【1】从零开始学习目标检测:YOLO算法详解
CSDN 2024-07-08 16:01:03 阅读 87
从零开始学习目标检测:YOLO算法详解
文章目录
从零开始学习目标检测:YOLO算法详解1. 🌟什么是目标检测?2.🌟传统的目标检测与基于深度学习的目标检测3.🌟目标检测算法的工作流程4.🌟目标检测可以干什么?5.🌟什么是YOLO
在过去的十年中,深度学习技术的发展引起了极大的关注,并成为人工智能领域中不可或缺的技术之一。深度学习在计算机视觉领域的应用越来越广泛,其中目标检测是备受关注的领域之一。目标检测是指在图像或视频中检测出目标的位置和边界框,然后对目标进行分类或识别。目标检测在计算机视觉领域中具有非常重要的应用,如目标跟踪、目标检索、视频监控、图像字幕、图像分割、医学影像等等。除了这些应用场景外,目标检测还可以应用于自动驾驶、机器人视觉、智能安防等领域。
1. 🌟什么是目标检测?

目标检测、分类和分割是计算机视觉领域中的三个重要任务,它们在输入和输出上有所不同,具体区别如下:
目标检测
目标检测的目标是在图像或视频中检测出目标的位置和边界框,然后对目标进行分类或识别。这个任务需要同时完成目标的位置定位和分类任务。目标检测输出的结果包括目标的位置和类别。简单来说,目标检测就是让计算机能够找到图像中的物体,并给出它们的位置和边界框。
分类
分类的目的是将事物按照其特征或属性进行归类或分组。简单来说,分类就是给事物贴上标签,将它们分成不同的类别。
分割
分割的目标是将图像分成不同的区域,每个区域代表图像中的不同物体或对象。简单来说,分割就是将图像按照物体的边界进行划分,让计算机能够识别和理解图像中的每个部分。通过分割,我们可以将图像中的不同物体从背景中分离出来,使计算机能够对它们进行独立处理和分析。
可以看出,目标检测是分类和分割的进一步扩展,需要同时完成物体位置的定位和分类任务。分类和分割通常只需要对整张图像或视频进行分析,而目标检测需要在图像中识别出物体的位置和边界框。在实际应用中,这三种任务通常会同时使用,以实现更精确和全面的图像分析和理解。
2.🌟传统的目标检测与基于深度学习的目标检测
目标检测方法通常可以分为基于机器学习和基于深度学习两类方法。
基于机器学习的目标检测方法
基于机器学习的目标检测方法通常使用传统的机器学习算法,例如支持向量机、<code>AdaBoost和随机森林等。这些方法的基本思想是提取图像特征并使用分类器对特征进行分类,然后使用对象检测器检测目标。这些算法需要手动选择和提取图像特征,因此需要领域专家的知识和经验。
基于深度学习的目标检测方法
基于深度学习的目标检测方法通常使用深度神经网络来自动学习特征并进行目标检测。目前比较流行的深度学习目标检测方法包括两类:基于区域提取的方法(两阶段检测方法)和单阶段检测方法。其中,基于区域提取的方法包括<code>R-CNN、Fast R-CNN、Faster R-CNN和Mask R-CNN等,它们主要通过候选区域提取器生成目标候选区域,并使用CNN网络对每个候选区域进行特征提取和分类。而单阶段检测方法则直接从图像中提取目标位置和类别信息,例如YOLO和SSD等,它们可以实现更快速的检测速度。

3.🌟目标检测算法的工作流程
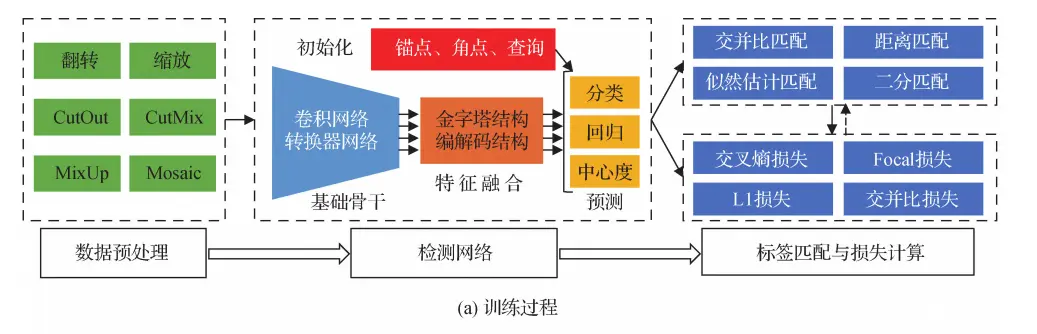
基于深度学习的目标检测主要包括训练和测试两个部分。训练的主要目的是利用训练数据集进行检测网络的参数学习。测试的主要目的是在经过训练后,评估检测网络的性能表现。
训练阶段
数据预处理:在训练数据集中,包含了大量的视觉图像和标注信息,如物体位置和类别。数据预处理的目的是通过对训练数据集的增强来提升检测网络的检测能力。常用的数据增强技术包括图像翻转、缩放、均值归一化和色调变化等。这些技术可以增加训练数据的数量和多样性,从而提高检测器的泛化能力。检测网络:检测网络一般由基础骨干、特征融合和预测网络三个部分组成。基础骨干通常采用用于图像分类的深度卷积网络,如<code>AlexNet、VGGNet、ResNet和DenseNet等。近期,基于Transformer的网络,如ViT、Swin和PVT等也开始被用于目标检测。在训练开始时,通常将在大规模图像分类数据库ImageNet上训练的预训练权重作为检测器骨干网络的初始权重。特征融合:特征融合是对基础骨干提取的特征进行融合,用于后续分类和回归。常见的特征融合方式是特征金字塔结构。预测网络:预测网络主要进行分类和回归等任务。在两阶段目标检测方法中,分类和回归通常采用全连接的方式,而在单阶段的方法中,分类和回归等通常采用全卷积的方式。检测器还需要一些初始化,如锚点框初始化、角点初始化和查询特征初始化等。标签分配与损失计算:标签分配的目的是为检测器预测提供真实值。在目标检测中,标签分配的准则包括交并比(IoU)准则、距离准则、似然估计准则和二分匹配等。基于标签分类的结果,采用损失函数计算分类和回归等任务的损失,并利用反向传播算法更新检测网络的权重。常用的分类损失函数有交叉熵损失函数、聚焦损失函数等,而回归损失函数有L1损失函数、平滑L1损失函数、交并比IoU损失函数、GIoU(generalized IoU)损失函数和CIoU(complete-IoU)损失函数等。非极大值抑制:在目标检测的输出结果中,可能会出现多个框或分割掩模与同一个物体相关联的情况,这些检测结果会产生冗余。因此需要使用非极大值抑制(NMS)技术,将多个重叠的检测结果进行筛选,只保留最有可能代表物体的检测结果。NMS的基本思想是通过比较检测结果的置信度得分,去除重叠框中得分较低的框,只保留得分最高的框。目标检测的评估指标:为了评估目标检测算法的性能,需要使用一些评估指标。常用的评估指标包括准确率(Precision)、召回率(Recall)、F1值、平均精度(Average Precision,AP)、均值召回率(Mean Average Precision,mAP)等。其中,AP是一种常用的评估指标,用于衡量检测器在不同置信度阈值下的性能表现。而mAP是AP的平均值,通常作为衡量整个检测算法性能的指标。
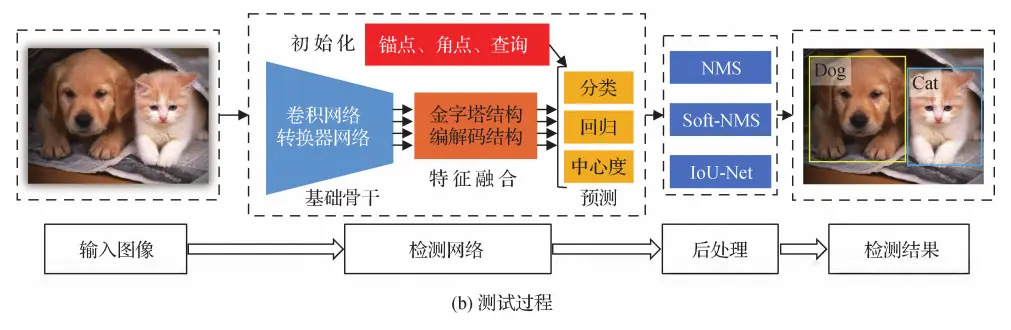
测试阶段
在测试阶段,首先需要输入一张待检测的图像。这张图像会被送入训练好的检测网络中进行处理,这个过程叫做前向传播<code>(forward propagation)。在检测网络中,图像会被分类,确定图像中存在哪些物体,并输出每个物体的位置信息。这些位置信息通常表示为边界框(bounding box),也可以表示为像素级的分割掩模(segmentation mask),它们描述了物体在图像中的位置和大小。
然而,在检测网络输出结果之后,可能会出现多个边界框或分割掩模与同一物体相关联的情况。这可能是因为图像中的物体形状、大小、角度等方面的变化,或者是因为图像的不同区域可能包含相同的物体。因此,需要对这些检测结果进行后处理,以便确定每个物体的最终边界框或分割掩模。
这个后处理过程的目标是为每个物体保留一个检测结果,并去除其他冗余的检测结果。这个过程被称为非极大值抑制(non-maximum suppression,NMS)。它的基本思想是通过比较检测结果的分类得分和位置信息,为每个物体保留一个得分最高的检测结果。在执行 NMS 之后,每个物体将仅对应一个边界框或分割掩模,这是最终的检测结果。
4.🌟目标检测可以干什么?
车辆和行人检测:自动驾驶汽车需要识别道路上的车辆和行人,并对它们的位置和速度进行准确的估计,以便做出正确的决策,例如避让障碍物或停车等。目标检测技术可以用于检测和跟踪道路上的车辆和行人,并估计它们的速度和方向。交通信号灯检测:自动驾驶汽车需要识别交通信号灯的状态,例如红灯或绿灯,以便决定是否停车或继续前行。目标检测技术可以用于检测和识别交通信号灯,并确定其状态。路标检测:自动驾驶汽车需要识别路标,例如标识路口、转弯或合并车道等的标志,以便正确地导航和做出决策。目标检测技术可以用于检测和识别各种路标,并确定它们的含义。障碍物检测:自动驾驶汽车需要检测和避免道路上的障碍物,例如路面上的水坑、石块或垃圾等。目标检测技术可以用于检测和跟踪道路上的各种障碍物,并提供避让策略。入侵检测:目标检测技术可以用于监控视频中的入侵者的自动检测和跟踪,例如未经授权进入建筑物或某个区域的人员。系统可以通过发送警报来及时通知安保人员并采取措施。丢失物品检测:目标检测技术可以用于监控视频中的丢失物品的自动检测和跟踪,例如钱包、手机或其他贵重物品。当系统检测到这些物品被遗失或被人拾起时,可以通过发送警报来通知相关人员。摔倒检测:目标检测技术可以用于监控视频中的摔倒事件的自动检测和跟踪,例如老年人或身体不便的人。系统可以通过发送警报来及时通知相关人员并采取措施。交通监控:目标检测技术可以用于交通监控视频中的车辆和行人的自动检测和跟踪,例如违法停车、超速行驶、路口违规等。系统可以通过发送警报来通知相关部门或管理人员。
再比如以下面智慧园区、智慧社区、智慧金融、智慧消防的应用场景,每种场景都会对应不同的算法功能。



5.🌟什么是YOLO
论文地址:https://arxiv.org/pdf/1506.02640v5.pdf

<code>YOLO (You Only Look Once)是一种目标检测算法,它在单个神经网络中同时完成对象检测和分类的任务。相比传统的目标检测算法,YOLO的主要特点是它采用了单次前向传递的方式进行目标检测。这意味着它能够在一次推理中同时预测图像中所有的目标类别和边界框。这种实时性使得YOLO在许多需要高效处理的应用中非常受欢迎,比如实时视频分析、自动驾驶和物体跟踪等。并且YOLO也是目前工业界应用最普遍的一种算法,我们可以通过YOLO算法实现各种各样的AI视觉任务。
YOLO的卷积神经网络架构是来自GoogleLeNet模型,YOLO的网络有24层卷积和2层全连接,与GoogLeNe不同的地方在于作者在某些3×3的卷积层前用了1×1的卷积降维, 整体结构图如下图所示:
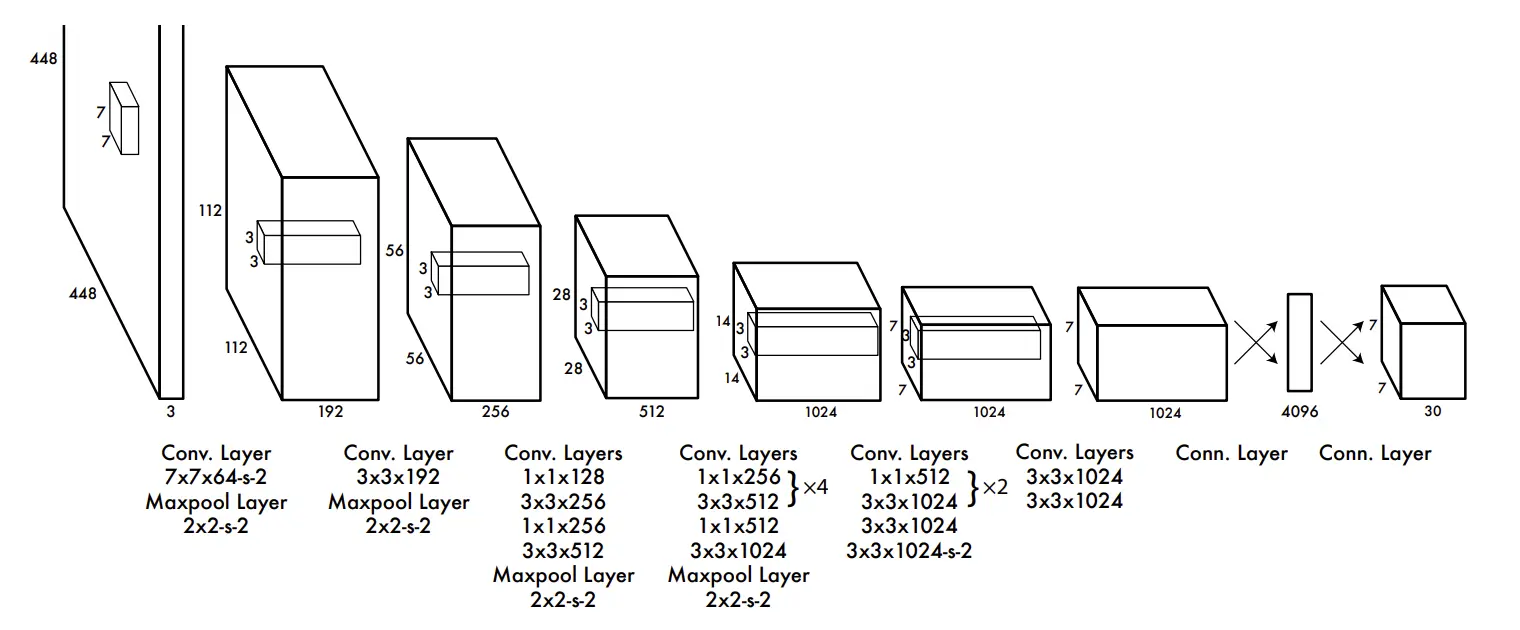
<code>YOLO算法的核心思想是将目标检测问题转化为回归问题。它将图像划分为一个固定数量的网格(比如7×7),每个网格预测固定数量的边界框和它们的置信度和类别概率。边界框指的是目标在图像中的位置和大小,置信度表示边界框中是否存在目标,类别概率表示目标属于哪个类别。
具体来说,YOLO算法将输入图像经过卷积神经网络提取特征后,得到一个S×S×(B×5+C)的张量。其中,S表示网格数量,B表示每个网格预测的边界框数量,C表示类别数量。张量中每个元素都表示一个边界框的信息,包括边界框的中心坐标、宽度、高度、置信度和类别概率。YOLO算法通过对张量进行解码,得到图像中所有目标的位置和类别。
YOLO算法的训练过程是基于交叉熵损失函数的反向传播。对于每个边界框,损失函数包括位置误差、置信度误差和类别误差。YOLO算法通过反向传播更新神经网络的参数,提高目标检测的准确率。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。