论文精读:HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
大风车滴呀滴溜溜地转 2024-06-12 09:01:06 阅读 86
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Status: Reading
Author: Dongsheng Li, Kaitao Song, Weiming Lu, Xu Tan, Yongliang Shen, Yueting Zhuang
Institution: 微软亚洲研究院(Microsoft Research Asia), 浙江大学(Zhejiang University)
Publisher: NeurIPS
Publishing/Release Date: December 3, 2023
Summary: 解决不同领域和多种模态的复杂任务是通往AGI的关键,尽管现在有各种各样的AI模型,但是它们没有办法自主地处理复杂任务,而LLMs恰好可以作为管理者控制现有的AI模型来完成任务。本文提出的HuggingGPT就是一个基于ChatGPT的Agent,可以利用HuggingFace上各种各样的AI模型来完成任务。首先通过ChatGPT根据用户的请求制定任务计划,然后根据HuggingFace上模型的功能描述选择可用的AI模型,之后通过这些模型来执行子任务,最后总结执行结果并给出响应。HuggingGPT可以解决跨领域跨模态的各种AI任务,在语言、视觉、语音等任务中都取得很好的效果。
Type: Paper
链接: https://arxiv.org/abs/2303.17580
代码是否开源: 开源
代码链接: https://github.com/microsoft/JARVIS
读前先问
大方向的任务是什么?Task带着问题读论文,边读边回答。
Agent
这个方向有什么问题?是什么类型的问题?Type
虽然AI模型众多,但是不能互相配合。
为什么会有这个问题?Why
没有一个大脑作为指挥。
作者是怎么解决这个问题的?How
将ChatGPT作为大脑来指挥各种AI模型。
怎么验证解决方案是否有效?
实验结果怎么样?What(重点关注有没有解决问题,而不是效果有多好)
论文精读
引言
目前的LLM技术尚不完善,在构建先进的AI系统的道路上面临着一些紧迫的挑战:
受限于文本生成的输入输出形式,目前的LLM缺乏处理视觉、语音等复杂信息的能力;在现实场景中,一些复杂的任务通常由多个子任务组成,因此需要多个模型的调度和协作,这也超出了语言模型的能力;对于一些具有挑战性的任务,LLM在Zero-Shot或Few-Shot设置中表现出出色的结果,但仍然弱于一些专家。
作者认为,为了处理复杂的AI任务,LLM应该能够与外部模型协调以利用它们的力量。关键问题是如何选择合适的中间件来桥接LLM和AI模型之间的联系,LLM恰好可以完成这个工作。将各种AI模型的描述融入到提示词中,LLM可以作为管理规划、调度、合作等这些AI模型的大脑。
在这篇论文中,作者提出了一种名为 HuggingGPT 的由 LLM 驱动的 Agent,可以自主处理各种复杂的 AI 任务,它连接了 LLM(即 ChatGPT)和 ML 社区(即 Hugging Face),并且可以处理来自不同模式的输入。更具体地说,LLM充当大脑:一方面根据用户请求拆解任务,另一方面根据模型描述为任务分配合适的模型。通过执行模型并将结果集成到计划任务中,HuggingGPT 可以自主满足复杂的用户请求。
HuggingGPT 的工作流如下图所示,可以分为四个阶段:
任务规划:使用ChatGPT分析用户的请求,了解他们的意图,并将其分解为可能的可解决的任务。模型选择:ChatGPT 根据模型描述选择托管在 Hugging Face 上的专家模型。任务执行:调用并执行每个选定的模型,并将结果返回给ChatGPT。响应生成:ChatGPT 集成所有模型的预测结果并为用户生成响应。
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Status: Reading
Author: Dongsheng Li, Kaitao Song, Weiming Lu, Xu Tan, Yongliang Shen, Yueting Zhuang
Institution: 微软亚洲研究院(Microsoft Research Asia), 浙江大学(Zhejiang University)
Publisher: NeurIPS
Publishing/Release Date: December 3, 2023
Summary: 解决不同领域和多种模态的复杂任务是通往AGI的关键,尽管现在有各种各样的AI模型,但是它们没有办法自主地处理复杂任务,而LLMs恰好可以作为管理者控制现有的AI模型来完成任务。本文提出的HuggingGPT就是一个基于ChatGPT的Agent,可以利用HuggingFace上各种各样的AI模型来完成任务。首先通过ChatGPT根据用户的请求制定任务计划,然后根据HuggingFace上模型的功能描述选择可用的AI模型,之后通过这些模型来执行子任务,最后总结执行结果并给出响应。HuggingGPT可以解决跨领域跨模态的各种AI任务,在语言、视觉、语音等任务中都取得很好的效果。
Type: Paper
链接: https://arxiv.org/abs/2303.17580
代码是否开源: 开源
代码链接: https://github.com/microsoft/JARVIS
读前先问
大方向的任务是什么?Task带着问题读论文,边读边回答。
Agent
这个方向有什么问题?是什么类型的问题?Type
虽然AI模型众多,但是不能互相配合。
为什么会有这个问题?Why
没有一个大脑作为指挥。
作者是怎么解决这个问题的?How
将ChatGPT作为大脑来指挥各种AI模型。
怎么验证解决方案是否有效?
实验结果怎么样?What(重点关注有没有解决问题,而不是效果有多好)
论文精读
引言
目前的LLM技术尚不完善,在构建先进的AI系统的道路上面临着一些紧迫的挑战:
受限于文本生成的输入输出形式,目前的LLM缺乏处理视觉、语音等复杂信息的能力;在现实场景中,一些复杂的任务通常由多个子任务组成,因此需要多个模型的调度和协作,这也超出了语言模型的能力;对于一些具有挑战性的任务,LLM在Zero-Shot或Few-Shot设置中表现出出色的结果,但仍然弱于一些专家。
作者认为,为了处理复杂的AI任务,LLM应该能够与外部模型协调以利用它们的力量。关键问题是如何选择合适的中间件来桥接LLM和AI模型之间的联系,LLM恰好可以完成这个工作。将各种AI模型的描述融入到提示词中,LLM可以作为管理规划、调度、合作等这些AI模型的大脑。
在这篇论文中,作者提出了一种名为 HuggingGPT 的由 LLM 驱动的 Agent,可以自主处理各种复杂的 AI 任务,它连接了 LLM(即 ChatGPT)和 ML 社区(即 Hugging Face),并且可以处理来自不同模式的输入。更具体地说,LLM充当大脑:一方面根据用户请求拆解任务,另一方面根据模型描述为任务分配合适的模型。通过执行模型并将结果集成到计划任务中,HuggingGPT 可以自主满足复杂的用户请求。
HuggingGPT 的工作流如下图所示,可以分为四个阶段:
任务规划:使用ChatGPT分析用户的请求,了解他们的意图,并将其分解为可能的可解决的任务。模型选择:ChatGPT 根据模型描述选择托管在 Hugging Face 上的专家模型。任务执行:调用并执行每个选定的模型,并将结果返回给ChatGPT。响应生成:ChatGPT 集成所有模型的预测结果并为用户生成响应。
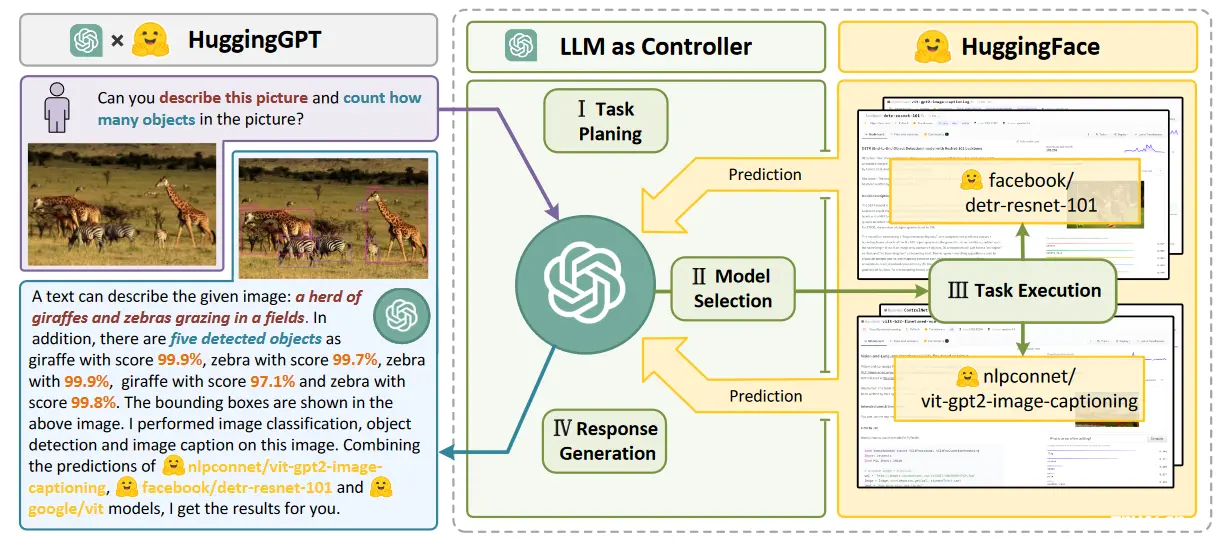
主要贡献:
提出HuggingGPT,结合LLM和专家模型,通过模型间合作协议,提供设计通用AI解决方案的新方法。将Hugging Face平台的任务特定模型与ChatGPT集成,处理多模态、多领域的广义AI任务,提供可靠的多模态对话服务。强调任务规划和模型选择的重要性,并提出评估LLMs在这方面能力的实验方法。大量跨模态和领域的实验表明,HuggingGPT在理解和解决复杂任务方面具有强大能力和巨大潜力。
方法
任务规划
任务规划模块旨在使用LLM分析用户请求,然后将其分解为结构化任务的集合,还要要求LLM确定这些分解任务的依赖关系和执行顺序,以建立它们的连接。
特定格式的指令:为了更好地表示用户请求并且在后续阶段使用,我们希望LLM能够输出特定格式(例如JSON)的内容,方便解析。一个任务则是由任务名称、任务ID、依赖任务和参数四部分组成。为了更好地理解任务规划的意图和标准,HuggingGPT 在提示词中融入了多个例子。
任务规划阶段的提示词如下图所示,为了支持更复杂的场景(例如,多轮对话),作者在提示词中还包含了聊天日志。

任务规划的模板
[{ "task": task, "id", task_id, "dep": dependency_task_ids, "args": { "text": text, "image": URL, "audio": URL, "video": URL}}]
| 名称 | 定义 |
|---|---|
| task | 代表解析任务的类型,涵盖了语言、视觉、视频、音频等不同的任务。 |
| id | 任务计划的唯一标识符,用于引用相关任务及其生成的资源。 |
| dep | 定义了执行所需的先决任务,仅当所有先决依赖任务完成后才会启动该任务。 |
| args | 包含任务执行所需参数的列表,三个子字段,根据任务类型填充文本、图像和音频资源。它们是根据用户的请求或依赖任务生成的资源来解析的。 |
支持的任务列表

模型选择
HuggingGPT 继续将任务与模型进行匹配的任务,即为解析的任务列表中的每个任务选择最合适的模型。作者使用模型描述作为连接每个模型的语言接口,从 ML 社区(例如 Hugging Face)收集专家模型的描述,然后采用动态上下文任务模型分配机制来为任务选择模型。
模型选择阶段的提示词如下图所示,将模型选择制定为单选问题,其中可用模型在给定上下文中作为选项呈现。由于最大上下文长度的限制,提示词中无法包含所有相关模型的信息。为了缓解这个问题,作者首先根据任务类型过滤模型,然后根据 Hugging Face 上的下载量对模型进行排名,选择前 K 个模型作为候选模型。

任务执行
HuggingGPT 会自动将任务参数输入到模型中,执行这些模型以获得推理结果,然后将其发送回 LLM。
由于先决任务的输出是动态生成的,HuggingGPT 还需要在启动任务之前动态指定任务的依赖资源。因此,任务执行阶段的重点是建立具有资源依赖性的任务之间的连接。
作者使用了一个唯一符号“”来维护资源依赖性。具体来说,HuggingGPT 将先决任务生成的资源标识为 -task_id,其中 task_id 是先决任务的 id。在任务规划阶段,如果某些任务依赖于先前执行的任务的输出(例如,task_id),HuggingGPT 会将此符号(即 -task_id)设置为参数中相应的资源子字段。然后在任务执行阶段,HuggingGPT 动态地用先决任务生成的资源替换该符号。
其余没有任何资源依赖的任务直接并行执行,进一步提高推理效率。也就是说,如果多个任务满足先决条件依赖关系,则可以同时执行多个任务。
响应生成
HuggingGPT 在本阶段将前三个阶段(任务规划、模型选择和任务执行)的所有信息整合为一个简洁的摘要,包括规划的任务列表、任务选择的模型以及模型的推理结果。
其中最重要的是推理结果,这是HuggingGPT做出最终决策的关键点。HuggingGPT 允许LLM接收结构化的推理结果作为输入,并以友好的人类语言形式生成响应。此外,LLM 不是简单地汇总结果,而是生成积极响应用户请求的响应,从而提供具有置信度的可靠决策。

实验
采用 GPT 模型的 gpt-3.5-turbo、text-davinci-003 和 gpt-4 变体作为主要 LLM,可通过 OpenAI API 公开访问,set the decoding temperature to 0,set the logit_bias to 0.2 on the format constraints (e.g., “{” and “}”)。
定性分析
下图中,用户的请求包括三个任务:检测示例图像中人的姿势,根据该姿势和指定文本生成新图像,以及创建描述该图像的语音。 HuggingGPT 将这些任务解析为六个任务,包括姿势检测、基于姿势的文生图、目标检测、图像分类、图像字幕和TTS。可以观察到 HuggingGPT 可以正确编排任务之间的执行顺序和资源依赖关系。例如,基于姿势的文生图任务必须遵循姿势检测并使用其输出作为输入。之后,HuggingGPT 为每个任务选择合适的模型,并将模型执行的结果综合为最终响应。

定量分析
任务规划在整个工作流程中起着至关重要的作用,因为它决定了后续流程中将执行哪些任务。因此,我们认为任务规划的质量可以用来衡量LLM作为HuggingGPT控制器的能力。
作者通过仅考虑任务类型来简化评估,不考虑其关联的参数。为了更好地对任务规划进行评估,作者将任务分为三个不同的类别并为它们制定不同的指标:
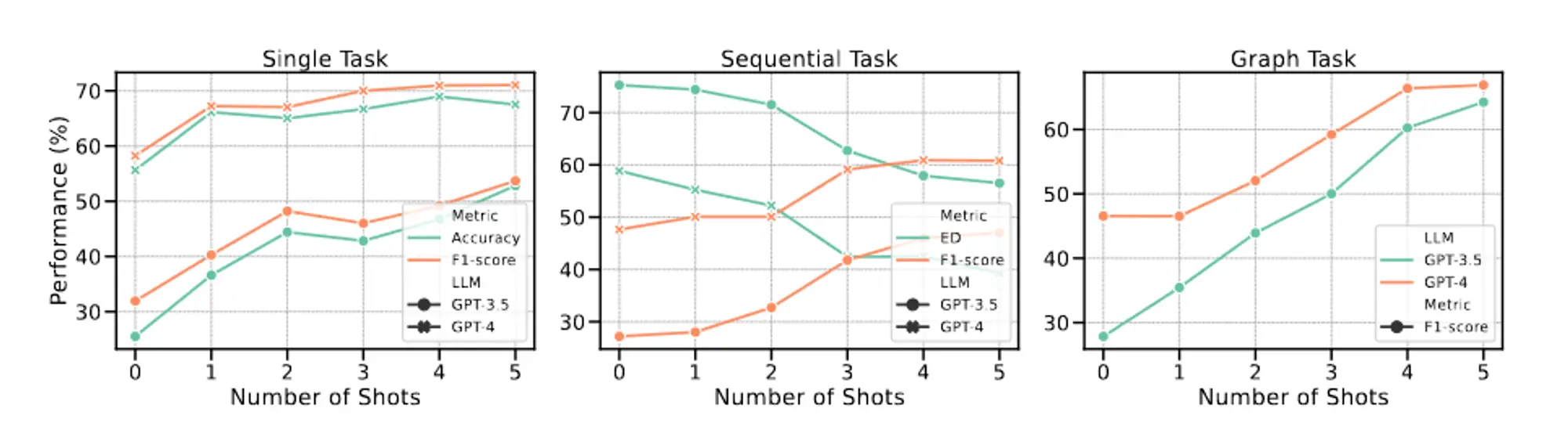
单任务:仅涉及一项任务的请求。当且仅当任务名称和预测标签完全相同时,才认为计划是正确的。在这种情况下使用 F1 和准确性作为评估指标。顺序任务:用户的请求可以分解为多个子任务的序列。在这种情况下采用 F1 和归一化编辑距离作为评估指标。图任务:用户请求可以分解为有向无环图。图任务中可能存在多种规划拓扑,仅依靠F1分数不足以反映LLM在规划方面的能力。为了解决这个问题,作者采用 GPT-4 作为批评者来评估规划的正确性。准确率是通过评估GPT-4的判断力得到的,简称GPT-4 Score。
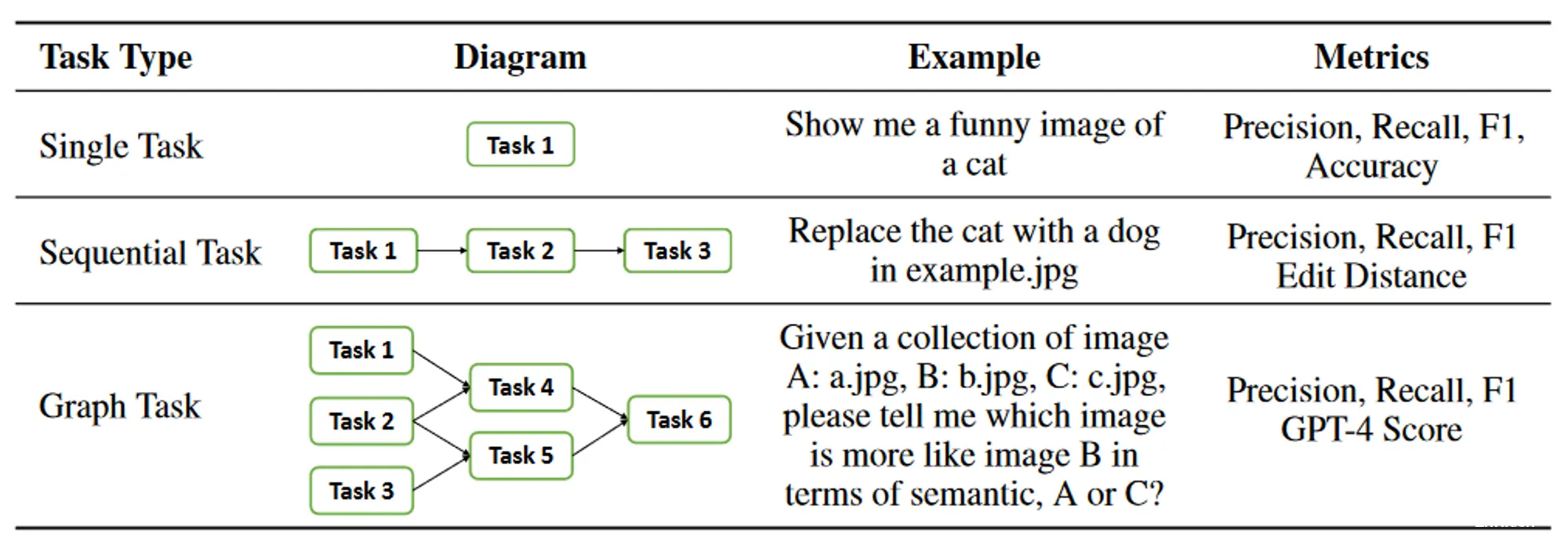
数据集
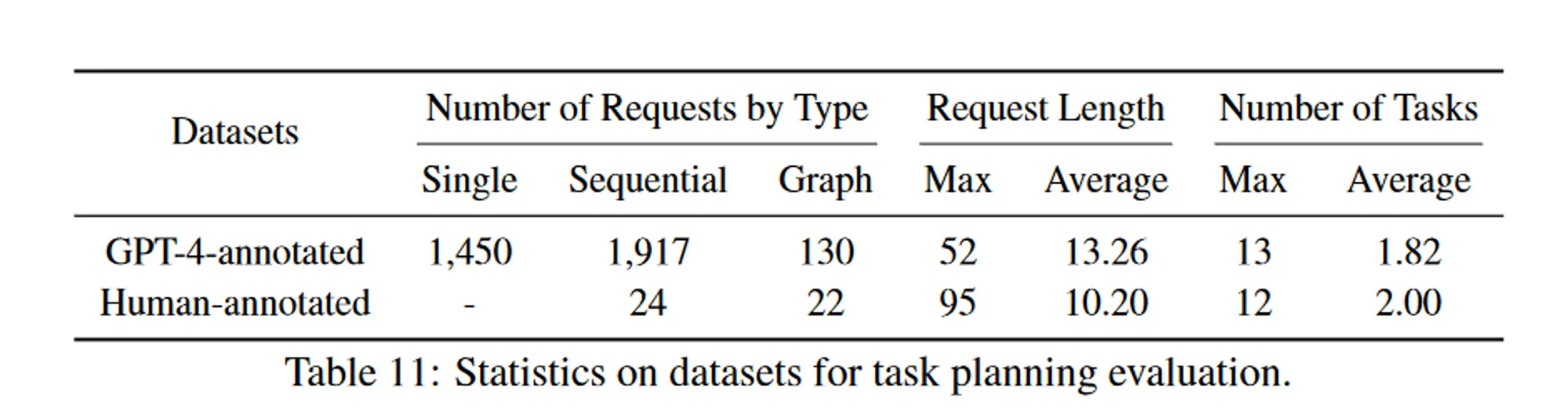
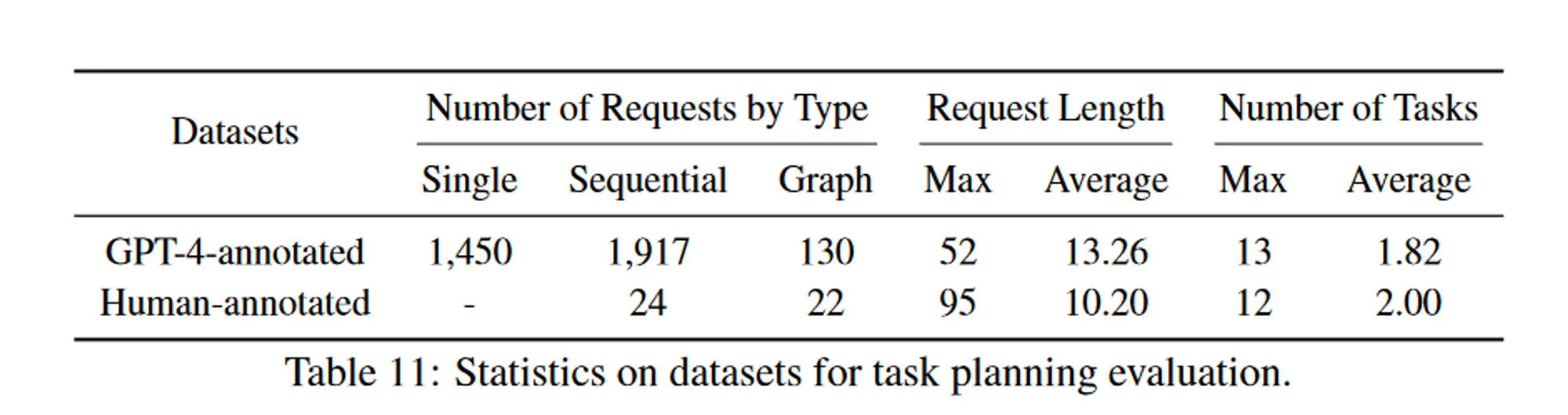
作者创建两个数据集用于评估任务规划,收集了 3497 个不同的用户请求
邀请一些标注者提交一些用户请求作为评估数据集,用 GPT-4 生成任务规划作为伪标签,涵盖单任务(1450个)、顺序任务(1917个)和图任务(130个)。邀请一些专家标注者将一些复杂请求(46 个示例,24个顺序任务+22个图任务)的任务规划标记为高质量的人工注释数据集。
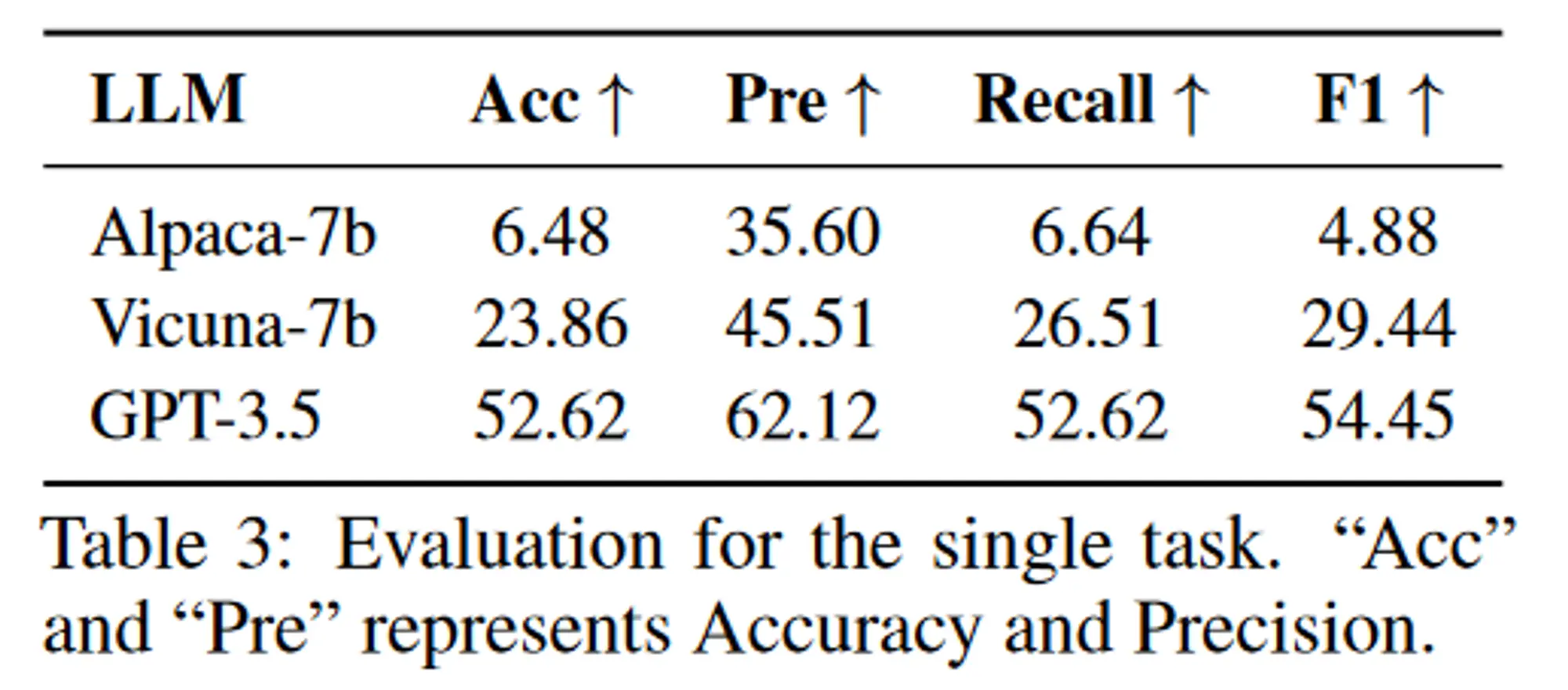
性能
单任务评估结果:
顺序任务评估结果:
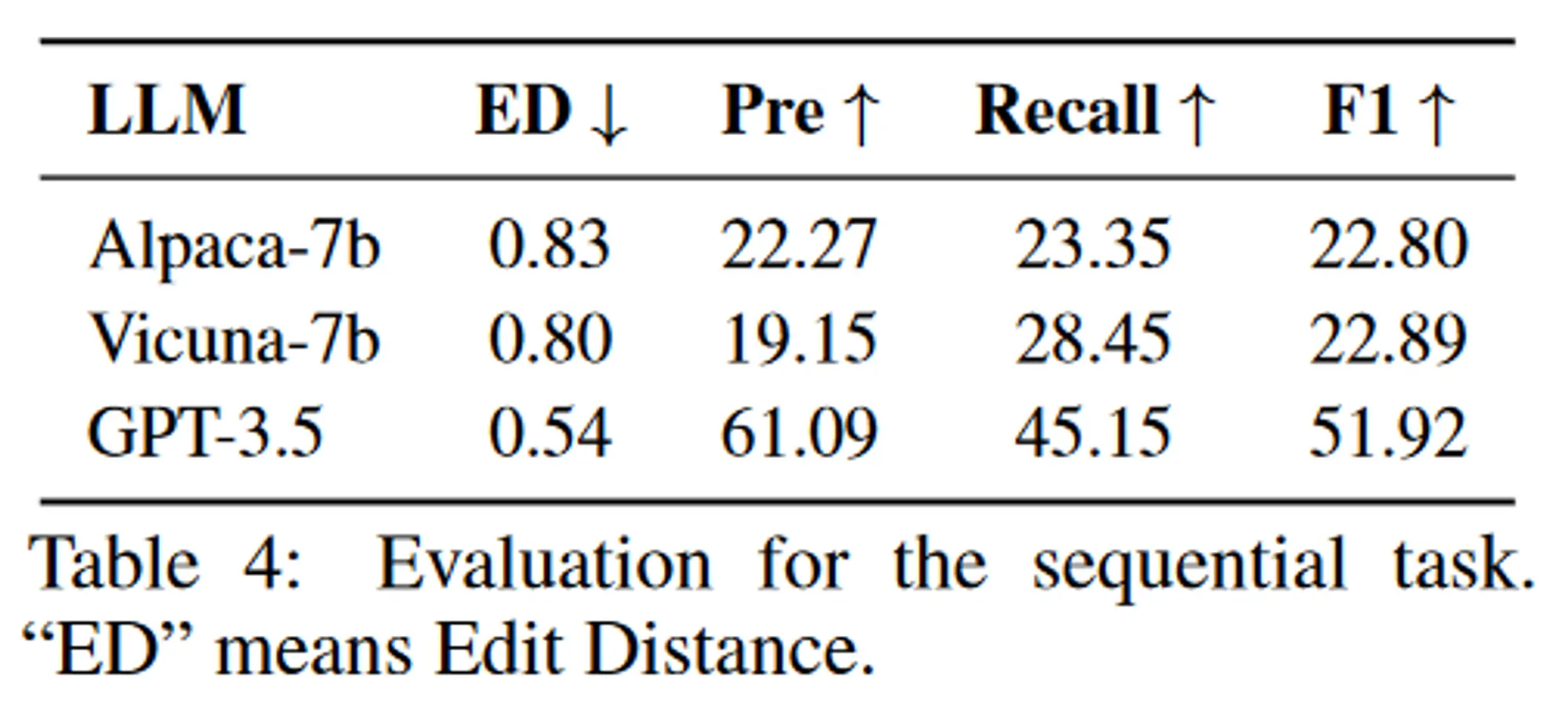
图任务评估结果:
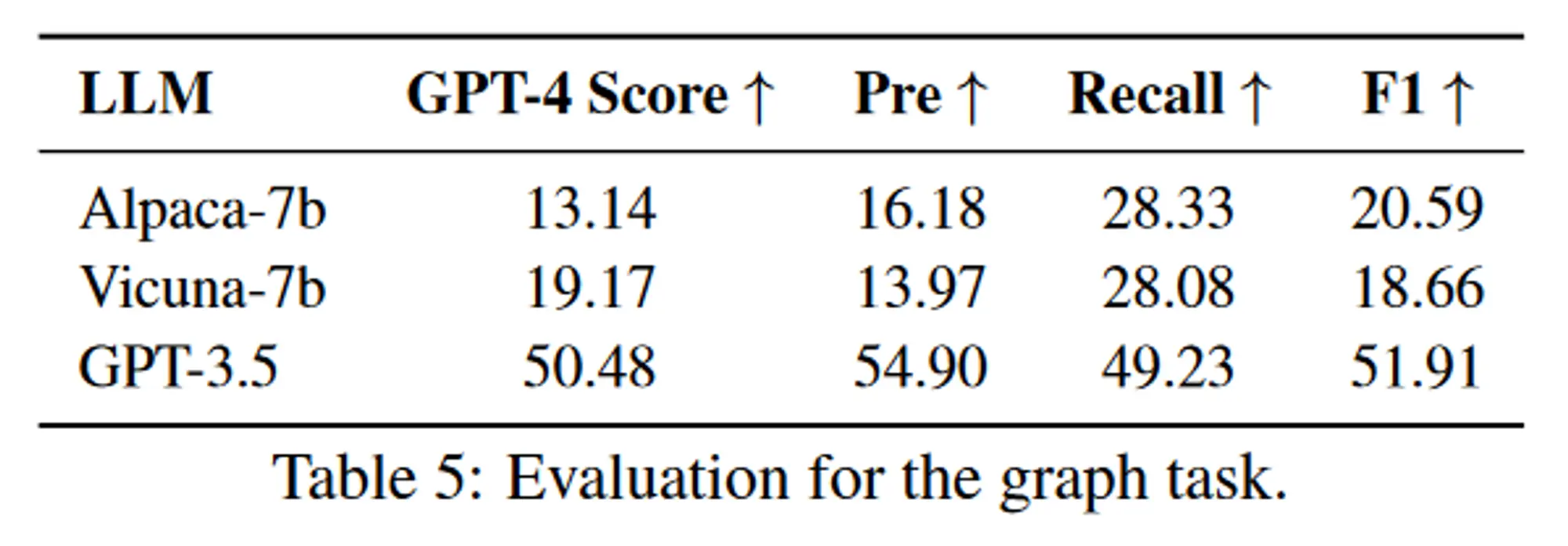
复杂任务评估结果:
消融实验
任务规划阶段,提示词中不同任务示例的多样性对结果的影响。多样性指的是提示词中涉及的不同任务类型的数量。增加示例的多样性可以适度提高LLM在任务规划方面的表现。
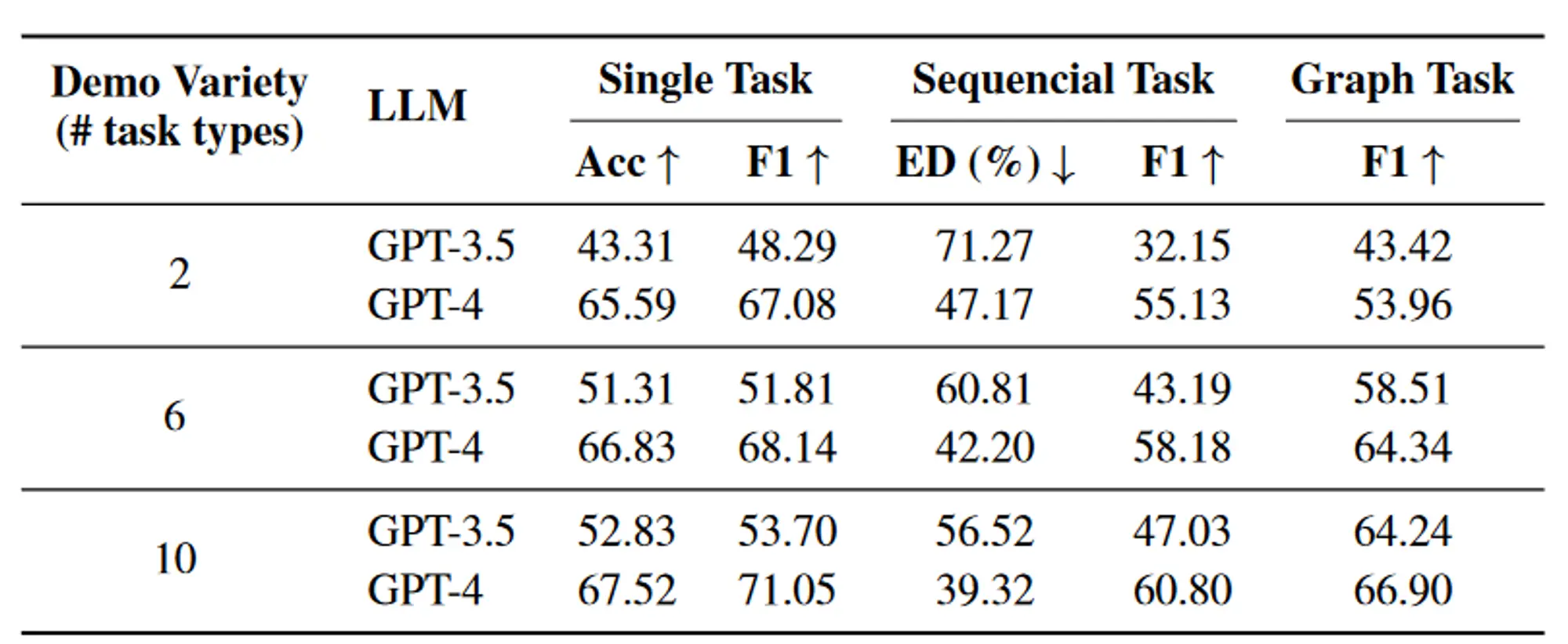
提示词中不同任务示例的数量对结果的影响。添加一些示例可以稍微提高模型性能,但当示例数量超过 4 个时,这种改进将受到限制。
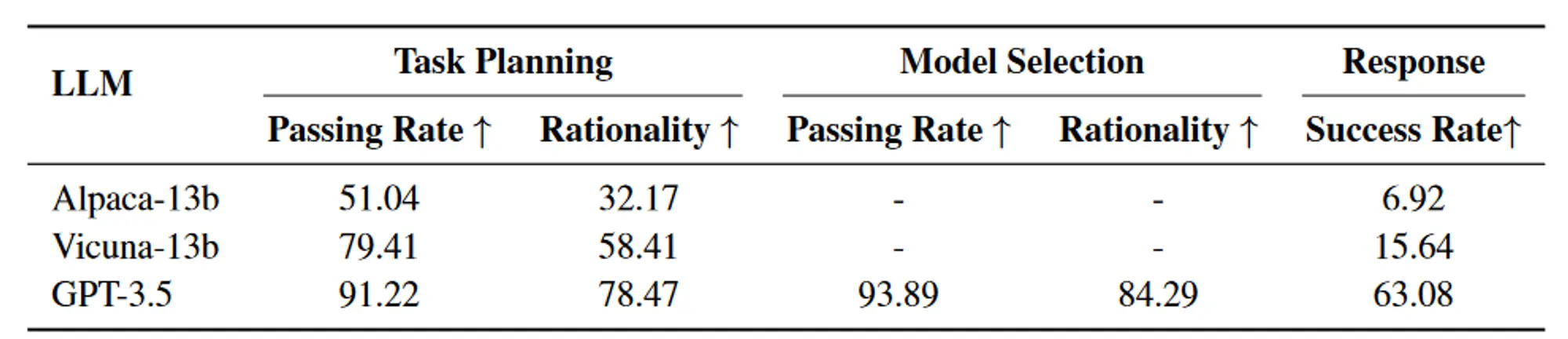
人工评测
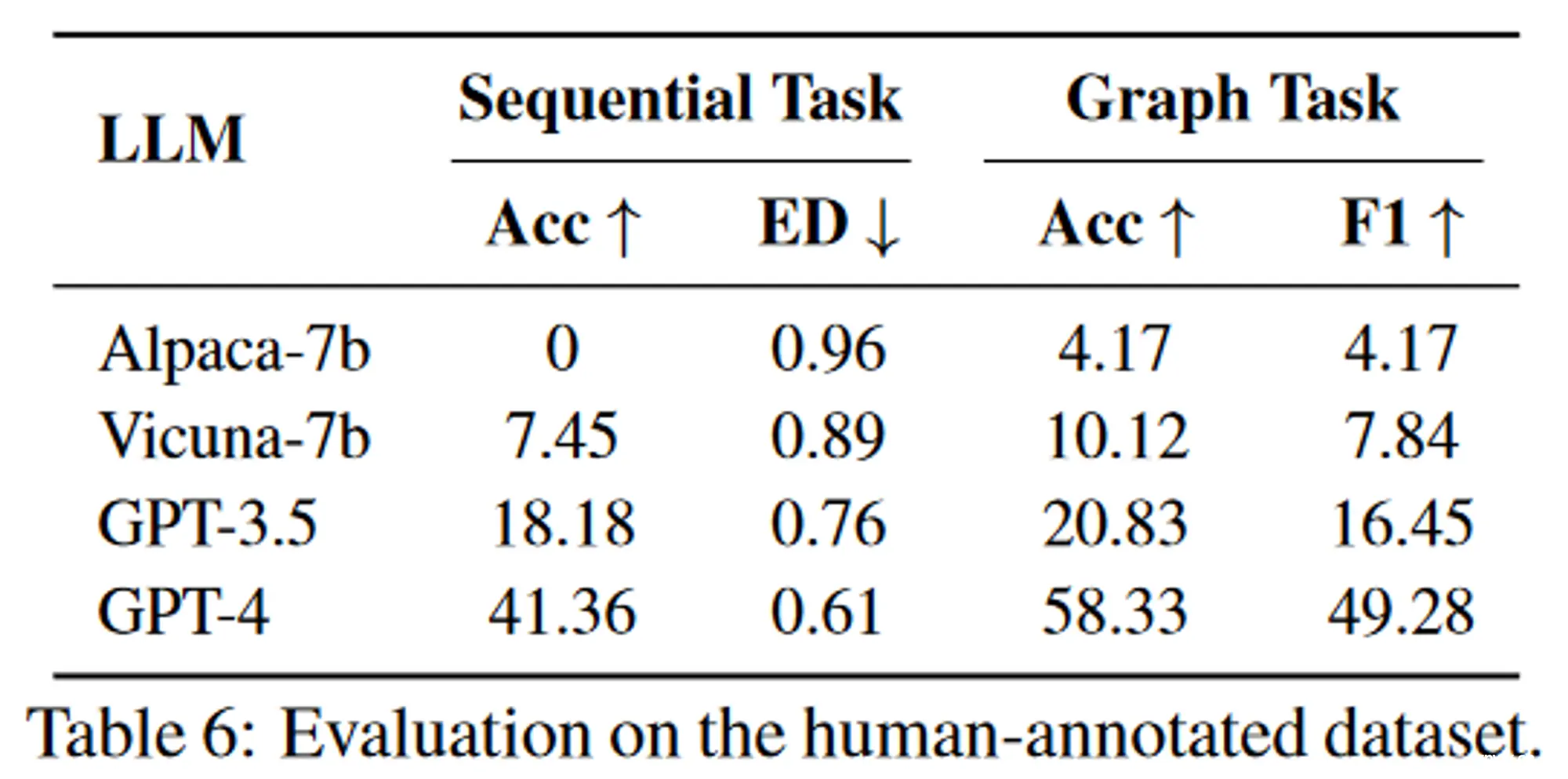
作者收集了 130 个不同的请求来评估 HuggingGPT 在各个阶段的性能,包括任务规划、模型选择和最终响应生成,设计了三个评价指标,即通过率、合理性、成功率。
限制
一些限制或改进空间:
HuggingGPT 中的规划很大程度上依赖于 LLM 的能力,而我们无法确保生成的计划始终可行且最优。因此,探索优化LLM的途径,提升其规划能力至关重要;效率是一个最大的挑战,要构建这样一个具有任务自动化功能的协作系统(即 HuggingGPT),它在很大程度上依赖于强大的控制器(例如 ChatGPT)。然而,HuggingGPT 在整个工作流程中需要与LLM进行多次交互,从而增加了生成响应的时间成本;令牌长度是使用 LLM 时的另一个常见问题,因为最大令牌长度始终受到限制,如何简洁有效地总结模型描述也是值得探索的;不稳定主要是因为LLM通常不可控,在推理过程中可能不符合指令或给出错误答案,从而导致程序工作流程出现异常。在设计系统时应该考虑如何减少推理过程中的这些不确定性。
速览笔记
Motivation
作者为什么做这件事?之前存在什么问题?
AI模型很多,但是大部分都是领域专家模型,没有一个控制器将它们都联合起来。
ChatGPT出来之后,展现出了强大的理解和推理能力,正好可以作为一个复杂AI系统的大脑。
Novelty
创建点在哪里?为什么要提出来这个?要解决什么问题?创新点包括:将ChatGPT作为控制器和规划器,解构复杂的任务,调用HuggingFace上的模型完成子任务,最后再汇总。
其实它也解决LLM只是一个纯语言模型,不能听、说和看的问题。
怎么才能想出来这个创新点?想问题的思路是什么?
推测作者的想法
站在当时的情境下,ChatGPT爆火,随之而来的就是AGI和Agent的概念。当时也有一些项目,像是AutoGPT、AgentGPT和BabyAGI等等,都是非常新的东西。
但是更多处理的还是文本这一个模态的信息,并不能处理其它像语音、图像和音频等模态的信息。
而GPT-4当时应该是还没有开放视觉能力,如果想要让ChatGPT拥有多模态的处理能力,就只能借助其它的模型,也就是HuggingFace上的模型。这些模型为了能够跟ChatGPT进行交互,也只能把输入输出都转换为文本的形式,这样就能搭建起一个以文本为媒介,ChatGPT为大脑的AI系统。
怎么就能发这个会议或者这个期刊的?
站在审稿人的角度看论文
一方面AGI和Agent这两点结合的很好,另外一方面,我觉得最重要的是,它提供了一种以文本为媒介的多模态处理方式,还不需要训练一个多模态模型。
Methods
对照代码,整理模型整体结构,分析每个模块的作用以及对性能的提升贡献(重点,呼应实验),找到核心模块(提点最多),以及判断跟创新点是否匹配
Experiments
训练集和测试集
用的哪个数据集,规模多少,评价指标是什么
作者自己创建两个数据集用于评估任务规划,收集了 3497 个不同的用户请求
邀请一些标注者提交一些用户请求作为评估数据集,用 GPT-4 生成任务规划作为伪标签,涵盖单任务(1450个)、顺序任务(1917个)和图任务(130个)。邀请一些专家标注者将一些复杂请求(46 个示例,24个顺序任务+22个图任务)的任务规划标记为高质量的人工注释数据集。
性能如何,好不好复现,是否有Code/Blog/知乎讨论
代码开源,但是数据集不开源,尝试一下demo可以,复现实验结果不太好弄。
浙大与微软发布的 HuggingGPT 在线演示惊艳亮相,可完成多模态复杂任务,将带来哪些影响? - 知乎
HuggingGPT - 知乎
浙大与微软发布的 HuggingGPT 在线演示惊艳亮相,可完成多模态复杂任务,将带来哪些影响? - 知乎
每个实验证明了什么
定量分析都是模型在任务规划阶段的指标。
消融实验是为了则是评估了提示词中示例的数量对结果的影响。
人类评估测试主要分了三个方面:通过率、合理性和成功率,我觉得最重要的事合理性。
有没有哪些实验没有做
论文中只对任务规划模块进行了定量分析,虽然给出的理由是任务规划模块最重要,但是我觉得其它模块也应该做实验分析。
任务规划模块,只考虑了任务类型的准确性,没有考虑参数,而且也没有考虑任务之间的依赖是否准确。对于顺序任务和图任务,我觉得顺序也是一个非常重要的因素;模型选择这一块,选择模型的准确性也需要评估。例如TTS任务,用户请求是合成的是中文,它会不会选择一个通用的TTS模型然后合成了英文输出;任务执行这一块倒是没有什么实验可以做;响应生成这一块,是邀请了人类专家做的评判,但是这一块我觉得有些评测可以自动化,比如统计图片中有多少只狗,这个在一些目标检测的数据集中应该是有标签的,可以自动评测。
Downsides
哪些提出的模块是有问题的
好像也没有什么问题,少一个模块都不大行。
哪些提出的点对性能提升存疑
暂无。
有没有能改进的地方
论文中提出的未来改进方向:
we plan to improve the quality and quantity of this dataset to further assist in evaluating the LLM’s planning capabilities.we believe that developing technologies to improve the ability of LLMs in task planning is very important, and we leave it as a future research direction.In the future, we will continue to explore more elements that can improve the capability of LLMs at different stages.we think that how to design and deploy systems with better stability for HuggingGPT or other autonomous agents will be very important in the future.
增加反馈机制,如果有哪个流程出现了问题,可以通过ChatGPT进行检查并反馈。
Thinking
能否迁移应用?(业务应用方向、模型改进、数据生产组织等方面)
超级缝合怪,牛逼o( ̄▽ ̄)d。
不一定要训练多模态大模型,借助现有的各种领域专家模型也可以。
下一篇: 第一篇【传奇开心果系列】我和AI面对面聊编程:深度比较PyQt5和tkinter.ttk
本文标签
论文精读:HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。