将 LLMs 精调至 1.58 比特: 使极端量化变简单
cnblogs 2024-09-30 08:13:00 阅读 74
随着大语言模型 (LLMs) 规模和复杂性的增长,寻找减少它们的计算和能耗的方法已成为一个关键挑战。一种流行的解决方案是量化,其中参数的精度从标准的 16 位浮点 (FP16) 或 32 位浮点 (FP32) 降低到 8 位或 4 位等低位格式。虽然这种方法显著减少了内存使用量并加快了计算速度,但往往以准确性为代价。过度降低精度可能导致模型丢失关键信息,从而导致性能下降。
BitNet 是一种特殊的 transformers 架构,它用仅三个值: <code>(-1, 0, 1) 表示每个参数,提供了每个参数仅为 1.58 $ (log_2(3)) $ 比特的极端量化。然而,这需要从头开始训练一个模型。虽然结果令人印象深刻,但并非每个人都有预算来进行大语言模型的预训练。为了克服这一限制,我们探索了一些技巧,允许将现有模型精调至 1.58 比特!继续阅读以了解更多!
目录
- <li>简介
- 更深入地了解什么是 BitNet
- 1.58 比特的预训练结果
- 1.58 比特的微调
- 使用的内核和测试标准
- 结论
- 致谢
- 更多资源
简介
BitNet 是由微软研究院提出的一种模型架构,其采用极端量化的方式,用仅三个值 -1、0 和 1 来表示每个参数。这导致模型每个参数仅使用 1.58 比特,显著降低了计算和内存需求。
该架构在执行矩阵乘法时使用 INT8 加法计算,这与以 Llama 为例的传统 LLM 架构的 FP16 乘加操作完全不同。
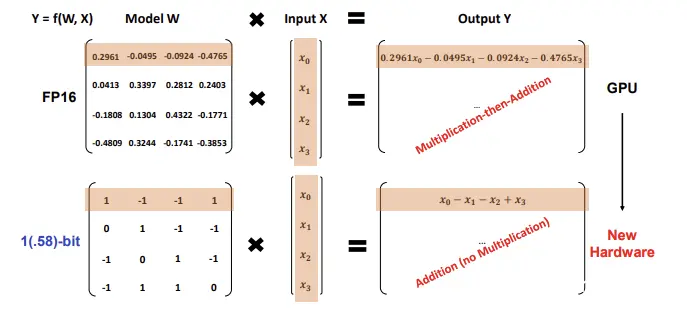
BitNet b1.58 的新计算范式 (出处: BitNet 论文 https://arxiv.org/abs/2402.17764)
这种方法在理论上降低能耗,与 Llama 基准相比,BitNet b1.58 在矩阵乘法方面节省了 71.4 倍的计算能耗。
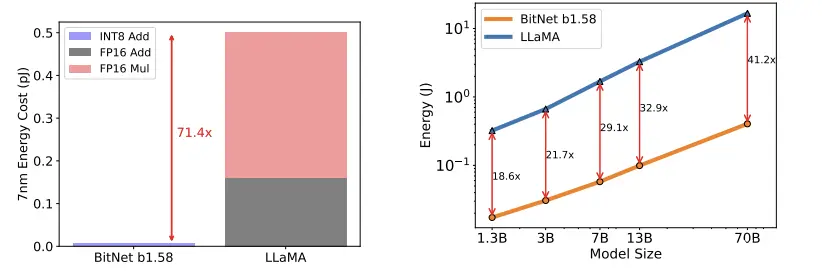
BitNet b1.58 与 Llama 的能耗对比 (出处: BitNet 论文 https://arxiv.org/abs/2402.17764)
我们成功地使用 BitNet 架构对 Llama3 8B model 模型进行了精调,在下游任务中取得了良好的性能。我们开发的 8B 模型由 HF1BitLLM 组织发布。其中两个模型在 10B 的 token 上进行了不同的训练设置的微调,而第三个模型在 100B 的 token 上进行了微调。值得注意的是,我们的模型在 MMLU 基准测试中超越了 Llama 1 7B 模型。
如何在 Transformers 中使用
为了将 BitNet 架构集成到 Transformers 中,我们引入了一种名为 “bitnet” 的新量化方法 (PR)。该方法涉及将标准的 Linear 层替换为专门设计用于 BitNet 架构的 BitLinear 层,其实现了相应的动态的激活量化、权重解包和矩阵乘法的操作。
在 Transformers 中加载和测试模型非常简单,API 没有任何更改:
<code>model = AutoModelForCausalLM.from_pretrained(
"HF1BitLLM/Llama3-8B-1.58-100B-tokens",
device_map="cuda",code>
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
input_text = "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:"
input_ids = tokenizer.encode(input_text, return_tensors="pt").cuda()code>
output = model.generate(input_ids, max_new_tokens=10)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
通过这段代码,一切都直接在幕后完美地完成了,因此无需担心额外的复杂性,您只需要做的只是安装最新版本的 transformers。
要快速测试模型,请查看这个 notebook。
更深入地了解什么是 BitNet
BitNet 在多头注意力和前馈网络中替换了传统的 Linear 层,使用了称为 BitLinear 的特殊层,这些层使用三值精度 (甚至在初始版本中使用二值精度)。在这个项目中,我们使用的 BitLinear 层对权重使用三值精度 (取值为 -1、0 和 1),并将激活量化为 8 位精度。我们在训练和推理中使用不同的 BitLinear 实现,接下来的部分将会介绍。
在三值精度训练中的主要障碍是权重值被离散化 (通过 round() 函数),因此不可微分。BitLinear 通过一个巧妙的技巧解决了这个问题: STE (Straight Through Estimator)。STE 允许梯度通过不可微分的取整操作,通过将其梯度近似为 1 (将 round() 视为等同于恒等函数) 来实现。另一种观点是,STE 让梯度通过取整步骤,好像取整从未发生过一样,从而使用标准基于梯度的优化技术来更新权重。
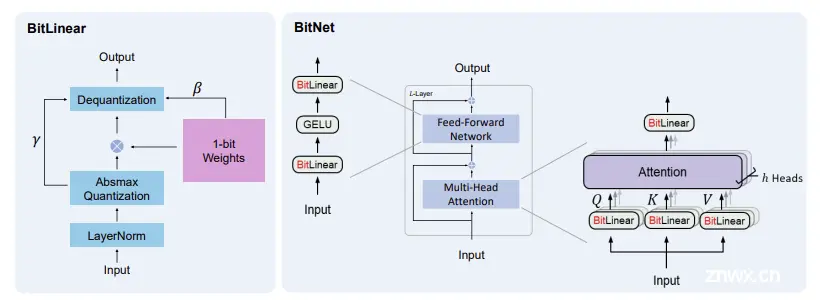
使用 BitLienar 的 BitNet 模型架构 (出处: BitNet 论文 https://arxiv.org/pdf/2310.11453)
训练
我们在完整精度下进行训练,但在训练过程中将权重量化为三值,使用 per-tensor 的对称量化。首先,我们计算权重矩阵的绝对值的平均值,并将其用作 scale。然后,我们将权重除以 scale,对值进行取整,将其限制在 -1 和 1 的区间内,最后将权重其反量化回完整精度。
\[scale_w = \frac{1}{\frac{1}{nm} \sum_{ij} |W_{ij}|}
\]
\[W_q = \text{clamp}_{[-1,1]}(\text{round}(W*scale))
\]
\[W_{dequantized} = W_q*scale_w
\]
激活然后被量化为指定的比特宽度 (在我们的情况下是 8 位),使用 per-token 的最大绝对值量化 (要了解量化方法的全面介绍,请查看这篇 post)。这涉及将激活缩放到 [-128, 127] 的范围以适应 8 位比特宽度。量化公式如下:
\[scale_x = \frac{127}{|X|_{\text{max}, , \text{dim}=-1}}
\]
\[X_q = \text{clamp}_{[-128,127]}(\text{round}(X*scale))
\]
\[X_{dequantized} = X_q * scale_x
\]
为了使这些公式更加清晰,下面是一些使用 3x3 的矩阵的权重和激活量化的例子:
例子 1: 权重矩阵量化
假设权重矩阵 $ W $为:
\[W = \begin{bmatrix}
0.8 & -0.5 & 1.2 \\
-1.5 & 0.4 & -0.9 \\
1.3 & -0.7 & 0.2
\end{bmatrix}
\]
第一步: 计算权重的 scale
使用公式:
k
\[scale_w = \frac{1}{\frac{1}{nm} \sum_{ij} |W_{ij}|}
\]
我们计算 $ W $ 激活值的平均值:
\[\frac{1}{nm} \sum_{ij} |W_{ij}| = \frac{1}{9}(0.8 + 0.5 + 1.2 + 1.5 + 0.4 + 0.9 + 1.3 + 0.7 + 0.2) = \frac{1}{9}(7.5) = 0.8333
\]
现在得到的 scale 为:
\[scale_w = \frac{1}{0.8333} \approx 1.2
\]
第二步: 量化权重矩阵
使用公式:
\[W_q = \text{clamp}_{[-1, 1]}(\text{round}(W \times scale_w))
\]
我们首先将权重缩放 $ scale_w \approx 1.2 $ 倍:
\[W \times scale_w =
\begin{bmatrix}
0.8 \times 1.2 & -0.5 \times 1.2 & 1.2 \times 1.2 \\
-1.5 \times 1.2 & 0.4 \times 1.2 & -0.9 \times 1.2 \\
1.3 \times 1.2 & -0.7 \times 1.2 & 0.2 \times 1.2
\end{bmatrix}
\begin{bmatrix}
0.96 & -0.6 & 1.44 \\
-1.8 & 0.48 & -1.08 \\
1.56 & -0.84 & 0.24
\end{bmatrix}
\]
然后我们将其取整并截断到 $ [-1, 1] $ 的区间内:
\[W_q =
\begin{bmatrix}
1 & -1 & 1 \\
-1 & 0 & -1 \\
1 & -1 & 0
\end{bmatrix}
\]
第三步: 反量化权重
最后我们反量化该权重:
\[W_{dequantized} = W_q \times scale_w
\]
使用 scale_w 将权重恢复到原来的范围,我们可以得到:
\[W_{dequantized} =
\begin{bmatrix}
1 \times 1.2 & -1 \times 1.2 & 1 \times 1.2 \\
-1 \times 1.2 & 0 \times 1.2 & -1 \times 1.2 \\
1 \times 1.2 & -1 \times 1.2 & 0 \times 1.2
\end{bmatrix}
\begin{bmatrix}
1.2 & -1.2 & 1.2 \\
-1.2 & 0 & -1.2 \\
1.2 & -1.2 & 0
\end{bmatrix}
\]
例子 2: 激活矩阵的量化
假设激活矩阵 $ X $ 为:
\[X =
\begin{bmatrix}
1.0 & -0.6 & 0.7 \\
-0.9 & 0.4 & -1.2 \\
0.8 & -0.5 & 0.3
\end{bmatrix}
\]
第一步: 计算激活的 scale
对于每一行 (或者通道),计算其最大的绝对值
- <li>第 1 行: 最大绝对值 = 1.0
- 第 2 行: 最大绝对值 = 1.2
- 第 3 行: 最大绝对值 = 0.8
计算每行的 scale:
\[\text{scale} = \begin{bmatrix}
\frac{127}{1.0} \\
\frac{127}{1.2} \\
\frac{127}{0.8}
\end{bmatrix}
\begin{bmatrix}
127 \\
105.83 \\
158.75
\end{bmatrix}
\]
步骤 2: 量化激活矩阵
使用以下公式:
\[X_q = \text{clamp}_{[-128,127]}(\text{round}(X \times \text{scale}))
\]
缩放相应的激活值:
\[X \times \text{scale} =
\begin{bmatrix}
1.0 \times 127 & -0.6 \times 127 & 0.7 \times 127 \\
-0.9 \times 105.83 & 0.4 \times 105.83 & -1.2 \times 105.83 \\
0.8 \times 158.75 & -0.5 \times 158.75 & 0.3 \times 158.75
\end{bmatrix}
\begin{bmatrix}
127 & -76.2 & 88.9 \\
-95.2 & 42.3 & -127 \\
127 & -79.4 & 47.6
\end{bmatrix}
\]
将值取整并截断在 $ [-128, 127] $ 的范围内:
\[X_q =
\begin{bmatrix}
127 & -76 & 89 \\
-95 & 42 & -127 \\
127 & -79 & 48
\end{bmatrix}
\]
第三步: 反量化激活
最后我们反量化激活值:
\[X_{dequantized} = X_q \times \frac{1}{\text{scale}}
\]
使用 scale 对值进行恢复:
\[X_{dequantized} =
\begin{bmatrix}
127 \times \frac{1}{127} & -76 \times \frac{1}{127} & 89 \times \frac{1}{127} \\
-95 \times \frac{1}{105.83} & 42 \times \frac{1}{105.83} & -127 \times \frac{1}{105.83} \\
127 \times \frac{1}{158.75} & -79 \times \frac{1}{158.75} & 48 \times \frac{1}{158.75}
\end{bmatrix}
\begin{bmatrix}
1.0 & -0.6 & 0.7 \\
-0.9 & 0.4 & -1.2 \\
0.8 & -0.5 & 0.3
\end{bmatrix}
\]
我们在量化激活之前使用层归一化 (Layer Normalization,LN) 以保持输出的方差:
\[\text{LN}(x) = \frac{x - E(x)}{\sqrt{\text{Var}(x) + \epsilon}}
\]
这里 ε 是防止溢出的一个非常小的值
如前所述, <code>round() 函数是不可微分的。我们使用 detach() 作为一个技巧,在反向传播中实现可微分的 STE (Straight-Through Estimator):
# Adapted from https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf
import torch
import torch.nn as nn
import torch.nn.functional as F
def activation_quant(x):
scale = 127.0 / x.abs().max(dim=-1, keepdim=True).values.clamp_(min=1e-5)
y = (x * scale).round().clamp_(-128, 127) / scale
return y
def weight_quant(w):
scale = 1.0 / w.abs().mean().clamp_(min=1e-5)
u = (w * scale).round().clamp_(-1, 1) / scale
return u
class BitLinear(nn.Linear):
"""
Only for training
"""
def forward(self, x):
w = self.weight
x_norm = LN(x)
# A trick for implementing Straight−Through−Estimator (STE) using detach()
x_quant = x_norm + (activation_quant(x_norm) - x_norm).detach()
w_quant = w + (weight_quant(w) - w).detach()
# Perform quantized linear transformation
y = F.linear(x_quant, w_quant)
return y
推理
在推理过程中,我们只是将权重量化为三值,而不重新反量化。我们对激活采用相同的方法,使用 8 位精度,然后使用高效的算子执行矩阵乘法,接着通过权重和激活的 scale 进行除法。这能够显著提高推理的速度,特别是在优化的硬件上。您可以看到,在训练期间反量化的过程与推理不同,因为矩阵乘法保持在 fp16/bf16/fp32 中以进行正确的训练。
# Adapted from https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf
import torch
import torch.nn as nn
import torch.nn.functional as F
def activation_quant_inference(x):
x = LN(x)
scale = 127.0 / x.abs().max(dim=-1, keepdim=True).values.clamp_(min=1e-5)
y = (x * scale).round().clamp_(-128, 127)
return y, scale
class BitLinear(nn.Linear):
"""
Only for training
"""
def forward(self, x):
w = self.weight # weights here are already quantized to (-1, 0, 1)
w_scale = self.w_scale
x_quant, x_scale = activation_quant_inference(x)
y = efficient_kernel(x_quant, w) / w_scale / x_scale
return y
1.58 比特的预训练结果
在尝试微调之前,我们首先尝试复现 BitNet 论文中关于预训练的结果。我们使用了一个小数据集 tinystories,以及一个 Llama3 8B 模型。我们发现,像论文中所做的那样添加归一化函数会提高性能。例如,在训练 2000 步之后,我们在验证集上的困惑度,没有归一化时为 6.3,使用归一化后为 5.9。在这两种情况下,训练都是稳定的。
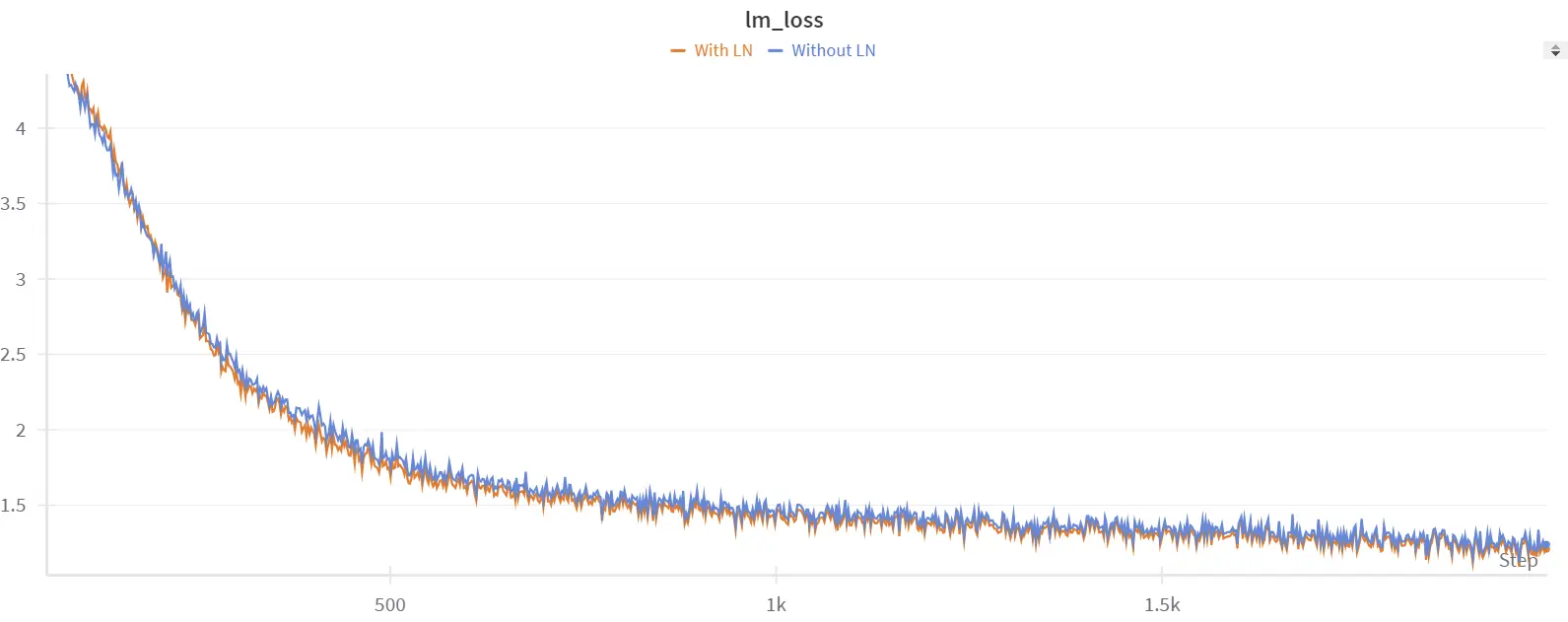
在有层归一化 (蓝色) 和没有 (橙色) 的预训练图像
虽然这种方法在预训练中看起来非常有趣,但只有少数机构能够负担大规模的预训练。然而,因为存在有大量强大的预训练模型,如果它们可以在预训练后转换为 1.58 位,将会非常有用。其他小组曾报告称,微调的结果不如预训练取得的结果那么强大,因此我们展开了研究,看看我们是否能够让 1.58 比特地微调起作用。
1.58 比特的微调
当我们从预训练的 Llama3 8B 权重开始微调时,模型表现略有提高,但并不如我们预期的那么好。
Note: 所有的实验都在 Nanotron 上进行,如果您对尝试 1.58 位的预训练或微调感兴趣,可以查看这个 PR 链接。
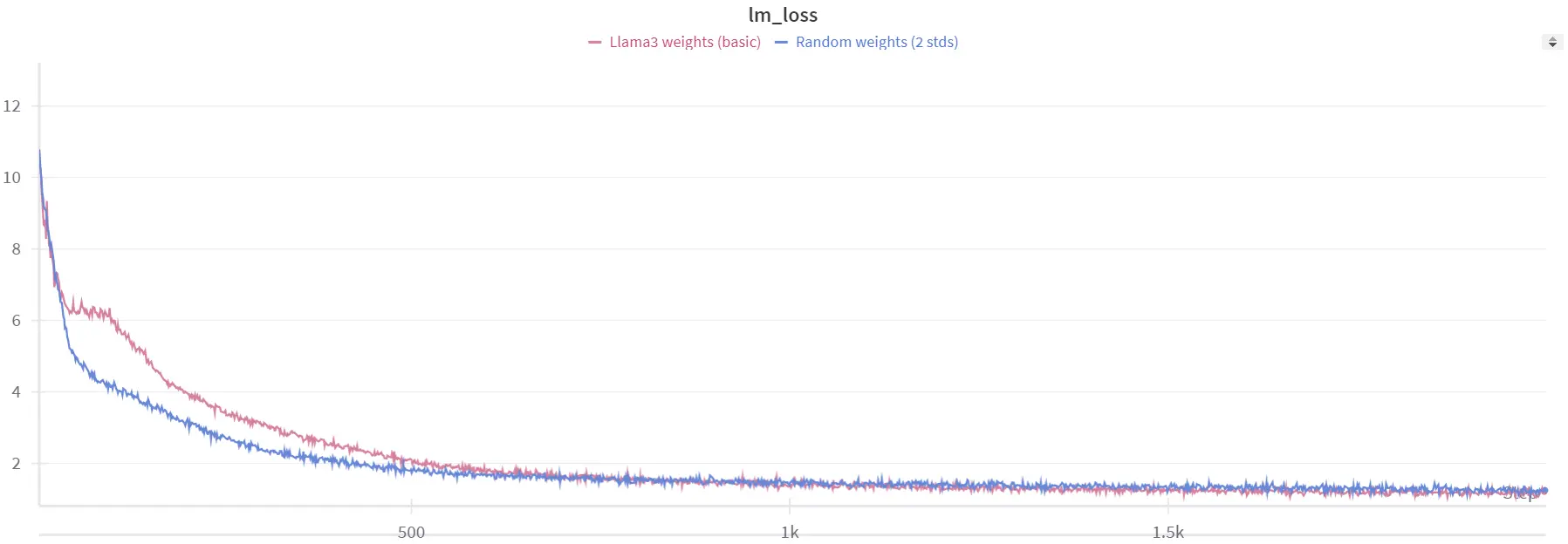
微调曲线对比预训练曲线
为了理解原因,我们尝试检查随机初始化模型和预训练模型的权重分布,以确定可能的问题。
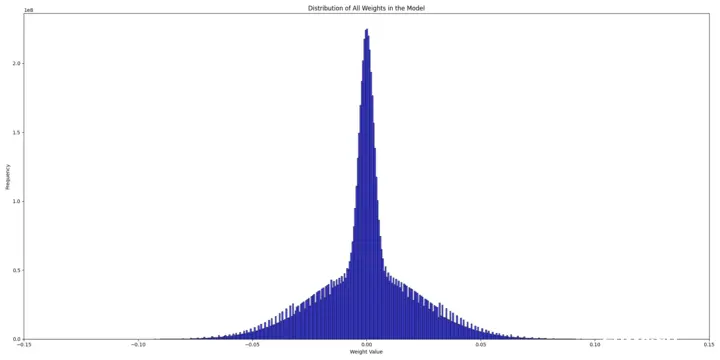
随机的权重分布 (合并的标准差为 2)
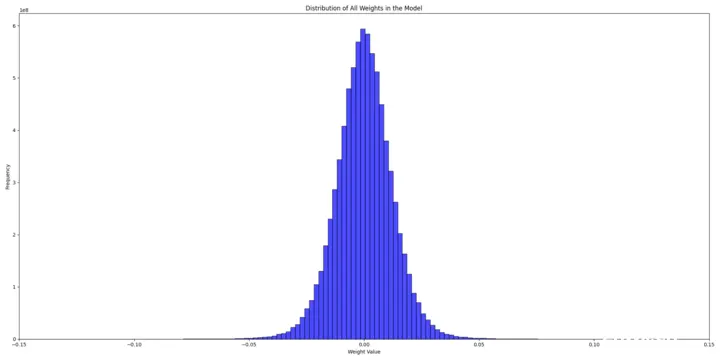
预训练 Llama3 的权重分布
两个分布的 scale 分别为:
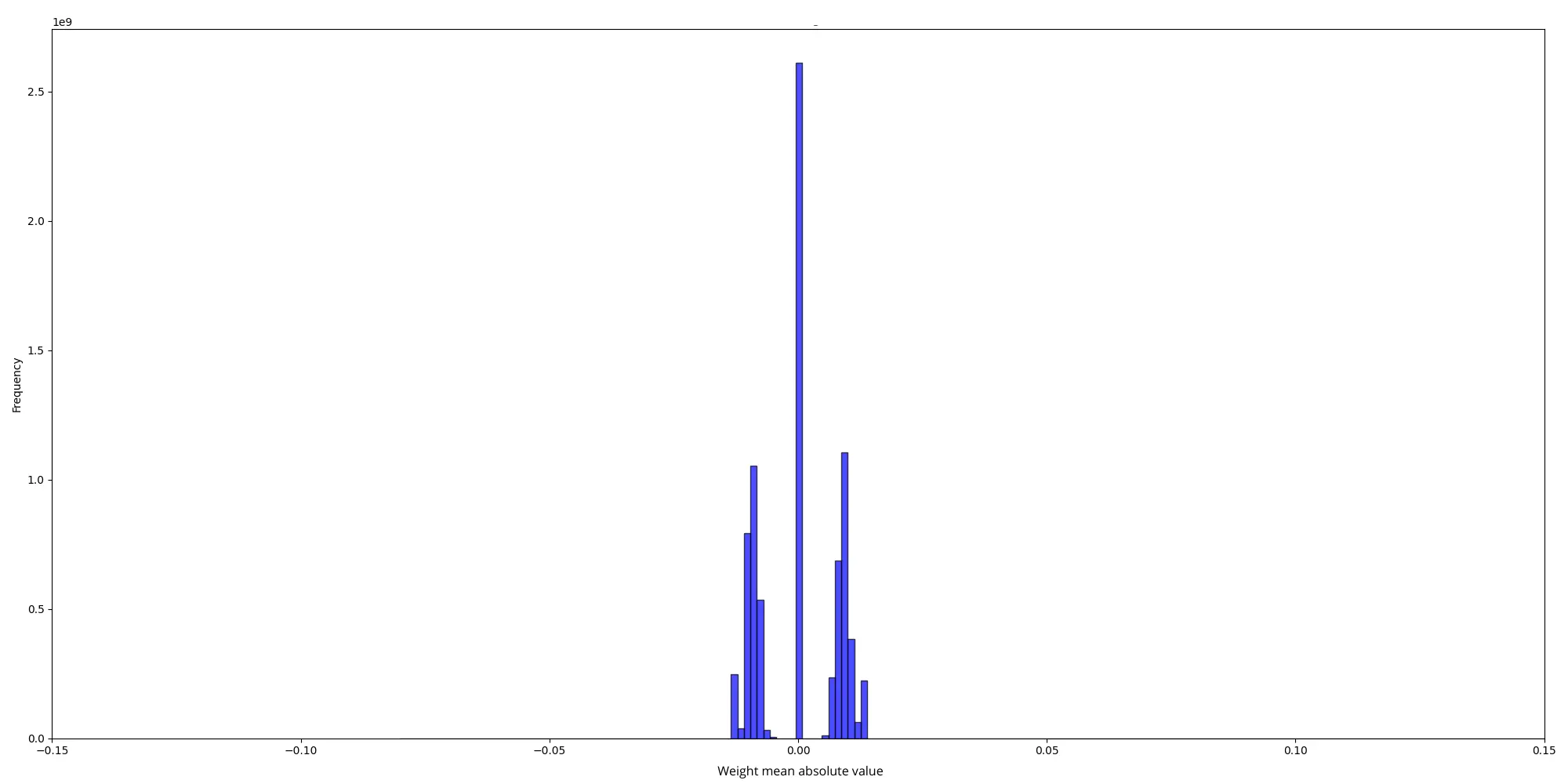
初始随机权重分布是两个正态分布的混合:
- <li>一个标准差为 $$ 0.025 $$
- 另一个标准差为 $$ \frac{0.025}{\sqrt{2 \cdot \text{num_hidden_layers}}} = 0.00325 $$
这是因为在 <code>nanotron 中对列线性权重和行线性权重使用了不同的标准差。在量化版本中,所有矩阵只有两个权重尺度 (50.25 和 402),这两个尺度分别是每个矩阵权重的绝对值的倒数的平均值: scale = 1.0 / w.abs().mean().clamp_(min=1e-5)
- <li>对于 $$\text{scale} = 50.25 $$,$$ w.abs().mean() = 0.0199 $$,导致 $$\text{std} = 0.025 $$,与我们的第一个标准差相匹配。用于推导标准差的公式基于 $$ |w| $$ 的半正态分布的期望:
\[\mathbb{E}(|w|) = \text{std}(w) \cdot \sqrt{\frac{2}{\pi}}
\]
- 对于 $$\text{scale} = 402 $$,$$ w.abs().mean() = 0.0025 $$,导致 $$\text{std} = 0.00325 $$
另一方面,预训练权重的分布看起来像是一个标准差为 $ 0.013 $ 的正态分布。
显然,预训练模型从更多信息 (scale) 开始,而随机初始化的模型从实际上没有信息开始,并随着时间逐渐增加信息。我们的结论是,从随机权重开始给予模型最小的初始信息,从而实现逐步学习过程,而在微调期间,引入 BitLinear 层会使模型丧失所有先前的信息。
为了改善微调结果,我们尝试了不同的技术。例如,我们尝试过使用 per-row 和 per-column 量化而不是 per-tensor 量化,以保留更多来自 Llama 3 权重的信息。我们还尝试改变尺度计算的方式: 不再仅仅将权重的平均绝对值作为尺度,而是将异常值 (超过 k 倍平均绝对值的值,其中 k 是我们在实验中尝试变化的常数) 的平均绝对值作为尺度,但我们并没有注意到明显的改善。
def scale_outliers(tensor, threshold_factor=1):
mean_absolute_value = torch.mean(torch.abs(tensor))
threshold = threshold_factor * mean_absolute_value
outliers = tensor[torch.abs(tensor) > threshold]
mean_outlier_value = torch.mean(torch.abs(outliers))
return mean_outlier_value
def weight_quant_scaling(w):
scale = 1.0 / scale_outliers(w).clamp_(min=1e-5)
quantized_weights = (w * scale).round().clamp_(-1, 1) / scale
return quantized_weights
我们观察到,随机权重和 Llama 3 权重在损失开始时的数值约为 13,这表明当引入量化时,Llama 3 模型失去了所有先前的信息。为了进一步研究模型在这个过程中失去了多少信息,我们尝试了 per-group 量化。
作为一个合理性检查,我们首先将 group 大小设置为 1,这基本上意味着没有量化。在这种情况下,损失从 1.45 开始,与正常微调时的情况相同。然而,当我们将组大小增加到 2 时,损失跳升到大约 11。这表明即使组大小最小为 2,模型仍几乎失去了所有信息。
为了解决这个问题,我们考虑逐渐引入量化而不是突然将其应用于每个张量的权重和激活。为了实现这一点,我们引入了一个 lambda 值来控制这个过程:
lambda_ = ?
x_quant = x + lambda_ *(activation_quant(x) - x).detach()
w_quant = w + lambda_ *(weight_quant(w) - w).detach()
当 lambda 设置为 0 是 , 实际上没有量化发生 , 当 lambda=1 时 , 将应用完全的量化 .
我们最初测试了一些离散的 lambda 值,比如 0.25、0.5、0.75 和 1。然而,这种方法并没有在结果上带来显著的改善,主要是因为 lambda=0.25 已经足够高,使损失开始得很高。
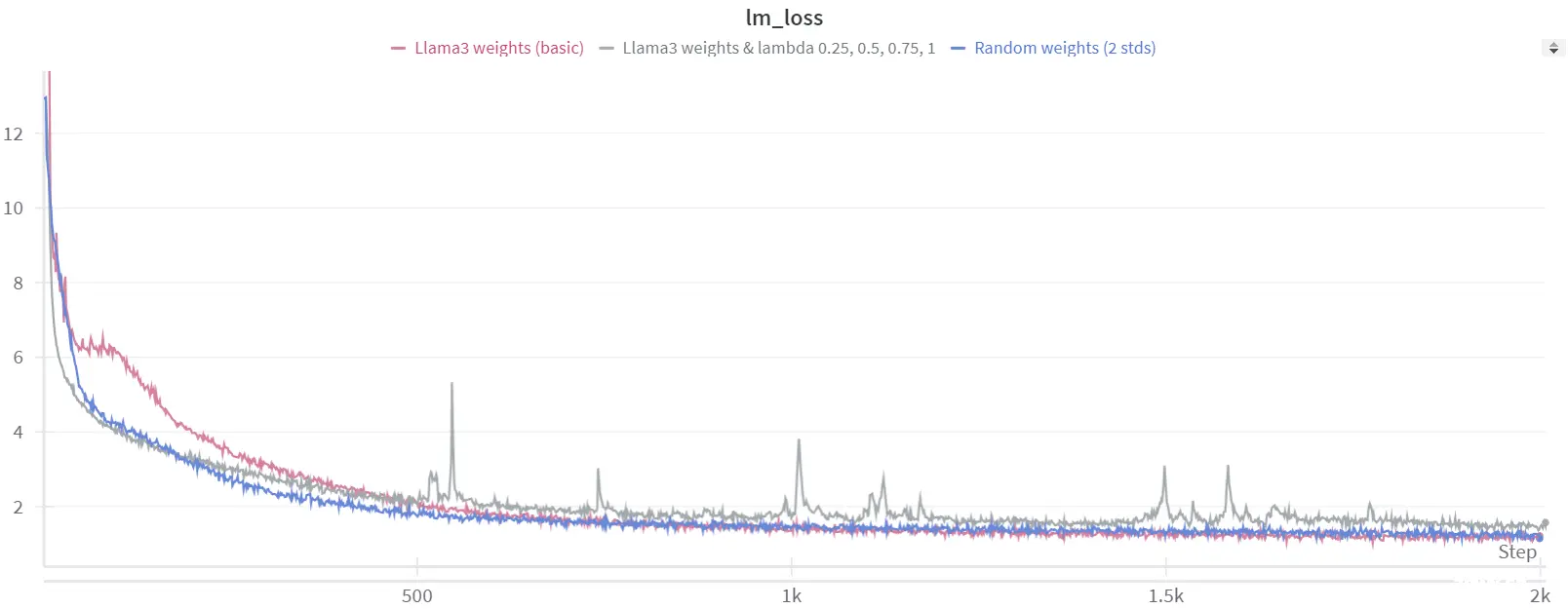
因此,我们决定尝试一个根据训练步骤动态调整的 <code>lambda 值。
使用这种动态的 lambda 值导致更好的损失收敛,但在推理过程中,当 lambda 设置为 1 时,困惑度 (perplexity 或者 ppl) 的结果仍然远非令人满意。我们意识到这很可能是因为模型在 lambda=1 的情况下还没有受过足够长时间的训练。为了解决这个问题,我们调整了我们的 lambda 值来改善训练过程。
lambda_ = min(2 * training_step / total_training_steps, 1)
在这种配置下,经过 2000 步之后,我们有:
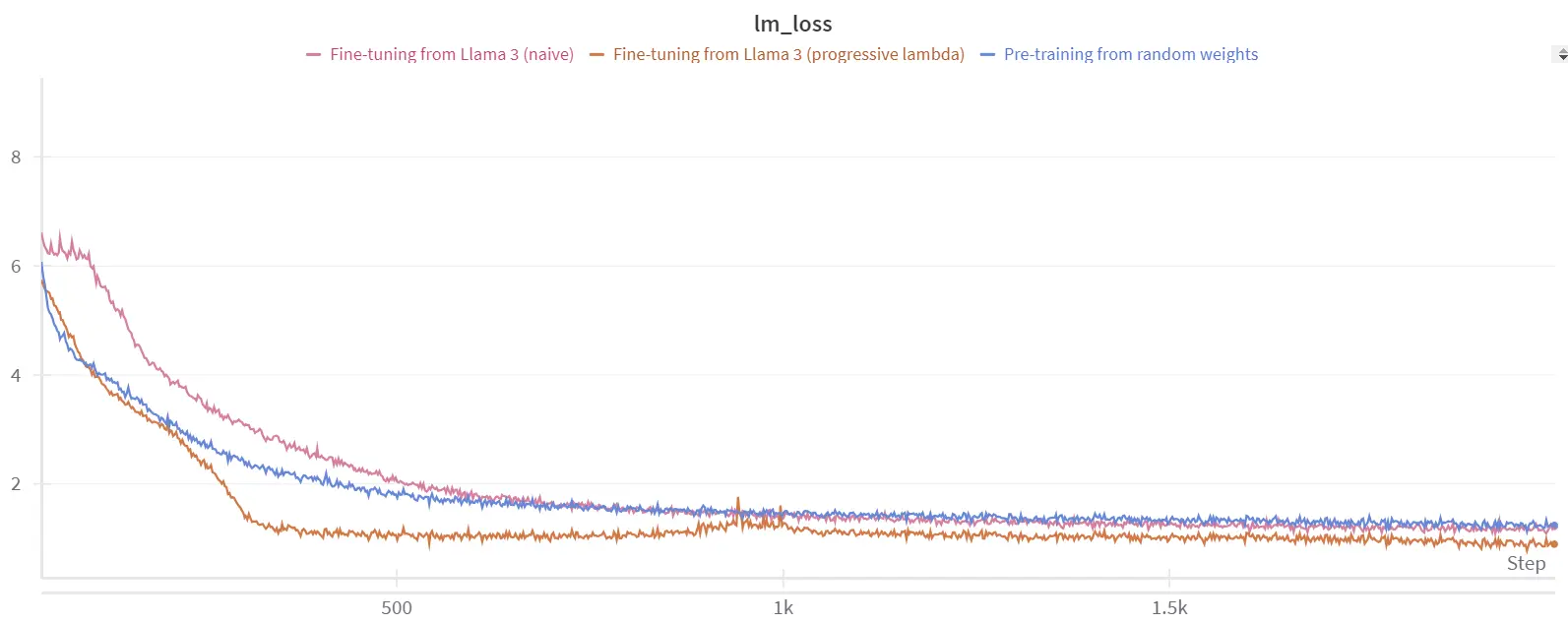
lambda = min(2*training_step/total_training_steps, 1) 时的微调图像
我们的微调方法整体上显示出更好的收敛性。你可以观察到在大约 1000 步时损失曲线略微增加,这对应于我们开始接近 <code>lambda=1 或完全量化的时候。然而,在这一点之后,损失立即开始再次收敛,导致困惑度约为 4,得到了改善。
尽管取得了进展,但当我们在 WikiText 数据集上测试量化模型 (而不是我们用于微调的 tinystories 数据集) 时,困惑度非常高。这表明在特定数据集上以低比特模式微调模型会导致其丧失大部分通用知识。这个问题可能是因为我们在三值权重中追求的最小表示在不同数据集之间可能会有显著差异。为解决这个问题,我们扩展了我们的训练过程,包括了更大的 FineWeb-edu 数据集。我们保持了一个 lambda 值为:
lambda_ = min(training_step/1000, 1)
我们选择了这个 lambda 值,因为它似乎是对模型进行 warmup 的一个很好的起点。然后,我们在 FineWeb-edu 数据集上使用学习率为 1e-4,训练了 5000 步。训练过程中使用了一个批量大小 (BS) 为 2B,总共训练了 10B 个 token。
找到合适的学习率和合适的衰减率是具有挑战性的; 这似乎是模型性能的一个关键因素。
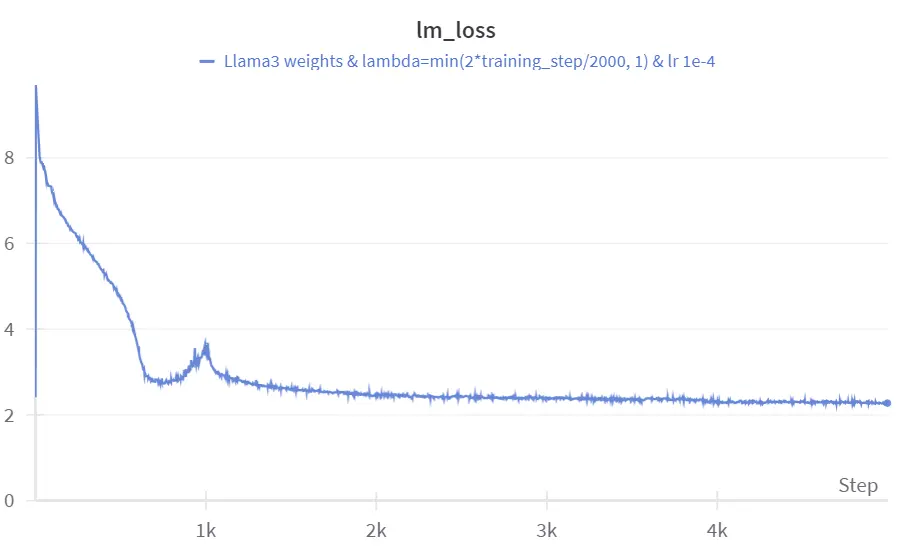
在 Fineweb-edu 上进行 warmup 量化时的微调图像
在 FineWeb-Edu 上微调后,在 WikiText 数据集上达到 12.2 的困惑度是相当令人印象深刻的,考虑到我们只使用了 100 亿个标记。其他评估指标也显示出了强大的性能,考虑到数据量有限 (请参见结果)。
尝试平滑 lambda 接近 1 时的急剧增加也是一个不错的想法。为了实现这一点,考虑使用 lambda 调度器,这些调度器在开始时呈指数增长,然后在接近 1 时趋于平稳。这种方法可以帮助模型更平稳地适应 lambda 值的变化,避免突然的波动。
<code>def scheduler(step, total_steps, k):
normalized_step = step / total_steps
return 1 - (1 - normalized_step)**k
对于不同的 k 值,总预热步数为 1,我们有如下图表:
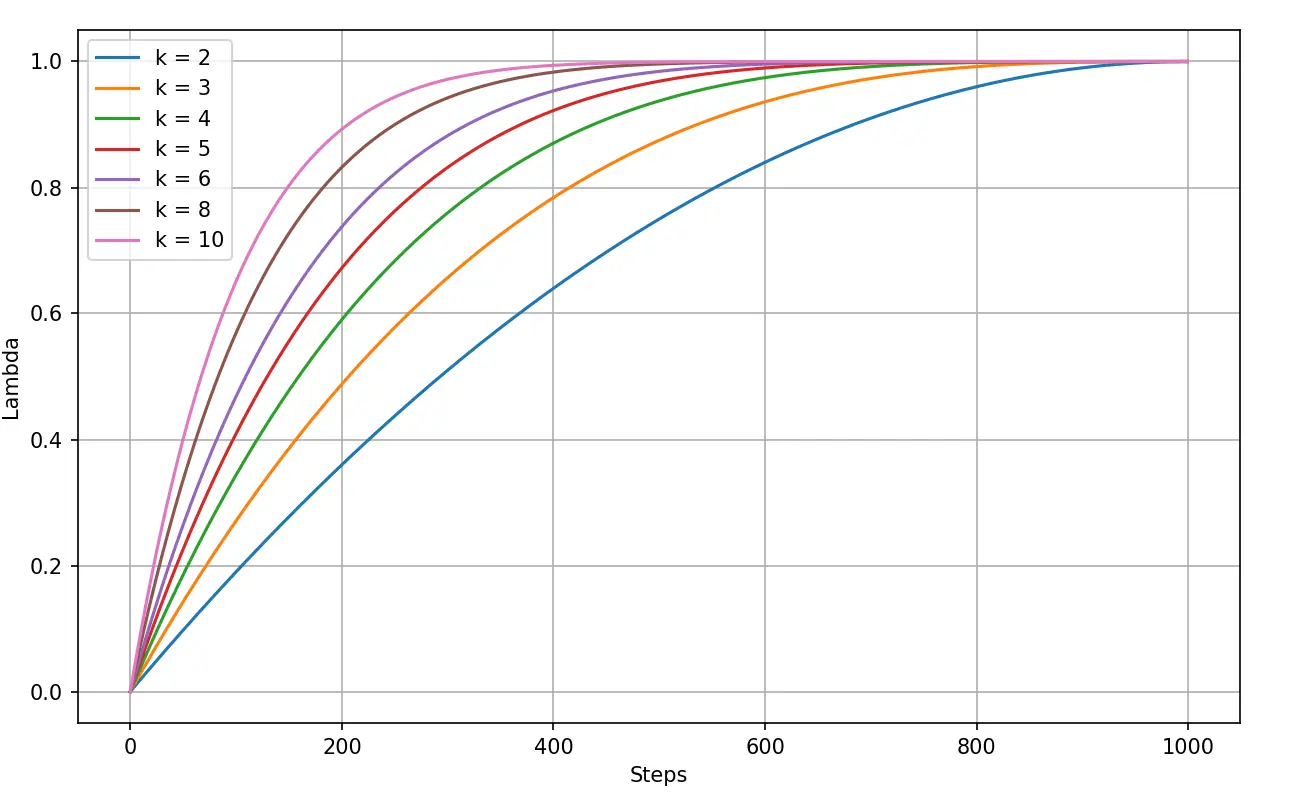
我们使用表现最好的学习率 1e-4 进行了 4 次实验 , 测试的 k 值分别为 4, 6, 8, 10.
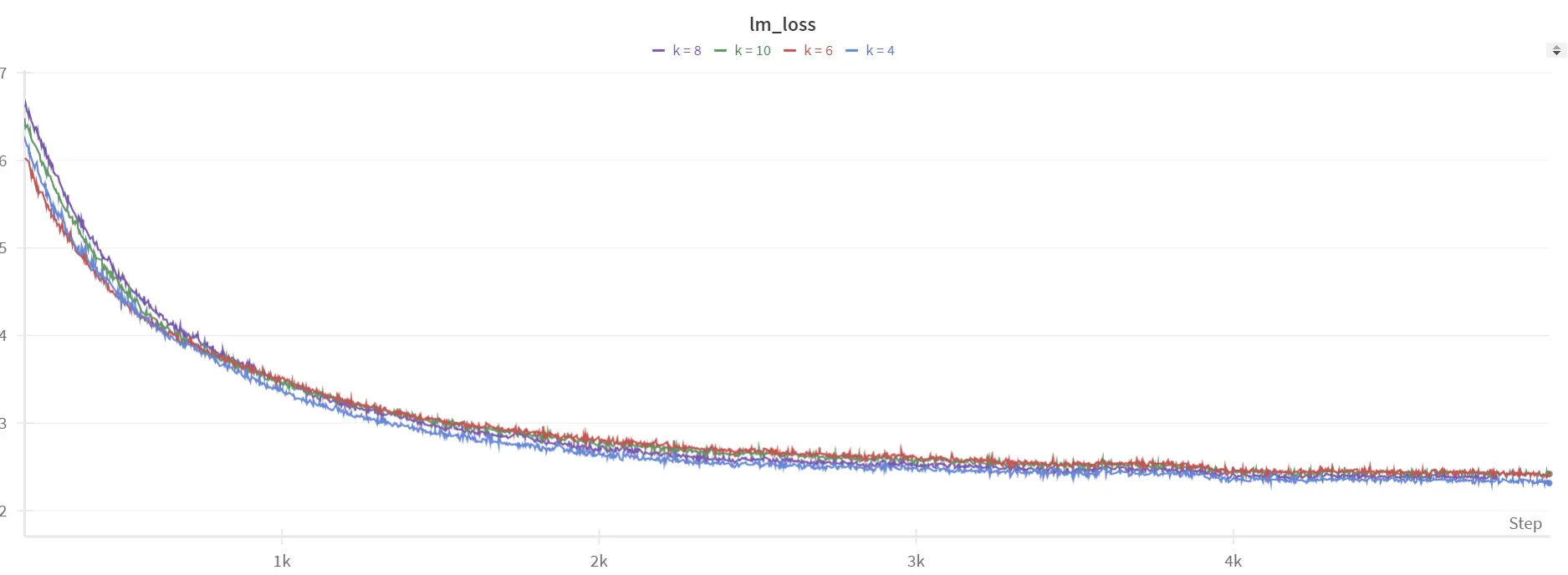
使用不同指数调度器时的微调图像
平滑效果很好,不像线性调度器那样出现尖峰。然而,困惑度并不理想,大约保持在 15 左右,对下游任务的表现也没有改善。
我们还注意到了开始时的尖峰,模型难以从中恢复。当 lambda = 0 时,基本上没有量化,所以损失开始很低,大约在 2 左右。但在第一步之后,出现了一个尖峰,类似于线性调度器的情况 (如上面的蓝色图表所示)。因此,我们尝试了另一种调度器即 Sigmoid 调度器,它开始缓慢上升,迅速上升到 1,然后在接近 1 时趋于稳定。
<code>def sigmoid_scheduler(step, total_steps, k):
# Sigmoid-like curve: slow start, fast middle, slow end
normalized_step = step / total_steps
return 1 / (1 + np.exp(-k *(normalized_step - 0.5)))
对于不同的 k 值有以下的曲线:
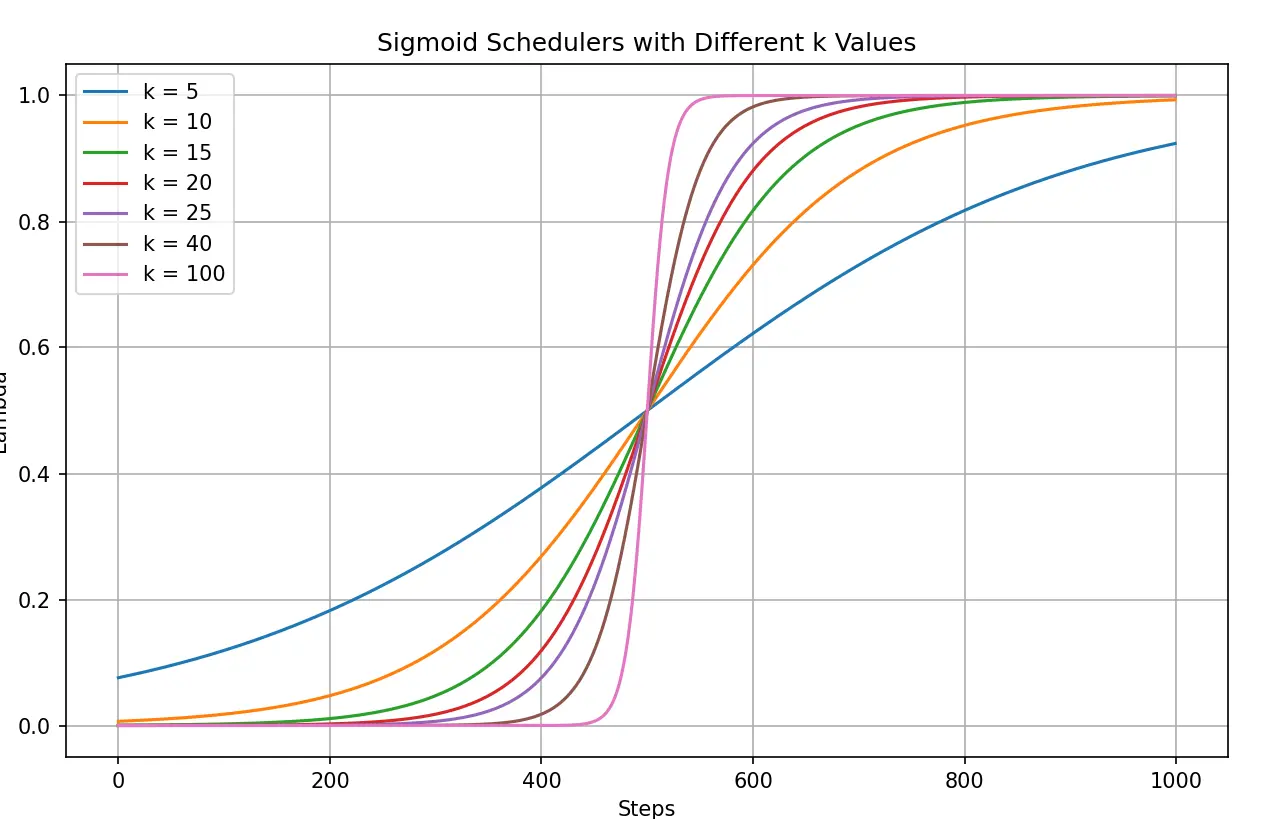
对于不同 k 值的 Sigmoid 调度器
我们这次在 k 为 15, 20, 25, 40 和 100 时进行了实验:
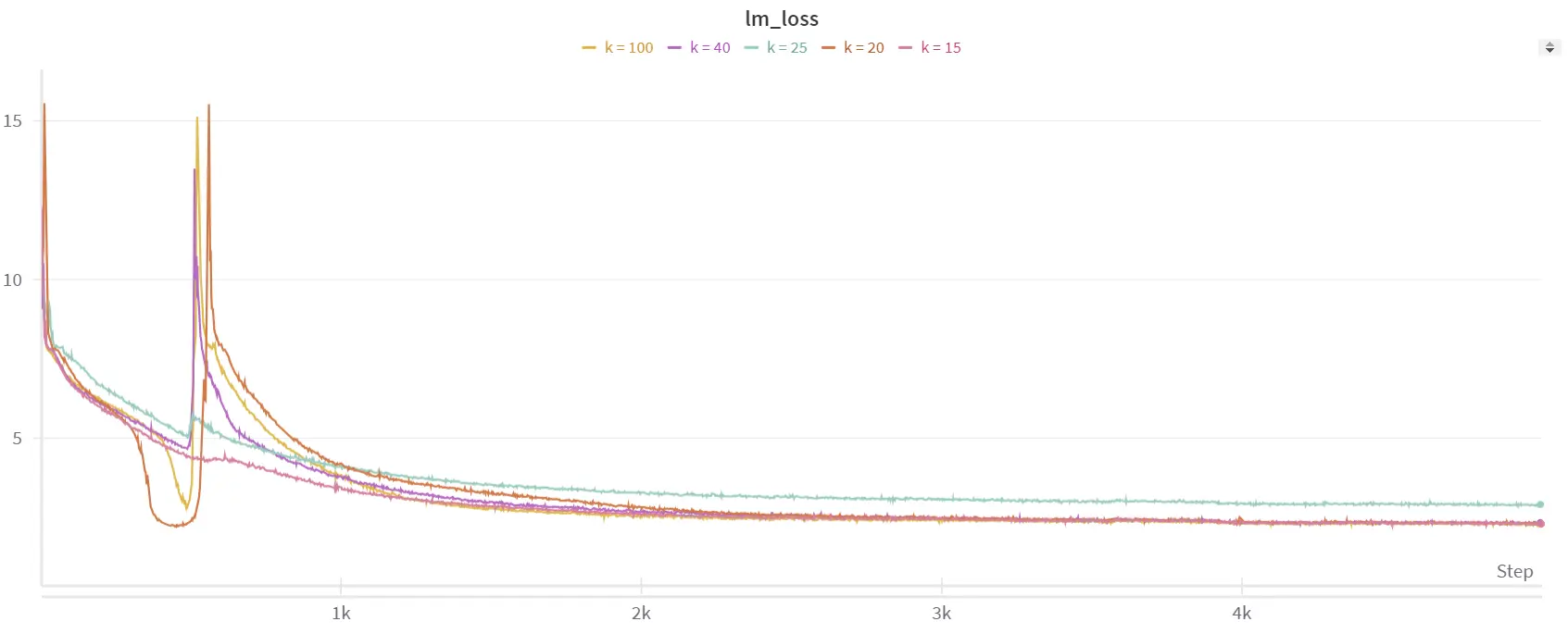
使用 Sigmoid 调度器进行微调的图像
lambda 的急剧增加导致在第 500 步左右出现不稳定,并没有解决第一次发散问题。然而,对于 $$ k = 100 $$,我们观察到在下游任务中有一些改善 (请参阅结果表),尽管困惑度仍保持在 13.5 左右。尽管如此,与线性调度器相比,并没有显示明显的性能提升。
此外,我们尝试了使用随机权重和各种学习率从头开始训练模型的实验。这使我们能够比较我们的微调方法与传统的预训练方法的有效性。
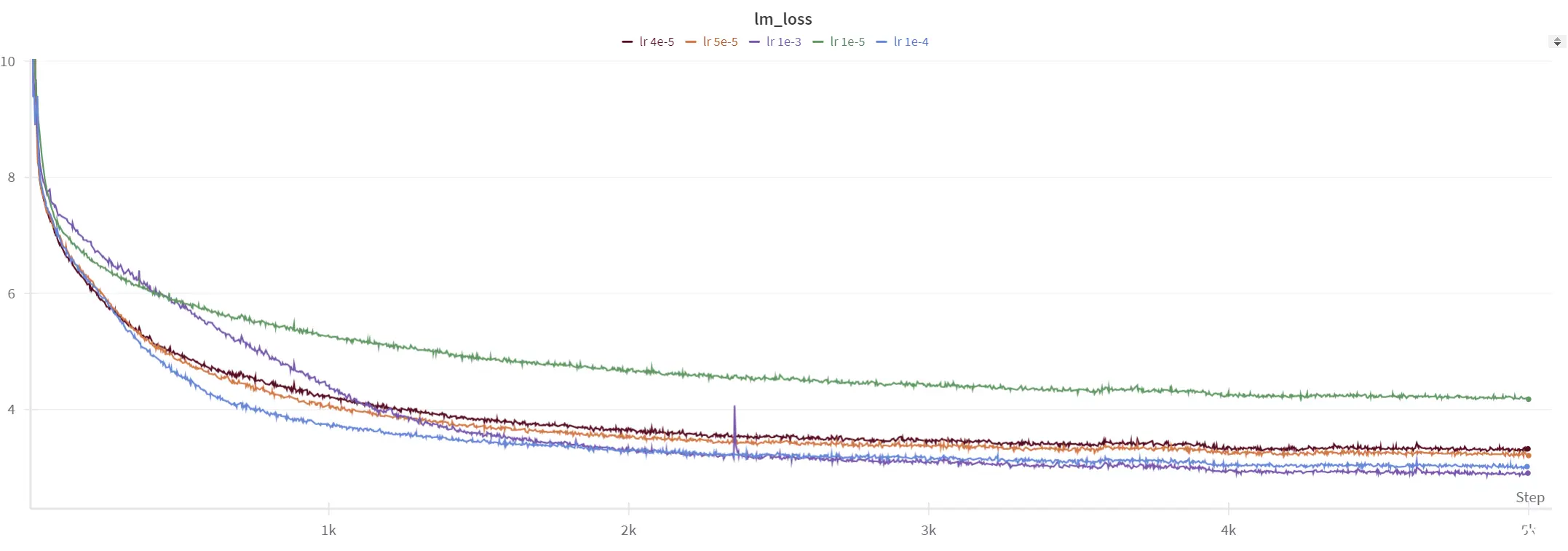
不同学习率时的训练图像
所有从随机权重训练的模型都没有比我们的微调模型表现更好。我们在这些模型中实现的最佳困惑度为 26,与我们的微调方法的结果相比略逊一筹。
扩展到 100B 个 token!
我们将实验扩展到了 100B 个 token,以查看是否能够达到 Llama 3 8B 模型的性能水平。我们进行了更长时间的训练运行,从较短运行中表现最佳的检查点开始,使用线性调度器,并持续微调了 45,000 步。我们尝试了不同的学习率,虽然在某些指标上模型的表现接近 Llama 3 模型,但平均而言,仍然落后一些。
这里是我们在训练过程中在不同 checkpoint 评估的一些指标的例子:
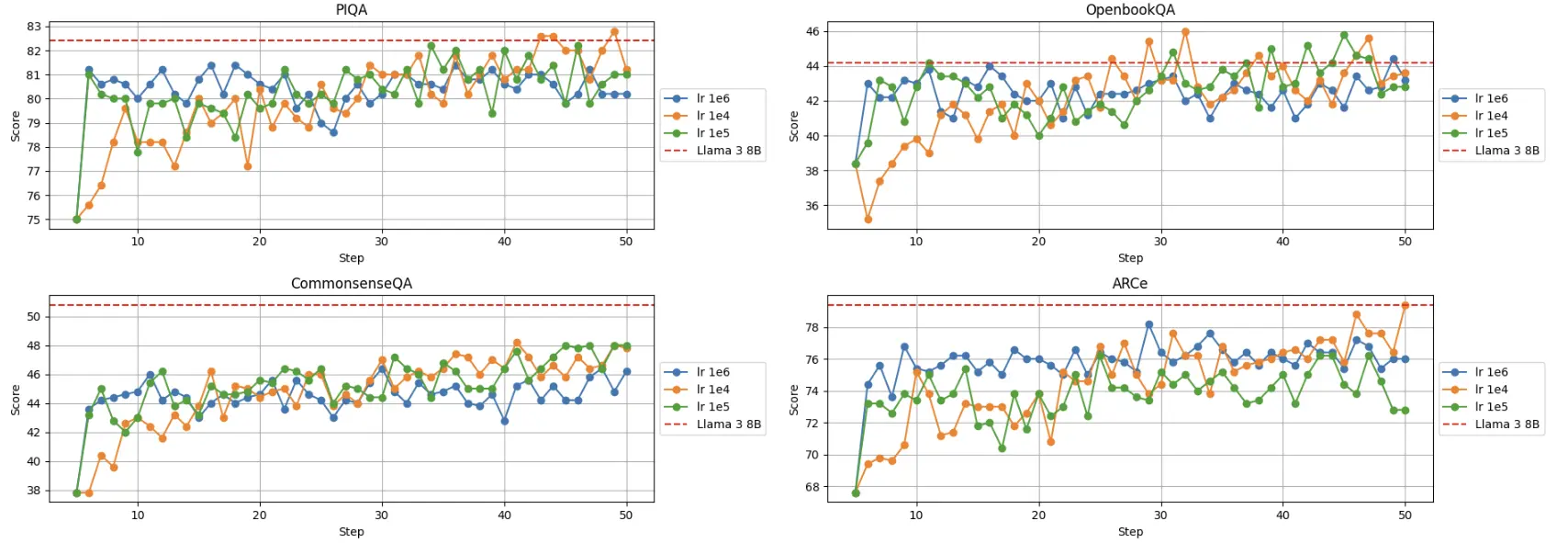
在训练中不同学习率的多个指标评估结果
平均的分数如下:
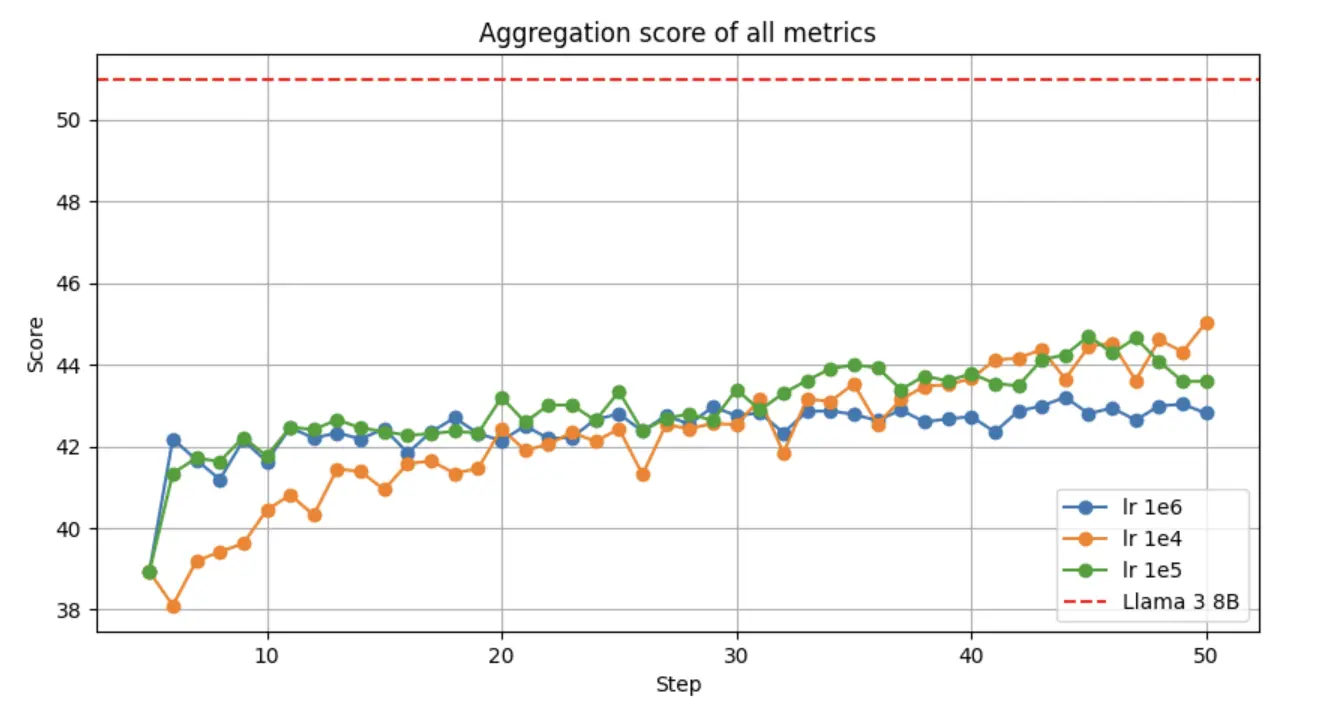
在训练中不同学习率的平均评估结果
在更小的模型上的实验
在我们对 SmolLM 等较小模型进行的初始实验中,我们观察到 warmup 量化技术并没有像对较大模型那样带来太多改进。这表明 warmup 量化的有效性可能与模型的大小和复杂性更密切相关。
例如,这里是 SmolLM 135M 模型的损失曲线,比较了从一开始就使用 warmup 量化和完全量化的情况。有趣的是,这些曲线非常接近,得到的困惑度并没有显著不同。
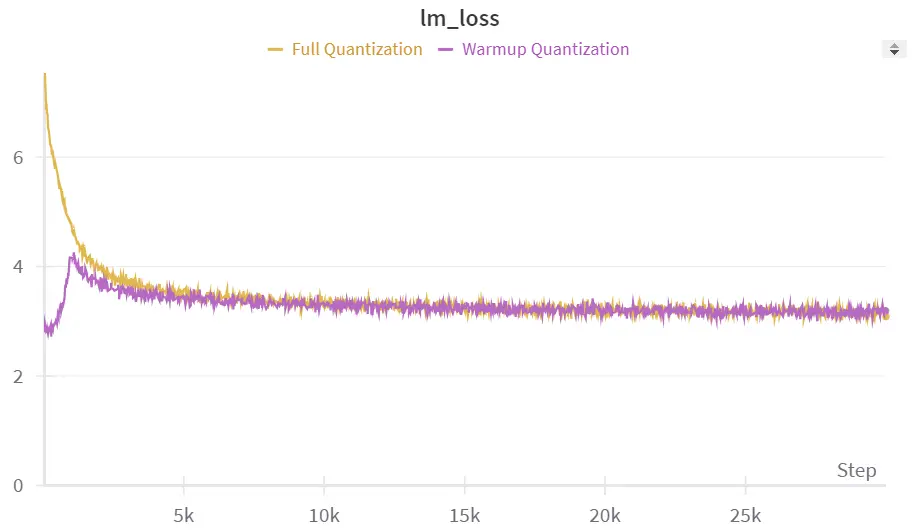
有 warmup 量化和没有时的 Smoll LLM 微调实验
对比与结论
BitNet 在与基准方法相比表现出色,特别是在较低比特数情况下。根据论文,BitNet 实现了与 8 位模型相当的分数,但推理成本显著更低。在 4 位模型的情况下,仅量化权重的方法胜过同时量化权重和激活的方法,因为激活更难量化。然而,使用 1.58 位权重的 BitNet 超越了仅权重和权重与激活量化方法。
下表展示了在 Llama3 8B 的 10B 个 token 微调过程之后各种指标的结果。这些结果与其他模型架构的结果进行了比较,以提供对性能的全面概述 (所有评估均使用 Lighteval 在 Nanotron 格式模型上进行)。
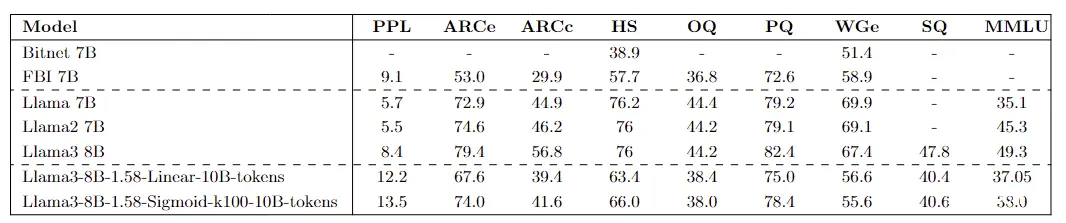
与 Llama 模型的指标比较: 线性表示线性 lambda 调度器,Sigmoid 表示 Sigmoid 调度器 (在我们的情况下 k = 100)
在仅使用三值权重进行 10B 个 token 微调后,该模型展现出令人印象深刻的性能,特别是与经历了更加广泛训练的其他模型相比。例如,它胜过了在数据集规模显著大得多的 100B 个 token 上训练的 Bitnet 7B 模型。此外,它的表现也优于 FBI LLM (Fully Binarized LLM) 模型,后者在更庞大的 1.26T 个 token 上进行了蒸馏。这突显了该模型的效率和有效性,尽管其微调过程相对规模较小。
对于 100B 个 token 的实验,我们拥有的表现最佳的 checkpoint 如下:

100B 个 token 微调后与 Llama 模型的指标比较
要复制这些结果,您可以查看这个 PR 将模型转换为 Nanotron 格式,解压权重 (检查函数 unpack_weights),并使用 lighteval。
请注意,尽管这些模型是从一个 Instruct-tuned 模型微调而来,它们仍需要使用 Instruct 数据集进行微调。这些可以被视为基础模型。
使用的算子和测试标准
为了从 BitNet 低精度权重中受益,我们将它们打包成一个 <code>int8 张量 (这使得参数数量从 80 B 降至 28 B!)。在推理过程中,这些权重在执行矩阵乘法之前必须进行解包。我们在 Cuda 和 Triton 中实现了自定义内核,以处理矩阵乘法过程中的即时解包。对于矩阵乘法本身,我们采用了缓存分块矩阵乘法技术。为了充分理解这种方法,让我们首先回顾一些 Cuda 编程基础知识。
基础的 GPU 概念: 线程、块、和共享内存
在深入了解缓存分块矩阵乘法之前,了解一些基本的 GPU 概念是很重要的:
- <li>线程 (thread) 和块 (block): GPU 同时执行成千上万个线程。这些线程被分组成块,每个块独立运行。网格由这些块 (grid) 组成,代表整个程序空间。例如,在矩阵乘法中,每个线程可能负责计算输出矩阵的一个单元。
- 共享内存 (share memory): 每个块都可以访问有限量的共享内存,比全局内存 (global memory, GPU 上的主内存) 要快得多。然而,共享内存大小有限,并在块内的所有线程之间共享。有效利用共享内存是提高 GPU 程序性能的关键。
矩阵乘法中的挑战
在 GPU 上简单实现矩阵乘法可能涉及每个线程通过直接从全局内存读取所需元素来计算结果矩阵的单个元素。然而,这种方法可能效率低下,原因如下:
- 内存带宽: 相对于 GPU 核心执行计算的速度,访问全局内存相对较慢。如果每个线程直接从全局内存读取矩阵元素,访存时间可能成为瓶颈。
- 冗余数据访问: 在矩阵乘法中,输入矩阵的许多元素被多次使用。如果每个线程独立从全局内存获取所需数据,相同的数据可能会被多次加载到 GPU 中,导致效率低下。例如,如果每个线程用于计算输出矩阵中的单个元素,则负责计算位置 (i, j) 的线程将需要从全局内存加载矩阵 A 的第 i 行和矩阵 B 的第 j 列。然而,其他线程,例如负责计算位置 (i+1, j) 的线程,无法重用这些数据,将不得不再次从全局内存中加载相同的第 j 列。
分块的概念
分块是一种用于解决这些挑战的技术,主要用于 FlashAttention 技术中以提高内核的效率。基本思想是将矩阵分成更小的子矩阵,称为块 (tile),这些块可以适应 GPU 的共享内存。计算不再一次完成整个输出矩阵,而是将计算分解为小块,逐块处理。
在矩阵乘法的背景下,这意味着将矩阵 A 和 B 划分为块,将这些块加载到共享内存中,然后在这些较小的块上执行乘法。这种方法允许线程重复使用存储在快速共享内存中的数据,减少了重复访问全局内存的需求。
具体操作如下:
- 将块加载到共享内存: 每个线程块协同地将矩阵 A 的一个小块和相应的矩阵 B 的一个小块从全局内存加载到共享内存。这个操作对每个小块只执行一次,然后该小块被块中的线程多次重复使用。
- 计算部分乘积: 一旦块加载到共享内存中,每个线程计算部分乘积。由于块中的所有线程都在共享内存中的相同块上工作,它们可以有效地重复使用数据,而无需额外访问全局内存。
- 累积结果: 计算完一个块的部分乘积后,线程将从矩阵 A 和 B 中加载下一个块到共享内存,并重复这个过程。结果累积在寄存器 (或本地内存) 中,一旦所有块都被处理,输出矩阵元素的最终值将被写回全局内存。
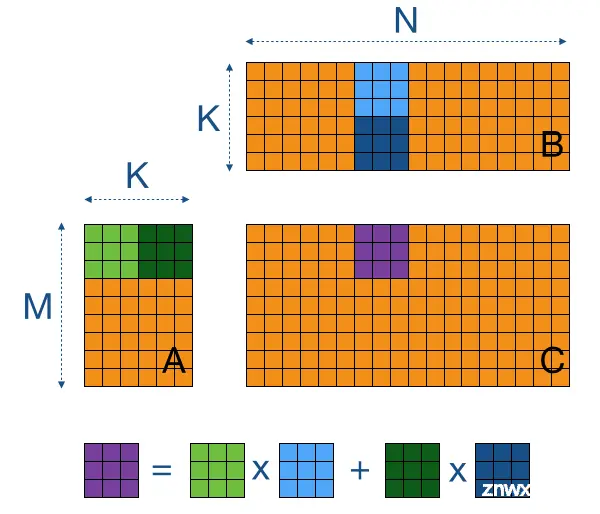
分块矩阵乘法图示 (来源 https://cnugteren.github.io/tutorial/pages/page4.html)
现实的考虑
在实现缓存分块矩阵乘法时,考虑了几个因素:
- <li>块大小: 块的大小应该选择以平衡能够放入共享内存的数据量和全局内存访问次数之间的权衡。
- 内存合并: 全局内存访问应该进行内存合并,这意味着相邻的线程访问相邻的内存位置。
- 占用率: 应该选择每个块中的线程数和网格中的块数,以确保高占用率,即在 GPU 上有尽可能多的活动线程束 (warp) (一个线程束是一组 32 个线程),以隐藏内存延迟。
Triton 算子
下面是我们作为基准的一个 triton 算子:
<code>@triton.autotune(
configs=get_cuda_autotune_config(),
key=['M', 'N', 'K'],
)
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
):
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.int32)
for i in range(4):
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
for j in range(0, tl.cdiv(K // 4, BLOCK_SIZE_K) ):
k = i * tl.cdiv(K // 4, BLOCK_SIZE_K) + j
# BLOCK_SIZE_K must be a divisor of K / 4
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0)
b_uint8 = tl.load(b_ptrs, mask=offs_k[:, None] < K // 4 - j * BLOCK_SIZE_K, other=0)
mask = 3<<(2*i)
b = ((b_uint8 & mask) >> (2*i))
# We accumulate the tiles along the K dimension.
tensor_full = tl.full((1,), 1, dtype=tl.int8)
accumulator += tl.dot(a, (b.to(tl.int8) - tensor_full), out_dtype=tl.int32)
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
c = accumulator
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :]
c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)
tl.store(c_ptrs, c, mask=c_mask)
def matmul(a, b):
assert a.shape[1] == b.shape[0] * 4, "Incompatible dimensions, the weight matrix need to be packed"
assert a.is_contiguous(), "Matrix A must be contiguous"
M, K = a.shape
_, N = b.shape
c = torch.empty((M, N), device=a.device, dtype=torch.float16)
grid = lambda META:(triton.cdiv(M, META['BLOCK_SIZE_M'])* triton.cdiv(N, META['BLOCK_SIZE_N']), )
matmul_kernel[grid](
a, b, c,
M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
)
return c
代码解析
- <li>确定分块位置
算子首先确定每个线程块负责的输出矩阵的块 (tile):
pid是每个线程块的唯一标识符,使用tl.program_id(axis=0)获得。- 网格被分成一组线程块 (
GROUP_SIZE_M)。每个组处理输出矩阵的一部分。 pid_m和pid_n是分块在 M 和 N 维度上的坐标,分别表示。- 计算偏移量 (
offs_am、offs_bn、offs_k) 以确定每个块中的线程将处理矩阵 A 和 B 的哪些元素。
- <li>加载和计算分块
算子使用循环以 <code>BLOCK_SIZE_K 的块大小迭代 K 维度。对于每个块:
- <li>
解包矩阵 B: 算子假设矩阵 B 是使用
int8值打包的,这意味着每个元素实际上代表四个较小的值打包成一个字节。解压过程发生在循环内:- 从全局内存加载
b_uint8作为打包的int8。 - 解压每个打包的值以获得用于计算的实际权重值。
- 从全局内存加载
点积: 内核计算从矩阵 A 和 B 加载的分块的点积,并将结果累积到
accumulator中。accumulator存储输出矩阵 C 的分块的部分结果。
加载分块: 从全局内存加载矩阵 A 和 B 的分块。
- <li>存储结果
在处理完沿着 K 维度的所有分块之后,存储在 <code>accumulator 中的最终结果被转换为 float16 ,并写回到全局内存中矩阵 C 的相应分块。写入过程使用掩码来确定内存边界,以确保只写入有效元素。
要获取代码的更详细解释,请查看这个 PR。
基准测试
我们对我们的算子进行了基准测试,与使用 @torch.compile 解压权重然后在 BF16 精度下执行矩阵乘法的方法进行了对比,发现两种方法的性能几乎相同。为了确保准确的基准测试,我们在 2000 次迭代中执行了矩阵乘法操作,并在最后 1000 次迭代中计算平均时间,以消除与初始加载或编译相关的任何低效性。下面是显示基准测试结果的图表。我们还测试了各种矩阵大小,其中 x 轴表示对数尺度上的乘法次数,y 轴显示平均时间 (以毫秒为单位)。
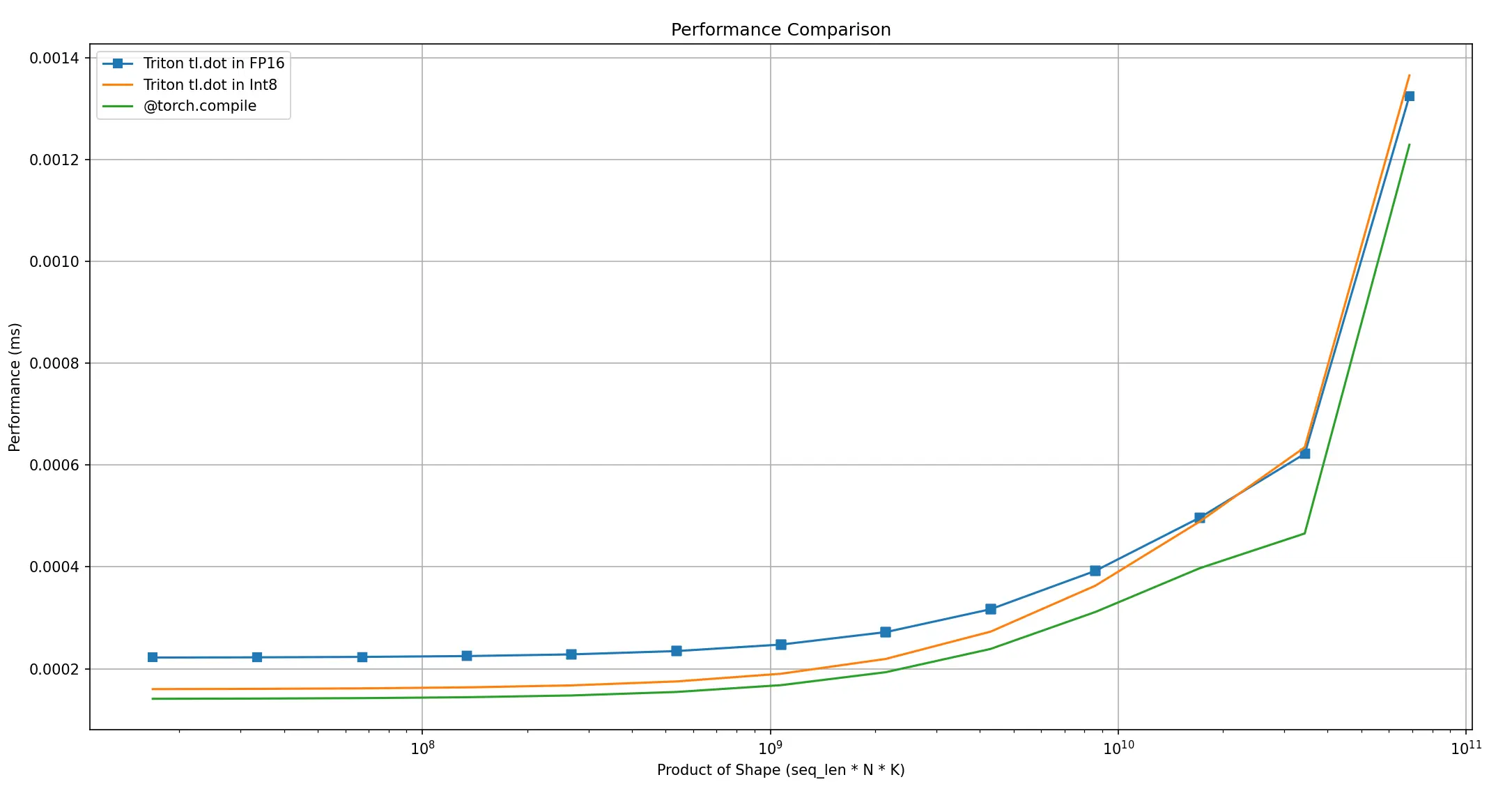
Triton 算子对比 torch.compile
我们还尝试使用 BitBlas,这是一个旨在使用混合精度执行矩阵运算的软件库。它通过允许在较低精度格式 (如 INT8、INT4,甚至 INT2) 而不是传统的 FP32 或 FP16 格式中进行计算,来帮助优化这些操作。
基准测试结果令人鼓舞,如图所示,BitBlas 在低精度下优于我们的自定义内核和 Torch 的 <code>matmul 函数。
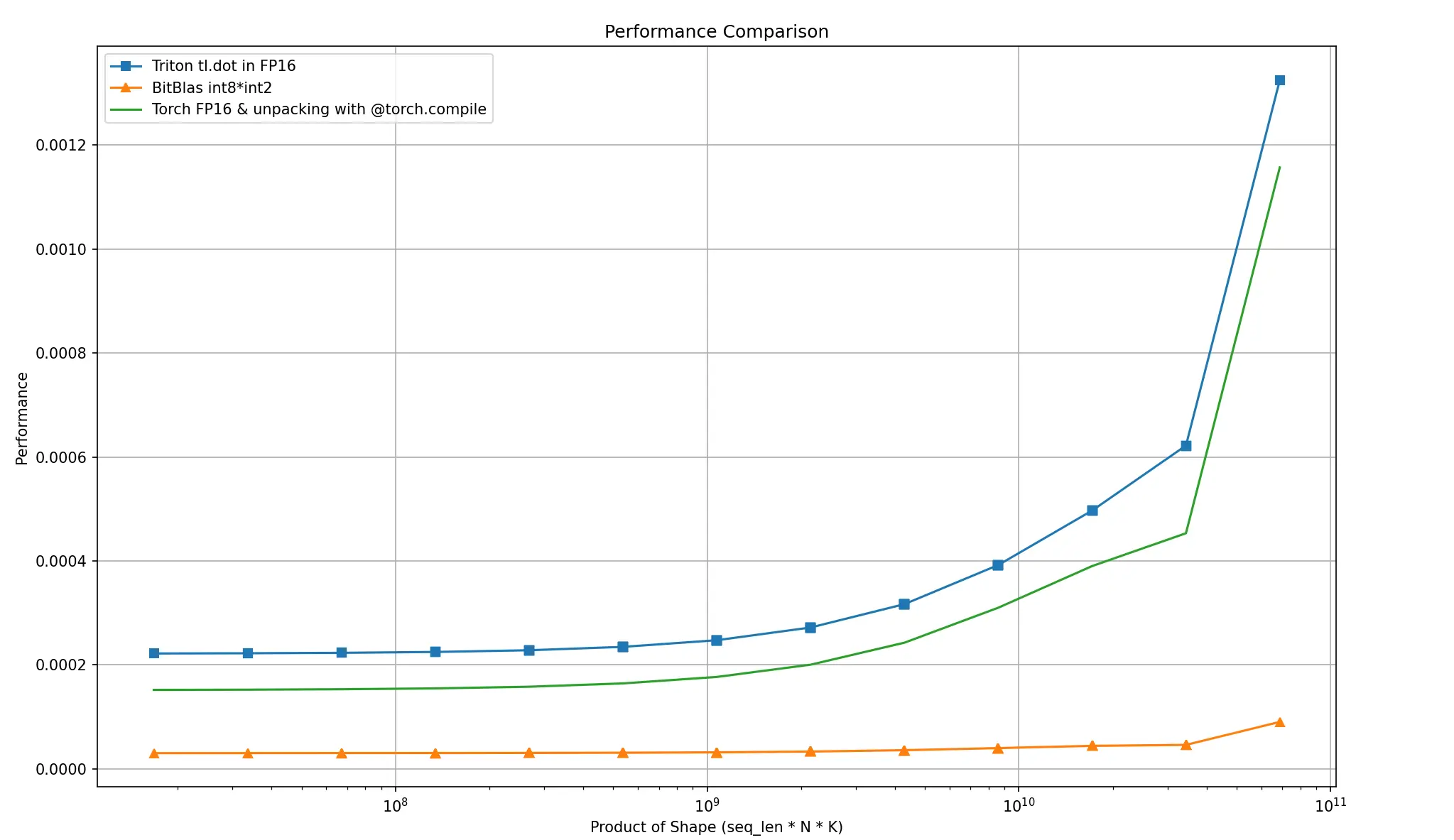
Bitblas 测试
然而,在模型加载过程中,BitBlas 需要编译适合权重矩阵形状的内核,并将它们存储在本地代码库中,这可能会增加初始加载时间。
结论
总之,随着大型语言模型的不断扩展,通过量化来减少它们的计算需求至关重要。本博文探讨了 1.58 位量化的方法,该方法使用了三值权重。虽然在 1.58 位进行预训练模型是资源密集型的,但我们已经证明,通过一些技巧,可以将现有模型微调到这个精度水平,实现高效的性能而不牺牲准确性。通过专门的内核优化推理速度,BitNet 为使大型语言模型更具实用性和可扩展性打开了新的可能性。
致谢
我们要衷心感谢 Leandro von Werra、Thomas Wolf 和 Marc Sun 在整个项目中提供的宝贵帮助和见解。我们还要感谢 Omar Sanseviero 和 Pedro Cuenca 在完善这篇博文方面的贡献,帮助我们清晰有效地向人工智能社区传达我们的发现。此外,我们要感谢 GeneralAI 团队在 BitNet 项目上的开创性工作。他们的研究对我们的努力具有基础性意义,我们特别感谢他们在论文中提供的清晰准确的数据。
更多资源
- <li>H. Wang et al., BitNet: Scaling 1-bit Transformers for Large Language Models . arxiv paper
- S. Ma et al., The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits . arxiv paper
- S. Ma et al., The Era of 1-bit LLMs: Training Tips, Code and FAQ . link
- RJ. Honicky, Are All Large Language Models Really in 1.58 Bits? . blogpost
- L. Mao, CUDA Matrix Multiplication Optimization . blogpost
- Tutorial: OpenCL SGEMM tuning for Kepler . link
- CUDAMODE . github, youtube
- Wen-mei W. Hwu, David B. Kirk, Izzat El Hajj, Programming Massively Parallel Processors : A Hands-on Approach
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。