电气设备施工现场风险状态判断ai模型训练数据集
qq767172261 2024-10-02 17:31:17 阅读 59
电气设备施工现场风险状态判断ai模型训练数据集

id:18 电气设备施工现场工人人工智能学习数据和工作环境安全数据,建立系统化管理体系,改变全球EHS范式,预防工业事故。数据集记录了387709例子电力设施建设以及施工现场相关的灾害安全环境数据,格式为jpg;同时以边界框、关键点作为标签,主要以json记录。


电气设备施工现场风险状态判断AI模型训练数据集
数据集描述
该数据集是一个专门用于电气设备施工现场风险状态判断的数据集,旨在帮助研究人员和开发者训练和评估基于深度学习的安全监测和风险评估模型。数据集涵盖了电力设施建设以及施工现场的各种工作环境,记录了大量灾害安全环境案例,并提供了详细的标注信息。通过高质量的图像和多种类型的标注(边界框、关键点),该数据集为开发高效且准确的安全管理系统提供了坚实的基础。
数据规模
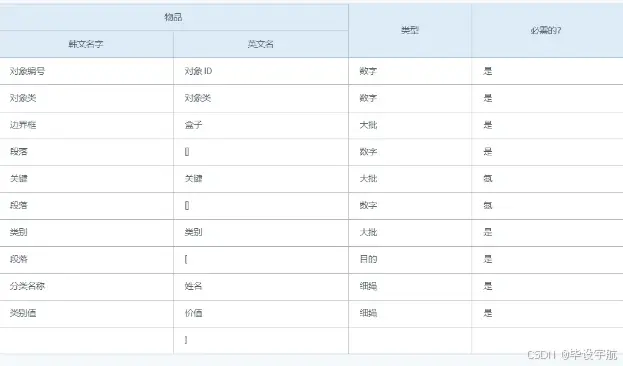
总样本数量:387,709张图片标注格式:JSON格式标签类型:
边界框 (Bounding Box)关键点 (Keypoints)
图像特性
多样化场景:覆盖了不同类型的电气设备施工现场的工作环境,包括高压输电线路建设、变电站施工、电缆敷设等。高质量手工标注:每张图像都有详细的标注信息,支持直接用于训练目标检测和关键点检测模型。真实拍摄:所有图像均为实际拍摄的真实场景,增强了模型在实际应用中的鲁棒性。多类别支持:包含多种不同类型的安全隐患和工作环境状态,丰富了数据集的多样性。无需预处理:数据集已经过处理,可以直接用于训练,无需额外的数据预处理步骤。
应用场景
智能监控:自动检测施工现场的安全隐患,辅助管理人员及时发现并采取应对措施,提高现场安全性。风险评估:通过分析图像中的关键点信息,进行详细的风险评估,提前预警潜在的安全风险。科研分析:用于研究目标检测和关键点检测算法在特定工业应用场景中的表现,特别是在复杂背景和光照条件下的鲁棒性。教育与培训:可用于安全相关的教育和培训项目,帮助学生和从业人员更好地识别和理解施工现场的安全隐患。系统化管理:集成到电气设备施工现场的管理系统中,实现对工作环境的自动化监测和管理,预防工业事故。
数据集结构
典型的数据集目录结构如下:
深色版本
<code>1electrical_construction_safety_dataset/
2├── images/
3│ ├── img_000001.jpg
4│ ├── img_000002.jpg
5│ └── ...
6├── annotations/
7│ ├── img_000001.json
8│ ├── img_000002.json
9│ └── ...
10├── README.txt # 数据说明文件
数据说明
检测目标:以JSON格式进行标注,包含边界框和关键点信息。数据集内容:
总共387,709张图片,每张图片都带有相应的JSON标注文件。标签类型:
边界框 (Bounding Box):用于标记图像中的物体位置,如工人、设备、危险区域等。关键点 (Keypoints):用于标记图像中的重要特征点,如工人的关节位置、设备的关键部位等。数据增广:数据集未做数据增广,用户可以根据需要自行进行数据增广。无需预处理:数据集已经过处理,可以直接用于训练,无需额外的数据预处理步骤。
示例代码
以下是一个使用Python和相关库(如OpenCV、PIL等)来加载和展示数据集的简单示例代码:
1import os
2import cv2
3import numpy as np
4from PIL import Image
5import json
6
7# 数据集路径
8dataset_path = 'path/to/electrical_construction_safety_dataset/'
9
10# 加载图像和标注
11def load_image_and_annotations(image_path, annotation_path):
12 # 读取图像
13 image = Image.open(image_path).convert('RGB')
14
15 # 读取并解析JSON格式的标注文件
16 with open(annotation_path, 'r') as f:
17 annotation = json.load(f)
18
19 # 解析边界框和关键点信息
20 bboxes = []
21 keypoints = []
22
23 for obj in annotation['objects']:
24 if 'bbox' in obj:
25 bboxes.append(obj['bbox'])
26 if 'keypoints' in obj:
27 keypoints.append(obj['keypoints'])
28
29 return image, bboxes, keypoints
30
31# 展示图像和标注
32def show_image_with_annotations(image, bboxes, keypoints):
33 img = np.array(image)
34
35 # 绘制边界框
36 for bbox in bboxes:
37 x, y, w, h = bbox
38 cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
39
40 # 绘制关键点
41 for kps in keypoints:
42 for kp in kps:
43 x, y = kp
44 cv2.circle(img, (int(x), int(y)), 5, (255, 0, 0), -1)
45
46 cv2.imshow('Image with Annotations', img)
47 cv2.waitKey(0)
48 cv2.destroyAllWindows()
49
50# 主函数
51if __name__ == "__main__":
52 images_dir = os.path.join(dataset_path, 'images')
53 annotations_dir = os.path.join(dataset_path, 'annotations')
54
55 # 获取图像列表
56 image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
57
58 # 随机选择一张图像
59 selected_image = np.random.choice(image_files)
60 image_path = os.path.join(images_dir, selected_image)
61 annotation_path = os.path.join(annotations_dir, selected_image.replace('.jpg', '.json'))
62
63 # 加载图像和标注
64 image, bboxes, keypoints = load_image_and_annotations(image_path, annotation_path)
65
66 # 展示带有标注的图像
67 show_image_with_annotations(image, bboxes, keypoints)
这段代码展示了如何加载图像和其对应的边界框和关键点标注文件,并在图像上绘制这些标注。您可以根据实际需求进一步扩展和修改这段代码,以适应您的具体应用场景。
改进方向
如果您已经使用YOLOv3、YOLOv5等模型对该数据集进行了训练,并且认为还有改进空间,以下是一些可能的改进方向:
数据增强:
进一步增加数据增强策略,例如旋转、翻转、缩放、颜色抖动等,以提高模型的泛化能力。使用混合增强技术,如MixUp、CutMix等,以增加数据多样性。
模型优化:
调整模型超参数,例如学习率、批量大小、优化器等,以找到最佳配置。尝试使用不同的骨干网络(Backbone),例如EfficientNet、ResNet等,以提高特征提取能力。引入注意力机制,如SENet、CBAM等,以增强模型对关键区域的关注。
损失函数:
尝试使用不同的损失函数,例如Focal Loss、IoU Loss等,以改善模型的收敛性能。结合多种损失函数,例如分类损失和回归损失的组合,以平衡不同类型的任务。
后处理:
使用非极大值抑制(NMS)的改进版本,如Soft-NMS、DIoU-NMS等,以提高检测结果的质量。引入边界框回归的改进方法,如GIoU、CIoU等,以提高定位精度。
迁移学习:
使用预训练模型进行微调,利用大规模数据集(如COCO、ImageNet)上的预训练权重,加快收敛速度并提高性能。
集成学习:
使用多个模型进行集成学习,通过投票或加权平均的方式提高最终的检测效果。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。