【Arxiv2023】Detect Everything with Few Examples
普莱姆 2024-08-28 10:01:02 阅读 81
【Arxiv2023】Detect Everything with Few Examples
机构:罗格斯大学
论文地址:https://arxiv.org/abs/2309.12969v3
代码地址:https://github.com/mlzxy/devit
本文提出了小样本目标检测领域的SOTA方法DE-ViT,采用元学习训练框架。DE-ViT提出了一种新的区域传递机制用于检测框定位,并且提出了一种空间积分层来讲mask转化为检测框输出。DE-ViT相比之前的方法提升巨大,在COCO数据集上,10-shot提升15AP,30shot提升7.2AP。
文章贡献/创新点
提出了一种FSOD的SOTA方法,DE-ViT,不需要微调。提出了一种新的区域传递框架,一个将mask转化为box的空间积分层,和一个新的特征投影层。DE-ViT在多个小样本和单样本检测任务上取得了SOTA性能。
虽然本文的性能很高,但本文采用的是DINO预训练的ViT,而不是其他方法采用的ResNet101作为backbone,所以其性能提升也有很大成都是来自于backbone的改进。
小样本目标检测(FSOD)任务定义
FSOD任务有基类
C
b
a
s
e
C_{base}
Cbase和新类
C
n
o
v
e
l
C_{novel}
Cnovel两种类别,
C
=
C
b
a
s
e
∪
C
n
o
v
e
l
C=C_{base}\cup C_{novel}
C=Cbase∪Cnovel并且
C
b
a
s
e
∩
C
n
o
v
e
l
=
∅
C_{base}\cap C_{novel}=\emptyset
Cbase∩Cnovel=∅,基类有足够多的样本而新类只有少量样本。对于
K
K
K-shot小样本任务,数据集中的每个新类只有
K
K
K个检测框标注,通常
K
=
1
,
3
,
5
,
10
,
30
K=1,3,5,10,30
K=1,3,5,10,30。
区域传递网络
文章认为,尽管预训练的ViT有很多语义信息,但缺乏用于box回归的坐标信息。通常做法是在基类上微调ViT backbone,但文章发现微调会导致ViT完全过拟合base类别而在新类上性能降低。这一点根据实验结果也可以看出来,如果直接微调的话,基类上
bAP
50
=
48.9
\text{bAP}_{50}=48.9
bAP50=48.9、
bAP
75
=
22.5
\text{bAP}_{75}=22.5
bAP75=22.5,性能很高,而新类上
nAP
50
=
4.5
\text{nAP}_{50}=4.5
nAP50=4.5、
nAP
75
=
2.2
\text{nAP}_{75}=2.2
nAP75=2.2性能很低,说明直接微调会验中过拟合到base类别上,新类根本训不出来。
新类上性能折半的问题在很多方法中都有存在,尤其是基于微调的方法。例如,TFA方法在10-shot的COCO数据集上基类上
bAP
=
33.9
\text{bAP}=33.9
bAP=33.9而新类上
nAP
=
10
\text{nAP}=10
nAP=10,在30-shot的COCO数据集上基类
bAP
=
34.5
\text{bAP}=34.5
bAP=34.5而新类
nAP
=
13.5
\text{nAP}=13.5
nAP=13.5。在新类上的性能下降比较严重。
为了解决这个问题,文章先用现成的RPN网络为图片生成候选区,并将候选区扩大一定比例来获取上下文信息。这些初始候选区会输入区域传递网络,经过逐层传播和微调,让其逐步拟合到物体真值检测框。而在微调过程中,作者并没有直接预测bounding box坐标,而是先预测mask输出,然后提出了一种可学习的空间积分层来将mask转化为bounding box输出。整体框架如下图所示:
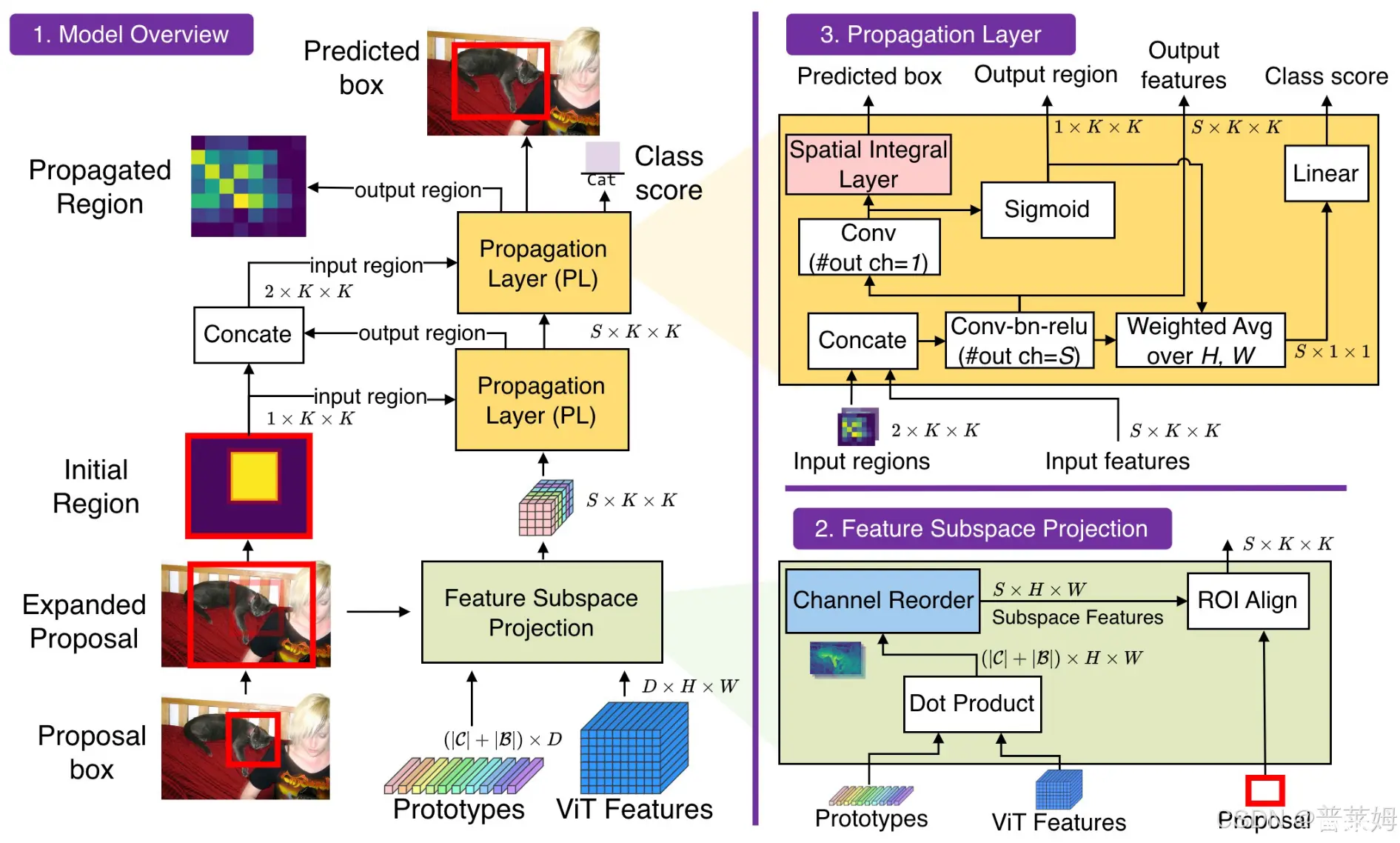
区域传递层
假设图片经过backbone和RoI后得到了相应的候选区
r
r
r和相应的候选区特征
h
h
h。区域传递层会根据之前所有次传播输出的候选区
r
0
:
t
−
1
∈
R
t
×
K
×
K
r_{0:t-1}\in\mathbb R^{t\times K\times K}
r0:t−1∈Rt×K×K和上一次传播输出的候选区特征
h
t
−
1
∈
R
S
×
K
×
K
h_{t-1}\in\mathbb R^{S\times K\times K}
ht−1∈RS×K×K来输出更新后的候选区
r
t
∈
R
1
×
K
×
K
r_t\in\mathbb R^{1\times K\times K}
rt∈R1×K×K、特征
h
t
∈
R
S
×
K
×
K
h_t\in\mathbb R^{S\times K\times K}
ht∈RS×K×K、检测框坐标
b
t
∈
R
4
b_t\in\mathbb R^4
bt∈R4和类别分数
c
t
∈
R
c_t\in\mathbb R
ct∈R。除了
b
t
b_t
bt和
c
t
c_t
ct,PL模块的其他输入和输出是相同的,因此可以堆叠提高性能。下面是PL模块的更新准则:
h
t
=
f
update
,
t
(
c
o
n
c
a
t
(
r
0
:
t
−
1
,
h
t
−
1
)
;
θ
)
,
h
t
,
r
e
g
i
o
n
=
f
region
,
t
(
h
t
;
θ
)
r
t
=
σ
(
h
t
,
r
e
g
i
o
n
)
,
b
t
=
f
integral
,
t
(
h
t
,
r
e
g
i
o
n
;
θ
)
c
t
=
f
class
,
t
(
WeightedAvgPool
(
h
t
,
r
t
)
;
θ
)
h_t=f_{\text{update},t}(\mathrm{concat}(r_{0:t-1},h_{t-1});\theta), h_{t,region}=f_{\text{region},t}(h_t;\theta)\\ r_t=\sigma(h_t,region), b_t=f_{\text{integral},t}(h_{t,region};\theta)\\ c_t=f_{\text{class},t}(\text{WeightedAvgPool}(h_t,r_t);\theta)
ht=fupdate,t(concat(r0:t−1,ht−1);θ),ht,region=fregion,t(ht;θ)rt=σ(ht,region),bt=fintegral,t(ht,region;θ)ct=fclass,t(WeightedAvgPool(ht,rt);θ)
可以看到基本的传播逻辑是:新的候选区特征
h
t
h_t
ht来自之前所有传播的候选区
r
0
:
t
−
1
r_{0:t-1}
r0:t−1和上一层的候选区特征
h
t
−
1
h_{t-1}
ht−1,新一层的候选区
r
t
r_t
rt仅来自上一层候选区特征
h
t
−
1
h_{t-1}
ht−1。box坐标
b
t
b_t
bt和类别分数都来自对应层的候选区
r
t
r_t
rt和候选区特征
h
t
h_t
ht。其中
b
t
b_t
bt使用空间积分层计算得到,
c
t
c_t
ct使用平均池化和全连接计算得到。中间变量
h
t
,
r
e
g
i
o
n
h_{t,region}
ht,region表示区域logits(可看作候选区中每个像素属于前景的概率)。
本文给出了区域传递层的可视化结果,可以看到,随着区域传递层的不断传播,区域会越来越集中到物体周围。
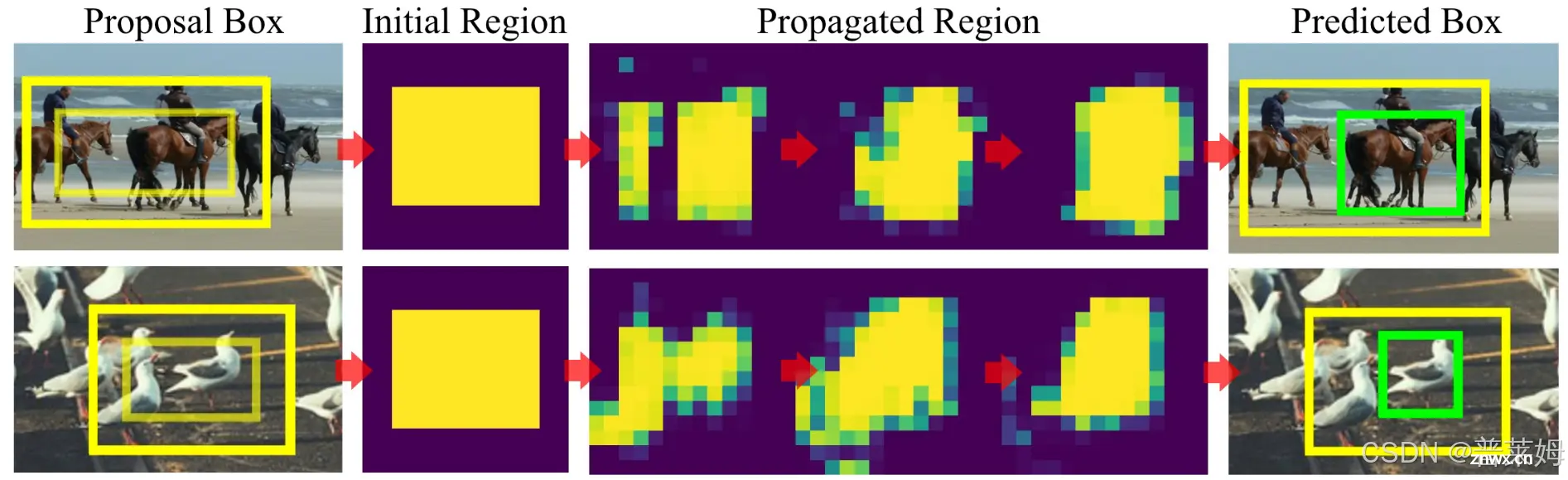
每一层PL输出的物体类别分数
c
t
c_t
ct和
b
t
b_t
bt分别使用常规的FocalLoss和L-1损失进行监督,而对于候选区logits-
r
t
r_t
rt,文章说使用BCE Loss和Dice Loss进行监督,监督目标来自于真值物体区域。
可学习的空间积分
可以看到文章最终要做的还是检测任务,中间输出的区域logits表示区域中每个像素属于前景的概率,它实际上相当于分割任务中得到的mask,这个mask还需要转化为检测框坐标,使用的就是文章提出的可以学习的空间积分层。
通常的mask只有前景和背景两种像素,如果想将其转化成检测框坐标,只需要统计所有前景像素中最左、最上、最右、最下的四个点坐标,分别将其作为box的
x
1
x_1
x1、
y
1
y_1
y1、
x
2
x_2
x2、
y
2
y_2
y2就行了。但这样的做法有两个问题,首先网络预测出来的logits是[0, 1]之间的连续值,无法明确地判断前景和背景,也就无法界定边界框坐标;其次以上转换方式无法微分,不能进行反向传播。针对这两个问题,本文使用可学习和可微的函数来从前景mask导出bounding box坐标。
假设
b
out
=
(
c
w
out
,
c
h
out
,
w
out
,
h
out
)
b^\text{out}=(c_w^\text{out}, c_h^\text{out}, w^\text{out}, h^\text{out})
bout=(cwout,chout,wout,hout)表示要输出的检测框坐标,其中
c
w
out
∈
[
0
,
W
]
c_w^\text{out}\in[0,W]
cwout∈[0,W],
w
out
∈
[
0
,
W
]
w^\text{out}\in[0,W]
wout∈[0,W],
c
h
out
∈
[
0
,
H
]
c_h^\text{out}\in[0,H]
chout∈[0,H],
h
out
∈
[
0
,
H
]
h^\text{out}\in[0,H]
hout∈[0,H]表示检测框的中心点的xy坐标、检测框的宽度和高度,另外
H
H
H和
W
W
W分别表示图片的高和宽。本文并不直接预测绝对值形式检测框坐标,而是先预测检测框的相对坐标,即
b
rel
=
(
c
w
rel
,
c
h
rel
,
w
rel
,
h
rel
)
∈
[
0
,
1
]
4
b^\text{rel}=(c_w^\text{rel},c_h^\text{rel},w^\text{rel},h^\text{rel})\in[0,1]^4
brel=(cwrel,chrel,wrel,hrel)∈[0,1]4,再通过下面表达式转化成绝对值形式的检测框坐标。
(
w
out
,
h
out
)
=
(
w
exp
w
rel
,
h
exp
h
rel
)
(
c
w
out
,
c
h
out
)
=
(
c
w
exp
−
0.5
w
exp
,
c
h
exp
−
0.5
h
exp
)
+
(
c
w
rel
w
exp
,
c
h
rel
h
exp
)
\begin{align} (w^\text{out},h^\text{out})&=(w^\text{exp}w^\text{rel},h^\text{exp}h^\text{rel})\\ (c_w^\text{out},c_h^\text{out})&=(c_w^\text{exp}-0.5w^\text{exp},c_h^\text{exp}-0.5h^\text{exp})+(c_w^\text{rel}w^\text{exp},c_h^\text{rel}h^\text{exp}) \end{align}
(wout,hout)(cwout,chout)=(wexpwrel,hexphrel)=(cwexp−0.5wexp,chexp−0.5hexp)+(cwrelwexp,chrelhexp)
其中
b
exp
b^\text{exp}
bexp是指RPN提取并扩充比例后的初始候选区的坐标。由于
c
w
rel
,
c
h
rel
,
w
exp
,
h
exp
c_w^\text{rel},c_h^\text{rel},w^\text{exp},h^\text{exp}
cwrel,chrel,wexp,hexp表示的是相对值,将他们和初始候选区的宽
w
exp
w^\text{exp}
wexp和高
h
exp
h^\text{exp}
hexp相乘就得到了绝对值,其中宽度和高度为
(
w
exp
w
rel
,
h
exp
h
rel
)
(w^\text{exp}w^\text{rel},h^\text{exp}h^\text{rel})
(wexpwrel,hexphrel),中心点坐标为
(
c
w
rel
w
exp
,
c
h
rel
h
exp
)
(c_w^\text{rel}w^\text{exp},c_h^\text{rel}h^\text{exp})
(cwrelwexp,chrelhexp),注意这里的中心点坐标是在初始候选区中的坐标,要将其再转换到整张图片上的坐标,需要增加一个偏移量
(
c
w
exp
−
0.5
w
exp
,
c
h
exp
−
0.5
h
exp
)
(c_w^\text{exp}-0.5w^\text{exp},c_h^\text{exp}-0.5h^\text{exp})
(cwexp−0.5wexp,chexp−0.5hexp)。
那么如何根据预测出来的区域logits,即mask,来计算检测框的相对坐标呢?以下面图片为例,给定物体和每个像素对应的logits,检测框的中心点可以看作物体的重心坐标,检测框的宽高就是物体外接矩形的宽高。
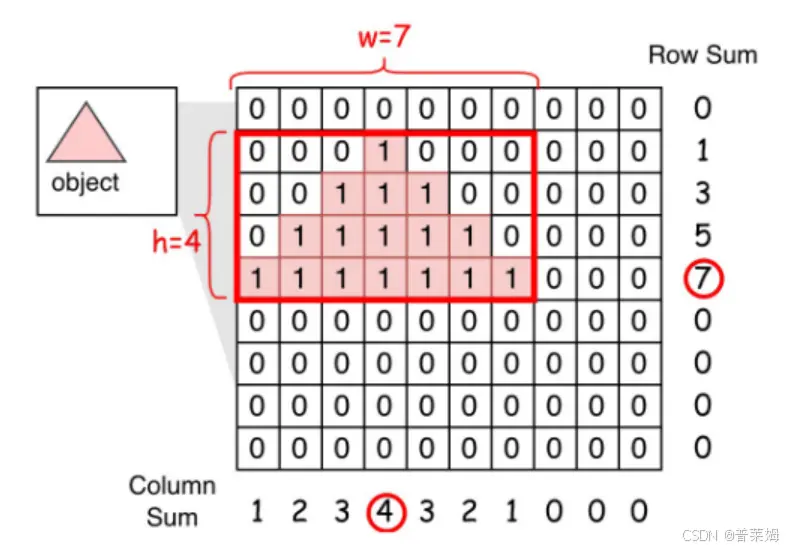
重心坐标可以用二维积分来计算,在离散情况下等于:
(
c
w
rel
,
c
h
rel
)
=
∑
i
,
j
=
1
K
,
K
(
i
K
,
j
K
)
∗
s
o
f
t
m
a
x
(
h
r
e
g
i
o
n
)
i
j
(c_w^\text{rel},c_h^\text{rel})=\sum_{i,j=1}^{K,K}\left(\frac iK,\frac jK\right)*\mathrm{softmax}(h_{region})_{ij}
(cwrel,chrel)=i,j=1∑K,K(Ki,Kj)∗softmax(hregion)ij
而检测框的宽和高是无法严格地根据前景概率按照数学表达式推导出来的。但显然检测框的宽和高与每行/列前景像素个数有关,因此本文在计算宽高的时候,会对每一行/列像素进行排序,并对排序后的结果进行加权平均,作为估计的检测框的宽和高。
w
rel
=
∑
i
=
1
K
∑
j
=
1
K
σ
(
h
r
e
g
i
o
n
)
(
i
)
j
K
θ
i
w
h
rel
=
∑
j
=
1
K
∑
i
=
1
K
σ
(
h
r
e
g
i
o
n
)
i
(
j
)
K
θ
j
h
w^\text{rel}=\sum_{i=1}^K\sum_{j=1}^K\frac{\sigma(h_{region})_{(i)j}}{K}\theta_i^\textbf{w}\\ h^\text{rel}=\sum_{j=1}^K\sum_{i=1}^K\frac{\sigma(h_{region})_{i(j)}}{K}\theta_j^\textbf{h}
wrel=i=1∑Kj=1∑KKσ(hregion)(i)jθiwhrel=j=1∑Ki=1∑KKσ(hregion)i(j)θjh
以行为例,我们来解释一下这个公式是如何得到的,离散情况下背景像素为0,前景像素为1,每行像素个数就等于该行元素之和,因此连续情况下也可以用
∑
i
=
1
K
σ
(
h
r
e
g
i
o
n
)
i
(
j
)
\sum_{i=1}^K\sigma(h_{region})_i(j)
∑i=1Kσ(hregion)i(j)来作为单行像素个数,其中
σ
(
h
r
e
g
i
o
n
)
\sigma(h_{region})
σ(hregion)是前景概率。
θ
j
h
\theta_j^\textbf{h}
θjh表示每行对应的权重,按照该权重对每行像素个数进行加权求平均,表示为
∑
j
=
1
K
1
K
每行像素个数
\sum_{j=1}^K\frac1K{每行像素个数}
∑j=1KK1每行像素个数,就得到了上面公式。
这里对重心的计算是严格从数学公式推导出来的,而宽高是用网络参数进行拟合得到的,因此是估计值。
特征子空间投影
FSOD的一个主要挑战是网络容易过拟合到base类别上,导致在novel类别上性能较低。考虑到低秩表示可以缓解过拟合,文章采用预训练的ViT特征来降低base和novel类别之间的差异。
给定一批支撑集图片,先提取他们的预训练ViT特征,然后用检测框坐标来裁剪对应的特征。对相同类别的特征求平均,作为对应类别的原型特征,表示为
p
C
∈
R
∣
C
∣
×
D
p_{\mathcal C}\in\mathbb R^{|{\mathcal C}|\times D}
pC∈R∣C∣×D,其中
C
\mathcal C
C表示类别集合,
D
D
D表示通道数。同时ViT提取的query图片特征表示为
h
v
i
t
∈
R
D
×
H
×
W
h_{vit}\in\mathbb R^{D\times H\times W}
hvit∈RD×H×W。二者乘积
p
C
⋅
h
v
i
t
∈
R
∣
C
∣
×
H
×
W
p_{\mathcal C}\cdot h_{vit}\in\mathbb R^{|\mathcal C|\times H\times W}
pC⋅hvit∈R∣C∣×H×W可以理解为query特征
h
v
i
t
h_{vit}
hvit在以
p
C
p_{\mathcal C}
pC为基的子空间上的投影。然而这个子空间面临两个挑战:
仅使用原型类别集合
C
\mathcal C
C不能够充分地捕获特征信息。转置集合
C
\mathcal C
C能够创造一个不同但等价的子空间,然而相应地设计一个转置不变的网络是很有挑战的。
针对这两个问题,本文给出了相应的解决方案:
针对
C
\mathcal C
C表达不充分的问题,提出了背景类别集合
B
\mathcal B
B,
B
∩
C
=
∅
\mathcal B\cap\mathcal C=\emptyset
B∩C=∅,相应地构建背景类别原型
p
B
∈
R
∣
B
∣
×
D
p_{\mathcal B}\in\mathbb R^{|\mathcal B|\times D}
pB∈R∣B∣×D来保留更多
h
v
i
t
h_{vit}
hvit的信息。
针对第二个问题,本文提出为每个类别
c
∈
C
c\in\mathcal C
c∈C构建单独的子空间,然后重排其他类别
C
\
c
\mathcal C\backslash c
C\c来解决转置歧义。
h
s
u
b
s
p
a
c
e
,
c
=
c
o
n
c
a
t
(
p
c
⋅
h
v
i
t
,
channel-reorder
(
p
C
\
c
⋅
h
v
i
t
)
,
p
B
⋅
h
v
i
t
)
h_{subspace,c}=\mathrm{concat}(p_c\cdot h_{vit},\text{channel-reorder}(p_{\mathcal C\backslash c}\cdot h_{vit}),p_{\mathcal B}\cdot h_{vit})
hsubspace,c=concat(pc⋅hvit,channel-reorder(pC\c⋅hvit),pB⋅hvit)
在公式中,
channel-reorder
\text{channel-reorder}
channel-reorder指讲通道按照数值大小排序,然后将
∣
C
∣
−
1
|C|-1
∣C∣−1个通道插值到预定义的通道数。背景类别集合
B
\mathcal B
B来自非物体类别,例如天空、路面、地面等。为了提升效率,本文并不是对每个类别都单独进行推理,而是先使用一个轻量化的原型分类器,找到最相近的
T
T
T个类别,只在这
T
T
T个类别上执行推理。
实验结果
本文在PascalVOC和COCO上测试了小样本和单样本这两种任务,可以看到在PascalVOC上的大部分shot情况下能够超越已有方法,相比NIFF提升比较明显。
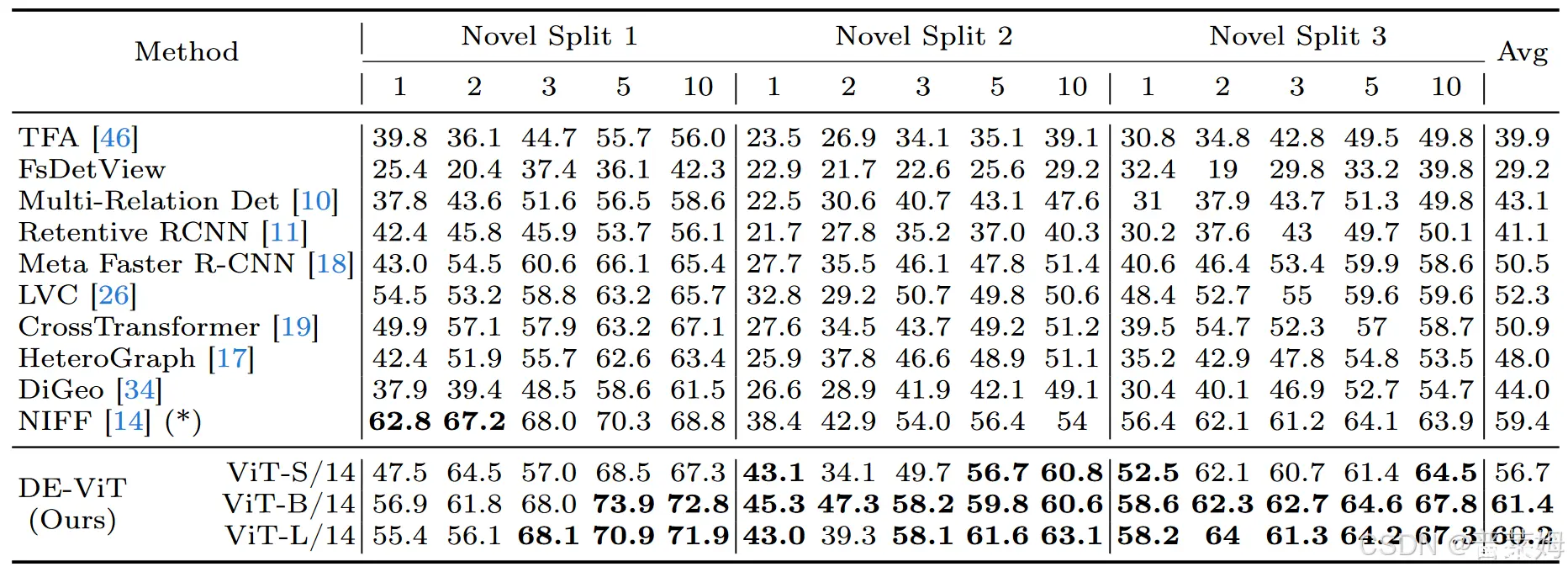
在COCO单样本任务上性能表现也非常有优势:
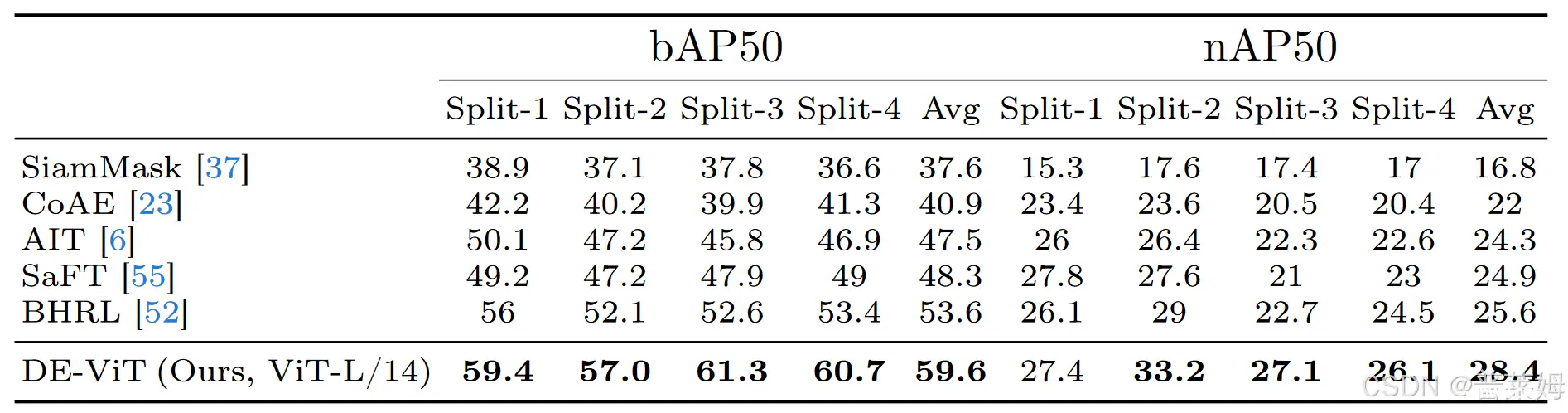
值得一提的是,对比方法中的NIFF以及其他很多FSOD研究都没有公开代码,这也某种程度上导致了小样本检测的发展远远落后于小样本分类,以至于很多FSOD论文的Intro总要吐槽一句FSOD的研究很少。而FSOD本身的流程比小样本分类和常规检测任务又复杂得多,不开源代码的工作基本就无法复现。希望后续的FSOD工作都有更多的热情release代码吧,这样不仅是提升可复现性,也能够方便后人开展进一步研究!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。