AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
CSDN 2024-06-23 13:31:04 阅读 92
博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
目录
一、引言
二、中文开/闭源大模型概览
三、开源大模型
3.1 优点
3.2 缺点
四、闭源大模型
4.1 优点
4.2 缺点
五、总结
一、引言
周日休息在家,只有码字才能缓解焦虑哈哈哈,闲逛CSDN发现又出新的话题活动啦——《开源大模型和闭源大模型,你怎么看》。“我怎么看?我坐着看,或者躺着看”。OpenAI变成CloseAI,你会发现,虚伪,是全世界的通病。扯远了哈哈,我认为,开源可以短时间让自家的大模型快速得到传播,构建影响力以及让行业内更多的人参与建设,完善技术栈。闭源可以维护较为健康的商业模式,高薪招聘更多优秀的人才继续进行迭代升级。存在即合理,从ios vs android,打到GPT4 vs LLama3,可能永远不会有胜负。今天我们详细聊聊中文大模型开闭源的那些事。
二、中文开/闭源大模型概览
大家先看《2024年中文大模型全景图》,对国内中文大模型开闭源情况有个概念。
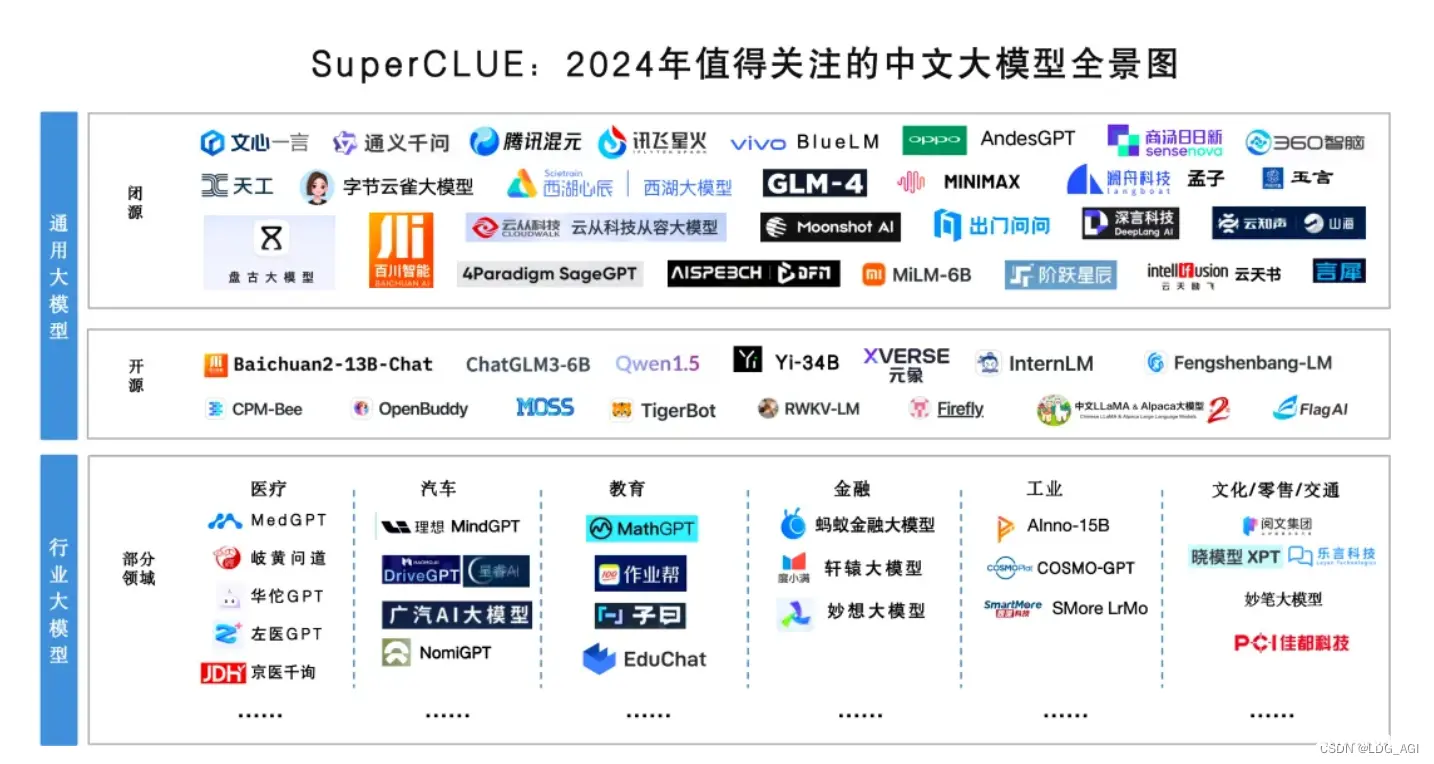
Tips:图片引自SuperCLUE中文大模型基准测评2024年4月报告,国内领先的大模型评测公司,高中室友创办的,没想到毕业多年,兜兜转转进入到了一个行业,如需合作需要可以联系我哈
闭源大模型:主要有文心一言、通义千问、腾讯混元、字节云雀、MINIMAX、GLM-4、Baichuan4、Moonshot月之暗面等。
开源大模型:主要有baichuan2-13B-Chat、ChatGLM3-6B、Qwen1.5、Chinese-LLaMA-Alpaca-3等。
从商业模式上讲,又可以分为3类。
以百度、MINIMAX为代表的完全闭源大模型:只提供商业化接口,高版本收费、低版本免费。以阿里为代表的部分开源、部分闭源:既提供商业化接口,又提供开源模型,两条腿走路,并驾齐驱都在升级迭代。以百川为代表的前期低版本开源、后期高版本闭源:前期通过baichuan-13B、baichuan2-13B快速打出名气,后来更高版本的baichuan3、baichuan4只提供商业化接口。
目前国内大模型发展可以用“兵荒马乱”来形容,谁能在最后杀出重围,还需要时间去考量,下面针对开、闭源的优缺点,谈一谈个人想法。
三、开源大模型
3.1 优点
1、创新和灵活性:开源模型鼓励创新,研究人员和开发者可以自由探索和改进模型,推动技术的发展。
2、社区协作:开源社区的力量不可忽视,众多开发者共同参与,能够快速发现和解决问题,加速模型的优化和完善。
3、低成本和可访问性:开源模型通常是免费的,降低了使用门槛,使更多人能够受益于先进的技术。
4、透明度和可解释性:源代码公开,有助于更好地理解模型的工作原理,提高模型的可解释性和可信度。
5、适应多样化需求:开源模型可以根据不同的应用场景和需求进行定制和扩展,满足个性化的要求。
3.2 缺点
1、质量和稳定性:由于开源模型的开发和维护分散,质量和稳定性可能存在一定的差异。
2、缺乏商业支持:开源模型通常没有商业公司提供的专业支持和服务,在遇到问题时可能需要自己解决。
3、训练和部署难度:对于一些复杂的大模型,训练和部署可能需要较高的技术水平和计算资源。
4、数据隐私和安全:开源模型可能涉及数据的共享和使用,需要注意数据隐私和安全问题。
5、知识产权风险:在使用开源模型时,需要注意遵守相关的开源协议,避免知识产权纠纷。
四、闭源大模型
4.1 优点
1、质量和稳定性保障:闭源模型通常由专业的团队开发和维护,经过严格的测试和验证,质量和稳定性相对较高。
2、商业支持和服务:商业公司提供闭源模型时,通常会附带专业的支持和服务,包括培训、技术支持等。
3、易于使用和集成:闭源模型通常提供了友好的用户界面和 API,便于开发者使用和集成到自己的系统中。
4、数据隐私和安全保护:商业公司通常会采取措施保护用户的数据隐私和安全。
5、持续更新和改进:商业公司会不断对闭源模型进行更新和改进,以提供更好的性能和功能。
4.2 缺点
1、成本较高:闭源模型通常需要用户购买许可证或订阅服务,成本相对较高。
2、缺乏透明度:用户无法直接查看模型的源代码,对模型的工作原理和内部机制了解有限。
3、定制和扩展性受限:闭源模型的定制和扩展性可能受到一定的限制,无法完全满足个性化需求。
4、社区参与度低:相比开源模型,闭源模型的社区参与度较低,开发者之间的交流和合作相对较少。
5、依赖供应商:用户对闭源模型的使用和发展较为依赖供应商,一旦供应商出现问题,可能会影响用户的使用。
五、总结
可以看到,开源和闭源模型各有其优缺点,选择适合自己需求的模型需要综合考虑多方面因素。在实际应用中,可以根据具体情况权衡利弊,并结合自身的技术能力和资源来做出决策。此外,随着技术的不断发展,开源和闭源模型的界限也在逐渐模糊,一些商业公司也开始采用开源的模式来推动技术的进步。
对于AI智能体开发而言,个人实际工作中,既使用闭源商业化接口,首先是省心,不用自己申请机器、部署、维护模型服务;其次是省钱,相较于购买GPU显卡,价格战下的商业接口便宜的可怕;最后是真的很好用,一般商业化的接口模型尺寸都要高于开源版,Agent开发过程中调用一些Tools就能达到极好的效果。又使用开源微调私有化部署模型,首先是安全,考量到数据安全,业务数据轻易不能外漏,安全意识很重要,如果外泄未来可能是雷区;其次是可微调,使用较大尺寸的模型,配以精选后的微调数据,画风上明显会有一定提升;最后是杀鸡焉用牛刀,对于一些简单任务,比如任务判断、工具选择、文本处理等一些简单但重复度高的工作,使用私有化部署的模型,长期看是可以节约成本的。
本文首先对国内中文大模型开闭源情况进行概述,其次区分开源、闭源分析优缺点,最后谈了谈工作中的感想,期待您的关注与互动噢,如果还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
上一篇: 【AI落地应用实战】LLM + TextIn文档解析技术实测 暨基于TextIn文档解析 + Kimi的智能文档解析助手
下一篇: python安装opencv报错ERROR: Could not build wheels for opencv-python, which is required to install pyproj
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。