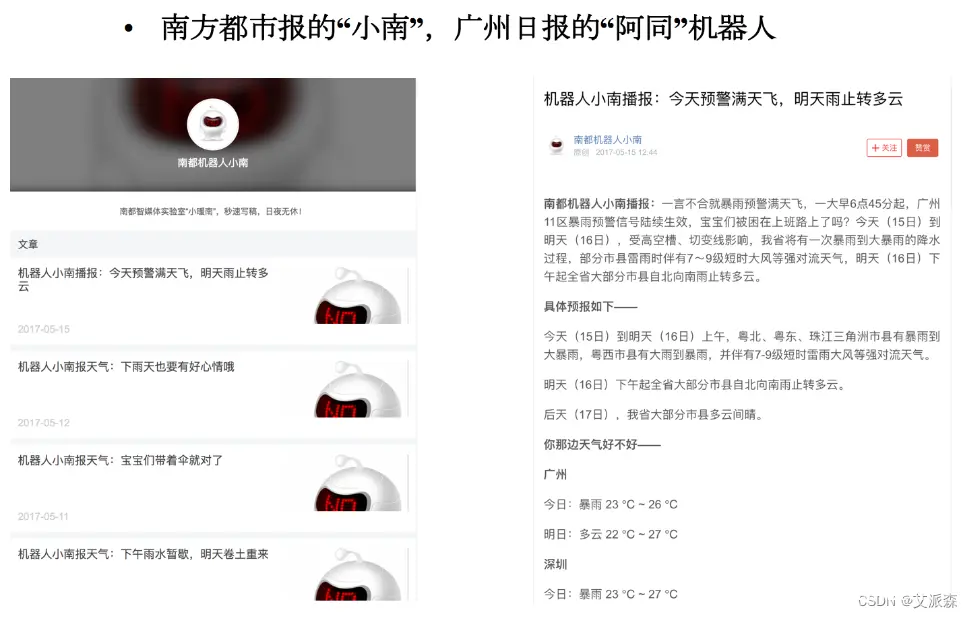
【机器学习】人工智能概述
艾派森 2024-06-23 11:01:15 阅读 72

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.人工智能概述
1.1 机器学习、人工智能与深度学习
1.2 机器学习、深度学习能做些什么
2.什么是机器学习
2.1 定义
2.2 解释
2.3 数据集构成
3.机器学习算法分类
4.机器学习开发流程
5.学习框架
6.文末福利
1.人工智能概述
1.1 机器学习、人工智能与深度学习
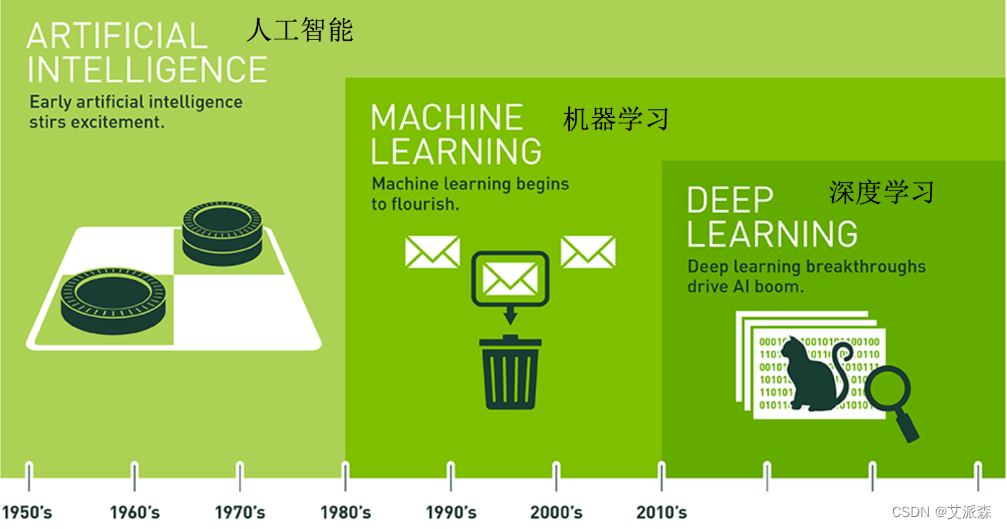
人工智能(AI):人工智能是一门研究如何使计算机能够模拟、理解和执行人类智能任务的学科。它的目标是让计算机具备类似于人类的智能水平,可以进行推理、学习、感知和决策。
机器学习:机器学习是人工智能的一个重要分支,它是让计算机通过从数据中学习和提取模式,自动改进执行特定任务的能力。在传统编程中,程序员需要明确指定计算机应该如何执行任务,而在机器学习中,计算机通过学习数据的规律和特征自主地进行任务执行,这种方式使得计算机在面对新的情况时也能做出合理的决策。
深度学习:深度学习是机器学习的一种方法,它是通过构建和训练深层神经网络来实现学习和特征提取的过程。这些深层神经网络由多个神经元层组成,允许计算机通过层次化的方式提取和学习数据中的复杂特征。深度学习在图像识别、自然语言处理、语音识别等领域取得了显著的成就,并且在人工智能的快速发展中起到了重要的推动作用。
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
深度学习是机器学习的一种技术手段,而机器学习是人工智能的一个重要组成部分。在实际应用中,深度学习带来了许多强大的AI模型和系统,使得计算机能够在复杂和大规模的数据中进行高效的学习和推理,从而实现了许多前所未有的人工智能应用。
达特茅斯会议-人工智能的起点
1956年8月,在美国汉诺斯小镇宁静的达特茅斯学院中,约翰·麦卡锡(John McCarthy),马文·闵斯基(Marvin Minsky,人工智能与认知学专家),克劳德·香农(Claude Shannon,信息论的创始人),艾伦·纽厄尔(Allen Newell,计算机科学家),赫伯特·西蒙(Herbert Simon,诺贝尔经济学奖得主)等科学家正聚在一起,讨论着一个完全不食人间烟火的主题:用机器来模仿人类学习以及其他方面的智能。会议足足开了两个月的时间,虽然大家没有达成普遍的共识,但是却为会议讨论的内容起了一个名字:人工智能。因此,1956年也就成为了人工智能元年。
1.2 机器学习、深度学习能做些什么
机器学习的应用场景非常多,可以说渗透到了各个行业领域当中。医疗、航空、教育、物流、电商等等领域的各种场景。

用在挖掘、预测领域:
应用场景:店铺销量预测、量化投资、广告推荐、企业客户分类、SQL语句安全检测分类…
用在图像领域:
应用场景:街道交通标志检测、人脸识别等等

用在自然语言处理领域:
应用场景:文本分类、情感分析、自动聊天、文本检测等等

2.什么是机器学习
2.1 定义
机器学习(Machine Learning)是一种人工智能(AI)的分支,它是通过计算机系统从数据中学习和改进执行特定任务的能力,而无需明确编程指令。换句话说,机器学习使得计算机可以通过数据的模式和规律,自动提取特征和知识,并在未来面对新的数据时做出合理的决策。
传统的程序设计中,程序员需要编写明确的规则和算法,以指导计算机完成特定任务。但在机器学习中,我们提供给计算机的是一组训练数据,包含输入和对应的输出结果。计算机通过对这些数据进行学习,找到数据中的模式和规律,从而能够在未来的数据中进行预测或分类。
机器学习任务可以分为以下几类:
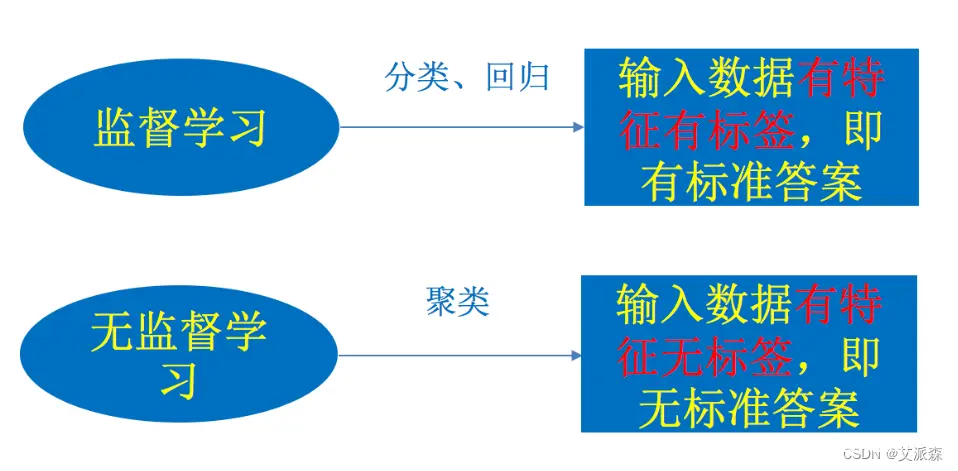
监督学习(Supervised Learning):在监督学习中,我们向计算机提供带有标签的训练数据,也就是输入数据和对应的正确输出。计算机通过学习这些数据来建立输入和输出之间的映射关系,从而能够预测未标记数据的输出。
无监督学习(Unsupervised Learning):在无监督学习中,我们向计算机提供没有标签的训练数据,计算机需要自主地发现数据中的结构和模式。无监督学习常用于聚类、降维和异常检测等任务。
强化学习(Reinforcement Learning):强化学习是一种通过尝试和错误来学习最佳决策策略的学习方法。在强化学习中,计算机代理根据环境的反馈(奖励或惩罚)不断调整策略,以最大化累积的奖励。
2.2 解释
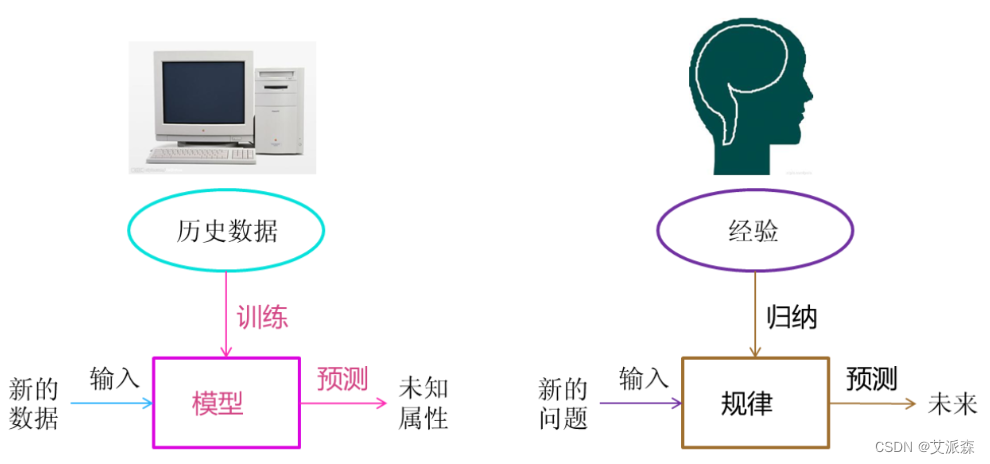
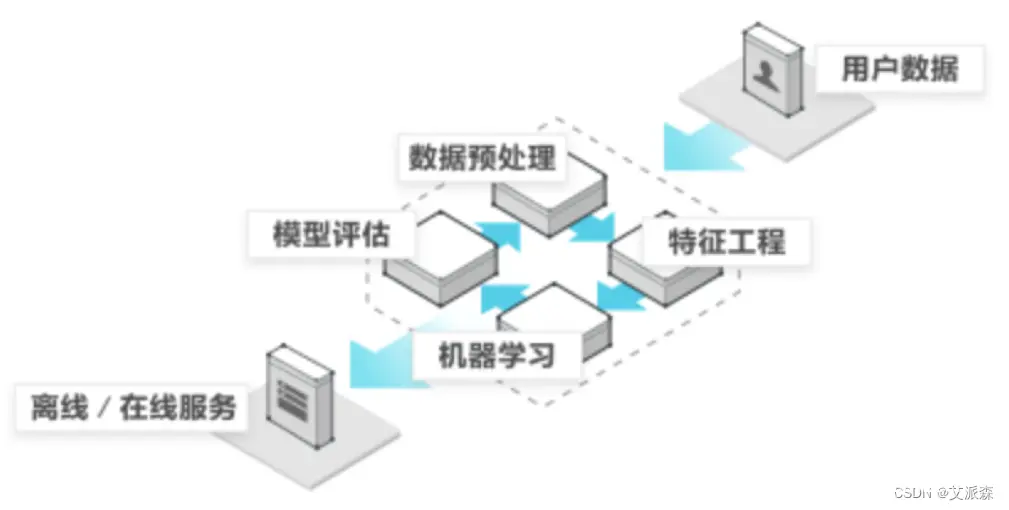
我们人从大量的日常经验中归纳规律,当面临新的问题的时候,就可以利用以往总结的规律去分析现实状况,采取最佳策略。从数据(大量的猫和狗的图片)中自动分析获得模型(辨别猫和狗的规律),从而使机器拥有识别猫和狗的能力。基于tensorflow深度学习的猫狗分类识别从数据(房屋的各种信息)中自动分析获得模型(判断房屋价格的规律),从而使机器拥有预测房屋价格的能力。基于随机森林模型对北京房价进行预测
从历史数据当中获得规律?这些历史数据是怎么的格式?
2.3 数据集构成
结构:特征值+目标值
注:
对于每一行数据我们可以称之为 样本。有些数据集可以没有目标值:
3.机器学习算法分类
特征值:猫/狗的图片;目标值:猫/狗-类别 分类问题 特征值:房屋的各个属性信息;目标值:房屋价格-连续型数据 回归问题特征值:人物的各个属性信息;目标值:无 无监督学习
监督学习(supervised learning)(预测) 定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络回归 线性回归、岭回归无监督学习(unsupervised learning) 定义:输入数据是由输入特征值所组成。聚类 k-means
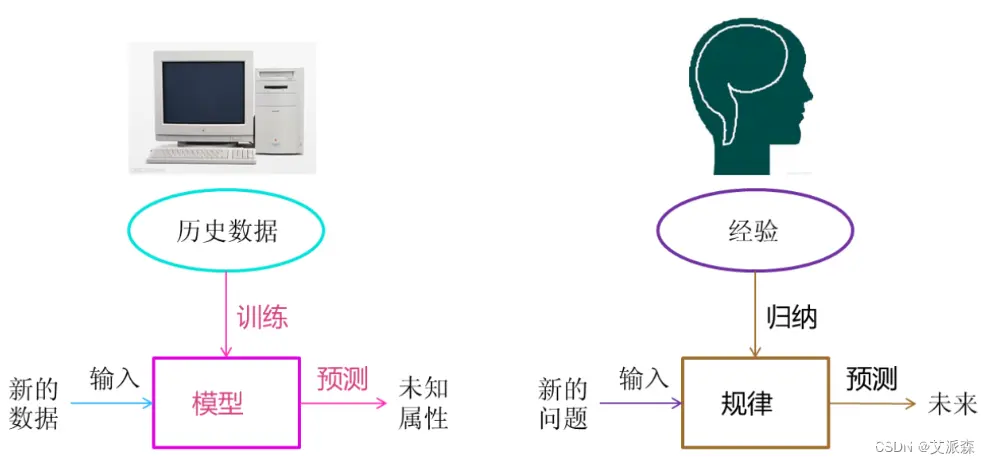
4.机器学习开发流程
流程图:
5.学习框架
需明确几点问题:
(1)算法是核心,数据与计算是基础
(2)找准定位
大部分复杂模型的算法设计都是算法工程师在做,而我们
分析很多的数据分析具体的业务应用常见的算法特征工程、调参数、优化
我们应该怎么做?
学会分析问题,使用机器学习算法的目的,想要算法完成何种任务
掌握算法基本思想,学会对问题用相应的算法解决学会利用库或者框架解决问题
当前重要的是掌握一些机器学习算法等技巧,从某个业务领域切入解决问题。
机器学习库与框架:

6.文末福利
《PySpark机器学习、自然语言处理与推荐系统》免费包邮送出3本!
内容简介:
使用PySpark构建机器学习模型、自然语言处理应用程序以及推荐系统,从而应对各种业务挑战。该书首先介绍Spark的基础知识及其演进,然后讲解使用PySpark构建传统机器学习算法以及自然语言处理和推荐系统的全部知识点。
《PySpark机器学习、自然语言处理与推荐系统》阐释如何构建有监督机器学习模型,比如线性回归、逻辑回归、决策树和随机森林,还介绍了无监督机器学习模型,比如K均值和层次聚类。该书重点介绍特征工程,以便使用PySpark创建有用的特征,从而训练机器学习模型。自然语言处理的相关章节将介绍文本处理、文本挖掘以及用于分类的嵌入。
在阅读完该书后,读者将了解如何使用PySpark的机器学习库构建和训练各种机器学习模型。此外,还将熟练掌握相关的PySpark组件,比如数据获取、数据处理和数据分析,通过使用它们开发数据驱动的智能应用。
编辑推荐:
适读人群 :数据科学家、机器学习工程师
使用PySpark构建机器学习模型、自然语言处理应用程序以及推荐系统,从而应对各种业务挑战。本书首先介绍Spark的基础知识,然后讲解使用PySpark构建传统机器学习算法以及自然语言处理和推荐系统的全部知识点。
本书阐释了如何构建有监督机器学习模型,比如线性回归、逻辑回归、决策树和随机森林,还介绍了无监督机器学习模型,比如K均值和层次聚类。本书重点介绍特征工程,以便使用PySpark创建有用的特征,从而训练机器学习模型。自然语言处理的相关章节将介绍文本处理、文本挖掘以及用于分类的嵌入。
在阅读完本书之后,读者将了解如何使用PySpark的机器学习库构建和训练各种机器学习模型。此外,还将熟练掌握相关的PySpark组件,从而进行数据获取、数据处理和数据分析,开发数据驱动的智能应用。
抽奖方式:评论区随机抽取3位小伙伴免费送出!参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”( 切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)活动截止时间: 2023-09-08 20:00:00 购买链接:https://item.jd.com/12611069.html
名单公布时间:2023-09-08 21:00:00
清华大学出版社9月“秋日阅读企划”活动开始啦,五折叠加无门槛优惠卷,点击即刻拥有!
领卷地址:
APP:https://pro.m.jd.com/mall/active/2Z3HoZGKy5i9aEpmoTUZnmcoAhHg/index.html
PC:https://pro.jd.com/mall/active/2Z3HoZGKy5i9aEpmoTUZnmcoAhHg/index.html
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。