论文分享|ACL2024主会|RAG相关论文简读
BrownSearch 2024-08-18 10:31:02 阅读 92
本文通过简读ACL2024主会中RAG和检索相关且在谷歌学术已公开的26篇论文,追踪RAG的研究热点
这些论文可以分为以下几类,每类中个人认为较值得一读的论文加粗标注出来:
面向RAG提出专门的LLM训练方法(1,4,14,16)面向特定任务或需求的RAG流程优化(2,12,13,15,17,19,20,23,25)chunking-free 的上下文检索(3,7)优化检索器(5,8,9,21,22,26)实证研究/Benchmark(6,10,11,18,24)
这里附上ACL2024论文列表链接:https://2024.aclweb.org/program/main_conference_papers/
1.Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation(中科院)
论文链接:https://arxiv.org/abs/2402.18150
开源地址:https://github.com/xsc1234/INFO-RAG
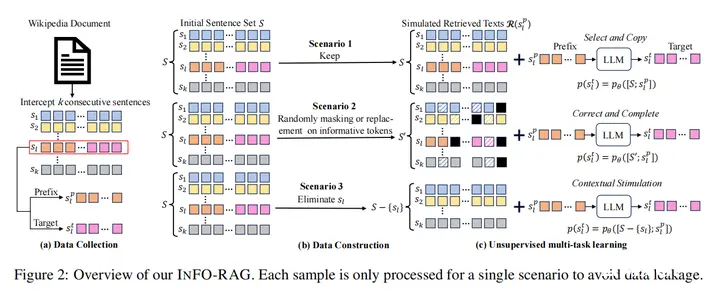
主要思想:本文提出将LLM作为文档信息优化器,从而能够利用完整的文档/不完整或不正确的文档/不包含正确答案的文档都能够输出正确答案。本文提出了一种无监督学习方法,让LLM利用经过一定变换的句子集合作为上下文,利用其中的一个句子的前缀来预测后缀。本文在常见问答/语言模型困惑度/代码生成任务上都取得了相较使用rag的llama2更好的效果。
2.An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation(哈工大)
论文链接:https://arxiv.org/abs/2406.01549
开源地址:https://github.com/zhukun1020/NoiseFilter_IB
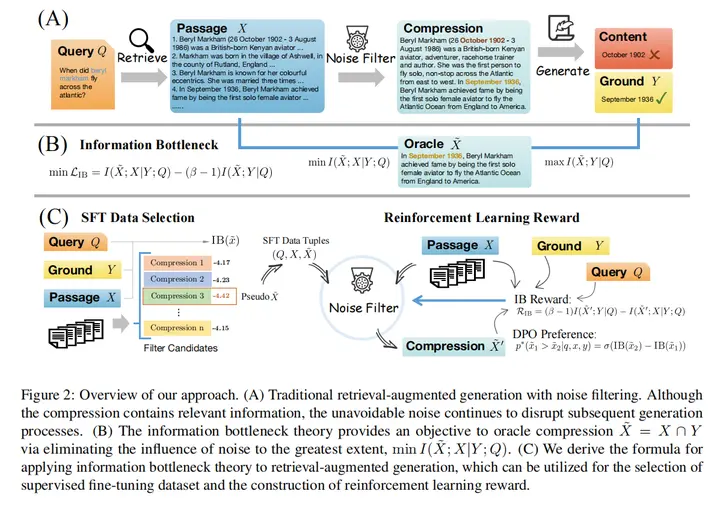
主要思想:使用信息瓶颈理论来优化上下文压缩器,最大化压缩后上下文与答案的互信息,最小化压缩后上下文与原上下文的互信息。为SFT数据选择和强化学习奖励信号都提供了一种较好的方法。
3.Grounding Language Model with Chunking-Free In-Context Retrieval(人大)
论文链接:https://arxiv.org/abs/2402.09760
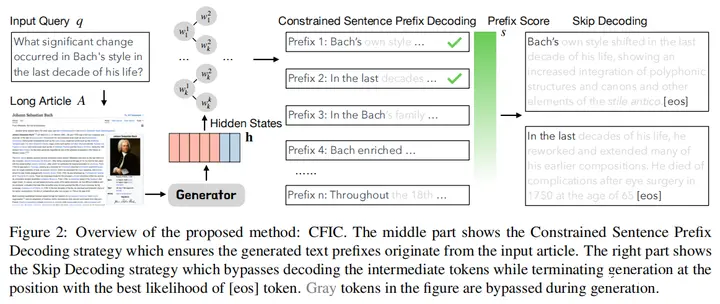
主要思想:为了解决长文本的分块不精确问题,提出不需要分块的上下文检索。将用户查询和长文档直接输入LLM,得到隐状态,再根据这些隐状态预测之后的token,利用预测token的概率,定位长文档中困惑度最低的topk个不一样的prefix,之后在解码时跳过prefix对应的句子内容,直到找到eos。
4.M-RAG: Reinforcing Large Language Model Performance through Retrieval-Augmented Generation with Multiple Partitions(华为)
论文链接:https://arxiv.org/abs/2405.16420
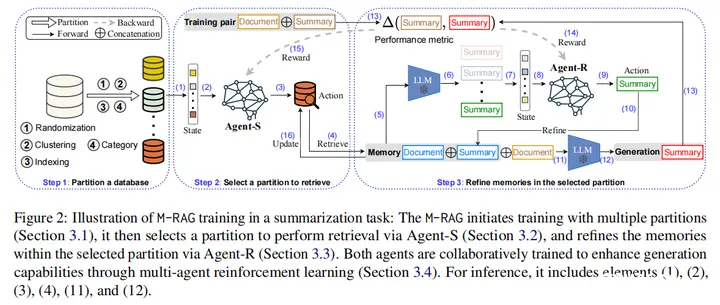
主要思想:数据库过大时会导致模型无法利用最关键的信息,本文提出RAG的多片范式。以文本摘要任务举例:1.先将一个用文档库构建而来的向量数据库分片;2.利用一个LLM作为Agent-S选择一个合适的分片进行文档检索得到memory;3.对于memory中每个文档利用Agent-R得到摘要,即组成Demonstrations,最后将这些示例和用户文档输入LLM得到最终的摘要。训练过程中使用多智能体协同强化学习对两个智能体进行训练优化。
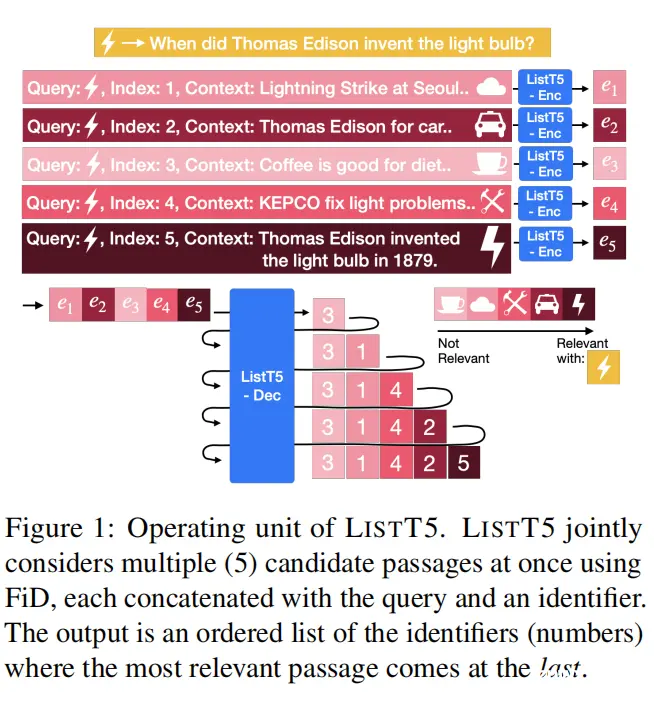
5.ListT5: Listwise Reranking with Fusion-in-Decoder Improves Zero-shot Retrieval(首尔国立大学)
论文链接:https://arxiv.org/abs/2402.15838
开源地址:https://github.com/soyoung97/ListT5
主要思想:使用T5模型的Fusion-In-Decoder(FiD)技术对文档精排,将粗排的若干文档和标识符一起输入,解码出标识符列表,作为精排的文档顺序。本文还提出一种高效的多级排序策略,分多层对越来越少的文档利用ListT5进行排序
6.On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models(华东师大)
论文链接:https://arxiv.org/abs/2406.16367
主要思想:由于LLM预训练阶段已经记住了常见的世界知识,长尾知识对于RAG格外重要。本文提出了一种 Generative Expected Calibration Error (GECE)指标对长尾知识进行评估,并只有出现长尾知识时才将文档输给LLM。这种方式提升了4倍的推理速度同时达到了和正常RAG流程相当的下游任务效果。
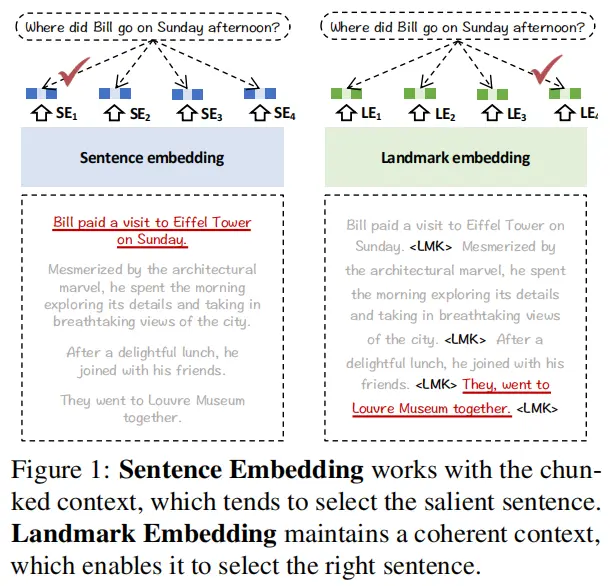
7.Landmark Embedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models(智源)
论文链接:http://arxiv.org/abs/2402.11573
开源地址:https://github.com/FlagOpen/FlagEmbedding
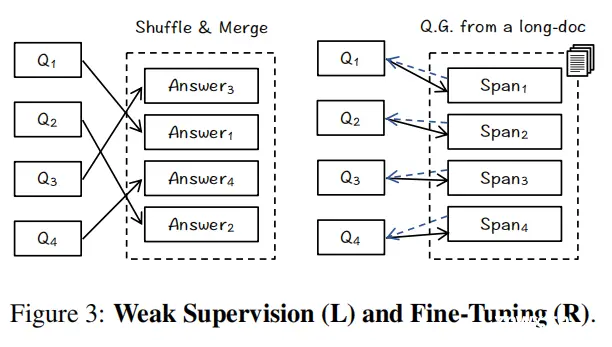
主要思想:分块方法一般是次优的,本文提出Landmark Embedding,实现不需要分块的表征编码。具体方法为:1.无需分块的架构设计:使用LLM作为编码器+滑动窗口机制,保持长上下文都能够输入,从而得到每句话在上下文中的语义表征(token得到这个span的编码)。2.位置感知的优化目标:使用e指数对位置进行建模,越往后的句子和查询对齐的对比学习损失梯度越大。3.多阶段训练(Figure3):(1)Distant supervision,直接使用MS MARCO的pair data进行训练,直接将文档和拼接;(2)Weak Supervision,从不同的查询中随机抽取文档答案,并将它们合并为一个伪长文进行训练。(3)Fine-Tuning,利用LLM对真实的长文档合成数据,每个span对应一个相应的问题。
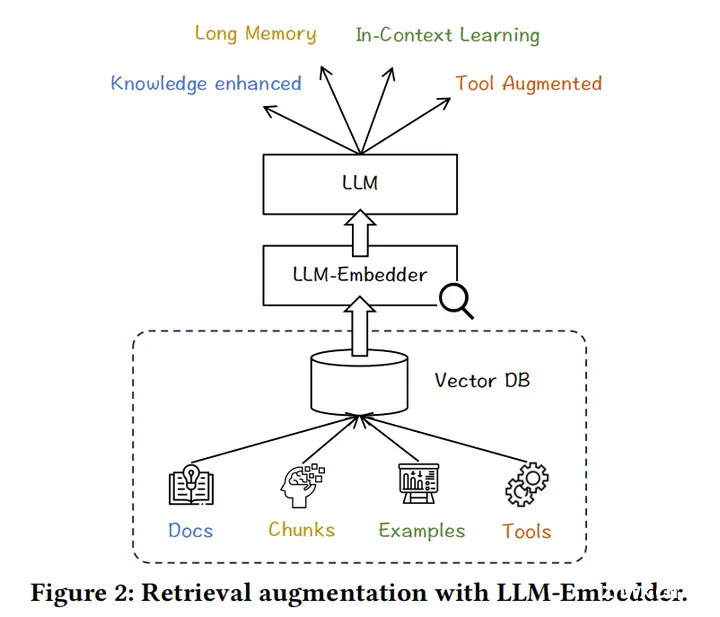
8.A Multi-Task Embedder For Retrieval Augmented LLM(智源,未找到同名公开论文,推测是以下这篇)
论文链接:https://arxiv.org/abs/2310.07554
开源地址:https://github.com/FlagOpen/FlagEmbedding
主要思想:基于bge,面向LLM的偏好,面向基于文档的知识增强,长上下文的文本块检索,上下文学习中的示例,工具选择等多个任务都进行了指令表征微调。由于任务种类多,本文还专门设计了一种同质难负采样策略,让每个batch内的数据都是同种任务的数据。
9.DAPR: A Benchmark on Document-Aware Passage Retrieval(UKP Lab)
论文链接:https://arxiv.org/abs/2305.13915
开源地址:https://github.com/UKPLab/acl2024-dapr
主要思想:区别于传统的短文本检索任务,用户经常要从大的语料库中检索长文档,比如维基百科、研究论文等,本文将这种任务命名为文档感知的段落检索,本文提出了两种思路来改进常见段落检索器在这个新任务上的效果:1.结合BM25的混合检索。2.上下文段落表征。这两种方法虽然取得了一定的提升,但是总的来说效果还是比较差。

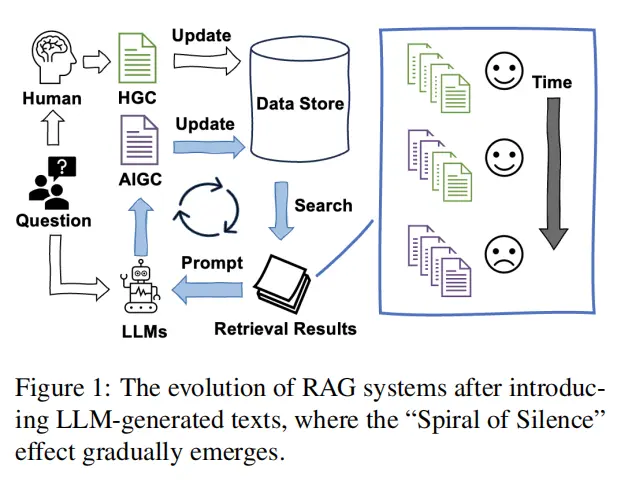
10.Spiral of Silence: How is Large Language Model Killing Information Retrieval?—A Case Study on Open Domain Question Answering(中科院)
论文链接:https://arxiv.org/abs/2404.10496
开源地址:https://github.com/VerdureChen/SOS-Retrieval-Loop
主要思想:本文发现如果将AI生成的内容加入数据库,RAG系统将存在沉默的螺旋现象,即AIGC的检索排序将高于HGC。本文以开放领域问答任务为例,证明了AI生成的不准确内容可能会逐步让准确的真实信息在网络上边缘化。
11.Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval(CMU)
论文链接:https://arxiv.org/abs/2404.04163
主要思想:探讨了基于transformer的文本表示学习模型中位置偏差的存在。本文先基于之前的研究,证明了因果语言模型的输入序列中间信息的丢失,并将其扩展到表示学习领域,研究了编码器-解码器模型的不同训练阶段的位置偏差,包括语言模型预训练、对比预训练和对比微调。对MS-MARCO文档集合的实验表明,经过对比预训练后,模型已经生成了能够更好地捕获输入的靠前内容的表征,而微调进一步加剧了这种影响。
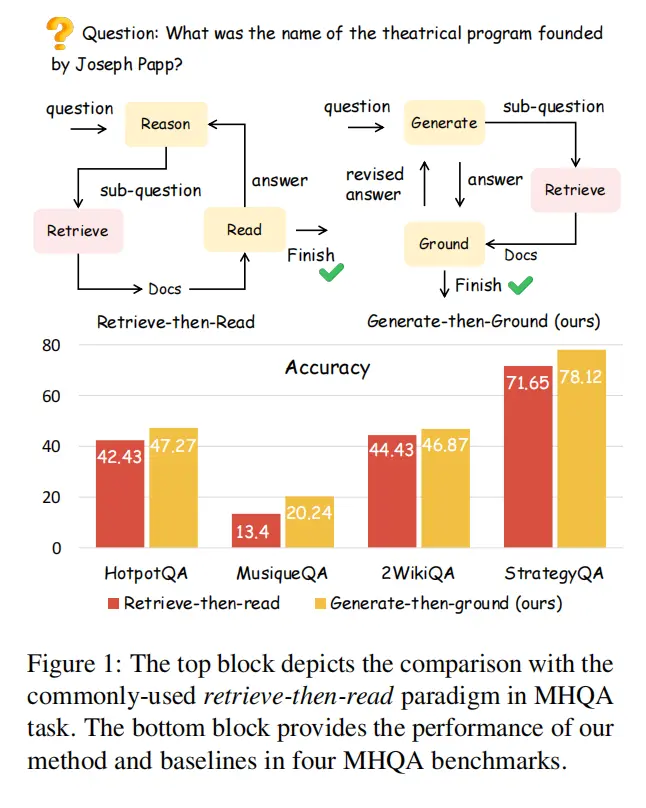
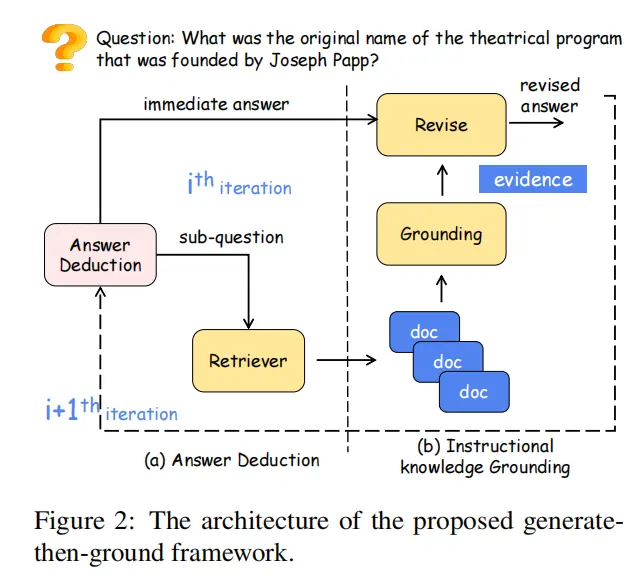
12.Generate-then-Ground in Retrieval-Augmented Generation for Multi-hop Question Answering(山东大学)
论文链接:https://arxiv.org/abs/2406.14891
主要思想:多跳问答中,由于检索得到文档的噪声,简单的Retrieve-then-Read流程效果一般,本文提出了一种新的Generate-then-Ground流程。GenGround使LLM交替使用两个步骤,直到得到最终答案: (1)生成一个更简单的单跳问题并直接生成答案;(2)在检索到的文档中追溯问答对,修改答案中的错误。新的流程在四个任务上都超过了Retrieve-then-Read流程。
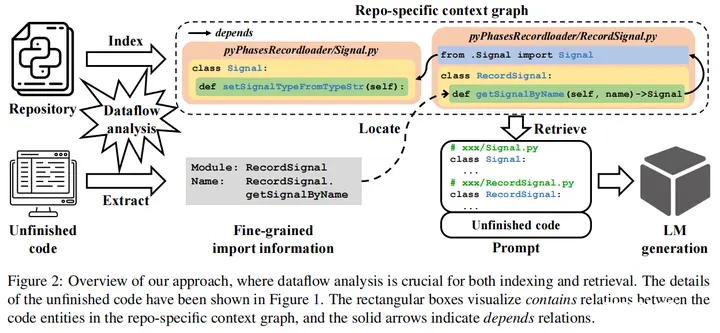
13.Dataflow-Guided Retrieval Augmentation for Repository-Level Code Completion(南京大学)
论文链接:Dataflow-Guided Retrieval Augmentation for Repository-Level Code Completion
开源地址:https://github.com/nju-websoft/DraCo
主要思想:对于预训练LM来说,在私人仓库中完成正确的代码补全是一项挑战。以往的研究基于导入关系或文本相似性检索跨文件上下文,这与代码补全的相关性并不高。在本文中,我们提出了一种数据流引导的检索增强方法DRACO,用于仓库级的代码补全。DRACO将私有仓库解析为代码实体,并通过扩展的数据流分析建立它们的关系,形成一个特定于仓库的上下文图。每当触发代码补全时,DRACO就会精确地从仓库特定的上下文图中检索相关的背景知识,并生成形式良好的提示词来询问代码LM。此外,本文还构建了一个大型Python数据集ReccEval,具有更多样化的代码补全目标。DRACO在代码Exact Match和标识符F1分数两个指标上都相较sota方法都提升了至少3%。
14.Understanding Retrieval Robustness for Retrieval-augmented Image Captioning(哥本哈根大学)
论文链接:Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
开源地址:https://github.com/lyan62/RobustCap
主要思想:检索增强的图像标题生成任务中,模型很容易被检索到的标题中出现较多的token误导,并将这些错误的token简单复制到输出中,根据这个发现,本文提出从更多样化的标题集合中采样,从而防止模型简单复制出现多的token。

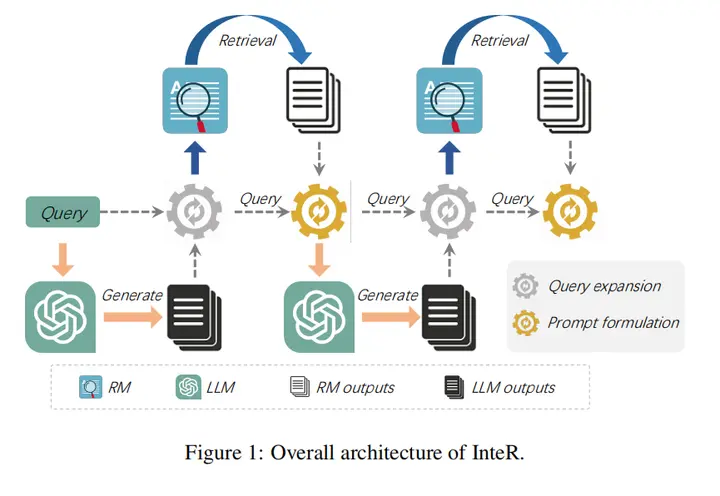
15.Synergistic Interplay between Search and Large Language Models for Information Retrieval(北大)
论文链接:https://arxiv.org/abs/2305.07402
开源地址:https://github.com/Cyril-JZ/InteR
主要思想:本文通过检索模型(Retrieval Model RM)和LLM之间的协同作用来促进信息优化,从而提升检索性能。InteR允许RM使用LLM生成的知识集合来扩展查询,并使LLM能够使用检索到的文档来增强提示。这种迭代的细化过程增强了RM和LLM的输入,从而带来更准确的检索。在大规模检索基准上的实验表明,InteR实现了最好的效果。
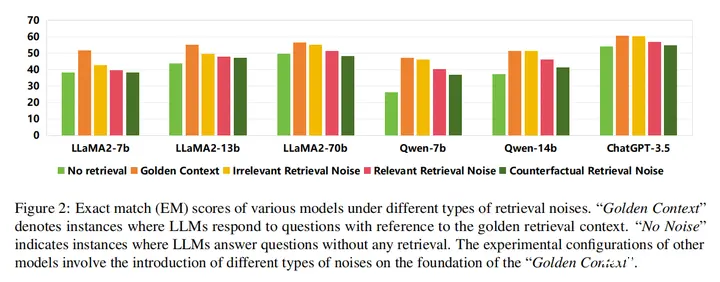
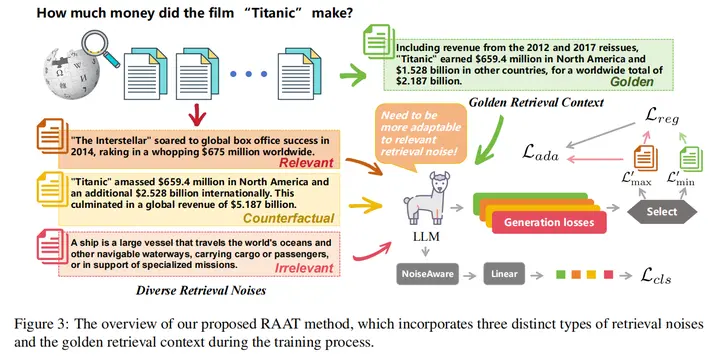
16.Enhancing Noise Robustness of Retrieval-Augmented Language Models with Adaptive Adversarial Training(中科大)
论文链接:https://arxiv.org/abs/2405.20978
开源地址:https://github.com/calubkk/RAAT
主要思想:本文首先研究了检索噪声,并将它们分为三种不同的类型(相关但无用,不相关,反事实),并分析了这些不同的检索噪声对LLM的鲁棒性的影响,发现不相关好于相关但无用好于反事实。随后,本文提出了一种新的RAG方法,称为检索增强自适应对抗训练(RAAT),利用自适应对抗性训练来动态调整模型的训练过程,在各种类型的文档下都利用交叉熵损失进行优化,并加上正则项让这四种损失梯度相差较小,从而能够处理检索噪声。同时,本文设计了一种噪声分类损失,通过多任务学习来确保模型内在的识别噪声上下文的能力。大量的实验表明,使用RAAT训练的LLaMA-2 7B模型在不同的噪声条件下,F1和EM评分有显著的改善。
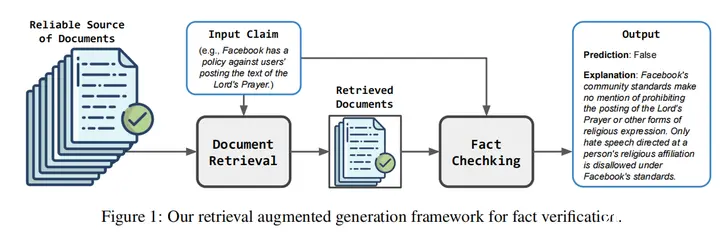
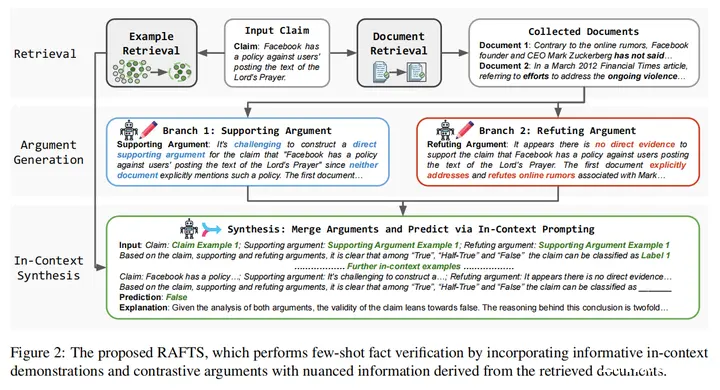
17.Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments(UIUC)
论文链接:https://arxiv.org/abs/2406.09815
主要思想:在本文中,我们提出了通过综合对比论证来检索增强事实核查(RAFTS)。在输入声明后,RAFTS从证据检索开始,本文设计了一个检索流程来从可验证的来源中粗排和重排相关文档。然后,RAFTS以检索到的证据为条件,形成相反的论点(即支持或反驳)。此外,RAFTS利用一个embedding模型来筛选有意义的示例,然后通过上下文学习来生成预测和解释。RAFTS仅使用一个7B LLM就超过了GPT系列模型在事实核查任务的效果。
18.RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models(NewsBreak)
论文链接:https://arxiv.org/pdf/2401.00396
主要思想:本文提出了一个语料库,用于对LLM应用程序的标准RAG框架中,各种领域和任务中的词语级别幻觉的分析。RAGTruth包含了使用RAG的来自不同LLM的近18,000个自然语言回复。这些回复在案例和词语层面上都经历了细致的人工标注,并结合了对幻觉强度的评估。同时,本文发现使用RAGTruth,可以训练一个堪比使用基于提示词的GPT-4的幻觉检测效果的小型LLM。


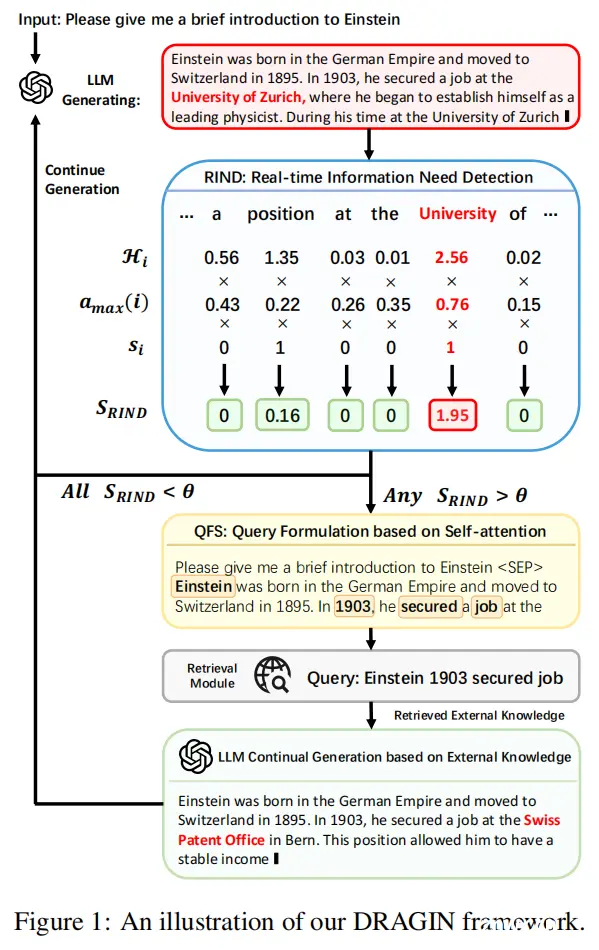
19.DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models(清华)
论文链接:https://arxiv.org/abs/2403.10081
开源地址:https://github.com/oneal2000/DRAGIN
主要思想:为了解决RAG中什么时候检索(when)和检索什么(what)的问题,先提出了一种结合生成token的不确定性分数,token影响力分数,和停用词属性的实时信息需求检测(RIND)方法,根据计算出的分数和阈值判断当前是否需要检索。如果需要检索,则再利用自注意力分数过滤出最重要的token作为改写后的查询词进行检索。DRAGIN在几个问答任务上取得了好于FLARE的性能。
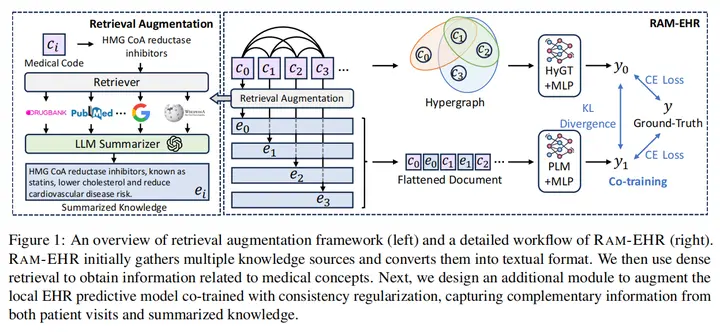
20.RAM-EHR: Retrieval Augmentation Meets Clinical Predictions on Electronic Health Records(埃默里大学)
论文链接:https://arxiv.org/abs/2403.00815
开源地址:https://github.com/ritaranx/RAM-EHR
主要思想:本文旨在解决基于电子健康记录的临床预测。RAM-EHR首先收集多个知识来源,将其转换为文本格式,并使用密集检索来获取与医学概念相关的信息。该策略解决了与概念的复杂名称关联难的问题。然后,RAM-EHR增强了局部EHR预测模型。局部EHR预测模型使用一致性正则化训练,以从患者访问关系和LLM总结的知识中获取互补信息。
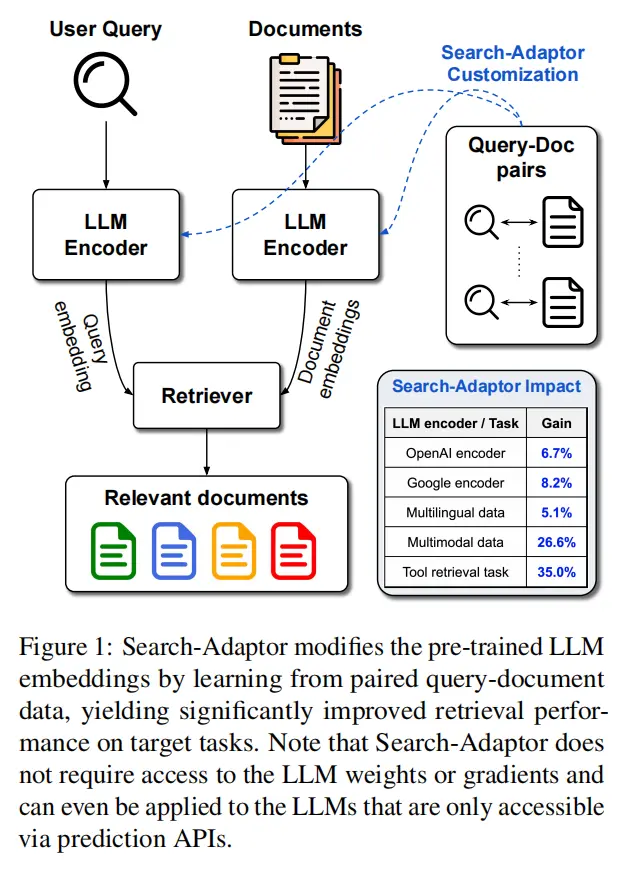
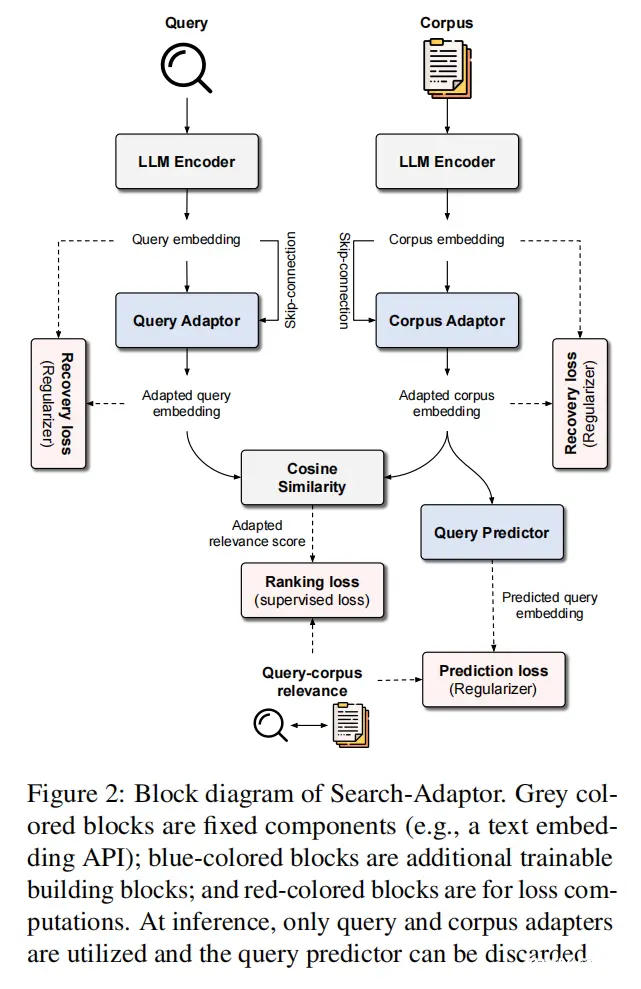
21.Search-Adaptor: Embedding Customization for Information Retrieval(谷歌)
论文链接:https://arxiv.org/abs/2310.08750
主要思想:由预训练LLM提取的表征(LLM Embedding,比如openai embedding服务)在改进信息检索和搜索方面具有重要的潜力。除了传统使用的零样本设置之外,我们还能够利用来自查询-语料库配对数据的信息进一步提高这些黑盒LLM Embedding的能力。在本文中,我们提出了一种新的方法,搜索适配器,以一种有效和鲁棒的方式定制LLM的信息检索。搜索适配器修改由黑盒LLM生成的表征,并可以与任何LLM集成,包括那些仅通过api调用的表征接口。在多个英语、多语言和多模态检索数据集上,我们展示了搜索适配器的一致和显著的性能优势——例如,在14个BEIR数据集中,谷歌表征api nDCG@10数值平均提高了5%以上。
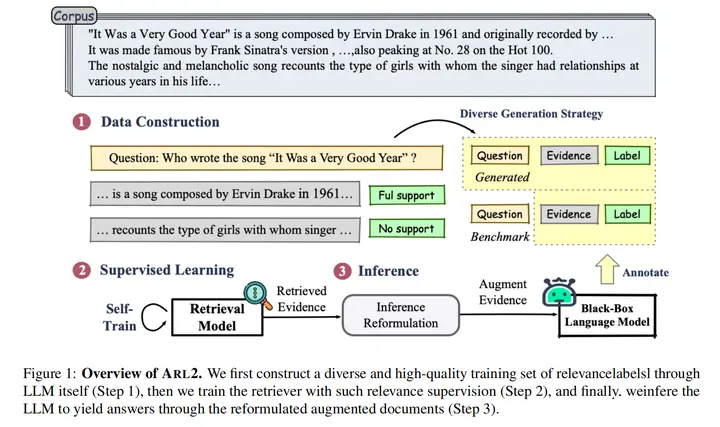
22.ARL2: Aligning Retrievers with Black-box Large Language Models via Self-guided Adaptive Relevance Labeling
论文链接:https://arxiv.org/abs/2402.13542
开源地址:https://github.com/zhanglingxi-cs/ARL2
主要思想:将检索器和LLM对齐,提示LLM获取文档和问题的相关程度,并利用得到的问题-文档相似度数据,利用对比学习和成对的logistic损失对检索器进行训练。最终训练后的效果超越了REPLUG。
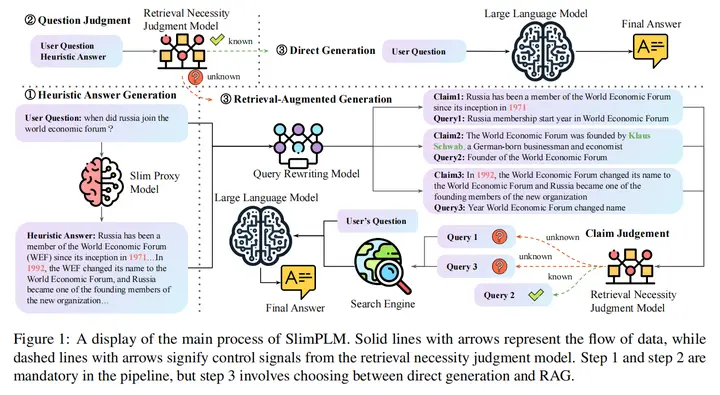
23.Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
论文链接:https://arxiv.org/abs/2402.12052
开源地址:https://github.com/plageon/SlimPLM
主要思想:通过训练一个小型LM作为评估器J,评判对于一个问题,相应的答案是否正确,如果正确则需要检索,不正确则不需要检索。对于用户问题,先生成启发式答案,将问题与启发式答案输入J进行判断,如果不需要检索则直接输入LLM生成;如果需要检索,先使用一个查询重写模型利用启发式答案和问题拆解为几个子问题和对应的断言,将这些断言和子问题交给J判断是否正确,如果正确则子查询不需要检索,不正确则需要对此子查询检索,最终再将矫正后的子查询和断言输入LLM生成最终答案。
24.Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts When Knowledge Conflicts?
论文链接:https://arxiv.org/abs/2401.11911
开源地址:https://github.com/Tan-Hexiang/RetrieveOrGenerated
主要思想:为了研究LLM如何合并利用检索的知识和AI生成的知识,本文设计了一个框架来确定LLM的响应归因于AI生成的内容还是检索到的上下文。为了方便地跟踪响应的来源,本文构建了具有冲突上下文的数据集,即每个问题都与生成和检索的上下文配对,但其中只有一个包含正确的答案。本文的实验显示,几个LLM(GPT-4/3.5和Llama2)的实验显著偏向于生成的上下文,即使它们提供了不正确的信息。本文进一步确定了导致这种偏差的两个关键因素: i)由LLM生成的上下文通常与问题表现出更大的相似性,增加了它们被选择的可能性;ii)检索上下文中使用的分块过程破坏了它们的完整性,从而阻碍了它们在llm中的充分利用。
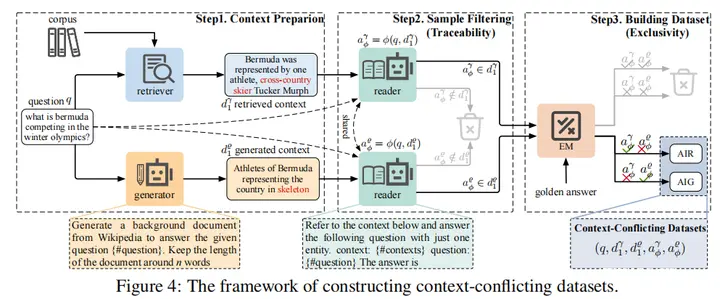
25.To Generate or to Retrieve? On the Effectiveness of Artificial Contexts for Medical Open-Domain Question Answering
论文链接:https://arxiv.org/abs/2403.01924
开源地址:https://github.com/disi-unibo-nlp/medgenie
主要思想:本文探讨了医学问答中检索的必要性,发现其实检索并不是必须的,可以通过专用模型生成来扩充上下阿文。提出使用生成-阅读的医学问答框架,并取得了sota。本文使用专门的LLM生成多视角的上下文,然后使用它们来提示LLM或微调的SLM
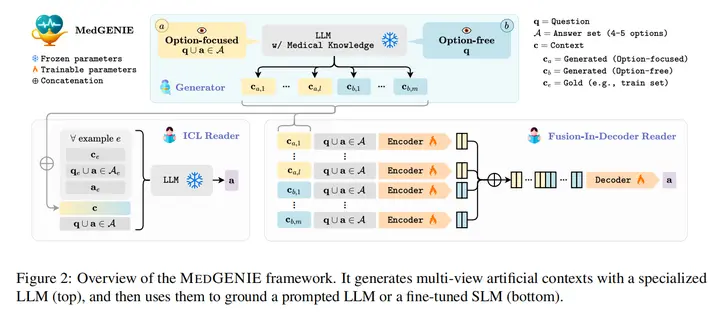
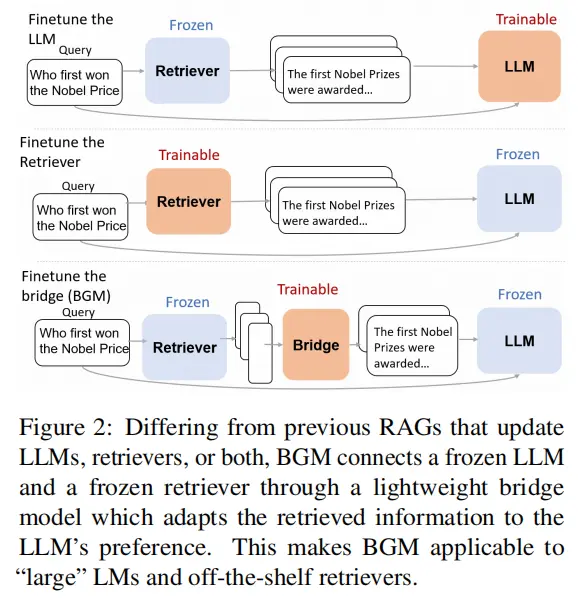
26.Bridging the Preference Gap between Retrievers and LLMs
论文链接:https://arxiv.org/abs/2401.06954
主要思想:通过在检索器和LLM之间建立桥来对齐两者的偏好。首先使用贪心算法不断加入对效果提升有用的银文档。再利用这些文档的分数排名监督微调桥模型,从而正确排序银文档。最后使用强化学习将桥模型和冻住的LLM一起训练,让桥模型对齐LLM的偏好。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。