江湖救急:MinerU安装宝典,AI侠客必备
OpenDataLab 2024-08-27 10:31:04 阅读 68
江湖传言,有一款名为MinerU的神器,能将繁复的PDF秘籍转化为易懂的AI“心法”。(MinerU完整功能介绍,点击查看:登顶GitHub Trending,开源工具MinerU助力复杂PDF高效解析提取)众多侠客摩拳擦掌,势必掌握这项能力。然而,第一步安装成了不少人的最大难关。
“我要崩溃了,MinerU安装不成功怎么办?”
“magic-pdf.json文件没有找到,是为什么”
……
正当众侠客困惑之际,一位老侠客悠然开口:“少侠莫慌,虽MinerU威力无穷,然其安装之术,亦有章可依。”他轻轻翻开崭新的《MinerU 0.7.0版本安装宝典》,以轻松的姿态,一一化解了这些难题。让我们跟随这位老侠客的指引,一起驾驭这款神器吧。

🚀0.7.0版本亮点速览
最新发布的 MinerU 0.7.0 b1版本,简化安装步骤提升易用性,同时加入了Beta版(测试版)表格识别功能。
易用性方面:
● 优化依赖包版本兼容性,减少30%依赖包数量,提升全平台安装成功率。
● 增加主流环境支持说明,提供对主流平台设备的最佳兼容性。
● 安装流程兼顾海外和国内用户,提升安装体验。
● 增加Win/Linux 使用cuda的逐步详细文档。
CLI优化:
● 简化 cli 命令,支持批量处理
MinerU 更新啦!易用性拉满,最新亮点速览
🚀快速开始
一、MinerU支持3种不同方式体验其效果,可按需选择
1. 在线简易体验(无需任何安装)
2. 使用CPU快速体验(Windows,Linux,Mac)
3. 使用GPU高效处理(Linux/Windows + CUDA)
二、本地安装,软硬件环境说明
为获得最佳的性能表现和最少的兼容性问题,最佳推荐的系统配置如下:
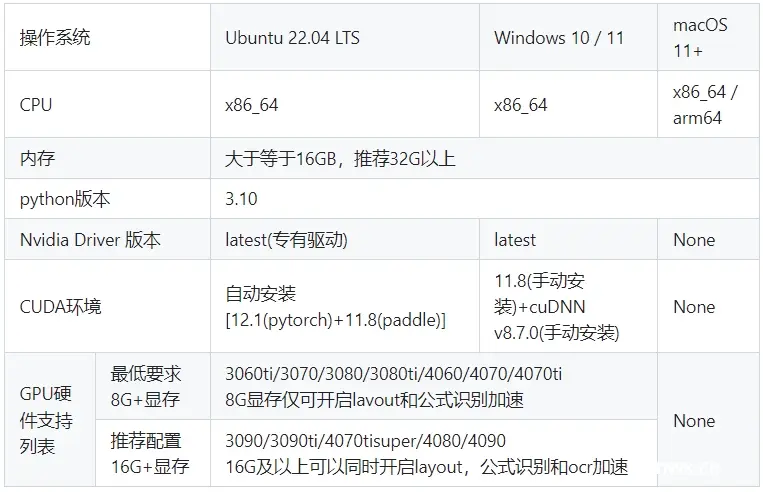
(其他非主线环境中,由于硬件、软件配置的多样性,以及第三方依赖项的兼容性问题,我们无法100%保证项目的完全可用性。因团队资源及人力有限,目前重点聚焦解决潜在BUG及新功能开发,因此,对于希望在非推荐环境中使用本项目的用户,我们建议先仔细阅读文档以及FAQ,大多数问题已经在FAQ中有对应的解决方案,除此之外我们鼓励社区反馈问题,以便我们能够逐步扩大支持范围。)
三、MinerU安装方式及要点
1. 在线简易体验
无需任何安装,浏览器访问,登录使用。
MinerU demo 地址:https://opendatalab.com/OpenSourceTools/Extractor/PDF
2. 使用CPU快速体验,安装步骤(Windows,Linux,Mac)
a.创建Conda环境并安装包
创建Conda环境后,安装magic-pdf 0.7.0b1版本,最新版本国内镜像源同步可能会有延迟,请耐心等待。
<code>conda create -n MinerU python=3.10conda activate MinerUpip install magic-pdf[full]==0.7.0b1 --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
(左右滑动查看)
b. 下载模型权重文件
使用Git LFS或SDK 从 Hugging Face 或 Model Scope 下载模型;务必检查模型目录是否完整,通过sha256校验下载的模型文件大小是否与网页一致;完成后移动模型到固态硬盘(将 models 目录移动到具有较大磁盘空间的目录中,最好是在固态硬盘(SSD)上)。
c. 拷贝配置文件并进行配置
在系统的【用户目录】下创建文件 magic-pdf.json,将下方 magic-pdf.template.json 配置模版文件中的内容拷贝进去,并修改模型权重所在位置。
(其中,models-dir 字段为模型权重存储绝对路径;bucket_info 字段仅是S3服务时需要修改配置;如果使用CPU的话,device-mode 字段设置为cpu,使用GPU的话,初始运行后再修改为cuda;另外 MinerU 0.7.0版本发布了Beta版表格识别功能,即 table-config 字段,但默认是关闭的,如需使用,可修改 false 值为 true,不过当前表格识别功能效果一般,仍在调试中,效果更好的版本将在后续重点发布,敬请期待)
{ "bucket_info":{ "bucket-name-1":["ak", "sk", "endpoint"], "bucket-name-2":["ak", "sk", "endpoint"] }, "models-dir":"/tmp/models", "device-mode":"cpu", "table-config": { "is_table_recog_enable": false, "max_time": 400 }}
❗️务必执行以下命令将配置文件拷贝到【用户目录】下,否则程序将无法运行
windows的用户目录为 'C:\Users\用户名', linux用户目录为 'home/用户名', macOS用户目录为 '/Users/用户名'
❗️ 配置 'models-dir'为模型文件的下载存储的绝对路径,避免程序找不到模型文件而导致无法运行;windows系统中此路径应包含盘符,且需把路径中所有的"\"替换为"/",否则会因为转义原因导致json文件语法错误。
cp magic-pdf.template.json ~/magic-pdf.json
3. GPU加速攻略
不同操作系统的GPU加速指令及更详细的教程,请访问:
● Ubuntu22.04LTS + GPU
https://github.com/opendatalab/MinerU/blob/master/docs/README_Ubuntu_CUDA_Acceleration_zh_CN.md
● Windows10/11 + GPU
https://github.com/opendatalab/MinerU/blob/master/docs/README_Windows_CUDA_Acceleration_zh_CN.md
四、MinerU安装之后的使用方法
本地安装MinerU后,我们提供了命令行语句、python接口调用代码2种不同使用方式参考,以满足本地文件处理及二次开发服务等不同场景需求:
1. 命令行
首先运行 magic-pdf pdf-command --help ,看一下这个命令行有哪些参数:
magic-pdf --help
Usage: magic-pdf [OPTIONS]
Options:
-v, --version 显示版本并退出
-p, --path PATH 本地 pdf 文件路径或目录 [required]
-o, --output-dir TEXT 输出本地目录
-m, --method [ocr|txt|auto] 指定解析方法:ocr: 光学识别解析PDF,txt: 文本型PDF解析方法,auto: 程序智能选择解析方法.
如果没有指定方法,则默认使用auto.
--help 显示此消息并退出.
然后调用即可运行:
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto
其中 {some_pdf} 可以是单个pdf文件,也可以是一个包含多个pdf文件目录的路径,方便批量文件处理。运行完命令后输出的结果会保存在{some_output_dir}目录下, 输出的文件列表如下:
├── some_pdf.md # markdown 文件
├── images # 存放图片目录
├── layout.pdf # layout 绘图
├── middle.json # minerU 中间处理结果
├── model.json # 模型推理结果
├── origin.pdf # 原 pdf 文件
└── spans.pdf # 最小粒度的bbox位置信息绘图
最终输出文件,详细参数说明:
https://github.com/opendatalab/MinerU/blob/master/docs/output_file_zh_cn.md
2. 通过API接口(Python代码开发)调用参考
处理本地磁盘上的文件,代码样例:
image_writer = DiskReaderWriter(local_image_dir)
image_dir = str(os.path.basename(local_image_dir))
jso_useful_key = {"_pdf_type": "", "model_list": []}
pipe = UNIPipe(pdf_bytes, jso_useful_key, image_writer)
pipe.pipe_classify()
pipe.pipe_analyze()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")code>
处理对象存储上的文件,代码样例:
s3pdf_cli = S3ReaderWriter(pdf_ak, pdf_sk, pdf_endpoint)
image_dir = "s3://img_bucket/"
s3image_cli = S3ReaderWriter(img_ak, img_sk, img_endpoint, parent_path=image_dir)
pdf_bytes = s3pdf_cli.read(s3_pdf_path, mode=s3pdf_cli.MODE_BIN)
jso_useful_key = {"_pdf_type": "", "model_list": []}
pipe = UNIPipe(pdf_bytes, jso_useful_key, s3image_cli)
pipe.pipe_classify()
pipe.pipe_analyze()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")code>
更全面的 Python 代码参考:
● 最简单的处理方式(demo.py):https://github.com/opendatalab/MinerU/blob/master/demo/demo.py
● 能够更清晰看到处理流程(magic_pdf_parse_main.py):https://github.com/opendatalab/MinerU/blob/master/demo/magic_pdf_parse_main.py
五、一些局限性说明
MinerU是一款将PDF转化为机器可读格式的开源工具(如markdown、json),它诞生于书生-浦语的预训练过程中,在科技文献中的文字、符号转化方面已经取得相对不错的效果。但因为它很年轻,还在成长中,目前仍有一些局限性,同步给你:
● 阅读顺序基于规则的分割,在一些情况下会乱序
● 不支持竖排文字
● 列表、代码块、目录在layout模型里还没有支持
● 漫画书、艺术图册、小学教材、习题尚不能很好解析
● 在一些公式密集的PDF上强制启用OCR效果会更好,如果您要处理包含大量公式的pdf,强烈建议开启OCR功能
● 使用pymuPDF提取文字的时候会出现文本行互相重叠的情况导致公式插入位置不准确。
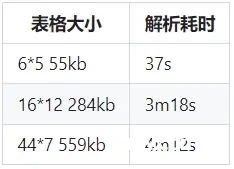
● 表格识别目前处于测试阶段,识别速度较慢,识别准确度有待提升。以下是我们在Ubuntu 22.04 LTS + Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz + NVIDIA GeForce RTX 4090环境下的一些性能测试结果,可供参考。
如果你在使用过程中,遇到问题或者结果不及预期可以到Github提交 issue,同时附上相关PDF,同步我们以便后续迭代功能。
你还有哪些需求?欢迎填写问卷,我们将综合大家的反馈,优先开发,你的意见对我们十分重要!务必填写一下问卷~https://www.wjx.cn/vm/etyOYsJ.aspx
更多MinerU信息,详见
MinerU Github仓库主页:https://github.com/opendatalab/MinerU
MinerU常见问题解答FAQ:https://github.com/opendatalab/MinerU/blob/master/docs/FAQ_zh_cn.md
开源数据处理宝藏工具,尽在 OpenDataLab GitHub仓库:https://github.com/opendatalab
还有超好用的多模态标注工具 LabelU:https://github.com/opendatalab/labelU
多模态对话标注管理平台Label-LLM:https://github.com/opendatalab/LabelLLM
不要吝啬你的star!

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。