模型架构。
“attention_dropout”: 0.0: 表示在注意力计算中应用的dropout的比率。Dropout是一种防止模型过拟合的技术。
“attention_softmax_in_fp32”: true: 表示是否在单精度浮点格式(FP32)中执行注意力机制的Softmax计算。
“auto_map”: 这部分将自动配置,模型映射到ChatGLM的配置和模型。
“bias_dropout_fusion”: true: 表示是否融合偏置和dropout。这通常用于优化和提高训练速度。
“eos_token_id”: 2: 定义结束符(End of Sentence)的标识符。
“ffn_hidden_size”: 13696: 表示前馈神经网络(Feedforward Neural Network,FFN)的隐藏层的大小。
“fp32_residual_connection”: false: 表示是否在单精度浮点格式(FP32)中应用残差连接。
“hidden_dropout”: 0.0: 隐藏层的dropout率。
“hidden_size”: 4096: 隐藏层的大小。
“kv_channels”: 128: 键值(Key-Value)的通道数。
“layernorm_epsilon”: 1e-05: 层归一化的epsilon值,为了防止除数为零。
“model_type”: “chatglm”: 模型类型。
“multi_query_attention”: true: 表示是否使用多查询注意力。
“multi_query_group_num”: 2: 在多查询注意力中的查询组数。
“num_attention_heads”: 32: 注意力机制的头数。
“num_layers”: 28: 模型的层数。
“original_rope”: true: 是否使用原始的ROPE模式。
“pad_token_id”: 2: 定义填充符的标识符。
“padded_vocab_size”: 65024: 表示经过填充后的词汇表大小。
“post_layer_norm”: true: 是否在层后应用层归一化。
“quantization_bit”: 0: 表示量化的位数。
“rmsnorm”: true: 表示是否使用RMS归一化。
“seq_length”: 32768: 序列长度。
“tie_word_embeddings”: false: 是否绑定输入和输出的词嵌入。
“torch_dtype”: “float16”: 使用的数据类型,这里是半精度浮点数。
“transformers_version”: “4.30.2”: 使用的Transformers库版本。
“use_cache”: true: 是否使用缓存以加快计算速度。
2.3、使用阿里云ECS云服务器g8i实例训练
在训练的算力上,本次实验选择了使用阿里云ECS云服务器g8i实例。强大的计算能力、丰富的硬件加速资源、高效的数据处理能力、全面的安全防护、适用性与灵活性以及易用性与服务支持等优势。这些特点使得ECS g8i实例成为本次训练模型的理想选择。
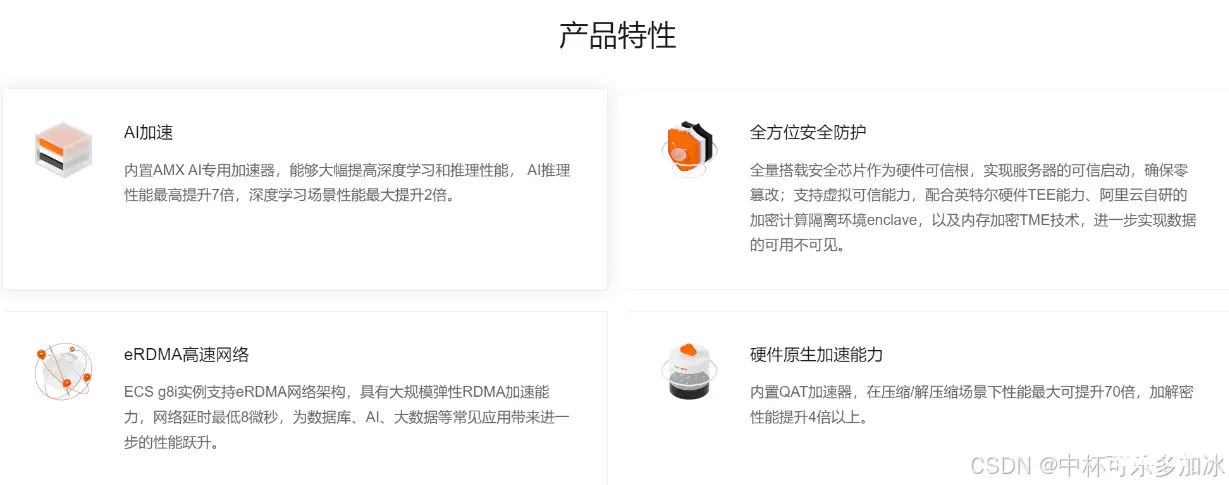
阿里云服务器ECS通用型g8i实例在通用算力彪悍提升的基础上,还依托第四代英特尔® 至强® 可扩展处理器内置的丰富硬件加速器,实现了场景化性能的狂飙,其中在深度学习训练场景性能提升 2 倍以上,推理性能提升 4 倍,加解密、压缩/解压缩等场景性能提升 4 倍以上,使得阿里云在统一技术架构下可获得更好的场景化性能扩展,为用户提供更高的性价比。
2.4、将模型转换为ONNX格式
ONNX(Open Neural Network Exchange)是一个开放的深度学习模型交换格式,允许模型在不同框架间转换,便于在不同平台和设备上的部署和推理。
在进行ONNX格式的转换之前,我们需要获取模型的输入和输出信息。因为ChatGLM2使用KV cache机制,因此需要在转换过程中模拟第一次文本生成时不带cache的输入,然后将输出作为第二次迭代时的cache输入,再通过第二次迭代验证输入数据的完整性。以下是PyTorch代码示例:
<code>outputs = model.forward(**input_tensors)
outputs2 = model.forward(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values
)
在获取了完整的输入输出信息后,我们可以使用torch.onnx.export接口将模型导出为ONNX文件。
2.5、使用OpenVINO™ Model Optimizer转换模型格式转换为IR格式
Model Optimizer,即模型优化器,是一个跨平台的命令行工具。它可以将深度学习训练框架如Caffe、TensorFlow、MXNet训练后的模型转换为部署所需要的模型。
使用OpenVINO™的Model Optimizer工具可以将ONNX模型文件转换为IR格式,并将精度压缩到FP16。与原始的FP32模式相比,FP16模型能够在保证输出准确性的前提下减少磁盘占用,并优化运行时的内存开销。这样处理后的模型更适合在资源受限的设备上进行高效推理。
整个pipeline的大部分代码都可以套用文本生成任务的常规流程,其中比较复杂一些的是OpenVINO™推理部分的工作,由于ChatGLM2-6B文本生成任务需要完成多次递归迭代,并且每次迭代会存在cache缓存,因此我们需要为不同的迭代轮次分别准备合适的输入数据。
2.6、模型效果
ChatGLM-6B + P-TuningAI新闻小助手演示
二、Intel oneAPI工具包使用
在算法实现过程中,我们使用到了oneAPI工具包:

英特尔相关软件具体使用如下:
Intel Optimizer for PyTorch:使用到了英特尔优化过的<code>PyTorch深度学习框架,以最少的代码更改应用 PyTorch 中尚未应用的最新性能优化,并自动混合 float32 和 bfloat16 之间的运算符数据类型精度,以减少计算工作量和模型大小。Interl Nerual Compressor:使用Nerual Compressor自动执行流行的模型压缩技术,例如跨多个深度学习框架的量化、修剪和知识蒸馏。并通过自动精度驱动的调优策略快速收敛量化模型
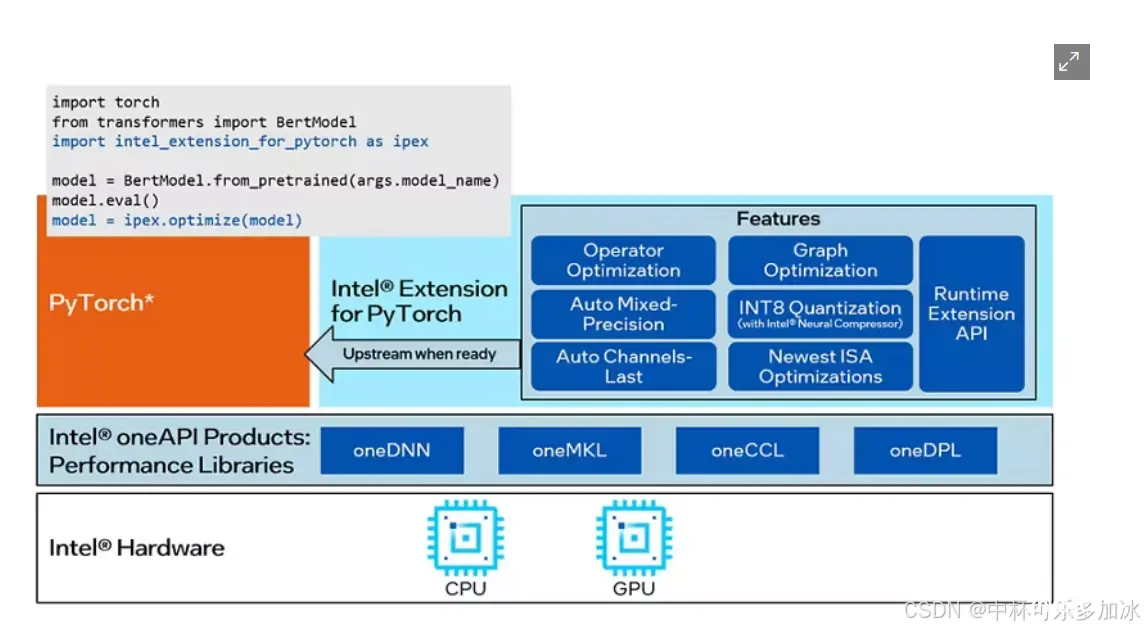
另外,Intel PyTorch 扩展库被用于优化模型的性能,通过<code>ipex.enable_auto_dnnl()导入 Intel PyTorch 扩展库并启用了自动 DNNL(Deep Neural Network Library)优化可以帮助我们更高效地进行深度学习模型的训练和推理,提高模型的性能和效率。 Intel Neural Compressor 被使用来对模型进行量化,减小模型的大小并提高在低功耗设备上的推理速度,同时保持相对较高的准确率
同时,也可以帮助我们减少模型的大小和计算工作量,从而更好地适应不同的硬件和场景需求。
三、后续待完善的部分
系统集成:原型中只实现了模型训练和测试的基本功能,未能实现完整的系统集成。计划通过系统集成技术,将模型集成到完整的杂草检测系统中,实现端到端的杂草检测功能。
模型优化:原型中使用的模型精度和推理速度还有提升空间。计划继续深入学习Interl Optimization for PyTorch,优化模型计算工作量和模型大小,并继续深入学习Interl Nerual Compressor提高在 CPU 或 GPU 上部署的深度学习推理的速度
上一篇: 开源 AI 模型实际部署以及后端搭建(一)--环境配置
下一篇: 基于全志的T527/I527开发板核心板:性能、显示、AI算力全面提升
本文标签
【Intel黑客松大赛】基于OpenVINO™ Model Optimizer + ChatGLM-6B + P-Tuning微调的AI新闻小助手
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。