利用亚马逊云科技Bedrock和LangChain开发AI驱动数据分析平台
CSDN 2024-08-24 13:31:01 阅读 74
项目简介:
小李哥将继续每天介绍一个基于亚马逊云科技AWS云计算平台的全球前沿AI技术解决方案,帮助大家快速了解国际上最热门的云计算平台亚马逊云科技AWS AI最佳实践,并应用到自己的日常工作里。
本次介绍的是如何在亚马逊云科技上SageMaker上利用LangChain框架开发代码调用Amazon Titan大语言模型,基于业务数据库Schema、用户问题以及提示词模板生成LLM链,调用大模型托管服务Amazon Bedrock上的AI大语言模型,生成业务所需的SQL查询语句并利用SQL链查询数据并生成用户问题的答案。本架构设计全部采用了云原生Serverless架构,提供可扩展和安全的AI解决方案。本方案的解决方案架构图如下:

方案所需基础知识
什么是 Amazon Bedrock?
Amazon Bedrock 是亚马逊云科技推出的一项生成式 AI 服务,旨在帮助开发者轻松访问和部署各种强大的基础模型(Foundation Models),如文本生成、对话生成、图像生成等。通过 Amazon Bedrock,开发者可以快速构建、定制和扩展 AI 应用程序,而无需从零开始训练模型。这种服务使得利用大规模预训练模型变得更加简便和高效,适用于各种行业的 AI 应用场景。
什么是 Amazon SageMaker?
Amazon SageMaker 是亚马逊云科技提供的一站式机器学习服务,帮助开发者和数据科学家轻松构建、训练和部署机器学习模型。SageMaker 提供了全面的工具,从数据准备、模型训练到部署和监控,覆盖了机器学习项目的全生命周期。通过 SageMaker,用户可以加速机器学习模型的开发和上线,并确保模型在生产环境中的稳定性和性能。
什么是 Amazon Glue?
Amazon Glue 是亚马逊云科技的一项完全托管的数据集成服务,用于发现、准备和组合数据,以实现更快的数据分析。Glue 提供了数据提取、转换和加载(ETL)的功能,支持自动数据爬网、元数据管理和数据清理。它使得企业能够轻松将数据从多个源系统整合到数据湖或数据仓库中,为后续的分析和报告提供干净、统一的数据集。

利用大模型生成 SQL 语句的应用场景
自助式数据查询:
利用大模型生成 SQL 语句,使非技术用户能够通过自然语言输入查询需求,自动生成相应的 SQL 语句进行数据库查询。这大大降低了数据访问的技术门槛,帮助用户快速获取所需的数据。
复杂查询自动化:
在需要构建复杂查询时,开发者可以通过描述性语言让大模型生成 SQL 语句,避免手动编写长而复杂的查询代码。这不仅提高了开发效率,还减少了语法错误的可能性。
数据分析支持:
分析师可以利用大模型生成 SQL 语句,根据业务问题自动生成分析查询,快速获取洞察,支持数据驱动的决策过程。
动态报告生成:
在报表生成系统中,用户可以通过自然语言描述需要的报告内容,大模型将生成对应的 SQL 语句并自动提取数据,生成实时报告。这种应用使得报告生成更加灵活和高效
本方案包括的内容
1.申请Amazon Bedrock上的Amazon Titan大模型访问权限。
2.运行Amazon Glue数据提取服务,将数据库的Schema导入到Amazon Glue Data Catalog
3.根据Data Catalog利用LangChain生成一个动态提示词模板
4. 通过LangChain API调用Amazon Titan大模型
5. 测试调用大模型生成业务数据库SQL查询语句
项目搭建具体步骤:
1. 登录亚马逊云科技控制台,在Amazon Bedrock中启用Amazon Titan Text G1 - Lite模型,该模型的ID为:”amazon.titan-text-lite-v1“。
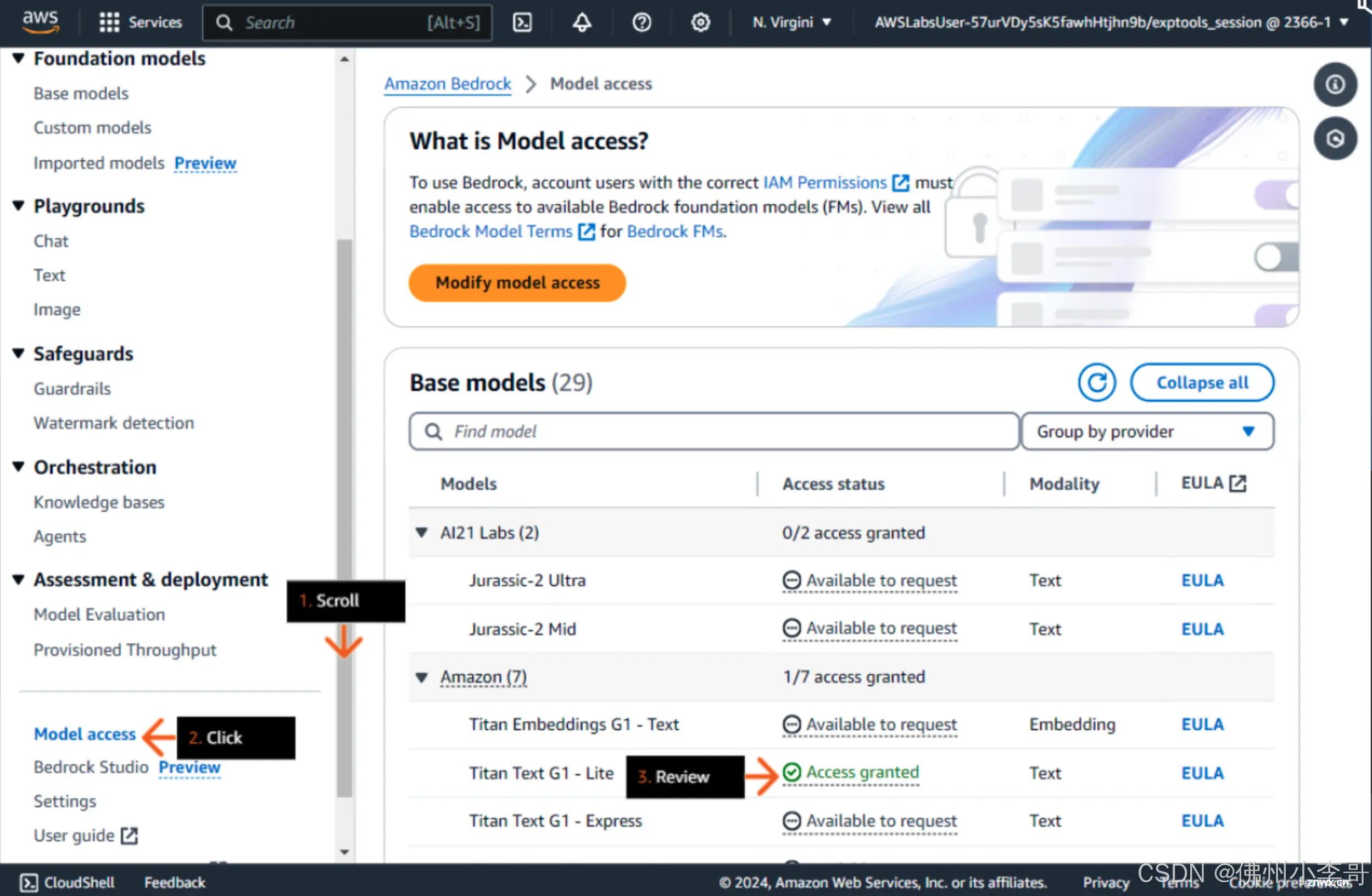
2. 下面进入亚马逊云科技SageMkaer服务Stuidio界面,点击Open打开Studio。
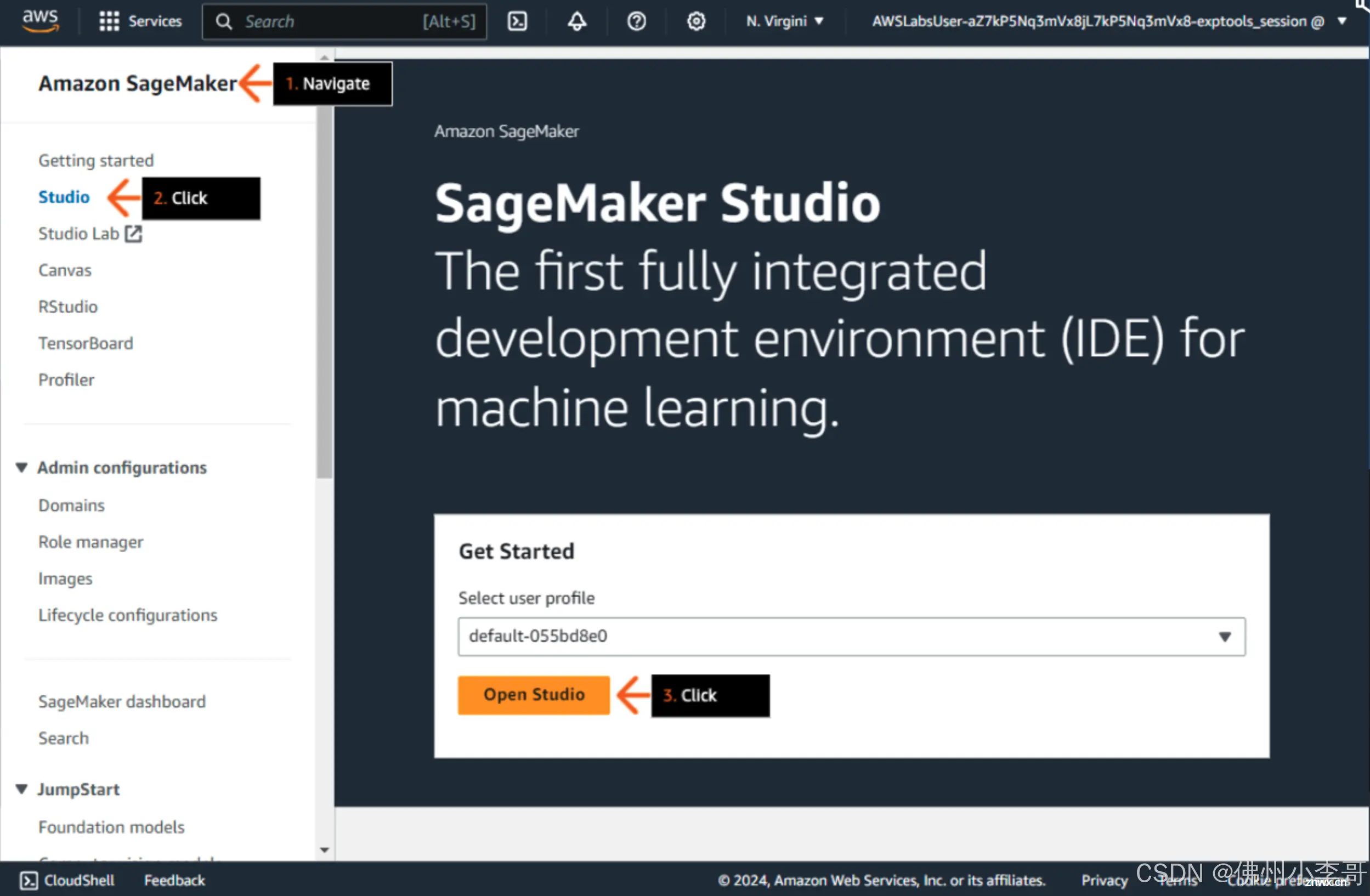
3. 创建一个新的Jupyter Notebook文件,命名为mda_text_to_sql_langchain_bedrock.ipynb。首先安装必要依赖,并导入。
<code>%%capture
!pip install sqlalchemy==2.0.29
!pip install langchain==0.1.19
!pip install langchain-experimental==0.0.58
!pip install PyAthena[SQLAlchemy]==3.8.2
!pip install -U langchain-aws==0.1.3
import os
import json
import boto3
import sqlalchemy
from sqlalchemy import create_engine
from langchain.docstore.document import Document
from langchain import PromptTemplate,SagemakerEndpoint,SQLDatabase,LLMChain
from langchain_experimental.sql import SQLDatabaseChain, SQLDatabaseSequentialChain
from langchain.llms.sagemaker_endpoint import LLMContentHandler
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts.prompt import PromptTemplate
from langchain.chains.api.prompt import API_RESPONSE_PROMPT
from langchain.chains import APIChain
from typing import Dict
import time
from langchain_aws import BedrockLLM
4. 接下来我们把json中的业务数据导入到DataFrame中
import pandas as pd
library_df = pd.read_json('s3_library_data.json',lines=True)
library_df
5. 在开始该实验之前,我们通过CloudFormation基础设施即代码服务,创建了Amazon Glue和Catalog云资源。这时我们通过CloudFormation Stack的数据获取这些云资源的ID名字。
## Update with the correct Cloudformation Stack Name
cloudformation_stack_name = '<LabStack>'
cfn_client = boto3.client('cloudformation')
def get_cfn_outputs(cloudformation_stack_name):
outputs = {}
for output in cfn_client.describe_stacks(StackName=cloudformation_stack_name)['Stacks'][0]['Outputs']:
outputs[output['OutputKey']] = output['OutputValue']
return outputs
outputs = get_cfn_outputs(cloudformation_stack_name)
json_formatted_str = json.dumps(outputs, indent=2)
print(json_formatted_str)
运行该代码得到的回复如下:
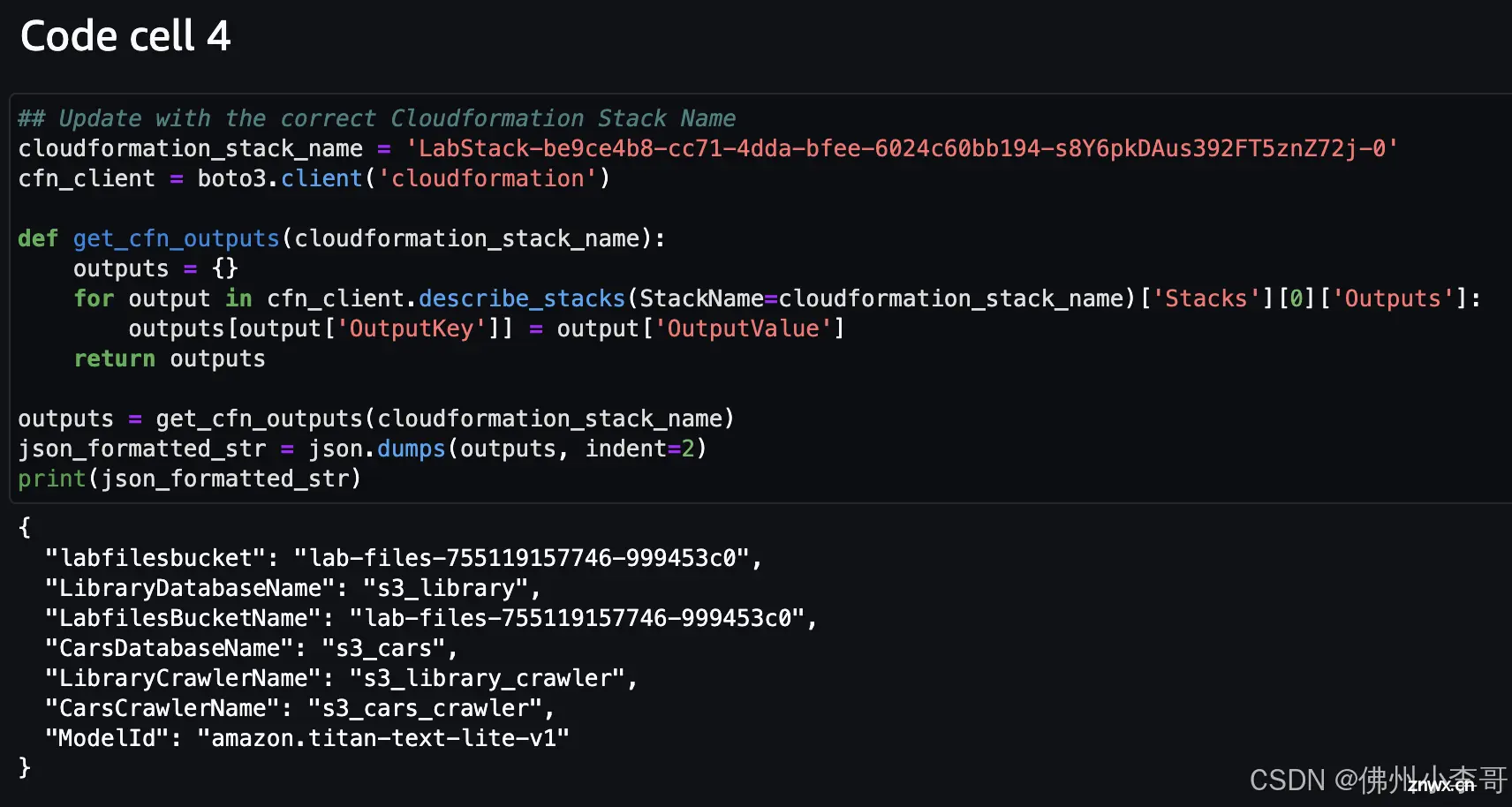
6. 我们继续在代码中指定我们的数据文件、Glue Crawler和Glue Database名字
<code># The following variables define the AWS Glue Data Catalog database and crawler to use.
## DIY Note ## You will be required to update some of the below variables as part of the DIY
data_file = 's3_library_data.json'
lab_files_folder = 'library-data'
glue_db_name = outputs['LibraryDatabaseName']
glue_crawler_name = outputs['LibraryCrawlerName']
# The below variable does not need to be changed.
lab_files_bucket = outputs['LabfilesBucketName']
print(lab_files_bucket)
7. 下一步我们通过亚马逊云科技Python SDK Boto3,开始运行一个Glue Crawler,在Glue中构建数据库的结构和元数据,供之后利用大模型查询使用。
client = boto3.client('glue')
print("About to start running the crawler: ", glue_crawler_name)
try:
response = client.start_crawler(Name=glue_crawler_name )
print("Successfully started crawler. The crawler may take 2-5 mins to detect the schema.")
while True:
# Get the crawler status.
response = client.get_crawler(Name=glue_crawler_name)
# Extract the crawler state.
status = response['Crawler']['State']
# Print the crawler status.
print(f"Crawler '{glue_crawler_name}' status: {status}")
if status == 'STOPPING': # Replace 'READY' with the desired completed state.
break # Exit the loop if the desired state is reached.
time.sleep(10) # Sleep for 10 seconds before checking the status again.
except:
print("error in starting crawler. Check the logs for the error details.")
8. 接下来我们利用SQLAlchemy Python库与数据库建立连接,通过Python代码调用数据库进行数据操作。
# Define the Region.
region = boto3.session.Session().region_name
## Athena variables
connathena=f"athena.{region}.amazonaws.com"
portathena='443' # Update, if port is differentcode>
schemaathena=glue_db_name # from user defined params
s3stagingathena=f's3://{lab_files_bucket}/athenaresults/' # from cfn params
wkgrpathena='primary' # Update, if workgroup is differentcode>
## Create the Athena connection string.
connection_string = f"awsathena+rest://@{connathena}:{portathena}/{schemaathena}?s3_staging_dir={s3stagingathena}/&work_group={wkgrpathena}"
## Create the Athena SQLAlchemy engine.
engine_athena = create_engine(connection_string, echo=False)
dbathena = SQLDatabase(engine_athena)
gdc = [schemaathena]
print("Connection to Athena database succeeded: ", gdc[0])
9. 处理Glue Catalog的信息,将数据源数据库的库名、数据库每个表命、每个列命存入字符串变量”columns_str“中。
# Generate dynamic prompts to populate the AWS Glue Data Catalog.
# Harvest AWS Glue crawler metadata.
def parse_catalog():
# Connect to the Data Catalog.
columns_str = 'database|table|column_name'
# Define the AWS Glue cient.
glue_client = boto3.client('glue')
for db in gdc:
response = glue_client.get_tables(DatabaseName =db)
for tables in response['TableList']:
# Classification in the response for S3 and other databases is different. Set classification based on the response location.
if tables['StorageDescriptor']['Location'].startswith('s3'): classification='s3' code>
else: classification = tables['Parameters']['classification']
for columns in tables['StorageDescriptor']['Columns']:
dbname,tblname,colname=tables['DatabaseName'],tables['Name'],columns['Name']
columns_str = columns_str+f'\n{dbname}|{tblname}|{colname}'
return columns_str
glue_catalog = parse_catalog()
print(glue_catalog)
基于我们测试的数据,输出的”columns_str“变量如下。
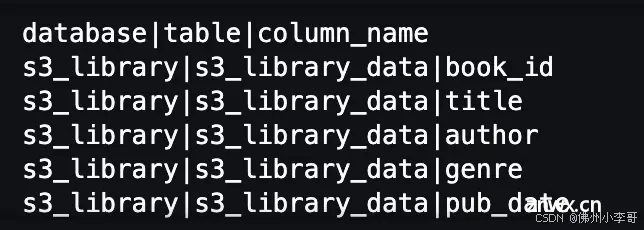
10. 我们定义函数”identify_channel“,使用LangChain框架的LLMChain方法,通过定义提示词模板调用Amazon Bedrock大模型,获取基于用户问题的生成的SQL数据查询语句,并返回语句以及最佳数据查询方法(利用Athena查询S3中的数据,或利用API查询数据)。
<code># Define the Bedrock LLM model to use.
bedrock_model = 'amazon.titan-text-lite-v1'
BEDROCK_CLIENT = boto3.client("bedrock-runtime", 'us-east-1')
# Amazon Titan does not require any inference modifiers.
if bedrock_model == 'amazon.titan-text-lite-v1':
inference_modifier = {}
else:
inference_modifier = {"temperature":0.0, "max_tokens":50}
llm = BedrockLLM(model_id=bedrock_model, client=BEDROCK_CLIENT, model_kwargs = inference_modifier)
def identify_channel(query):
prompt_template_titan = """You are a SQL expert. Convert the below natural language question into a valid SQL statement. The schema has the structure below:\n
"""+glue_catalog+"""
\n
Here is the question to be answered:\n
{query}
\n
Provide the SQL query that would retrieve the data based on the natural language request.\n
"""
prompt_template = prompt_template_titan
# print(prompt_template)
## Define prompt 1.
PROMPT_channel = PromptTemplate(template=prompt_template, input_variables=["query"])
# Define the LLM chain.
llm_chain = LLMChain(prompt=PROMPT_channel, llm=llm)
# Run the query and save to generated texts.
generated_texts = llm_chain.run(query)
# Set the channel from where the query can be answered.
if 's3' in generated_texts:
channel='db'code>
db=dbathena
print("SET database to athena")
elif 'api' in generated_texts:
channel='api'code>
print("SET database to weather api")
else: raise Exception("User question cannot be answered by any of the channels mentioned in the catalog")
# print("Step complete. Channel is: ", channel)
return channel, db
11. 下面我们定义函数”run_query“,通过最优的数据查询方法,利用调用LangChain框架"SQLDatabaseChain.from_llm"方法,访问数据库执行我们刚生成的SQL语句。
def run_query(query):
channel, db = identify_channel(query) # Call the identify channel function first.
_DEFAULT_TEMPLATE = """
Here is a schema of a table:
<schema>
{table_info}
</schema>
Run a SQL query to answer the question. Follow this format:
SQLQuery: the correct SQL query. For example: select count ( * ) from s3_library_data where genre = 'Novel'
SQLResult: the result of the SQL query.
Answer: convert the SQLResult to a grammatically correct sentence.
Here is question: {input}"""
PROMPT_sql = PromptTemplate(
input_variables=["table_info","input"], template=_DEFAULT_TEMPLATE
)
if channel=='db':
db_chain = SQLDatabaseChain.from_llm(llm, db, prompt=PROMPT_sql, verbose=True, return_intermediate_steps=False)
response=db_chain.run(query)
else: raise Exception("Unlisted channel. Check your unified catalog")
return response
12. 我们通过测试问题,调用”run_query“函数进行测试生成回复。
# query = """How many books with a genre of Fantasy are in the library?"""
# query = """Find 3 books in the library with Tarzan in the title?"""
# query = """How many books by author Stephen King are in the library?"""
query = """How many total books are there in the library?"""
response = run_query(query)
print("----------------------------------------------------------------------")
print(f'SQL and response from user query {query} \n {response}')
我们得到大模型通过LangChain调用数据库后生成的SQL查询语句回复。

以上就是在亚马逊云科技上利用亚马逊云科技上利用Amazon Bedrock上的大模型和LangChain开发AI驱动的数据平台的全部步骤。欢迎大家未来与我一起,未来获取更多国际前沿的生成式AI开发方案。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。