ControlNet++:让AI图像生成更精准、更可控
人工智能大模型讲师培训咨询叶梓 2024-08-03 11:01:02 阅读 94
在人工智能的世界里,文本到图像的生成技术正变得越来越先进。但如何确保生成的图像精确地反映我们的想象呢?最近,一项名为ControlNet++的新技术为我们提供了答案。
ControlNet++是一种新颖的方法,它通过优化生成图像与给定条件之间的像素级循环一致性,显著提高了文本到图像生成的可控性。这意味着,无论你的想象多么独特,ControlNet++都能更准确地帮你实现。

ControlNet++:更可控的图像生成
像素级循环一致性
ControlNet++的核心思想是确保生成的图像在像素级别上与给定的条件控制保持一致。条件控制可以是分割掩码、线稿边缘、深度图等,这些都是图像的重要视觉特征。循环一致性意味着如果我们将条件控制应用到生成模型上,生成的图像应该能够反映出这些条件,并且如果我们从生成的图像中重新提取条件,应该能够回到最初的输入条件。

预训练的判别奖励模型
ControlNet++使用预训练的判别模型来提取生成图像的条件。这些预训练模型已经在大量数据上训练过,能够识别和提取图像中的特定特征,如边缘或深度信息。
优化一致性损失
为了实现循环一致性,ControlNet++优化了一个一致性损失函数。这个损失函数衡量了生成图像的条件与输入条件控制之间的差异。通过最小化这个损失,生成模型被引导去产生与输入条件更加一致的图像。
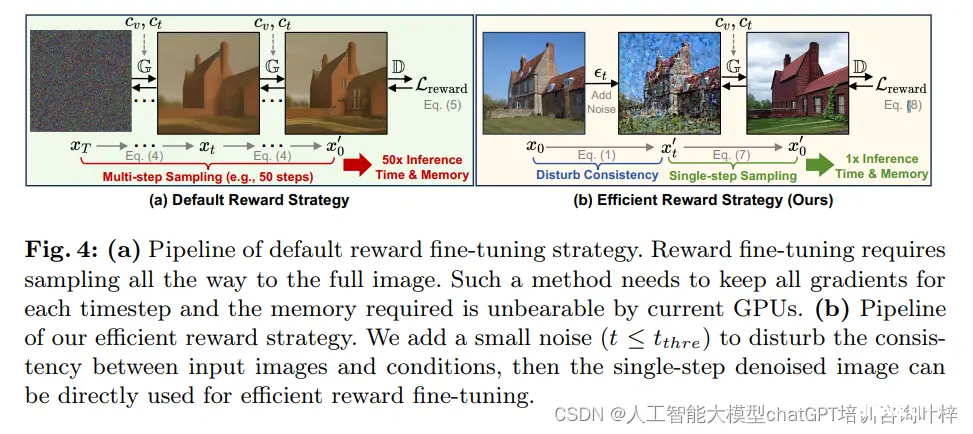
高效的奖励微调策略
在传统的扩散模型中,生成图像需要从随机噪声开始,逐步去噪,这通常需要多步采样,计算成本高且耗时。ControlNet++提出了一种高效的奖励微调策略,通过向训练图像添加噪声,然后进行单步去噪,来快速计算一致性损失,从而避免了多步采样的开销。
实验验证
实验设置
条件控制和数据集:选择了多个数据集来训练和评估模型,包括ADE20K、COCOStuff和MultiGen-20M,这些数据集提供了精确的图像-标签配对,如分割掩码、边缘图和深度图。评估和指标:使用了多种评估指标,包括mIoU(交并比)、F1-Score、SSIM(结构相似性)、RMSE(均方根误差)等,来衡量生成图像与输入条件之间的相似度。
基线比较
对比方法:与ControlNet++进行比较的方法包括T2I-Adapter、ControlNet v1.1、GLIGEN、Uni-ControlNet和UniControl等,这些方法都是在可控文本到图像扩散模型领域的先驱。公平比较:为了确保比较的公平性,所有方法都使用相同的图像条件和文本提示进行评估。
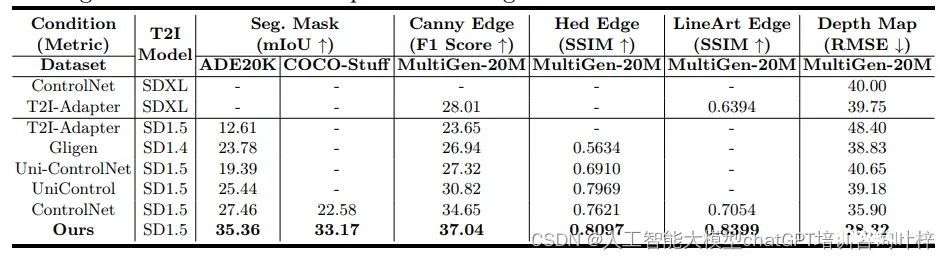
实验结果
控制性比较:ControlNet++在多个条件控制任务中的控制性均优于现有方法。例如,在分割掩码条件下,ControlNet++实现了7.9%的mIoU提升,在深度图条件下实现了7.6%的RMSE降低。定性比较:提供了可视化的比较结果,展示了ControlNet++在保持输入条件一致性方面的优势。相比之下,现有方法在生成与条件控制一致的图像方面存在不足。

图像质量比较
FID(Fréchet Inception Distance):ControlNet++在多种条件下的FID值通常优于现有方法,表明其在提高控制性的同时,图像质量并未降低。CLIP分数:为了评估文本控制性,使用CLIP分数对不同方法进行了评估。ControlNet++在多个数据集上取得了与现有方法相当或更好的结果。
生成图像的有效性
训练判别模型:使用ControlNet++生成的图像和真实标注的标签创建了一个新的数据集,用于训练分割模型。实验结果表明,使用ControlNet++生成的图像训练的分割模型性能优于使用ControlNet生成的图像。
消融研究
损失设置:研究表明,结合像素级一致性损失和扩散训练损失可以提高控制性而不损害图像质量。文本提示的影响:探讨了不同文本提示对生成结果的影响,ControlNet++在各种文本提示情况下都能生成与输入条件一致的图像。
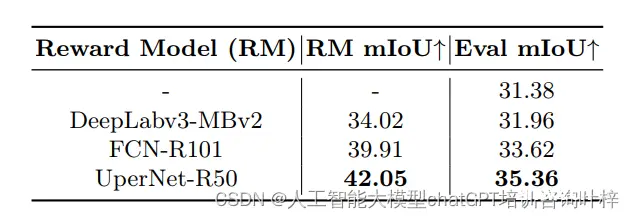
实验结果证明了ControlNet++在提高文本到图像生成模型的可控性方面的有效性,同时保持了图像质量。此外,ControlNet++生成的图像可以有效地用于训练更强大的判别模型。
这些实验结果不仅验证了ControlNet++的技术优势,还展示了其在实际应用中的潜力。通过这些详细的实验,研究人员能够展示ControlNet++如何在多个方面超越现有技术。
论文链接:https://arxiv.org/pdf/2404.07987
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。