万字详解AI开发中的数据预处理(清洗)
和老莫一起学AI 2024-09-09 11:01:02 阅读 69
数据清洗(Data Cleaning)是通过修改、添加或删除数据的方式为数据分析做准备的过程,这个过程通常也被称为数据预处理(Data Preprocessing)。对于数据科学家和机器学习工程师来说,熟练掌握数据清洗全流程至关重要,因为数据预处理后的质量将直接影响他们或训练的模型从数据中获得的所有结论和观点(insights) 。
在这篇博文中,我们将重点讲述类别型特征(categorical feature)方面的数据清理概念(本文第5部分),给出合适的图片以帮助理解,并提供代码演示等。
在本文结束时,我相信你不仅会了解什么是数据清洗,还能完美地掌握数据清洗的步骤,如何进行实操,以及最重要的是如何从你的数据中得到最好的结果。
01 为什么我们需要清洗数据?
有时,在我们能够从数据中提取有用的信息之前,需要对数据进行清洗/预处理。大多数现实生活中的数据都有很多需要处理的地方,如缺失值、非信息特征等,因此,在使用数据之前,我们一直需要对其进行清洗,以便在使用数据时达到最佳效果。
以机器学习流程为例,它的工作对象只有数字。如果我们打算使用具有文本、日期时间特征和其他非数字特征的数据,我们需要找到一种方法,用数字****来表示它们,而不丢失它们所携带的信息。
比如说一个简单的逻辑回归模型只是用一个线性函数将因变量映射到自变量上,如:y= wx + b。其中,w是权重,可以是任何数字,b是偏差,也是一个数字。
如果给你一组数据;[小、中、大],你会发现不可能计算出:y=w*small+b。
但如果你把“小”编码为1,“中”编码为2,“大”的编码为3,从而把你的数据转化为[1,2,3],你会发现你不仅能够计算y=w*1+b,而且其中编码的信息仍然被保留。
02 数据清洗有哪些步骤?
数据清洗是我们在为数据分析做准备的过程中对数据进行的一系列操作的统称。
数据清洗的步骤包括:
处理缺失值(Handling missing values)对类别型特征进行编码(Encoding categorical features)异常值检测(Outliers detection)变换(Transformations)…
后续我们将重点展开处理缺失值和对类别型特征进行编码。
03 处理缺失值(Handling missing values)
在进行数据预处理时遇到的最常见的问题之一就是我们数据中存在缺失值。这个情况是非常常见的,可能因为 :
填写数据的人有意或无意的遗漏,或者数据根本不适合填在此处。工作人员将数据输入电脑时出现遗漏。
数据科学家如果不注意,可能会从包含缺失值的数据中得出错误的推论,这就是为什么我们需要研究缺失值并学会有效地解决它。
早期的机器学习库(比如scikit learn)不允许将缺失值传入。这就会带来一定的挑战,因为数据科学家在将数据传递给scikit learn ML模型之前,需要迭代很多方法来处理缺失值。最新的机器学习模型和平台已经解除了这一障碍,特别是基于梯度提升机(gradient boosting machines)的一些算法或工具,如Xgboost、Catboost、LightGBM等等。
我特别看好的是Catboost方法,它允许用户在三个选项(Forbidden, Min, and Max)中进行选择。Forbidden将缺失值视为错误,而Min将缺失值设定为小于特定特征(列)中的所有其他值。这样,我们就可以肯定,在对特征进行基本的决策树分裂(decision tree splitting)时,这些缺失值也会被考虑在内。
LightGBM[1]和XGboost[2]也能以相当方便的方式处理缺失值。然而,在进行预处理时,要尽可能多地尝试各种方法。使用像我们上面讨论的那些库,其他的工具,如automl等等。
缺失值一般分为三类,即:
完全随机缺失(MCAR) 。如果我们没有任何信息、理由或任何可以帮助计算它的东西,那么这个缺失值就是完全随机缺失。例如,“我是一个很困的研究生,不小心把咖啡打翻在我们收集的纸质调查表上,让我们失去了所有本来我们会有的数据。”
随机缺失(MAR) 。如果我们有信息、理由或任何东西(特别是来自其他已知值)可以帮助计算,那么这个缺失值就是随机缺失。例如,“我进行一项调查,其中有一个关于个人收入的问题。但是女性不太可能直接回答关于收入的问题。”
非随机缺失(NMAR) 。缺失的变量的值与它缺失的原因有关。例如,“如果我进行的调查包括一个关于个人收入的问题。那些低收入的人明显不太可能回答这个问题”。因此,我们知道为什么这种数据点可能缺失。
04 如何使用Python检测缺失值?
在我们处理缺失值之前,我们理应学习如何检测它们,并根据缺失值的数量、我们有多少数据等等来决定如何处理我们的数据。我喜欢并经常使用的一个方法是为某一列设置一个阈值,以决定它是可以修复还是无法修复。
下面,你会看到一个函数,它实现了我们在之前讨论的一些想法。
<code>ini复制代码def missing_removal(df, thresh, confirm= None):
holder= {}
for col in df.columns:
rate= df[col].isnull().sum() / df.shape[0]
if rate > thresh:
holder[col]= rate
if confirm==True:
df.drop(columns= [i for i in holder], inplace= True)
return df
else:
print(f' Number of columns that have Nan values above the thresh specified{len(holder)}')
return holder
Quick note
如果confirm参数设置为True,所有缺失值百分比高于设定阈值的列都会被删除;如果confirm参数设置为None或False,该函数会返回数据中所有列的缺失值百分比列表。现在去你的数据上试试吧!
4.1 统计归纳法(Statistical imputation)
这是一种被长期证明有效的方法。只需要简单地用某一列的平均数、中位数、模式来填补该列中的缺失数据。这很有效,正在阅读的伙伴们,请相信我!
Scikit-learn提供了一个名为SimpleImputer[3]的子类,就是以这种方式处理我们的缺失值。
下面是一个简短的代码描述,能够有助于我们更好地理解统计归因法。
ini复制代码from sklearn.impute import SimpleImputer
# store the columns of the dataframe 存储dataframe的所有列
cols= df.columns
#instantiate the SimpleImputer subclass 实例化SimpleImputer子类
#Depending on how you want to imput, you can use most_frequent, mean, median and constant 根据你想输入的方式,你可以使用most_frequent、mean、median和constant。
imputer= SimpleImputer(strategy= 'most_frequent')
df= imputer.fit_transform(df)
# convert back to dataframe 转换回dataframe
df= pd.DataFrame(df, columns= cols)
4.2 链式方程多重填补 Multiple Imputation by Chained Equations (MICE)
在这种方法中,每一列和它的缺失值被建模为数据中其他列的函数。 这个过程不断重复,直到之前计算出的值与当前值之间的公差非常小,并且低于给定的阈值。
Scikit-learn提供了一个名为IterativeImputer[4]的子类,可以用它处理缺失值。
下面是一个简短的代码描述,希望能帮你理解这种方法。
ini复制代码from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
# store the columns of the dataframe 存储dataframe的所有列
cols= df.columns
#instantiate IterativeImputer subclass 实例化IterativeImputer子类
imputer= IterativeImputer(max_iter= 3)
df= imputer.fit_transform(df)
# convert back to dataframe 转换回dataframe
df= pd.DataFrame(df, columns= cols)
希望上述这些内容足以让你有效地处理缺失值。
关于缺失值的更多信息,请查看Matt Brems的这份材料[5]。
05 对类别型特征进行编码(Encoding categorical features)
5.1 什么是类别型特征
类别型特征是只取离散值的特征。它们不具有连续值,如3.45,2.67等。一个类别型特征的值可以是大、中、小,1-5的排名,是和不是,1和0,黄色、红色、蓝色等等。它们基本上代表类别,如年龄组、国家、颜色、性别等。
很多时候类别型特征是以文本格式出现的,有些时候它们是以数字格式出现的(大多数人经常无法识别这种格式的类别型特征)。
5.2 如何识别类别型特征?
如何识别类别型特征不应该是一个大问题,大多数时候,分类特征是以文本格式出现的。
如果有一种排名形式,而且它们实际上是以数字格式出现的,那怎么办?此时要做的就是检查一列中唯一值的数量,并将其与该列中的行数进行比较。 例如,一列有2000行,只有5或10个唯一值,你很可能不需要别人来告诉你该列是分类列。这没有什么规则,只能依靠直觉,你可能是对的,也可能是错的。
5.3 类别型特征编码方法
给定一个类别型特征,正如前文我们所研究的那样,我们面临的问题是将每个特征中的独特类别转换为数字,同时不丢失其中编码的信息。基于一些可观察的特征,有各种类别型特征的编码方法。同时也有两类类别型特征:有序的类别型特征:在这一特定特征中,类别之间存在固有的顺序或关系,例如大小(小、大、中)、年龄组等。无序的类别型特征:该特征的类别之间没有合理的顺序,如国家、城市、名称等。
处理上述两类的方法是不同的。我在处理无序的类别型特征时使用下面这些方法:
独热编码(One-hot encoding)频数编码(Frequency/count encoding)目标编码/均值编码(Target mean encoding)有序整数编码(Ordered integer encoding)二进制编码(Binary encoding)留一法(Leave-one-out)编码证据权重编码(Weight of evidence encoding)
对于有序的类别型特征,我们只使用
标签编码或序号编码(Label encoding or ordinal encoding)
现在,我们将尝试一个接一个地研究其中的一些方法。并尽可能地用Python实现它们,主要是使用名为category_encoders的Python库。
可以使用 pip install category_encoders 来安装这个库。
1) 独热编码(One-hot encoding)
独热编码是对无序的类别型特征(nominal categorical features)进行编码的最有效方法之一。这种方法为列中的每个类别创建一个新的二进制列。理想情况下,我们会删除其中一列以避免各列之间的共线性,因此,具有K个唯一类别的特征会在数据中产生额外的K-1列。
这种方法的缺点是,当一个特征有许多唯一的类别或数据中有许多类别型特征时,它就会扩展特征空间(feature space)。

上图解释了独热编码的概念,以该种方式对特征进行编码能够消除所有形式的分层结构。
下面介绍如何在Python中实现这种方法。
<code>kotlin复制代码import pandas as pd
data= pd.get_dummies(data, columns, drop_first= True)
#check https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html for more info
2)频数编码(Frequency/count encoding)
这种方法同样非常有效。它根据无序的类别型特征在特征(列)中出现的频率为无序的类别型特征引入了分层结构(hierarchy)。 它与计数编码非常相似,因为计数编码可以取任何值,而频率编码则规一化为0到1之间。

下面介绍频数编码在Python中的实现:
<code>python复制代码# Frequency encoding 频率编码
# cols is the columns we wish to encode cols参数是我们要编码的那些列
#df is the dataFrame df参数是dataFrame
def freq_enc(df, cols):
for col in cols:
df[col]= df[col].map(round(df[col].value_counts()/len(df),4))
return df
# count encoding 计数编码
def count_enc(df, cols):
for col in cols:
df[col]= df[col].map(round(df[col].value_counts()))
return df
3) 目标编码/均值编码(Target mean encoding)
这种方法的思路是非常好的!它有一个非常独特的地方,就是它在计算过程中使用了目标列,这在一般的机器学习应用过程中是非常罕见的。类别型特征中的每一个类别都被替换成该类别目标列的平均值。
该方法非常好,但是如果它编码了太多关于目标列的信息,可能会导致过拟合。因此,在使用该方法之前,我们需要确保这个类别型特征与目标列没有高度关联。
测试数据通过映射使用来自训练数据的存储值进行编码。

下面介绍目标编码/均值编码在Python中的实现:
<code>ini复制代码# target mean encoding
#target_col is the name of the target column (str)
def target_mean_enc(df, cols, target_col):
mean_holder= {}
for col in cols:
col_mean= {}
cat= list(df[col].unique())
for i in cat:
data= df[df[col]== i]
mean= np.mean(data[target_col])
col_mean[i]= mean
mean_holder[col]= col_mean
return mean_holder
上面的函数返回一个字典,其中包含被编码列的平均值,然后将字典映射到数据上。见下图:
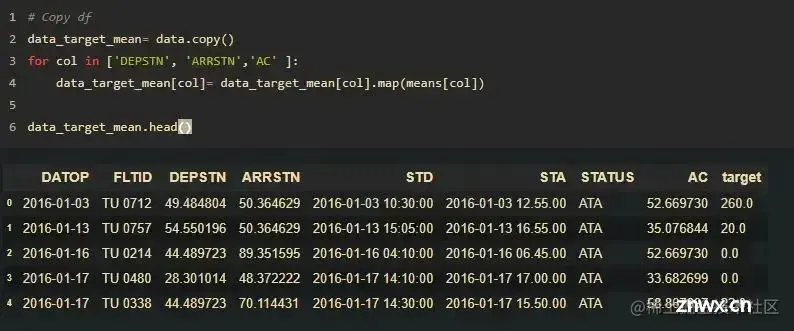
4) 有序整数编码(Ordered integer encoding)
这种方法与目标编码/均值编码非常相似,只是它更进一步,它根据目标均值(target mean)的大小对类别进行排序。

在实现有序整数编码后,dataframe看起来像这样:

下面介绍有序整数编码在Python中的实现:
<code>css复制代码def ordered_interger_encoder(data, cols, target_col):
mean_holder= { }
for col in cols:
labels = list(enumerate(data.groupby([col])[target_col].mean().sort_values().index))
col_mean= { value:order for order,value in labels}
mean_holder[col]= col_mean
return mean_holder
5) 二进制编码(Binary encoding)
二进制编码的工作原理是独一无二的,几乎与独热编码类似,不过还是有很多创新点。首先,它根据那些唯一特征(unique features)在数据中的出现方式为其分配level(不过这个level没有任何意义) 。然后,这些level被转换为二进制。最后各个数字被划分到不同的列。

下面介绍了使用category_encoders库进行二进制编码的演示:
ini复制代码from category_encoders import BinaryEncoder
binary= BinaryEncoder(cols= ['STATUS'])
binary.fit(data)
train= binary.transform(train_data)
test= binary.transform(test_data)
6) 留一法(Leave-one-out)编码
这种方法也非常类似于目标编码/均值编码,只是在每个级别上都计算目标均值,而不是只考虑在特定级别上。不过,目标编码/均值编码仍用于测试数据(查看更多信息[6])。

下面介绍留一法(Leave-one-out)编码在Python中的实现:
<code>ini复制代码from category_encoders import leave_one_out
binary= leave_one_out(cols= ['STATUS'])
binary.fit(data)
train= binary.transform(train_data)
test= binary.transform(test_data)
7) 证据权重编码(Weight of evidence encoding)
这是一种已经在信用风险分析中使用了长达七十年的方法。它通常用于逻辑回归任务的特征转化,因为它有助于揭示我们之前可能看不到的特征之间的相关性。这种方法只能用于分类任务。
它通过对列中的每个类别应用ln(p(good)/p(bad))来转换分类列。
p(good)是目标列的一个类别,例如p(1),而p(bad)是第二种类别,可能只是p(0)。

下面介绍了使用category_encoders库进行证据权重编码的演示:
ini复制代码from category_encoders import WOEEncoder
binary= WOEEncoder(cols= ['STATUS'])
binary.fit(data)
train= binary.transform(train_data)
test= binary.transform(test_data)
8) 标签编码(Label Encoding)和序号编码(Ordinal Encoding)
这种方法用于对无序的类别型特征进行编码,我们只需要根据我们可以推断出的大小为每个类别分配数字。

下面介绍这种方法在Python中的实现:
<code>bash复制代码df['size']= df['size'].map({ 'small':1, 'medium':2, 'big':3})
df
06 数据清洗工具和库
在该文章中提到了一些机器学习库,如scikit learn[7]和category_encoders[8]。还有其他一些有助于数据预处理的Python库,包括:Numpy, Pandas, Seaborn, Matplotlib, Imblearn等等。
然而,如果你是那种不喜欢写太多代码的人,你可以看看OpenRefine[9]、Trifacta Wrangler[10]等这些工具。
07 总结
到此为止,我们所讨论的大部分概念的代码实现与实例都可以在本文找到。我希望这篇文章能够让你对特征编码(Categorical Encoding) 的概念和如何填补缺失值有一个较深刻的认识。
如果你要问应该使用哪种方法?
数据清洗是一个反复的过程,因此,你可以随意尝试,并坚持使用对你的数据最有效的那一种。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。