【人工智能图像补全复现】基于GAN的图像补全
quanjui 2024-08-11 15:31:03 阅读 60
文章目录
摘要:一、引言:二、现状和未来发展前景:1、现状:2、具体应用:2.1 图像和视觉领域2.2 语音和语言领域
3、未来发展:
三、模型实现:1、准备工作2、具体步骤(1)数据预处理(2)模型构造:
五、感悟和后续改进:
摘要:
本文解析和实现论文Globally and Locally Consistent Image Completion中的相关方法。论文亮点在于使用全局(整张图片)和局部(缺失补全部分)两种鉴别器来训练,并运用GAN使生成图像在各个尺度的特征与真实图像匹配。
关键词:GAN;图像补全;多种鉴别器训练
文章来源:SIGGRAPH 2017 Globally and Locally Consistent Image Completion
下载链接:点这里
应用场景:图像补全(Image completion),目标移除(Object remove)
使用的数据集是CelebA人脸数据集这里
本文项目代码 GitHub 地址:这里
本文项目代码 AI Studio 地址:这里
一、引言:
图像补全是深度学习领域的热门应用,本文解析和实现论文Globally and Locally Consistent Image Completion中的相关方法。论文亮点在于使用全局(整张图片)和局部(缺失补全部分)两种鉴别器来训练,该文章完全以卷积网络作为基础,遵循GAN的思路,设计为两部分(三个网络),一部分用于生成图像,即生成网络,另一部分用于鉴别生成图像是否与原图像一致,即全局鉴别器和局部鉴别器。在整个网络中,作者采用ReLU函数,在最后一层采用Sigmoid函数使得输出在0到1区间内。
二、现状和未来发展前景:
1、现状:
我们使用的两个模型最底层是生成对抗网络(GAN),GAN在过去几年中得到了广泛的研究。其中最显着的影响是在计算机视觉领域,在诸如可信图像生成(plausible image generation)、图像到图像转换(image-to-image translation)、面部属性操作(facial attribute manipulation)和类似领域等挑战方面取得了巨大进步。但看了相关的大量文献我们发现 GAN 应用于现实世界的问题仍然存在重大挑战,最新的技术主要研究方向主要为如何高质量图像的生成,如何使图像生成多样性以及稳定训练。
2、具体应用:
2.1 图像和视觉领域
GAN能够生成与真实数据分布一致的图像,用GAN来将一个低清模糊图像变换为具有丰富细节的高清图像。
GAN也开始用于生成自动驾驶场景,利用GAN来生成与实际交通场景分布一致的图像,再训练一个基于RNN 的转移模型实现预测的目的。
基于GAN模型可以利用仿真图像和真实图像实现人眼检测。
2.2 语音和语言领域
Li 等于2017年提出用GAN来表征对话之间的隐式关联性,从而生成对话文本。Zhang等与2016年提出基于GAN 的文本生成。
SeqGAN在语音、诗词和音乐生成方面可以超过传统方法。
Reed 等于2016年提出用GAN基于文本描述来生成图像。
3、未来发展:
GAN虽然解决了生成式模型的一些问题,并且对其他方法的发展具有一定的启发意义,但是GAN并不完美,它在解决已有问题的同时也引入了一些新的问题。GAN 最突出的优点同时也是它最大的问题根源。
后续如何彻底解决崩溃模式并继续优化训练过程是GAN的一个研究方向。另外关于GAN收敛性和均衡点存在性的理论推断也是未来的一个重要研究课题。并且如何根据简单随机的输入,生成多样的、能够与人类交互的数据,是近期的一个应用发展方向。从GAN 与其他方法交叉融合的角度,如何将GAN 与特征学习、模仿学习、强化学习等技术更好地融合,开发新的人工智能应用或者促进这些方法的发展,是很有意义的发展方向。
从长远来看,如何利用GAN 推动人工智能的发展与应用,提升人工智能理解世界的能力,甚至激发人工智能的创造力是值得研究者思考的问题。
三、模型实现:
1、准备工作
(1)对应环境
Pytorch with GPU
numpy
OpenCV
Paddle
(2)下载数据集
2、具体步骤
(1)数据预处理
1)解压数据压缩包:

2)提前将图像转换为 ndarray 格式,存入.npy文件

3)加载处理完成后的train和test文件:

4)构建所需填充的空洞mask:

(2)模型构造:
1)网络构造:
补全网络:是完全卷积的,用来修复图像。
全局上下文鉴别器:以完整的图像作为输入,识别场景的全局一致性。
局部上下文鉴别器:只关注完成区域周围的一个小区域,以判断更详细的外观质量。
对图像完成网络进行训练,以欺骗两个上下文鉴别器网络,这要求它生成在总体一致性和细节方面与真实图像无法区分的图像。
2)网络架构:
此网络由一个完成网络和两个辅助上下文鉴别器网络组成,这两个鉴别器网络只用于训练完成网络,在测试过程中不使用。全局鉴别器网络以整个图像为输入,而局部鉴别器网络仅以完成区域周围的一小块区域作为输入。训练两个鉴别器网络以确定图像是真实的还是由完成网络完成的,而生成网络被训练来欺骗两个鉴别器网络,使生成的图像达到真实图像的水平。
3)补全网络结构
补全网络先利用卷积降低图片的分辨率然后利用去卷积增大图片的分辨率得到修复结果。为了保证生成区域尽量不模糊,文中降低分辨率的操作是使用strided convolution 的方式进行的,而且只用了两次,将图片的size 变为原来的四分之一。同时在中间层还使用了空洞卷积来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
4)代码(搭建补全网络);







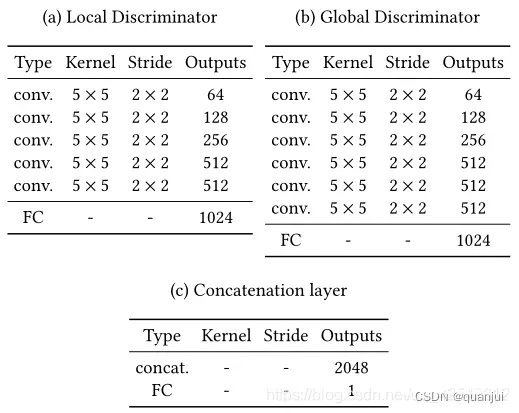
5)内容鉴别器
这些网络基于卷积神经网络,将图像压缩成小特征向量。 网络的输出通过连接层融合在一起,连接层预测出图像是真实的概率的一个连续值。网络结构如下:
遵循编码器结构,该结构先将待处理的图像降低分辨率,从而减少内存使用和计算时间,然后使用 deconvolution layers恢复成原始的分辨率。作者只使用了降低分辨率了两次,降低为原始大小的1/4,这对缺失区域生成非模糊纹理非常重要。在进行deconvolution之间,在中间层还使用了 dilated convolutional layers 来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
使用dilated convolutional layers,dilated convolutional扩展了卷积核,能够保证每个输出像素具有更大的输入面积,并且拥有相同数量的参数和计算能力。通过使用低分辨率的 dilated convolutional ,模型在计算每个输出像素时可以有效地“看到”输入图像的更大区域,如下图:



6)定义损失函数:
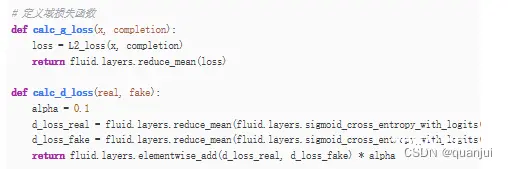
7)定义Program:
分别定义补全网络和鉴别器,分开训练
参数定义:

定义判别器的gprogram:
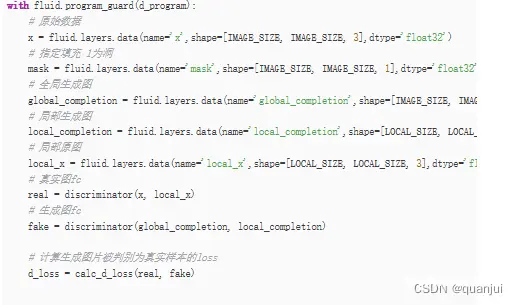
定义判别生成图片的gprogram:
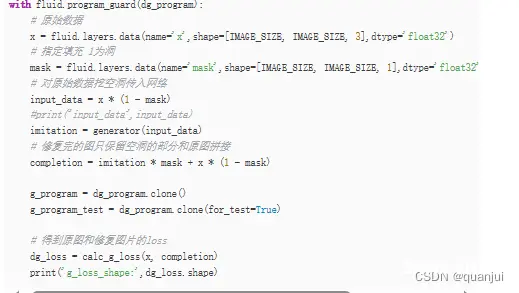
优化器:

对数据集进行标准化操作:

使用的输入图像大小:128*128,训练方式改为:先训练生成器再将生成器和判别器一起训练。
初始化:

训练生成器:

如上图代码所示,训练生成器并创建文件夹保存模型:
生成器判断器一起训练:


测试部分:
原始数据:
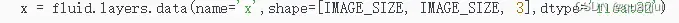
指定填充 1为洞:
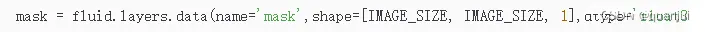
全局生成图:
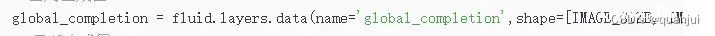
局部生成:
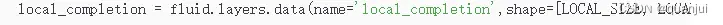
局部原图:

进行参数初始化:

获取训练和测试程序:
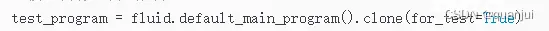
加载模型:


结果展示代码:

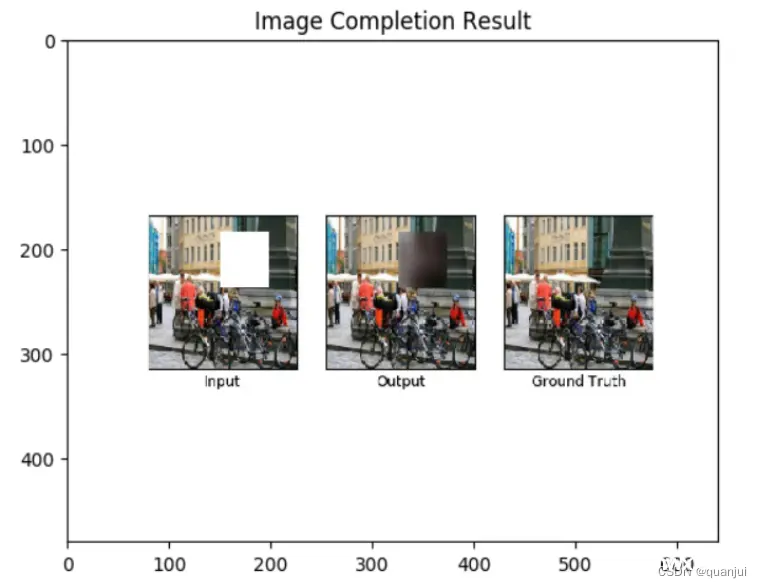
结果展示:

五、感悟和后续改进:
这次的实验让我对GAN有了更加深刻的理解,我们训练出来的效果因为训练次数的原因并没有原文中那么好,而且作者还提出了可以使用这个模型进口罩去除,后续我们会继续尝试争取可以完成这一个实验效果。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。