(2024,通用逼近定理(UAT),函数逼近,Kolmogorov–Arnold定理(KAT),任意深度/宽度的网络逼近)综述
EDPJ 2024-09-02 15:01:01 阅读 63
A Survey on Universal Approximation Theorems
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
1. 简介
2. 神经网络(NN)
3. 通用逼近定理(UATs)
3.1 UAT:前身
3.2 UAT:任意宽度的情况
3.3 UAT:任意深度情况
4. 结论和进一步阅读
0. 摘要
本文讨论了关于神经网络(NNs)逼近能力的各种定理,这些定理被称为通用逼近定理(universal approximation theorems,UATs)。本文系统地概述了 UATs,从函数逼近的初步结果开始,如泰勒定理、傅里叶定理、魏尔斯特拉斯(Weierstrass)逼近定理、Kolmogorov–Arnold representation theorem (KAT) 等。UATs 的理论和数值方面从任意宽度和深度进行了覆盖。
1. 简介
神经网络(NN)或人工神经网络(artificial neural network,ANN)是由人工神经元按层排列组成的网络 [1, 2]。人工神经元(也称为感知器,perceptrons)受到生物神经网络(biological neural networks,BNNs)中生物神经元的启发 [3]。生物神经元是大脑中 BNN 的信号处理单元,类似地,人工神经元是 ANN 中的数据处理单元。
本文的其余部分仅讨论 ANN 和人工神经元,并将其简单地称为 NN 和神经元。从数学的角度来看,神经元由非线性函数(也称为激活函数)和线性函数的组合构成 [4]。因此,NN,作为神经元的网络,可以被视为非线性函数。
本综述集中于前馈神经网络(feedforward neural networks,FNNs)即多层感知器(multi-layer perceptrons,MLPs)的结果,这些是最简单和最流行的 NN 类别。如今,NN 是人工智能(AI)和机器学习(ML)中最流行的领域之一,因为其能够建模复杂的关系 [5, 6, 7]。UAT 是与 NN 逼近能力相关的定理,即 NN 逼近任意函数的能力 [8]。一般来说,UAT 意味着具有适当参数的 NN 可以逼近任何连续函数,即是能够表示数据中复杂关系的广义模型 [9, 10, 11]。此外,UAT 还关注 NN 的表达能力,描述了 NN(具有给定结构)能够逼近的函数类别 [12, 13]。NN 的结构可以由 NN 中的层数(即深度)和层中最大神经元数(即宽度)来表征。
已有一些关于 UAT 的综述 [8, 14, 15],它们集中于特定领域如软计算、微分几何等。早期的 UAT 综述[8, 16] 仅覆盖了任意宽度方向的结果。尽管 NN 的逼近能力在理论和实践中均有兴趣,但据作者所知,文献中缺乏涵盖任意宽度和深度方向结果的全面综述。这促使了本文的动机,其主要目的是提供一个详细的 UAT 综述,供对该主题感兴趣的学生和研究人员使用。
本文组织如下。第 2 节简要介绍了 NN 及其相关术语。第 3 节从函数逼近的初步结果开始,随后是任意宽度和任意深度方向的 UAT。最后,第 4 节给出了结论和进一步阅读的建议。
符号和定义:N 和 R 分别表示自然数集和实数集。R^n 表示 n 维欧几里得空间,R^(m×n) 表示 m×n 实数矩阵空间。向量 x ∈ X ⊆ R^n 的 p-范数或 l^p 范数定义为:

函数 f: X→Y 的 L^p 范数定义为

Lebesgue 空间或 L^p 空间是包含满足

的可测函数 f 的函数空间。 如果 R^n 的子集 X 是闭合且有界的,则称其为紧集(compact)。如果拓扑空间 T 的子集 S 的每个元素要么属于 T,要么与 T 的某个元素任意接近,则称其在 T 中是稠密的(dense)。拓扑空间的例子包括欧几里得空间、度量空间(metric spaces)、流形(manifolds)等。
2. 神经网络(NN)
NN 是由神经元按层排列组成的网络。这些层是顺序连接的,即每层的输出作为输入传递到下一层。这形成了一个网络或多层配置。因此,NN 可以表示为以下形式的复合函数 [17]:

其中 x ∈ R^n 是输入,y ∈ R^m 是预测输出,f_NN: R^n→R^m 是 NN 函数,f0,f1,...,f_(L+1) 是 NN 的各层。其中, f_0 表示输入层,f_(L+1) 是输出层,f1,...,fL 是隐藏层(见图 1(a))。
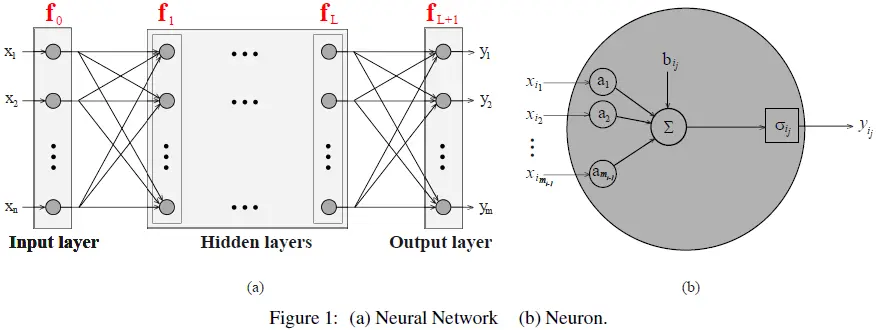
隐藏层的数量记为 L,因此神经网络中的总层数为 L+2,即包括输入层和输出层。设第 i 层的输入记为 xi,第 i 层的输出记为 y_i。则 NN 的每一层可以表示为:


其中 σi 包含了第 i 层的逐元素激活函数,m_i 是第 i 层的神经元数量,Ai∈R^(m_i × m_(i−1)) 是权重矩阵,bi ∈ R^(mi) 是偏置向量,xi∈R^(m_(i−1)),yi∈R^(mi)。注意,方程(5)中的层本身是复合函数,而NN是层的组合,也因此成为复合函数。仿射项(affine term) Ai·xi + bi 是 NN 的线性部分,而激活函数是非线性部分。一般来说,任何实值函数都可以用作激活函数。以下是常用的激活函数 [18]:
1)ReLU(修正线性单元,Rectified Linear Unit))函数:

2)阶跃(Step)函数:

3)逻辑(Logistic)函数:

4) 双曲正切(Hyperbolic tangent,Tanh)函数:

这些函数的图示见图 2。注意,逻辑函数和双曲正切函数属于 sigmoid(S 型)函数。一般来说,sigmoid 函数是一个有界函数(常规范围为 [0, 1]),在 R 的每个点上具有非负导数,并且恰好有一个拐点,即 sigmoid 函数的特征是如图 2(c) 和 (d) 所示的 sigmoid 曲线。
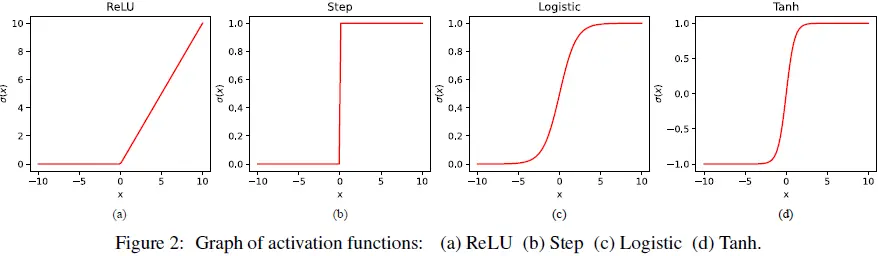
与 NN 相关的术语及其简要描述如下:
神经元(Neuron):是 NN 中的数据处理单元。神经元可以表示为一个标量值函数:

其中 y_ij 是第 i 层中第 j 个神经元的输出,A_ij = [a1,a2,…,a_(m_(i−1))] 是权重矩阵 Ai 的第 j 行,b_ij 是偏置向量 b_i 的第 j 个元素(见图 1(b))。
层(Layer):是一组接收相同输入的神经元。一般来说,层是向量值函数。层可以分为三类:输入层、输出层和隐藏层。
输入层(Input layer):每个神经元只有一个输入,并且它只是简单地传递输入,即
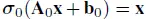
隐藏层(Hidden layer):每个神经元可以有多个输入,并且给出一个标量输出。激活函数通常是非线性的。
输出层(Output layer):每个神经元可以有多个输入,并且给出一个标量输出。在回归问题中,激活函数通常是线性的,而在分类问题中则是非线性的。
宽度(Width):是层中神经元的最大数量,即宽度 W=max_i m_i。
深度(Depth):是隐藏层的数量加上输出层的数量,即深度 D=L+1。
浅层神经网络(Shallow NN):是只有一个隐藏层的 NN,即 D=2。
深层神经网络(Deep NN):是有多个隐藏层的 NN,即 D>2。
例如,我们可以考虑一个具有一个输入、一个输出、一个线性输出层和一个包含三个神经元的隐藏层的 NN,可以表示为:

令

方程 (11) 可展开为

并且对于 x∈[−10,10],我们可以通过代入方程 (11) 来计算输出。图 3(a) 显示了输出 y 的图示。

现在,通过将 A2 改为 [−0.4,0.2,−0.3] 并保持 A1 不变,我们得到图 3(b) 中的输出。同样,对于 A2=[−0.3,0.5,0.1] 和 A2=[0.2,−0.7,0.6],输出分别如图 3(c) 和 (d) 所示。
这些例子说明了我们可以使用 NN 表示复杂的非线性关系。由于 NN 的主要用途是建模数据中的关系,因此 NN 的逼近能力问题自然引起了人们的兴趣。现在的问题是,我们能否使用 NN 逼近任何连续函数?这引出了所谓的通用逼近定理(UATs),下面将讨论这些理论结果。
3. 通用逼近定理(UATs)
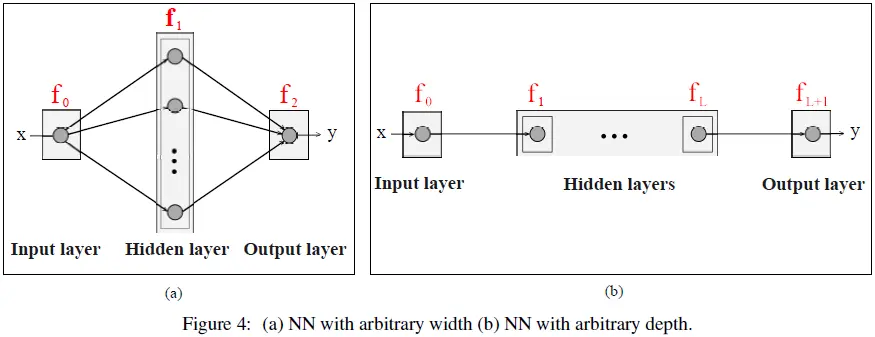
通用逼近定理(UATs)是与 NN 逼近能力相关的理论结果。一般来说,UAT 在以下方向进行探讨:
任意宽度:研究具有任意数量神经元(但隐藏层数量有限)的 NN 的逼近能力。例如,图 4(a)显示了一个具有一个隐藏层并且具有任意数量神经元的 NN。任意深度:研究具有任意数量隐藏层(但每层神经元数量有限)的 NN 的逼近能力。例如,图 4(b) 显示了一个具有任意数量隐藏层且每层有一个神经元的 NN。

在讨论任意宽度和深度情况下的 UAT 之前,简要总结一下函数逼近的初步结果。
3.1 UAT:前身
NN 以所需精度逼近任意函数的能力具有理论和实际意义。理论兴趣源于线性代数 [4]、分析学 [19]、拓扑学 [20] 等数学领域。将一个连续函数表示为简单分量(也称为基函数)的叠加的问题早已被研究。该方向的初步结果之一是泰勒定理 [21, 22],如下所述:
定理 1(泰勒,1715 年):任何在 a∈R 处 k 次可微的连续函数 f(x):R→R 可以表示为多项式的和:
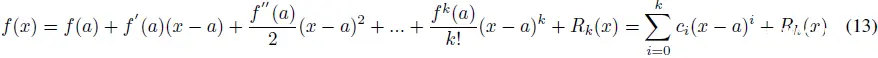

其中 R_k(x) 是余项。
当 a=0 时,方程(13)的特例为:

这是更常用的版本,称为麦克劳林级数(Maclaurin series)。泰勒/麦克劳林级数表明,多项式函数可以以足够的精度逼近任何连续的光滑函数。泰勒定理可以被认为是基于线性化方法的数学基础。类似的想法在傅里叶级数 [23, 24] 中也有所体现,其中初始结果是针对周期函数的:
定理 2(傅里叶,1807 年):任何连续的周期函数 f(x) 都可以表示为正弦波的和:

其中 T 是函数的周期,Ai 是第 i 个谐波分量的幅度,ϕi 是相位。
后来,这些结果被推广到非周期函数,产生了傅里叶变换。傅里叶级数和变换引发了频域分析和设计方法的产生。另一个里程碑是魏尔斯特拉斯(Weierstrass)逼近定理 [25],可以看作是泰勒定理向任意连续函数的扩展,如下所述:
定理 3(魏尔斯特拉斯,1885 年):任何定义在区间 [a,b] 上的连续实值函数 f(x):[a,b]→R 都可以用一个有限阶数(N)的多项式函数
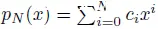
来逼近,使得对于任意的 ϵ>0,有:
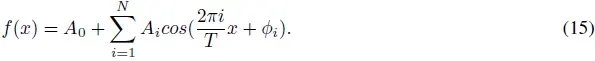
魏尔斯特拉斯定理表明,在一个闭区间上的任何连续函数都可以由一个多项式函数以任意精度均匀逼近。魏尔斯特拉斯逼近定理可以被认为是多项式回归和插值方法的数学基础。
在 20 世纪初,分解连续多变量函数为有限个连续单变量和双变量函数叠加的问题吸引了大量研究兴趣。这始于希尔伯特第十三问题的连续变种 [26]:是否可以将任何多于两个变量的连续函数表示为有限个双变量连续函数的叠加?这个问题由 Kolmogorov 和 Arnold 在 1957 年解决,产生了 Kolmogorov-Arnold 表示定理 [27],如下所述:
定理 4(Kolmogorov-Arnold,1959 年):任何连续多变量函数 f: [0,1]^n → R 可以表示为:

其中 α_ij: [0,1]→R, β_j: R→R。
上述定理 1 到 4 揭示了正弦函数、多项式函数等的逼近能力。在 NN 引入后,sigmoid 函数的逼近能力开始流行,因为在 NN 的初始版本中使用了 sigmoid 函数作为激活函数。后来,不同激活函数如 ReLU、阶跃 和 tanh 的 NN 的逼近能力被引入。这导致了几种被称为通用逼近定理(UATs)的定理,这些定理将在本文的其余部分讨论。
3.2 UAT:任意宽度的情况
本节讨论具有任意大宽度的 NN 的逼近能力。NN 的深度或层数被认为是有限的。例如,考虑以下具有一个隐藏层且使用 ReLU 激活函数和线性输出层的 NN:

这些方程分别对应于具有一个隐藏层神经元 (a, b)、两个神经元 (c) 和三个神经元 (d) 的 NN。对于这些情况,输出如图 5 所示。图中的曲线表明,曲线中的折叠数随着神经元数量的增加而增加。例如,图 5 (c) 和 (d) 中的曲线分别具有两个和三个折叠,对应于具有两个和三个隐藏层神经元的 NN。这表明通过一个具有任意神经元数量的 NN,可以在曲线中引入任意数量的折叠。
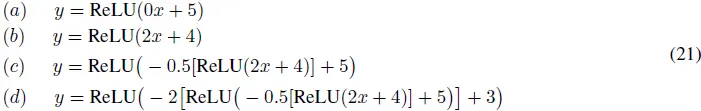
这些结果展示了 NN 在引入曲线复杂性方面的能力,这为其逼近任意连续函数提供了理论基础。
折线也称为分段线性曲线。因此,使用一个隐藏层和 ReLU 激活函数,可以获得连续函数的分段线性逼近。关于折叠数量和线性部分的理论结果在文献 [28] 中有所介绍,其陈述如下:
定理 5 (Pascanu et al., 2013):考虑函数 f_NN(x) 的图像,它沿着由线性方程

定义的 H 个超平面折叠。则 f_NN 的线性部分的数量为:
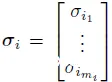
通常,随着隐藏层中神经元数量的增加,逼近能力(输出中的折叠或弯曲数量)也会增加,这可以从图 5 中观察到。这使得具有足够数量神经元和隐藏层的 NN 成为通用逼近器,可以用于建模具有任意模式的数据,即 NN 是广义模型。这是 UAT 的核心思想。
UAT 的初始版本在 20 世纪 80 年代引入,尝试将 Kolmogorov-Arnold 表示定理和其他初步结果扩展到 NNs。在 Cun [29] 和 Lapedes和Farber [30] 的研究中,已经表明,使用具有两个隐藏层和单调激活函数的 NN 可以任意逼近连续函数。Irie 和 Miyake [31]表明,一个具有无限神经元的单隐藏层网络可以逼近任意函数。随后,Gallant 和 White [32] 表明,一个具有单调余弦激活函数的单隐藏层可以给出给定函数的傅里叶级数逼近。然而,这种逼近仅限于紧集上的平方可积函数(参见 Dirichlet 的傅里叶级数逼近条件 [33])。随后,Funahashi [9],Hornick 等[10],和 Cybenko [11] 通过对紧集上任意连续函数的这些结果进行了推广,提出了在任意宽度情况下的 UAT 的流行版本。
UAT 大多通过 NN 生成的函数 f_NN(x) 在给定的感兴趣函数空间内的密度来陈述,即如果 f_NN(x) 在给定空间中是密集的,那么,该空间中的任何函数都可以由 f_NN 逼近。这引出了以下定理:
定理 6 (Funahashi, Hornick et al., 和 Cybenko, 1989):设 X 是 R^n 的任何紧子集,并且 σ 是任意的 Sigmoid 激活函数,则形式如下的有限和:
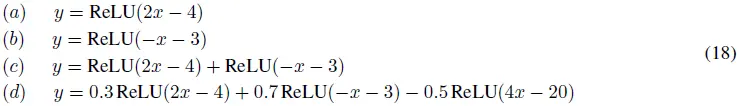
在 X 上是稠密的。换句话说,给定任意的 f: X→R 和 ϵ>0,存在如公式 (20) 所示的有限和 f_NN,使得对于所有 x∈X 都有

上述定理意味着,具有一个隐藏层和 Sigmoid 激活函数的 NN 可以以任意精度逼近有界域上的任何连续单变量函数。Hornik [34] 表明,NN 具有通用逼近能力的主要原因是多层前馈架构。在文献 [35] 中,表明具有非多项式激活函数的多层感知器(MLP)是通用逼近器,这导致了以下定理:
定理 7 (Leshno et al., 1993):设 X 是 R^n 的任何紧子集,并且 σ 是激活函数,则当且仅当 σ 不是多项式函数时,公式 (20) 中的有限和在 X 上是稠密的。
后来,对于其他激活函数如 ReLU、阶跃函数、tanh 等(这些都是非多项式函数)也发展了类似的定理。因此,深度为 2 的 NN(即具有一个隐藏层的 NN,也称为浅层 NN)与合适的激活函数是通用逼近器。同样,具有多个隐藏层的 NN(即深度NN)也是如此。然而,深度为 1 的 NN 或没有任何隐藏层的 NN 具有有限的逼近能力。更多关于浅层 NN 的 UAT 结果可以在 [36, 37] 中找到。
3.3 UAT:任意深度情况
本节重点讨论深度 NN(即具有任意深度和有限宽度的 NN)的逼近能力。任意深度情况在最近获得了很多研究兴趣,特别是在深度学习作为机器学习中的一个独立领域引入之后。为了更好地理解这一思想,我们从每层只有一个神经元的 NN 开始,即如图 4(b) 所示的宽度为 W=1 和任意深度的NN。在这种情况下,每一层将是一个标量值函数。考虑以下具有 ReLU 激活函数的 NN 在隐藏层和一个线性输出层:

这些分别对应于具有一个隐藏层(a,b)、两个隐藏层(c)和三个隐藏层(d)的NN。对于这些情况,其输出如图 6 所示。

对于每层只有一个神经元且具有 ReLU 激活函数的 NN,输出可以是直线(如图 6(a) 所示)、具有一个折点的分段线性曲线(如图 6(b) 所示)或具有两个折点的分段线性曲线(如图 6(c) 和 (d) 所示)。图 6(c) 中的倾斜部分可以通过乘以一个权重来旋转,这会改变斜率。然而,图 6(c) 中的水平部分对应于恒定输出,因此乘以一个权重项仍然是恒定输出。这意味着图 6(c) 中的水平部分不能通过线性映射进行旋转。因此,在两个折点之后,后续层无法增加任何进一步的折点,这可以在图 6(d) 中观察到。然而,通过增加隐藏层中的神经元数量(如公式 (21) 所示),折点数量可以增加到超过 2 个。这表明宽度为 1 的具有 ReLU 激活函数的 NN 的逼近能力有限。这同样适用于其他激活函数。关于这一方面的理论结果在文献 [13] 中有所介绍,具体如下:
定理 8 (Lu et al., 2017):除了一个可以忽略不计的集合,所有函数 f:R^n→R 不能被任何宽度 W≤n 的 ReLU 网络所逼近。
上述定理表明,宽度为 1 的 NN 只能逼近一小类单变量函数,即通用逼近所需的最小宽度应大于1。类似的结果可以在文献 [38] 中找到。这引出了找到具有DNN 的通用逼近所需最小宽度的问题。该方向的一个初步结果表明,宽度为 n+4 的 NN 具有 ReLU 激活函数是通用逼近器,如下所述 [13]:
定理 9 (Lu et al., 2017):对于任意勒贝格可积(Lebesgue-integrable)函数 f: R^n→R 和 ϵ>0,存在一个宽度 W≤n+4 且具有 ReLU 激活函数的神经网络 f_NN 满足:

这意味着具有任意隐藏层和每层最多 n+4 个神经元的 NN 可以以足够的精度逼近勒贝格可积空间中的任何函数。后来,研究表明在深度 NN 中通用逼近所需的最小宽度是 n+1,这导致了以下定理 [39]:
定理 10 (Park et al., 2021):勒贝格可积函数 f: R^n→R^m 的通用逼近所需的最小宽度是 max{n+1,m}。
因此,宽度为 2 的 NN 与合适的激活函数也是连续单变量函数的通用逼近器。关于宽度有限的 NN 的 UAT 的类似结果可以在文献 [40, 41] 中找到。除此之外,文献中还研究了深度有限和宽度有限的 NN 的 UAT [42, 43]。
4. 结论和进一步阅读
本文讨论了 NN 逼近能力的主要结果和定理。本文重点介绍了前馈 NN 或多层感知器(MLP)的 UAT。其他版本的 NN(如 CNN [44, 45]、残差网络(ResNet)[46, 47]、RNN [48, 49]、transformer [50] 等)的 UAT 的扩展可以在文献中找到。关于 NN 和 ML 的其他主题,可以参考 [4, 7] 中的书籍。本文中讨论的示例的 Python 代码可在 GitHub 上找到。
项目页面:https://github.com/MIDHUNTA30/NN-PYTHON
论文地址:https://arxiv.org/abs/2407.12895
上一篇: FLUX + LoRA 实测,AI 绘画开启新纪元,5分钟带你部署体验
下一篇: 时间序列预测方法概述
本文标签
Kolmogorov–Arnold定理(KAT) 通用逼近定理(UAT) 任意深度/宽度的网络逼近)综述 (2024 函数逼近
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。