AI绘图开源工具Stable Diffusion WebUI前端API调用
再不会AIGC就不礼貌了 2024-06-20 16:33:01 阅读 85
背景
本文主要介绍 AI 绘图开源工具 Stable Diffusion WebUI 的 API 开启和基本调用方法,通过本文的阅读,你将了解到 stable-diffusion-webui 的基本介绍、安装及 API 环境配置;文生图、图生图、局部重绘、后期处理等 API 接口调用;图像处理开发中常用到一些方法如 Base64、PNG、Canvas及 URL 相互转换、Canvas 颜色转换等。
AI 绘图工具目前市面上比较广泛使用的主要有两款,一个是 Midjourney,它提供面向用户有好的操作界面,文生图、图生图等功能非常强大,但是它是一款收费软件;另一个就是开源工具 Stable Diffusion, 同样具有强大的AI绘图和图片再创造能力,但是学习成本和上手难度相对较大,不过由于它是开源的,现在有非常多的用户和开发者,我们可以找到丰富的训练模型和学习资源。本文介绍的 Stable Diffusion WebUI 就是基于 Stable Diffusion 的具有比较完善的可视化操作界面的 AI 绘图开源工具,它的 github 访问地址是 github.com/AUTOMATIC11…。
顺便一提,本文上方的
Banner图就是使用Stable Diffusion生成的😎
使用体验
在正式开发之前,我们可以先体验一下 Stable Diffusion WebUI 以及两个接口封装和操作界面比较优秀的 AI 绘图网站,了解文生图、图生图、后期处理等基本操作步骤。
🔗 stablediffusionweb.com/WebUI🔗 d.design🔗 www.liblibai.com
环境配置
安装 Stable Diffusion WebUI
我们首先需要先在本地或者服务器安装部署 Stable Diffusion WebUI,可以从Github克隆仓库,然后按说明文档进行安装,对前端开发来说安装流程非常简单,详细安装流程大家可以自行搜索,现在网上已经有很多保姆级的教程,本文不再赘述。
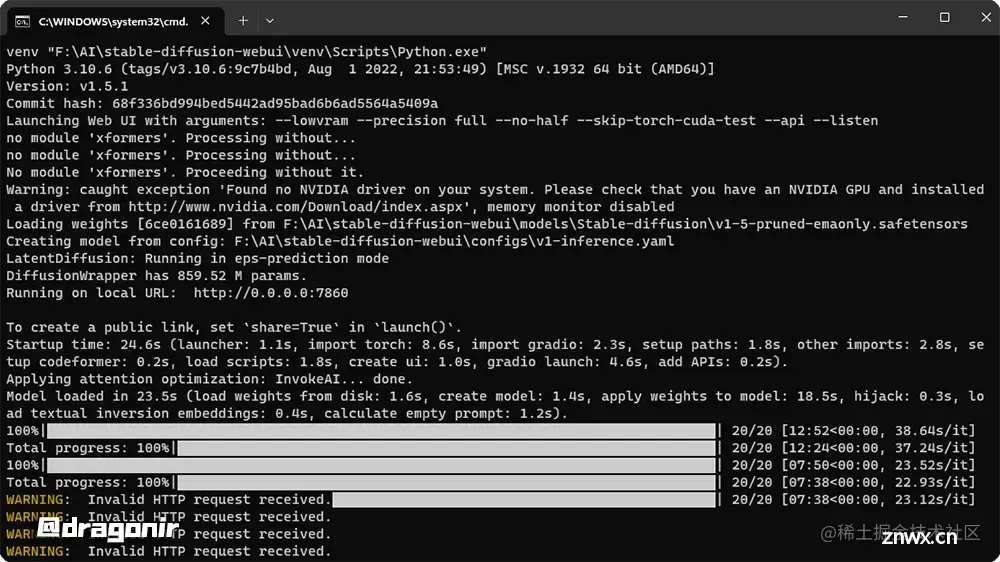
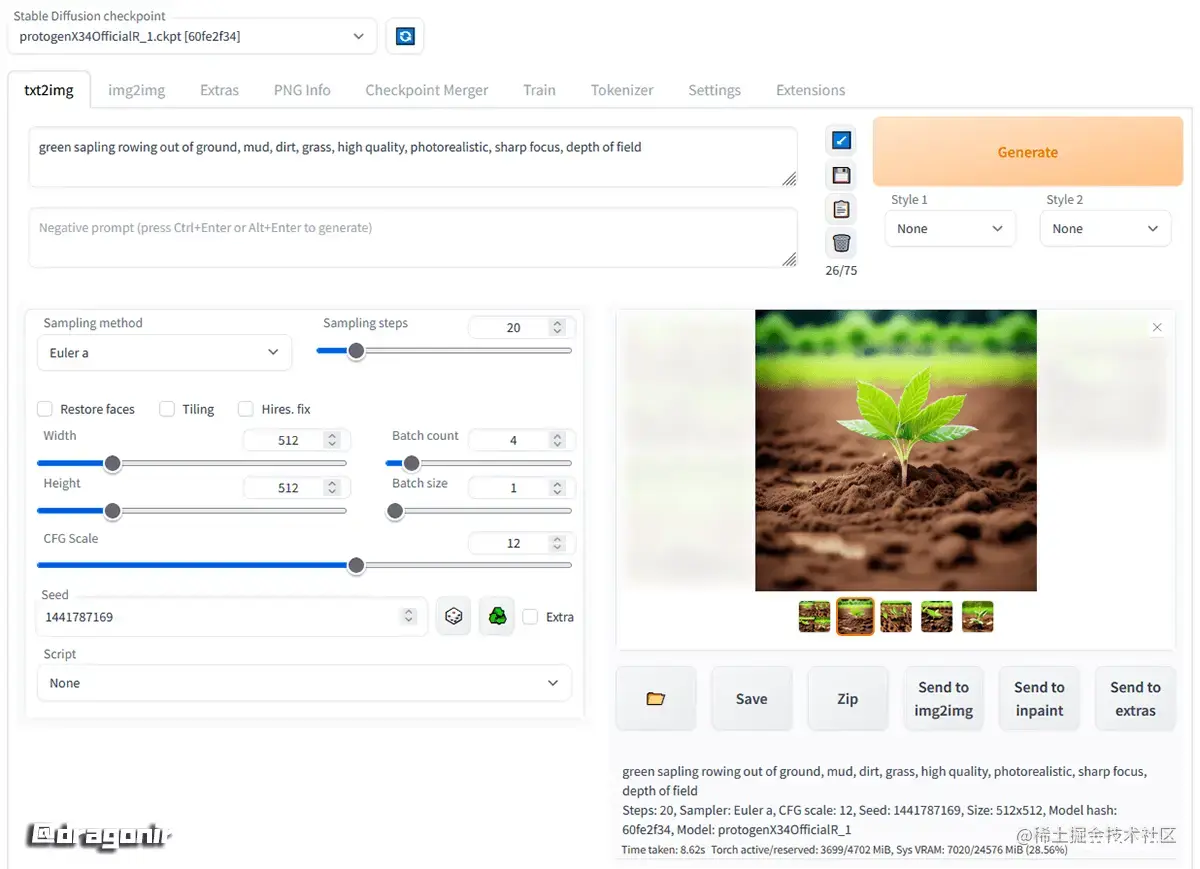
安装完成后,在 Windows操作系统中进入 stable-diffusion-webui 根目录,然后双击 webui-user.bat 文件即可开启本地运行服务,在浏览器中输入 http://localhost:7860 加载如下所示的界面。在 txt2img 输入框中输入需要生图图像的的正向关键词和反向关键词,点击 Generate 按钮即可生成图像。
完成基本安装后,还可以安装界面汉化插件、关键字中文翻译插件、自己喜欢的风格模型等,都可以按照教程非常容易实现。
开启 API 功能
在 stable-diffusion-webui 根目录下找到文件 webui-user.bat,使用编辑器打开这个文件,然后在 COMMANDLINE_ARGS 配置项后面添加 --api。
set COMMANDLINE_ARGS= --lowvram --precision full --api --listen
然后双击 webui-user.bat 重启服务,此时在浏览器中输入地址 https://localhost:7860/doc,就能看到如下所示的所有接口文档了,我们可以从文档中找到需要接入的接口及详细参数。

💡我们还可以配置如上所示的 --listen 参数,这样就可以通过局域网访问 stable-diffusion-webui 的接口了。
实现
文生图
文生图接口,可以通过向 stable-diffusion-webui 服务发送正向关键字、反向关键字、图片尺寸、采样步数等参数来调用AI能力生成图片。我们先来看看它有哪些可配置的 payload 参数选项。(暂时只用到后面写了注释的参数,基本上可以满足大部分文生图参数配置)

{ "enable_hr": false, // 开启高清hr "denoising_strength": 0, // 降噪强度 "hr_scale": 2, // 高清级别 "hr_upscaler": "string", "hr_second_pass_steps": 0, "hr_resize_x": 0, "hr_resize_y": 0, "hr_sampler_name": "string", "hr_prompt": "", "hr_negative_prompt": "", "prompt": "", // 正向关键字 "styles": [ "string" ], "seed": -1, // 随机种子 "subseed": -1, // 子级种子 "subseed_strength": 0, // 子级种子影响力度 "seed_resize_from_h": -1, "seed_resize_from_w": -1, "sampler_name": "string", "batch_size": 1, // 每次生成的张数 "n_iter": 1, // 生成批次 "steps": 50, // 生成步数 "cfg_scale": 7, // 关键词相关性 "width": 512, // 生成图像宽度 "height": 512, // 生成图像高度 "restore_faces": false, // 面部修复 "tiling": false, // 平铺 "do_not_save_samples": false, "do_not_save_grid": false, "negative_prompt": "string", // 反向关键字 "eta": 0, // 等待时间 "s_min_uncond": 0, "s_churn": 0, "s_tmax": 0, "s_tmin": 0, "s_noise": 1, "override_settings": {}, // 覆盖性配置 "override_settings_restore_afterwards": true, "script_args": [], // lora 模型参数配置 "sampler_index": "Euler", // 采样方法 "script_name": "string", "send_images": true, // 是否发送图像 "save_images": false, // 是否在服务端保存生成的图像 "alwayson_scripts": {} // alwayson配置}
根据需要的参数,在页面逻辑中,我们可以像下面这样实现,此时服务端会根据接口参数,一次生成4张对应的图。接口返回成功之后,我们会接收到一个包含所有图片数据名为 images 的数组,数组项是格式为 base64 的图片,我们可以向下面这样转化为页面上可直接显示的图片。
const response = await txt2img({ id_task: `task(${taskId})`, // 正向关键词 prompt: 'xxxx', // 反向关键词 negative_prompt: 'xxxx', // 随机种子 seed: 'xxxx', // 生成步数 steps: 7, // 关键词相关性 cfg_scale: 20, width: 1024, height: 1024, // 每次生成的张数 batch_size: 4, // 生成批次 n_iter: 1, // 采样方法 sampler_index: 'xxxx', // 采用的模型哈希值 sd_model_hash: 'xxxx', override_settings: { sd_model_checkpoint: sdModelCheckpoint, eta_noise_seed_delta: 0.0, CLIP_stop_at_last_layers: 1.0, },})if (response.status === 200 && response.data) { try { const images = response.data.images; if (images.length === 0) return; data.imageUrls = images.map(item => `data:image/png;base64,${item}`); } catch (err) {}}
生成效果就是本文 Banner 图中的粉色长头发的 3D 卡通风格小姐姐 ✨ ,正向关键字大致是 girl, long hair, pink,模型采用的是 3dAnimationDiffusion_v10,其他参数可自行调节。本文后续实例的图生图、图优化都将采用这张图作为参考图进行演示。

图生图
图生图接口,stable-diffusion-webui 将根据我们从接口传送的参考图,生成内容和风格类似的图片,就像最近抖音上很火的瞬息全宇宙特效一样,也可以将同一张图片通过选择不同模型转化为另一种画风。下面是图生图接口的详细 payload 参数,可以观察到基本上和文生图是一样的,多了一些与参考图片相关的配置,如 init_images。

{ "init_images": [ "string" ], "resize_mode": 0, "denoising_strength": 0.75, "image_cfg_scale": 0, "mask": "string", "mask_blur": 0, "mask_blur_x": 4, "mask_blur_y": 4, "inpainting_fill": 0, "inpaint_full_res": true, "inpaint_full_res_padding": 0, "inpainting_mask_invert": 0, "initial_noise_multiplier": 0, "prompt": "", "styles": [ "string" ], "seed": -1, "subseed": -1, "subseed_strength": 0, "seed_resize_from_h": -1, "seed_resize_from_w": -1, "sampler_name": "string", "batch_size": 1, "n_iter": 1, "steps": 50, "cfg_scale": 7, "width": 512, "height": 512, "restore_faces": false, "tiling": false, "do_not_save_samples": false, "do_not_save_grid": false, "negative_prompt": "string", "eta": 0, "s_min_uncond": 0, "s_churn": 0, "s_tmax": 0, "s_tmin": 0, "s_noise": 1, "override_settings": {}, "override_settings_restore_afterwards": true, "script_args": [], "sampler_index": "Euler", "include_init_images": false, "script_name": "string", "send_images": true, "save_images": false, "alwayson_scripts": {}}
在页面接口逻辑中,我们可以通过以下方法实现,其他参数和文生图都是一样的,我们只需要把参考图以 base64 格式添加到 init_images 数组即可。
const response = await img2img({ // 正向关键词 prompt: prompt, // 反向关键词 negative_prompt: negativePrompt, // 初始图像 init_images: [sourceImage.value], // 尺寸缩放 resize_mode: 0, // ...});
我们将文生图示例中的图片作为参考图,然后将大模型切换为 墨幽人造人_v1030,就能得到如下图所示的真人写实风格的图片。

局部重绘
图生图 API 还可以实现图片局部重绘、涂鸦、重绘蒙版、高清放大、图像扩充等效果。本文中,我们简单讲解以下如何实现局部重绘功能。
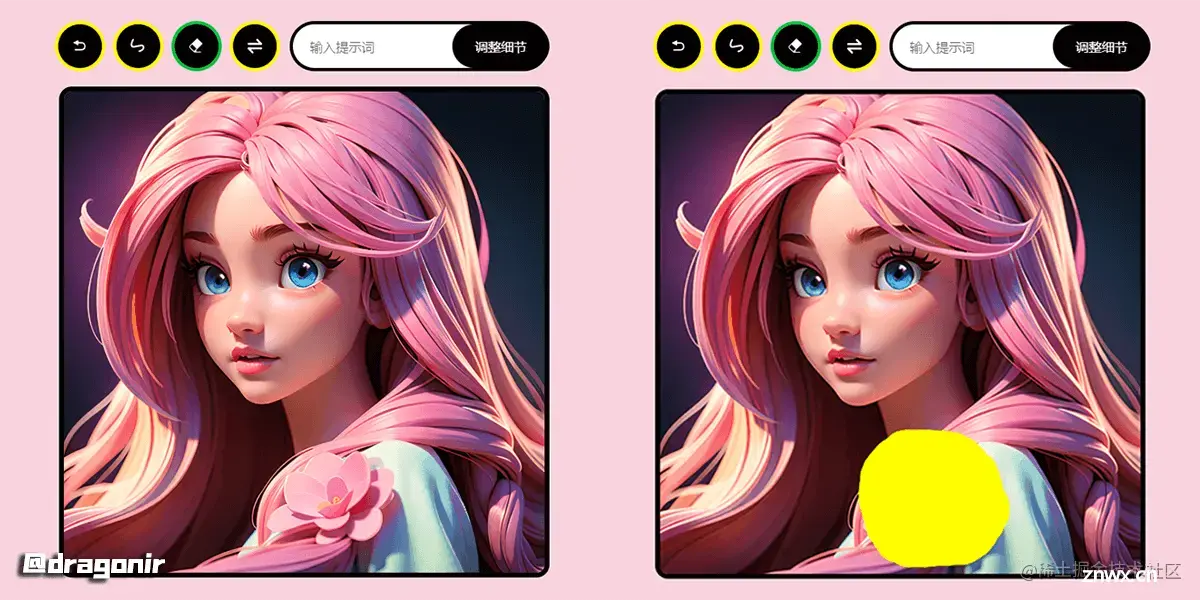
要实现局部重绘功能,首先我们需要使用 Canvas 创建一个画布,然后通过鼠标移动在画布上涂抹出需要重绘的路径,在实际开发时我们可以实现一个如下图所示的图片重绘编辑器,右侧图片黄色区域 🟨 是经过画笔涂抹需要重绘修改的区域。涂抹功能可以通过以下代码简单实现,像擦除、画笔大小颜色选择、撤销重做等扩展功能可自行搜索如何实现。
<div> <canvas id="canvas"></canvas> <img src="your_image.jpg" id="image"> <button onclick="clearMask()">清除遮罩</button></div><script>var canvas = document.getElementById('canvas');var image = document.getElementById('image');// 设置canvas宽高与图像尺寸相同canvas.width = image.width;canvas.height = image.height;var ctx = canvas.getContext('2d');var isDrawing = false; // 是否正在绘制var lastX = 0;var lastY = 0;// 鼠标按下事件处理程序canvas.addEventListener('mousedown', function(e) { isDrawing = true; [lastX, lastY] = [e.offsetX, e.offsetY];});// 鼠标移动事件处理程序canvas.addEventListener('mousemove', function(e) { if (!isDrawing) return; drawMask(e.offsetX, e.offsetY);});// 鼠标释放事件处理程序canvas.addEventListener('mouseup', function() { isDrawing = false;});// 绘制遮罩函数function drawMask(x, y) { ctx.beginPath(); ctx.moveTo(lastX, lastY); ctx.lineTo(x, y); ctx.strokeStyle = 'rgba(0, 0, 0, 1)'; // 设置遮罩颜色(黑色) ctx.lineWidth = 20; // 设置遮罩宽度 ctx.lineCap = 'round'; // 设置线条末端形状为圆形 ctx.stroke(); [lastX, lastY] = [x, y];}// 清除遮罩函数function clearMask() { ctx.clearRect(0, 0, canvas.width, canvas.height);}</script>
涂抹完成后,我们右键保存图片,可以得到如下图左侧所示的图片。但是 stable-diffusion-webui 需要的 Mask遮罩图是涂改区域为纯白色,非修改区域为黑色,且大小需要和原图一致,如右侧图片所示。此时就需要将得到的左侧透明遮罩层转换为右侧需要的遮罩层图片。

Canvas 遮罩层转换方法可以通过如下方式实现,绘制 Mask 图片,Canvas 使用鼠标绘制黑色图案,导出图片时需要把空白部分变为黑色,绘制线条的部分变为白色,并且需要转换成和原图相同的尺寸。其中两个参数 _canvas 是需要转换的画布,_image 是涂抹的原图。其中用于获取图像原始尺寸的方法 getImageOriginSize 可以在本文末尾方法汇总中查看
export const drawMask = async (_canvas, _image) => { return new Promise(async(resolve) => { const canvas = _canvas; const ctx = canvas.getContext('2d'); const imageData = ctx.getImageData(0, 0, canvas.clientWidth, canvas.clientHeight); const imageDataContent = imageData.data; // 修改图像数据中的像素颜色 for (let i = 0; i < imageDataContent.length; i += 4) { // 判断透明度是否小于阈值 if (imageDataContent[i + 3] < 128) { // 将透明部分设置为黑色 imageDataContent[i] = 0; imageDataContent[i + 1] = 0; imageDataContent[i + 2] = 0; imageDataContent[i + 3] = 255; } else { // 将线条部分设置为白色 imageDataContent[i] = 255; imageDataContent[i + 1] = 255; imageDataContent[i + 2] = 255; imageDataContent[i + 3] = 255; } } // 将修改后的图像数据导出为图片格式 const exportCanvas = document.createElement('canvas'); exportCanvas.width = canvas.clientWidth; exportCanvas.height = canvas.clientHeight; const exportCtx = exportCanvas.getContext('2d'); exportCtx.putImageData(imageData, 0, 0); // mask放大到和原图一致 const size = await getImageOriginSize(_image); const finalMask = await scaleImage(exportCanvas.toDataURL(), size.width, size.height); resolve(finalMask); });}
然后我们将转换后的遮罩图以 base64 的形式作为 mask 参数添加到接口参数中,添加一些正向关键字等参数进行图生图接口请求,返回结果和上述 API 都是一样的,最终就可以得到下面所示的图像,可以观察到被涂抹区域的花朵消失了 🌺。
const response = await img2img({ init_images: [sourceImage.value], mask: data.mask, // ...});

💡本文实现中将用到非常多关于图像转换的方法,,比如PNG转Base64、URL转Base64、Canvas转Base64等,这些方法的具体实现将放在文章末尾的汇总中。
后期处理
后期处理接口,可以实现图片高清放大、裁切、扩充等功能,有批量和单图调整两种接口,如下所示是单图调整接口。我们先来看看单图优化 API 可以接收的参数有哪些:

{ "resize_mode": 0, "show_extras_results": true, "gfpgan_visibility": 0, "codeformer_visibility": 0, "codeformer_weight": 0, "upscaling_resize": 2, "upscaling_resize_w": 512, "upscaling_resize_h": 512, "upscaling_crop": true, "upscaler_1": "None", "upscaler_2": "None", "extras_upscaler_2_visibility": 0, "upscale_first": false, "image": "" // 原图}

其他
更多接口
stable-diffusion-webui 还有许多实用的 API 可以调用,比如可以通过进度查询接口实时获取到生成图片的进度、剩余时间、排队状态等、可以通过配置查询接口获取到配置信息、已安装的模型列表等;反向推理接口可以通过已生成的图片反推出图像信息、描述关键字等。具体接口使用方法和参数都可以在 API 文档中查询。

实用方法
在做 Web 图片处理应用时需要用到很多图片相关的实用方法,以下是一些简单汇总。
① Canvas转Base64/PNG
要将 Canvas 转换为 Base64 格式图像数据,可以使用 Canvas 的 toDataURL() 方法。该方法将返回一个包含图像数据的字符串,其中包括图像的类型,如 image/png 和 Base64 编码的图像数据。
// 获取 Canvas 元素var canvas = document.getElementById("myCanvas");var ctx = canvas.getContext("2d");// 将 Canvas 转换为 Base64 格式的图像数据var dataURL = canvas.toDataURL();
② 图片URL转Base64
export const convertUrlToBase64 = src => { return new Promise(resolve => { const img = new Image() img.crossOrigin = '' img.src = src img.onload = function () { const canvas = document.createElement('canvas'); canvas.width = img.width; canvas.height = img.height; const ctx = canvas.getContext('2d'); ctx.drawImage(img, 0, 0, img.width, img.height); const ext = img.src.substring(img.src.lastIndexOf('.') + 1).toLowerCase(); const dataURL = canvas.toDataURL('image/' + ext); resolve(dataURL); } });};
③ Base64转PNG
export const convertBase64ToImage = src => { return new Promise((resolve) => { const arr = src.split(','); const byteString = atob(arr[1]); const ab = new ArrayBuffer(byteString.length); const ia = new Uint8Array(ab); for (let i = 0; i < byteString.length; i++) { ia[i] = byteString.charCodeAt(i); } const file = new File([ab], generateRandomId(), { type: 'image/png' }); resolve(file); });}
④ 获取图像原始尺寸
export const getImageOriginSize = (src) => { return new Promise((resolve) => { const image = new Image(); image.src = src; image.onload = () => { resolve({ width: image.naturalWidth, height: image.naturalHeight }); }; });}
⑤ 等比缩放Base64
export const scaleImage = (src, width, height) => { return new Promise((resolve) => { const image = new Image(); image.src = src; image.onload = () => { const canvas = document.createElement('canvas'); canvas.width = width; canvas.height = height; const ctx = canvas.getContext('2d'); ctx.drawImage(image, 0, 0, width, height); resolve(canvas.toDataURL()); }; })};
还有上述文章中提到的将透明彩色 Canvas 转化为 stable-diffusion-webui 局部重绘所需的黑底白色图案方法等。
总结
本文主要包含的知识点包括:
stable-diffusion-webui 的基本介绍stable-diffusion-webui 安装及 API 环境配置文生图、图生图、局部重绘、后期处理等 API 接口调用图像处理开发中常用到一些方法如 Base64、PNG、Canvas及 URL 相互转换、Canvas 颜色转换等
想了解其他前端知识或其他未在本文中详细描述的AI相关开发技术相关知识,可阅读我往期的文章。如果有疑问可以在评论中留言,如果觉得文章对你有帮助,不要忘了一键三连哦 👍。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
上一篇: web期末作业设计网页:动漫网站设计——千与千寻(10页) HTML+CSS+JavaScript 学生DW网页设计作业成品 动漫网页设计作业 web网页设计与开发 html实训大作业
下一篇: WebAuthn 无密码身份认证
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。