COLMAP进化版:Global Structure-from-Motion Revisited论文粗读(更新中)
m0_74310646 2024-09-07 08:01:02 阅读 61
Abstract
从图像中恢复 3D 结构和相机运动一直是计算机视觉研究的长期焦点,被称为运动结构 (SfM)。这个问题的解决方案分为渐进式和全局式两种。到目前为止,最受欢迎的系统由于其卓越的准确性和鲁棒性而遵循增量范式,而全局方法的可扩展性和效率大大提高。在这项工作中,我们重新审视了全局 SfM 的问题,并提出 GLOMAP 作为一种新的通用系统,其性能优于全球 SfM 的最新技术。在准确性和稳健性方面,我们实现的结果与COLMAP(使用最广泛的增量SfM)相当或更胜一筹,同时速度快几个数量级。
1.introduction
从图像集合中恢复 3D 结构和相机运动仍然是计算机视觉中的一个基本问题,它与各种下游任务高度相关,例如新视图合成或基于云的映射和定位。多年来,出现了解决该问题的两种主要范例:增量方法和全局方法。 两者都从基于图像的特征提取和匹配开始,然后进行双视图几何估计以构造输入图像的初始视图图。
然后,增量方法从两个视图中进行重建,并通过配准额外的相机图像和相关的 3D 结构来顺序扩展它。这个过程交织了绝对相机位姿估计、三角测量和束调整,尽管实现了高精度和鲁棒性,但由于昂贵的重复束调整而限制了可扩展性。相比之下,全局方法通过共同考虑视图图中的所有两个视图几何形状,在单独的旋转 和平移平均 步骤中立即恢复所有输入图像的相机几何形状。 通常,在最终全局束调整步骤之前,全局估计的相机几何形状随后被用作 3D 结构三角测量的初始化。
虽然最先进的增量方法被认为更准确和稳健,但全局方法的重建过程更具可扩展性,并且在实践中速度要快几个数量级。 在本文中,我们重新审视全局 SfM 的问题,并提出了一个综合系统,该系统可实现与最先进的增量 SfM(例如图 1a)相似的准确性和鲁棒性水平,同时保持全局方法的效率和可扩展性。

增量 SfM 和全局 SfM 之间的准确性和鲁棒性差距的主要原因在于全局平移平均步骤。 平移平均描述了根据视图图中的一组相对姿势估计全局相机位置的问题。 这一过程在实践中面临三大挑战:
第一个是尺度模糊性:估计的双视图几何的相对平移只能在尺度范围内确定。 因此,为了准确估计全局相机位置,需要相对方向的三元组。然而,当这些三元组形成倾斜三角形时,估计的尺度在观察中特别容易出现噪声。
第二,将相对的双视图几何形状准确地分解为旋转和平移分量,需要精确的相机内在知识的先验知识。 如果没有这些信息,估计的平移方向通常会出现很大的误差。
第三,近共线运动导致的退化重建问题(一条线上拍照)。 这种运动模式很常见,尤其是在序列数据集中(比如视频帧)。 这些问题共同导致相机位置估计的不稳定,严重影响现有全局 SfM 系统的整体精度和鲁棒性。
这项工作的主要贡献是引入了通用的全局 SfM 系统,称为 GLOMAP。 与以往的全球SfM系统的核心区别在于全球定位的步骤。GLOMAP 实现了与最先进的增量 SfM 系统 [59] 相似的鲁棒性和准确性,同时保持了全局 SfM 管道的效率。 与大多数以前的全局 SfM 系统不同,我们的系统可以处理未知的相机内在特征(例如,如互联网照片中所示)并稳健地处理顺序图像数据(比如手持视频或自动驾驶汽车场景)。
Q1:全局三角测量是什么?
全局三角测量(Global Triangulation)通常指的是在计算机视觉和三维重建中,通过多个图像的特征点匹配来计算三维点的位置的过程。与增量式三角测量相比,全局三角测量一次性考虑所有图像和所有匹配的特征点,以生成最一致的三维点云。以下是全局三角测量的一些关键点:
全局一致性:
全局三角测量考虑所有图像和特征点之间的几何关系,力求生成一个全局一致的三维结构。这意味着所有图像之间的相对位置和方向(即相机姿态)以及三维点的位置都是相互一致的。
多视几何:
全局三角测量使用来自多个视角(图像)的特征点来确定三维点的位置。这与增量式方法不同,后者通常是逐步增加新的图像并调整相应的三维点。
全局优化:
在全局三角测量中,经常使用全局优化技术(如捆绑调整,Bundle Adjustment)来调整相机参数和三维点的位置,使得重投影误差(即图像中的特征点和由三维点投影回图像平面的点之间的误差)最小化。这种全局优化可以显著提高重建的精度和一致性。
2.Review of Global Structure-from-Motion
全局 SfM pipeline通常由三个主要步骤组成:对应搜索、相机姿态估计以及联合相机和结构细化。
2.1Correspondence Search-特征提取、匹配,得到R和t
增量 SfM 和全局 SfM 都从输入图像 I = {I1,...,IN} 中提取显着图像特征开始。 传统上,检测特征点 ,然后使用从检测周围的局部上下文导出的紧凑签名进行描述。 接下来是搜索图像对 (Ii, Ij) 之间的特征对应关系,首先有效地识别具有重叠视场的图像子集 ,然后以成本更高的过程对它们进行匹配。
匹配通常首先纯粹基于紧凑的视觉特征来完成,最初产生相对较大比例的异常值。 然后通过稳健地恢复重叠对的双视图几何来验证这些。 基于相机的几何配置,这会产生具有一般运动的平面场景和具有一般场景的纯相机旋转的单应性 Hij,或者用于一般场景和一般运动的基本矩阵 Fij(未校准)和基本矩阵 Eij(校准) 。 当相机内参近似已知时,它们可以分解为相对旋转 Rij ∈ SO(3) 和平移 tij ∈ R3。
2.2 Global Camera Pose Estimation-恢复相机
全局相机位姿估计是区分全局 SfM 和增量 SfM 的关键步骤。全局 SfM 不是通过重复的三角测量和束调整来顺序注册相机,而是使用视图图 G 作为输入一次性估计所有相机位姿 Pi = (Ri, ci) ∈ SE(3)。 为了使问题易于处理,通常将其分解为单独的旋转和平移平均步骤。
旋转平均,有时也称为旋转同步,已经研究了几十年,并且与位姿图优化 (PGO) 算法相关,一般表示为一个非线性优化问题,惩罚全局旋转与估计的相对姿势的偏差。具体来说,绝对旋转 Ri 和相对旋转 Rij 理想情况下应满足约束 Rij = RjR⊤ i 。然而,在实践中,由于噪声和异常值,这并不完全成立。因此,该问题通常使用鲁棒的最小度量目标进行建模,并优化为

Hartley等[26]全面概述了鲁棒因子ρ(如Huber)、旋转参数化(如四元数或轴角)和距离度量d(如弦距或测地线距离)的各种选择。
基于这些原理, 学者们提出了多种方法做改进以提升效果,已经探索了各种稳健的损失函数来处理异常值,最近,出现了基于学习的方法,我们使用 Chatterjee 等人自己的实现[Chatterjee, A., Govindu, V.M.: Efficient and robust large-scale rotation averaging.
In: Proceedings of the IEEE International Conference on Computer Vision. pp.
521–528 (2013)]。作为一种可扩展的方法,可以在存在噪声以及异常值污染的输入旋转的情况下提供准确的结果。
平移平均,旋转平均后,旋转 Ri 可以从相机位姿中分解出来。 仍有待确定的是摄像机位置 ci。 平移平均描述了基于约束
, 估计与成对相对平移 tij 最大程度一致的全局相机位置的问题。 然而,由于噪声和异常值以及相对翻译的未知规模,该任务尤其具有挑战性。 原则上,如果视图图具有平行刚度性质,则相机位姿可以唯一确定。
在我们提出的系统中,我们跳过了平移平均的步骤。相反,我们直接对相机和点位置进行联合估计。我们将此步骤称为全局定位,详细信息将在第3.2节中介绍。
用于相机姿态估计的结构。一些工作已经探索了将3D结构结合到相机位置估计中。Ariel等人。直接使用双视图几何中的对应关系来估计全局平移。Wilson等人发现,3D点可以以与相机中心类似的方式处理,因此可以轻松地纳入优化。Cui等人通过将点轨迹包含到具有线性关系的优化问题中来扩展。为了减少尺度漂移,Holynski等人将线和平面特征集成到优化问题中。Manam等人。[44]通过在优化中重新权衡相对平移来合并对应关系。LiGT 提出了一种“仅姿态”方法,用于求解具有由点施加的线性全局平移约束的相机位置。这些作品的共同主题是,结合对3D场景结构的约束有助于相机位置估计的鲁棒性和准确性,我们把我们的工作作为一个灵感。
2.3Global Structure and Pose Refinement-获得全局3D结构
在恢复相机之后,可以通过三角测量获得全局3D结构。与相机外参和内参一起,然后通常使用全局光束法平差来细化3D结构。
全局三角测量。给定两个视图匹配,可传递对应 可用于提高完整性和准确性,我们的方法通过单个联合全局优化方法以及摄像机位置直接估计3D点(参见第3.2节)。全局束平差是获得精确的最终3D结构Xk ∈ R3、相机外参Pi和相机内参πi的必要条件。对应的优化问题如下:

相关请参考Triggs等人[70]对光束法平差的全面回顾。
2.4 Hybrid Structure-from-Motion - 将全局SfM的增量鲁棒性和高效性联合收割机结合起来
为了将全局SfM的增量鲁棒性和高效性联合收割机结合起来,以前的工作已经制定了混合系统。HSfM [17]建议使用旋转增量估计相机位置。Liu等人。[41]提出了一种图划分方法,首先将整个图像集划分为重叠的聚类。在每个集群内,通过全局SfM方法估计相机姿态。然而,这样的方法仍然是不适用的相机本质是不准确的,根据他们的配方。我们的方法克服了这个限制,通过不同的建模的目标在全局定位步骤。
2.5 Frameworks for Structure-from-Motion
有多个开源SfM管道可用。增量式SfM范式由于其在现实场景中的鲁棒性和准确性而成为目前使用最为广泛的范式。Bundler 和VisualSfM 是10年前的系统。在此基础上,Schönberger等人开发了COLMAP,一种通用的SfM和多视角立体估计系统。COLMAP是一种多功能工具,在许多数据集上都表现出了强大的性能,使其成为近年来基于图像的3D重建的标准工具。
几个开源管道也可用于全球SfM。比如OpenMVG,Theia,还有几个基于学习的管道可用。比如PixSfM,VGGSfM,我们提出了一个新的端到端的全局SfM管道,并将其作为开源贡献发布给社区,以促进下游应用和进一步研究。
3.Technical Contributions
本节介绍了我们为改善全局SfM最新技术水平所做的主要技术贡献(参见图2),并在鲁棒性和准确性方面接近增量SfM的差距。

3.1Feature Track Construction-优化了特征检测、匹配、稀疏重建过程的精度
特征轨迹必须仔细构造,以实现精确的重建。我们首先仅考虑由双视图几何验证产生的内点特征对应关系。在这一步中,我们区分两视图几何的初始分类:如果单应性H最好地描述了两视图几何,我们使用H来验证内点。同样的原理也适用于本质矩阵E和基本矩阵F。我们通过进行手征测试进一步过滤离群值。靠近任何核线或具有小三角测量角度的匹配也被移除,以避免由于大的不确定性而导致的奇异性。在对所有视图图边缘进行成对过滤后,我们通过连接所有剩余的匹配来形成特征轨迹。
Q1.什么是特征轨迹?
特征轨迹(Feature Tracks)是计算机视觉和多视图几何中的一个重要概念。它指的是在多张图像中识别出相同的物理点或特征,并在这些图像中跟踪它们的位置变化。特征轨迹的构建对于三维重建、运动估计和场景理解等任务非常关键。
具体来说,特征轨迹的构建过程包括以下几个步骤:
特征检测:在每张图像中检测出显著的特征点,如角点、边缘或纹理。特征描述:为每个特征点生成一个特征描述符,以便在不同图像之间进行匹配。特征匹配:在不同的图像中找到相同的特征点,这通常通过比较特征描述符来完成。轨迹构建:将同一个物理点在不同图像中的匹配结果连接起来,形成特征轨迹。
通过特征轨迹,可以追踪同一个物理点在多个图像中的位置变化,这对于恢复场景的三维结构、相机的运动轨迹以及进行后续的计算和分析都非常重要。特征轨迹越准确,最终的重建结果就越精确。
Q2:在colmap中,跟这一块相关的是什么?
在COLMAP(一个用于结构从运动(SfM)和多视图立体匹配的开源软件)中,与“只考虑通过两视几何验证生成的内点特征对应关系”相关的知识主要涉及两视几何基础的理论和方法。这些概念包括:
两视几何(Two-View Geometry):
在计算机视觉中,两视几何描述了从两个不同视点观察同一个场景时,图像中点的对应关系。两视几何的核心是理解和计算这些点之间的映射关系。
内点和外点:
内点(Inliers)指的是符合几何模型的点对,例如在两视几何中符合基础矩阵或本质矩阵约束的点对。外点(Outliers)则是那些不符合几何模型的点对。
基础矩阵(Fundamental Matrix, F):
基础矩阵描述了在不考虑相机内参的情况下,两张图像之间点的对应关系。它包含了两个图像中的点之间的所有几何信息。
本质矩阵(Essential Matrix, E):
本质矩阵是已知相机内参情况下的基础矩阵,它进一步约束了两张图像中点的对应关系,包含了相机的旋转和平移信息。
单应矩阵(Homography Matrix, H):
单应矩阵用于描述当场景为平面或相机在同一平面上移动时,两张图像之间点的变换关系。它是一种特殊的两视几何情况。
特征匹配和验证:
COLMAP通过特征检测(例如SIFT)、特征描述符匹配和两视几何的模型拟合与验证(例如使用RANSAC算法)来识别内点和外点。内点是经过模型验证后确定为准确匹配的点对,而外点则是被过滤掉的错误匹配。
显性测试(Cheirality Test):
用于确定重建点是否在相机的前方。若重建的三维点位于相机的后方,则这些点被认为是错误的匹配,因而被过滤掉。
在COLMAP中,这些概念和技术被应用于特征匹配、两视几何模型的估计和验证,以及构建稳定的特征轨迹。通过严格的内点筛选和验证过程,COLMAP能够提高三维重建的精度和鲁棒性。
Q3:特征轨迹涉及特征检测、匹配、稀疏重建步骤中的哪几步 ?
特征轨迹(Feature Tracks)是在COLMAP的稀疏重建过程中生成和维护的,主要涉及的步骤是Feature Matching和Mapper。以下是详细说明:
Feature Matching(特征匹配):
在特征匹配阶段,COLMAP会找到相邻图像间的特征点对。这些匹配的特征点对可以被看作是初步的特征轨迹的开始。在这一阶段,COLMAP会识别哪些特征点在不同图像中对应于同一物理点,从而建立初步的特征轨迹。
Mapper(地图构建/稀疏重建):
在Mapper阶段,特征轨迹会进一步被扩展和优化。具体来说,在初始化重建时,选择的初始图像对会提供第一批三维点,这些点的特征轨迹也会被记录。在增量式重建过程中,随着新的图像被添加,已有特征轨迹会被进一步延伸,新的特征轨迹也会被创建。这一过程中,COLMAP会不断更新特征轨迹,以反映新加入图像中的特征点与已有三维点的对应关系。几何验证和全局优化过程中,特征轨迹会被进一步精炼,确保它们的一致性和准确性。
特征轨迹是三维重建的基础数据之一,它记录了特征点在不同图像间的匹配关系,确保了特征点在三维空间中的位置能够被准确计算和优化。总之,特征轨迹的生成和维护贯穿于Feature Matching和Mapper这两个步骤中,是稀疏重建过程中的重要一环。
3.2 Global Positioning of Cameras and Points
该步骤旨在联合恢复点和相机位置(参见图3)。我们直接执行联合全局三角测量和相机位置估计,而不是执行平移平均,然后进行全局三角测量。不同于以往的工作,我们的目标函数是初始化自由和一致收敛到一个很好的解决方案在实践中。在标准的增量和全局SfM系统中,特征轨迹通过重投影误差进行验证和优化,以确保可靠和准确的三角测量。
然而,跨多个视图的重投影误差是高度非凸的,因此要求精细的初始化。此外,误差是无界的,因此它对离群值不鲁棒。了克服这些挑战,我们建立在【Zhuang, B., Cheong, L.F., Lee, G.H.: Baseline desensitizing in translation aver-
aging. In: Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition. pp. 4539–4547 (2018)】提出的目标函数的基础上,并使用归一化方向差作为误差度量。原始公式是根据相对平移提出的,而在我们的公式中,我们丢弃了相对平移约束,只包括相机光线约束。具体的优化问题arg请看论文。
与经典的平移平均相比,在优化中丢弃相对平移项具有两个关键优点。首先,我们的方法对具有不准确或未知相机固有特性以及不遵循预期针孔模型的退化相机的数据集的适用性(例如,当处理任意的互联网照片时)。这是因为需要精确的intrinsic知识来解决相对平移,当他们偏离期望值时,估计的两视图平移具有较大的误差。由于尺度未知,平移平均本质上是不适定的,因此从噪声和异常值污染的观察结果中恢复相机位置具有挑战性,特别是当相对平移误差随着基线较长而加剧时。相反,我们提出的管道依赖于仔细过滤的两个视图的几何形状和错误定义w.r.t.照相机的光线。因此,差的相机固有函数仅使各个相机的估计偏置,而不是也使其他重叠相机偏置。第二,全局SfM在共线运动场景中的适用性,这是平移平均的已知退化情况。与成对相对平移相比,特征轨迹约束多个重叠相机。因此,我们提出的管道可以更可靠地处理常见的向前或侧向运动场景(见第4.3节)。
Q1:什么是BA
联合优化(Bundle Adjustment):
三角测量:通过匹配的特征点和相机的初始位姿估计三维点的位置。这一步骤称为三角测量。全局优化:使用Bundle Adjustment方法,对所有相机的位姿和三维点的位置进行全局优化,最小化重投影误差(即三维点投影到图像平面后的误差)。
迭代优化:通过反复进行特征匹配、三角测量和全局优化,逐步提高相机位置和三维点的估计精度。每次优化后,新的三维点和相机位姿会用于进一步的特征匹配和估计。
这种方法的优点是能够在全局范围内同时优化相机位置和三维点的位置,从而得到更加一致和准确的重建结果。
3.3 Global Bundle Adjustment
全局定位步骤提供了对相机和点的鲁棒估计。然而,准确性是有限的,特别是当相机的内参是事先不知道。作为进一步的改进,我们进行了几轮的全球捆绑调整使用Levenberg-Marquardt和Huber损失作为一个鲁棒。在每一轮中,摄像机旋转首先是固定的,然后用内在函数和点进行联合优化。这样的设计对于重建顺序数据特别重要。在构建第一个光束法平差问题之前,我们根据角度误差对3D点观测值进行预滤波,同时允许未校准相机有更大的误差。然后,我们过滤的基础上在图像空间的重投影误差的轨道。当过滤轨迹的比率降至福尔斯0.1%以下时,迭代停止。
3.4 Camera Clustering
对于从互联网上收集的图像,不重叠的图像可能会被错误地匹配在一起。因此,不同的重建崩溃成一个单一的。为了克服这个问题,我们通过对相机进行聚类来对重建进行后处理。首先,通过对每个图像对的可见点的数量进行计数来构造共可见图G。具有少于5个计数的对被丢弃,因为相对姿态不能被可靠地确定为低于该数量,并且剩余对的中值被用于设置内点阈值τ。然后,我们通过寻找G中的强连通分量来找到约束良好的摄像机集群。这样的分量仅由具有多于τ计数的连接对来定义。然后,我们仔细尝试合并两个强分量,如果至少有两个边缘的计数超过0.75τ。我们递归地重复这个过程,直到没有更多的集群可以合并。每个连接的分量作为单独的重建输出。
3.5 Proposed Pipeline
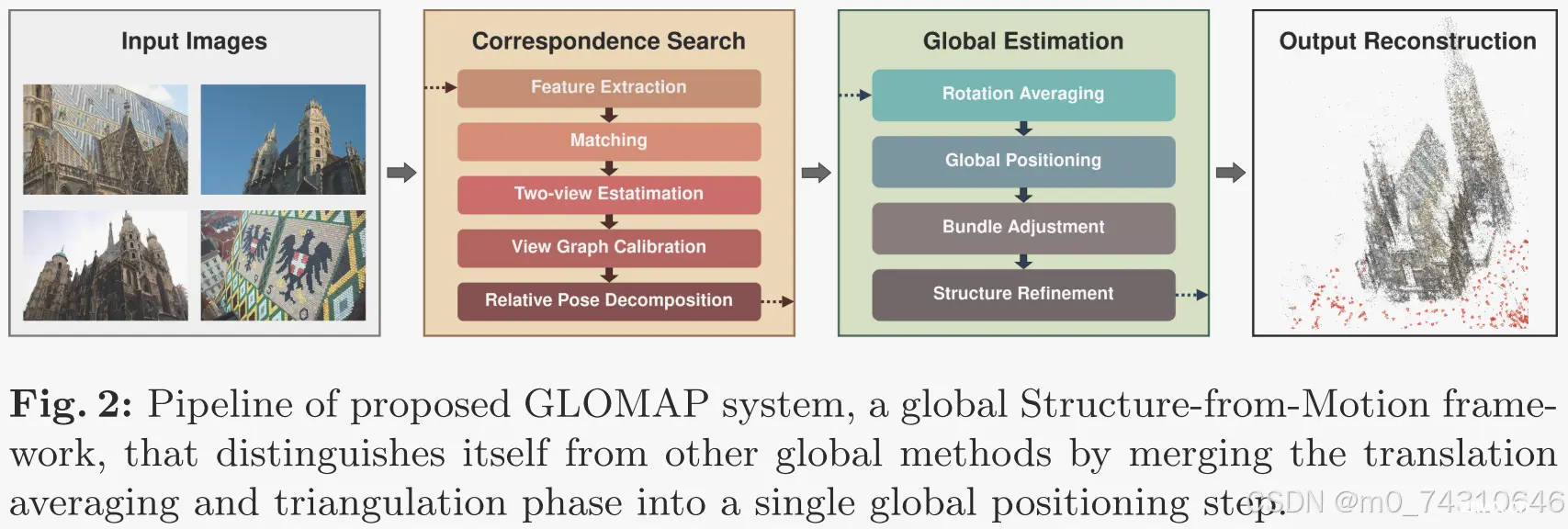
所提出的方法的流水线总结在图2中。它由两个主要部分组成:对应搜索和全局估计。
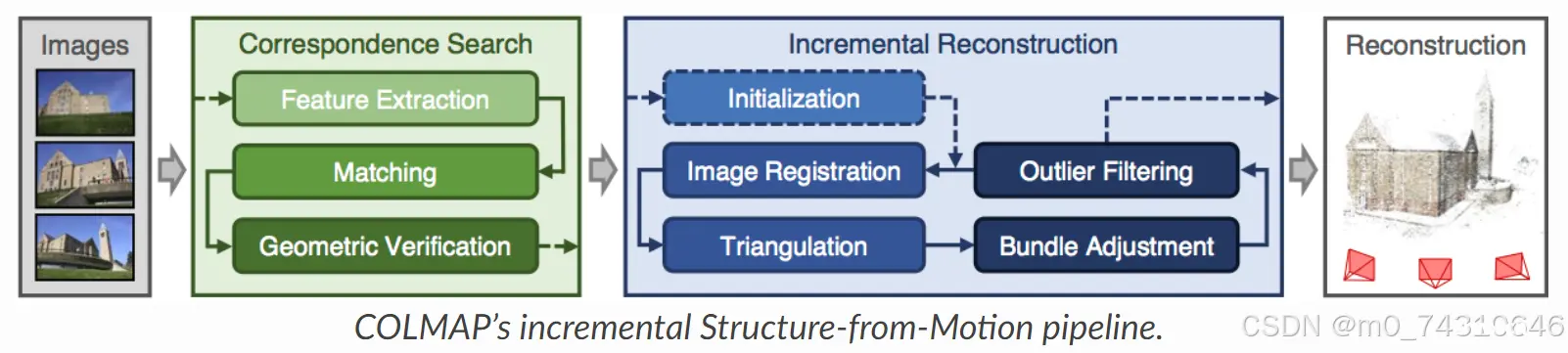
3.5.1colmap pipeline
原来的colmap分了两大步骤:在对应搜索阶段中,经过特征提取、匹配、集合验证得到匹配结果,然后在增量重建阶段,通过图像配准、三角测量、BA、外点滤波迭代得到稀疏点云。

Q1:Geometric Verification
几何验证(Geometric Verification)是计算机视觉和图像处理中的一个重要步骤,特别是在图像匹配和图像检索的任务中。它用于验证初步匹配的图像特征点是否在几何上是一致的,从而减少错误匹配。具体来说,几何验证涉及以下几个步骤:
特征点检测和描述:在图像中检测并描述关键特征点(如SIFT、SURF、ORB等特征点)。初步匹配:使用特征描述符在不同图像之间进行初步匹配,找到潜在的对应关系。几何约束应用:应用几何约束(如单应矩阵、基础矩阵)来验证初步匹配的特征点是否符合几何一致性。例如,单应矩阵可以用于平面上的特征匹配,而基础矩阵适用于立体视觉中的特征匹配。鲁棒估计方法:使用鲁棒估计方法(如RANSAC)来估计几何变换模型并剔除离群点,保留那些符合几何模型的匹配点。
几何验证的目的是确保匹配点不仅在描述符空间内接近,而且在图像几何结构上也是合理的。这对于提高图像匹配和图像检索的准确性非常重要,特别是在存在噪声或遮挡的情况下。
Q2:image registration
图像配准(Image Registration)是计算机视觉和图像处理中的一项关键技术,用于将两张或多张图像对齐到同一个坐标系。这个过程在医学影像分析、遥感图像处理、图像拼接和视频稳定等领域有广泛应用。
图像配准的步骤通常包括:
特征提取:
在图像中提取显著的特征点或特征区域。这些特征可以是角点(如Harris角点检测器)、边缘(如Canny边缘检测器)、区域(如SIFT、SURF特征)等。
特征匹配:
在两张图像中找到对应的特征点对。这一步可以通过特征描述符(如SIFT、SURF、ORB)来实现,并使用匹配算法(如最近邻匹配)来找到最佳匹配对。
变换模型估计:
根据匹配的特征点对,估计从一个图像到另一个图像的变换模型。常见的变换模型包括仿射变换、刚性变换、透视变换等。可以使用如RANSAC等鲁棒估计方法来排除错误匹配并估计最佳的变换参数。
图像变换和重采样:
应用估计的变换模型,将一个图像变换到另一个图像的坐标系中。这一步涉及图像的重采样和插值,以生成对齐后的图像。
配准验证:
通过视觉检查或计算配准后的图像差异,验证配准的效果。对于医学图像,可能还会计算定量指标(如互信息、均方误差)来评估配准质量。
具体的配准方法可以根据应用场景的不同而有所变化。
3.5.2 对应搜索
对于对应搜索,它从特征提取和匹配开始。从匹配中估计出两视图几何,包括基本矩阵、本质矩阵和单应性。排除几何上不可行的匹配。(对应3.1节中的检测、匹配)

然后,类似于Sweeney等人对几何验证的图像对执行视图图校准。利用更新的相机内参,估计相对相机姿态。(对应3.1节中的相机参数校准,内参、外参)
Q1:view graph calibration是什么?
“View graph calibration” 是一个技术术语,主要用于计算机视觉、图像处理和计算机图形学领域。它指的是对多个视图(通常是相机拍摄的图像)进行几何校准,以确保这些视图之间的一致性和精确的空间关系。具体而言,这种校准过程通常包括以下几个步骤:
相机参数校准:确定相机的内参(如焦距、主点位置、畸变系数)和外参(相机在三维空间中的位置和方向)。特征点匹配:在不同视图中识别并匹配相同的特征点(如角点、边缘)。几何变换计算:基于特征点的匹配结果,计算视图之间的几何变换矩阵(如单应矩阵或本质矩阵)。误差优化:通过最小化重投影误差来优化相机参数和几何变换,使得匹配的特征点在不同视图中的投影位置尽可能一致。
这种校准的目的是为了在多视图系统中获取精确的三维信息,常用于立体视觉、运动捕捉、增强现实和机器人导航等应用场景。
Q2:Relative Pose Decomposition是什么?
相对姿态分解(Relative Pose Decomposition)是在计算机视觉和机器人领域中用来从两张图像中恢复相机之间的相对位置和姿态(位置和方向)的过程。具体来说,这个过程涉及以下步骤:
特征点检测和匹配:在两张图像中检测特征点,并找到它们之间的匹配对。基础矩阵计算:利用匹配的特征点对计算基础矩阵(Fundamental Matrix),它描述了两张图像之间的几何关系。本质矩阵估计:通过基础矩阵和相机内参(内参数矩阵)估计本质矩阵(Essential Matrix)。本质矩阵用于去除相机内参的影响,只保留相机间的相对姿态信息。相对姿态分解:从本质矩阵中分解出相对旋转矩阵(R)和平移向量(t),这两者共同描述了相机之间的相对姿态。
分解本质矩阵时,会得到四组可能的解,需要通过进一步的验证(如对三维点进行重建和投影检查)来确定唯一的正确解。
具体步骤如下:
计算基础矩阵:基于特征匹配点,用如RANSAC算法来估计基础矩阵,排除错误匹配。估计本质矩阵:使用相机的内参矩阵(K),通过公式 �=����E=KTFK 计算本质矩阵。分解本质矩阵:从本质矩阵 �E 中分解出相对旋转 �R 和相对平移 �t,通常通过奇异值分解(SVD)来实现。
3.5.3全局估计
至于全局估计,全局旋转通过平均[14]来估计,并且不一致的相对姿态通过对Rij和RjR i之间的角距离进行阈值化来过滤。(对应3.2节)
然后,相机和点的位置联合估计通过全局定位,其次是全局光束法平差(BA)。(对应3.2节的联合全局三角测量和相机位置估计)

可选地,可以通过结构细化来进一步提高重建的准确性。在该步骤中,利用估计的相机姿态对点进行重新三角化,并且执行多轮全局光束法平差。相机聚类也可以应用于实现相干重建。
4.part of Experiments
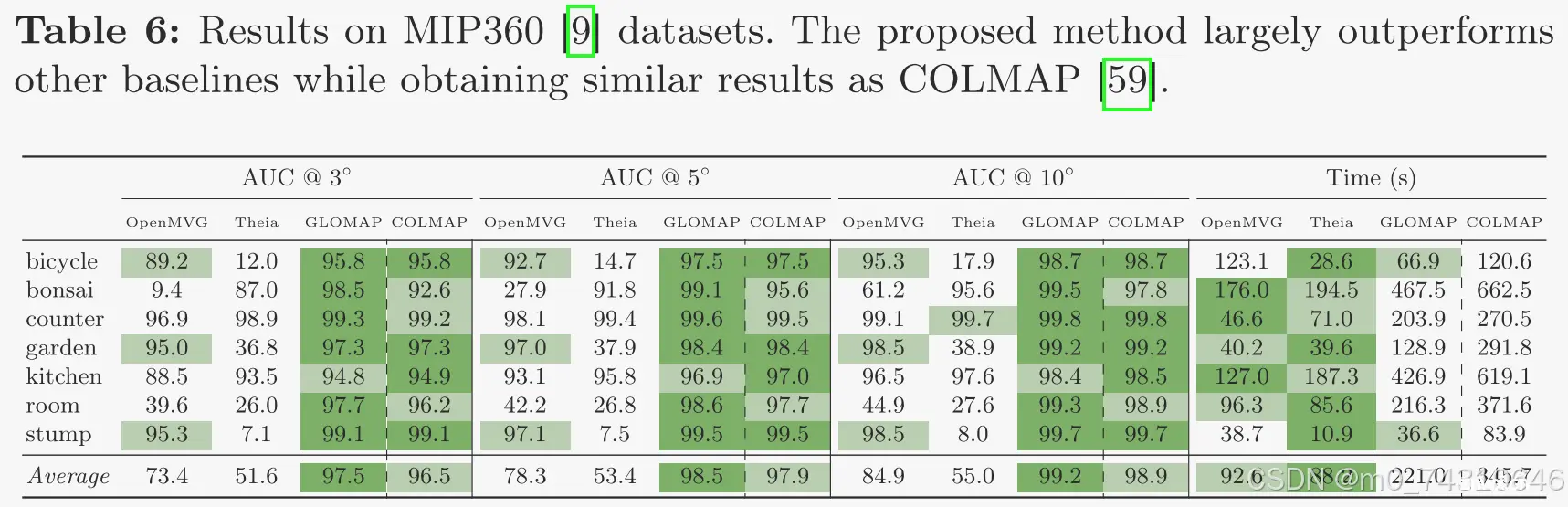
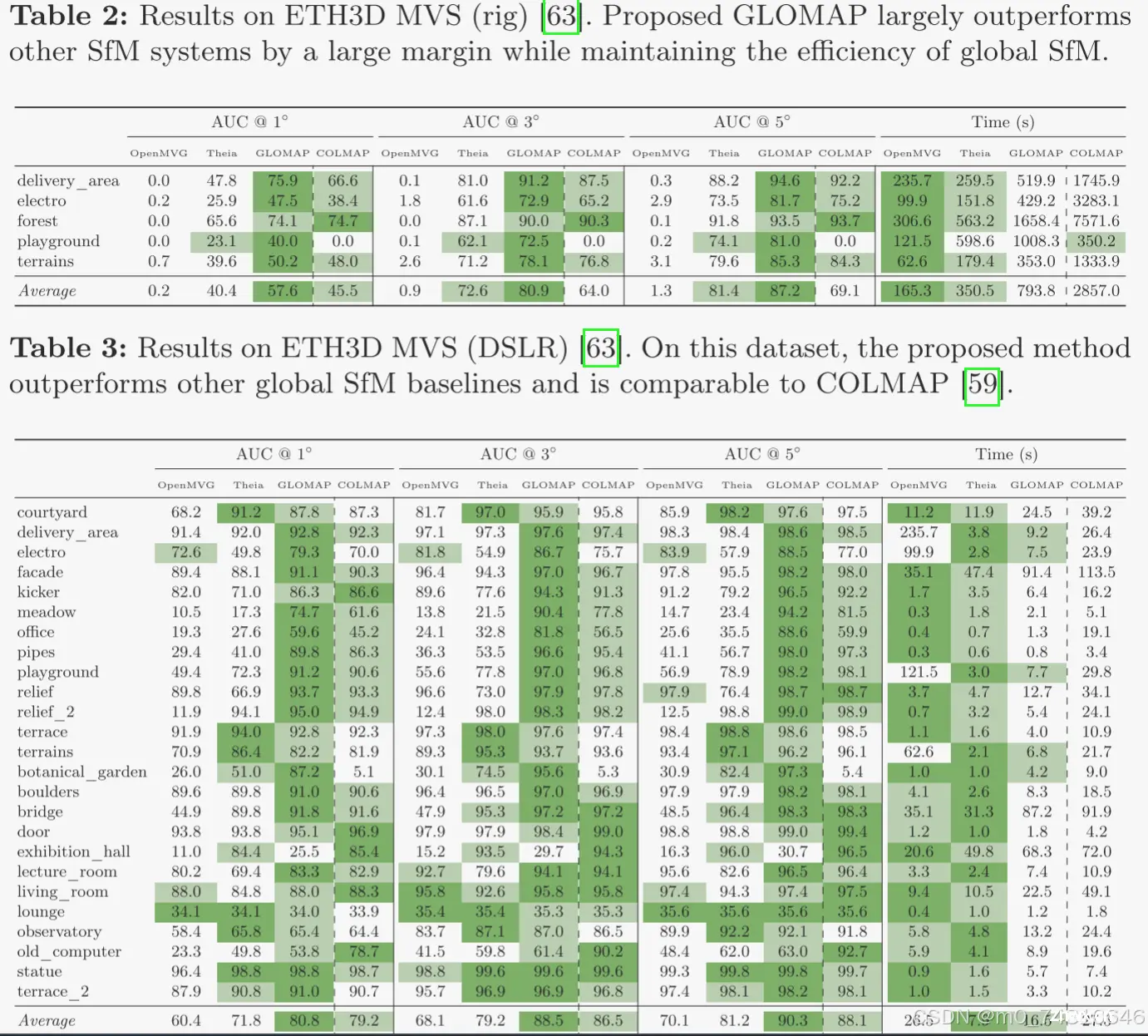
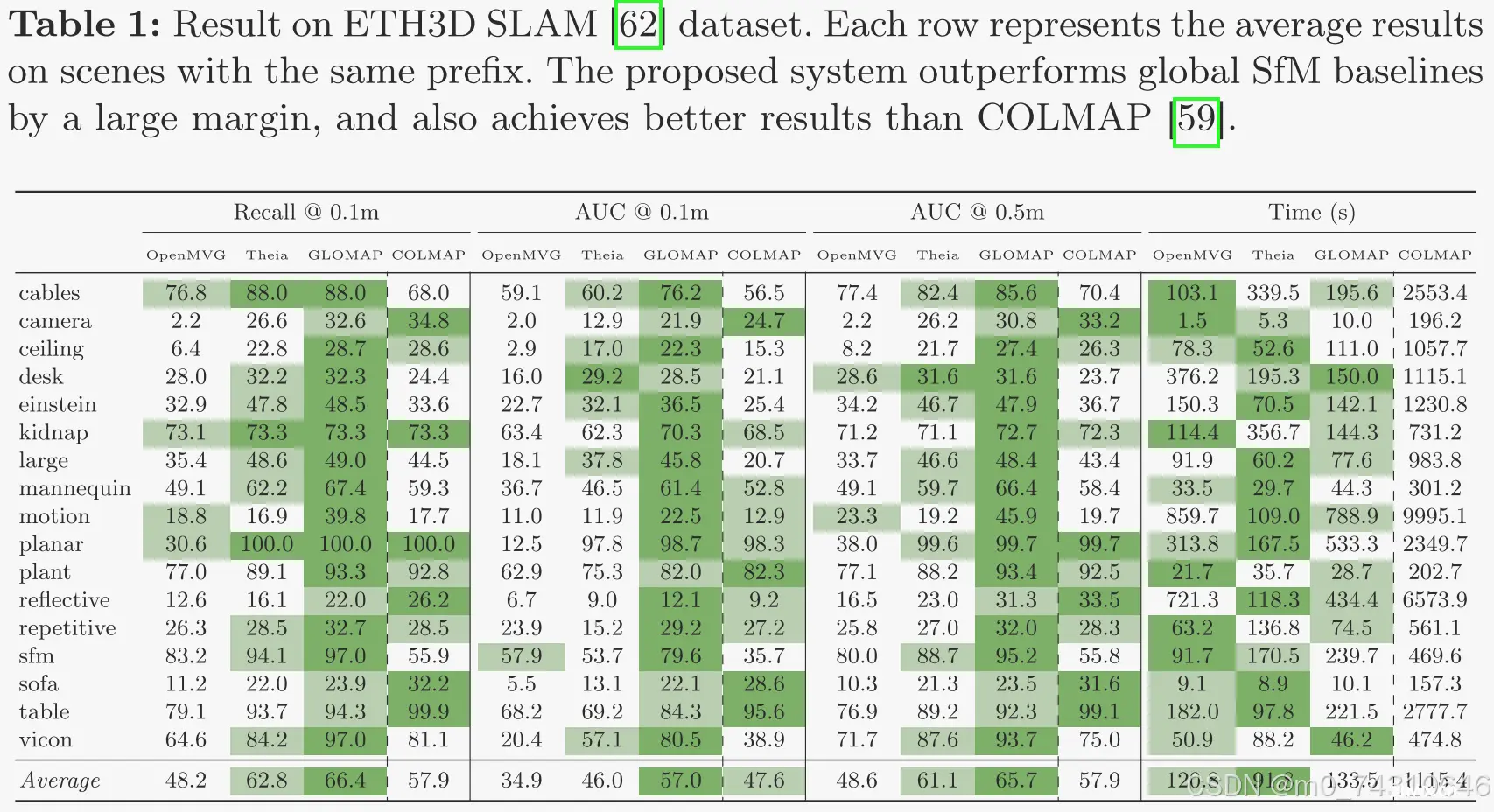
ETH3D SLAM数据集上的表现:

ETH3D MVS (rig)和ETH3D MVS (DSLR)的表现:

IMC 2023、MIP360
Limitations
虽然总体上取得了令人满意的性能,但仍然存在一些失败的情况。主要原因是旋转平均失败,例如,由于对称结构(见表3中的Exhibition_Hall)。在这种情况下,我们的方法可以与现有的方法(如Doppelganger [11])相结合。此外,由于我们依赖于传统的对应搜索,错误估计的两视图几何形状或无法完全匹配图像对(例如,由于剧烈的外观或视点变化)将导致降级的结果,或者在最坏的情况下,导致灾难性的故障。
5. Conclusion
我们提出了GLOMAP作为一个新的全局SfM管道。这一类以前的系统被认为比增量方法更有效,但不太可靠。我们重新审视了这个问题,并得出结论,关键在于优化中的点的使用。而不是估计相机的位置,通过不适定的平移平均和单独获得3D结构从点三角测量,我们将它们合并到一个单一的全球定位步骤。在各种数据集上的大量实验表明,该系统在准确性和鲁棒性方面达到了与增量方法相当或上级的结果,同时速度快了几个数量级。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。