寒假本科创新学习——机器学习(一)
徐徐同学 2024-06-14 09:31:06 阅读 64
绪论
1.1什么是机器学习1.1.1 Arthur Samuel给出的定义1.1.2 显著式编程和非显著式编程1.1.3 Tom Mitshell给出的定义 1.2基本术语
1.1什么是机器学习
1.1.1 Arthur Samuel给出的定义
Arthur Samuel是机器学习领域的先驱之一,
他编写了世界上第一个棋类游戏的人工智能程序
Arthur Samuel 的定义:
Machine Learning is Field of study that gives computers the ability to learn without being explicitly programmed.
机器学习是这样的领域,他赋予计算机学习的能力,(这种学习的能力)不是通过显著式编程获得的。
1.1.2 显著式编程和非显著式编程
什么是显著式编程 ?
举例来说:
比如我们要编写一个程序来自动区别苹果🍎和柠檬🍋,如果我们人为的告诉计算机苹果🍎是红色的,柠檬🍋是黄色的,所以计算机看到红色就把它识别为🍎,看到黄色就把它识别为🍋,这就是显著式编程
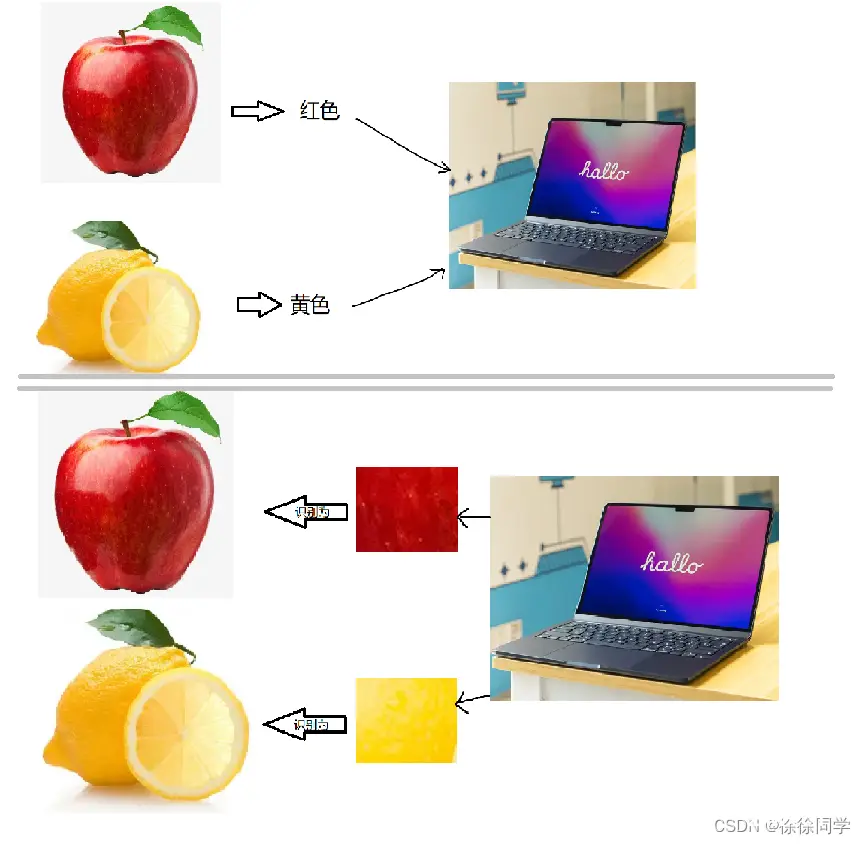
非显著式编程 ?
紧接上面的例子,如果我们只给计算机一堆🍎的图片,同时给计算机一堆🍋的图片,然后编写程序让计算机自己去总结🍎和🍋的区别(前提是编写的程序没毛病),那么计算机很有可能通过大量图片也能总结出苹果是红色、柠檬是黄色这个规律,当然,计算机也有可能总结出其他的规律。
我们事先并不约束计算机必须总结出什么规律,而是让计算机自己挑出最能区分🍎和🍋的一些规律,从而完成对苹果和柠檬的识别
↓
像这种让计算机自己总结规律的编程方法,叫做非显著式编程
Arthur Samuel所定义的机器学习是专指这种非显著式的编程方法
另一个例子
比如我们想让一个机器人去教室外给我们接一杯水
显著式的编程是这样的:首先我们要向这个机器人发出指令让它向左转(因为门在机器人的左边),然后我们要让它朝前走五步,接下来,让机器人右转,再向前走五步(走到咖啡机面前),然后我们发指令让机器人把杯子放在合适的位置,再让机器人点 “冲咖啡” 按钮,咖啡冲好之后,再次发指令,让机器人原路返回
由此可见,显著式编程有很大的劣势
我们必须帮机器人规划其所处环境,要把环境调查的一清二楚(机器人的位置在哪里,咖啡机在哪里,咖啡机上的按钮在哪里,机器人应该怎么走······)
(有这个时间为啥还要用机器人呢 ?)
这时候非显著式编程的优势就体现出来了
非显著式的编程是这样的:
首先我们规定机器人可以采取一系列的行为(向左转,向右转,取杯子,按按钮······),接下来,我们规定在特定的环境下,机器人做这些行为所带来的收益,叫做收益函数(比如机器人摔倒了,或者采取了某个行为导致撞到墙上、水洒出杯子,此时规定收益函数的值为负;如果机器人采取了某个行为 成功取到了咖啡,那么我们的程序就要“奖励”这个行为,规定此时收益函数的值为正)我们规定了行为和收益函数后,我们就不用管了,只需构造一个算法让计算机自己去找最大化收益函数的行为
可以想象,一开始计算机采用随机化的行为,但是只要我们的程序编的足够好,计算机是可能找到一个最大化收益函数的行为模式的
由此可见,非显著式编程的优势在于,它通过数据,经验自动的学习,完成我们交给它的任务
1.1.3 Tom Mitshell给出的定义
Tom Mitshell 在他的书《Machine Learning》中提出了一个比较正式的定义 :
A compute program is said to learn from experience E with respect to same task T and some performance measure P,if its performance on T,as measured by P, improves with experience E
一个计算程序被称为可以学习,是指它能够针对某个任务T和某个性能P,从经验E中学习,这种学习特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高
我们还是举最开始的那个例子,在这个苹果🍎和柠檬🍋的例子中
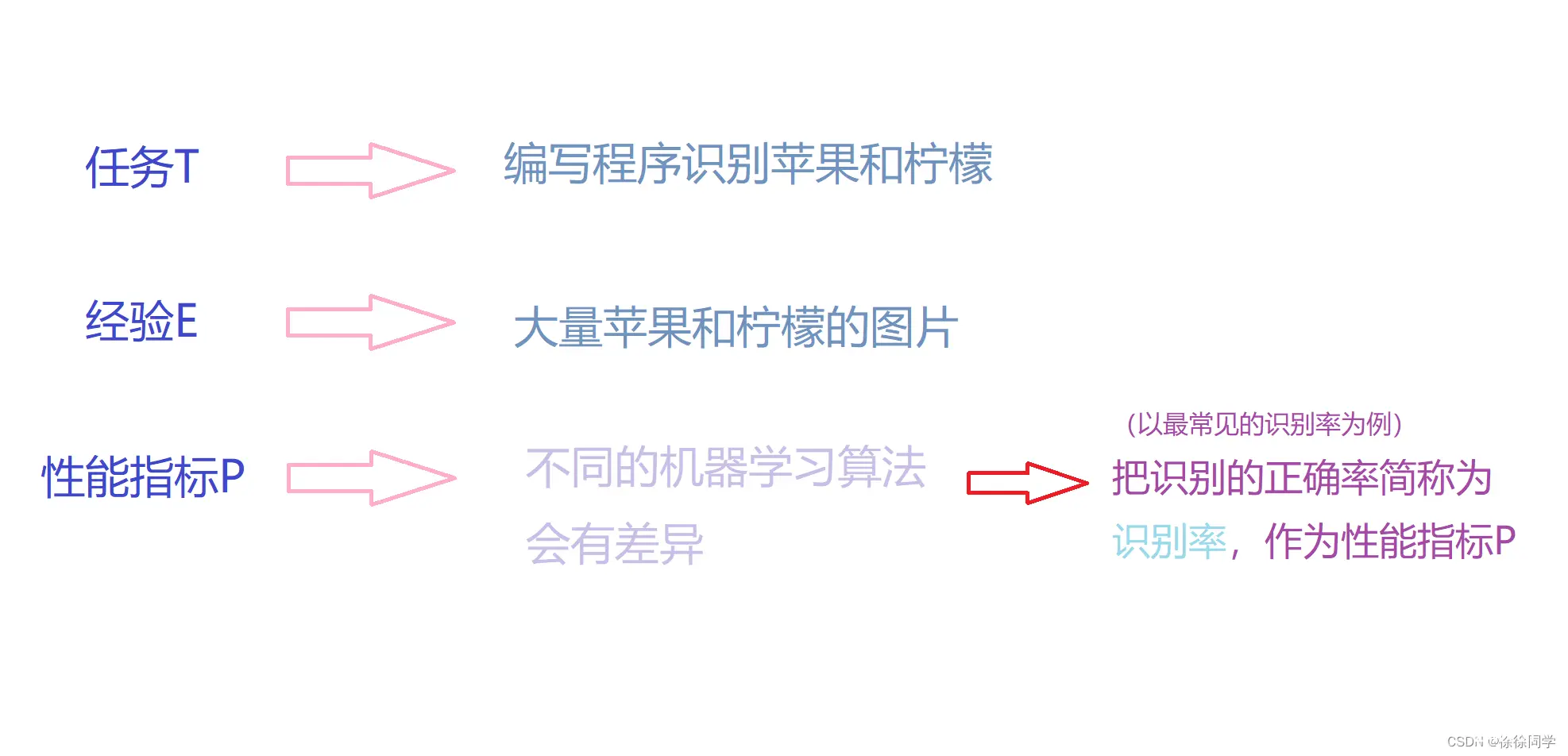
在机器学习中,把这大量苹果和柠檬的图片叫做训练样本(training samples)
根据Tom Mitshell对机器学习的定义,机器学习就是根据任务,来构造某种算法,这种算法的特点是当训练样本越来越多时(即E越来越多),识别率也会越来越高
显然,显著式编程是无法达到这个目的的
通过上面的描述可以看出,Tom Mitshell的定义比Arthur Samuel的定义更加数学化
根据经验E来提高性能指标P的过程是典型的最优化问题,数学中的最优化的各种理论都可运用其中,所以数学在现代机器学习中占有重要地位
1.2基本术语

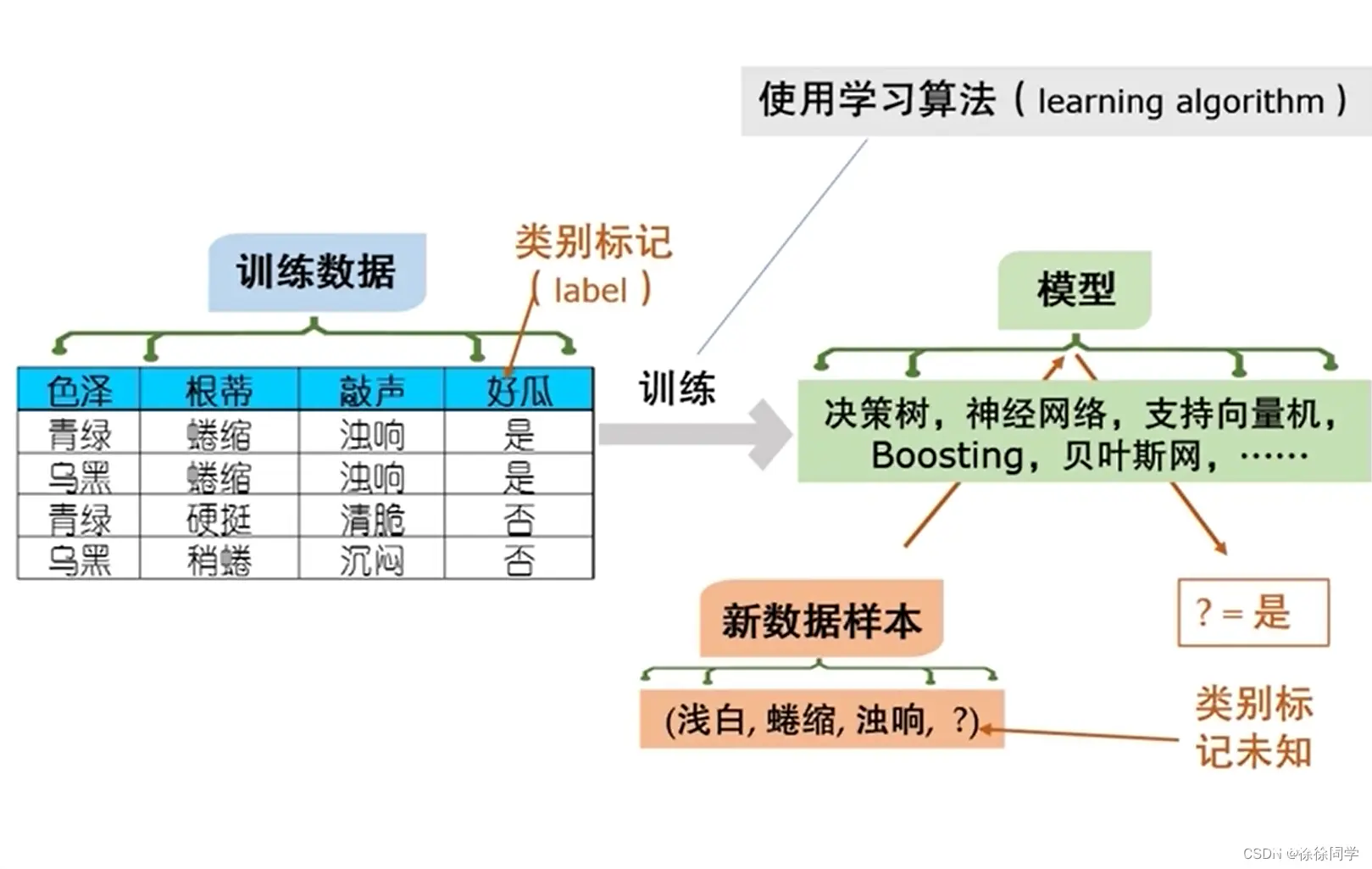
数据集:我们拿到所有数据构成的一个集合(即上图中《训练数据》这个表 )
训练:我们拿到数据用来建立这个模型,建立这个模型的过程就是训练
测试(test):建立这个模型之后,给一个新的数据,然后用这个模型判断这个数据做对or做错(其实就是使用这个模型)
测试数据的 结果/答案 应该是已知的,否则没法了解模型给出的结果是对是错;同时,为了得到一个客观的结果,测试数据和训练数据应该是分开的→测试数据一开始就应该留出来
🐖测试是把模型拿来用,而这个“用”,既可能是用来考察这个模型好不好,也可能是给个数据让模型真的给出结果
示例(instance)和样例(example):
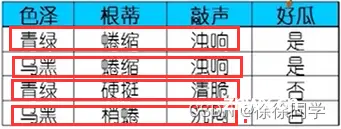
↑ 每一行就是一个示例(instance)
而每一行加上对应最后一列的 是或否,就是一个样例(example)
区别: example是有结果的,而instance是没有结果的
样本(example):概念比较模糊,有时候可以指每一个样例(example),有时候也可以指整个数据集
属性(attribute)= 特征(feature):表中瓜的色泽、根蒂、敲声都是属性/特征
属性值:可以理解为在某个属性上的 “取值”
比如,第一个瓜在色泽上的属性值是青绿
属性空间 (attribute space)= 样本空间(sample space)= 输入空间:把每个属性想象成一个坐标轴,属性张成的空间就是属性空间 / 样本空间
特征向量(feature vector):每个西瓜🍉都可以在属性空间中找到自己对应坐标的位置,由于空间中的每个点对应一坐标向量,因此我们也把一个示例(注意不是样例)成为一个“特征向量”
标记空间(label space)=输出空间:一般我们用(xi,yi)表示第 i 个样例,其中yi∈Y是示例xi的标记(label),Y是所有标记的集合,Y也称“标记空间” 或 “输出空间”
聚类(clustering)和簇(cluster):
聚类(clustering)是将集中训练的西瓜分成若干组,而分成的每个组称为一个簇(cluster)
这些自动形成的簇肯恶搞对应一些潜在的概念划分,例如“浅色瓜”和“深色瓜”,甚至“本地瓜”和“外地瓜”
这样的学习过程有助于我们了解数据内在的规律,为更深入的分析数据建立基础
监督学习(supervised learning) 和 无监督学习(unsupervised learning) :依据训练数据是否有标记信息,学习任务大致课分为监督学习 和 无监督学习,分类和回归是前者的代表,聚类是后者的代表

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。