零基础5分钟上手谷歌云GCP核心云开发技能 - 利用语音AI服务搭建应用
CSDN 2024-08-11 15:31:02 阅读 53
简介:
欢迎来到小李哥全新谷歌云GCP云计算知识学习系列,适用于任何无云计算或者谷歌云技术背景的开发者,让大家零基础5分钟通过这篇文章就能完全学会谷歌云一个经典的服务开发架构方案。
我将每天介绍一个基于全球三大云计算平台(AWS, Azure, GCP)的全球前沿云开发/架构技术基础解决方案,帮助大家快速了解国际上最热门的云计算平台上的最佳实践和前沿技术,并应用到自己的日常工作里。本次我将介绍如何在谷歌云上利用语音AI服务speech-to-text的API,搭建自己的云端应用系统。示范架构图如下:

方案所需基础知识
什么是谷歌云 GCP Speech-to-Text 服务?
谷歌云 GCP Speech-to-Text 是 Google Cloud Platform 提供的一项强大的语音识别服务。它利用先进的深度学习算法,将语音转化为高精度的文本。该服务支持多种语言和方言,并且可以处理实时音频流和预录音频文件,是开发语音驱动应用和服务的理想选择。

使用 GCP Speech-to-Text 进行语音转录的优势
通过 GCP Speech-to-Text 服务,开发者可以快速、高效地实现语音转录功能,提升应用的智能化和用户体验。
高精度:
采用先进的深度学习模型,谷歌家的AI模型一直是顶流的存在不容置疑,能够高精度地转录各种语音内容。
多语言支持:
支持全球 120 多种语言和方言,适用于多语言环境中的语音识别需求。
实时转录:
可以处理实时音频流,适用于实时字幕、实时会议记录等应用场景。
自定义词汇:
用户可以添加特定词汇和短语,提高特定领域的转录准确性。自动添加标点符号,使转录文本更具可读性。
可扩展性:
无论是处理少量音频文件还是大规模语音数据,服务都能轻松扩展,满足不同规模的需求。

应用谷歌云 GCP Speech-to-Text 的场景
谷歌云 GCP Speech-to-Text 服务在多个应用场景中都能发挥重要作用,以下是一些常见的使用场景:
1. 实时字幕和转录
实时会议记录:在视频会议或电话会议中,实时转录语音内容,生成会议记录,便于会后查阅和分享。直播字幕:为直播视频提供实时字幕,提高内容的可访问性,帮助听力障碍者理解直播内容。
2. 客户服务
呼叫中心:将客户服务电话的语音内容实时转录为文本,帮助客服代表快速获取通话内容,提升服务质量。语音留言转录:自动将语音留言转录为文本,方便用户查阅和管理。
3. 语音命令和控制
智能家居设备:通过语音指令控制智能家居设备,如开关灯、调节温度等,提升用户体验。车载系统:在车载导航和娱乐系统中,通过语音指令实现导航、播放音乐等功能,增强驾驶安全性。
4. 教育和培训
在线课程:将在线课程的语音内容转录为文本,生成课程笔记,方便学生复习和查阅。学术研究:转录学术讲座和研讨会内容,为研究人员提供文本资料,便于分析和引用。
5. 媒体和娱乐
播客转录:将播客内容转录为文本,生成文字稿,便于用户阅读和搜索。影片字幕制作:为电影和电视剧生成准确的字幕,提高内容的可访问性和观看体验。
本方案包括的内容:
1. 为调用云端语音AI服务创建API key
2. 创建调用云端语音AI服务的API请求
3. 发起调用,调用API获取转录文字响应(语音转文字)
项目搭建具体步骤:
1.首先我们登录我们的GCP控制台, 进入到API管理服务“APIs & services > Credentials”。接下来我们创建一个API key,创建完成后。
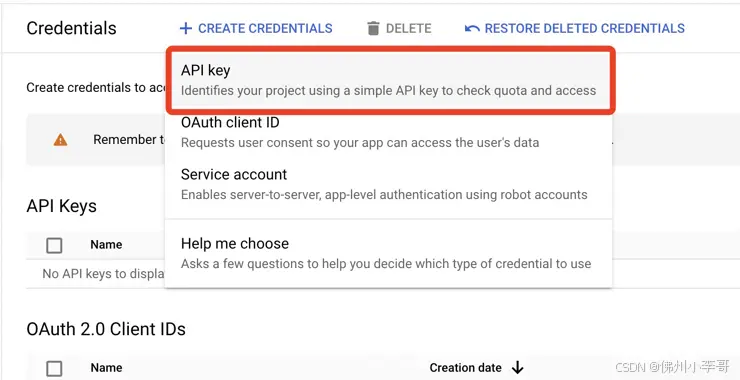
2. 创建完成后,会自动弹出创建的API Key明文。

3. 接下来我们登录GCP上的Compute Engine服务器,通过SSH登入Linux 命令行中。

4. 接下来我们在命令行中导入我们刚创建的API Key
<code>export API_KEY=<YOUR_API_KEY>
5. 接下来我们创建并打开一个"request.json"文件,用作创建我们Speech-to-Text API的请求内容。
touch request.json
nano request.json
6. 接下来我们在json中复制添加以下内容,并且点击control+x和y进行Nano的保存。。
{
"config": {
"encoding":"FLAC",
"languageCode": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
参数解释:
config:配置
包含转录过程的配置设置。
encoding:编码
指定音频文件的编码格式,例如 FLAC、MP3 等。
languageCode:语言代码
指定音频文件中使用的语言,例如 en-US 表示美式英语。
audio:音频
包含音频文件的信息。
uri:统一资源标识符
指定音频文件所在的位置,通常是一个云存储地址,例如 gs:// 开头的 Google Cloud Storage 地址。
7. 最后我们开始通过Linux命令行根据我们的json文件配置,调用Speech-to-Text的API实现语音转录。运行如下命令:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json \
"https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}"
8.我们得到了如下的音频转录结果
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}
9. 如果我们想把输出的结果导入到一个文件中,我们可以使用如下的命令。
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json \
"https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}" > result.json
10. 除了使用Bash脚本调用API,我们也可以直接在Python代码中直接在应用中调用API。参考代码如下。
from google.cloud import speech_v1p1beta1 as speech
def transcribe_gcs(gcs_uri):
client = speech.SpeechClient()
audio = speech.RecognitionAudio(uri=gcs_uri)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.FLAC,
language_code="en-US"code>
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
print("Transcript: {}".format(result.alternatives[0].transcript))
if __name__ == "__main__":
gcs_uri = "gs://cloud-samples-tests/speech/brooklyn.flac"
transcribe_gcs(gcs_uri)
代码解释:
导入库:
from google.cloud import speech_v1p1beta1 as speech:导入 Google Speech-to-Text API 客户端库。
创建客户端:
client = speech.SpeechClient():创建 Speech-to-Text 客户端对象。
定义音频和配置:
audio = speech.RecognitionAudio(uri=gcs_uri):指定音频文件的 URI。
config = speech.RecognitionConfig(encoding=speech.RecognitionConfig.AudioEncoding.FLAC, language_code="en-US"):配置音频文件的编码格式和语言代码。
调用 API:
response = client.recognize(config=config, audio=audio):调用 recognize 方法进行转录。
处理响应:
遍历 response.results 并打印转录文本。
以上就是在谷歌云GCP上创建语音AI服务的全部步骤。欢迎大家关注0基础5分钟上手谷歌云系列,未来获取更多国际前沿的谷歌云GCP云开发/云架构方案!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。