基于Pytorch实现AI写藏头诗
Jason_Honey2 2024-07-13 09:01:01 阅读 80
网上你找了一圈发现开源的代码不是付费订阅就是代码有问题,基于Pytorch实现AI写藏头诗看我这篇就够了。
用到的工具:华为云ModelArts平台的notebook/Pycharm/Vscode都行。
镜像:pytorch1.8-cuda10.2-cudnn7-ubuntu18.04,有GPU优先使用GPU资源。
实验背景
在短时测试使用场景,可使用华为云Modelarts的notebook的公共资源池完成相关场景测试验证。
Modelarts Standard公共资源池提供公共的大规模计算集群,根据用户作业参数分配使用,资源按作业隔离。 用户下发训练作业、部署模型均可以使用ModelArts提供的公共资源池完成,按照使用量计费,方便快捷。公共资源池使用共享资源,在任何时候都有可能排队。有关Modelarts资源池的介绍请参考Modelarts公共资源池。
本实验主要介绍基于modelarts的notebook开发环境,来进行LSTM模型的训练->推理的代码实战开发和运行。本实验会使用到ModelArts服务。
实验步骤
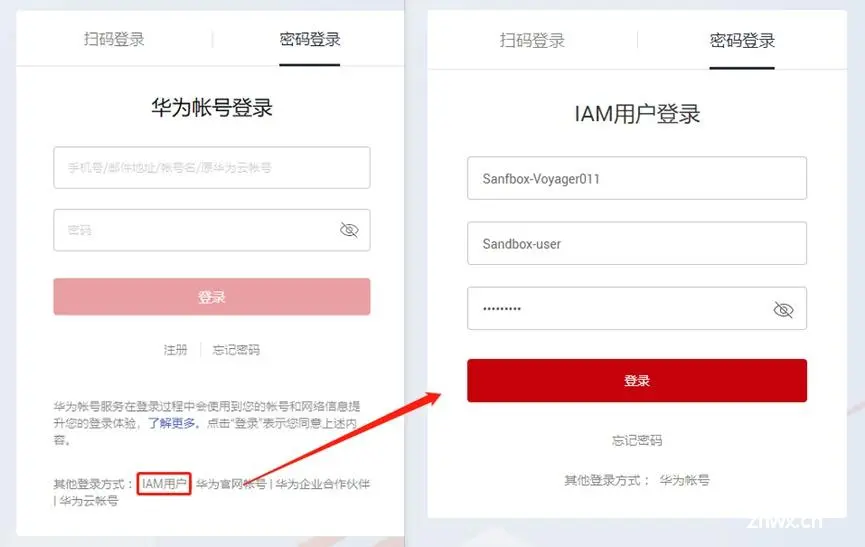
操作前提:登录华为云
进入【实验操作桌面】,打开谷歌浏览器进入华为云登录页面。选择【IAM用户登录】模式,于登录对话框中输入系统为您分配的华为云实验账号和密码登录华为云,如下图所示:
注意:账号信息详见实验手册上方,切勿使用您自己的华为云账号登录。
任务一:创建开发环境
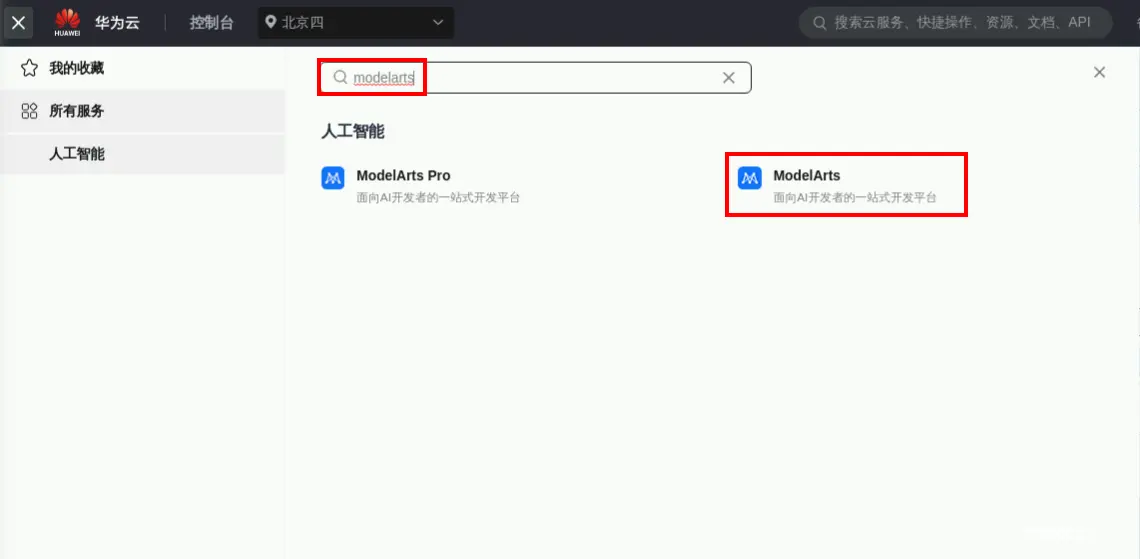
步骤1 进入控制台
在华为云控制台中搜索并单击“ModelArts”,进入ModelArts控制台。如下图所示:
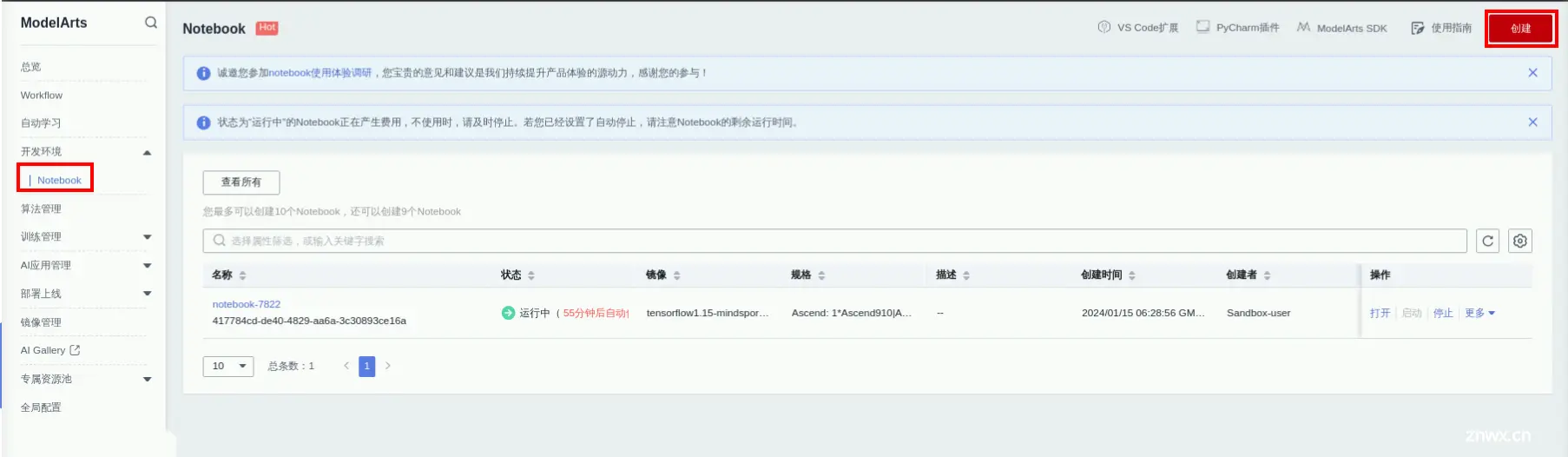
步骤2 进入notebook列表
点击左侧列表中的“开发环境” > “Notebook”,并点击“创建”。如下图所示:
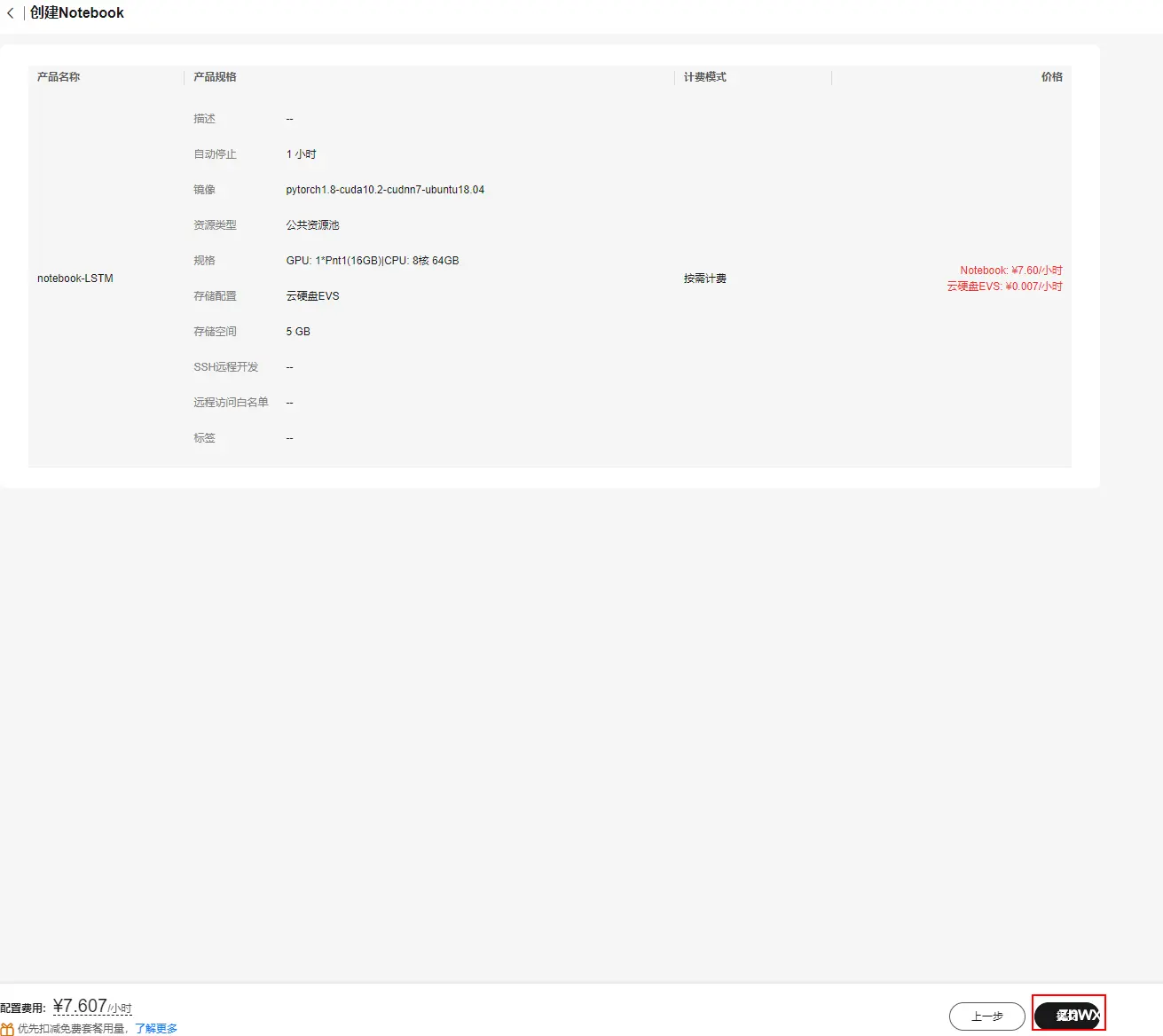
步骤3 配置notebook参数
在创建Notebook页面中,进行以下配置。如下图所示:
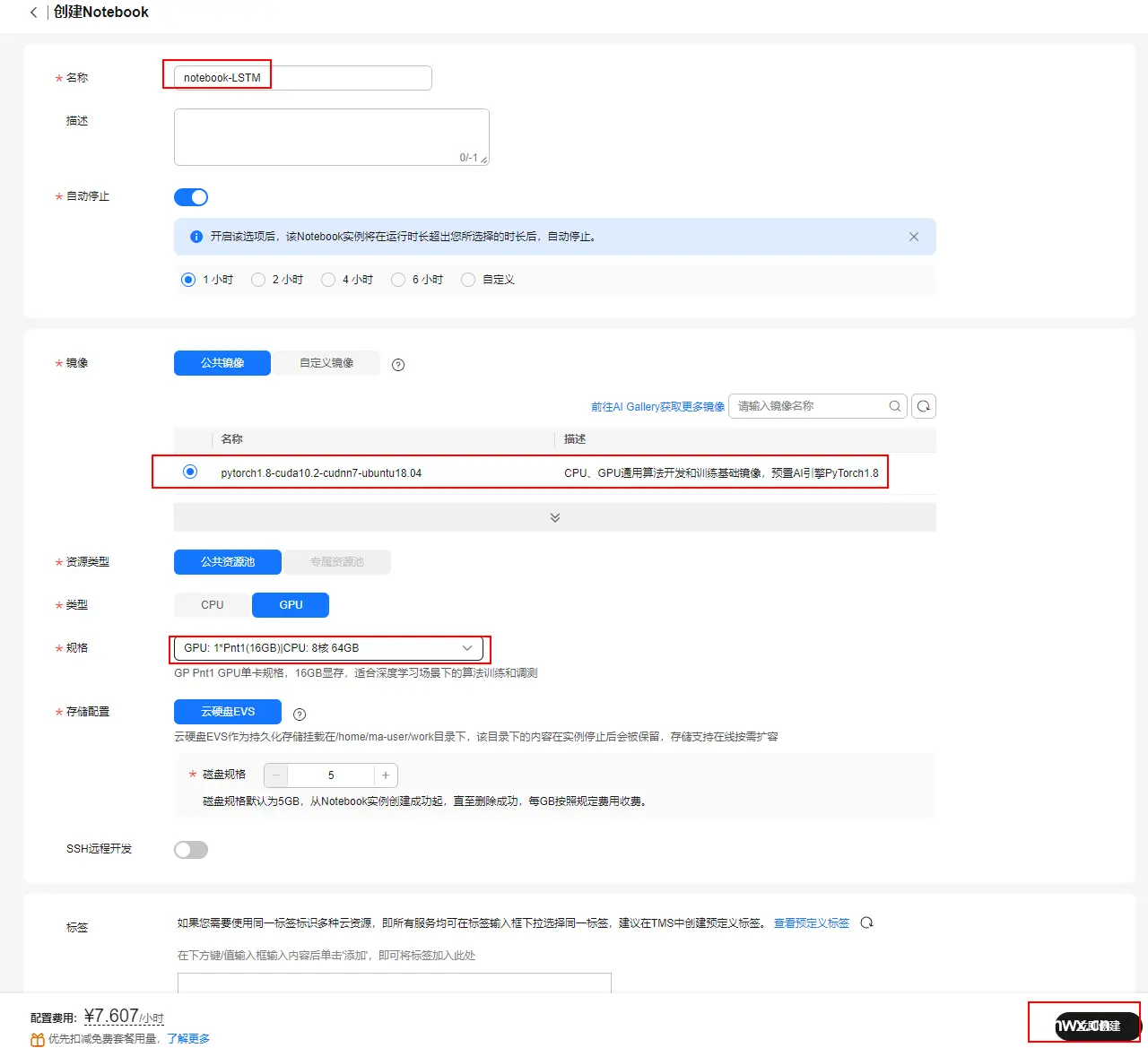
主要参数信息如下,其余配置请保持默认配置
名称:notebook-LSTM(名称固定)
镜像:选择“公共镜像”,并选择“pytorch1.8-cuda10.2-cudnn7-ubuntu18.04”
资源类型:选择“公共资源池”
类型:选择“GPU”
规格:选择“GPU: 1*Pnt1(16GB)|CPU: 8核 64GB”
其他保持默认
确认无误后,点击“立即创建”。
步骤4 提交notebook创建请求
点击“提交”,即开始创建,如下图所示。
点击“立即返回”,稍等片刻即创建成功,您可查看已创建的Notebook。如下图所示:

任务二:进入notebook开发环境
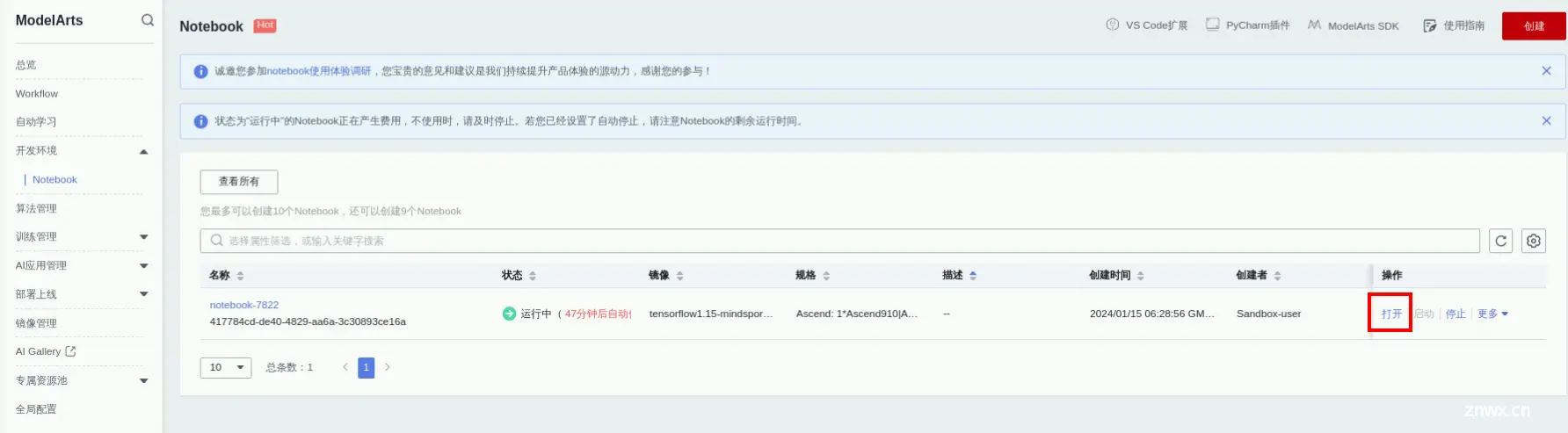
步骤1 打开notebook环境
点击新建的notebook的打开按钮,进入notebook开发环境,如下图所示:
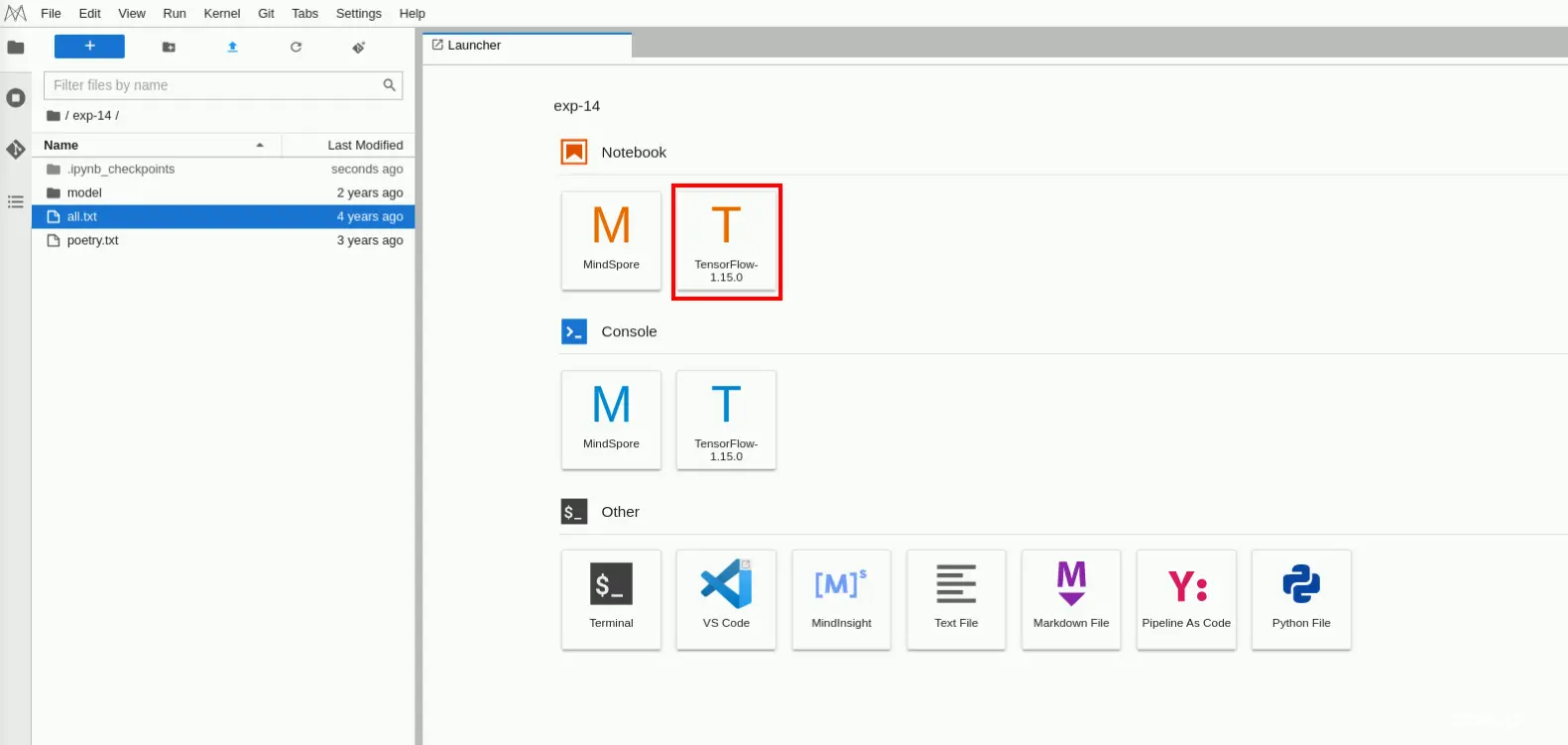
步骤2 进入notebook开发环境
进入tensorflow开发环境,如下图所示:
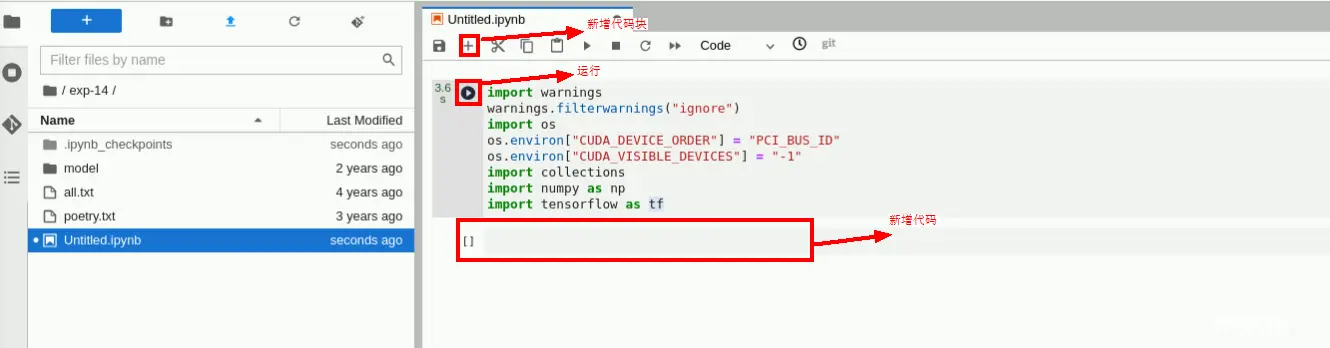
任务三 运行代码
对下文的每个代码片段,在tensorflow开发环境中,新建一个代码块进行运行,如下图所示:
步骤1 安装需要的包
输入:
<code>!pip install torchnet
输出:
Looking in indexes: http://repo.myhuaweicloud.com/repository/pypi/simple
Requirement already satisfied: torchnet in /home/ma-user/anaconda3/envs/PyTorch-1.8/lib/python3.7/site-packages (0.0.4)
Requirement already satisfied: visdom in /home/ma-user/anaconda3/envs/PyTorch-1.8/lib/python3.7/site-packages (from torchnet) (0.2.4)
s (from requests->visdom->torchnet) (1.26.12)
Requirement already satisfied: charset-normalizer~=2.0.0 in /home/ma-user/anaconda3/envs/PyTorch-1.8/lib/python3.7/site-packages (from requests->visdom->torchnet) (2.0.12)
Requirement already satisfied: certifi>=2017.4.17 in /home/ma-user/anaconda3/envs/PyTorch-1.8/lib/python3.7/site-packages (from requests->visdom->torchnet) (2022.9.24)
WARNING: You are using pip version 21.0.1; however, version 24.0 is available.
You should consider upgrading via the '/home/ma-user/anaconda3/envs/PyTorch-1.8/bin/python3.7 -m pip install --upgrade pip' command.
步骤2 获取数据
import moxing as mox
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/course/NLP_Course/LSTM','LSTM_poem-master')
输出结果可刷新查看右边的文件夹:
步骤3 数据集来源和读取数据集
本次采用的是唐诗数据集,一共有接近60000首唐诗,不需要标签,因为AI自动写诗可以看成是语言模型的一个应用
其中一首诗的一句如下:

任务定义:给出一首诗的开头几个词,或者首句(随便),续写之后的句子。
测试结果初窥:

读取数据集
输入:
<code>%cd /home/ma-user/work/LSTM_poem-master
import numpy as np
file_path="tang.npz"code>
poem=np.load(file_path,allow_pickle=True)
poem.files
查看结果:

一些其他操作:
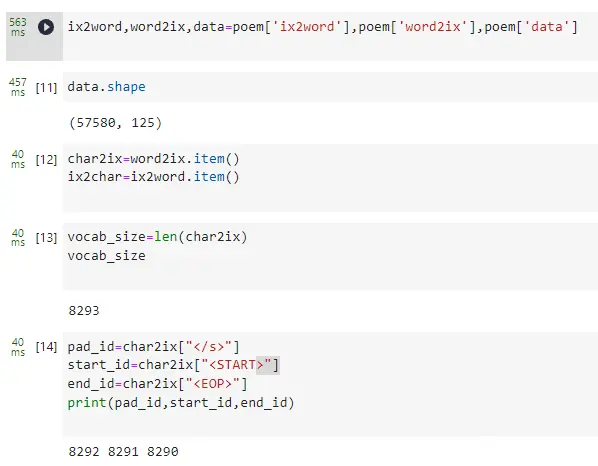
<code>ix2word,word2ix,data=poem['ix2word'],poem['word2ix'],poem['data']
data.shape
char2ix=word2ix.item()
ix2char=ix2word.item()
vocab_size=len(char2ix)
vocab_size
pad_id=char2ix["</s>"]
start_id=char2ix["<START>"]
end_id=char2ix["<EOP>"]
print(pad_id,start_id,end_id)
查看运行结果
步骤4 数据预处理
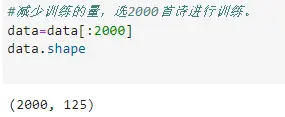
减少训练的量,选2000首诗进行训练。
<code>data=data[:2000]
data.shape
结果:
把放在放到后面,#将数据进行转换。
<code>#把</s>放在放到后面。
def reverse(poem):
ind=np.argwhere(poem==start_id).item()
new_poem=poem[ind:len(poem)]
pad=poem[0:ind]
return np.hstack((new_poem,pad))
#将数据进行转换。
for i in range(len(data)):
data[i]=reverse(data[i])
for i in range(data.shape
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。