【Datawhale AI 夏令营2024--CV】深度学习入门
幽径微澜 2024-08-06 16:31:02 阅读 93
一、深度学习入门
1.全连接神经网络整体结构
输入层--->隐藏层(卷积+池化)--->全连接层--->输出层
2.全连接神经网络的结构单元
单元到整体--->基础模块--->model
(参数)x1--w11-->
x2--(权重)w12--> x1 * w11+x2 * w12+...+b1(求和) --->激活函数-->输出
b1(偏置)-->
神经元数学表达式:a=h(x1w11+x2w12+...+b1)
3.非线性激活函数
sigmoid激活函数
Tanh激活函数
relu激活函数
Leaky ReLU激活函数
4.神经网络的前向传播
全连接神经网络前向传播:(y=model(x))
a11=sigmoid(x1w11+x2w13+b1)
a12=sigmoid(x1w12+x2w14+b2)
a21=relu(a11w21+a12w22+b3)
y=a21
x:参数(图像/像素矩阵)
w:权重
b:偏置
sigmoid / relu:激活函数
a:神经元
w、b有一组最优的使y更接近于真实值
5.神经网络的损失函数
均方误差的损失函数:J(x)
回归问题<--->均方误差
精度上升,loss值下降
训练过程中,用**标签**和**模型** **前向传播**的结果计算误差得出**损失函数**,再利用**损失函数**进行**反向传播**(梯度下降法)更新**w**和**b**使损失函数的值越来越低(前向传播---计算误差---反向传播)
6.梯度下降法(反向传播)
梯度下降是一种优化算法,用于最小化函数。
梯度下降算法基于这样一个原理:损失函数的梯度指向函数增长最快的方向。
在训练循环中,我们首先加载一小批量数据,将其输入到神经网络中进行前向传播,计算出网络的输出。
然后,我们使用损失函数来计算当前批次的损失,并通过反向传播算法计算损失函数关于每个参数的梯度。
这些梯度告诉我们如何调整权重和偏置以减少损失。
当数据集非常大时,一次性处理所有数据可能会导致内存不足或计算过于缓慢。
通过将数据分成小批量,我们可以更频繁地更新模型参数,这使得训练过程更加高效。

二、常见网络
VGG16
1.特点:
vgg-block内的卷积层都是同结构的
池化层都得上一层的卷积层特征缩减一半
深度较深,参数量够大
较小的filter size/kernel size
2.卷积神经网络的基本组成部分:
(1)带填充以保持分辨率的卷积层
(2)非线性激活函数,如RuLU
(3)池化层、最大池化层
3. 网络参数:
第一个vgg block层:
(1)输入为224* 224 *3,卷积核数量为64个;卷积核尺寸大小为3 * 3 * 3;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为224 * 224 * 64的特征图输出
(2)输入为224* 224 *64,卷积核数量为64个;卷积核尺寸大小为3 * 3 * 64;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为224 * 224 * 64的特征图输出
(3)输入为224* 224 *64,池化核为2 * 2,步幅为2(stride=2)后得到的尺寸为112 * 112 * 64的池化层的特征图输出
第二个vgg block层:
(1)输入为112 * 112 * 64,卷积核数量为128个;卷积核尺寸大小为3 * 3 * 64;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为112 * 112 * 128的特征图输出
(2)输入为112 * 112 * 128,卷积核数量为128个;卷积核尺寸大小为3 * 3 * 128;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为112 * 112 * 128的特征图输出
(3)输入为112 * 112 * 128,池化核为2 * 2,步幅为2(stride=2)后得到的尺寸为56 * 56 * 128的池化层的特征图输出
第三个vgg block层:
(1)输入为56 * 56 * 128,卷积核数量为256个;卷积核尺寸大小为3 * 3 * 128;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为56 * 56 * 256的特征图输出
(2)输入为56 * 56 * 256,卷积核数量为256个;卷积核尺寸大小为3 * 3 * 256;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为56 * 56 * 256的特征图输出
(3)输入为56 * 56 * 256,卷积核数量为256个;卷积核尺寸大小为3 * 3 * 256;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为56 * 56 * 256的特征图输出
(4)输入为56 * 56 * 256,池化核为2 * 2,步幅为2(stride=2)后得到的尺寸为28 * 28 * 256的池化层的特征图输出
第四个vgg block层:
(1)输入为28 * 28 * 256,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 256;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为28 * 28 * 512的特征图输出
(2)输入为28 * 28 * 512,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 512;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为28 * 28 * 512的特征图输出
(3)输入为28 * 28 * 512,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 512;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为28 * 28 * 512的特征图输出
(4)输入为28 * 28 * 512,池化核为2 * 2,步幅为2(stride=2)后得到的尺寸为14 * 14 * 512的池化层的特征图输出
第五个vgg block层:
(1)输入为14 * 14 * 512,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 512;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为14 * 14 * 512的特征图输出
(2)输入为14 * 14 * 512,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 512;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为14 * 14 * 512的特征图输出
(3)输入为14 * 14 * 512,卷积核数量为512个;卷积核尺寸大小为3 * 3 * 512;步幅为1(stride=1),填充为1(padding=1);卷积后得到的shape为14 * 14 * 512的特征图输出
(4)输入为14 * 14 * 512,池化核为2 * 2,步幅为2(stride=2)后得到的尺寸为7 * 7 * 512的池化层的特征图输出.该层后面还隐藏了flatten操作,通过展平得到7 * 7 * 512=25088个参数后与之后的全连接层相连
第1-3层全连接层:
第1-3层神经元个数分别为4096,4096,1000.其中前两层再使用ReLU后还使用了Dropout对神经元随机失活,最后一层全连接层使用softmax输出1000个分类
LeNet
1. LeNet-5
LeNet-5:5层神经网络(!池化不算一层)
研究目的:手写数字识别
2.组成
特征提取部分:由两个卷积层和两个池化层组成
全连接层:由三个全连接层组成
模型单元结构:一个卷积层、一个sigmoid激活函数、一个池化层
x ---> cnn + sigmoid + pool
数据的传输:
卷积层输入为四维的数据(B,C,W,H)
卷积层输出为思维的数据(B,C,FW,FH)
全连接层的输入为二维数据(B,L)
全连接层的输出为二维数据(B,FL)
展平操作:W * H * 数量(竖着一列)
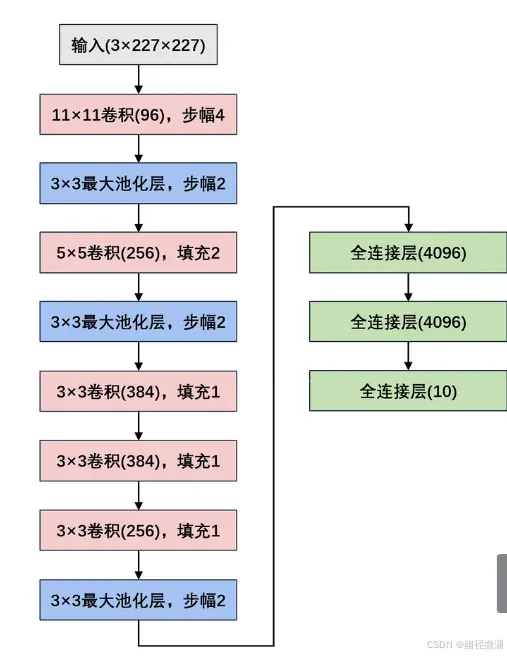
AlexNet
1.网络结构
和LeNet的设计理念非常相似,但 AlexNet比相对较小的LeNet深
由八层组成:五个卷积层、两个全连接隐藏层、一个全连接输出层
使用ReLU激活函数
2.网络参数
三、模型训练
学习了大佬的:https://www.kaggle.com/code/amywucn/vit-head1000-epoch100-0-48/notebook?scriptVersionId=187845119
1、训练数据加载器 (train_loader):
FFDIDataset 是一个自定义的数据集类,用于加载训练数据。train_label['path'].head(1000) 提供了训练数据的文件路径,train_label['target'].head(1000) 提供了对应的标签。transforms.Compose([...]) 创建了一个数据预处理管道,包括将图像调整大小为 (256, 256),随机水平翻转和垂直翻转,将图像转换为张量,以及归一化到特定的均值和标准差。batch_size=40 指定了每个批次的样本数为 40。shuffle=True 表示每个 epoch 开始时是否对数据进行洗牌。num_workers=4 指定用于数据加载的线程数。pin_memory=True 如果设置为 True,将数据置于固定内存中,可加快数据传输到 GPU 的速度。
train_loader = torch.utils.data.DataLoader(
FFDIDataset(train_label['path'].head(1000), train_label['target'].head(1000),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=40, shuffle=True, num_workers=4, pin_memory=True
)
2、验证数据加载器 (val_loader):
类似地,val_loader 加载验证数据集。val_label['path'].head(1000) 和 val_label['target'].head(1000) 提供了验证数据的文件路径和标签。这里只进行了大小调整、转换为张量和归一化操作,没有应用随机翻转。
val_loader = torch.utils.data.DataLoader(
FFDIDataset(val_label['path'].head(1000), val_label['target'].head(1000),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=40, shuffle=False, num_workers=4, pin_memory=True
)
3、损失函数和优化器
使用交叉熵损失函数,适用于多类别分类任务。.cuda() 方法将损失函数移动到 GPU 上进行计算。
使用 Adam 优化器,学习率为 0.005,优化模型的参数 model.parameters()。
# 损失函数
criterion = nn.CrossEntropyLoss().cuda()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), 0.005)
4、学习率调度器
设置了一个学习率调度器 StepLR,每 4 个 epoch 降低学习率,降低率为当前学习率乘以 gamma=0.85。
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.85)
best_acc = 0.0
5、 训练循环
开始一个循环,训练模型和评估模型的性能。scheduler.step() 每个 epoch 调用一次学习率调度器,更新优化器的学习率。train(train_loader, model, criterion, optimizer, epoch) 是一个自定义的训练函数,用于训练模型。validate(val_loader, model, criterion) 是一个自定义的验证函数,用于评估模型在验证集上的性能。如果当前 epoch 的验证准确率 val_acc 超过了之前记录的最佳准确率 best_acc,则更新 best_acc,并保存当前模型的参数到文件 ./model_{best_acc}.pt。
for epoch in range(100):
scheduler.step()
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_acc = validate(val_loader, model, criterion)
if val_acc.avg.item() > best_acc:
best_acc = round(val_acc.avg.item(), 2)
torch.save(model.state_dict(), f'./model_{best_acc}.pt')
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。