啥是RLFH标注、SFT标注、RM标注?一篇文章让你系统了解大模型标注
AI数据标注猿 2024-09-11 12:31:01 阅读 85
标注猿的第80篇原创
一个用数据视角看AI世界的标注猿
大家好,我是AI数据标注猿刘吉,一个用数据视角看AI世界的标注猿。
世界人工智能大会过后,感觉市场都变得热闹了起来呢,就连社区群里也变得热闹了,从找标注项目到找数据资源,大家对于数据的需求果然还是真实的。
最近接触到的大模型项目也多了起来,虽然还是一如既往的不稳定,但是需求增多的还是明显。所以最近也组建了一个小语种的团队,都是具有多年翻译经验的小伙伴,做这方面业务的小伙伴欢迎私信交流。
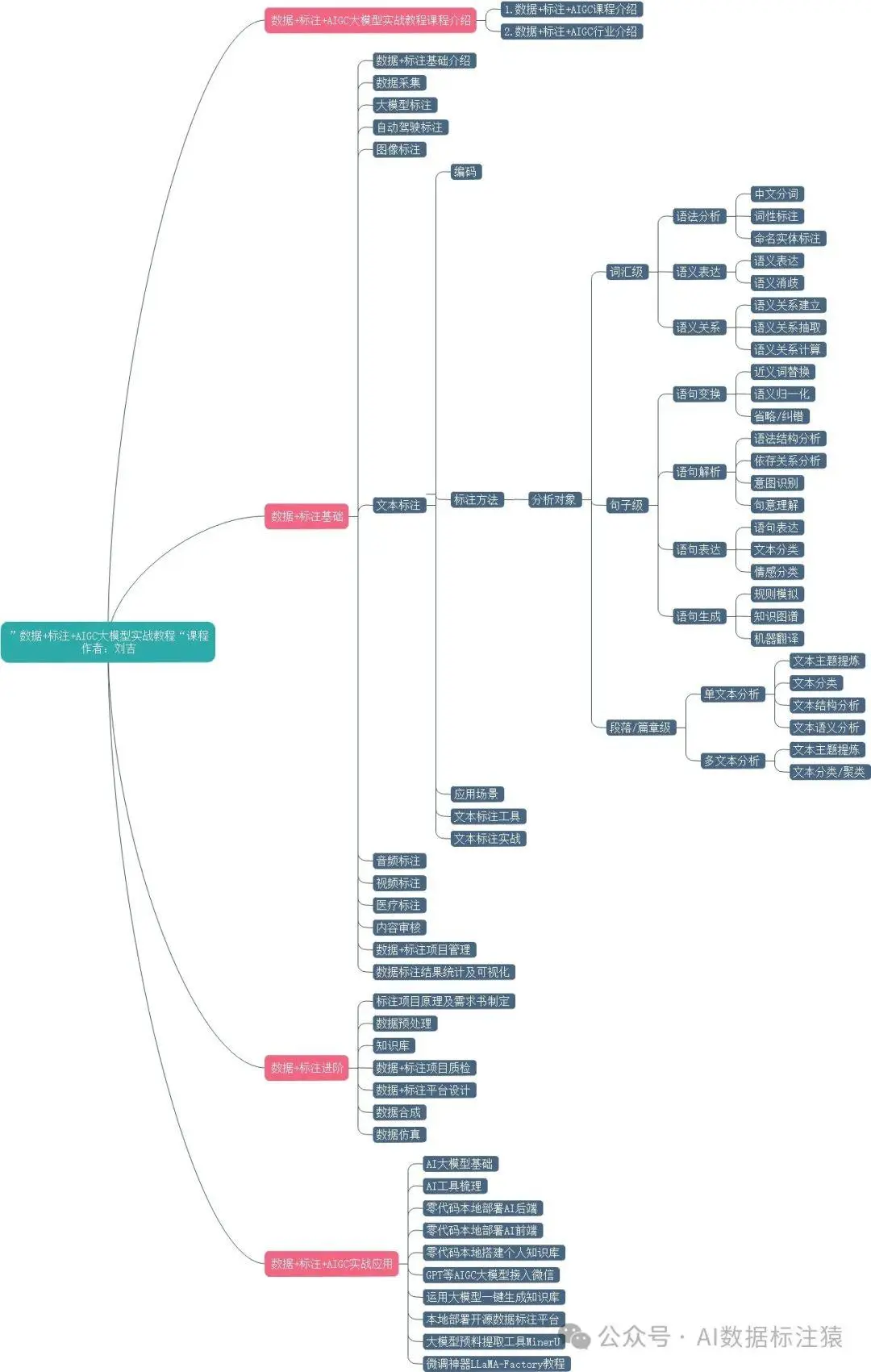
言归正传,在做大模型的过程中,也和很多小伙伴沟通了目前已有的大模型标注项目类型,包括我在内的很多小伙伴对自己做的项目都有点一知半解,只是在不断的跟着需求在做数据。所以就利用一些时间系统的整理了关于大模型标注的相关内容做一个学习和分享。本文会从以下几个方面进行讲解:
从NLP阶段开始梳理相关的文本标注
大模型中的数据标注需求
一.从NLP阶段开始梳理相关的文本标注
最开始接触文本类标注的时候应该是在2016年的时候,那个时候刚入行。到现在也有8年的时间了。我记得很清楚第一个文本标注项目是金融新闻类文本标注,标注内容是实体和实体关系标注。
接到项目的确不太理解需求内容是什么,开始查相关资料理解需求,用了大概一个星期的时间把需求理解清楚标注工具也开发了一版能用的。那个阶段真是谈不上好用,能用就行。
不过再从现在的需求来看,已经基本用不到那个阶段的标注方法了。就拿实体、分词举例大部分都已经处理完了,词库也非常丰富了。可能只有一些极不常见的行业或者业务才能用到了。
但是要说之前NLP阶段的那些标注逻辑真完全没有用了么?我觉得也不是,真的可以帮你更深入得理解语义,别忘了GPT也是基于Token的。而大模型阶段基本上都是针对语义理解的标注。
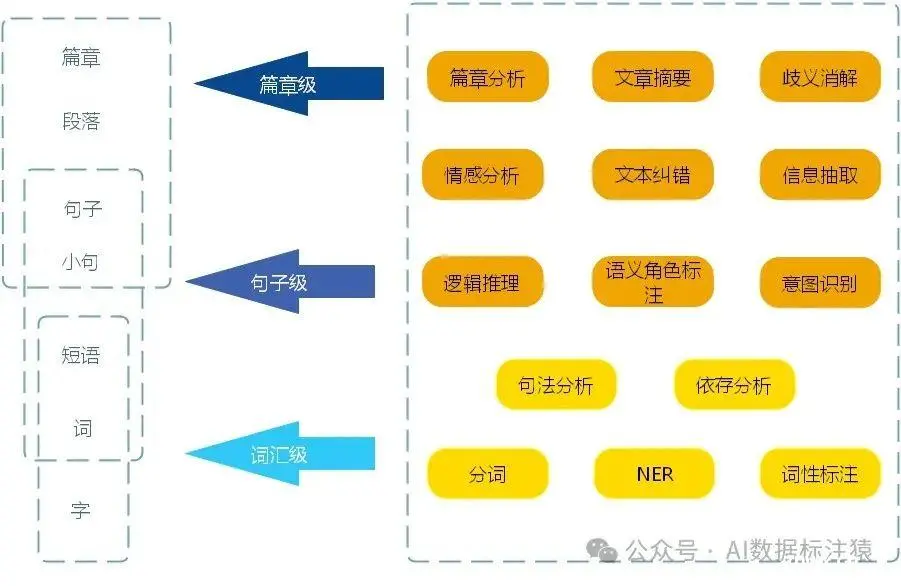
在这里我就不详细介绍NLP相关标注的内容了,我列举了一个导图,详细列举了相关标注方法。
本文重点来讲解一下目前涉及到的文本大模型中的数据标注需求。与之前NLP阶段的标注需求相比较大模型的标注需求基本都是基于语义理解的标注。标注方法变简单了,但是标注理解难度增加了。
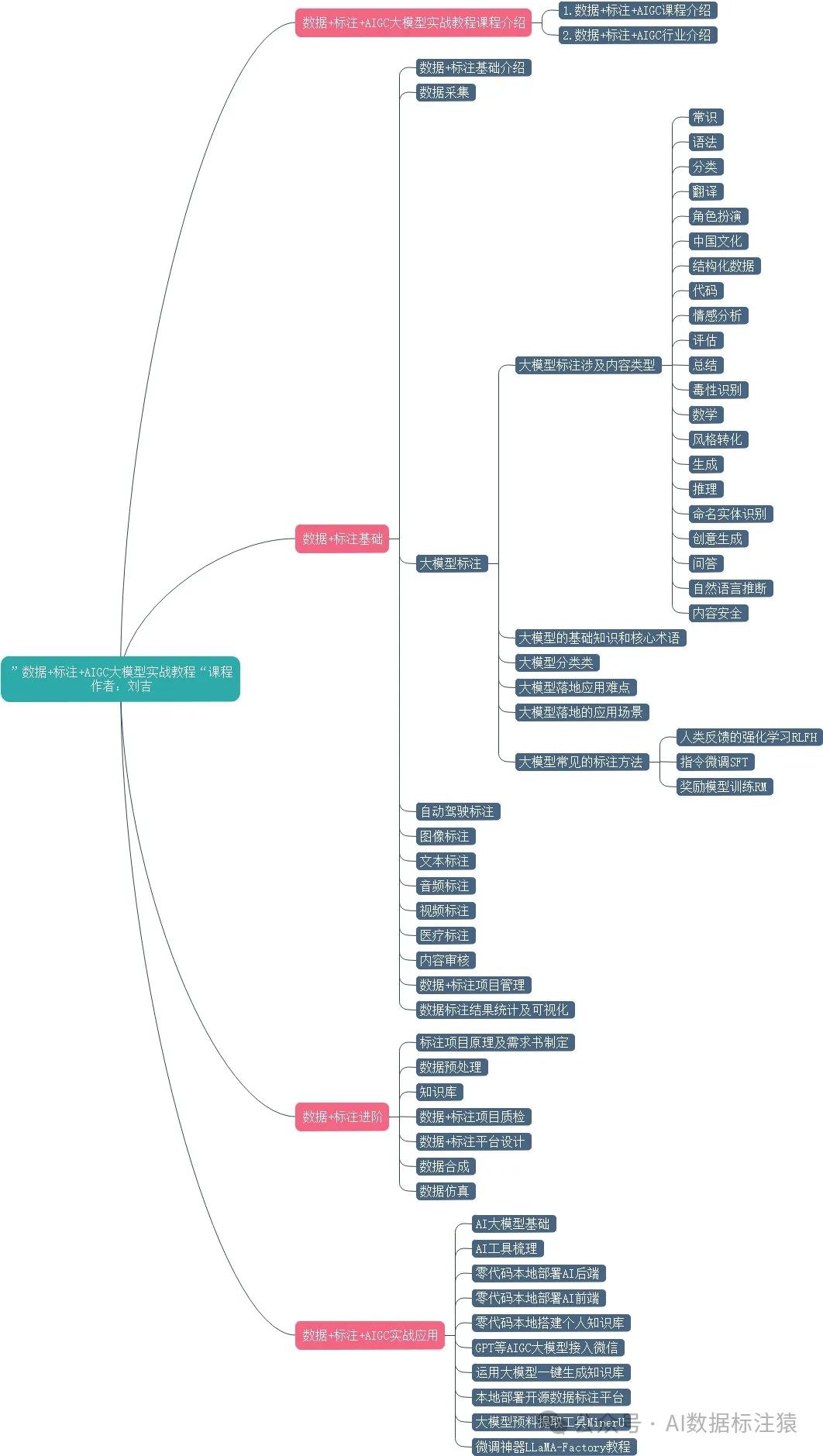
相比于传统的基于“给定上下文,预测下一个词”的NLP算法来说,大模型在训练阶段引入了人类偏好或者人类的反馈来对模型整体的输出结果进行进一步优化。
而所谓的大模型标注就是在每个训练阶段提供基于人类反馈生成的人类偏好数据集。
接下来我们就针对目前已有的这个标注都是啥具体学习学习。
RLFH(Reinforcement Learning from Human Feedback)人类反馈的强化学习:是一种训练和微调大型语言模型的方法,使其能够正确遵循人类指令。用人类反馈的数据训练奖励模型,用奖励模型生成奖励信号。
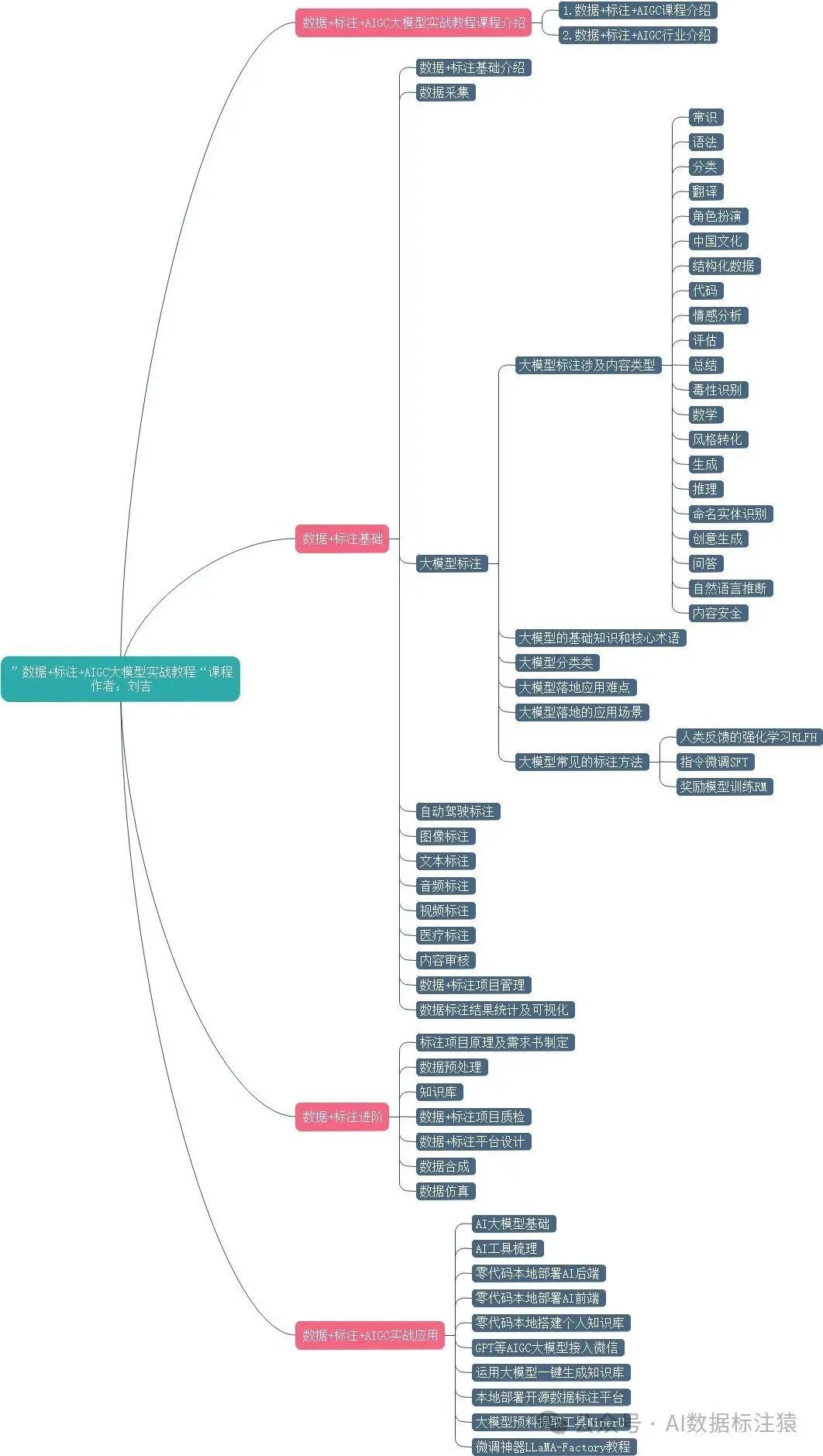
RLFH最核心的步骤就训练奖励模型(reward model,RM),奖励模型就是利用基于人类反馈生成的人类偏好数据集,训练代表特定任务所需结果的奖励函数。然后利用奖励模型,通过强化学习算法近端策略优化(Proximal Policy Optimization,PPO)迭代地改进原始输入的监督微调SFT 模型,以改变其内部文本分布以优先考虑人类喜欢的序列。
目前RLHF的优化训练主要可以分为以下三个步骤阶段:
指令微调(SFT):使用精选的人类回答数据集来微调预训练的大语言模型以应对各种查询。
指令微调SFT (Supervised fine-tuning) 的数据集是问答对,即 (prompt, answer) 对,prompt我们可以理解为指令或问题,answer就是针对该指令或问题的高质量答案。SFT 就是在预训练模型基础上利用这些人工标注的数据进一步微调。
所以在这部分的标注基本上就是问答对标注,基本上包含三种形式的标注方法:
问答对编写标注:这部分标注工作一般在项目初期,目前大模型公司在这个阶段相对少了。接下来如果是一些企业要训练自己的大模型的时候这个阶段的需求会相对比较多一些。但是这部分标注可能会更多的内部人员完成。
原本在这个阶段的标注会消耗很大一部分资金,但国内的大部分大模型公司最终只消耗了ChatGPT API调用的费用,就完成了0到1的过程。
这里足可以说明国内公司的聪明机智。不过提示一下,咱能不能把字段命名的GPT4-Answer改一下,别这么直接,也太通熟易懂了吧。
问答对判断:目前这部分的标注是比较多的,大部分公司选择的是在自己大模型的生成结果和其他大模型的生成结果进行比较,选择一个比较优的结果。目前我已知的都是跟GPT结果做比较。
问答对优化:利用问答对判断的方法,进行判断之后,在对不理想的结果进行人工优化。
为了提升大模型的帮助性、降低有害性会不断的做SFT,通过高质量的数据给模型展示无害的、有帮助性的回答,规训模型的生成内容。
奖励模型训练(RW):使用一个包含人类对同一查询的多个答案打分的数据集训练一个奖励模型。
训练奖励模型,即通过手动对同一提示的不同输出进行排序来分配相应的分数,然后进行监督奖励模型的训练,生成一个用人类偏好校准的奖励模型(RM,也称为偏好模型)。
训练奖励模型的基本目标是获得一个模型,该模型接收一系列的文本,之后返回每个文本对应的标量奖励,该奖励会在数字值的大小上代表人类偏好,越大表示越接近人类偏好,越小表示越脱离人类偏好。标量奖励的输出是RLHF最为关键的一步,对RLHF过程中的强化学习RL算法至关重要。
训练RM的数据集包含同一提示的不同输出,query表示提示信息或者说指令信息,chosen为标注后排序分数较高的答案,即针对提示选择的答案;rejected为标注后排序分数较低的答案,即针对提示拒绝的答案。训练的目的就是让生成的用人类偏好校准的奖励模型会给chosen的答案分数高,而给rejected答案的分数低。
训练RM是一个排序任务,针对query,输入chosen和rejected答案,训练目标尽可能的使得chosen答案和rejected答案的差值更大。
在这个阶段的标注中,openai在训练chatGPT时,针对相同的query(在大模型背景下即是prompt)会生成4-9个不同的答案,任意抽取两个答案交由标注人员评估相对优劣,这样根据排列组合原理,相同query根据生成答案的数量,可以形成(6, 36)个不同的训练集。这里之所以会使用排序标注方式,是因为标注数量的要求,很难只使用一个标注人员,如果使用多个标注人员,直接对生成结果打分可能很不稳定。
看到这里或许就明白了,为什么很多大模型公司在试标阶段一次会安排每个标注员进行那么多轮的试标而且每次试标数据都高达几百条。基于人类反馈的标注不管结果选择是什么,其都应该是有价值的。
所谓的没有价值就应该是没有迎合算法所需的策略,或者由于需求不明确导致的结果一致性不好,那这部分试错成本本应该是由算法公司承担,反而通过试标的方式转嫁给了服务商。
这里也足可以看到国内的大模型公司的更加聪明机智了,国外大模型公司发展拼的是真金白银的投入,国内大模型公司拼的谁更能薅羊毛,能薅一把是一把的那种。
近端策略优化(PPO:Proximal Policy Optimization):是一种基于策略的强化学习算法,旨在通过改进策略梯度方法来优化学习过程。PPO算法的关键步骤包括收集数据、计算优势估计、优化目标函数和更新策略,通过这些步骤,PPO算法能够有效地提高学习效率并保持学习过程的稳定性。
利用 PPO算法,根据 RW 模型的奖励反馈进一步微调指令微调后的SFT 模型。
它的核心思路是借用强化学习进一步微调大模型的生成策略,使得生成结果对齐(Alignment)人类的价值体系。SFT的优化目标比较直接,但是忽略了几个关键因素,因而需要进一步优化,openAI选择了PPO算法。
基于上面的分析,我们可以得出在这个训练过程中,会涉及到如下标注工作:
反馈采集:
直接反馈:评估模型生成的输出(例如对话系统中的回复),并给出明确的评分或评价。例如,人类可能会对模型的回答打分,从1到5不等,或者指出回答中的具体问题。
比较反馈:对比模型生成的多个输出,并选择最优或次优选项。这种比较反馈帮助模型了解在不同选项中哪个更符合人类偏好。
行为示范:
行为示范数据:提供正确或期望的行为示范。例如,在机器人控制任务中,人类操作机器人完成任务,并记录操作数据。这些示范数据用于教模型如何执行任务。
标注奖励信号:
奖励/惩罚信号:根据人类反馈生成的奖励信号。这些信号可以是直接的正面或负面反馈(如“好”或“差”),或者是更复杂的评分系统。奖励信号用于训练奖励模型,使其能够预测人类反馈。
反馈数据处理:
数据清洗和预处理:对收集到的反馈数据进行清洗和预处理,确保数据的质量和一致性。这包括处理缺失值、纠正错误和标准化评分等。
训练奖励模型:
奖励模型训练数据:使用标注的反馈数据训练奖励模型。奖励模型是一个预测模型,旨在根据人类反馈估计每个行为或输出的奖励值。此步骤需要大量高质量的标注数据,以确保奖励模型的准确性。
反馈循环:
持续反馈收集和标注:在模型的迭代训练过程中,持续收集和标注新的反馈数据。这确保了模型可以不断地从新的数据中学习和改进。
错误分类和原因标注:
错误类型分类:对模型输出中的错误进行分类,例如语法错误、逻辑错误、上下文不一致等。每种错误类型都有相应的标签,帮助模型识别和避免类似错误。
错误原因分析:标注具体错误的原因,提供详细的解释。这有助于模型更好地理解为什么某个输出不符合期望,从而改进其行为。
情感和语气标注:
情感标注:对对话或文本中的情感进行标注,例如快乐、悲伤、愤怒等。情感标注帮助模型在生成回应时更好地把握情感基调。
语气标注:标注文本的语气,如礼貌、正式、友好、幽默等。这有助于模型在不同场景下调整语气,使其输出更符合用户期望。
上下文关联标注:
上下文一致性:标注对话或文本中上下文的一致性,确保模型在生成新内容时能够与之前的内容保持一致。
相关性标注:标注输出内容与输入内容的相关性,确保模型生成的内容是相关且有意义的。
偏见和公正性标注:
偏见识别:标注输出中的潜在偏见,例如性别偏见、种族偏见等。这有助于模型学习避免这些偏见,生成更加公正的内容。
公正性检查:对模型输出进行公正性检查,确保其内容符合道德和社会规范。
复杂任务的分步骤标注:
任务分解标注:将复杂任务分解为多个步骤,并对每个步骤进行标注。这有助于模型在处理复杂任务时能够逐步执行,提高准确性和效率。
步骤关联标注:标注各步骤之间的关系和依赖性,确保模型在执行任务时能够合理安排步骤顺序。
多模态标注:
视觉和文本联合标注:对包含图像和文本的任务进行联合标注,例如图像描述、视频中的对话标注等。这有助于模型处理多模态数据。
音频和文本联合标注:对音频数据进行转录并标注语音中的情感、语气等特征。
用户体验反馈:
用户满意度标注:收集用户对模型输出的满意度评分和反馈,标注用户体验相关的数据。
交互流畅性标注:标注用户与模型交互的流畅性,包括响应时间、交互次数等。
生成数据合规审核:
生成数据合规:对大模型生成数据进行安全合规审核。
以上就是对大模型相关数据标注的整理,主要是基于已有项目需求、相关资料的分析整理。欢迎小伙伴们的指正补充交流。
上一篇: 【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
下一篇: 从零训练一个多模态LLM:预训练+指令微调+对齐+融合多模态+链接外部系统
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。