揭秘 FineVideo 数据集构建的背后的秘密
cnblogs 2024-10-13 09:43:00 阅读 57
开放视频数据集稀缺,因此减缓了开源视频 AI 的发展。为此,我们构建了 FineVideo,这是一个包含 43,000 个视频的数据集,总时长为 3,400 小时,并带有丰富的描述、叙事细节、场景分割和问答对。
FineVideo 包含高度多样化的视频和元数据集合,使其成为训练模型理解视频内容、训练扩散模型从文本描述生成视频或使用其结构化数据作为输入训练计算机视觉模型的良好素材。
等等,你还没有看过 FineVideo 吗?通过 数据集探索页面 查看它。
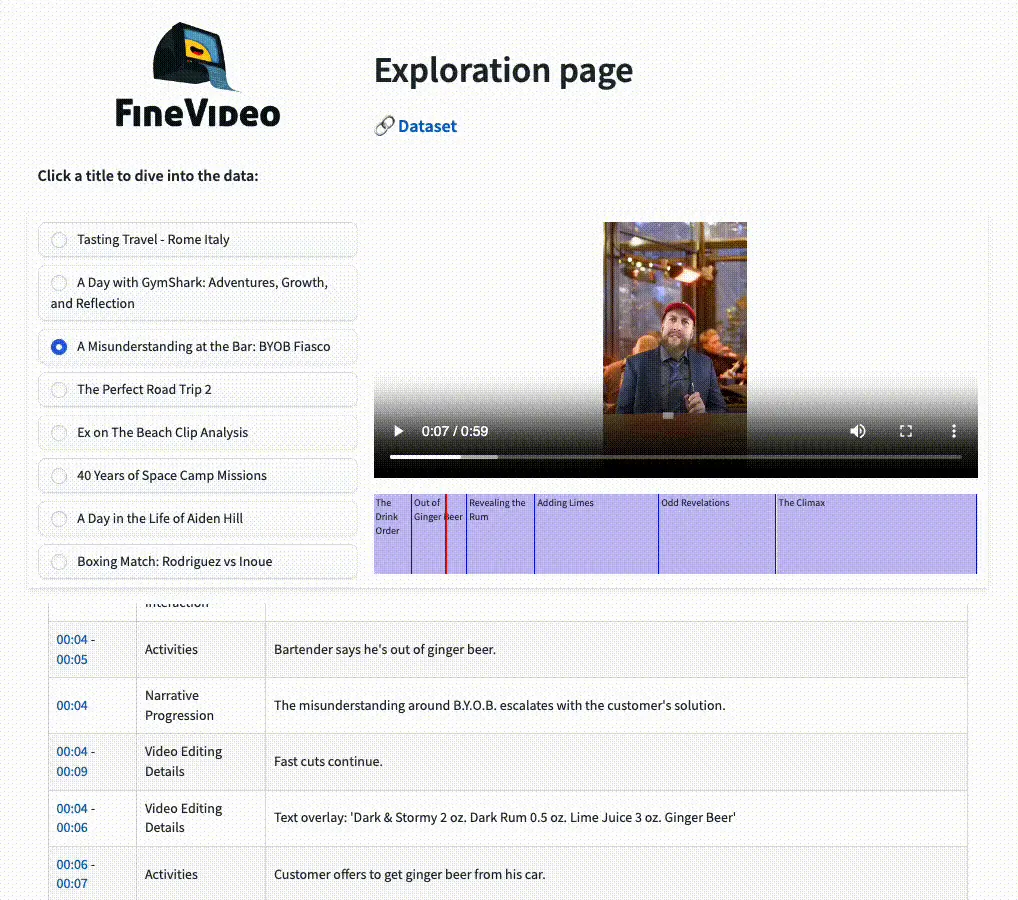
关于这篇博客文章
在这篇博客文章中,我们分享了开发 FineVideo 的技术细节和代码: 从 YouTube-Commons 中的 190 万个视频开始,到最终获得 44,000 个带有详细标注的视频。
一个好的开始方式是查看我们旅程的不同步骤。这些步骤涉及内容过滤、标注和输出结构化。
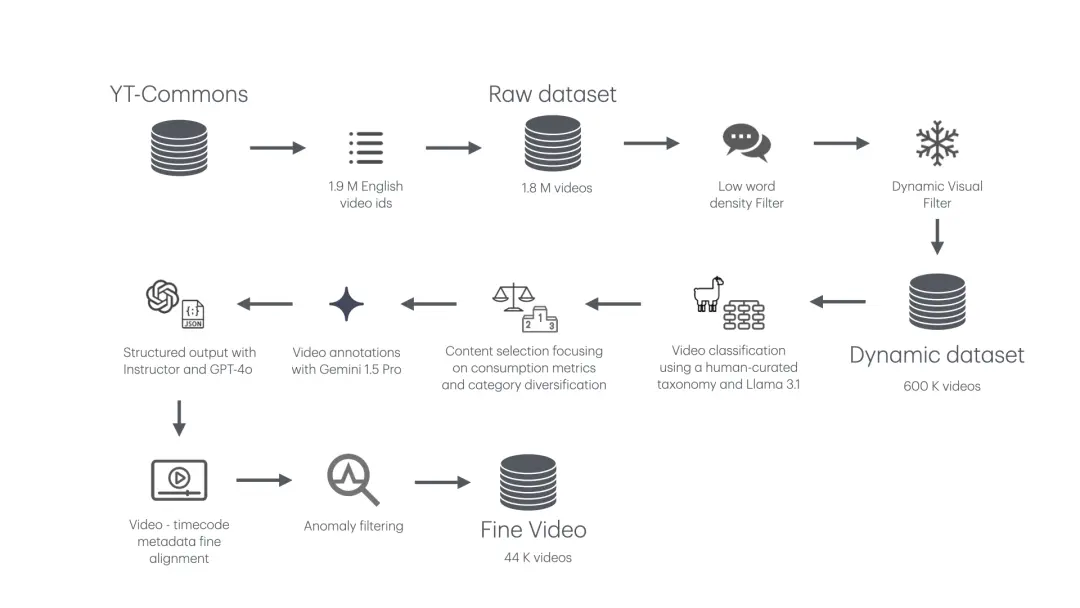
FineVideo 视频过滤和标注管道
在接下来的部分中,我们将讨论每个步骤,并提供相关代码部分的参考。如果你更喜欢直接浏览代码,请查看我们在 Github 上的 FineVideo 仓库。
首先,让我们看看我们是如何获得初始的 YouTube 视频列表并应用一些初步过滤的。
构建原始数据集
我们的旅程从 YouTube-Commons 开始: 这是一个包含在 YouTube 上共享的 CC-By 许可下的视频音频转录的集合。该项目由 PleIAs 创建并维护,作为其语料库收集项目的一部分。
过滤 YouTube-Commons
YouTube Commons 包含多种语言的视频和转录,我们的初始任务是将其内容缩小到同一种语言。
我们过滤 YouTube-Commons 中的英语视频,同时收集相关元数据。通过这种初步过滤,我们收集了 190 万个视频、它们的闭 captions 和元数据。
以下是一些过滤和保留的元数据字段的详细信息:
过滤
| 字段 | 过滤值 | 描述 |
|---|---|---|
| original_language | en | 英语视频 |
| transcription_language | en | 英语转录 |
元数据字段
| 字段 | 描述 |
|---|---|
| acodec | 音频编解码器 |
| age_limit | YouTube 视频的年龄限制 |
| categories | YouTube 视频类别 |
| channel | YouTube 频道 |
| channel_follower_count | 频道订阅用户数量 |
| channel_id | YouTube 频道标识符 |
| character_count | 闭 captions 中的字符数 |
| comment_count | YouTube 评论数量 |
| description | YouTube 视频描述 |
| duration_string | 视频时长,格式为 hh:mm:ss |
| license | 视频许可证 |
| like_count | YouTube 视频点赞数量 |
| resolution | 视频分辨率,格式为宽度 x 高度 |
| tags | YouTube 视频的自由文本标签 |
| text | 闭 captions |
| title | YouTube 视频标题 |
| upload_date | YouTube 上传日期 |
| vcodec | 视频编解码器 |
| video_id | YouTube 视频标识符 |
| view_count | YouTube 观看次数 |
| word_count | 闭 captions 中的单词数 |
内容过滤和元数据收集的代码可在此处找到 [链接]
下载视频
一旦我们有了 190 万个目标视频列表,我们成功下载了 180 万个视频 (一些视频被频道所有者删除,一些视频更改了权限)。
我们探索了两种不同的分布式下载方法。 选项 1: Video2dataset
video2dataset 是一个开源项目 [链接],专注于分布式视频下载、转换和打包为不同的数据集格式。该项目原生支持 Slurm 工作负载管理器,因此我们可以在我们的 CPU 集群上运行它。
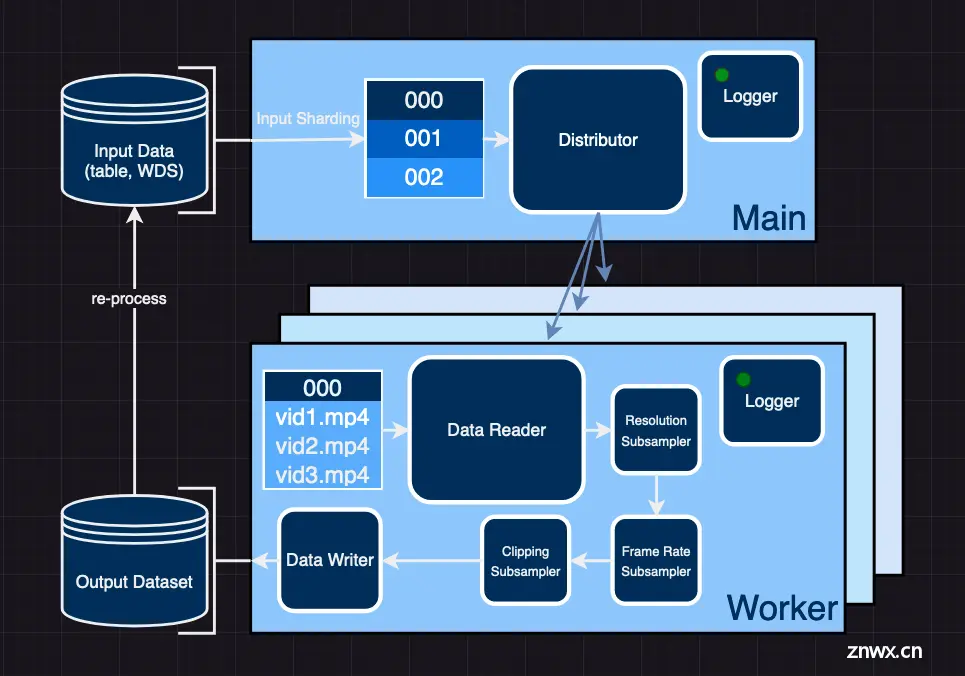
来源: Video2Dataset GitHub 页面
由于我们所有集群实例都通过相同的公共 IP 访问互联网,我们为项目贡献了指定代理的可能性,以方便视频下载。虽然该功能尚未合并,但你可以通过我们的 PR [链接] 修补 video2dataset 以使用代理功能。
选项 2: 云批处理作业
大多数云提供商都有通过简单定义执行每项作业的实例类型、定义队列并提供包含将执行的代码的容器来运行作业的可能性。
我们使用 Google Cloud 和 AWS 运行一个自制的 Docker 容器,使用 ytdlp 下载视频和元数据,并将结果推送到 S3。
构建 Docker 容器的文件可在此处找到 [代码]。
我们的结论
虽然 Video2Dataset 在有代理的情况下是可行的,并允许我们进行额外的处理步骤,但我们能够对代理进行的每秒请求数成为了瓶颈。这使我们转向云批处理作业。
保留动态内容
在我们的最佳视频搜索中,我们将选择范围缩小到既有视觉动作又有中等快速语速的内容。我们通过词密度过滤和视觉动态性过滤来实现这一点。
词密度过滤
我们以视频中的词密度作为音频动态性的代理。词密度的定义为:
<code>词密度 = 闭 captions 中的单词数 / 视频总时长 (秒)
通过在不同密度阈值下采样并视觉评估内容质量,我们决定删除词密度低于 0.5 词/秒的所有视频。
示例:
| 词密度 | 示例 |
|---|---|
| 0.25 | 点击查看示例视频 |
| 0.5 | 点击查看示例视频 |
| 0.75 | 点击查看示例视频 |
| 1.0 | 点击查看示例视频 |
词密度过滤和探索示例的代码可在此处找到 [链接]
视觉动态性过滤
我们重新利用 FFMPEG 的 Freezedetect 过滤器 来判断视频的动态性。虽然此过滤器旨在识别视频中的冻结部分 (多个相同帧连续放置),但我们可以通过将 noise 参数设置为非常高的值来识别低运动块。
我们不是在整个视频上运行 freezedetect,而是通过时间片段分析视频,并根据被分类为静态的片段数量来投票视频是否静态。通过手动评估,我们设置了一个阈值,如果分析的片段中有 40%是低运动的,则丢弃该视频。
经过此过滤后丢弃的一些内容类型:
| 类型 | 示例 |
|---|---|
| 静态图像配音乐 | 点击查看示例视频 |
| 演示屏幕录制 | 点击查看示例视频 |
| 高度静态的人对着摄像头说话 | 点击查看示例视频 |
分类视频动态性的 DockerFile 和代码可在此处找到 [链接]
从分析的 180 万个视频中,经过此步骤后我们保留了 60 万个动态视频。在这一阶段,我们深入研究视频内容,这对于确保数据集的多样性至关重要。
视频分类
为了实现最多样化的内容选择,我们使用闭 captions 和 YouTube 元数据对 60 万个过滤后的资产进行分类。为了在分类过程中获得控制,我们创建了一个分类法,并指导标注过程以遵循该分类法。
自定义构建的分类法
我们使用 GPT4-o 引导自定义构建的分类法,并由信息科学家审查和调整。该分类法包含 126 个细分类别,分为多个层次。这种多层次的方法允许 FineVideo 的用户根据其特定用例对数据集进行切片。
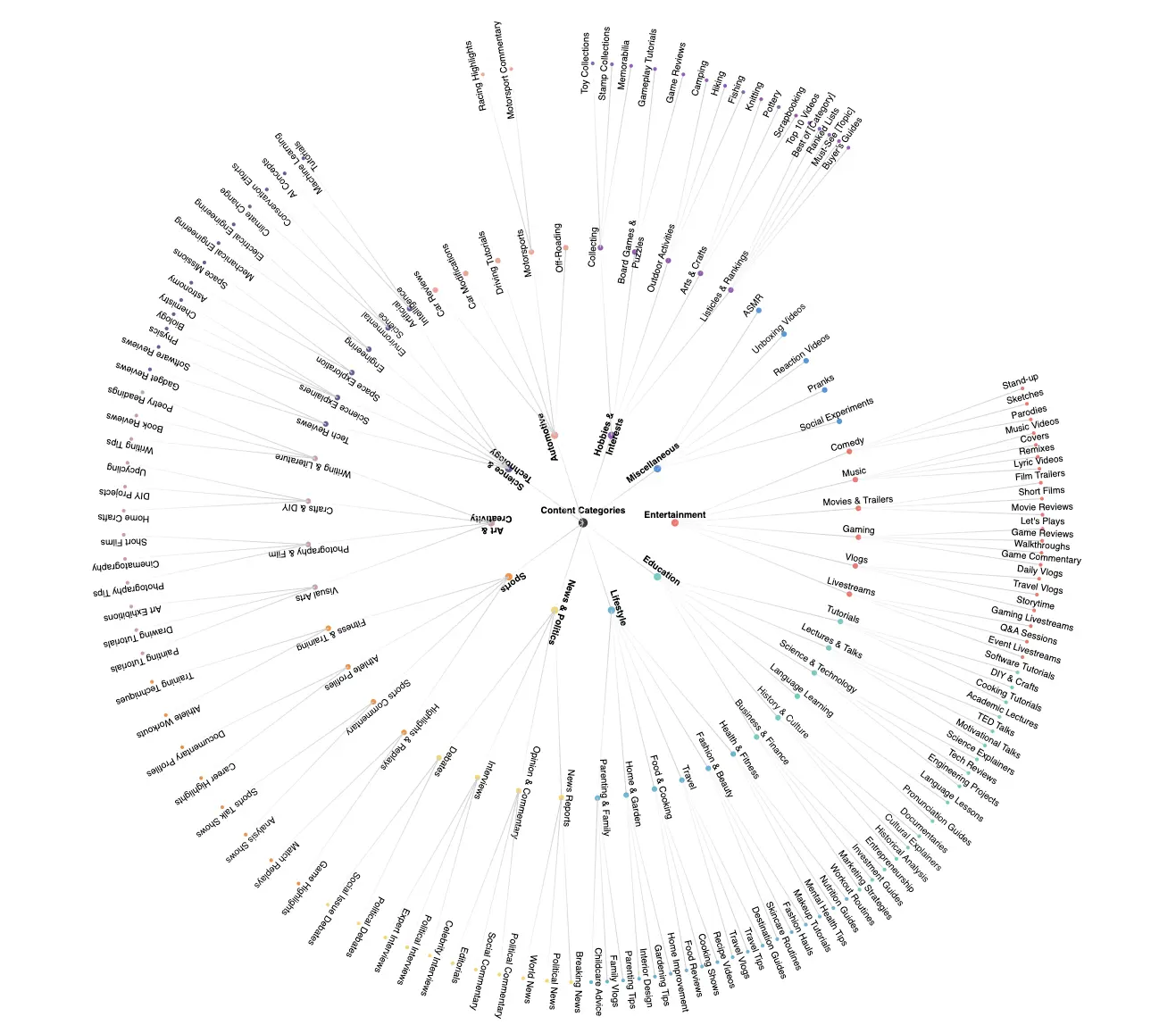
分类法也可在 JSON 中找到 [链接]
通过初始版本的分类法,我们开始内容标注,并通过查看内容标注的结果,在信息科学家的帮助下,我们相应地调整了分类法。
内容标注
我们使用 Llama 3.1 70B 通过 Text Generation Inference TGI [代码] 对视频进行分类。
提示需要多次迭代以确保答案严格是我们分类法中的一个类别。在我们的提示评估过程中,我们发现通过从提示中删除现有的 YouTube 标签和类别,结果的质量显著提高: YouTube 元数据使 Llama 3.1 生成的文本偏向于 YouTube 提供的类别之一。
<code>prompt_template = """
给定这些类别: {leaves}
根据其闭 captions 和一些元数据细节对 YouTube 视频进行分类。仅返回所选类别,不要返回其他内容!
标题: {title}
描述: {description}
频道: {channel}
闭 captions: {closed_caption}
"""
分类法反馈循环 - 内容标注
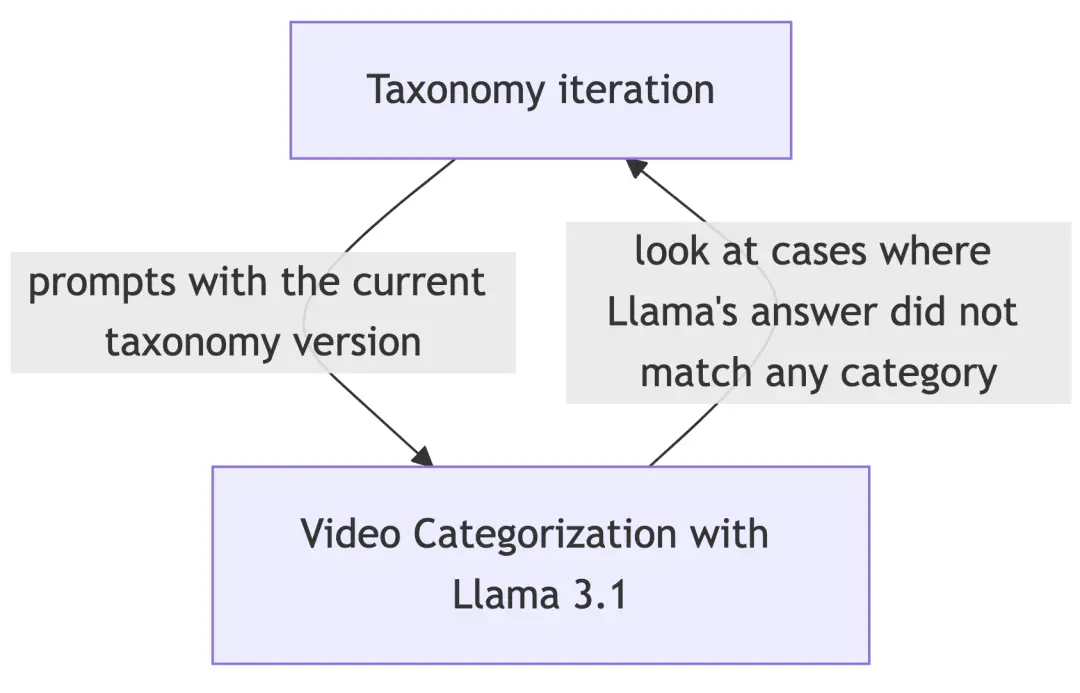
分类法调整在内容分类过程中的反馈循环
信息科学家的角色之一是随着时间的推移对分类法进行调整,以添加新类别或在需要时增加一些额外的区分度。
使用 LLMs 进行内容分类将分类法的调整时间从几个月/年缩短到几小时。此外,在某些情况下,我们创建了专门用于丢弃敏感视频的类别,例如属于 <code>Firearms & Weapons 和 Substance Use & Drugs 的视频。
贡献描述性元数据
在这一阶段,我们有三个视频级别的元数据来源:
- 视频类别 (使用 Llama 3.1 推断)
- YouTube 元数据 (标题、描述)
- YouTube-Commons 的转录
为了在视频理解领域做出贡献,我们决定深入到时间码级别的元数据,例如活动、对象、叙事和编辑方面。
虽然我们考虑过将人工标注作为主动学习设置的一部分,其中一个或多个模型提出标注,人工进行 QA 步骤,但我们发现 Gemini 是一个很好的解决方案,特别是在我们限制了输入视频长度和输出格式的情况下。
长视频 & Gemini 1.5 Pro
我们深入研究了 Gemini 1.5 Pro,迭代我们的提示并测试了不同内容长度。
由于其限制为 1M 个 token,这大约相当于~1 小时的视频,我们被迫丢弃超过 1 小时的视频。
为了克服这种情况,我们尝试加速超过 1 小时的视频,以便适应 Gemini 的上下文。d
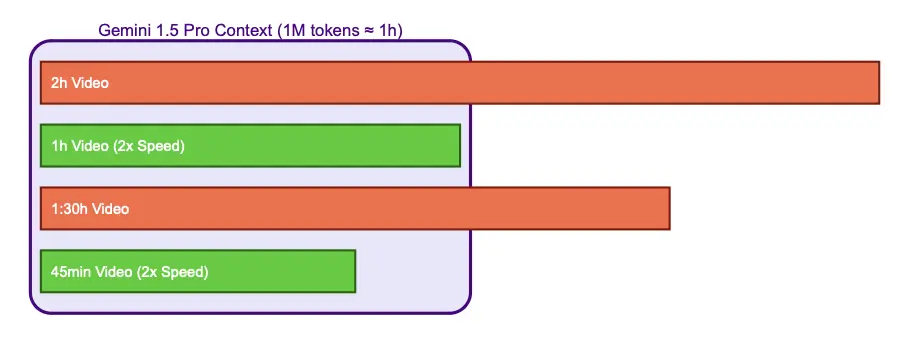
探索: 加速视频以适应 Gemini 的上下文
虽然在高层次上似乎有效,但当我们开始查看细节时,我们发现只有视频的前几分钟被准确标注。
发现质量在长视频上下降,我们想知道这是否会影响我们其余的视频?通过采样不同长度的视频并检查标注的视频覆盖率,我们发现超过 10 分钟的视频质量有所下降。
为了与我们的目标一致,即向社区提供高质量的数据,我们丢弃了超过 10 分钟的视频。
内容选择
由于每小时的视频使用 Gemini 标注成本超过 5 美元,我们不能标注所有经过过滤的视频。因此,我们希望确保在所有主题上都有良好的覆盖,并在内容多样性和预算之间找到一个良好的平衡。我们将此大小约束设置为 4,000 小时的视频。
为了从 60 万个视频中选择 4,000 小时的内容,我们准备了一个算法,该算法平衡了内容类别、用户参与度和频道代表性,以达到目标时长。
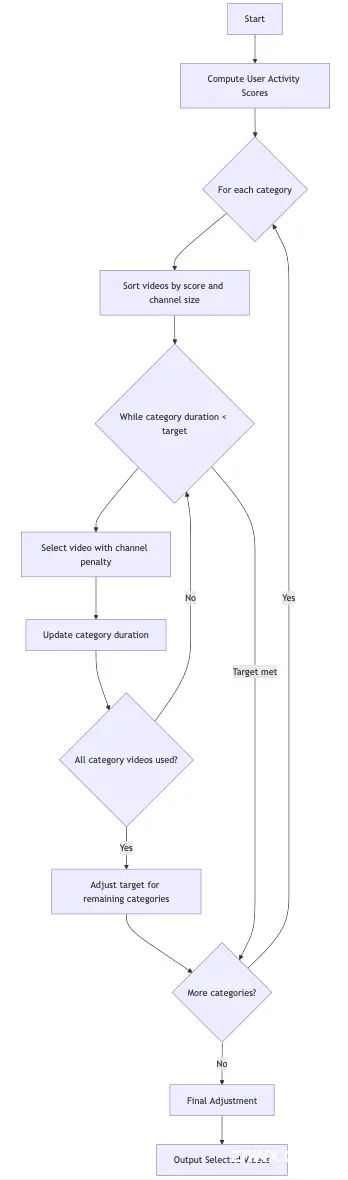
内容选择算法的一些关键部分:
- 活动评分: 我们通过结合评论、观看和点赞数量计算每个视频的参与度指标,并赋予不同权重。此评分有助于优先考虑与观众产生共鸣的视频。
- 视频选择: 此步骤迭代选择视频以达到目标时长,同时确保多样性。它在高参与度内容和各种类别及频道的代表性之间进行平衡,使用惩罚系统避免任何单一频道的过度代表。
- 最终调整: 我们调整选择以尽可能接近目标时长,而不超过它。它按时长对选定的视频进行排序,并将它们添加到最终列表中,直到达到最接近目标总时长的可能。
代码可在此处找到 [链接]。
使用 Gemini 1.5 Pro 和 GPT4o 进行结构化输出标注
为什么需要结构化数据?
我们构建 FineVideo 的目标之一是提供结构化数据,以赋能我们的社区: 如果你正在研究多模态 LLMs,你可以对数据进行切片,并决定哪些类别适合你的预训练或微调组合。如果你更关注计算机视觉,你可以直接使用数据集来训练基于 FineVideo 中包含的数值类别的分类器,例如动态性评分、场景边界或音视频相关性评分。
结构化数据和 Gemini 1.5
Gemini 1.5 Pro 允许通过提供模式生成基于 JSON 的输出。我们探索了这一功能,并很快意识到两个问题:
- 我们无法将原始模式适应 Gemini,因为我们的模式非常复杂
- 当我们尝试使用稍微简化的模式 (仍然相当复杂) 时,Gemini 结果的质量显著下降: 大多数场景类型的数据 (角色、活动、道具) 丢失。我们尝试将提示拆分为多个提示,并将不同的提示匹配到模式的不同部分,但没有取得太大成功。
我们观察到的完全符合其他研究人员的经验: 添加具体的模式约束可能会降低性能。(Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models)。
我们的解决方案依赖于使用 Gemini 1.5 生成自由文本,并添加第二步处理步骤,将 Gemini 的结果与我们的模式对齐。
我们使用的 Gemini 提示如下:
<code>研究视频并提供以下关于视频和构成它的语义场景的详细信息:
- characterList: 在整个视频中出现的角色列表,以及一个视觉描述,应该允许我只看一张他们的图片就能识别他们。
- scenes: 场景列表,具有以下属性:
- 场景的开始/结束时间戳
- 场景中出现的所有角色列表
- 所有活动及其时间戳列表
- 所有道具及其时间戳列表
- 所有视频编辑细节及其开始/结束时间戳列表。细节包括过渡、效果、音乐以及建议,如可以删除的场景片段及其原因
- 场景情绪,并附上视觉效果、音频和上下文如何贡献的说明。使用以下分类法,仅返回名称: {"moods":{"Positive":[{"name":"Happy","description":"Feeling joyful, content, or delighted."},{"name":"Excited","description":"Feeling enthusiastic, energetic, or eager."},{"name":"Calm","description":"Feeling peaceful, relaxed, or serene."},{"name":"Grateful","description":"Feeling appreciative or thankful."},{"name":"Proud","description":"Feeling satisfied with one's achievements or the achievements of others."}],"Negative":[{"name":"Sad","description":"Feeling down, unhappy, or sorrowful."},{"name":"Angry","description":"Feeling irritated, frustrated, or furious."},{"name":"Anxious","description":"Feeling nervous, worried, or uneasy."},{"name":"Lonely","description":"Feeling isolated, disconnected, or abandoned."},{"name":"Bored","description":"Feeling uninterested, disengaged, or restless."}],"Neutral":[{"name":"Indifferent","description":"Feeling neither particularly positive nor negative."},{"name":"Content","description":"Feeling satisfied but not overly excited."},{"name":"Curious","description":"Feeling interested or inquisitive without strong emotion."},{"name":"Confused","description":"Feeling uncertain or unclear but without strong negative feelings."},{"name":"Pensive","description":"Feeling thoughtful or reflective without strong emotional engagement."}]}}
- 场景内的特定情绪变化时刻,报告时间戳以及我们在任何维度 (视觉/听觉) 中的过渡
- 场景叙事进展和情节发展
- 场景内的特定叙事时刻。报告时间戳和发生的事情
- 角色互动和动态描述及其开始/结束时间戳
- 特定主题元素和描述
- 特定相关事件,以创建更深层次的意义和潜台词,未明确说明但有助于内容的丰富性和深度,时间戳和描述
- 场景动态性评分。评分范围为 0 到 1。1 为高度动态
- 音视频相关性评分。评分范围为 0 到 1。0 表示我们看到的内容与语音不相关,1 表示高度相关
- storylines: 找到的不同故事线列表以及哪些场景属于它。
- 指定高潮 (场景和时间戳),如果内容呈现叙事故事,或者更像是一个事实或非叙事信息的集合
- 如果有不属于故事线的场景,解释这些场景如何对视频做出贡献
- 从整体视频和故事线来看,哪些视频片段可以修剪以使其更具动态性?
- q&a: 关于视频的 5 个问答列表,重点关注细节 (对象和/或活动) 、整体故事推理和情绪。尽可能关注音频和视频中捕捉到的 Q&A 方面,仅通过查看转录难以获得。
添加 Instructor
一旦 Gemini 处理了结果,我们使用 Instructor 对其进行解析: 一个基于 Pydantic 的库,用于在给定模式的情况下实现结构化输出。请参见下表中的示例。
Instructor 允许我们使用不同的模型来将 Gemini 的自由文本转换为我们定义的 Pydantic 模式。我们尝试了 Gemini 和 GPT4o,并最终选择了 GPT4o,因为其成功率更高。
视频
点击查看视频
Gemini 输出
CharacterList:
Man Slim build, brown eyes, shaved sides, black hoodie with colorful logo, black pants.
Scenes
Scene 1
Start 0:00 End 0:55
Characters: [Man]
Activities:
Introduces bus
Describes peaceful location with cows
Props: Bus, cows, deck.
Mood:Excited, adventure.
Narrative Progression:
Introduction to bus.
Tour begins outside, highlighting nature and relaxation.
Dynamism Score 0.7
Audio-Visual Correlation 1
Instructor 输出
{
"title": "Bertie the Bus Tour",
"description": "Guided tour of converted bus.",
"characterList": [
{
"name": "Narrator",
"description": "Slim build, brown eyes, shaved sides, black hoodie with colorful logo, black pants."
}
],
"scenes": [
{
"sceneId": 1,
"title": "Introduction to Bus",
"timestamps": {
"start": "0:00",
"end": "0:55"
},
"cast": ["Narrator"],
"activities": [
"Narrator speaks in front of bus",
"Shows outdoor deck with chairs, cows nearby."
],
"props": ["Bus", "Deck", "Cows"],
"mood": "Excited, adventure."
}
],
"dynamismScore": 0.7,
"audioVisualCorrelation": 1
}
值得注意的是,Gemini 的内容过滤会丢弃一些视频,这是使用 Gemini 时可能发生的情况。在我们的案例中,由于我们目标的内容量,Gemini 过滤掉的总分钟数可以忽略不计。
标注视频的完整代码可在此处找到 [链接]。
精细对齐和异常过滤
在视频标注并将其数据正确对齐到我们的模式后,我们查看数据的时域,并确保其与视频对齐: Gemini 1.5 以每秒 1 帧的速度读取视频,而视频通常有 25-29 帧每秒。在我们的精细对齐中,我们确保 Gemini 1.5 提供的场景边界与视频中的正确帧匹配。
我们还使用这种时域对齐来丢弃 Gemini 停止提供有用数据且视频部分被错误标注的情况。请注意,由于我们在管道早期丢弃了所有超过 10 分钟的内容,因此质量差的数据视频数量可以忽略不计 (低于 0.5%)。
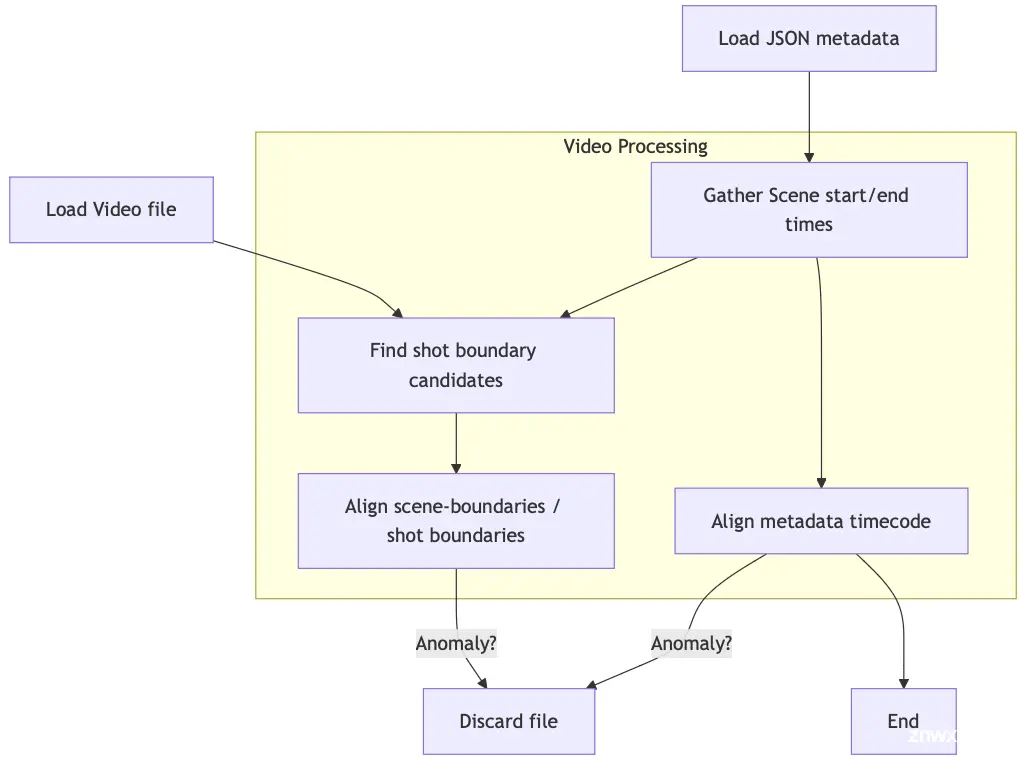
精细元数据 - 视频场景边界到镜头对齐作为丢弃异常值的机制
视频对齐的代码可在此处找到 [链接]
未来工作
我们目前正在准备使用 FineVideo 训练多模态 LLM,我们计划在完成后与社区分享模型权重和训练配方。
我们也对 FineVideo 的其他扩展持开放态度,请告诉我们你希望看到什么!
原文链接: https://hf.co/blog/fine-video
原文作者: Miquel Farré, Andres Marafioti, Lewis Tunstall, Leandro von Werra, Pedro Cuenca, Thomas Wolf
译者: roseking
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。