算法金 | 再见!!!梯度下降(多图)
cnblogs 2024-06-20 08:13:00 阅读 90

大侠幸会,在下全网同名「算法金」
0 基础转 AI 上岸,多个算法赛 Top
「日更万日,让更多人享受智能乐趣」
接前天 李沐:用随机梯度下降来优化人生!
今天把达叔 6 脉神剑给佩奇了,上 吴恩达:机器学习的六个核心算法! ——梯度下降
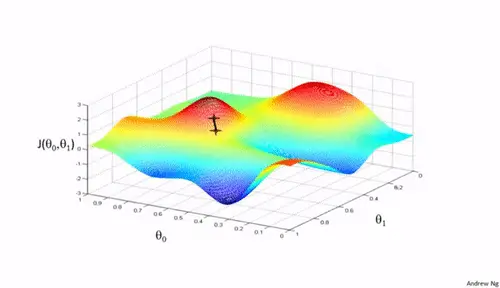
1、 目标
- 梯度下降优化算法的概述,目的在于帮助读者理解不同算法的优缺点。
2、 开整
- 梯度下降法在优化神经网络中的应用和普遍性。
3、 梯度下降法的变形形式
- 批梯度下降法:使用整个数据集计算梯度。
- 随机梯度下降法(SGD):使用单个样本计算梯度。
- 小批量梯度下降法:使用小批量样本计算梯度。
4、 挑战
5、 梯度下降优化算法
- 动量法:加速SGD并减少摇摆。
- Nesterov加速梯度下降法(NAG):提供预知能力以调整步长。
- Adagrad:自适应学习率,适应稀疏数据。
- Adadelta:解决Adagrad学习率递减问题。
- RMSprop:处理Adagrad学习率问题,使用指数衰减平均。
- Adam:结合动量和自适应学习率。
6、 并行和分布式SGD
- Hogwild!:无锁并行SGD。
- Downpour SGD:异步SGD,使用参数服务器。
- 延迟容忍SGD:适应更新延迟的并行SGD。
- TensorFlow:支持大规模分布式计算的框架。
- 弹性平均SGD(EASGD):增强探索能力的SGD。
7、 优化SGD的其他策略
- 数据集的洗牌和课程学习:避免模型偏差,提高收敛性。
- 批量归一化:提高学习率,减少对初始化的依赖。
- Early stopping:提前结束训练以防止过拟合。
- 梯度噪音:提高模型对初始化的鲁棒性。
8、 总结
- 对梯度下降及其优化算法的总结,以及不同场景下算法的选择建议。
走你~

1. 摘要
- 梯度下降优化算法的概述,目的在于帮助读者理解不同算法的优缺点
梯度下降优化算法的概述
梯度下降优化算法是机器学习和深度学习中最常用的优化算法之一。它通过不断调整模型参数,使得损失函数的值逐渐减小,从而使模型逐步逼近最优解
梯度下降优化算法的优点
- 简单易实现:梯度下降算法的基本原理简单,容易理解和实现
- 广泛应用:无论是线性回归、逻辑回归,还是复杂的神经网络,梯度下降算法都可以应用
梯度下降优化算法的缺点
- 依赖初始值:梯度下降算法的收敛速度和最终结果可能会受到初始值的影响
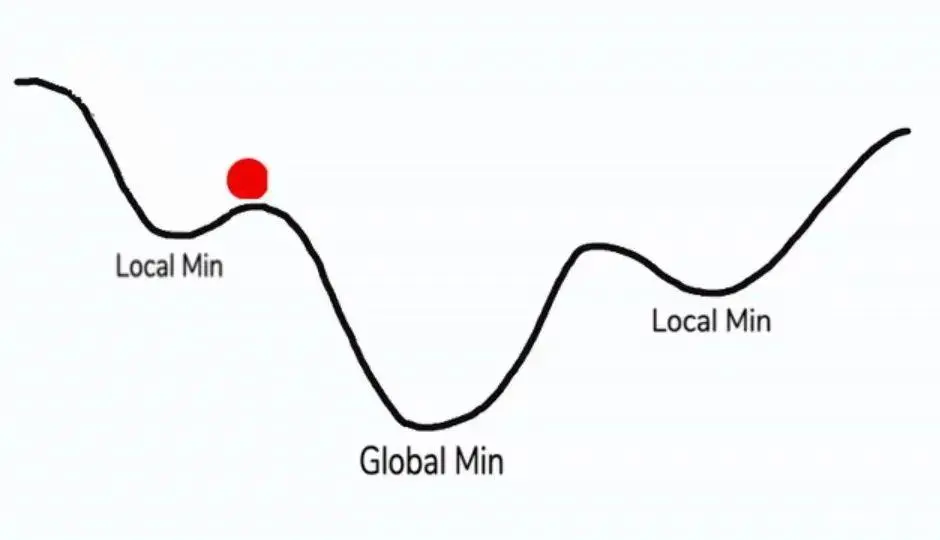
- 容易陷入局部最优:在复杂的非凸损失函数中,梯度下降算法可能会陷入局部最优解,而无法找到全局最优解
梯度下降算法的改进
为了克服上述缺点,研究人员提出了多种改进算法,如动量法、Adagrad、Adam等。这些改进算法在加速收敛、避免局部最优等方面有显著效果。我们将在后续内容中详细介绍这些改进算法
2. 应用和普遍性
- 梯度下降法在优化神经网络中的应用和普遍性
梯度下降法在机器学习和深度学习中的重要性不可忽视。作为一种经典的优化算法,梯度下降法被广泛应用于各种模型的训练过程中,尤其是在神经网络的优化中。
梯度下降法的基本原理
梯度下降法的核心思想是通过不断调整模型参数,使得损失函数的值逐渐减小,从而使模型逐步逼近最优解。具体来说,梯度下降法通过计算损失函数相对于模型参数的梯度,然后沿着梯度的反方向更新参数,以达到最小化损失函数的目的。


(梯度下降 by Divakar Kapil)
神经网络中的应用
在神经网络的训练过程中,梯度下降法起到了至关重要的作用。神经网络的训练过程本质上就是一个通过梯度下降法优化损失函数的过程。具体步骤如下:
- 前向传播:计算当前参数下的模型输出和损失函数值
- 反向传播:计算损失函数相对于模型参数的梯度
- 参数更新:使用梯度下降法更新模型参数
这个过程会反复进行,直到损失函数的值收敛到某个最小值。
普遍性
梯度下降法不仅在神经网络中广泛应用,还被应用于其他很多机器学习模型中,比如线性回归、逻辑回归、支持向量机等。它的普遍性和适用性使得它成为机器学习领域的一个重要工具。
在实际应用中,梯度下降法的具体形式有很多,比如批梯度下降法、随机梯度下降法和小批量梯度下降法。不同形式的梯度下降法在计算效率、收敛速度和收敛稳定性上各有优劣,我们将在下一部分详细介绍这些变形形式。

3. 梯度下降法的变形形式
- 批梯度下降法:使用整个数据集计算梯度
- 随机梯度下降法(SGD):使用单个样本计算梯度
- 小批量梯度下降法:使用小批量样本计算梯度
批梯度下降法
批梯度下降法,也称为标准梯度下降法,是最基本的梯度下降变形形式。它使用整个数据集来计算损失函数的梯度,然后一次性更新模型参数。
优点
- 稳定性高:每次更新都是基于整个数据集,因此梯度估计非常准确
- 容易实现:算法实现简单,便于理解和应用
缺点
- 计算量大:每次更新都需要遍历整个数据集,对于大型数据集计算开销巨大
- 内存需求高:需要将整个数据集加载到内存中,可能导致内存不足
公式
批梯度下降法的更新公式如下:
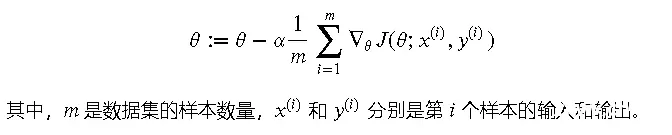

(梯度下降 by Saugat Bhattarai)
随机梯度下降法(SGD)
随机梯度下降法是一种通过每次仅使用一个样本来计算梯度的变形形式。它每次随机选择一个样本进行参数更新,这使得算法在处理大型数据集时更加高效。
优点
- 计算效率高:每次更新只需要计算一个样本的梯度,大大减少了计算开销
- 内存需求低:每次只需加载一个样本,节省内存
缺点
- 收敛不稳定:由于每次更新基于单个样本,梯度估计有较大噪声,可能导致收敛过程不稳定
- 可能震荡:在非凸损失函数中,更新方向可能来回震荡,难以到达全局最优解
公式
随机梯度下降法的更新公式如下:

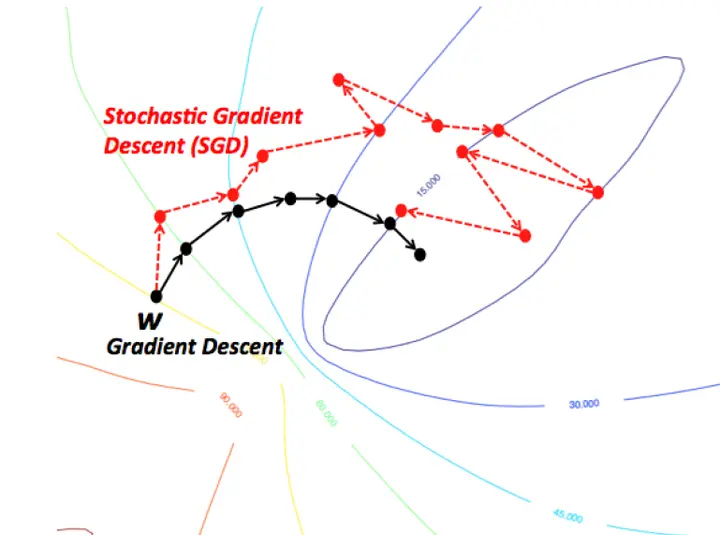
(SGD by bogotobogo com)
小批量梯度下降法
小批量梯度下降法是一种折中方案,它每次使用一个小批量(mini-batch)样本来计算梯度并更新参数。小批量的大小通常在 32 到 512 之间。
优点
- 计算效率与稳定性平衡:结合了批梯度下降和随机梯度下降的优点,计算效率和稳定性较好
- 硬件友好:小批量的计算可以充分利用现代硬件的并行计算能力
缺点
- 参数调整复杂:需要选择合适的小批量大小,以平衡计算效率和稳定性
公式
小批量梯度下降法的更新公式如下:


(Mini-batch gradient descent by Ayush Pradhan)
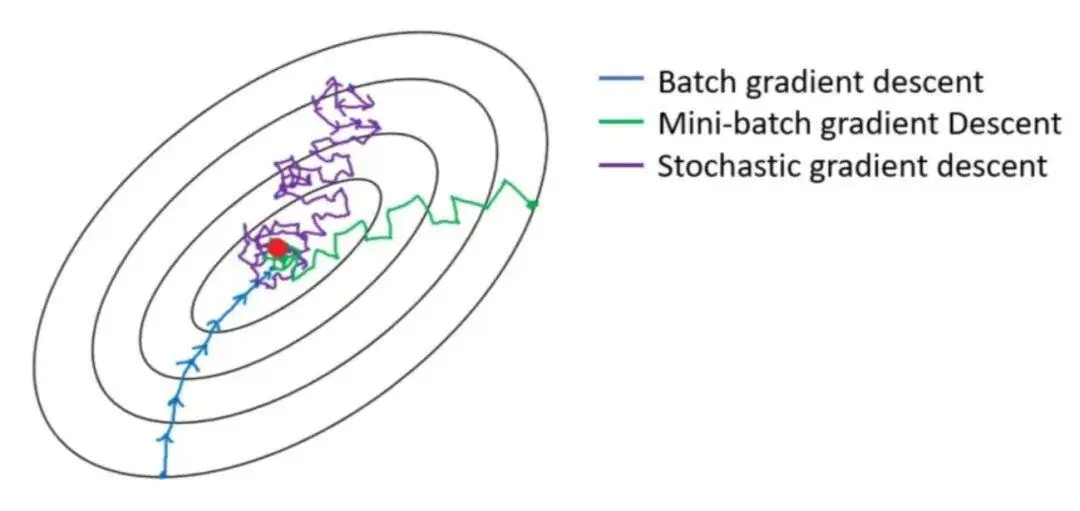
三种方式对比下,感受下这性感的曲线

4. 挑战

学习率的选择
学习率是梯度下降算法中的一个关键参数,它决定了每次更新参数的步长。选择合适的学习率非常重要,学习率过大或过小都会影响模型的收敛效果。
学习率过大
当学习率过大时,参数更新的步长过大,可能会导致模型在损失函数表面跳跃,从而错过最优解。这种情况会导致损失函数震荡或发散,无法收敛。
学习率过小
当学习率过小时,参数更新的步长过小,模型收敛速度会变得非常慢,甚至可能陷入局部最优。这种情况会导致训练时间过长,难以获得满意的结果。
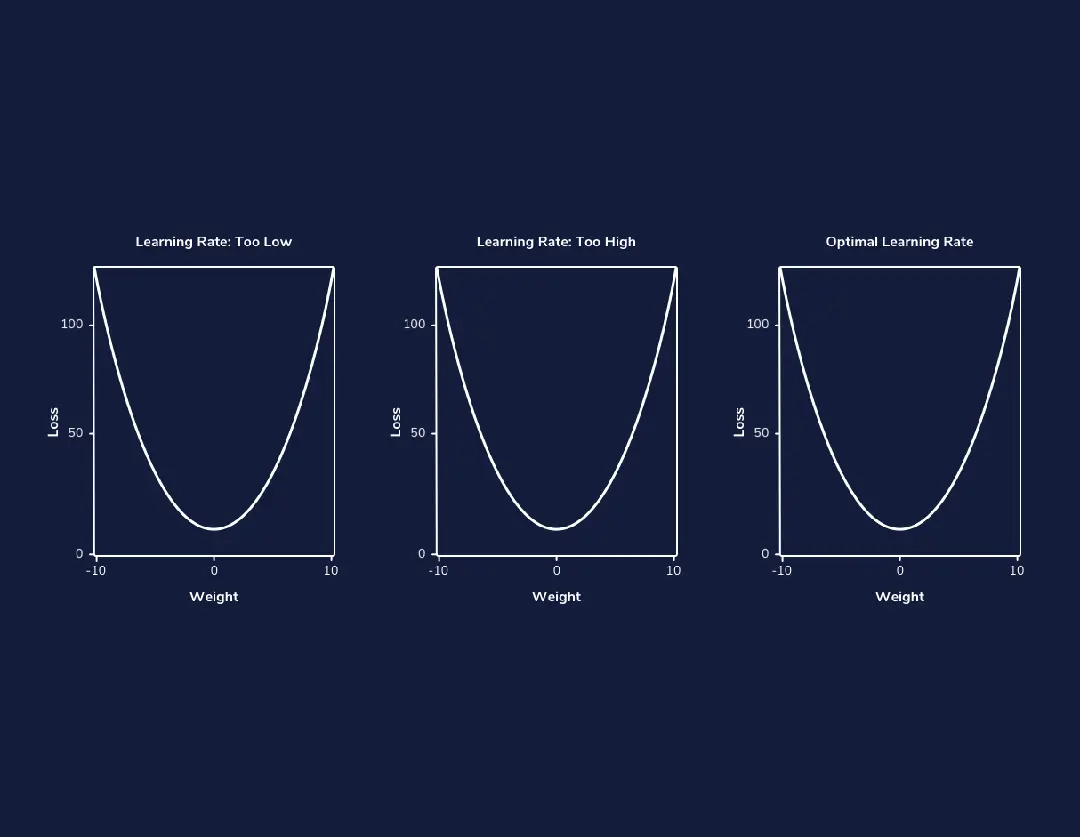
学习率调整
为了应对学习率选择的问题,研究人员提出了多种学习率调整策略,以动态调整学习率,使得模型能够更快、更稳定地收敛。
学习率衰减
学习率衰减是一种常用的策略,它会随着训练的进行逐渐减小学习率。这样可以在训练初期使用较大的学习率加速收敛,在训练后期使用较小的学习率稳定收敛。

学习率调度器
学习率调度器是一种更灵活的调整策略,可以根据预设的规则动态调整学习率。例如,在每经过一定次数的迭代后,将学习率减半。
自适应学习率
一些优化算法如 Adagrad、RMSprop 和 Adam,通过引入自适应学习率机制,使得每个参数都有不同的学习率,能够根据参数的历史梯度信息自动调整学习率。
不同参数的学习率需求
在实际应用中,不同的模型参数可能需要不同的学习率。例如,在深度神经网络中,靠近输入层的参数可能需要较小的学习率,而靠近输出层的参数可能需要较大的学习率。为了解决这个问题,可以使用分层学习率策略,针对不同层设置不同的学习率。
高度非凸误差函数的优化问题
在深度学习中,模型的损失函数通常是高度非凸的,包含多个局部最优解。传统的梯度下降算法在这种情况下容易陷入局部最优解,从而影响模型性能。
动量法
动量法通过在更新参数时加入动量项,能够在一定程度上克服局部最优问题。它会在每次更新时,保留一部分之前的更新方向,从而加速收敛。
5. 梯度下降优化算法
- 动量法:加速SGD并减少摇摆
- Nesterov加速梯度下降法(NAG):提供预知能力以调整步长
- Adagrad:自适应学习率,适应稀疏数据
- Adadelta:解决Adagrad学习率递减问题
- RMSprop:处理Adagrad学习率问题,使用指数衰减平均
- Adam:结合动量和自适应学习率
动量法
动量法是一种在梯度下降法基础上改进的优化算法。它通过在参数更新时加入一个动量项,可以加速收敛并减少参数更新过程中的摇摆现象。
原理
动量法会在每次更新参数时,保留一部分之前的更新方向,并在此基础上进行新的更新。这种方法使得更新方向更加平滑,从而加快收敛速度。
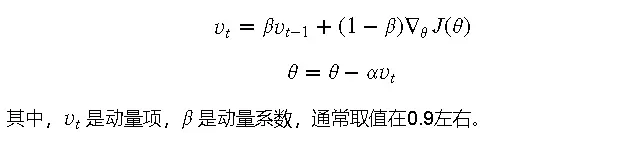
优点
- 加速收敛:尤其在鞍点附近,动量法可以显著加速收敛速度
- 减少振荡:在陡峭的损失函数区域,可以减少参数更新过程中的振荡
缺点
- 参数选择:需要选择合适的动量系数和学习率

Nesterov加速梯度下降法(NAG)
NAG是在动量法的基础上进一步改进的算法。它在计算梯度时,考虑了当前动量的方向,从而提供了预知能力,可以更准确地调整步长。
原理
NAG会先根据当前动量方向预估一下参数的位置,然后在这个预估位置计算梯度,从而更新参数。
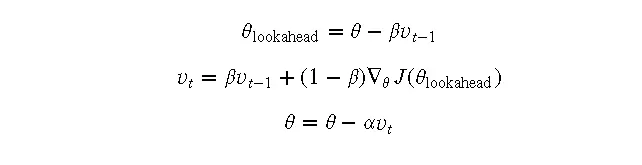
优点
- 更准确的更新方向:由于考虑了动量方向,更新方向更加准确
- 更快的收敛速度:在一些情况下,比动量法收敛速度更快
缺点
- 实现复杂:相对于动量法,NAG的实现更复杂

(MGD vs NAG by Akshay L Chandra)
与动量(红色)相比-摇摆幅度较小 by Akshay L Chandra.gif")
(仔细看,NAG(蓝色)与动量(红色)相比-摇摆幅度较小 by Akshay L Chandra)
Adagrad
Adagrad是一种自适应学习率的优化算法,特别适用于处理稀疏数据。它通过调整每个参数的学习率,使得在训练过程中自动适应不同参数的更新需求。
原理
Adagrad会根据历史梯度累积平方和来调整每个参数的学习率。对于更新较频繁的参数,学习率会逐渐减小;对于更新较少的参数,学习率则相对较大。

优点
缺点
- 学习率递减:随着时间推移,学习率会不断减小,导致收敛速度减慢

(AdaGrad(白色)与梯度下降(青色)在具有鞍点的地形上。AdaGrad 的学习率被设置为高于梯度下降的学习率,但无论学习率如何,AdaGrad 的路径更直的观点在很大程度上都是正确的 by Lili Jiang)
Adadelta
Adadelta是对Adagrad的改进算法,主要解决Adagrad学习率递减的问题。它通过限制累积梯度的窗口大小,避免学习率无限减小。
原理
Adadelta会使用滑动平均的方法来限制累积梯度的影响,从而使得学习率在训练过程中保持相对稳定。
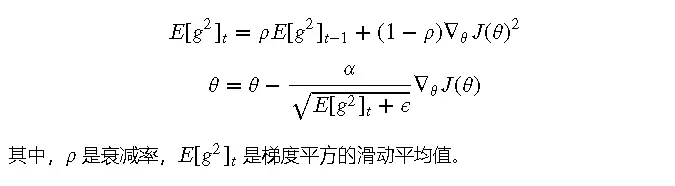
优点
缺点
- 复杂性增加:相对于Adagrad,Adadelta的实现更加复杂
RMSprop
RMSprop也是一种自适应学习率的优化算法,主要解决了Adagrad学习率递减的问题。它通过引入指数衰减平均,使得学习率在训练过程中保持相对稳定。
原理
RMSprop会使用指数衰减平均的方法来计算累积梯度的平方,从而调整每个参数的学习率。
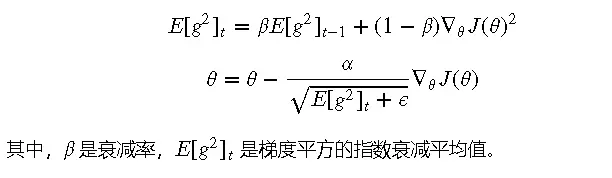
优点
- 稳定的学习率:避免了Adagrad中学习率无限减小的问题
- 适用于深度神经网络:在深度神经网络中表现良好
缺点
- 参数选择复杂:需要选择合适的衰减率和学习率
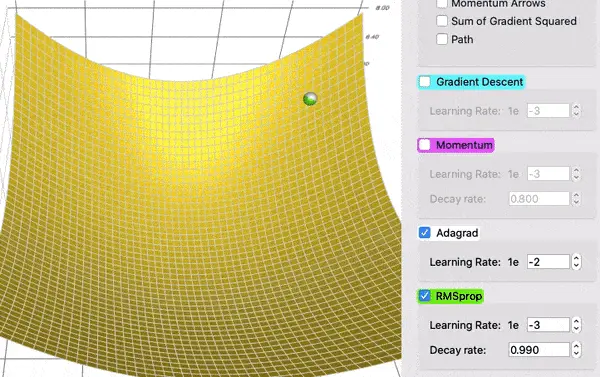
(RMSProp (绿色) vs AdaGrad (白色).第一轮只是显示球;第二次运行还显示了由平方表示的梯度平方和 by Lili Jiang)
Adam
Adam是一种结合动量和自适应学习率的优化算法,综合了动量法和RMSprop的优点,在深度学习中广泛应用。
原理
Adam算法会同时计算梯度的一阶动量和二阶动量,并使用这两个动量来调整每个参数的学习率。

优点
- 快速收敛:结合动量和自适应学习率,收敛速度快
- 稳定性高:在深度神经网络中表现出色,稳定性高
缺点
- 参数选择复杂:需要选择合适的动量系数和学习率

再次,感受下这德芙般丝滑的曲线

6. 并行和分布式SGD
- Hogwild!:无锁并行SGD
- Downpour SGD:异步SGD,使用参数服务器
- 延迟容忍SGD:适应更新延迟的并行SGD
- TensorFlow:支持大规模分布式计算的框架
- 弹性平均SGD(EASGD):增强探索能力的SGD
Hogwild!:无锁并行SGD
Hogwild! 是一种无锁并行SGD算法,旨在提高梯度下降的并行计算效率。在这种算法中,每个计算节点可以独立地更新参数,而无需等待其他节点完成更新,从而大大提高了计算速度。
原理
Hogwild! 算法通过允许多个计算节点同时更新共享参数,而不使用锁机制,从而减少了同步开销。虽然这样可能会引入一些更新冲突,但实际应用中这种影响通常较小。
优点
- 高效并行:大大减少了同步开销,提高了计算效率
- 简单实现:实现相对简单,不需要复杂的锁机制
缺点
- 可能引入冲突:由于无锁更新,可能会引入一些更新冲突,影响最终结果
Downpour SGD:异步SGD,使用参数服务器
Downpour SGD 是一种异步SGD算法,它使用参数服务器来协调多个计算节点的参数更新。每个计算节点独立计算梯度并异步发送给参数服务器,参数服务器负责更新全局参数。
原理
Downpour SGD 算法通过使用参数服务器来管理全局参数,各个计算节点可以独立地进行计算并异步更新参数。这样可以提高并行计算的效率,同时保持参数的一致性。
优点
- 高效并行:异步更新减少了同步开销,提高了计算效率
- 适应大规模数据:适合处理大规模数据和模型
缺点
- 实现复杂:需要参数服务器和多个计算节点的协调,增加了实现复杂度
- 延迟问题:由于异步更新,可能会引入更新延迟,影响收敛速度
延迟容忍SGD:适应更新延迟的并行SGD
延迟容忍SGD是一种能够适应更新延迟的并行SGD算法。它通过在更新过程中容忍一定的延迟,来提高并行计算的效率。
原理
延迟容忍SGD 通过允许一定的延迟来进行参数更新,从而提高计算效率。即使在更新过程中有一些节点的更新延迟,算法仍然能够有效地进行参数更新。
优点
- 适应延迟:能够容忍一定的更新延迟,提高并行计算的效率
- 稳定性高:在有延迟的环境中,算法仍能稳定收敛
缺点
- 参数选择复杂:需要选择合适的延迟容忍参数,增加了实现复杂度
TensorFlow:支持大规模分布式计算的框架
TensorFlow 是一个支持大规模分布式计算的开源框架,它提供了多种并行和分布式计算的工具,能够方便地实现并行和分布式SGD。
原理
TensorFlow 通过数据并行和模型并行的方式,实现了大规模分布式计算。数据并行是将数据分成多个小批量,分发到不同的计算节点进行并行计算;模型并行是将模型分成多个部分,分发到不同的计算节点进行并行计算。
优点
- 强大功能:支持多种并行和分布式计算方式,功能强大
- 社区支持:有广泛的社区支持和丰富的文档
缺点
- 学习曲线陡峭:相对于其他框架,TensorFlow 的学习曲线较陡峭,初学者需要一定的时间来掌握
弹性平均SGD(EASGD):增强探索能力的SGD
弹性平均SGD(EASGD)是一种增强探索能力的并行SGD算法。它通过在参数更新时加入弹性平均项,增强了参数的探索能力,避免陷入局部最优。
原理
EASGD 通过在参数更新时,将参数向全局平均值靠拢,从而增强参数的探索能力。具体来说,在每次更新时,不仅根据梯度更新参数,还会根据全局平均值调整参数。

优点
- 增强探索能力:通过加入弹性平均项,增强了参数的探索能力
- 避免局部最优:有效避免陷入局部最优
缺点
- 实现复杂:需要计算全局参数的平均值,增加了实现复杂度

7. 优化SGD的其他策略
- 数据集的洗牌和课程学习:避免模型偏差,提高收敛性
- 批量归一化:提高学习率,减少对初始化的依赖
- Early stopping:提前结束训练以防止过拟合
- 梯度噪音:提高模型对初始化的鲁棒性
数据集的洗牌和课程学习
在使用随机梯度下降(SGD)时,数据集的洗牌和课程学习策略可以显著提高模型的收敛性和稳定性。
数据集的洗牌
在每个训练周期开始前,将数据集进行随机打乱(洗牌),可以防止模型对数据顺序的依赖,从而减少过拟合的风险。
课程学习
课程学习是一种逐步增加训练难度的策略,先用简单的样本进行训练,再逐步引入更复杂的样本。这种方法可以帮助模型更快地收敛,并提高最终的模型性能。
批量归一化

批量归一化是一种加速深度神经网络训练的技术。通过对每一层的激活值进行归一化,批量归一化可以使得每层输入的分布更加稳定,从而允许使用更高的学习率,并减少对参数初始化的依赖。
原理
批量归一化在每一层的输入上,先计算均值和方差,然后对输入进行归一化处理,再通过可训练的尺度和平移参数进行线性变换。
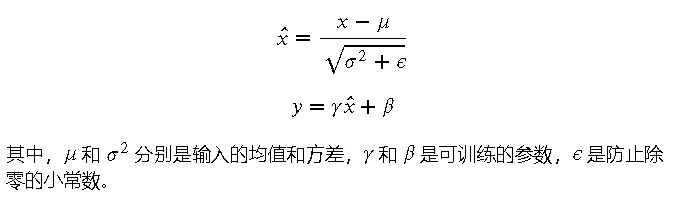
优点
缺点
- 计算开销:在每层增加了额外的计算开销
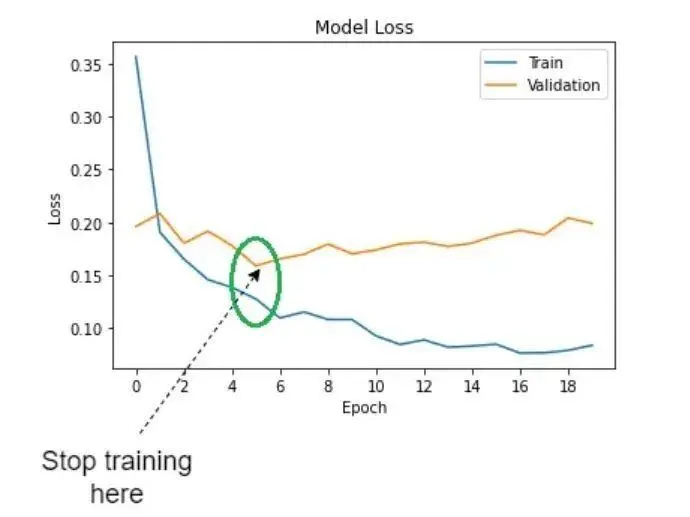
Early stopping
Early stopping 是一种防止过拟合的策略。当验证集的损失函数在训练过程中不再下降时,提前停止训练,从而防止模型在训练集上过拟合。
原理
在每个训练周期结束时,计算验证集的损失函数值。如果损失函数在连续若干周期内不再下降或开始上升,则提前停止训练。
优点
- 防止过拟合:通过提前停止训练,防止模型在训练集上过拟合
- 节省计算资源:避免了不必要的训练周期,节省计算资源
缺点
- 需要验证集:需要一个独立的验证集来监控模型性能
梯度噪音
在梯度下降过程中加入噪音,可以帮助模型跳出局部最优解,提高模型对参数初始化的鲁棒性。
原理
在每次更新参数时,向梯度中加入一个随机噪音项,使得参数更新过程更加随机,从而增加探索全局最优解的可能性。

优点
- 增强探索能力:帮助模型跳出局部最优解
- 提高鲁棒性:提高模型对参数初始化的鲁棒性
缺点
- 可能增加训练时间:随机噪音的引入可能会增加训练时间
[ 抱个拳,总个结 ]
- 对梯度下降及其优化算法的总结,以及不同场景下算法的选择建议
梯度下降及其优化算法总结
梯度下降法是机器学习和深度学习中最基础和常用的优化算法之一。通过不断调整模型参数,使得损失函数的值逐渐减小,梯度下降法能够帮助模型逐步逼近最优解。根据数据集和具体应用场景的不同,可以选择不同形式的梯度下降法,如批梯度下降法、随机梯度下降法和小批量梯度下降法。
1. 批梯度下降法
- 使用整个数据集计算梯度
- 适用于较小的数据集,计算稳定但速度慢
2. 随机梯度下降法(SGD)
- 使用单个样本计算梯度
- 计算速度快,但梯度估计噪声大,适用于大规模数据集
3. 小批量梯度下降法
- 使用小批量样本计算梯度
- 结合了批梯度下降法和随机梯度下降法的优点,计算效率和稳定性较好
梯度下降优化算法
为了提高梯度下降法的收敛速度和稳定性,研究人员提出了多种优化算法,这些优化算法在不同的应用场景下有各自的优劣。
1. 动量法
- 加速SGD并减少摇摆,适用于有鞍点的损失函数
2. Nesterov加速梯度下降法(NAG)
- 提供预知能力以调整步长,比动量法收敛更快
3. Adagrad
- 自适应学习率,适应稀疏数据,但学习率递减
4. Adadelta
- 解决Adagrad学习率递减问题,保持稳定学习率
5. RMSprop
- 使用指数衰减平均处理Adagrad学习率问题,适用于深度神经网络
6. Adam
- 结合动量和自适应学习率,综合了动量法和RMSprop的优点,适用于各种应用场景
并行和分布式SGD
在处理大规模数据和模型时,并行和分布式SGD是提高计算效率的重要手段。以下是一些常用的并行和分布式SGD算法:
1. Hogwild!
- 无锁并行SGD,提高计算效率,但可能引入冲突
2. Downpour SGD
- 异步SGD,使用参数服务器,适用于大规模分布式计算
3. 延迟容忍SGD
- 适应更新延迟,提高并行计算效率
4. TensorFlow
- 支持大规模分布式计算的框架,功能强大
5. 弹性平均SGD(EASGD)
- 增强探索能力,避免局部最优
优化SGD的其他策略
除了上述优化算法,还有一些策略可以进一步优化SGD的效果:
1. 数据集的洗牌和课程学习
- 避免模型偏差,提高收敛性
2. 批量归一化
- 提高学习率,减少对初始化的依赖
3. Early stopping
- 提前结束训练以防止过拟合
4. 梯度噪音
- 提高模型对初始化的鲁棒性
不同场景下算法选择建议
- 小规模数据集:可以选择批梯度下降法或小批量梯度下降法
- 大规模数据集:随机梯度下降法或小批量梯度下降法更为合适
- 稀疏数据:Adagrad 或 RMSprop 是不错的选择
- 深度神经网络:Adam、RMSprop 或动量法可以加速收敛并提高稳定性
- 分布式计算:Downpour SGD 或 TensorFlow 框架支持大规模分布式计算
- 需要快速收敛:Nesterov加速梯度下降法(NAG)或 Adam
通过合理选择和组合这些算法和策略,可以在不同的应用场景中获得更好的优化效果,提高模型的性能和训练效率。
吴恩达:机器学习的六个核心算法!
回归算法,逻辑回归,决策树算法, 神经网络,K-means,梯度下降(本文)
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵
内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。