基于AI的D2C前端代码生成技术深入总结
阿里巴巴淘系技术团队官网博客 2024-08-22 14:33:01 阅读 85

在AI技术日益渗透至各领域的背景下,本文深入探讨了B端(D2C)前端代码生成技术的核心挑战与实战解决方案,诚实地揭示了在实现自动化代码生成过程中遭遇的重重难关。

产品介绍
▐ 背景
● 做为淘天内的AI创新团队,在团队内做了很多AI大模型的探索,了解到AI可以解决大量简单重复的事情,B端场景标准化程度比较高,不管是低代码还是源码开发,理论上都可提效;
● 在基础平台也有非常多的B端页面研发,有天然的研发提效诉求,经过调研,预计每年可在团队内部节省非常客观的数据。
▐ 产品能力

▐ 落地业务
5+项目落地,平均提效15%,用户调用5000次+
在实际落地过程中遇到了非常多的问题,通过技术+产品的方式解决了很多问题,这里列举一些印象最深的分享给大家。
<code>遇到的问题
▐ 一、prompt管理&测评成本大
问题描述:一开始在idealab上做模型和prompt的评测,但是因为需要大量的测试数据集(100+图片),经常改动一句话就需要重新测评所有的测试数据,导致测评的成本非常高,且不能打分,测评的效率也很低。
解决方案:我们自己打造了一套专门用于UI测评的系统,可以在测评系统上快速测评图片和高效打分,并且可以版本化管理prompt内容,从而能更方便的对外开放使用。
工欲善其事必先利其器,有了这套系统我们评测的效率也大大提升。
▐ 二、图片识别准确率过低
问题描述:我们定义了一套准确率的规则,主要是结构布局、组件类型、组件内容;一开始使用GPT4V,图片识别准确率只有50%,不到及格线。
阶段1:我们发现4V对中文识别非常差,对英文识别比较好,通过OCR翻译成英文后识别,再重新翻译回中文,识别率达到70%-80%
阶段2:今天3月gemini和gpt4o出来之后,我们又对gemini做了大量测试,gemini的图片识别能力更强,性能更好,且token数也足够长,切换到gemini之后,大部分测评图片的准确率能达到90%左右。
▐ 三、某些图片内容识别准确率低
问题描述1:比如:表格详情label项,搜索表格里的搜表单项,表单页面的表单组件的每行个数,有时出现4个,有时5个,子组件的先后顺序都会识别错误。
问题描述2:如table的操作项,通常AI可能会把|或者空格认为是一个操作项,我们定义table的操作项用action表示,但经常会出现多一列叫"操作"的column,表单的标题的*号难以处理。
图一
图二
图三
解决方案一:
通过ocr分析组件标题位置,能得出标题在同一水平线的个数是6个,就能得出表单的一行个数,从而进行正确的布局。
同样可以得出标题的所在顺序,从而重新排列子组件。
<code>[
{
"height": 15,
"width": 54,
"word": "项目管理",
"x": 0,
"y": 10
},
{
"height": 55,
"width": 15,
"word": "新建项目",
"x": 93,
"y": -10
},
{
"height": 12,
"width": 13,
"word": "2",
"x": 401,
"y": 71
}
]
解决方案二:对JSON做预处理
table action做拆分,工程去做,还有操作项有空格、换行符等等
去掉表单label内容里的*,并增加require标识
▐ 四、上行prompt过长导致模型返回错误&出现幻觉
问题描述:当我们要识别更多组件和不同类型的页面时,我们发现在一套提示词里如果描述了太多的demo示例,导致上行Token过长,AI会产生幻觉;且一套提示词token会超长,导致调用时间变长,很多时候AI会直接返回错误,且调用成本也增加。
解决方案:通过页面类型来拆分出不同的提示词,从而减少prompt过长且出现幻觉的问题,页面类型背后主要还是通过AI+OCR来识别,准确率在95%以上,即使不能很好的识别页面类型,还可以通过通用prompt来兜底。
▐ 五、下行组件节点过多导致准确率下降
问题描述:模型返回的组件节点过多,会导致出错率增加准确率下降。
解决方案:实际在很多场景可能只需要对组件做一个标识,比如,是否包含图片,是否是链接,是否能复制,这种情况下识别的准确率会非常高。
▐ 六、定制场景差异大,生成内容无法复用
问题描述:实际在对接业务时,业务场景的差异都非常大,我们只能提供非常基础和通用的组件识别,且生成的代码都是通用的fusion和antd组件源码,无法满足业务诉求。
解决方案:我们把之前做的一整套AI能力抽象化和标准化,提供组件化的能力开放出来,让业务只需要定制个别组件,就能完成业务定制页面的识别和代码生成,这样业务定制一套D2C的成本降低80%。
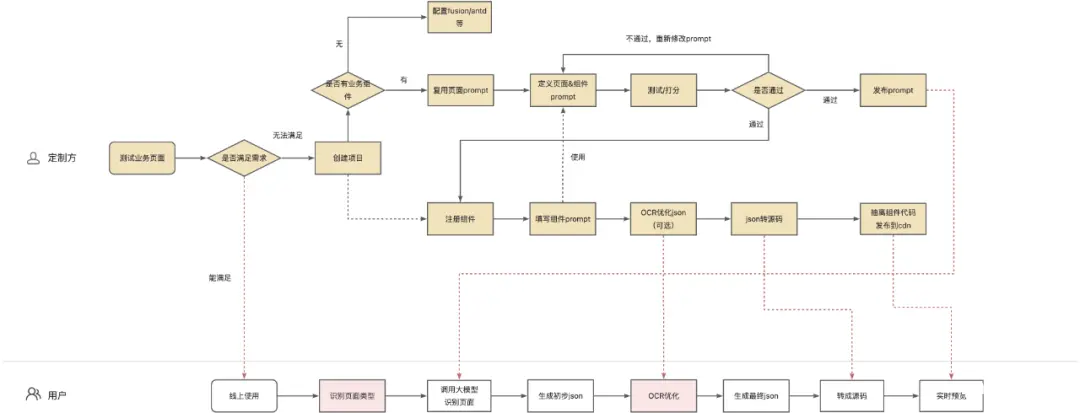
▐ AI可提效的点
首先AI不是万能的,AI能通过图片生成的代码主要有(包括但不限于)以下:
页面静态内容生成:
包括组件、组件基本布局、组件静态文案内容填充、表单必填项等等
自动生成表格内部的cell渲染内容,比如状态、图片、进度条等等
name标识命名(包括表单组件的name,表格列的dataIndex等),命名对于英文不好的同学一直是比较头疼的事
方案一:根据标题中文名称让AI自动生成规范的英文标识命名
方案二:根据接口文档自动生成name,并自动关联接口和生成请求逻辑,辅助接口联调
组件className类名
部分布局等样式
规范代码风格:比如表格使用json来定义columns
很多外包代码质量很差,很难维护,通过AI可以自动生成高质量代码
业务通用逻辑:如表格的删除需要二次确认,再提交接口
其他待补充...
▐ AI不适用场景
也是目前我们还没有解决的点。
模型对于icon识别不是很好,只能识别常见的如复制、删除、箭头,对于不常见的icon无法识别
经常会出现一些样式风格识别错误的情况,比如步骤条的几种风格'circle', 'arrow', 'dot'
对于字体识别比较差,比如对于字体的颜色、大小、类型无法很好的识别,B端一般都有规范,或者通过OCR可以解决一部分
AI无法识别不存在的内容(或者业务逻辑),比如一张表单图里无法知道表单组件是否需要做自适应宽度还是宽度变长后一行个数变多,需要自行定义;
一些不常见的细节逻辑,比如合并表格等
其他补充中...
▐ prompt规范&使用建议
推荐readme格式来书写prompt
提示词里不要包含上面、下面等含糊的词,一定要具体和精确描述
重要的内容可以放在prompt的最后提示强调
不要在示例里一次性把所有的属性都全局返回,会有很多冗余的字段描述,可以描述成,如果xxx情况,就添加属性xxx,这样可以减少AI的返回,在工程里做默认值设置
其他补充中...

结语
从prompt管理的繁琐与测评效率低下,到图片识别精度的瓶颈,再到定制场景的多样性难题,本文逐一分享了团队的应对策略与优化成果。这不仅是一次技术实践的深度剖析,也是对AI在D2C方向潜力与局限的客观总结,为前端开发者和AI研究者提供了宝贵的经验与启示。

团队介绍
我们是淘天基础平台-创新&效能团队,一支专注于通过AI技术驱动来创新和提升淘天技术研发效能的团队,我们团队拥有众多核心产品和技术,这些都是基于多模态大模型(图生文、文生图、文生文、RAG)的应用实践落地产品。作为一支充满活力和创新精神的团队,我们始终在不断地探索和研究最新的AI技术,力求通过持续的技术创新和突破,提升淘天业务技术底座的研发效率,同时让每一位淘天员工都能享受到更好的研发体验。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。