智能体应用开发:构建各类垂直领域的ai智能体应用
CSDN 2024-06-11 14:31:07 阅读 78
最近在做个类似的项目,有用到这方面的知识,顺便做一些记录和笔记吧,希望能帮到大家了解智能体应用开发
目录
引言
AI原生应用的兴起
智能体在AI中的角色
实现原理详解
机器学习基础
数据管理与关联数据库
数据结构
Embedding
检索方案
部分实践代码
强化学习与决策制定
首先,我们需要定义MDP的几个关键元素:
智能体的设计与开发
需求分析与场景定义
智能体架构设计
开发工具与平台
零代码/低代码开发平台
开源框架与库
引言
AI原生应用的兴起
随着人工智能技术的飞速发展,AI原生应用逐渐成为创新的前沿。这些应用从设计之初就将AI技术作为核心,与传统的应用程序相比,它们能够提供更加智能化、个性化的服务。AI原生应用正在改变我们与技术的互动方式,从简单的工具使用转变为与智能助手的协作,这些助手能够理解我们的需求,预测我们的行动,并提供定制化的解决方案。
智能体在AI中的角色
智能体(Agent)是AI领域中一个关键的概念,它指的是能够在特定环境中自主运作并执行任务的软件实体。智能体不仅可以感知其环境,还能做出决策并采取行动以达成目标。在AI原生应用中,智能体充当着用户与复杂AI系统之间的桥梁,它们使得AI技术更加易于访问和使用。
实现原理详解
机器学习基础
机器学习是智能体实现智能行为的关键技术之一。它使智能体能够从数据中学习并改进其性能。
监督学习:智能体通过已标记的训练数据学习预测或决策任务。非监督学习:智能体在没有明确标记的数据中寻找模式和结构。强化学习:智能体通过与环境的交互学习最优行为策略以最大化某种累积奖励。
数据管理与关联数据库
智能体需要有效的数据管理来支持其学习和决策过程。
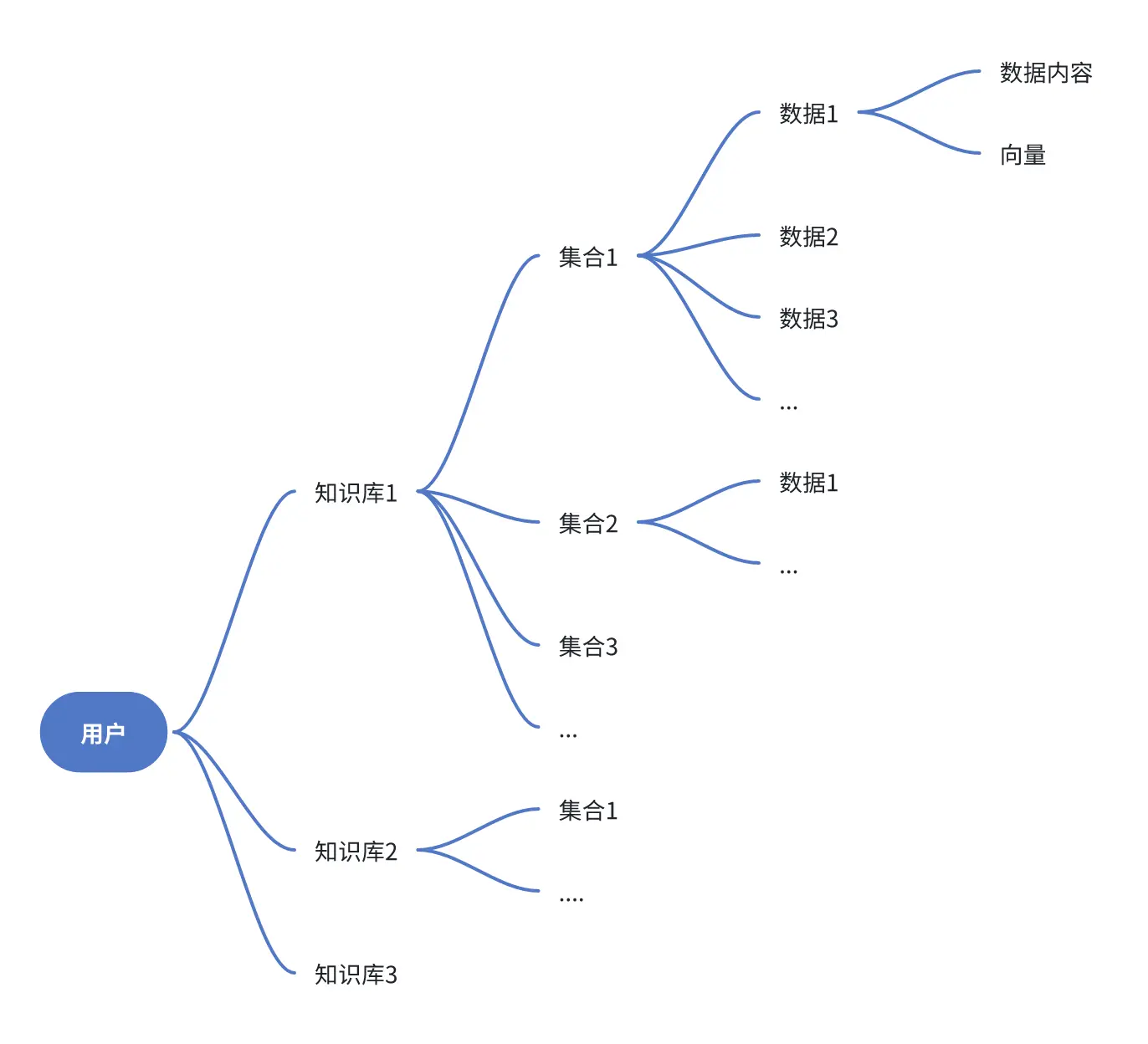
数据库的类型与选择:根据智能体的需求选择合适的数据库系统,如关系型数据库、NoSQL数据库等。
关联规则与数据挖掘:使用数据挖掘技术发现数据中的关联规则,帮助智能体做出更好的决策。
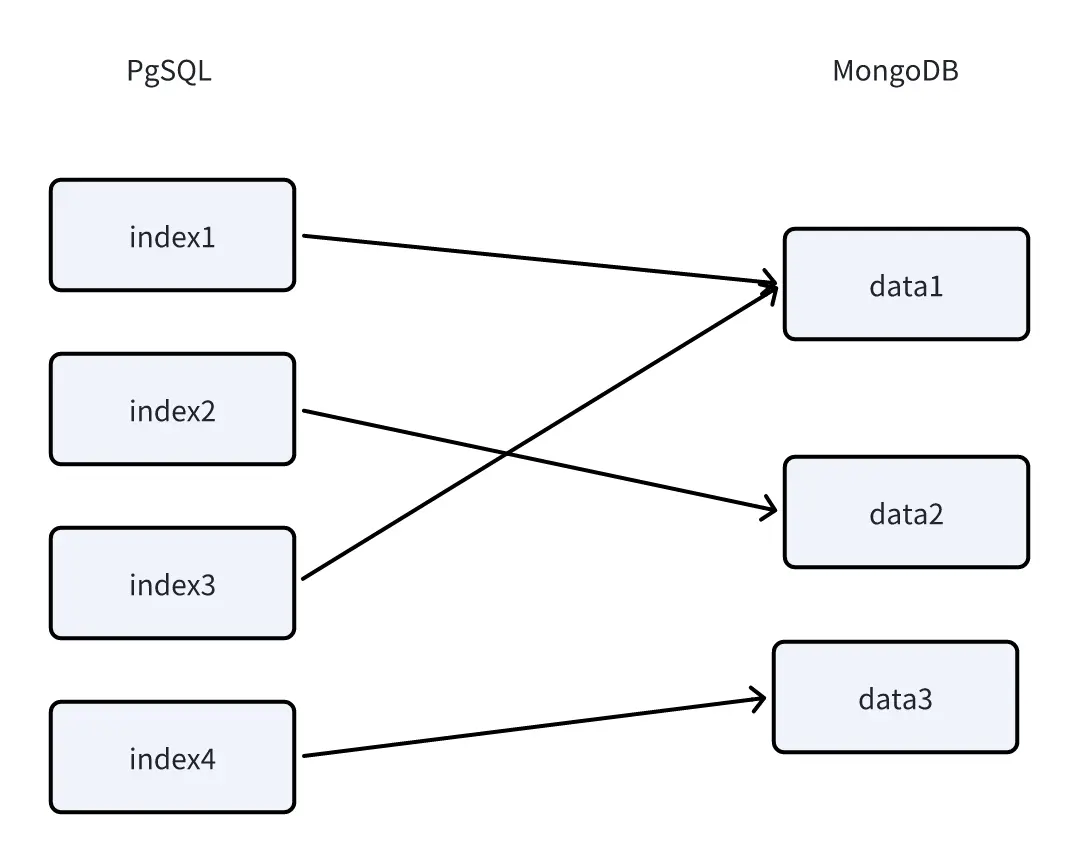
数据结构
Embedding
人类的文字、图片、视频等媒介是无法直接被计算机理解的,要想让计算机理解两段文字是否有相似性、相关性,通常需要将它们转成计算机可以理解的语言,向量是其中的一种方式。
向量可以简单理解为一个数字数组,两个向量之间可以通过数学公式得出一个距离,距离越小代表两个向量的相似度越大。从而映射到文字、图片、视频等媒介上,可以用来判断两个媒介之间的相似度。向量搜索便是利用了这个原理。
而由于文字是有多种类型,并且拥有成千上万种组合方式,因此在转成向量进行相似度匹配时,很难保障其精确性。在向量方案构建的知识库中,通常使用topk召回的方式,也就是查找前k个最相似的内容,丢给大模型去做更进一步的语义判断、逻辑推理和归纳总结,从而实现知识库问答。因此,在知识库问答中,向量搜索的环节是最为重要的。
影响向量搜索精度的因素非常多,主要包括:向量模型的质量、数据的质量(长度,完整性,多样性)、检索器的精度(速度与精度之间的取舍)。与数据质量对应的就是检索词的质量。
检索器的精度比较容易解决,向量模型的训练略复杂,因此数据和检索词质量优化成了一个重要的环节。
检索方案
通过改进问题处理来实现消除指代和扩展问题,这将增强对话的连贯性以及语义的深度。使用Concat查询技术来提升连续对话的重排序过程,从而提高排序的准确性。利用RRF合并策略,整合多个来源的搜索结果,以提升整体的搜索效果。通过重排序机制,对结果进行再次排序,以提升搜索结果的精确度。
部分实践代码
import re# 假设我们有以下对话历史和问题dialog_history = ["今天天气怎么样?", "明天会下雨吗?", "北京的天气如何?"]current_question = "北京明天的天气怎么样?"# 指代消除和问题扩展def expand_question(question, history): # 这里简单用正则表达式匹配和替换,实际情况可能需要更复杂的NLP处理 for q in history: question = re.sub(r"\b北京\b", q, question, flags=re.IGNORECASE) return questionexpanded_question = expand_question(current_question, dialog_history)# Concat查询,假设我们有两个不同的搜索引擎返回的结果def concat_query(expanded_question): # 这里假设search_engine_1和search_engine_2是两个搜索函数 results_1 = search_engine_1(expanded_question) results_2 = search_engine_2(expanded_question) # 合并结果 return results_1 + results_2concatenated_results = concat_query(expanded_question)# RRF合并方式,这里我们简单地使用取并集的方式def rrf_merge(results): # 假设result是一个包含多个搜索结果的列表 merged_results = list(set(results)) # 使用set去重 return merged_resultsrrf_results = rrf_merge(concatenated_results)# Rerank二次排序,这里我们简单地根据结果的相关性进行排序def rerank(results): # 这里假设我们有一个函数来评估结果的相关性 ranked_results = sorted(results, key=lambda x: relevance_score(x), reverse=True) return ranked_resultsreranked_results = rerank(rrf_results)# 假设的搜索函数和相关性评分函数def search_engine_1(question): # 这里只是一个示例,实际中会调用搜索引擎API return ["晴", "多云", "有雨"]def search_engine_2(question): # 这里只是一个示例,实际中会调用另一个搜索引擎API return ["有雨", "晴转多云"]def relevance_score(result): # 这里只是一个示例,实际中会根据结果的相关性进行评分 return len(result)# 输出最终结果print("Expanded Question:", expanded_question)print("Reranked Results:", reranked_results)
强化学习与决策制定
强化学习是智能体在动态环境中做出决策的关键。
马尔可夫决策过程(MDP):提供了一种数学框架来分析决策过程。
首先,我们需要定义MDP的几个关键元素:
状态(States): 对话系统的状态可以是当前对话的历史和当前问题。动作(Actions): 在重排序的上下文中,动作可能是选择不同的排序策略或调整排序参数。奖励(Rewards): 奖励可以是基于用户满意度的反馈,或者是排序后结果的相关性得分。转移概率(Transition Probabilities): 这表示在给定状态下,采取某个动作后转移到新状态的概率。import numpy as np# 假设我们有一组候选答案和它们的初始相关性得分candidates = ["答案1", "答案2", "答案3"]initial_scores = np.array([0.7, 0.6, 0.8])# 定义状态转移矩阵,这里简化为随机选择动作transition_matrix = np.random.rand(len(candidates), len(candidates))# 定义奖励函数,这里简化为基于初始得分的随机奖励def reward_function(state, action): # 假设奖励与初始得分成正比 return initial_scores[action]# 定义MDP模型class MDP: def __init__(self, states, actions, transition_probabilities, reward_function): self.states = states self.actions = actions self.transition_probabilities = transition_probabilities self.reward_function = reward_function def step(self, state, action): # 执行动作并返回奖励和下一个状态 next_state = np.random.choice(self.states, p=self.transition_probabilities[state][action]) reward = self.reward_function(state, action) return reward, next_state# 初始化MDPmdp = MDP(states=candidates, actions=range(len(candidates)), transition_probabilities=transition_matrix, reward_function=reward_function)# 简单的策略迭代算法def policy_iteration(mdp, gamma=0.9, theta=1e-6): policy = {s: np.random.choice(mdp.actions) for s in mdp.states} V = {s: 0 for s in mdp.states} while True: delta = 0 for s in mdp.states: v = V[s] V[s] = max([sum([mdp.transition_probabilities[s][a][i] * (mdp.reward_function(s, a) + gamma * V[i]) for i in mdp.states]) for a in mdp.actions]) delta = max(delta, abs(v - V[s])) if delta < theta: break policy = {s: np.argmax([sum([mdp.transition_probabilities[s][a][i] * (mdp.reward_function(s, a) + gamma * V[i]) for i in mdp.states]) for a in mdp.actions]) for s in mdp.states} return policy, V# 执行策略迭代policy, value_function = policy_iteration(mdp)# 输出最优策略print("最优策略:", policy)
智能体的设计与开发
需求分析与场景定义
设计和开发智能体的第一步是进行需求分析和场景定义。这一阶段的目标是明确智能体需要解决的问题、它将如何与用户或其他系统交互,以及它需要满足的性能标准。需求分析包括但不限于:
用户需求调研:了解目标用户群体的需求和期望。功能定义:列出智能体需要实现的具体功能。场景模拟:设想智能体在不同情境下的应用案例。性能指标:确定智能体的性能标准,如响应时间、准确性等。
智能体架构设计
智能体的架构设计是构建其内部结构和组件的过程。一个良好的架构设计能够确保智能体的灵活性、可扩展性和可维护性。架构设计的关键要素包括:
感知模块:负责收集环境信息。决策模块:基于感知信息和内部知识库做出决策。行动模块:执行决策模块的指令,与外部环境交互。学习模块:使智能体能够从经验中学习并优化行为。通信模块:如果需要与其他系统或智能体交互,设计通信接口。
开发工具与平台
选择合适的开发工具和平台对于智能体的开发至关重要。这些工具和平台能够提供必要的支持,帮助开发者快速构建和测试智能体。
开发环境:选择支持智能体开发的语言和开发环境,如Python、Java等。API和SDK:利用现有的API和SDK来加速开发过程,如语音识别、图像处理等。版本控制:使用版本控制系统,如Git,来管理代码和协作。
零代码/低代码开发平台
零代码/低代码开发平台使得非技术用户也能够参与到智能体的开发中来。这些平台通过可视化的拖拽界面和预定义的模板简化了开发流程:
可视化编程:通过图形界面进行编程,无需编写代码。模板和组件:提供可重用的模板和组件,加速开发过程。自动化部署:一键部署智能体到不同的平台和设备。
开源框架与库
利用开源框架和库可以减少开发工作量,同时利用社区的力量来改进和维护智能体:
机器学习框架:如TensorFlow、PyTorch等,用于构建和训练智能体的模型。自然语言处理库:如NLTK、spaCy等,提供语言处理的工具和算法。强化学习库:如OpenAI Gym、DeepMind Lab等,提供强化学习的环境和算法。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。