[BUUCTF从零单排] Web方向 02.Web入门篇之『常见的搜集』解题思路(dirsearch工具详解)
Eastmount 2024-10-07 08:03:01 阅读 68
这是作者新开的一个专栏《BUUCTF从零单排》,旨在从零学习CTF知识,方便更多初学者了解各种类型的安全题目,后续分享一定程度会对不同类型的题目进行总结,并结合CTF书籍和真实案例实践,希望对您有所帮助。当然,也欢迎大家去BUUCTF网站实践,由于作者能力有限,该系列文章比较基础,写得不好的地方还请见谅,后续会持续深入,加油!
前文介绍了Web方向的基础题目——粗心的小李,考察的是git泄露文件知识。这篇文章同样是Web方向的题目——常见的搜集,该题目主要考察信息收集知识,为了方便大家思考,文章摘要部分尽量少提,大家也可以先尝试实践,再看WriteUp。基础性文章,希望对您有所帮助,尤其是对网络安全工具的使用和理解。
欢迎关注作者新建的『网络攻防和AI安全之家』知识星球(文章末尾)
文章目录
一.题目描述二.解题思路1.dirsearch安装及基本用法2.信息采集3.寻找flag
三.探索扩展1.dirsearch词典问题2.dirsearch基础用法
四.总结
前文赏析:
[BUUCTF从零单排] Web方向 01.Web入门篇之粗心的小李解题思路[BUUCTF从零单排] Web方向 02.Web入门篇之『常见的搜集』解题思路
一.题目描述
该题目的具体描述如下:
题目:[第一章 web入门] 常见的搜集方向:信息收集来源:《从0到1:CTFer成长之路》书籍配套题目,来源网站:book.nu1l.com
接着解锁该题目并开启探索。
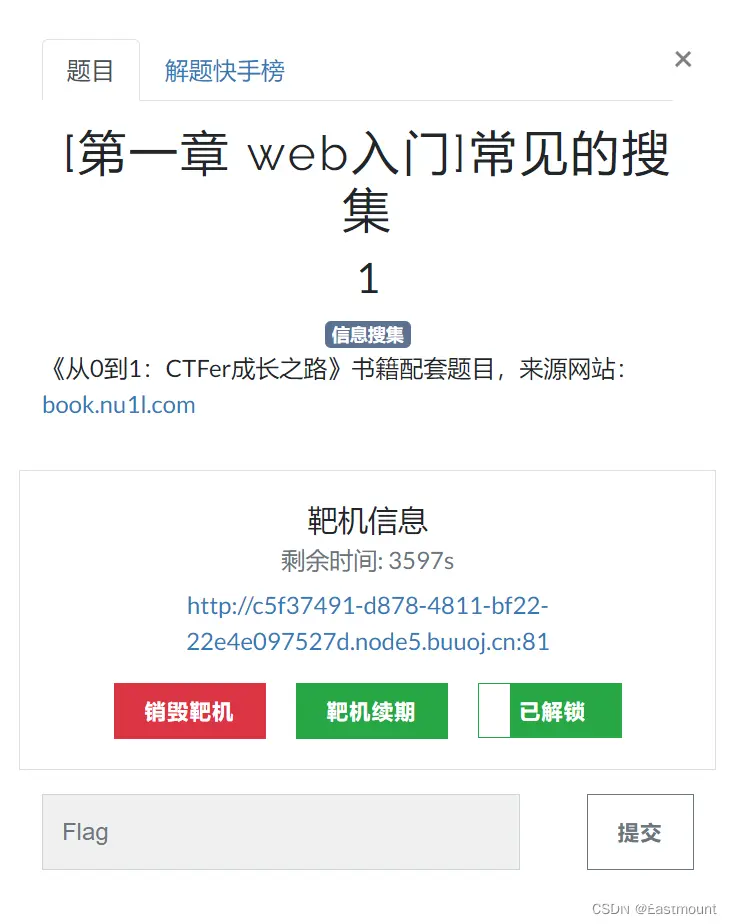
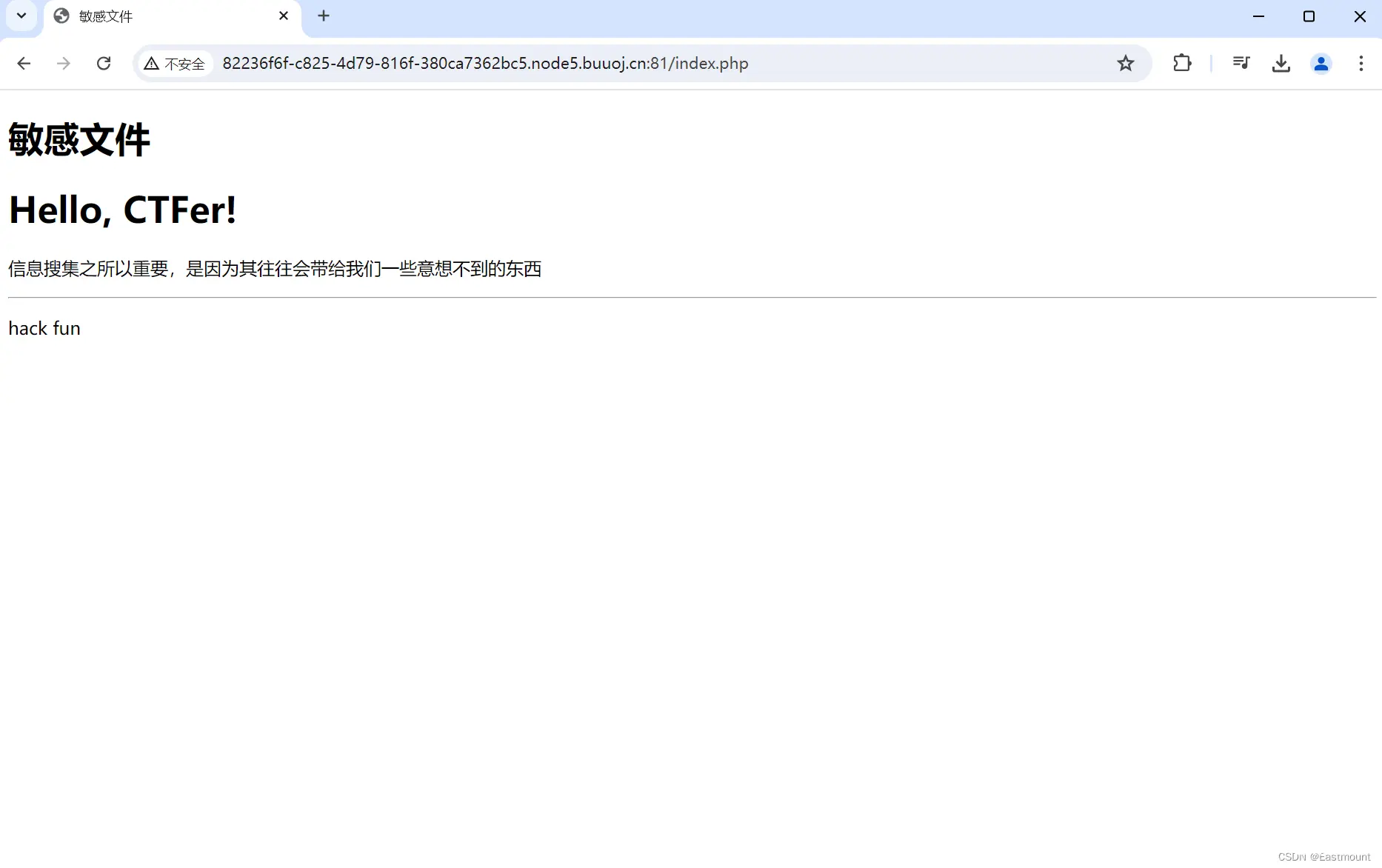
打开网站如下所示:
http://8122d9bd-c977-44f6-a044-b206ef36511f.node5.buuoj.cn:81/
Hello, CTFer!
信息搜集之所以重要,是因为其往往会带给我们一些意想不到的东西
hack fun
二.解题思路
首先,打开该网页通过描述,可以知道该题目考察的是信息收集。作为初学者,我们第一想法是网站扫描和源码解析,如下图所示:
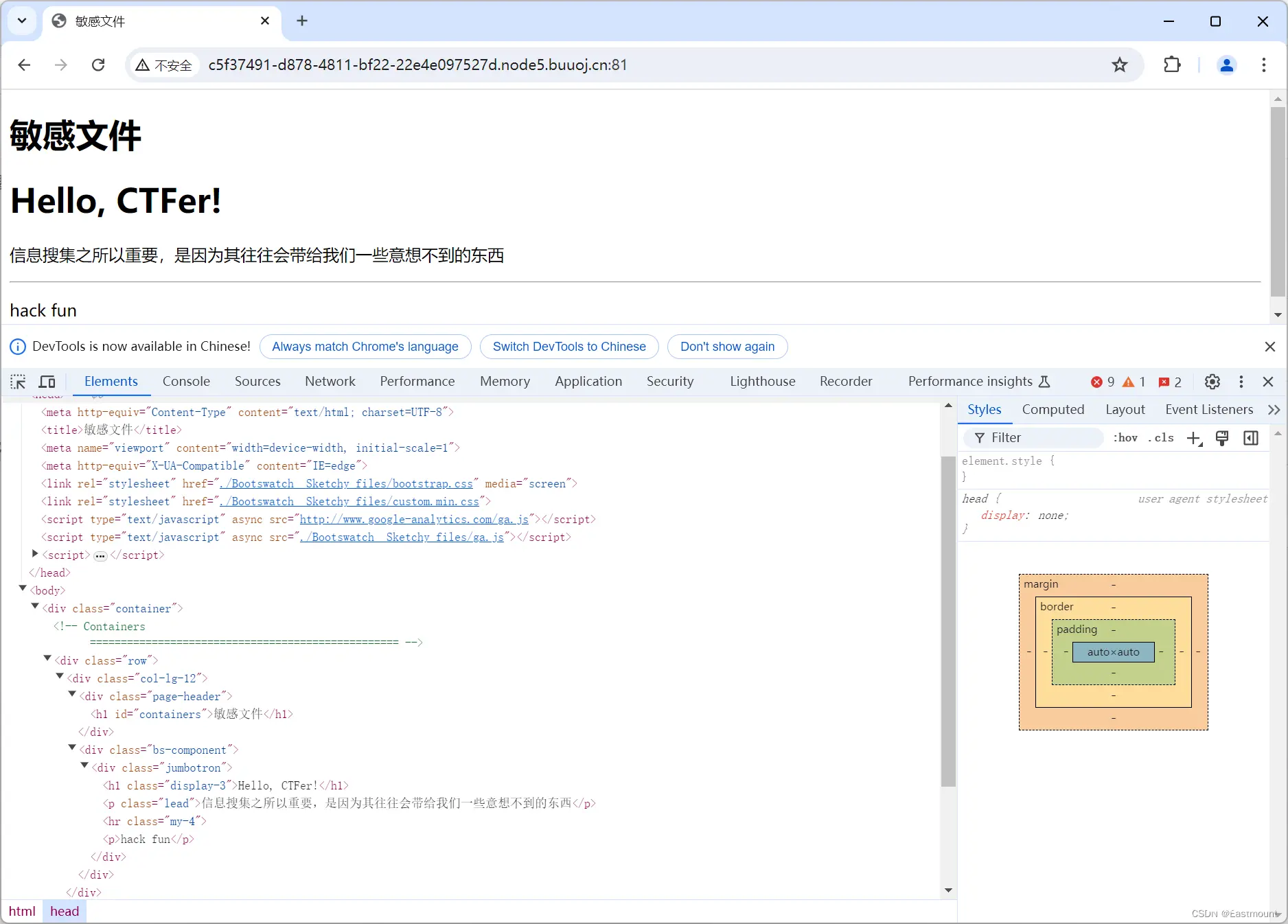
然而,源码并没有透露相关信息,因此换种方法——尝试利用dirsearch工具进行信息采集。
1.dirsearch安装及基本用法
Dirsearch是一个用于探测Web服务器上的隐藏目录和文件的工具,它通过发送HTTP请求来尝试访问可能存在的路径,从而找到不列在网站目录页面上的隐藏资源。具体功能包括:
快速扫描多线程支持自定义字典多种选项颜色化输出HTTP代理支持报告生成
由于整个源码已在GitHub开源,因此我们可以直接下载安装(注意Python3开发)。如下图所示:
https://github.com/maurosoria/dirsearch
下载后的文件目录如下所示:
输入CMD调用pip进行安装。
如下图所示:
pip install dirsearch

另一种安装方法是去到Python软件目录scripts位置,通过pip命令安装。
pip install DirSearch
安装过程,如下图所示:
读者可以尝试在Kali中进行安装。
2.信息采集
接下来,我们将利用dirsearch工具采集信息。
首先我们先介绍dirsearch工具的基本用法。
python dirsearch.py -u url -e txt -w db/dicc.txt
其中,-u参数表示需要扫描的目标链接,-e参数表示执行扫描的文件扩展名(如txt),-w参数指定自定义字典,比如使用dirsearch自带的词典(db目录下的dicc.txt文件)。
接着开启具体的信息采集。
第一步,扫描指定网站内容,打开界面如下图所示。
<code> python dirsearch.py -u http://82236f6f-c825-4d79-816f-380ca7362bc5.node5.buuoj.cn:81 -e *
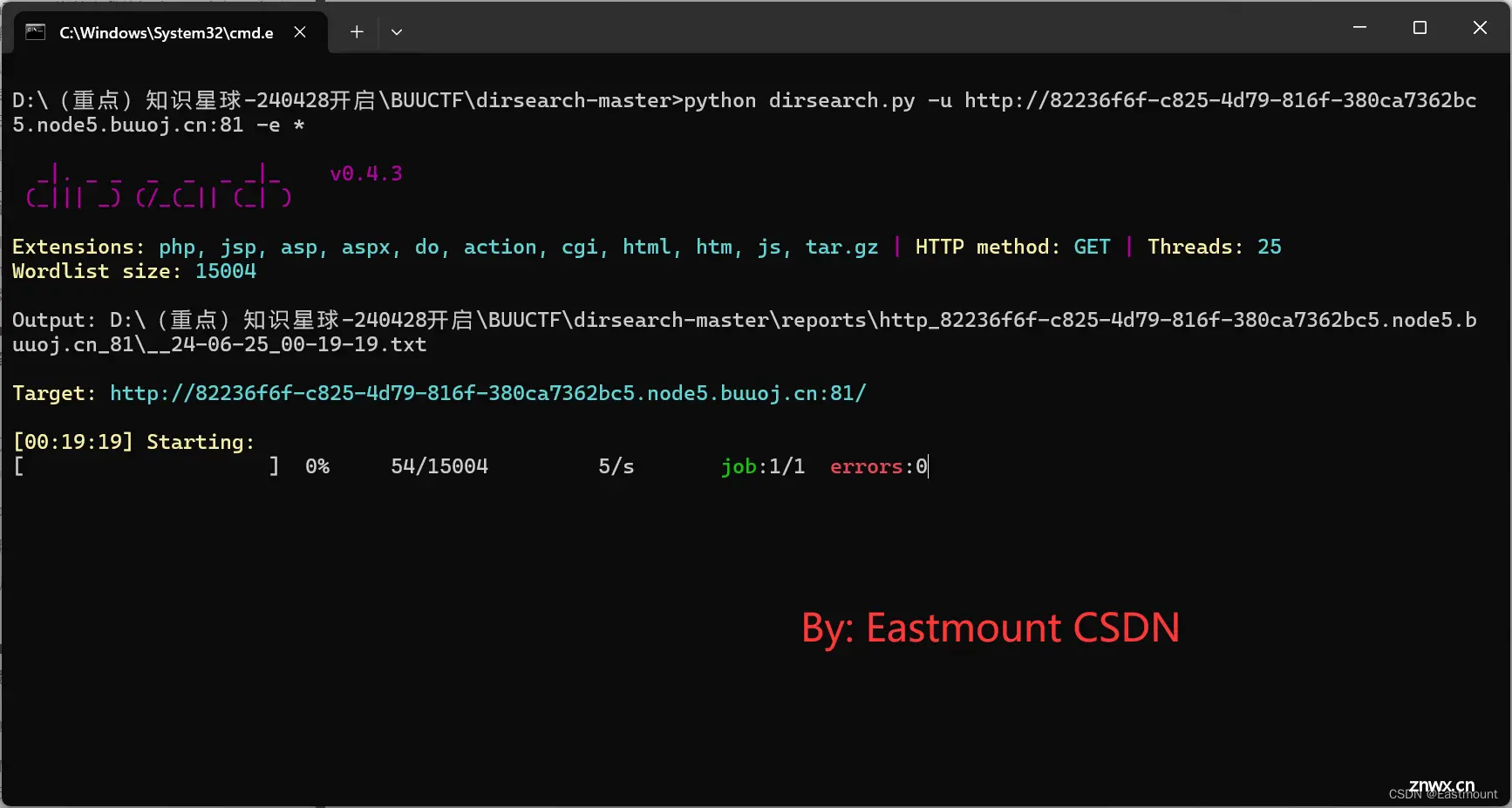
由扫描结果可以发现,通过词典可以访问不同类型的文件,比如“/.htaccess.bak1”显示未403,而“/.index.php.swp”显示存在200。因此,通过访问这些泄露文件来寻找线索。
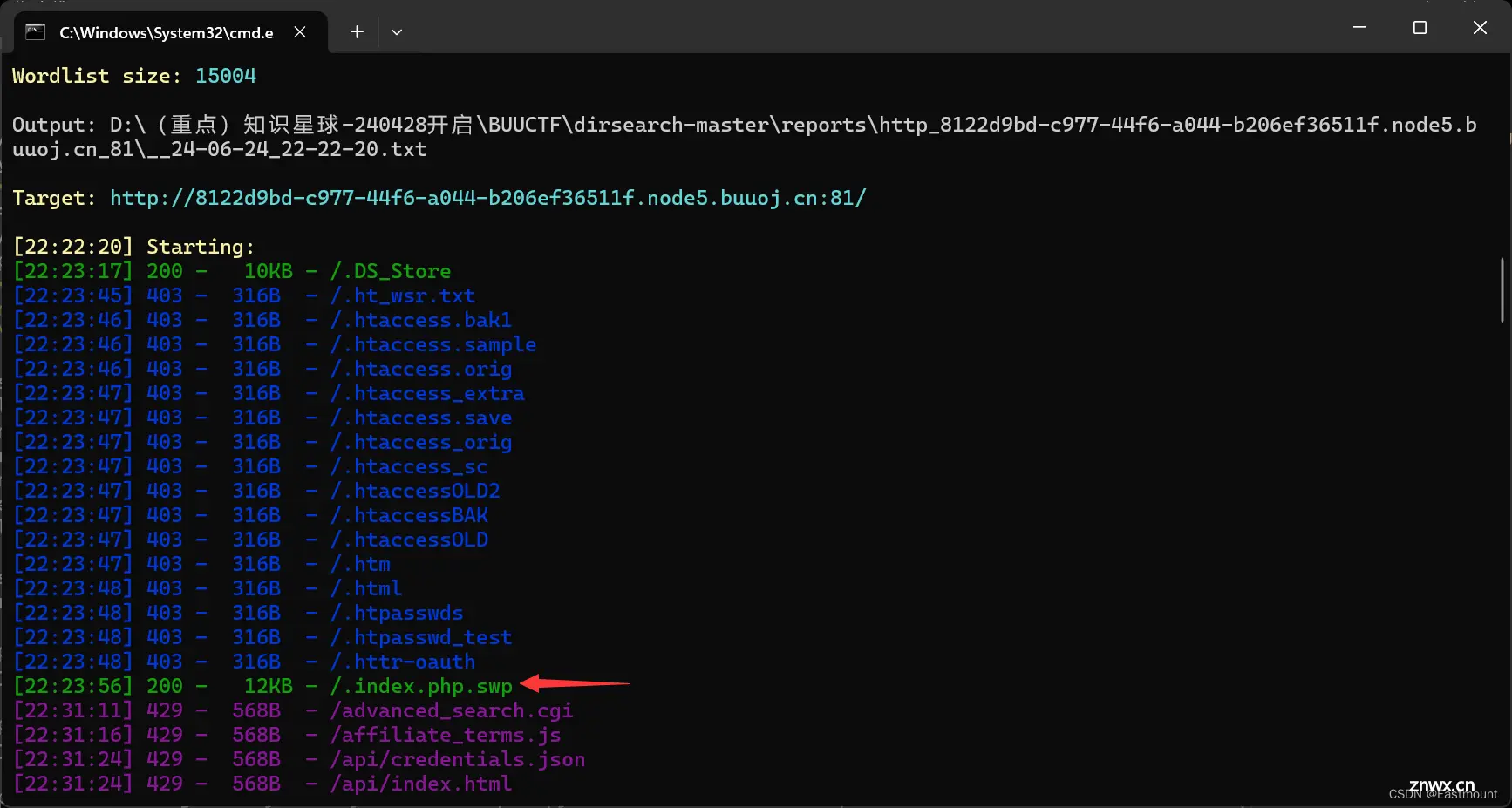
同样还可以看到其它文件。
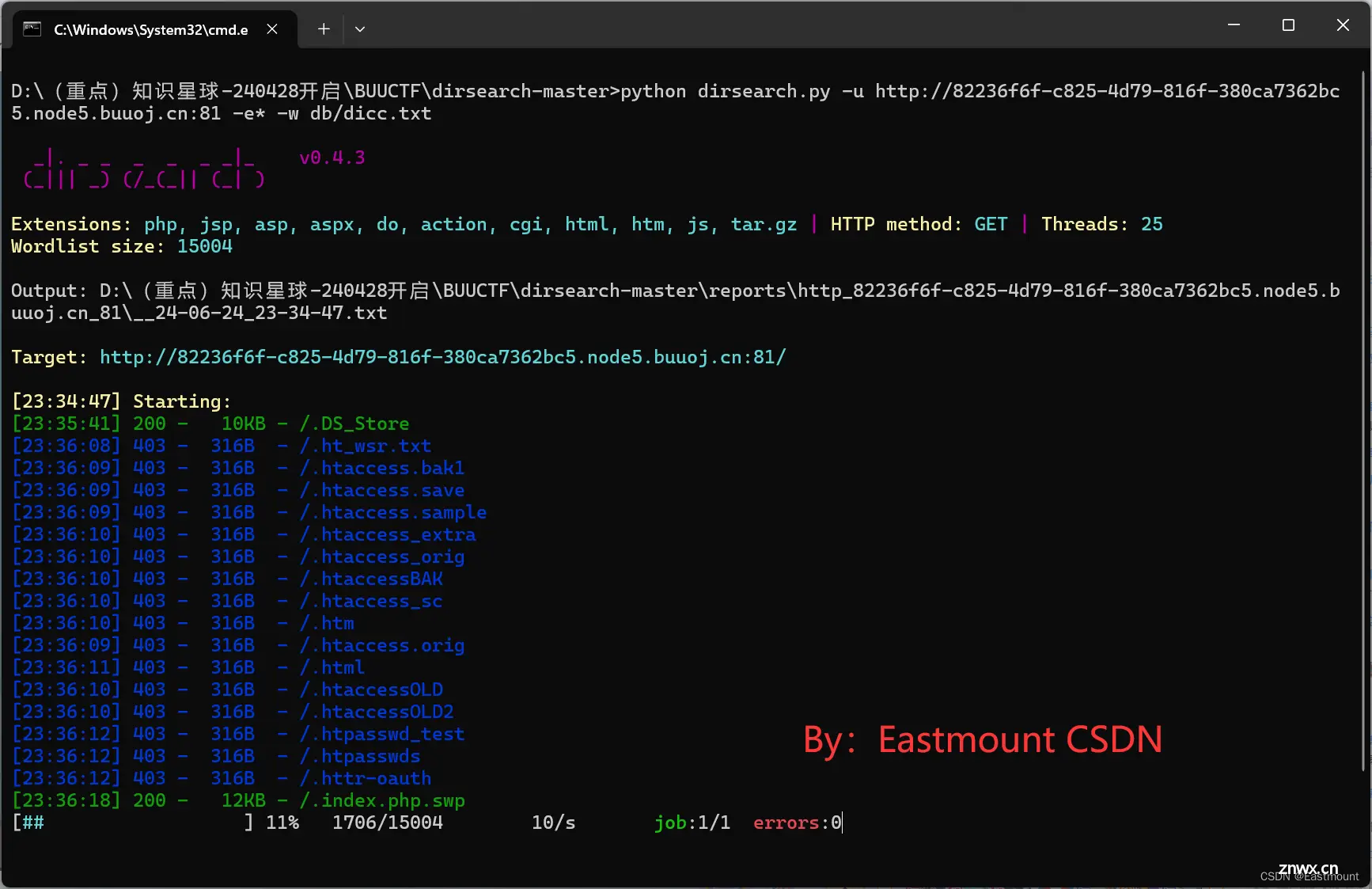
第二步,通过访问指定文件夹扫描指定文件,如dicc.txt。
<code>python dirsearch.py -u http://82236f6f-c825-4d79-816f-380ca7362bc5.node5.buuoj.cn:81 -e * -w db/dicc.txt
下图展示了如何向词典中添加自定义文件。
同理可以设置递归访问。
<code>python dirsearch.py -u http://82236f6f-c825-4d79-816f-380ca7362bc5.node5.buuoj.cn:81 -w db/dicc.txt -r --deep-recursive
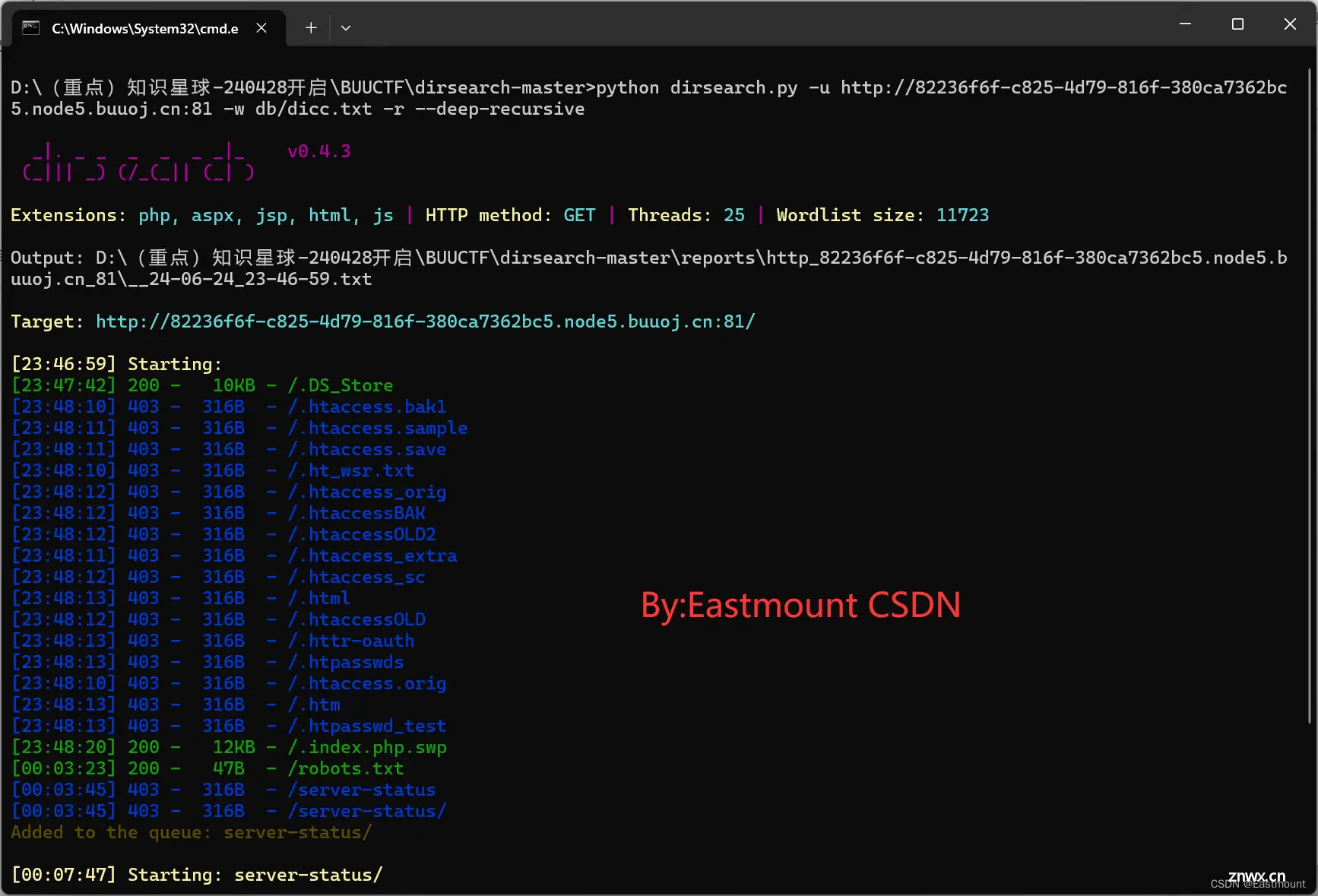
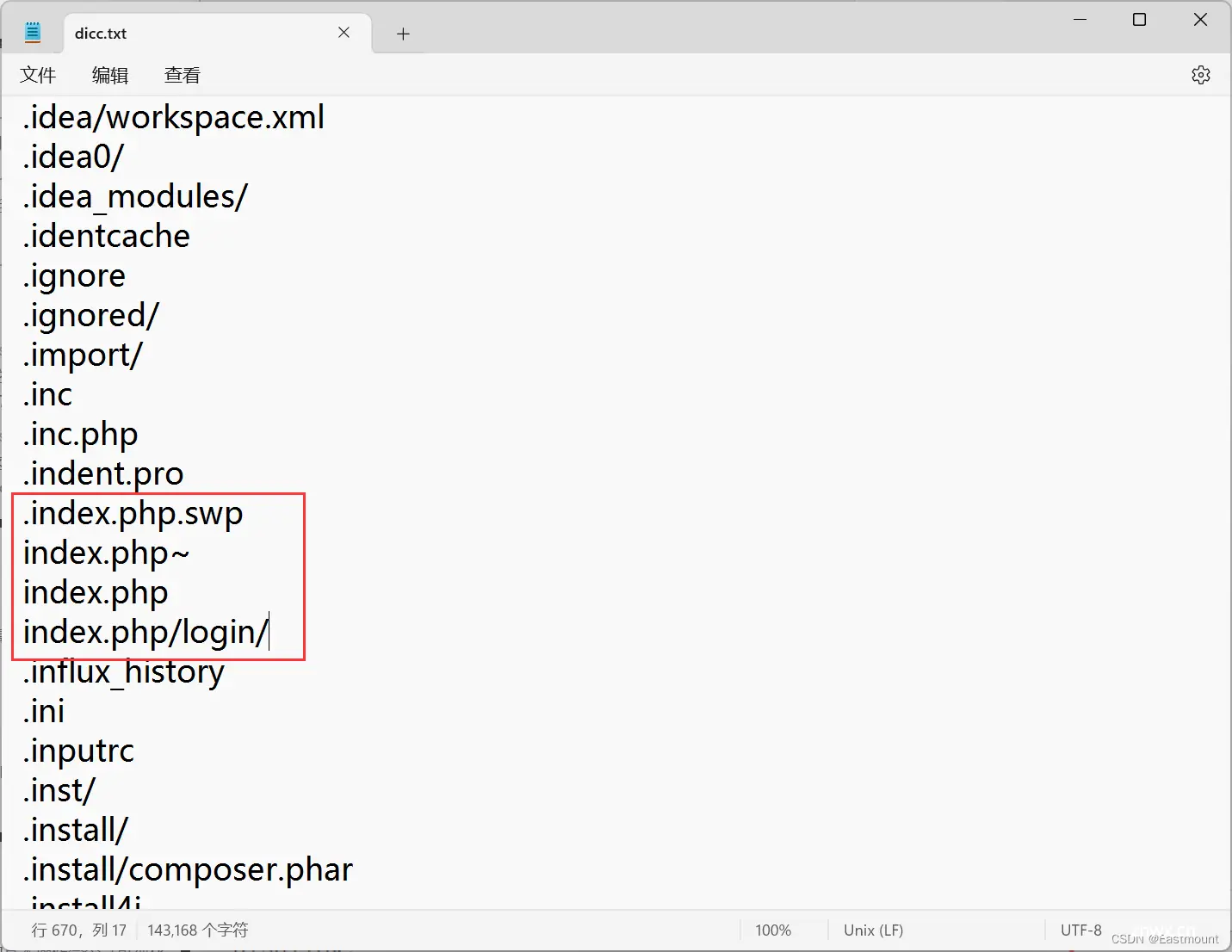
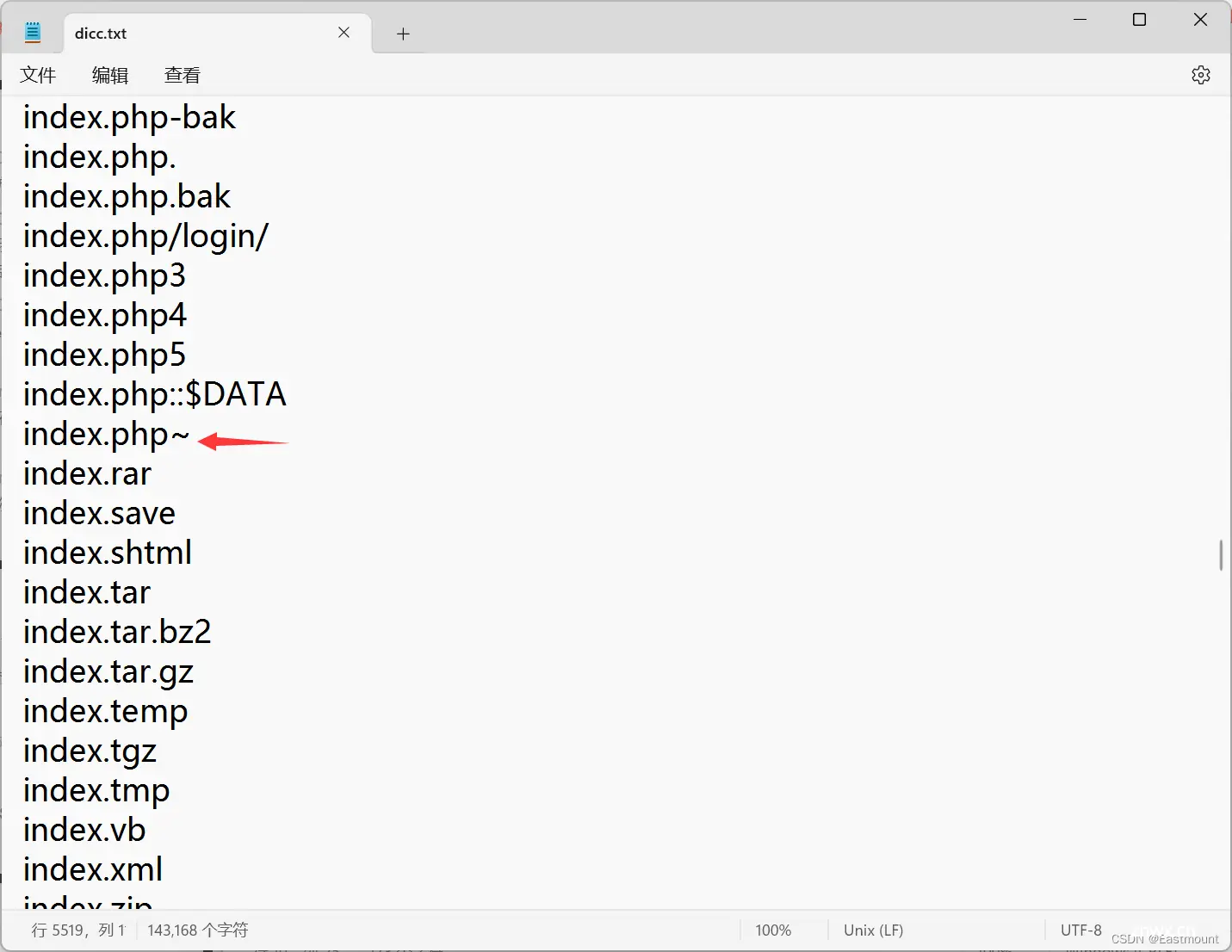
注意:在作者扫描过程中,主要发现了如下图所示的文件,不知道为什么“index.php~”文件无法发现,并且dicc.txt词典中包括该名称,似乎词典-w参数未起作用。
第三步,分别分析扫描发现的3个关键泄露文件,找到对应的flag。
.index.php.swprobots.txtindex.php~
3.寻找flag
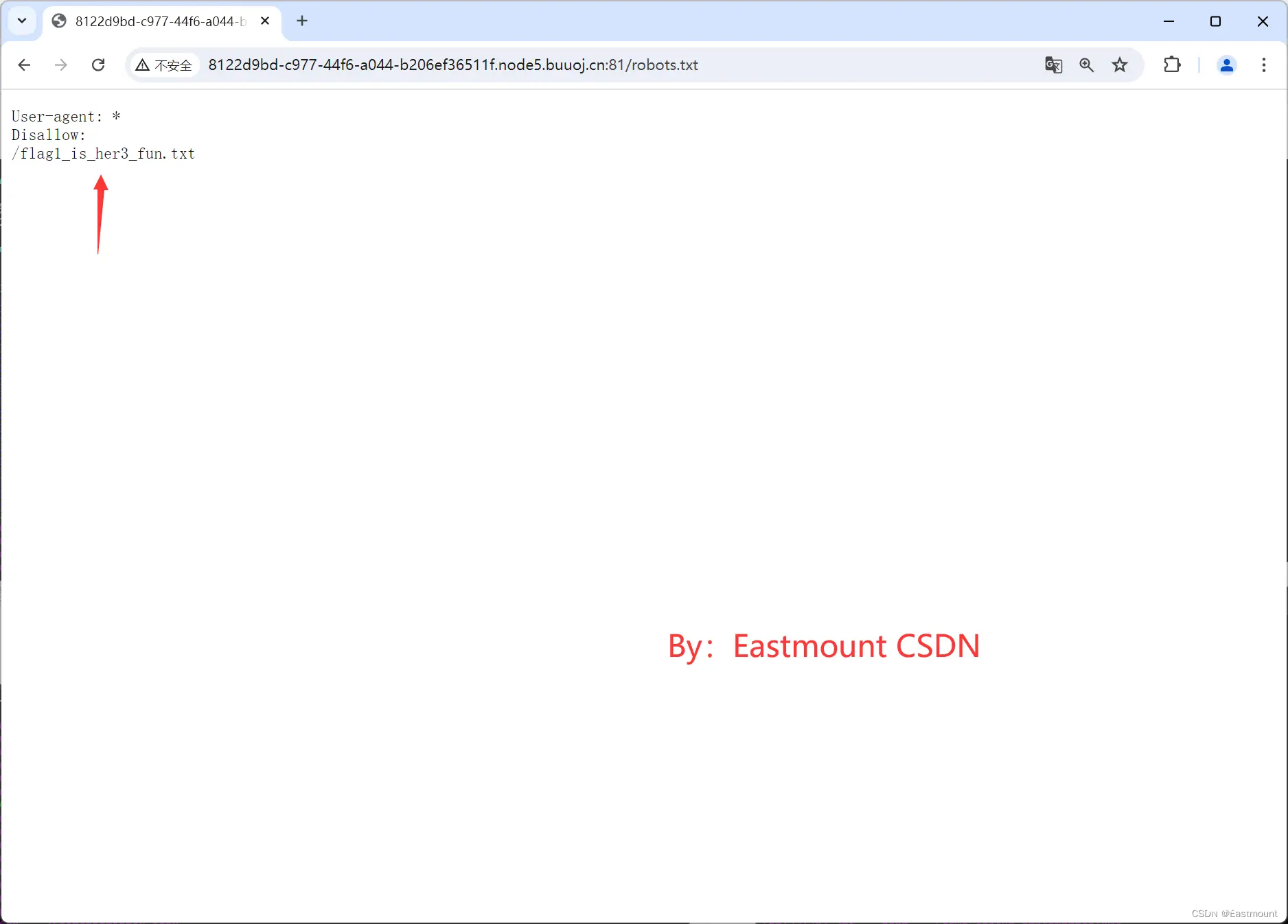
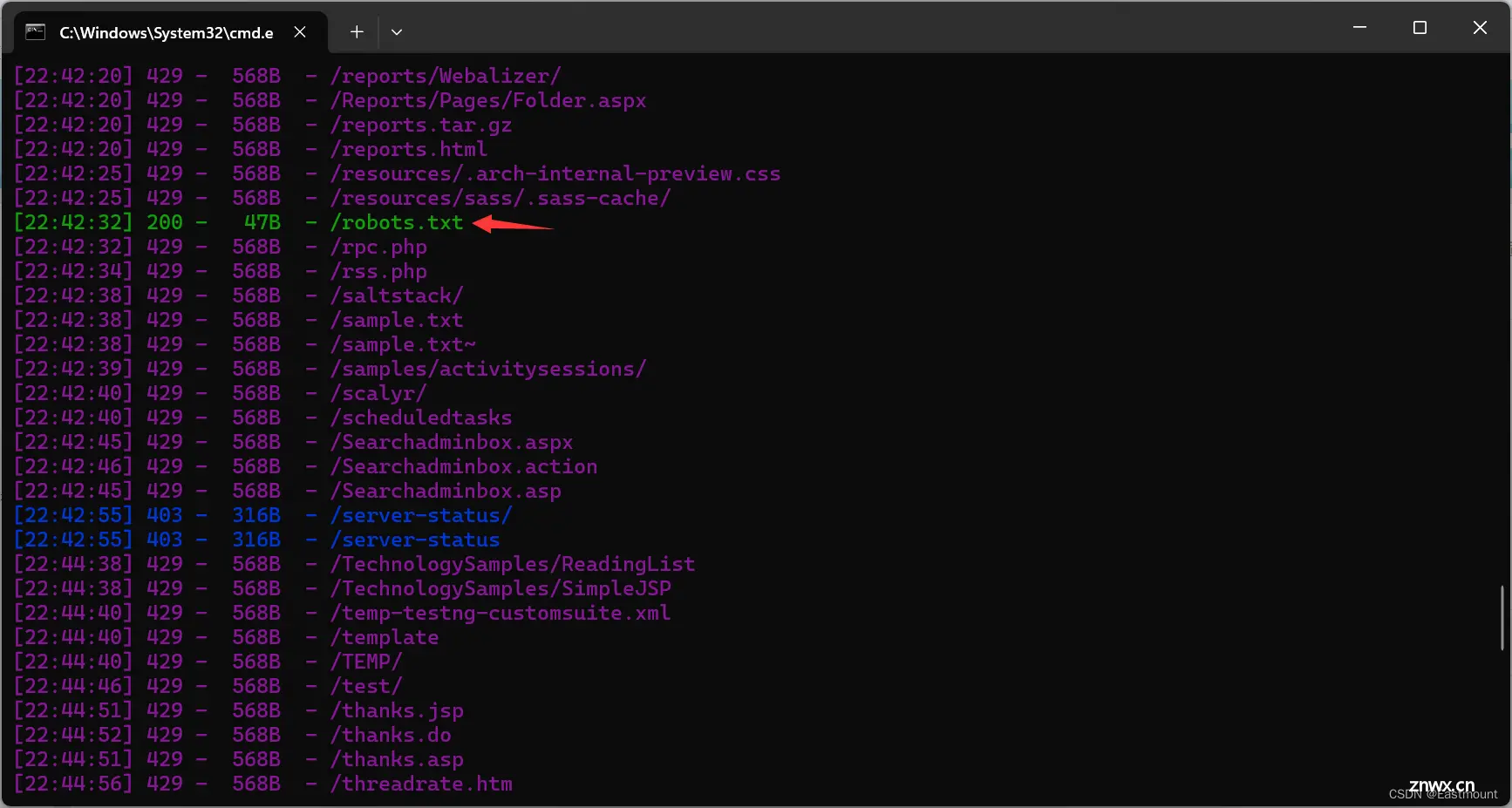
第一步,访问 robots.txt 文件并找到flag。
http://8122d9bd-c977-44f6-a044-b206ef36511f.node5.buuoj.cn:81/robots.txt
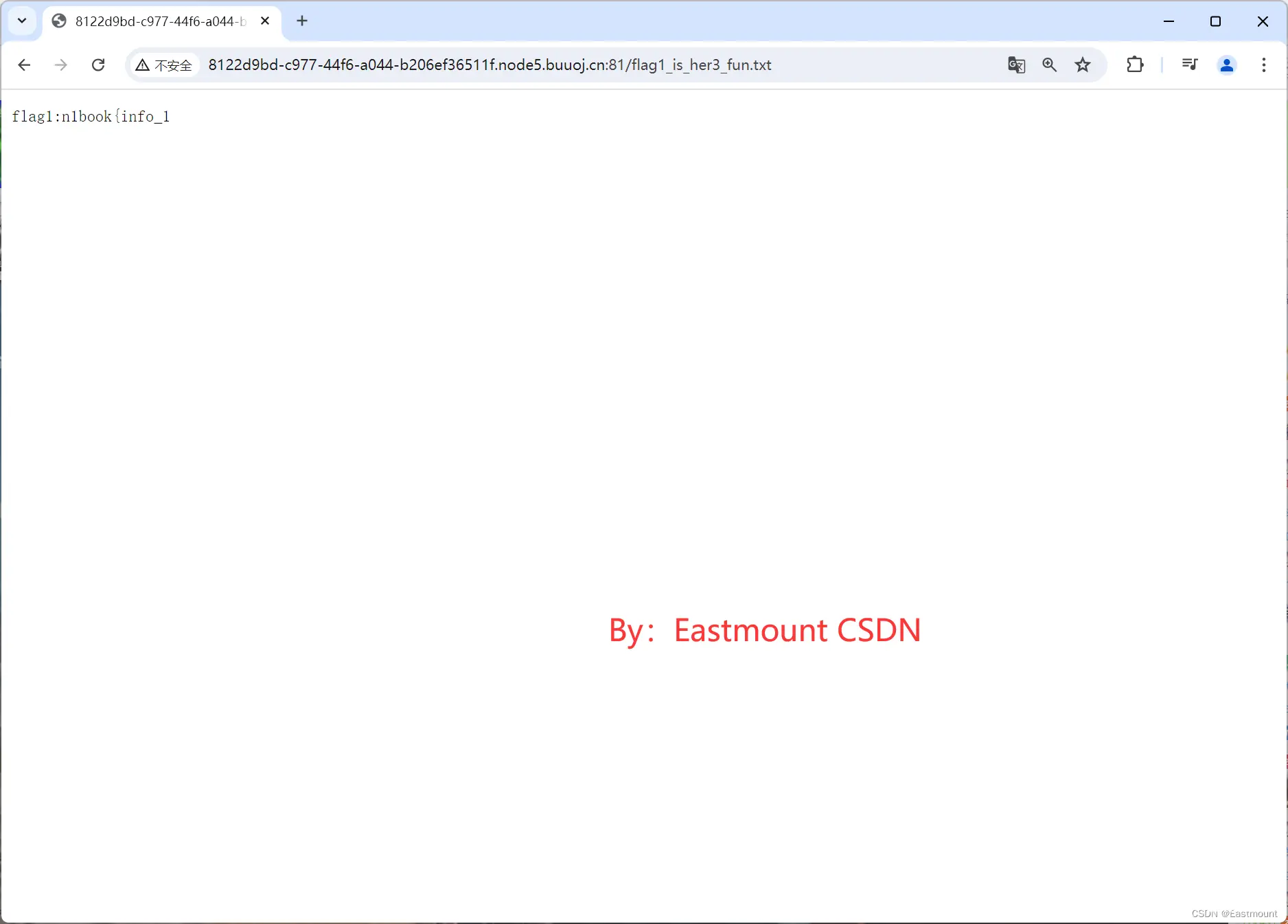
可以看到其网页中提示了一个新的txt文件,打开它可以看到第一个flag。
http://8122d9bd-c977-44f6-a044-b206ef36511f.node5.buuoj.cn:81/flag1_is_her3_fun.txt
找到flag1,结果为:
flag1:n1book{info_1
提示:robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。 当一个搜索机器人或爬虫访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。 另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。
第二步,访问 .index.php.swp 文件获取第二个flag,该文件为vim备份文件,格式通常为 .filename.swp 或者 .swo 或者.swn。
http://8122d9bd-c977-44f6-a044-b206ef36511f.node5.buuoj.cn:81/.index.php.swp
提示:.index.php.swp是在vim编辑器异常退出时保留的备份文件,可以用vim -r .index.php.swp(建议使用WSL,不用开启Linux虚拟机)恢复原始内容。
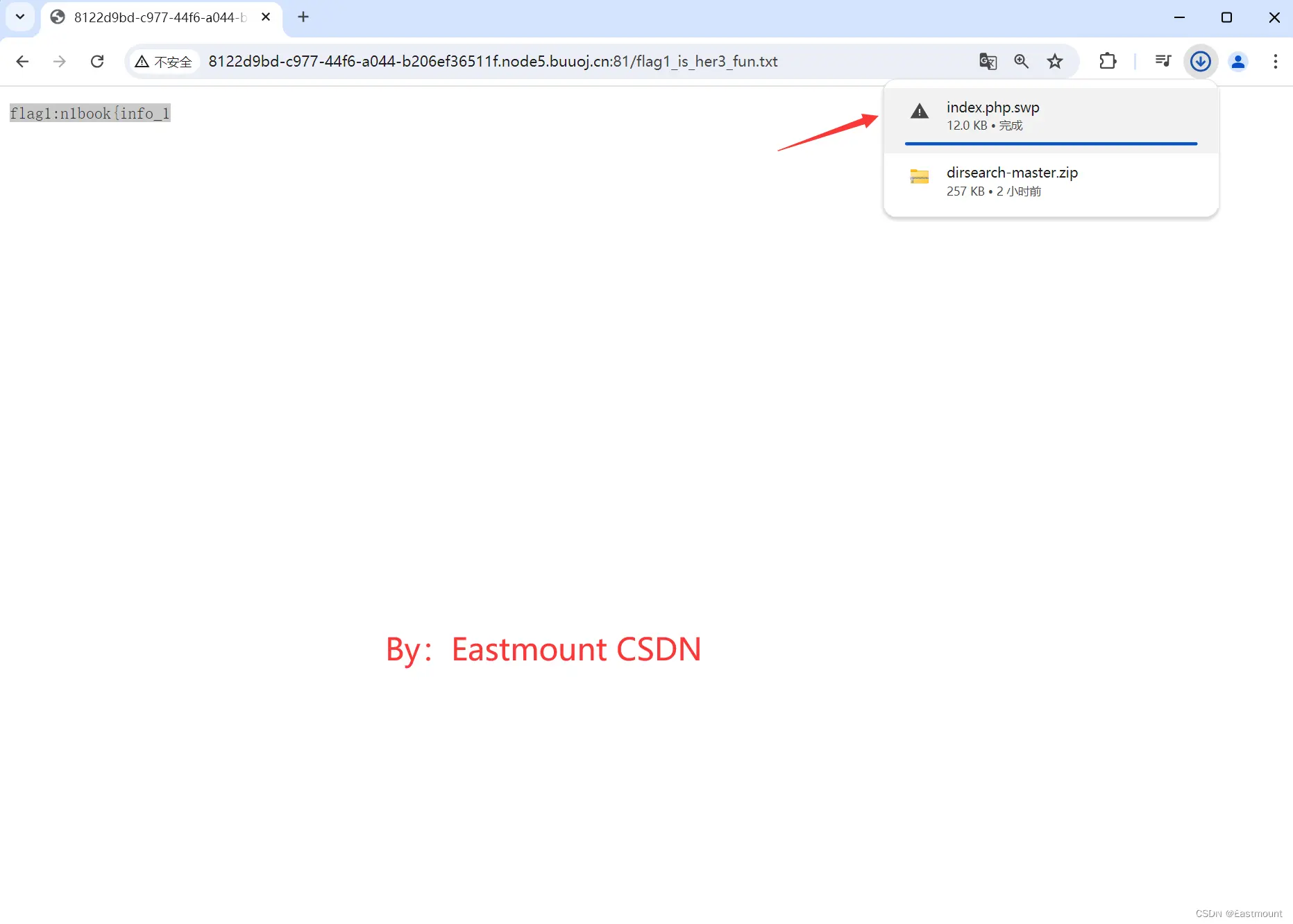
访问该网址可以将 index.php.swp 文件下载到本地,并在该文件中找到对应的flag3。
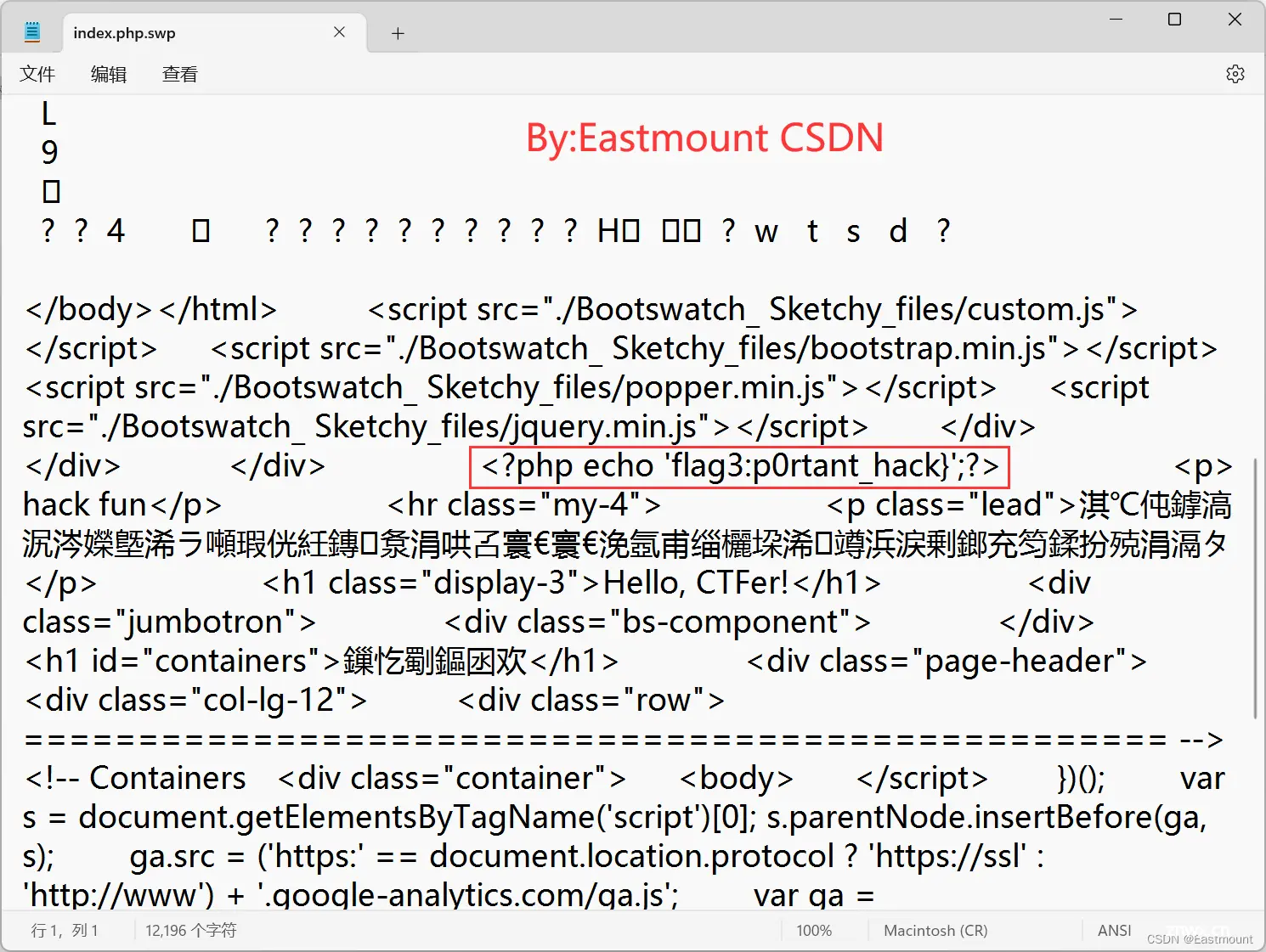
找到flag3,结果如下:
<code><?php echo 'flag3:p0rtant_hack}';?>
第三步,访问 index.php~ 文件找到对应的flag。
http://82236f6f-c825-4d79-816f-380ca7362bc5.node5.buuoj.cn:81/index.php~
gedit备份文件,格式为filename~,比如index.php~。
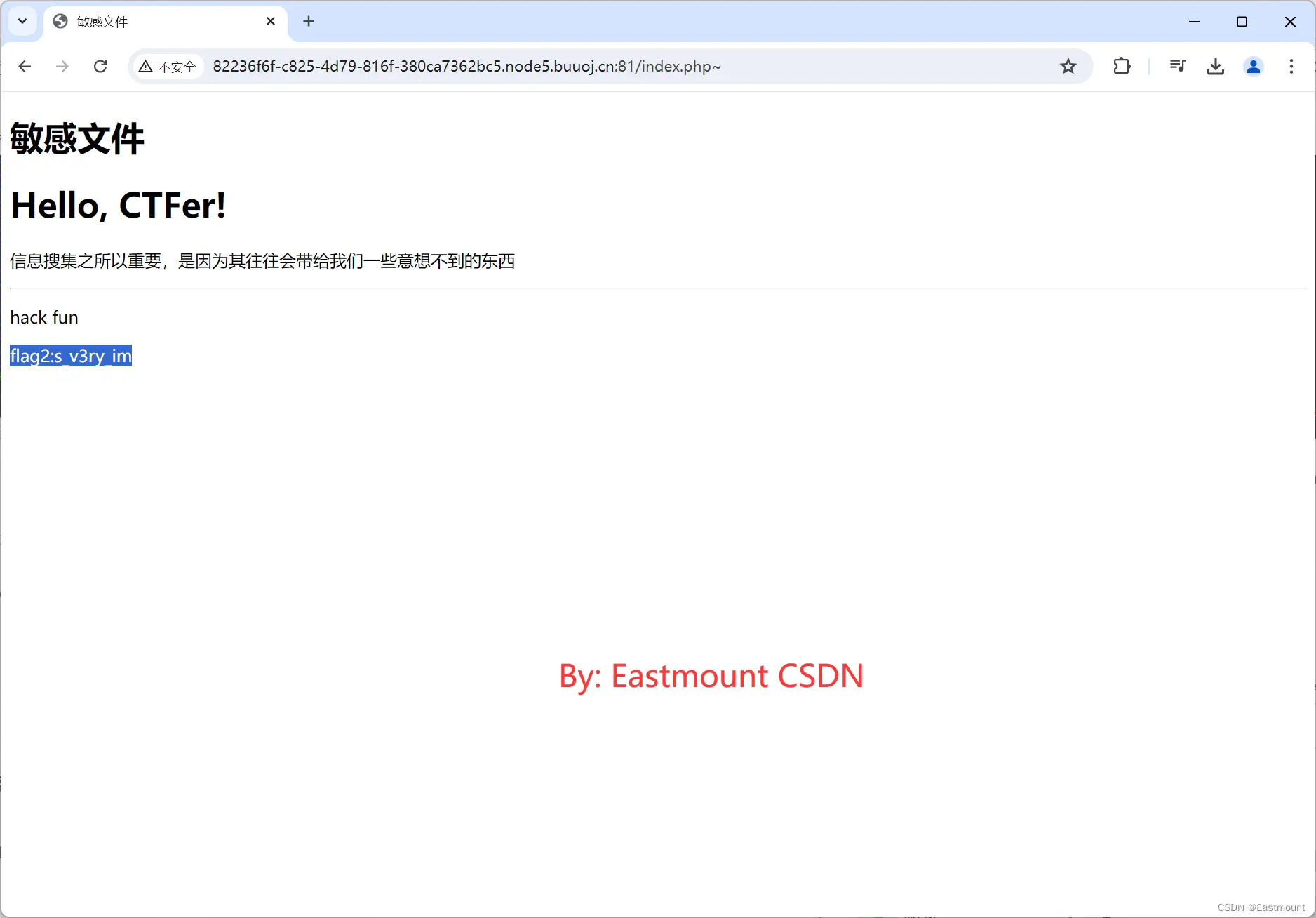
其输出结果可以看到flag2,结果为:
flag2:s_v3ry_im
第四步,构造最终的flag并提交。
flag1:n1book{info_1flag2:s_v3ry_imflag3:p0rtant_hack}
最终结果:
n1book{info_1s_v3ry_imp0rtant_hack}
三.探索扩展
读者可以尝试其它工具扫描,如御剑工具。具体用法详见作者之前的文章:
[网络安全自学篇] 八.Web漏洞及端口扫描之Nmap、ThreatScan和DirBuster原理详解
同样,可以在本机上使用docker构建环境,用dirsearch扫描服务器文件并得到目标
1.dirsearch词典问题
在dirsearch工具中,包含一个db目录,用于存储信息采集的词典,如dicc.txt。
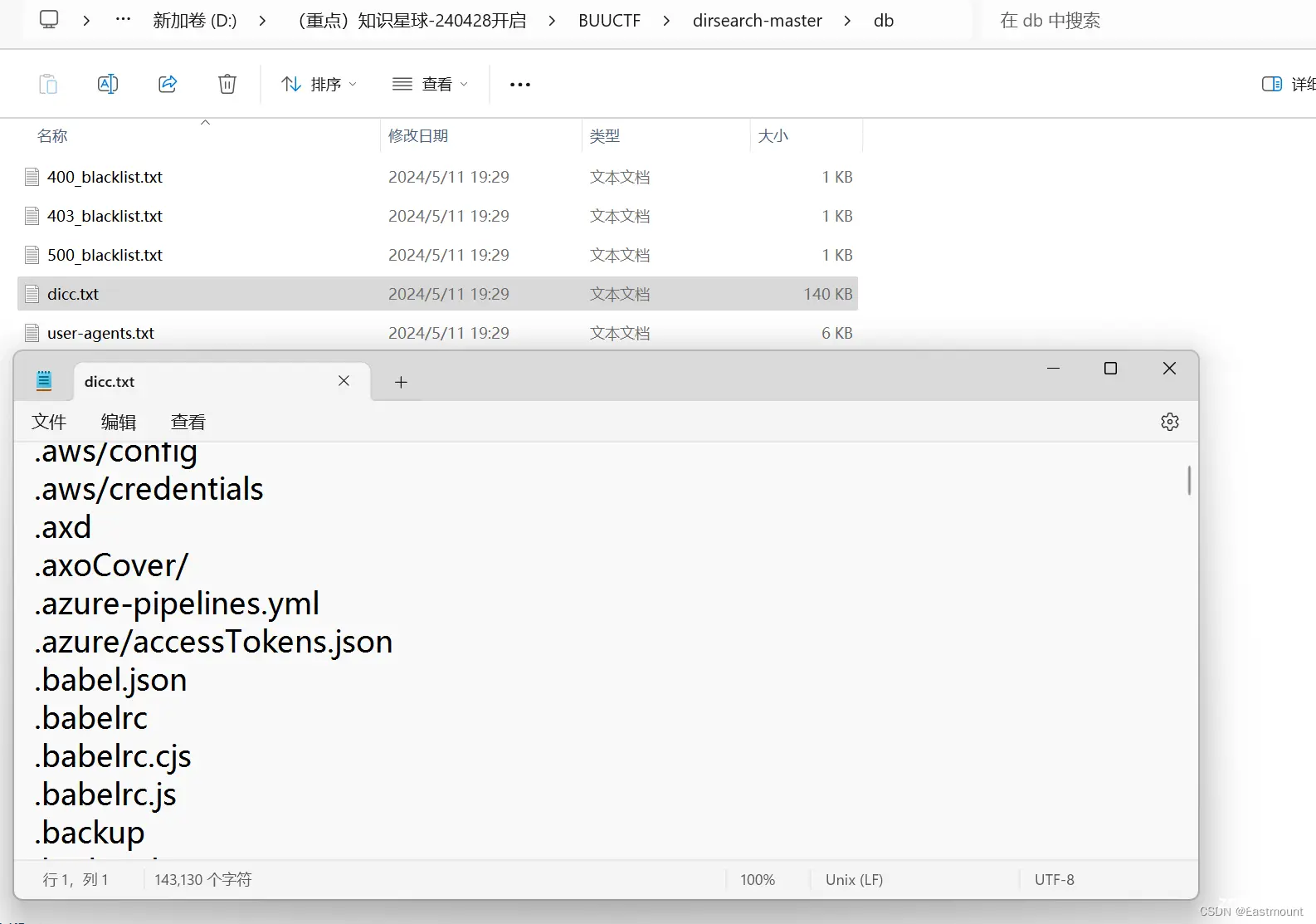
词典中包括常见的泄露信息或文件名词,如“.index.php.swp”。
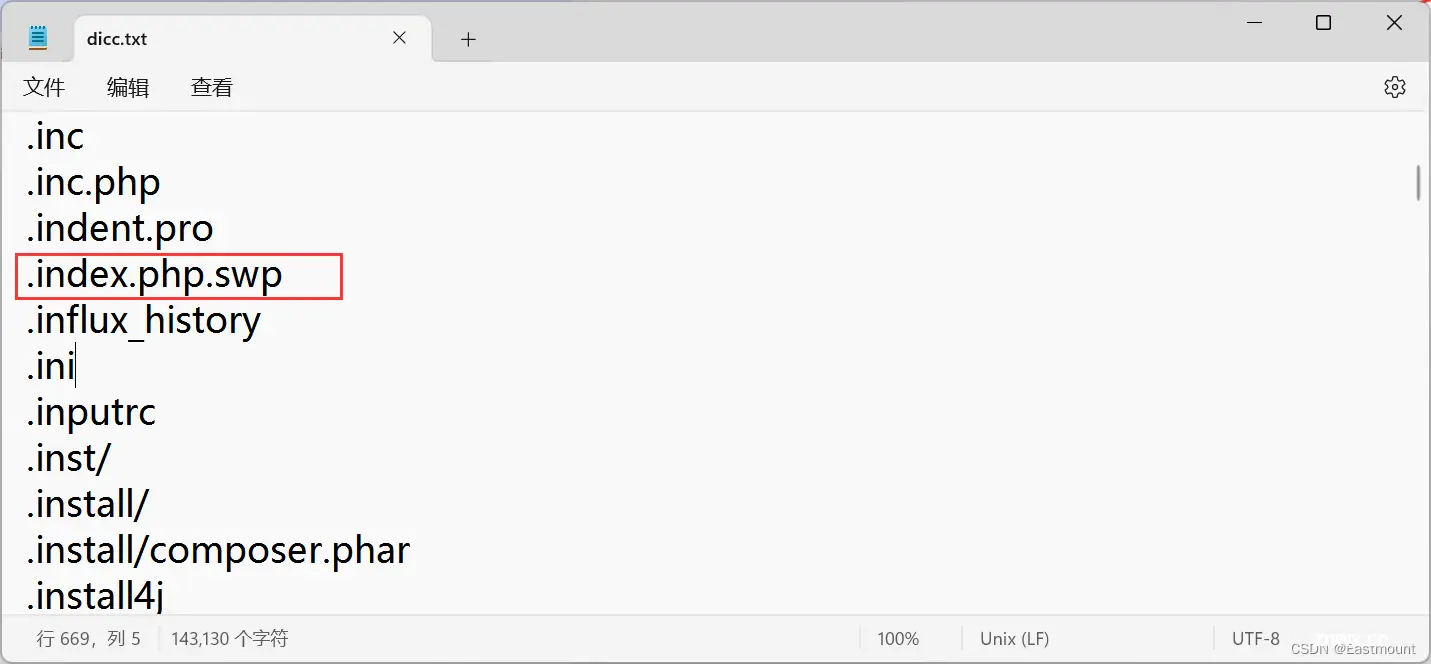
然而,在该题目中,作者进行了多种尝试,仍然无法扫描出“index.php~”文件,并且设置词典未起作用(词典中包括对应名词)。如果读者知道具体原因还请告知,谢谢。

其他作者扫描结果如下图所示。
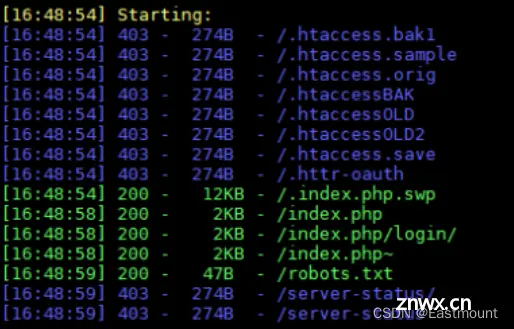
而作者的dirsearch只能发现两个代表性泄露信息文件。
2.dirsearch基础用法
最后,我们补充下dirsearch工具的部分用法。该工具会在reports目录中保存每次扫描结果的内容,如下图所示:
并且 requirements.txt 文件中包含详细的依赖包信息。
<code>PySocks>=1.7.1
Jinja2>=3.0.0
certifi>=2017.4.17
defusedxml>=0.7.0
markupsafe>=2.0.0
pyopenssl>=21.0.0
charset_normalizer~=2.0.0
requests>=2.27.0
requests_ntlm>=1.1.0
colorama>=0.4.4
ntlm_auth>=1.5.0
pyparsing>=2.4.7
beautifulsoup4>=4.8.0
mysql-connector-python>=8.0.20
psycopg[binary]>=3.0
requests-toolbelt>=1.0.0
官方文档也有各种参数用法,读者可以结合具体需求学习。
具体用法:参考文献8
<code>1) 帮助查询
python dirsearch.py -h
2) 扫描单个URL并限制线程数和扩展名
python dirsearch.py -u url -t 10 -e php,asp --exclude-extensions=html
3) 从URL列表文件中批量扫描
python dirsearch.py -l urls.txt -t 5 -e php
4) 使用自定义字典和深度递归扫描
python dirsearch.py -u url -w wordlist.txt -r --deep-recursive
5) 在请求中使用自定义HTTP头
python dirsearch.py -u url -H "X-Custom-Header: Value" -H "Authorization: Bearer token"
6) 指定线程数和延迟时间
python dirsearch.py -u url -t 20 --delay 0.5
7) 包含和排除特定状态码:包含200和302,排除404和500响应
python dirsearch.py -u url -i 200,302 -x 404,500
8) 使用代理进行扫描
python dirsearch.py -u url -p http://127.0.0.1:8080
9) 保存输出到文件
python dirsearch.py -u url -o output.txt
10) 从标准输入读取URL
cat urls.txt | python dirsearch.py --stdin -t 10
11) 设定最大运行时间和最大重试次数
python dirsearch.py -u url --max-time 300 --retries 5
12) 排除特定文本出现的响应
python dirsearch.py -u url --exclude-text "Not Found" --exclude-text "Error"
13) 设置最小和最大响应长度
python dirsearch.py -u url --min-response-size 1000 --max-response-size 50000
四.总结
写到这里,这篇文章就介绍完毕,基础性文章,希望对您有所帮助。同时建议读者多实践,尝试各种类型的CTF题目。
2024年4月28日是Eastmount的安全星球——『网络攻防和AI安全之家』正式创建和运营的日子,该星球目前主营业务为 安全零基础答疑、安全技术分享、AI安全技术分享、AI安全论文交流、威胁情报每日推送、网络攻防技术总结、系统安全技术实战、面试求职、安全考研考博、简历修改及润色、学术交流及答疑、人脉触达、认知提升等。下面是星球的新人券,欢迎新老博友和朋友加入,一起分享更多安全知识,比较良心的星球,非常适合初学者和换安全专业的读者学习。
目前收到了很多博友、朋友和老师的支持和点赞,尤其是一些看了我文章多年的老粉,购买来感谢,真的很感动,类目。未来,我将分享更多高质量文章,更多安全干货,真心帮助到大家。虽然起步晚,但贵在坚持,像十多年如一日的博客分享那样,脚踏实地,只争朝夕。继续加油,再次感谢!

(By:Eastmount 2024-06-28 夜于贵阳 http://blog.csdn.net/eastmount/ )
参考资料:
[1] 《从0到1CTFer成长之路》 Null战队,电子工业出版社[2] CTFHub_N1Book-常见的搜集&粗心的小李(robots.txt、index.php~、.index.php.swp文件泄露、git泄露)- zhengna[3] N1BOOK第一关摸鱼:[第一章 web入门]常见的搜集 - MR.QQQQIU[4] https://github.com/Jason1314Zhang/BUUCTF-WP[5] [第一章 web入门]常见的搜集 1 - LI-AO1134[6] BUUCTF N1BOOK [第一章 web入门] - Sk1y[7] Dirsearch简单使用 - xiaopeisec[8] [网络安全] Dirsearch 工具的安装、使用详细教程 - 酒酿小小丸子
下一篇: Nuxt.js 应用中的 app:suspense:resolve 钩子详解
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。