构建本地 AI 智能体:LangGraph、AI 智能体和 Ollama 使用指南
七七Seven~ 2024-09-30 12:31:01 阅读 98
一、Ollama 快速介绍
Ollama 是一个开源项目,它使在本地机器上运行大型语言模型(LLM)变得简单且用户友好。它提供了一个用户友好的平台,简化了 LLM 技术的复杂性,使其易于访问和定制,适用于希望利用 AI 力量而无需广泛的技术专业知识的用户。
它易于安装。此外,我们有一系列模型和一套全面的功能和功能,旨在增强用户体验。

关键特点:
本地部署:直接在本地机器上运行复杂的 LLM,确保数据隐私并减少对外部服务器的依赖。用户友好的界面:设计直观易用,适用于不同技术水平的用户。可定制性:微调 AI 模型以满足您的特定需求,无论是研究、开发还是个人项目。开源:作为开源项目,Ollama 鼓励社区贡献和持续改进,促进创新和协作。轻松安装:Ollama 以其用户友好的安装过程脱颖而出,为 Windows、macOS 和 Linux 用户提供直观、无忧的设置方法。
Ollama 社区是一个充满活力、以项目为驱动的社区,促进协作和创新,有一个活跃的开源社区增强其开发、工具和集成。
二、使用 LangGraph 和 Ollama 创建 AI 智能体的步骤
在这个演示中,我们将使用qwen2:7b 模型创建一个简单的智能体示例。这个智能体可以使用 Tavily 搜索 API 搜索网络并生成响应。
我们将从安装 Langgraph 开始,这是一个设计用于使用 LLM 构建有状态、多参与者应用程序的库,非常适合创建智能体和多智能体工作流程。LangGraph 受到 Pregel、Apache Beam 和 NetworkX 的启发,由 LangChain Inc. 开发,可以独立于 LangChain 使用。
我们将使用qwen2:7b 作为我们的 LLM 模型,该模型将与 Ollama 和 Tavily 的搜索 API 集成。Tavily 的 API 针对 LLM 进行了优化,提供了事实性、高效、持久的搜索体验。
开始安装langgraph包:
<code>pip install -U langgraph
如有需要,安装其他包:
pip install langchain-openai langchainhub
完成安装后,我们将进入下一个关键步骤:提供 Travily API 密钥。
注册 Travily 并生成 API 密钥。
export TAVILY_API_KEY="apikeygoeshere"code>
现在,我们将运行以下代码来获取模型。请尝试使用 Llama 或任何其他版本的 qwen2:7b。
ollama pull qwen2:7b
导入构建智能体所需的所有必要库。
from langchain import hub
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.prompts import PromptTemplate
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_community.chat_models import ChatOllama
我们将首先定义我们想要使用的工具,并将工具与 llm 绑定。在这个简单的例子中,我们将使用通过 Tavily 提供的内置搜索工具。
示例代码如下所示:
import os
# 设置环境变量"TAVILY_API_KEY",将其值设为一个API密钥字符串
# 这个密钥用于认证和授权应用程序访问Tavily API的服务
# 通过将API密钥存储在环境变量中,可以提高代码的安全性和可维护性,避免硬编码敏感信息
os.environ["TAVILY_API_KEY"] = "tvly-xxxxxxxxxx"
# 初始化ChatOpenAI实例,设置以下参数:
# model参数指定使用的语言模型为"qwen2:7b"
# temperature参数设置为0.0,这意味着生成的响应将更加确定和基于模型的知识,减少随机性
# api_key参数设置为"ollama"
# base_url参数指定了与模型交互的API基础URL,此处指向本地主机上的一个特定端口和路径
llm = ChatOpenAI(model="qwen2:7b", temperature=0.0, api_key="ollama", base_url="http://localhost:11434/v1")code>
# 创建工具列表,其中包含一个TavilySearchResults实例,用于执行搜索操作
# max_results参数设置为3,这意味着每次搜索将返回最多3个结果
tools = [TavilySearchResults(max_results=3)]
下面的代码片段检索一个提示模板并以可读格式打印。然后可以根据需要使用或修改此模板。
# 从LangChain的Hub中拉取一个预定义的prompt模板
prompt = hub.pull("wfh/react-agent-executor")
# 使用pretty_print()方法以更易读的格式打印模板内容
prompt.pretty_print()
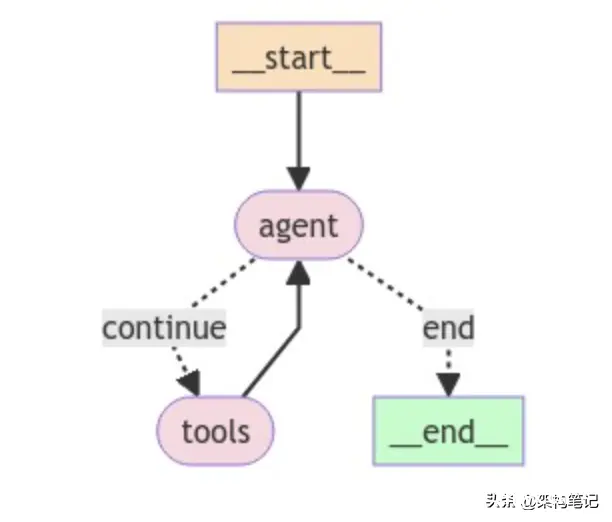
使用前面创建的语言模型(llm)、一组工具(tools)和一个提示模板(prompt)创建一个智能体(agent)。
<code># 创建agent对象
agent = create_react_agent(llm, tools, messages_modifier=prompt)
from IPython.display import Image, display
# agent.get_graph()方法返回代理的内部状态图,描述了代理的组件和它们之间的关系
# draw_mermaid_png()方法将状态图转换为PNG格式的图像,便于可视化展示
display(Image(agent.get_graph().draw_mermaid_png()))
这段代码的作用是在Jupyter Notebook中显示智能体的结构和工作流程图,帮助理解和调试智能体的行为。

agent 节点会使用消息列表调用语言模型。如果生成的 AIMessage 包含 tool_calls,则图将调用 tools 节点。tools 节点执行工具(每个 tool_call 执行一个工具),并将响应作为 ToolMessage 对象添加到消息列表中。然后 agent 节点再次调用语言模型。这个过程会一直重复,直到响应中不再有 tool_calls。然后 agent 返回包含键 “messages” 的字典,其中包含了完整的消息列表。
<code># 调用agent的invoke方法
response = agent.invoke({"messages": [("user", "解释人工智能")]})
# 遍历响应字典中'messages'键对应的列表,该列表包含了代理生成的响应消息
for message in response['messages']:
print(message.content)
生成如下响应:
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【<code>保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/weixin_58753619/article/details/141902078?spm=1001.2014.3001.5501,如有侵权,请联系删除。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。