深入调研亚马逊云科技AI平台Amazon Bedrock热门开发功能
CSDN 2024-09-01 15:01:02 阅读 64
国际数据公司(IDC)在2024 年 8 月发布了《 中国大模型平台市场份额, 2023 :大模型元年——初局 》调研报告 。IDC的数据显示,2023年中国大模型平台及相关应用市场规模达惊人的17.65亿元人民币,且科学计算大模型仍处于蓝海市场,市场中有大量的AI相关的市场和岗位需求。根据麦肯锡报告显示,对该领域的人才需求将从目前的100万增长到2030年的600万,这表明在未来AI就业市场仍有大量机会,提前布局学习AI相关技能将提前享受AI带来的红利。
今天小李哥就带大家学习、深入调研来自目前全球市场规模最大的云计算厂商亚马逊云科技AWS推出的大模型平台Amazon Bedrock,学习国际目前最前沿的AI热门技术和方案,沉浸式体验Bedrock一些列的云开发实用功能,并将其应用到日常工作、项目中,提升实操技能的同时加速职场。
方案所需基础知识
Amazon Bedrock 是一项完全托管的服务,通过统一的 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI 和 Amazon 等领先 AI 公司的高性能基础模型(FMs),同时提供广泛的功能,让开发者能够在确保安全、隐私和负责任 AI 的前提下构建生成式 AI 应用。
使用 Amazon Bedrock,开发者们可以:
轻松地测试、评估开发者的用例在不同基础模型下的表现;使用微调和检索增强生成(RAG)等技术定制化开发应用程序;构建可以使用开发者的企业系统和数据源自动执行任务的智能 Agents。
由于 Amazon Bedrock 是 Serverless 的服务,开发者无需管理任何基础设施,并且可以使用开发者已经熟悉其它的亚马逊云科技服务安全地集成和部署生成式 AI 功能到开发者的应用中。
成本预估:
在本实践中,我们主要介绍通过 Amazon Bedrock 基础模型及其使用方法、模型评估、安全围栏等功能。 不同功能模块的价格计费方式不同,具体可以参考亚马逊云科技官方计费模型。
如果大家按照我指导的内容完成本动手实践,其消耗的云服务成本应小于 5 美元(约35元人民币)。
本实践包括的内容
1. 使用控制台和API代码调用的方式与AI大模型交互
2. 利用Amazon Bedrock模型评估功能对大模型性能评估
3. 利用Amazon Bedrock Guardrails功能筛选AI大模型输入、输出内容中的有害内容,构建负责任的AI
功能实践具体步骤
使用控制台和API代码调用的方式与AI大模型交互
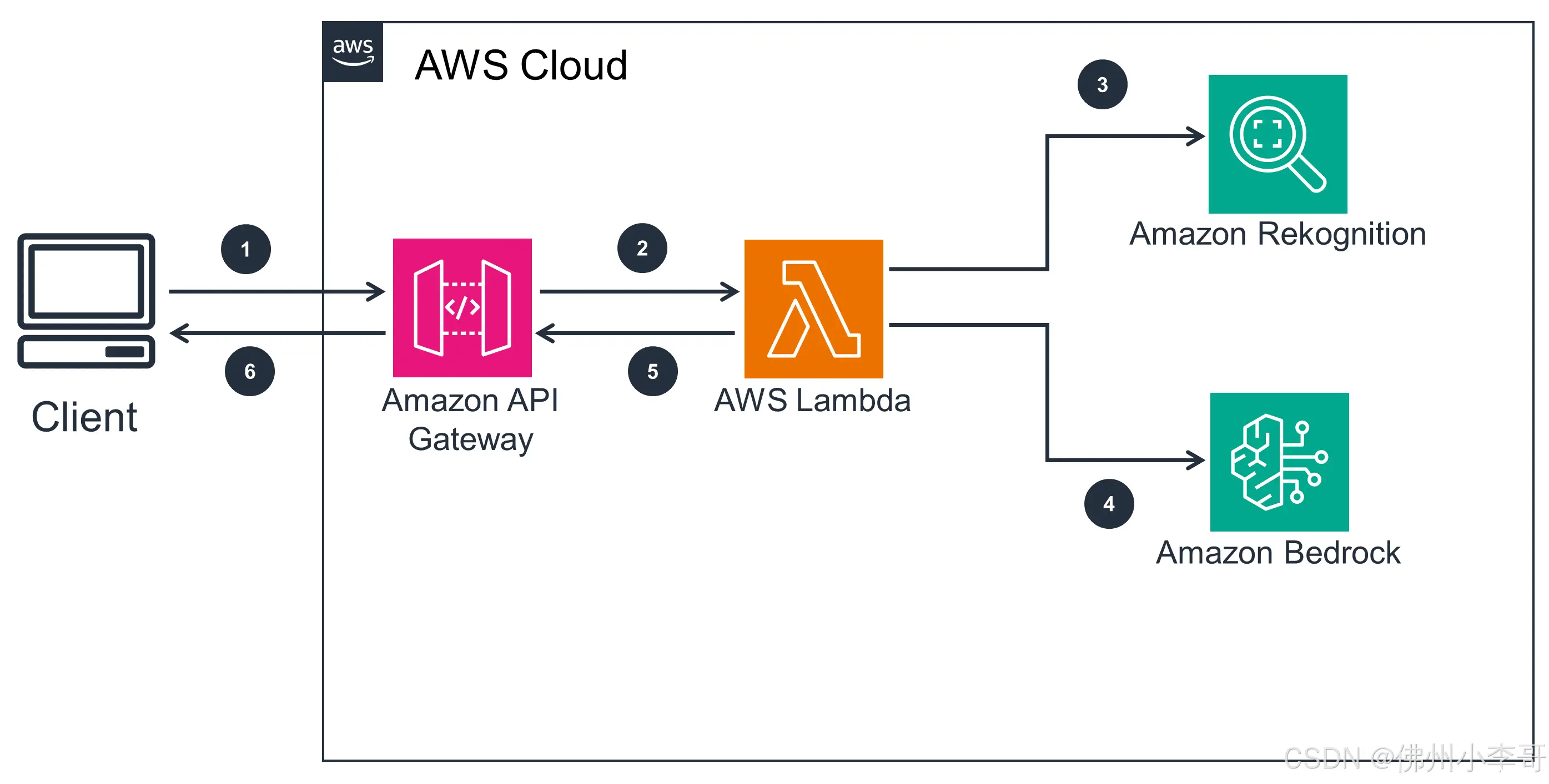
1. 进入亚马逊云科技Amazon Bedrock服务主页,
2. 在左侧导航栏,在 Playgrounds 中我们可以看到 Chat, Text, Image 三个功能模块,含义分别为:
Chat: 在对话式界面中,轻松尝试各种语言处理任务。您可以体验多种预训练模型。Text: 通过快速迭代,在各种语言处理任务中进行实验,尝试多种预训练模型。Image: 只需向预训练模型提供文字提示,即可轻松生成引人入胜的图像。
3. 我们点击左侧的Chat功能,并点击”Slect Model“选择模型。
4.我们选择Meta最新的AI大模型Llama 3.1 70B,来体验其强大的推理能力和中文处理能力,点击应用(Apply):
5. 接下来我们利用Llama 3.1大模型的生成能力,帮我们设计一个上海2日游的行程。将该问题输入到聊天窗口中,将响应长度调整到 2048(防止返回结果因为 token 限制被截断;UI 上的限制为 2048 token,此模型 API 支持的最大 token 为 8k),点击运行(Run):
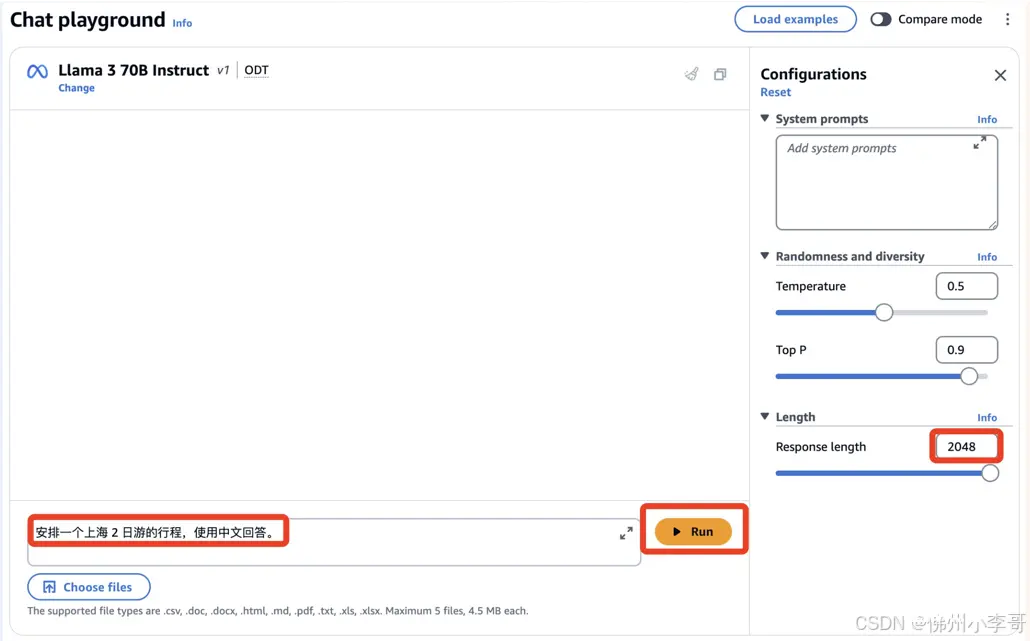
6. 我们得到大模型给我们回复的行程计划
<code>**Day 1**
**上午**
* 9:00 am: 开始于上海的标志性建筑 - 东方明珠电视塔( Oriental Pearl Tower),登塔顶俯瞰上海全景。
* 10:30 am: 从东方明珠电视塔步行到浦东陆家嘴金融区,欣赏上海的摩天大楼和繁华都市景象。
**下午**
* 1:00 pm: 去人民广场(People's Square)附近的南京路步行街,感受上海的商业气息和人流。
* 3:00 pm: 访问上海博物馆(Shanghai Museum),了解上海的历史和文化。
**晚上**
* 7:00 pm: 去外滩(The Bund)欣赏黄浦江两岸的美景,观看夜晚的灯光秀。
* 9:00 pm: 在外滩附近的餐厅享用上海特色小吃和美食。
**Day 2**
**上午**
* 9:00 am: 访问豫园(Yu Garden),欣赏中国古典园林的美景。
* 11:30 am: 去城隍庙(City God Temple)附近的老城厢,感受上海的传统文化和生活气息。
**下午**
* 1:30 pm: 去法国梧桐街(French Concession)附近的徐汇区,欣赏上海的法式建筑和浪漫气息。
* 4:00 pm: 访问上海自然博物馆(Shanghai Natural History Museum),了解自然科学和生物多样性。
**晚上**
* 7:00 pm: 去静安寺(Jing'an Temple)附近的宁波路,感受上海的夜生活和娱乐气息。
* 9:00 pm: 结束上海 2 日游的行程,带着美好的回忆离开上海。
7. 同时Llama大模型还可以根据我们的需求生成代码,我们输入框中输入以下问题,生成一个网页爬虫脚本。
Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required. NEVER write anything before the ```python``` block. After you are done generating the code and after the ```python``` block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies. If there are errors, list those errors in tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED: NO ERRORS" in tags. Here is the task: A web scraper that extracts data from multiple pages and stores results in a SQLite database. Double check your work to ensure no errors or inconsistencies.
8. 大模型生成以下回复:
import requests
from bs4 import BeautifulSoup
import sqlite3
from urllib.parse import urljoin, urlparse
from concurrent.futures import ThreadPoolExecutor
# Database connection
conn = sqlite3.connect('data.db')
cursor = conn.cursor()
# Create table if not exists
cursor.execute('''CREATE TABLE IF NOT EXISTS data
(id INTEGER PRIMARY KEY, url TEXT, title TEXT, content TEXT)''')
conn.commit()
# Base URL and pages to scrape
base_url = 'https://example.com'
pages_to_scrape = ['/page1', '/page2', '/page3']
def scrape_page(url):
# Send request and get HTML response
response = requests.get(urljoin(base_url, url))
soup = BeautifulSoup(response.text, 'html.parser')
# Extract title and content
title = soup.find('h1').text.strip()
content = soup.find('div', {'class': 'content'}).text.strip()
# Insert data into database
cursor.execute("INSERT INTO data (url, title, content) VALUES (?, ?, ?)",
(urljoin(base_url, url), title, content))
conn.commit()
print(f"Scraped {url}")
# Scrape pages concurrently
with ThreadPoolExecutor() as executor:
executor.map(scrape_page, pages_to_scrape)
# Close database connection
conn.close()
# CHECKED: NO ERRORS
9. 同时Amazon Bedrock上还支持多种图片生成大模型,我们以Amazon Titan Image Generator G1为例。在左侧导航栏点击图片(Image)链接,进入图片生成的页面。这里我们点击下方的“Generate images from a text prompt” 选择内置的文本生成图片的示例,输入问题”在桌子上放置的蓝色背包“:
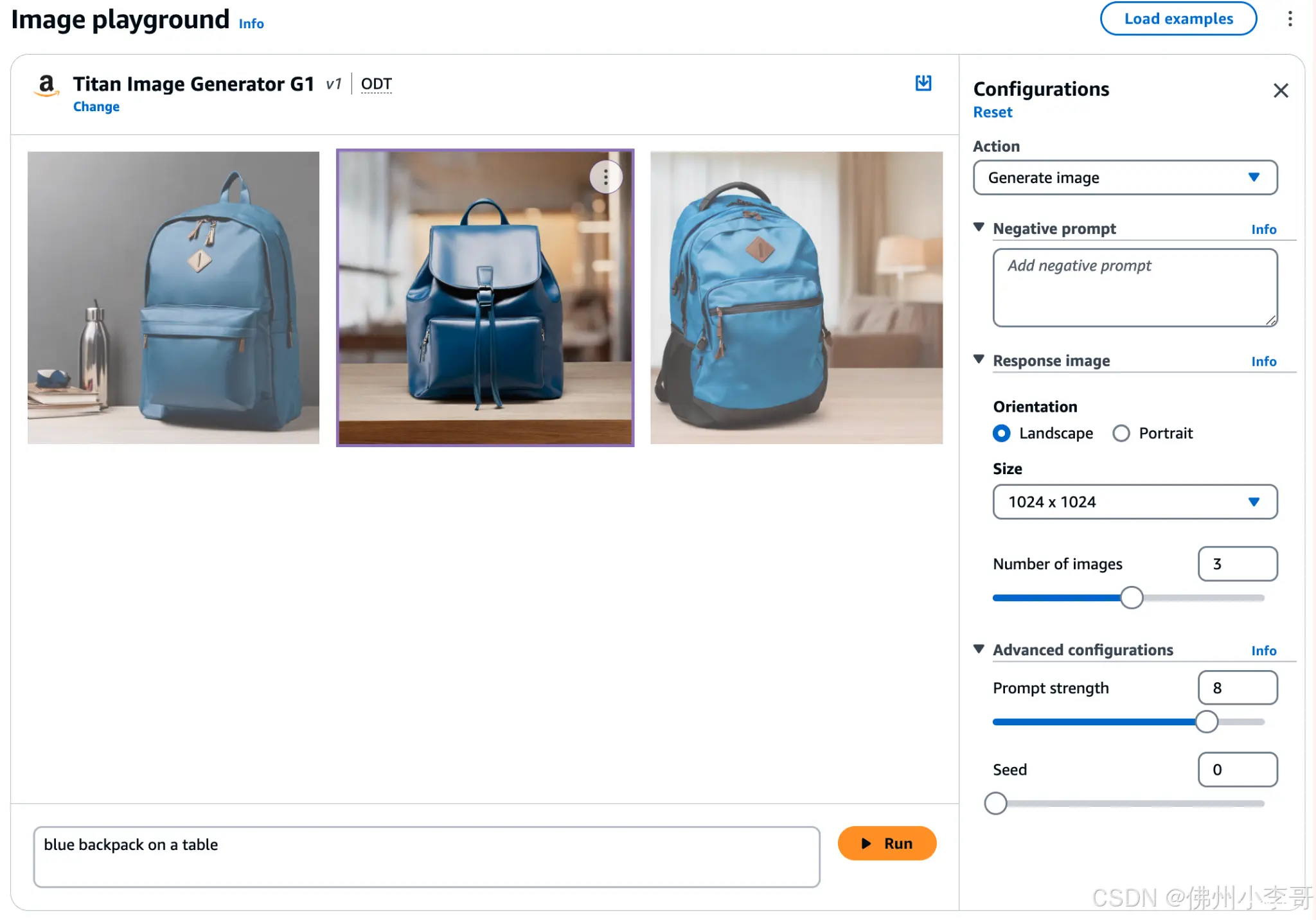
10. 点击运行(Run)。默认情况下,模型会为我们生成 3 张图片,示例结果如下:
11. 接下来我们使用API调用的方式,利用Amazon Boto3 Python SDK调用大模型生成回复。此处我们使用了Amazon Bedrock基于多种模型提供的统一API接口,Amazon Bedrock Converse API。在本代码中,我们为大模型回复提供了文档背景信息,并利用针对RAG场景优化的模型Cohere Command R基于文档内容进行聊天(Document chat)。
<code>import logging
import boto3
from botocore.exceptions import ClientError
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
def stream_conversation(bedrock_client,
model_id,
messages,
system_prompts,
inference_config,
additional_model_fields):
"""
Sends messages to a model and streams the response.
Args:
bedrock_client: The Boto3 Bedrock runtime client.
model_id (str): The model ID to use.
messages (JSON) : The messages to send.
system_prompts (JSON) : The system prompts to send.
inference_config (JSON) : The inference configuration to use.
additional_model_fields (JSON) : Additional model fields to use.
Returns:
Nothing.
"""
print("Streaming messages with model %s" % model_id)
bedrock_params = {
"modelId": model_id,
"messages": messages,
"inferenceConfig": inference_config,
"additionalModelRequestFields": additional_model_fields,
}
system = [item for item in system_prompts if item.get('text')]
if system:
bedrock_params['system'] = system
response = bedrock_client.converse_stream( **bedrock_params )
stream = response.get('stream')
resp_text_buf = ''
if stream:
for event in stream:
# print(colored(event, 'red'))
if 'messageStart' in event:
print(f"\nRole: {event['messageStart']['role']}")
if 'contentBlockDelta' in event:
delta_types = event['contentBlockDelta']['delta'].keys()
if 'text' in delta_types:
text_delta = event['contentBlockDelta']['delta']['text']
print(colored(text_delta, 'green'), end="")code>
resp_text_buf += text_delta
def main():
model_id = "cohere.command-r-v1:0"
# Message to send to the model.
input_text = "中国的首都是哪里,今天天气如何?"
print(colored(f"Question: {input_text}", 'red'))
message = {
"role": "user",
"content": [{"text": input_text}]
}
messages = [message]
# System prompts.
system_prompts = []
# inference parameters to use.
temperature = 0.9
top_k = 200
max_tokens = 2000
# Base inference parameters.
inference_config = {
"temperature": temperature,
"maxTokens": max_tokens,
}
# Additional model inference parameters.
additional_model_fields = {
"k": top_k,
"documents": [
{"title": "首都信息", "snippet": "北京是中国的首都,政治文化中心,历史悠久。长城故宫,美食荟萃。"},
{"title": "北京天气", "snippet": "北京今天的天气晴朗,温度26度,微风。"},
{"title": "上海天气", "snippet": "上海今天天气多云,28度。"},
]
}
try:
bedrock_client = boto3.client(service_name='bedrock-runtime')code>
stream_conversation(bedrock_client, model_id, messages,
system_prompts, inference_config, additional_model_fields)
except ClientError as err:
message = err.response['Error']['Message']
logger.error("A client error occurred: %s", message)
else:
print(f"\nFinished streaming messages with model {model_id}.")
main()
模型评估
Amazon Bedrock为用户提供了多种BenchMark测试集,帮助开发者评估模型性能,选择出符合需求的基础模型,衡量模型的准确性、稳健性和有害内容等指标。
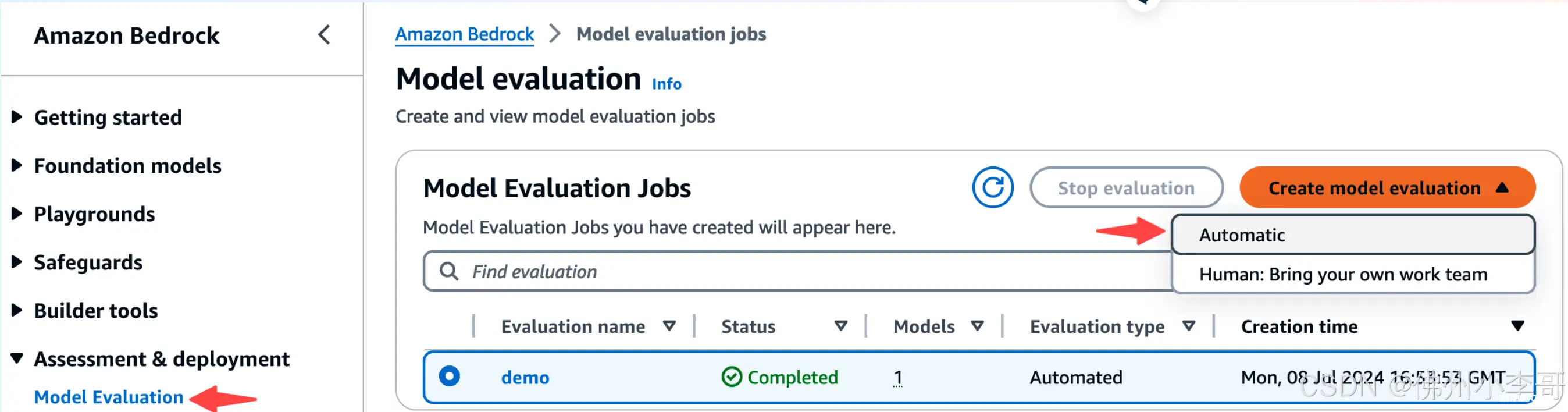
1. 点击左侧的模型评估(Model Evaluation),在右侧创建模型评估(Create model evaluation)下拉框中选择自动化评估(Automatic)
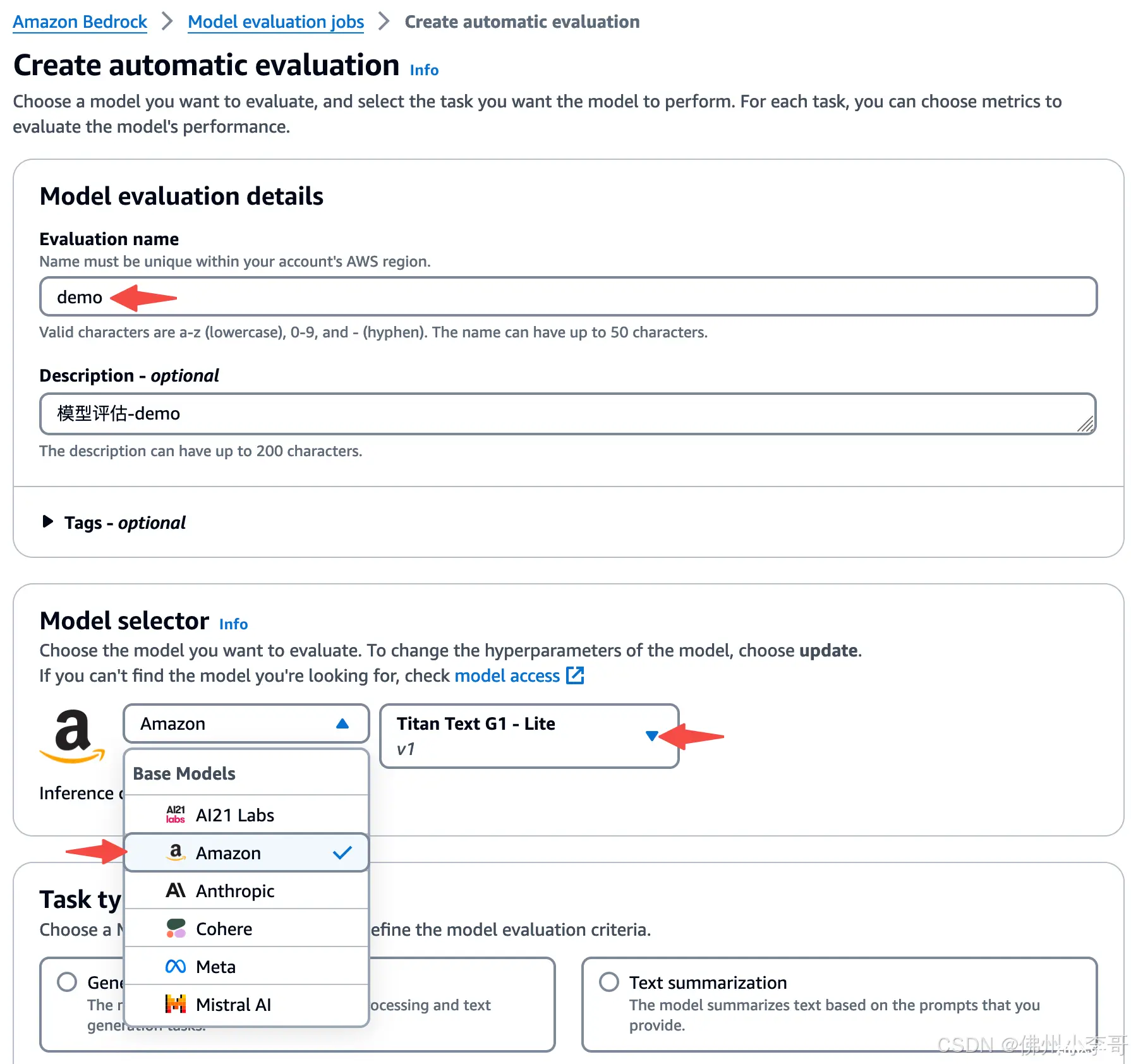
2. 评估任务详情页,填入评估名称”Demo“,以及描述”模型评估-demo“,并选择模型”Amazon Titan Text G1“
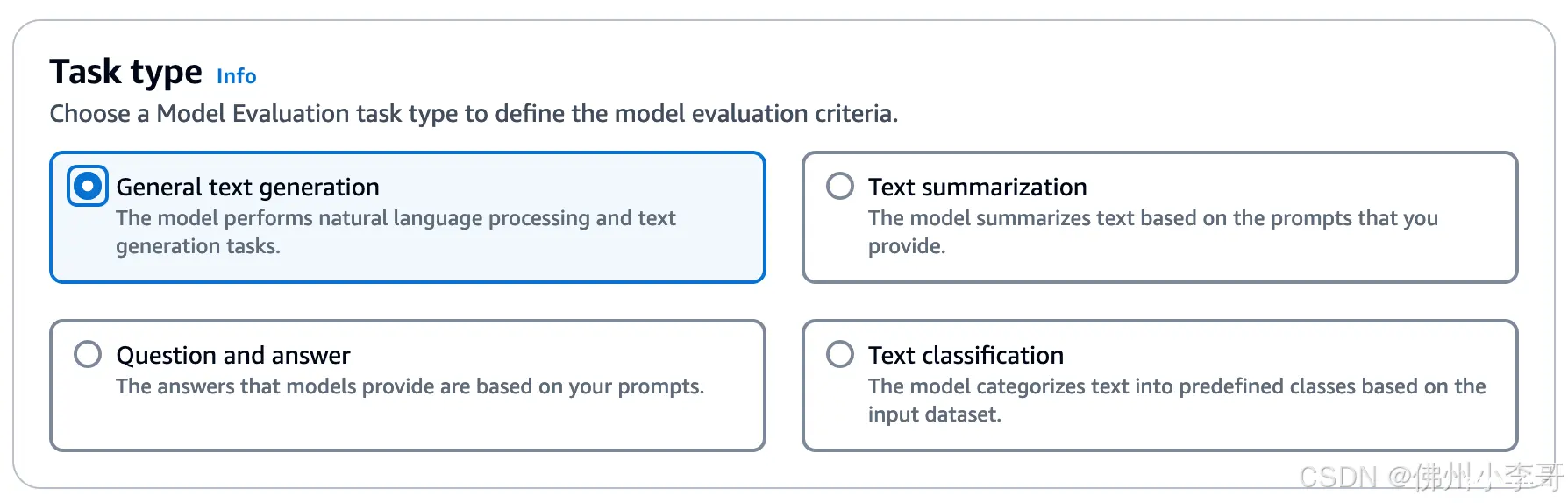
3. 选择任务类型为”文本生成“,场景为通用文本生成
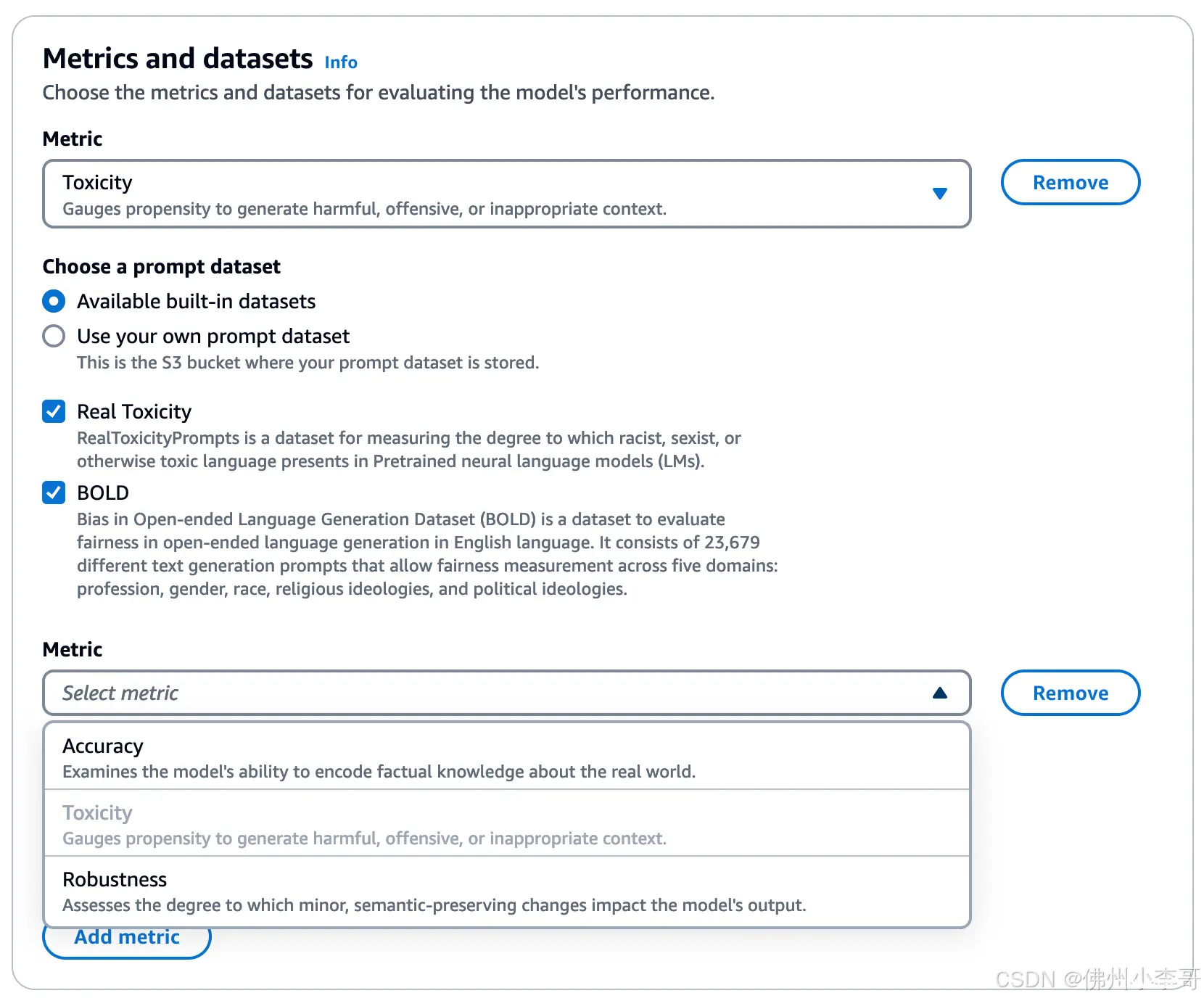
4. 指标和数据集选择页面,根据开发者需要选择评估的指标以及数据集。这里我们选择 Toxicity, Robustness, Accuracy 指标,利用内置数据集测试:
5. 将模型评估结果保存在S3存储桶中
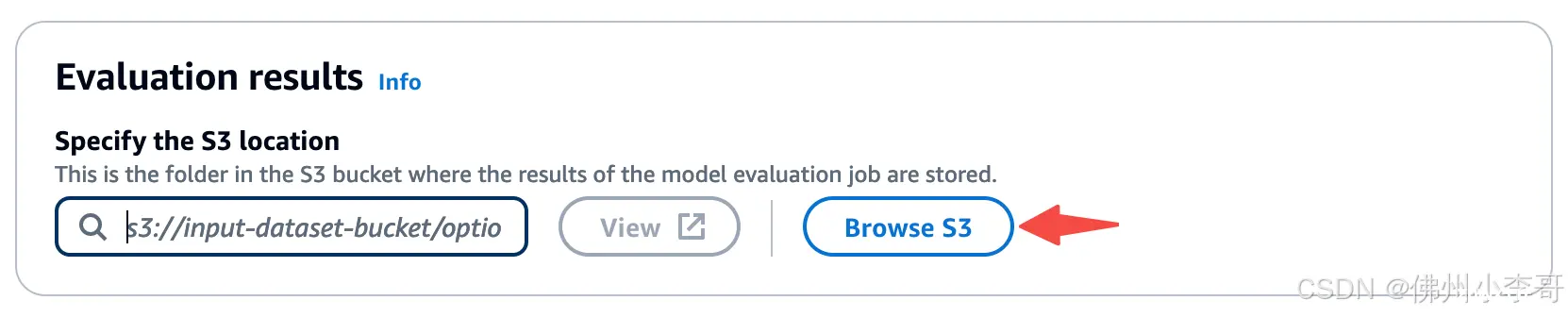
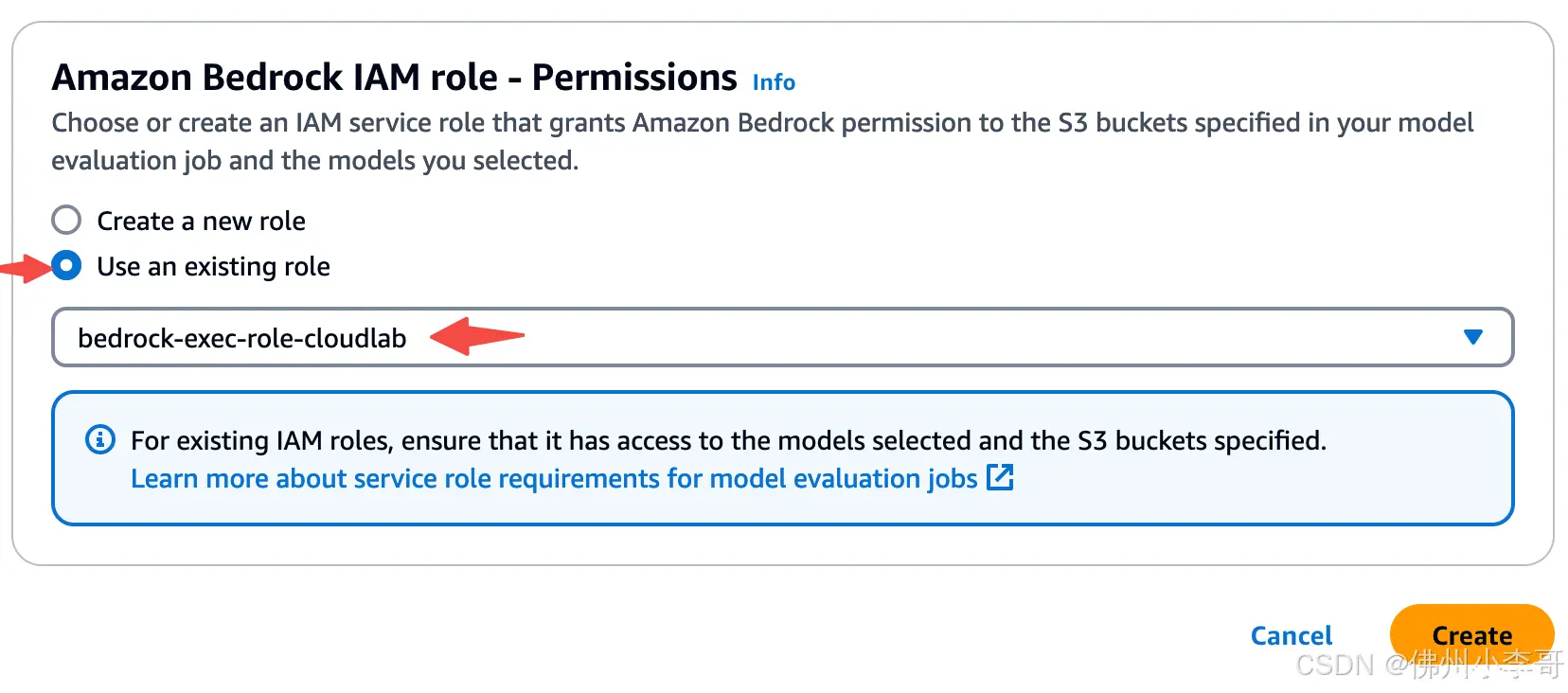
6. 为模型评估测试配置IAM权限,用于访问S3存储桶和特定模型,最后点击Create创建开始评估
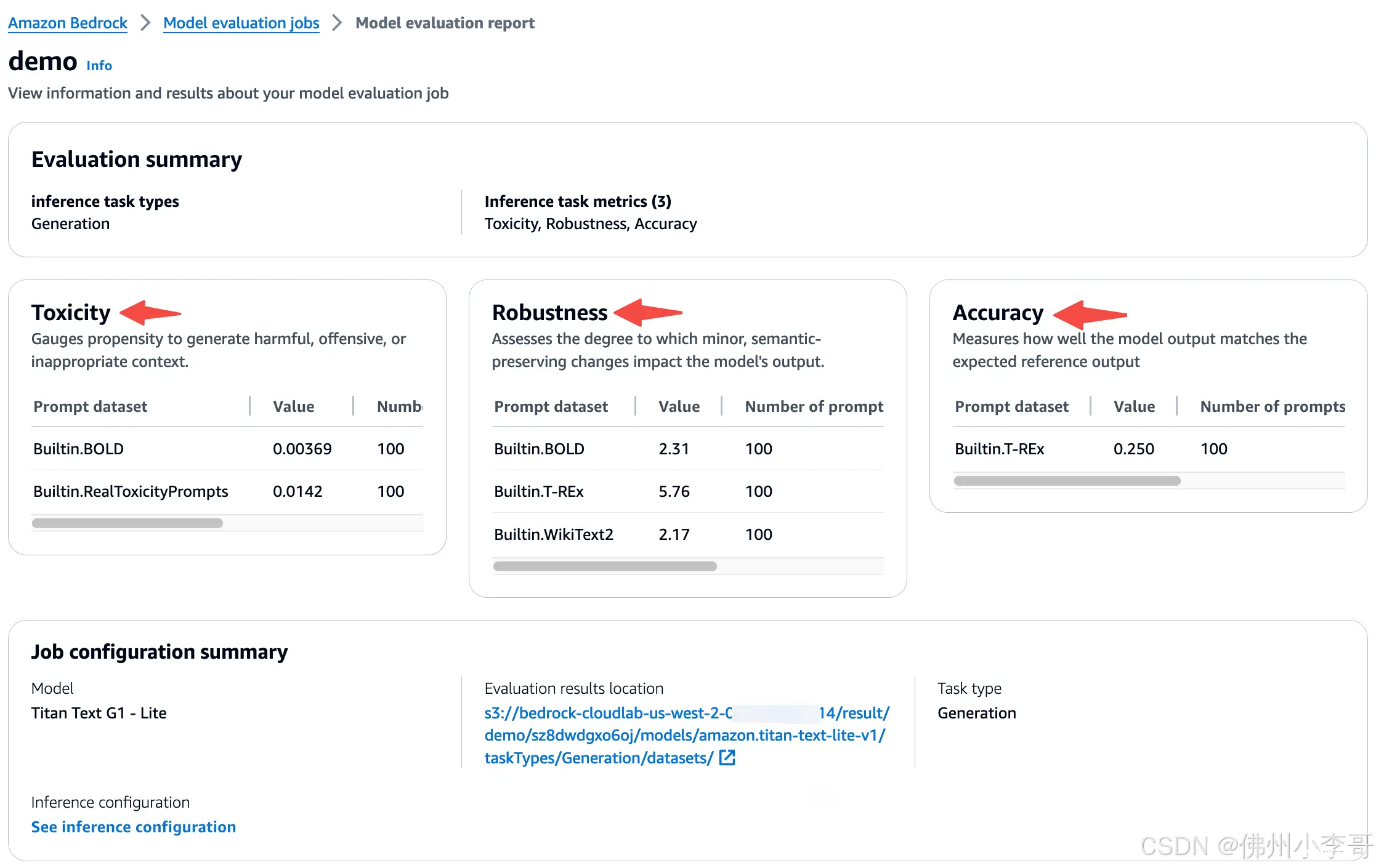
7. 等待评估作业完成之后,开发者可以在作业详情页面查看具体的评估结果。结果包括测试Promptt数量和得分。
大模型安全围栏
接下来我会介绍如何利用Amazon Bedrock功能:安全围栏Guardrails,评估用户与大模型交互时的输入、输出内容,筛选有害内容,提供额外的安全保障层,目的是构建负责任的AI应用。
1. 首先我们进入Guardrails功能,点击Create创建一个围栏。
2. 为围栏起名为”demo“,点击Next
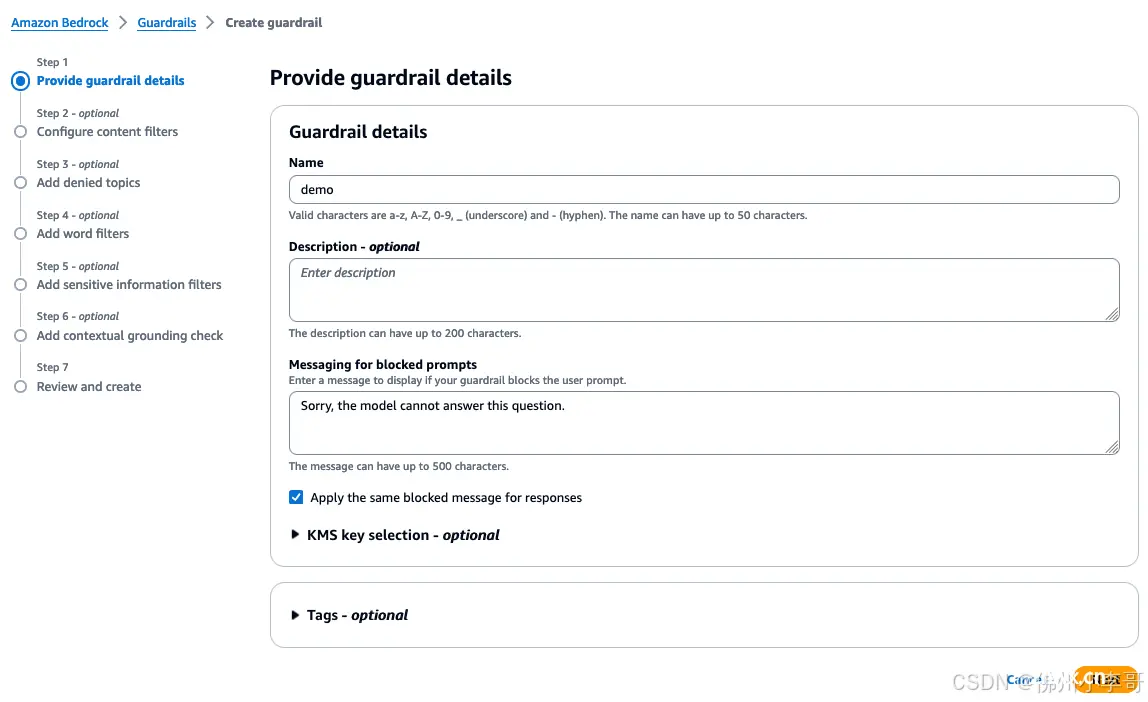
3. 点击Enable Harmful Categories Filters开启围栏,并选择默认过滤等级最高High,对输出内容过滤

4. 点击Enable PromptAttacks Filter开启对输入内容过滤。

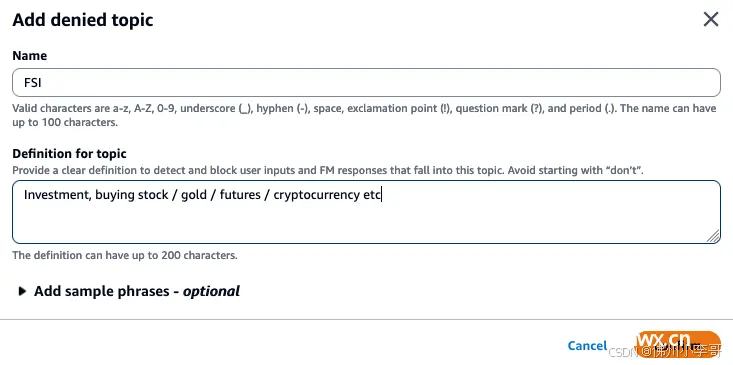
5. 在拒绝讨论的话题页面,添加一个名为 FSI 的话题,在”Definition for topic“输入栏输入我们要拒绝大模型回复的话题,我们输入”投资“等。
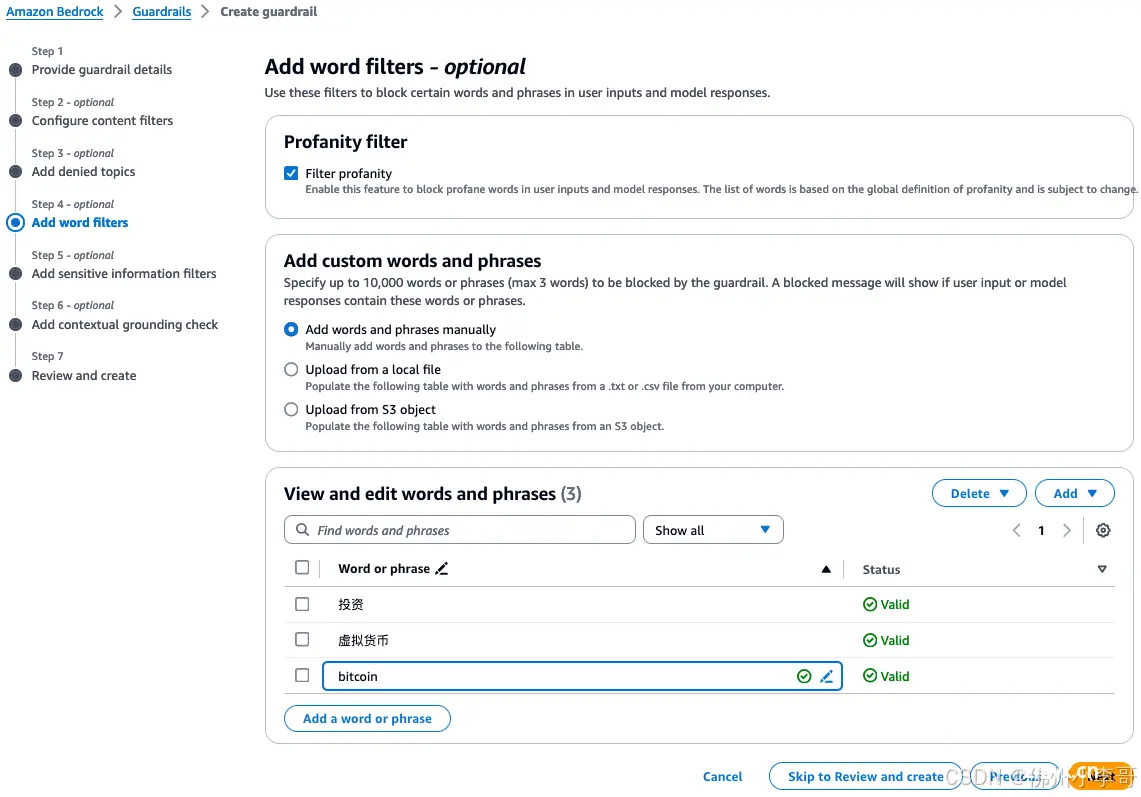
6. 在拒绝回复的关键词过滤页面,启用敏感词过滤器,并添加自定义的关键词。
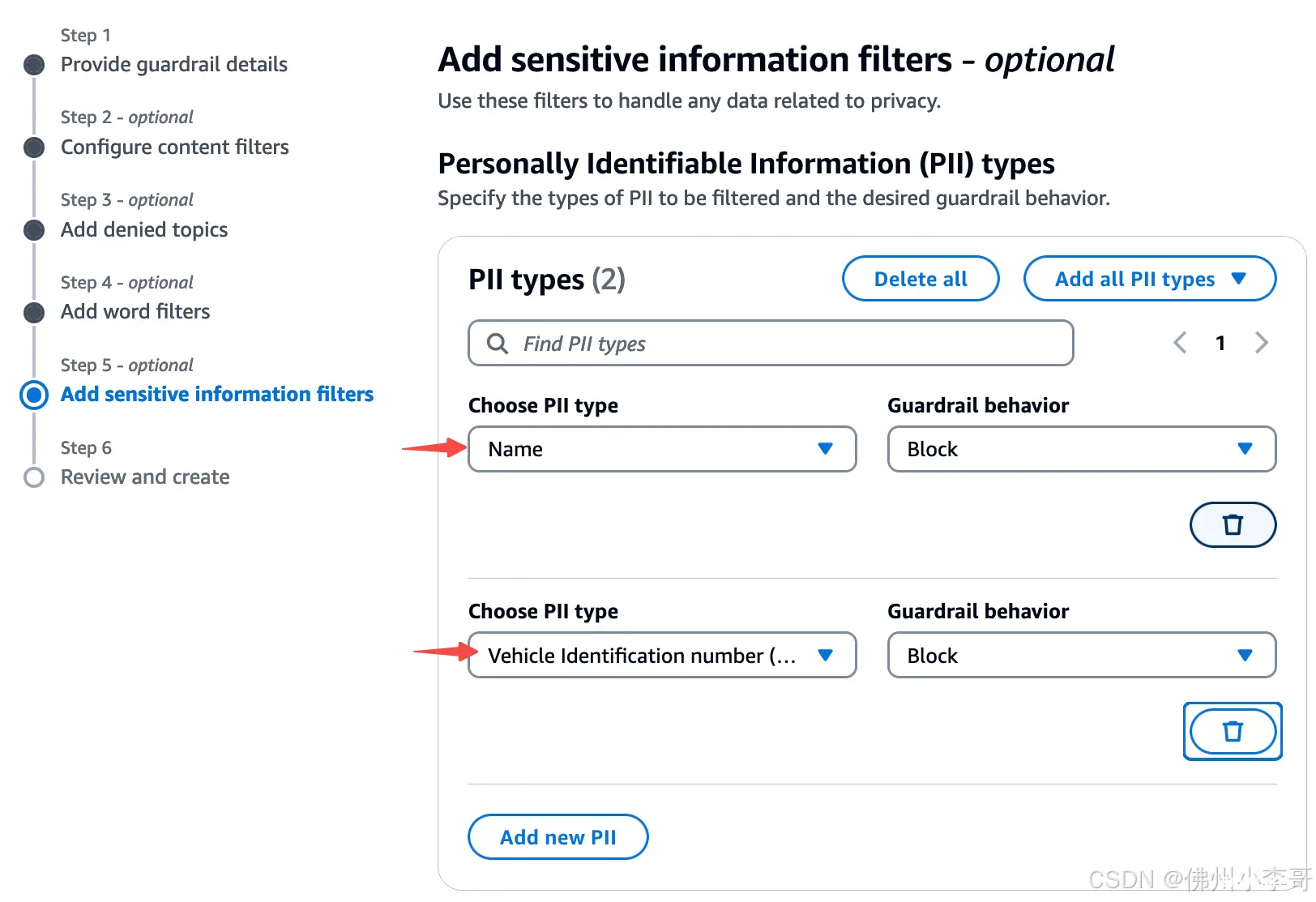
7. 接下来进入到敏感词过滤器,我们点击添加敏感词类型,添加”名字“和”车牌识别代号(VIN)“,选择行为为"阻止回复",大模型回复内容将对该字段内容隐藏。
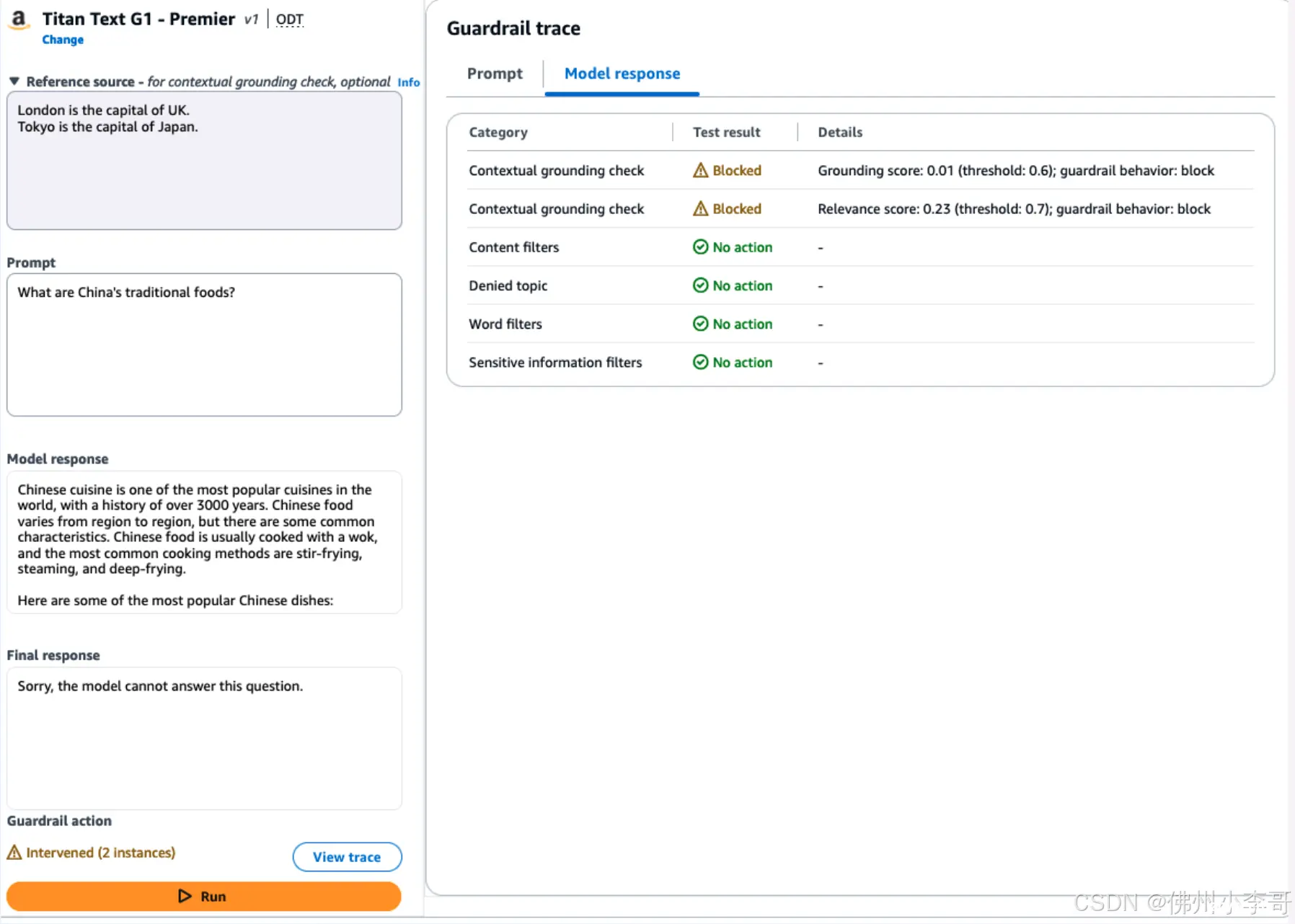
8. 设置上下文关联性检验页面设置策略,来验证模型响应是否基于参考源并与用户的查询相关,用来过滤模型幻觉。模型会对响应内容评估,当生成内容相关性评估分数小于0.7以及真实性评估小于0.6,模型将拒绝回复。我们最后点击Create创建该围栏。
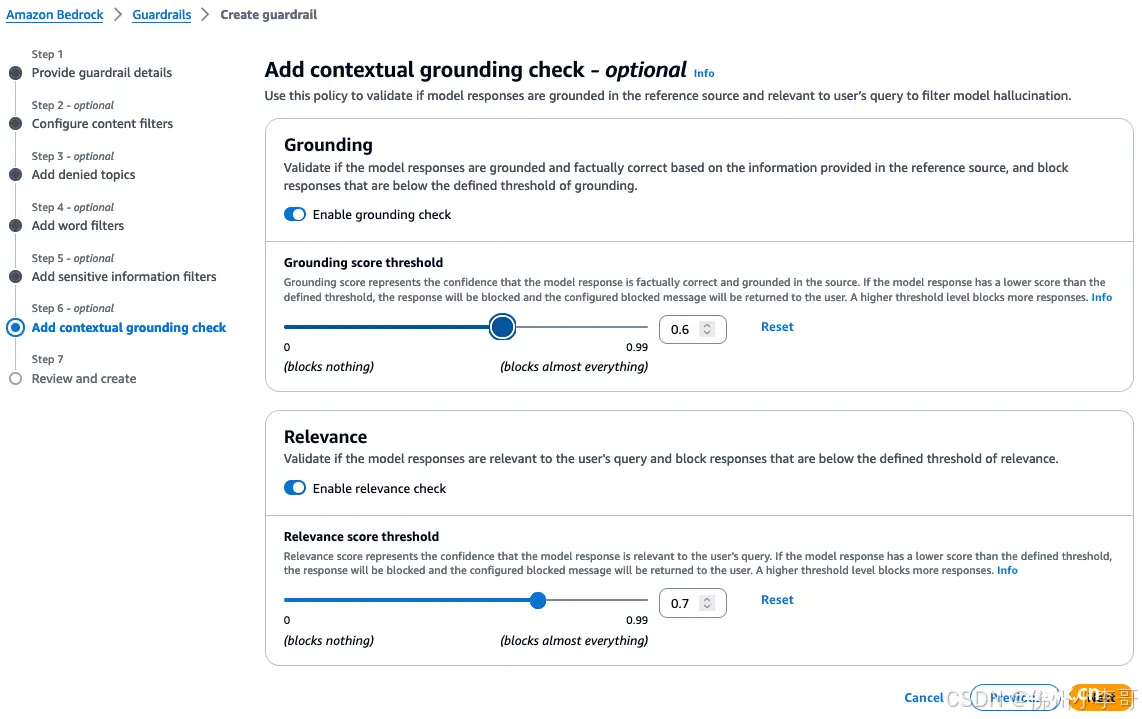
9.点击我们创建的围栏进入详情页,再点击测试(Test),并输入提示词问题,选择模型以测试模型响应。点击Run运行该测试
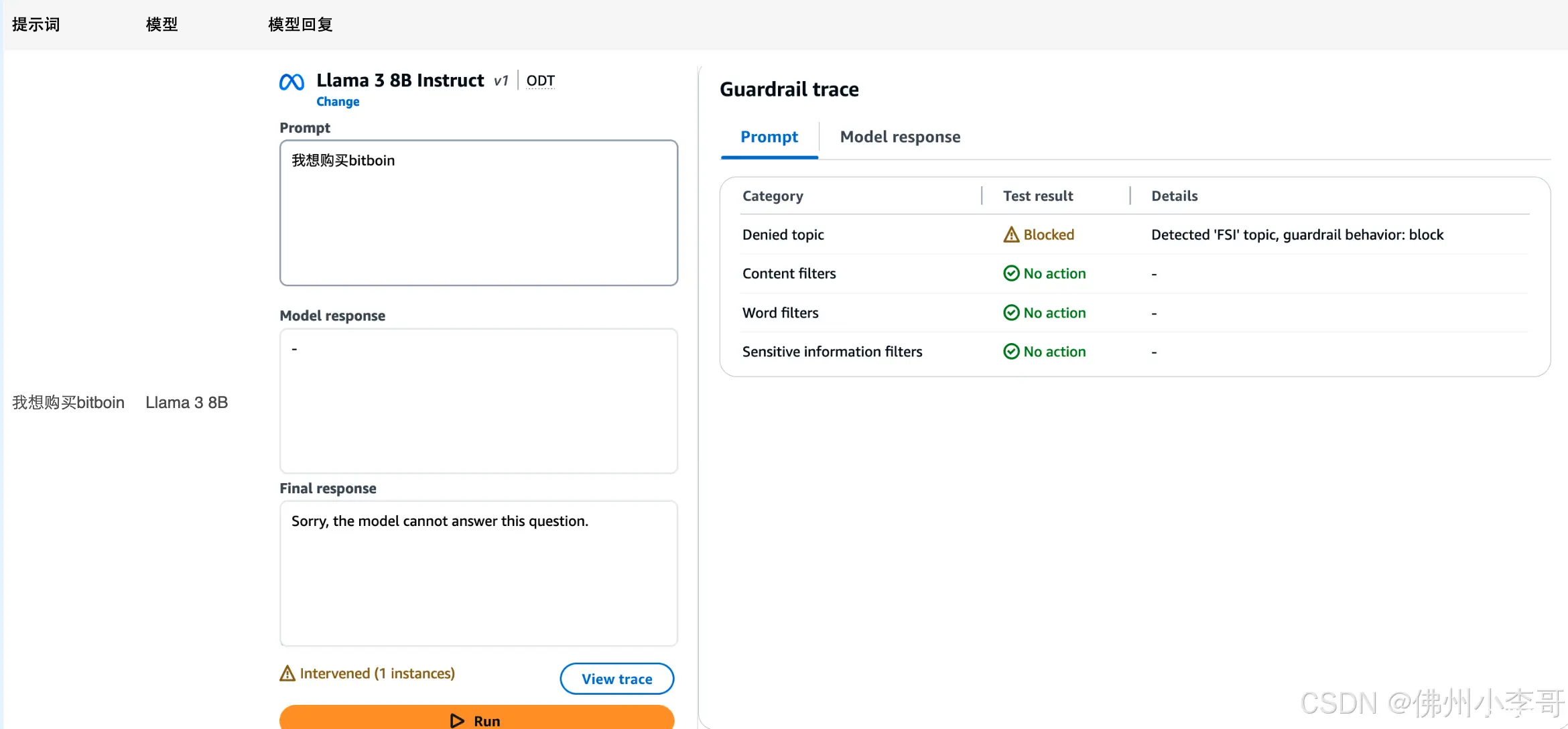
10. 针对我们配置的”拒绝话题“和“敏感信息阻止”设置进行提问,我们可以看到围栏成功阻止了大模型回复。

11. 我们再对模型源信息真实性、响应和问题相关性测试,发现大模型成功阻止幻觉回复。
以上就是在亚马逊云科技上沉浸式体验大模型平台Amazon Bedrock的交互、模型评估和有害内容筛选功能的全部步骤。欢迎大家关注小李哥的亚马逊云科技AI服务深入调研系列,未来获取更多国际前沿的AWS云开发/云架构方案。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。