【AI知识点】置信区间(Confidence Interval)
AI完全体 2024-10-12 10:31:02 阅读 76
AI知识点总结:【AI知识点】
AI论文精读、项目、思考:【AI修炼之路】
置信区间(Confidence Interval, CI) 是统计学中用于估计总体参数的范围。它给出了一个区间,并且这个区间包含总体参数的概率等于某个指定的置信水平(通常是 90%、95% 或 99%)。与点估计不同,置信区间通过区间估计给出了参数的可能范围,从而提供了更可靠的信息。
1. 定义
置信区间是用于估计总体参数(如均值、比例等)的一个区间。与点估计(即单个估计值)不同,置信区间提供了一系列可能包含总体参数的值,并伴随着一定的置信水平。
置信区间可以看作是一个范围,表示我们对这个范围包含真实参数值的信心程度。例如,给定 95% 的置信水平,置信区间表示我们有 95% 的信心认为该区间包含总体参数。
2. 置信水平
置信水平(Confidence Level) 表示区间包含总体参数的概率。通常使用的置信水平有 90%、95%、99% 等。置信水平越高,置信区间越宽,表示我们更有把握认为总体参数落在该区间内。
3. 置信区间的计算
对于总体均值
μ
\mu
μ,当样本量较大且样本均值服从正态分布时,置信区间可以通过以下公式计算:
置信区间
=
(
X
‾
−
z
α
/
2
⋅
σ
n
,
X
‾
+
z
α
/
2
⋅
σ
n
)
\text{置信区间} = \left( \overline{X} - z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}}, \overline{X} + z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} \right)
置信区间=(X−zα/2⋅n
σ,X+zα/2⋅n
σ)
其中:
X
‾
\overline{X}
X 是样本均值。
σ
\sigma
σ 是总体的标准差,若不知道
σ
\sigma
σ,可以用样本标准差
s
s
s 代替。
n
n
n 是样本量。
z
α
/
2
z_{\alpha/2}
zα/2 是对应置信水平的标准正态分布的临界值。例如,对于 95% 置信水平,
z
α
/
2
=
1.96
z_{\alpha/2} = 1.96
zα/2=1.96。
临界值:在标准正态分布中,临界值是位于分布尾部的那个点,使得在该点外的面积(即尾部面积)等于
(
1
−
置信水平
)
/
2
(1 - \text{置信水平}) / 2
(1−置信水平)/2。例如,在 95% 的置信水平下,左右两侧各留出 2.5% 的尾部面积,因此 95% 的置信区间在
z
z
z 轴上对应的临界值是 1.96。1.96 是标准正态分布
x
x
x 轴上的一个点,它表示距离均值 1.96 个标准差的位置。
图示如下:
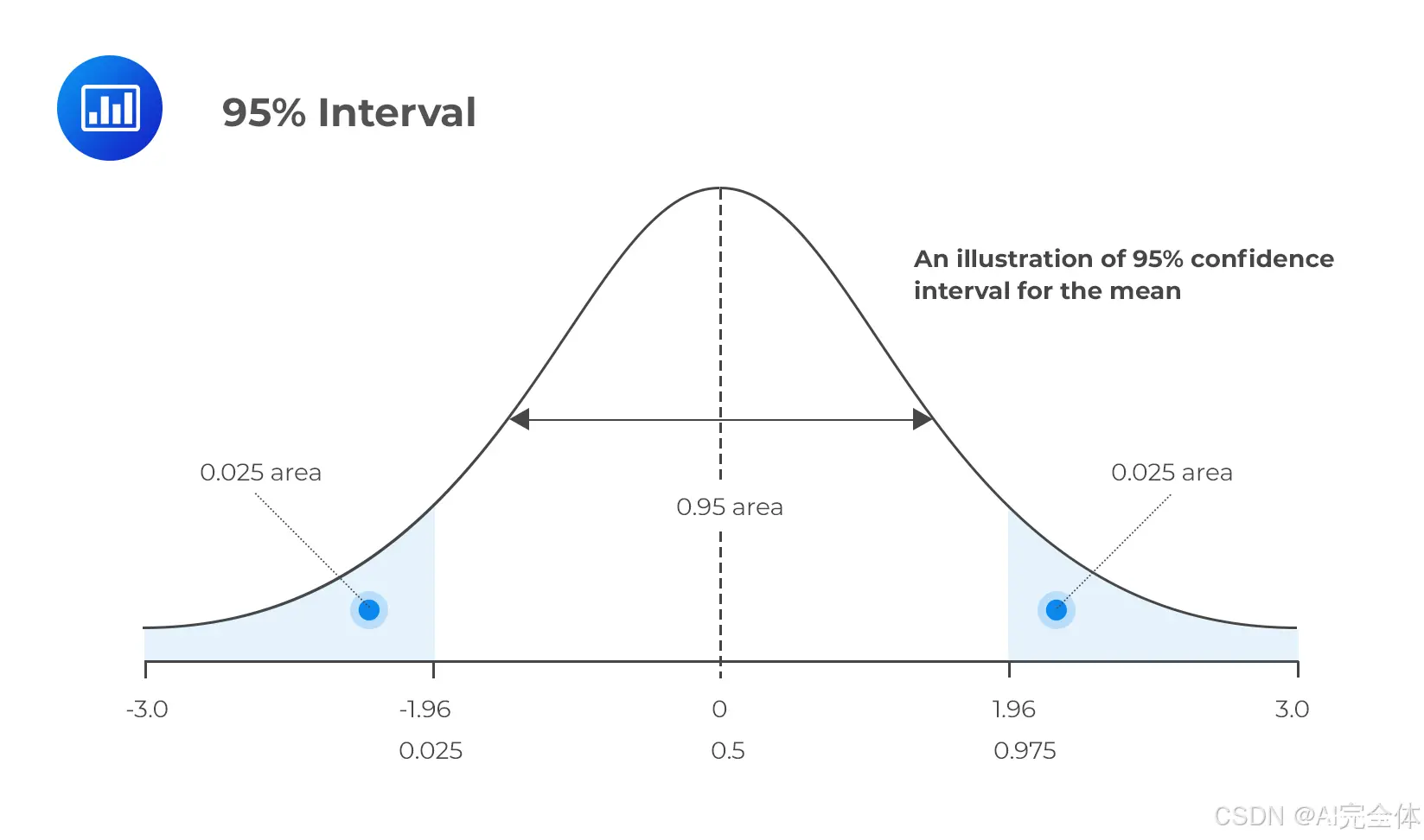
图片来源:https://analystprep.com/cfa-level-1-exam/quantitative-methods/confidence-intervals-2/
4. 置信区间的例子
假设我们从某个城市中抽取了 100 人的样本,测量他们的年收入,计算出样本均值为
X
‾
=
50
,
000
\overline{X} = 50,000
X=50,000 美元,样本标准差为
s
=
10
,
000
s = 10,000
s=10,000 美元。我们希望以 95% 的置信水平来估计该城市居民的平均年收入。
根据 95% 置信水平,对应的
z
α
/
2
=
1.96
z_{\alpha/2} = 1.96
zα/2=1.96,样本量
n
=
100
n = 100
n=100,置信区间为:
置信区间
=
(
50
,
000
−
1.96
⋅
10
,
000
100
,
50
,
000
+
1.96
⋅
10
,
000
100
)
\text{置信区间} = \left( 50,000 - 1.96 \cdot \frac{10,000}{\sqrt{100}}, 50,000 + 1.96 \cdot \frac{10,000}{\sqrt{100}} \right)
置信区间=(50,000−1.96⋅100
10,000,50,000+1.96⋅100
10,000)
=
(
50
,
000
−
1
,
960
,
50
,
000
+
1
,
960
)
= (50,000 - 1,960, 50,000 + 1,960)
=(50,000−1,960,50,000+1,960)
=
(
48
,
040
,
51
,
960
)
= (48,040, 51,960)
=(48,040,51,960)
因此,我们可以说我们有 95% 的信心认为该城市的平均年收入在
48
,
040
48,040
48,040 美元到
51
,
960
51,960
51,960 美元之间。
5. 不同类型的置信区间
a. 总体均值的置信区间
适用于推断总体均值时的置信区间,通常使用
z
z
z 检验(样本量较大)或
t
t
t 检验(样本量较小,且总体方差未知)。
b. 总体比例的置信区间
当研究总体的某种比例(如支持率)时,可以用置信区间来推断总体比例的范围。
c. 差异的置信区间
用于比较两个总体均值或比例的差异时,可以计算差异的置信区间来确定总体间差异的可能范围。
6. 置信区间的应用
a. 医学研究
在临床试验中,置信区间常用于估计治疗效果的大小。例如,研究某种药物的疗效是否显著,置信区间可以帮助研究者判断药物的有效性。
b. 市场调研
在市场调研中,置信区间可以用于估计市场份额、顾客满意度等参数的范围。例如,估计某品牌在市场中的份额,置信区间可以帮助估计该份额的上限和下限。
c. 质量控制
在制造业中,置信区间常用于监控产品质量,估计产品在某个规格范围内的比例。
7. 置信区间与假设检验的关系
置信区间和假设检验都是用于统计推断的工具,但它们在使用方式和目标上有所不同:
置信区间:用于估计总体参数的范围。它告诉我们总体参数落在某个区间内的可能性。假设检验:用于判断某一特定假设是否成立。它告诉我们是否可以拒绝某个假设。
假设检验的结果与置信区间的一致性:
如果我们通过假设检验拒绝了某个值作为总体参数,那么这个值通常不会出现在相应的置信区间内。反之,如果某个值落在置信区间之外,那么我们会拒绝这个值作为总体参数,在对应的假设检验中也会拒绝零假设。
8. 总结
置信区间是统计推断中的重要工具,它提供了总体参数的一个估计范围,并通过置信水平反映了对该估计范围的信心程度。置信区间结合了样本数据和统计理论,帮助我们在不确定性中做出更有依据的推断和决策。
上一篇: 腾讯云2024年数字生态大会开发者嘉年华(数据库动手实验)探索AI驱动TDSQL-C数据库
下一篇: LLMs之PE:AI for Grant Writing的简介、使用方法、案例应用之详细攻略
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。