RAG 入门指南:从零开始构建一个 RAG 系统
AIGC大模型 吱屋猪 2024-10-03 14:01:01 阅读 71
本文正文字数约 3300 字,阅读时间 10 分钟。
从零开始构建一个应用可以让我们快速理解应用的各个部分。
这个方法其实非常适用于 RAG。
我在以前的文章中有介绍过 RAG 的概念、原理以及应用等,但其实,亲自动手来构建一个 RAG 系统或许能够让我们更快速的理解 RAG 到底是什么。
本文将为读者提供一个从零开始搭建一个 RAG 应用的入门教程。
RAG 简介
在开始之前,我还是打算再次简要的介绍一下 RAG。
在 Meta 的官方 Blog 上有这样一段话:
Building a model that researches and contextualizes is more challenging, but it’s essential for future advancements. We recently made substantial progress in this realm with our Retrieval Augmented Generation (RAG) architecture, an end-to-end differentiable model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq2seq generator (our Bidirectional and Auto-Regressive Transformers BART model). RAG can be fine-tuned on knowledge-intensive downstream tasks to achieve state-of-the-art results compared with even the largest pretrained seq2seq language models. And unlike these pretrained models, RAG’s internal knowledge can be easily altered or even supplemented on the fly, enabling researchers and engineers to control what RAG knows and doesn’t know without wasting time or compute power retraining the entire model.
这段话主要讲述了一个新的模型架构,也就是 RAG (检索增强生成) 的重要性和优势。可以概括为以下几点:
1. 构建一个能够进行研究和上下文分析的模型虽然更具挑战性,但对未来的技术进步非常关键;
2. 通过在知识密集的下游任务上微调,RAG 可以实现最先进的结果,比现有的最大的预训练序列到序列语言模型还要好;
3. 与传统的预训练模型不同,RAG 的内部知识可以轻松地动态更改或补充。也就是说,研究人员和工程师可以控制 RAG 知道和不知道的内容,而不需要浪费时间或计算资源重新训练整个模型。
这段话信息量很大,但是作为初学者,简而言之:
RAG 的本质是在传递给 LLM 的提示语中,通过一个检索工具来添加自己的数据。
接下来,我们就要开始准备我们的 RAG 应用了。
RAG 系统的高层组件
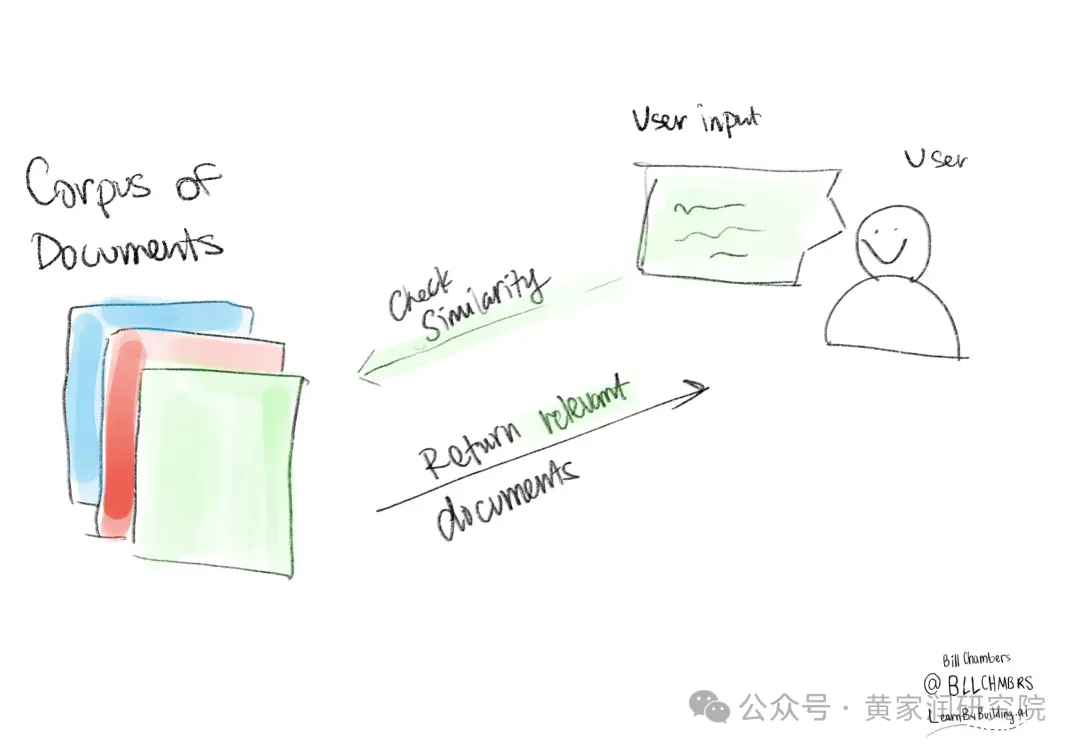
• 一组文档,正式说法为语料库
• 用户输入
• 语料库和用户输入之间的相似性度量
这是简化版的 RAG 组件系统,我们不需要考虑向量存储,甚至目前还不需要 LLM。
以下是一篇 RAG 论文中的系统概述:
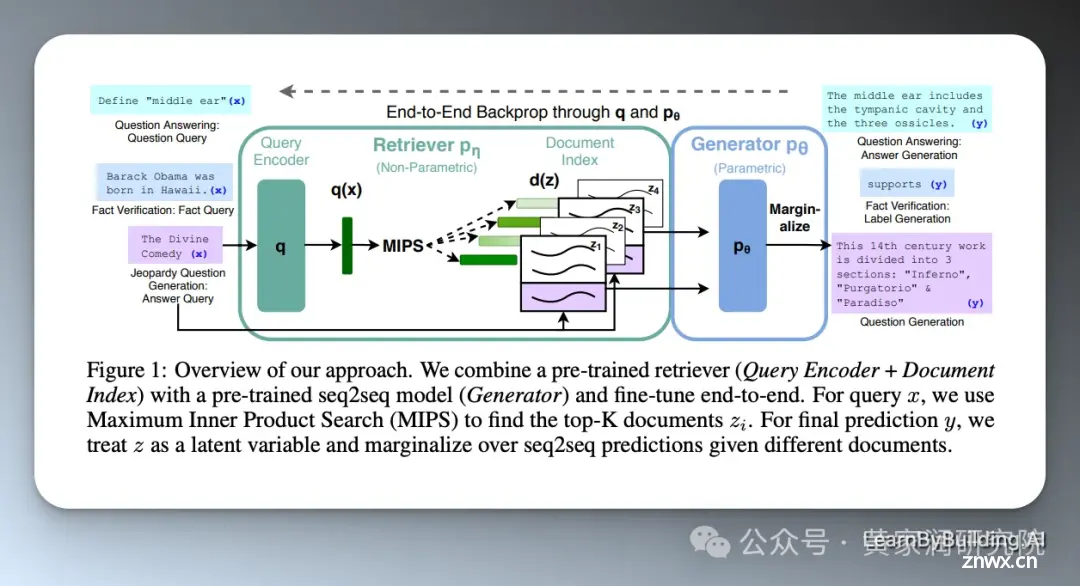
它假设了很多背景信息,比我们预设的简化版要复杂的多。
对于想要深入研究的人来说,这篇论文很有价值,但是对于我们想要入门的人来说,通过一步一步构建自己的 RAG 系统来学习才更适合。
RAG 系统的查询步骤
查询用户输入
进行相似性度量
对用户输入和检索到的文档进行后处理
这里的后处理即将检索到的文档和用户输入发送给 LLM 进行处理,最终生成回答。
相似性度量是指用来评估两个对象之间相似程度的方法。在文本处理和信息检索中,相似性度量可以帮助我们确定两个文本之间的相似度。在 RAG 系统中,我们可以使用这些相似性度量方法之一来比较用户输入和文档集合中的每个文档,从而找到最相关的文档。
从零开始构建 RAG 系统
现在,我们将以一个具体的案例从零开始来构建一个 RAG 系统。
以下是简化版的流程图。
以下是具体步骤。
获取文档集合
我们首先定义一个简单的文档语料库。
corpus_of_documents = [ "Take a leisurely walk in the park and enjoy the fresh air.", "Visit a local museum and discover something new.", "Attend a live music concert and feel the rhythm.", "Go for a hike and admire the natural scenery.", "Have a picnic with friends and share some laughs.", "Explore a new cuisine by dining at an ethnic restaurant.", "Take a yoga class and stretch your body and mind.", "Join a local sports league and enjoy some friendly competition.", "Attend a workshop or lecture on a topic you're interested in.", "Visit an amusement park and ride the roller coasters." ]
定义和执行相似性度量
现在我们需要一种方法来衡量我们将要接收的用户输入与我们组织的文档集合之间的相似性。
可以说,最简单的相似性度量是杰卡德相似性。
杰卡德相似性(Jaccard Similarity)是一种衡量两个集合相似程度的简单方法。它计算两个集合的交集和并集的比例,用于比较两个文本之间的相似性。简而言之就是,杰卡德相似性看两个集合中共同元素的数量占所有元素的总数量的比例。
对语料库进行预处理
由于我们需要进行相似性度量,所以需要将字符串处理成集合。
我们可以使用最简单的方式来进行预处理,也就是将字符串转换为小写并按照空格分割。
# 将语料库字符串按照空格分割,并返回杰卡德相似性的结果 def jaccard_similarity(query, document): query = query.lower().split(" ") document = document.lower().split(" ") intersection = set(query).intersection(set(document)) union = set(query).union(set(document)) return len(intersection)/len(union)
然后,我们需要定义一个函数,该函数接受用户的精确查询和我们的语料库,并根据相似性的结果将最匹配的文档返回给用户。
def return_response(query, corpus): similarities = [] for doc in corpus: similarity = jaccard_similarity(user_input, doc) similarities.append(similarity) return corpus_of_documents[similarities.index(max(similarities))]
现在,我们可以试着运行一下。
定义用户查询输入。
user_input = "I like to hike"
将输出的结果打印出来。
print(return_response(user_input, corpus_of_documents))

如果不想在自己电脑上配置 Python 环境,可以直接使用线上的 Python 编辑器,比如:https://www.programiz.com/python-programming/online-compiler/
至此,我们已经构建出了一个最基本的 RAG 系统。
相似性问题
由于我们选择了一个非常简单的相似性度量方法来学习,所以会带来一些问题。
它没有语义概念,只是简单地看两个文档中有哪些词,然后进行对比。
也就是说,只要我们提供的用户输入里包含这些词,那么我们就会得到相同的结果,因为那就是最接近的文档。
比如,我将用户输入换成了 user_input = "I don't like to hike"。

输出结果和上文的输出结果一样。
这是一个在 RAG 中会经常遇到的话题,我们会在后面解决这个问题。
目前,我们还没有对我们检索到的文档进行任何后处理。只是实现了 RAG 的「检索」功能。
下一步是通过结合 LLM 来增强生成。
添加 LLM
要方便快捷的添加 LLM,我们可以直接在本地机器上运行一个开源的 LLM。
这里,我将使用 Ollama 的 Llama 3.1 模型。当然,你也可以使用 OpenAI 的 GPT-4 或 Anthropic 的 Claude 或者其他 LLM。
可以到 ollama 官网下载安装自己想要的 LLM:https://ollama.com/
现在,我们需要对代码做些修改了。
如果是在本地运行 LLM,那么,你需要在自己电脑上配置好 Python 相关的环境,这样在后续步骤中,才能将代码运行起来。
现在,需要引入一些库。
import requests import json
我们的步骤会有所变化:
1. 获取用户输入;
2. 获取最相似的文档(通过我们的相似性度量来衡量);
3. 将这个文档作为提示语传递给 LLM;
4. 最后将结果返回给用户。
user_input = "I like to hike" relevant_document = return_response(user_input, corpus_of_documents) full_response = [] prompt = """ You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information. This is the recommended activity: {relevant_document} The user input is: {user_input} Compile a recommendation to the user based on the recommended activity and the user input. """
定义好以上步骤之后,我们现在来调用 Ollama 的 API。
在编辑此代码之前,你需要先运行 LLM 在后台,直接在命令行里输入 ollama serve 即可。
url = 'http://localhost:11434/api/generate' data = { "model": "llama3.1", "prompt": prompt.format(user_input=user_input, relevant_document=relevant_document) } headers = {'Content-Type': 'application/json'} response = requests.post(url, data=json.dumps(data), headers=headers, stream=True) try: count = 0 for line in response.iter_lines(): if line: decoded_line = json.loads(line.decode('utf-8')) full_response.append(decoded_line['response']) finally: response.close() print(''.join(full_response))
运行以上代码,即可看到结果。

现在我们已经从零开始构建了一个完整的 RAG 系统。
现在 LLM 就可以直接帮我们处理上文提到的相似性问题。如果把用户输入改成 I don't like to hike.,那么我们会得到以下这样的回答。

总结以及改进点
尽管我们已经搭建出了一个完整的 RAG 系统,但是,真实场景下的 RAG 系统也许会更加复杂,涉及向量数据库(Vector Database)、嵌入(Embedding)和提示语工程(Prompt Engineering)等。
如果想要更加深入的学习 RAG,你也许需要在此基础之上考虑以下的一些改进点。
文档数量:更多的文档可能意味着更多的推荐,目前,我们只给 LLM 提供一个文档。我们可以输入多个文档作为“上下文”,让模型根据用户输入提供更个性化的推荐。
文档的深度/大小:更高质量的内容和包含更多信息的长文档可能更好。
提供给 LLM 的文档部分:如果我们有更大或更全面的文档,我们可能只想添加这些文档的部分内容,或者多个文档的部分内容,或一些变体。在词汇中,这称为分块(chunking)。
文档存储工具:我们可能会以不同的方式或不同的数据库存储文档。特别是如果我们有大量文档,可能会考虑将它们存储在向量存储中。
相似性度量:我们如何衡量相似性是至关重要的,我们可能需要在性能和全面性之间权衡。
文档和用户输入的预处理:我们可以在将用户输入传递给相似性度量之前进行一些额外的预处理或增强。例如,我们可以使用嵌入将输入转换为向量。
提示语:我们可以对 LLM/模型使用不同的提示语,并根据我们想要的输出进行调整,以获得我们想要的结果。
你可以在我的 GitHub 上获取到本文所有代码:https://github.com/Erichain/ai-application-demos/blob/main/create-rag-from-scratch.py
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享]👈
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
目标:了解AI大模型的基本概念、发展历程和核心原理。内容:
L1.1 人工智能简述与大模型起源L1.2 大模型与通用人工智能L1.3 GPT模型的发展历程L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。内容:
L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用L2.4 总结与展望
阶段3:AI大模型应用架构实践
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。内容:
L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。内容:
L4.1 模型私有化部署概述L4.2 模型私有化部署的关键技术L4.3 模型私有化部署的实施步骤L4.4 模型私有化部署的应用场景
学习计划:
阶段1:1-2个月,建立AI大模型的基础知识体系。阶段2:2-3个月,专注于API应用开发能力的提升。阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享👈

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。