前端监控方案sentry整体概览
六点二十 2024-06-11 16:03:04 阅读 68
查看PDF
目 录
1. Sentry介绍
1.1. 编写目的
1.2. 名词定义
2. Sentry监控原理概述
2.1. 常见的性能优化指标及获取方式
2.2. 常见的前端异常及其捕获方式
3. Sentry 整体架构
4. Sentry安装部署
4.1. 前提条件
4.2. 安装
5. Sentry环境配置
5.1. 初始化配置
5.2. 应用服务配置
6. Sentry项目创建配置
6.1. 前端接入和使用
6.2. 域名解析配置示例
7. 常见问题解决
Sentry介绍
Sentry 是一套开源的实时的异常收集、追踪、监控系统。这套解决方案由对应各种语言的 SDK 和一套庞大的数据后台服务组成,通过 Sentry SDK 的配置,还可以上报错误关联的版本信息、发布环境。同时 Sentry SDK 会自动捕捉异常发生前的相关操作,便于后续异常追踪。异常数据上报到数据服务之后,会通过过滤、关键信息提取、归纳展示在数据后台的 Web 界面中。
编写目的
此文档主要为帮助运维人员了解Sentry系统的原理、架构、配置、运行和维护,以确保软件系统的稳定性和可靠性,为自动化运维相关工作实施提供依据。
名词定义
本文相关名词定义如下:
| 名称
| 说明
|
| FP
| first paint, 表示页面开始首次绘制的时间点,值越小约好。在 FP 时间点之前,用户看到的是导航之前的页面。
|
| FCP
| first contentful paint, lighthouse 面板的六大指标之一,表示首次绘制任何文本、图像、非空白 canvas 或者 SVG 的时间点,值越小约好。
|
| FMP
| first meaningful paint, 首次完成有意义内容绘制的时间点,值越小约好。
|
| SI
| speed index, 速度指标, lighthouse 面板中的六大指标之一,用于衡量页面加载期间内容的绘制速度,值越小约好。
|
| LCP
| lagest contentful paint, lighthouse 面板中的六大指标之一,完成最大内容绘制的时间点,值越小约好。
|
| TTI
| time to ineractive, 可交互时间, lighthouse 面板中的六大指标之一, 用于测量页面从开始加载到主要资源完成渲染,并能够快速、可靠地响应用户输入所需的时间, 值越小约好。
|
| TBT
| total blocking time,总的阻塞时间, lighthouse 面板中的六大指标之一,用于测量FCP到TTI之间的总的阻塞时间,值越小约好。
|
| FID
| first input delay, 首次输入延迟,测量从用户第一次与页面交互(例如当他们单击链接、点按按钮或使用由 JavaScript 驱动的自定义控件)直到浏览器对交互作出响应,并实际能够开始处理事件处理程序所经过的时间,指标的值越小约好。
|
| CLS
| Cumulative Layout Shift, 累积布局偏移,用于测量整个页面生命周期内发生的所有意外布局偏移中最大一连串的布局偏移情况,值越小,表示页面视觉越稳定。
|
| DSN
| Data Source Name , DSN告诉Sentry SDK 将事件发送到哪里,以便事件与正确的项目相关联。
|
实际在做性能分析时,上面列举的性能指标并不会全部使用。如果是本地通过 lighthouse 进行性能分析,会使用6大指标: FCP、LCP、SI、TTI、TBT、CLS。这些指标涵盖了页面渲染、交互和视觉稳定性情况。如果是通过 Sentry 等工具进行性能分析,会使用 4 大指标: FCP、LCP、FID、CLS。这些指标也涵盖了页面渲染、交互、视觉稳定性情况。
Sentry监控原理概述
衡量一个站点性能的好坏,我们通常看两个方面: 首屏性能和页面加载以后整个交互的流畅程度。这两个指标的好坏,决定了站点是否可以吸引用户和留住用户。为了能获得好的用户体验,我们常常需要对站点做性能优化。做性能优化,首先要对站点进行性能分析,寻找到底是哪个阶段性能较差,然后具体问题具体分析,找到对应的解决方案。最直接的方式是打开浏览器 performance、network、lighthouse 面板,然后对页面加载过程进行分析,这是一个有效的办法,但在实际使用时却存在非常大的局限性。也许,我们自己访问站点的时候性能很好,没有什么问题,但用户在实际访问时,由于设备、网络、使用姿势、使用人数、使用时间段、服务吞吐量等原因,整个体验很可能会没有达到我们的预期。这种情况下进行性能分析就非常麻烦了,首先我们无法感知,其次我们也无法在本地直接复现出用户的使用情形。
异常监控的核心作用就是通过上报的异常,帮开发人员及时发现线上问题并快速修复。要达到这个目的,异常监控需要做到以下 3 点: 线上应用出现异常时,可以及时推送给开发人员,安排相关人员去处理。上报的异常,含有异常类型、发生异常的源文件及行列信息、异常的追踪栈信息等详细信息,可以帮助开发人员快速定位问题。可以获取发生异常的用户行为,帮助开发人员、测试人员重现问题和测试回归。这三点,分别对应异常自动推送、异常详情获取、用户行为获取。
这个时候,我们可以借助监控工具来处理这个问题,如 Sentry这类工具,可以在用户访问站点时,将性能指标数据、异常详细信息通过接口上报给监控平台。监控平台接收到上报数据以后,对数据做汇总、计算,然后以可视化图表的方式展示。通过这些图表,我们就可以进行性能分析和快速定位问题,找到影响用户体验的因素或帮助开发人员、测试人员重现问题和测试回规,非常方便。
常见的性能优化指标及获取方式
做性能分析,不管是在本地,还是通过工具,最重要的是要有数据支撑。目前,w3c 对性能相关数据,已经有了详尽的分类标准和与之配套的获取方式。详细分析常用的性能优化指标以及获取指标数据的方式。页面加载过程模型如下图:

这个加载过程模型,是web性能工作组早在 2012 年就针对页面加载过程制定的,定义了从上一个页面结束,到下一个页面从开始加载到完成加载的整个过程。基于这个模型,我们可以获取到页面加载过程中各个阶段的耗时情况,然后分析出页面加载性能。
通过 window.performance.timing 这个接口获取加载过程模型中各个阶段的耗时数据:
var timing = window.performance.timing; // 返回数据格式 { navigationStart, // 同一个浏览器上下文中,上一个文档结束时的时间戳。如果没有上一个文档,这个值会和 fetchStart 相同。 unloadEventStart, // 上一个文档 unload 事件触发时的时间戳。如果没有上一个文档,为 0。 unloadEventEnd, // 上一个文档 unload 事件结束时的时间戳。如果没有上一个文档,为 0。 redirectStart, // 表示第一个 http 重定向开始时的时间戳。如果没有重定向或者有一个非同源的重定向,为 0。 redirectEnd, // 表示最后一个 http 重定向结束时的时间戳。如果没有重定向或者有一个非同源的重定向,为 0。 fetchStart, // 表示浏览器准备好使用 http 请求来获取文档的时间戳。这个时间点会在检查任何缓存之前。 domainLookupStart, // 域名查询开始的时间戳。如果使用了持久连接或者本地有缓存,这个值会和 fetchStart 相同。 domainLookupEnd, // 域名查询结束的时间戳。如果使用了持久连接或者本地有缓存,这个值会和 fetchStart 相同。 connectStart, // http 请求向服务器发送连接请求时的时间戳。如果使用了持久连接,这个值会和 fetchStart 相同。 connectEnd, // 浏览器和服务器之前建立连接的时间戳,所有握手和认证过程全部结束。如果使用了持久连接,这个值会和 fetchStart 相同。 secureConnectionStart, // 浏览器与服务器开始安全链接的握手时的时间戳。如果当前网页不要求安全连接,返回 0。 requestStart, // 浏览器向服务器发起 http 请求(或者读取本地缓存)时的时间戳,即获取 html 文档。 responseStart, // 浏览器从服务器接收到第一个字节时的时间戳。 responseEnd, // 浏览器从服务器接受到最后一个字节时的时间戳。 domLoading, // dom 结构开始解析的时间戳,document.readyState 的值为 loading。 domInteractive, // dom 结构解析结束,开始加载内嵌资源的时间戳,document.readyState 的状态为 interactive。 domContentLoadedEventStart, // DOMContentLoaded 事件触发时的时间戳,所有需要执行的脚本执行完毕。 domContentLoadedEventEnd, // DOMContentLoaded 事件结束时的时间戳 domComplete, // dom 文档完成解析的时间戳, document.readyState 的值为 complete。 loadEventStart, // load 事件触发的时间。 loadEventEnd // load 时间结束时的时间。 }
window.performance.timing 已被废弃,改用 window.performance.getEntriesByType('navigation')。window.performance.timing,返回的是一个 UNIX 类型的绝对时间,和用户的系统时间相关,分析的时候需要再次计算。而新的 api,返回的是一个相对时间,可以直接用来分析,非常方便。
页面何时开始渲染 - FP & FCP
FP, first paint, 表示页面开始首次绘制的时间点,值越小约好。在FP时间点之前,用户看到的是导航之前的页面。
FCP, first contentful paint, lighthouse 面板的六大指标之一,表示首次绘制任何文本、图像、非空白canvas或者SVG的时间点,值越小约好。
指标可以通过以下接口performance.getEntry、performance.getEntriesByName、performanceObserver 来获取示例如下:
performance.getEntries().filter(item => item.name === 'first-paint')[0]; // 获取 FP 时间 performance.getEntries().filter(item => item.name === 'first-contentful-paint')[0]; // 获取 FCP 时间 performance.getEntriesByName('first-paint'); // 获取 FP 时间 performance.getEntriesByName('first-contentful-paint'); // 获取 FCP 时间 // 也可以通过 performanceObserver 的方式获取 var observer = new PerformanceObserver(function(list, obj) { var entries = list.getEntries(); entries.forEach(item => { if (item.name === 'first-paint') { ... } if (item.name === 'first-contentful-paint') { ... } }) }); observer.observe({type: 'paint'}); 页面何时渲染主要内容 - FMP & SI & LCP
FMP, first meaningful paint, 首次完成有意义内容绘制的时间点,值越小约好。
SI, speed index, 速度指标, lighthouse 面板中的六大指标之一,用于衡量页面加载期间内容的绘制速度,值越小约好。
LCP, lagest contentful paint, lighthouse 面板中的六大指标之一,完成最大内容绘制的时间点,值越小约好。
FMP,是一个已经废弃的性能指标。在实践过程中,由于FMP对页面加载的微小差异过于敏感,经常会出现结果不一致的情况,因此性能分析的时候不再使用这个指标。
SI和FMP一样,官方也没有提供有效的获取接口,只能通过lighthouse面板来查看,不作为Sentry 等工具做性能分析的指标。
通过 performanceObserver 这个接口,我们可以获取到 LCP 指标数据:
new PerformanceObserver((entryList) => { for (const entry of entryList.getEntries()) { console.log('LCP candidate:', entry.startTime, entry); } }).observe({type: 'largest-contentful-paint', buffered: true}); 何时可以交互 - TTI & TBT
衡量页面何时可以交互,有两个指标: TTI 和 TBT。
TTI, time to ineractive, 可交互时间, lighthouse 面板中的六大指标之一, 用于测量页面从开始加载到主要资源完成渲染,并能够快速、可靠地响应用户输入所需的时间, 值越小约好。
和 FMP、SI 一样,官方并没有提供获取 TTI 的有效接口,只能通过 lighthouse 面板来查看,不会作为 Sentry 做性能分析的指标。
TBT, total blocking time, 总的阻塞时间, lighthouse 面板中的六大指标之一,用于测量 FCP 到 TTI 之间的总的阻塞时间,值越小约好。和 TTI 一样,官方也没有提供获取 TBT 的有效接口,只能通过 lighthouse 面板来查看,不会作为 Sentry 做性能分析的指标。
交互是否有延迟 - FID & MPFID & Long Task
衡量交互是否有延迟,有3个指标: FID、MPFID、Long Task。其中,FID和MPFID可用来衡量用户首次交互延迟的情况,Long Task用来衡量用户在使用应用的过程中遇到的延迟、阻塞情况。
FID, first input delay, 首次输入延迟,测量从用户第一次与页面交互(例如当他们单击链接、点按按钮或使用由 JavaScript 驱动的自定义控件)直到浏览器对交互作出响应,并实际能够开始处理事件处理程序所经过的时间。FID 指标的值越小约好。
MPFID, Max Potential First Input Delay,最大潜在首次输入延迟,用于测量用户可能遇到的最坏情况的首次输入延迟。和FMP一样,这个指标已经被废弃不再使用。
Long Task,衡量用户在使用过程中遇到的交互延迟、阻塞情况。这个指标,可以告诉我们哪些任务执行耗费了 50ms 或更多时间。
通过 performanceObserver,我们可以获取到 FID 指标数据示例如下:
new PerformanceObserver((entryList) => { for (const entry of entryList.getEntries()) { const delay = entry.processingStart - entry.startTime; console.log('FID candidate:', delay, entry); } }).observe({type: 'first-input', buffered: true}); 页面视觉是否有稳定 - CLS
衡量页面视觉是否稳定,有 1 个指标: CLS
CLS, Cumulative Layout Shift, 累积布局偏移,用于测量整个页面生命周期内发生的所有意外布局偏移中最大一连串的布局偏移情况。CLS, 值越小,表示页面视觉越稳定。
通过 performanceObserver,我们可以获取到 CLS 指标数据示例如下:
new PerformanceObserver(function(list) { var perfEntries = list.getEntries(); for (var i = 0; i < perfEntries.length; i++) { ... } })observe({type: 'layout-shift', buffered: true});
Sentry性能监控原理
简单来说,就是通过 window.performance.getEntries 和 performanceObserver 这两个 api,获取用户在使用应用过程中涉及的 load 相关、fcp、lcp、fid、cls 等指标数据,然后通过接口上报。监控平台拿到数据以后,通过可视化图标的方式展示性能指标数据,帮助我们分析。
常见的前端异常及其捕获方式JS代码执行时异常
js代码执行异常,是最常遇到的异常。这一类型的异常,又可以具体细分为:Error,最基本的错误类型,其他的错误类型都继承自该类型。
RangeError: 范围错误。当出现堆栈溢出(递归没有终止条件)、数值超出范围(new Array 传入负数或者一个特别大的整数)情况时会抛出这个异常。ReferenceError,引用错误。当一个不存在的对象被引用时发生的异常。SyntaxError,语法错误。如变量以数字开头;花括号没有闭合等。TypeError,类型错误。如把 number 当 str 使用。URIError,向全局 URI 处理函数传递一个不合法的 URI 时,就会抛出这个异常。如使用decodeURI('%')、decodeURIComponent('%')。EvalError, 一个关于 eval 的异常,不会被 javascript 抛出。
通常,我们会通过 try...catch 语句块来捕获这一类型异常。如果不使用 try...catch,我们也可以通过 window.onerror = callback 或者 window.addEventListener('error', callback) 的方式进行全局捕获。
Promise类型异常
在使用promise时,如果promise被reject但没有做catch处理时,就会抛出promise类异常。
Promise.reject(); // Uncaught (in promise) undefined
promise 类型的异常无法被 try...catch 捕获,也无法被 window.onerror = callback 或者 window.addEventListener('error', callback) 的方式全局捕获。针对这一类型的异常, 我们需要通过window.onrejectionhandled = callback 或者 window.addListener('rejectionhandled', callback) 的方式去全局捕获。
资源加载类型异常
如果我们页面的img、js、css 等资源链接失效,就会提示资源类型加载如异常。如果我们页面的img、js、css 等资源链接失效,就会提示资源类型加载如异常。
<img src="localhost:3000/data.png" /> // Get localhost:3000/data.png net::ERR_FILE_NOT_FOUND
针对这一类的异常,我们可以通过 window.addEventListener('error', callback, true) 的方式进行全局捕获,使用window.onerror = callback的方式是无法捕获静态资源类异常的。原因是资源类型错误没有冒泡,只能在捕获阶段捕获,而window.onerror是通过在冒泡阶段捕获错误,对静态资源加载类型异常无效,所以只能借助 window.addEventListener('error', callback, true) 的方式捕获。
接口请求类型异常
在浏览器端发起一个接口请求时,如果请求的 url 的有问题,也会抛出异常。
不同的请求方式,异常捕获方式也不相同:
接口调用是通过 fetch 发起的
我们可以通过 fetch(url).then(callback).catch(callback) 的方式去捕获异常。
接口调用通过 xhr 实例发起
如果是 xhr.open 方法执行时出现异常,可以通过 window.addEventListener('error', callback) 或者 window.onerror 的方式捕获异常。
xhr.open('GET', "https://") // Uncaught DOMException: Failed to execute 'open' on 'XMLHttpRequest': Invalid URL at ....
如果是 xhr.send 方法执行时出现异常,可以通过 xhr.onerror 或者 xhr.addEventListener('error', callback) 的方式捕获异常。
xhr.open('get', '/user/userInfo'); xhr.send(); // send localhost:3000/user/userinfo net::ERR_FAILED 跨域脚本执行异常
当项目中引用的第三方脚本执行发生错误时,会抛出一类特殊的异常。这类型异常和之前讲过的异常都不同,它的msg只有 'Script error' 信息,没有具体的行、列、类型信息。之以会这样,是因为浏览器的安全机制: 浏览器只允许同域下的脚本捕获具体异常信息,跨域脚本中的异常,不会报告错误的细节。针对这类型的异常,我们可以通过 window.addEventListener('error', callback) 或者 window.onerror 的方式捕获异常。
如果我们想获取这类异常的详情,需要做以下两个操作:
在发起请求的 script 标签上添加 crossorigin="anonymous"请求响应头中添加 Access-Control-Allow-Origin: *
这样就可以获取到跨域异常的细节信息了。
Sentry异常监控原理
为了能自动捕获应用异常,Sentry劫持覆写了window.onerror和window.unhandledrejection这两个api。劫持覆写 window.onerror 的代码如下:
oldErrorHandler = window.onerror; window.onerror = function (msg, url, line, column, error) { // 收集异常信息并上报 triggerHandlers('error', { column: column, error: error, line: line, msg: msg, url: url, }); if (oldErrorHandler) { return oldErrorHandler.apply(this, arguments); } return false; };
劫持覆写 window.unhandledrejection 的代码如下:
oldOnUnhandledRejectionHandler = window.onunhandledrejection; window.onunhandledrejection = function (e) { // 收集异常信息并上报 triggerHandlers('unhandledrejection', e); if (oldOnUnhandledRejectionHandler) { return oldOnUnhandledRejectionHandler.apply(this, arguments); } return true; };
虽然通过劫持覆写 window.onerror和window.unhandledrejection已足以完成异常自动捕获,但为了能获取更详尽的异常信息, Sentry 在内部做了一些更细微的异常捕获。具体来说,就是 Sentry 内部对异常发生的特殊上下文,做了标记。这些特殊上下文包括: dom节点事件回调、setTimeout / setInterval 回调、xhr 接口调用、requestAnimationFrame 回调等。举个例子,如果是click事件的handler中发生了异常, Sentry会捕获这个异常,并将异常发生时的事件name、dom节点描述、handler函数名等信息上报。
Sentry 整体架构
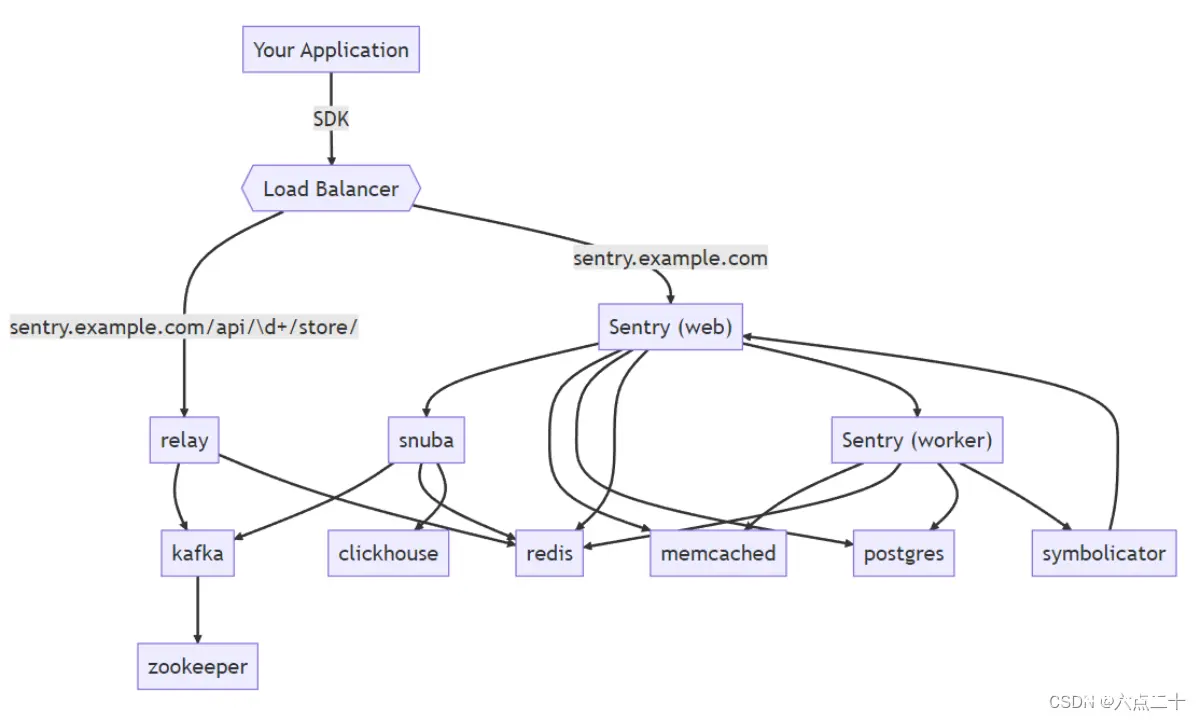
从上到下:
第一层 Load Balancer(负载均衡器)负责路由转发。错误上报转发到 /api/\d+/store 。这一层承担数据入口。 第二层 Sentry Web主要跟配置等持久化数据打交道,创建项目、权限控制、限流分配等都是它负责。查询搜索错误消息、Dashboard 聚合等功能则是 Snuba 承担,由它来当翻译官,把用户查询条件转化为 SQL 语句发给 ClickHouse。 第三层 Relay 负责消息中继转发,并把数据先汇集到 Kafka。Snuba 负责接收 SentryWeb 的请求,进行数据的聚合、搜索。Sentry Worker 则是一个队列服务,主要负责数据的存储。 第四层 Kafka 作为消息队列。ClickHouse 负责实时的数据分析。Redis 和 Memcached 负责项目配置、错误基础信息的存储和统计。Postgres 承担基础数据持久化(主要是项目、用户权限管理等)。Symbolicator 主要用于错误信息格式化。 第五层 最底下的 Zookeeper 是 Kafka 用于节点信息同步,如果我们设置了多个 ClickHouse 节点,也可以用它来保存主从同步信息或者做分布式表。 Sentry安装部署
Sentry 的管理后台是基于 Python Django 开发的。这个管理后台由背后的 Postgres 数据库(管理后台默认的数据库)、ClickHouse(存数据特征的数据库)、relay、kafka、redis 等一些基础服务或由 Sentry 官方维护的总共 23 个服务支撑运行。可见的是,如果独立的部署和维护这 23 个服务将是异常复杂和困难的。幸运的是,官方提供了基于 docker 镜像的一键部署实现。具体落地方案可将sentry应用单机单节点部署在某一台独立服务器上,保证各环境数据上报网络通畅即可,具体环境和项目可以通过设置合理规范的前缀名区分,重要项目数据需要设置定时备份策略。
前提条件
部署 Sentry的实例要求最低配置如下:
Docker 19.03.6+Docker-Compose 1.28.0+4 CPU Cores8 GB RAM20 GB Free Disk Space
示例操作系统:Debian 10.3
安装
第1步 - 安装docker
准备docker.service系统配置文件
touch /opt/docker.service
vi /opt/docker.service
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify # the default is not to use systemd for cgroups because the delegate issues still # exists and systemd currently does not support the cgroup feature set required # for containers run by docker ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Uncomment TasksMax if your systemd version supports it. # Only systemd 226 and above support this version. #TasksMax=infinity TimeoutStartSec=0 # set delegate yes so that systemd does not reset the cgroups of docker containers Delegate=yes # kill only the docker process, not all processes in the cgroup KillMode=process # restart the docker process if it exits prematurely Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target
编写并执行安装shell脚本:
#.1.enable-ip-forward sudo sed -i 's/^net.ipv4.ip_forward.*/net.ipv4.ip_forward=1/g' /etc/sysctl.conf sudo cat /etc/sysctl.conf | grep "^net.ipv4.ip_forward" > /dev/null || echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf sudo /sbin/sysctl -p /etc/sysctl.conf #.2.setup-docker-ce sudo curl -L https://download.docker.com/linux/static/stable/x86_64/docker-20.10.8.tgz -o /opt/docker-20.10.8.tgz sudo tar -xvf /opt/docker-20.10.8.tgz --directory=/opt/ sudo mv /opt/docker/* /usr/bin/ sudo mv /opt/docker.service /etc/systemd/system/ sudo rm -rf /opt/docker sudo chmod +x /etc/systemd/system/docker.service sudo systemctl daemon-reload sudo systemctl start docker sudo systemctl is-active docker #.3.set-on-start sudo systemctl enable docker sudo systemctl is-enabled docker ################################################################# #.4.do-it-again # systemctl stop docker # systemctl disable docker.service # rm -rf /opt/{docker,docker.service} # rm -f /etc/systemd/system/docker.service # rm -f /usr/bin/{docker*,containerd*,ctr,runc}
第2步 - 安装docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/bin/docker-compose sudo docker-compose --version第3步 - 安装sentry
#将一键部署项目onpremise的源代码克隆到工作台目录mkdir -p /data/app/ && cd /data/app/git clone GitHub - getsentry/self-hosted: Sentry, feature-complete and packaged up for low-volume deployments and proofs-of-conceptonpremise部署主要文件结构和作用:
clickhouse/config.xml:clickhouse 配置文件
cron/:定时任务的镜像构建配置和启动脚本
nginx/nginx.conf:nginx 配置
relay/config.example.yml:relay 服务配置文件
sentry/:sentry-onpremise-local镜像的构建和基于此镜像启动的主服务的配置都在这个文件夹下
Dockerfile:sentry-onpremise-local 的镜像构建配置,会以此启动很多服务requirements.example.txt:由此生成 requirements.txt,需要额外安装的 Django 插件需要被写在这里面config.example.yml:由此生成 config.yml,一般放运行时不能通过管理后台修改的配置sentry.conf.example.py:由此生成 sentry.conf.py,为 python 代码,覆盖或合并至 sentry 服务中,从而影响 sentry 运行。
.env:镜像版本、数据保留天数、端口等配置
docker-compose.yml:Compose工具配置,多docker的批量配置和启动设置
install.sh:Sentry 一键部署流程脚本
执行一键部署脚本:
cd onpremise # 直接运行 ./install.sh 将 Sentry 及其依赖都通过 docker 安装 ./install.sh
执行onpremise的根路径下install.sh此即可完成快速部署,脚本运行的过程中,大致会经历以下步骤:
环境检查生成服务配置docker volume 数据卷创建(可理解为 docker 运行的应用的数据存储路径的创建)拉取和升级基础镜像构建镜像服务初始化设置管理员账号(如果跳过此步,可手动创建)
在执行结束后,会提示创建完毕,运行 docker-compose up -d 启动服务

删除服务:
# 停止所有运行 docker-compose down # 移除所有 volume docker volume prune
重启服务:
# 关闭服务 docker-compose down # 启动服务 docker-compose up -d
Sentry环境配置 初始化配置
第一次访问管理后台,可以看到欢迎页面,完成必填项的配置,即可正式访问管理后台。
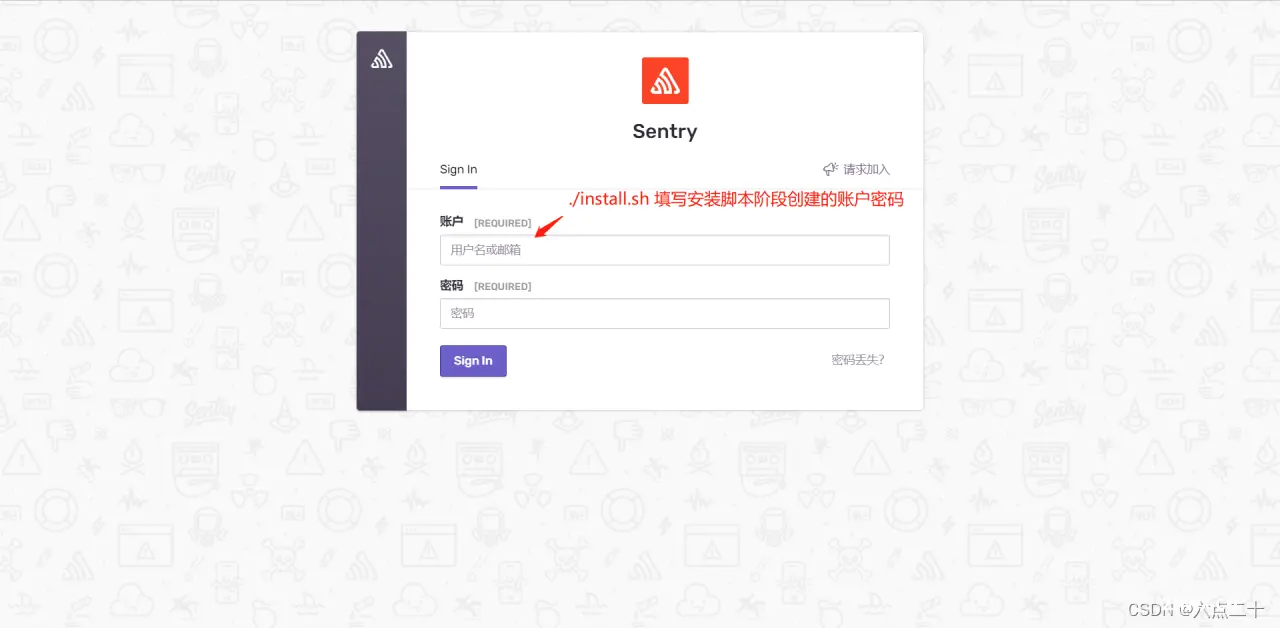

Root URL:异常上报接口的公网根地址(在做网络解析配置时,后台服务可以配置到内网外网两个域名,只将上报接口的解析规则 /api/[id]/store/ 配置到公网环境,保证数据不会泄密)。Admin Email:在 install.sh 阶段创建的管理员账号。
Outbound email:这部分内容为邮件服务配置,可以先不配置。设置语言和时区
Sentry部署成功之后,我们可以进行一些设置。点击头像【User settings】 -【 Account Details】来设置语言何时区等

应用服务配置
一键部署的 Sentry 服务总会有不符合我们使用和维护设计的地方,需要通过对部署配置的修改来满足自己的需求。
Docker数据存储位置修改
在服务运行的过程中,会在docker volume数据卷挂载位置存储数据,如Postgres、运行日志等,docker volume默认挂载在/var目录下,如果你的/var目录容量较小,随着服务的运行会很快占满,需要对docker volume挂载目录进行修改。
# 在容量最大的目录下创建文件夹 mkdir -p /data/var/lib/ # 停止 docker 服务 systemctl stop docker # 将 docker 的默认数据复制到新路径下,删除旧数据并创建软连接,即使得存储实际占用磁盘为新路径 /bin/cp -a /var/lib/docker /data/var/lib/docker && rm -rf /var/lib/docker && ln -s /data/var/lib/docker /var/lib/docker # 重启 docker 服务 systemctl start docker 使用独立数据库确保数据稳定性
在数据库单机化部署的情况下,一旦出现机器故障,数据会损坏丢失,而onpremise的一键部署就是以 docker的形式单机运行的数据库服务,且数据库数据也存储在本地。可以看到 Sentry 的数据库有两个,Postgres和ClickHouse。虽然Sentry不是业务应用,在宕机后不影响业务正常运行,数据的稳定并不是特别重要,但是Postgres中存储了接入Sentry的业务应用的id和token与对应关系,在这些数据丢失后,业务应用必须要修改代码以修改 token 重新上线。为了避免这种影响,且公司有现成的可容灾和定期备份的Postgres数据库,所以将数据库切换为外部数据库。
修改 sentry.conf.example.py 文件中 DATABASES 变量即可:
DATABASES = { 'default': { 'ENGINE': 'sentry.db.postgres', 'NAME': '数据库名', 'USER': '数据库用户名', 'PASSWORD': '数据库密码', 'HOST': '数据库域名', 'PORT': '数据库端口号', } }
将Postgres相关信息从docker-compose.yml文件中删除:
depends_on: - redis - postgres # 删除 # ... services: # ... # 删除开始 postgres: << : *restart_policy image: 'postgres:14.5' environment: POSTGRES_HOST_AUTH_METHOD: 'trust' volumes: - 'sentry-postgres:/var/lib/postgresql/data' # 删除结束 # ... volumes: sentry-data: external: true sentry-postgres: # 删除 external: true # 删除 控制磁盘占用
随着数据的上报,服务器本地的磁盘占用和数据库大小会越来越大,按照 Sentry 定时数据任务的配置保留90天来说,全量接入后磁盘占用会维持在一个比较大的值,同时这么大的数据量对数据的查询也是一个负担。为了减轻负担,需要从服务端和业务应用端同时入手。根据实际情况可以将数据保留时长改为30天或者7天等更短时长。
修改 .env 文件: SENTRY_EVENT_RETENTION_DAYS=7 手动清除 # 因为cleanup的使用delete命令删除postgresql数据,但postgrdsql对于 delete, update等操作,只是将对应行标志为DEAD,并没有真正释放磁盘空间。 # 清除 postgres 中的无效数据 vacuumdb -U postgres -d postgres -v -f --analyze 定期清除 crontab -e # 使用 crontab 在linux实现定时任务 # 输入 0 0 * * * vacuumdb -U postgres -d postgres -v -f --analyze Sentry项目创建配置 前端接入和使用
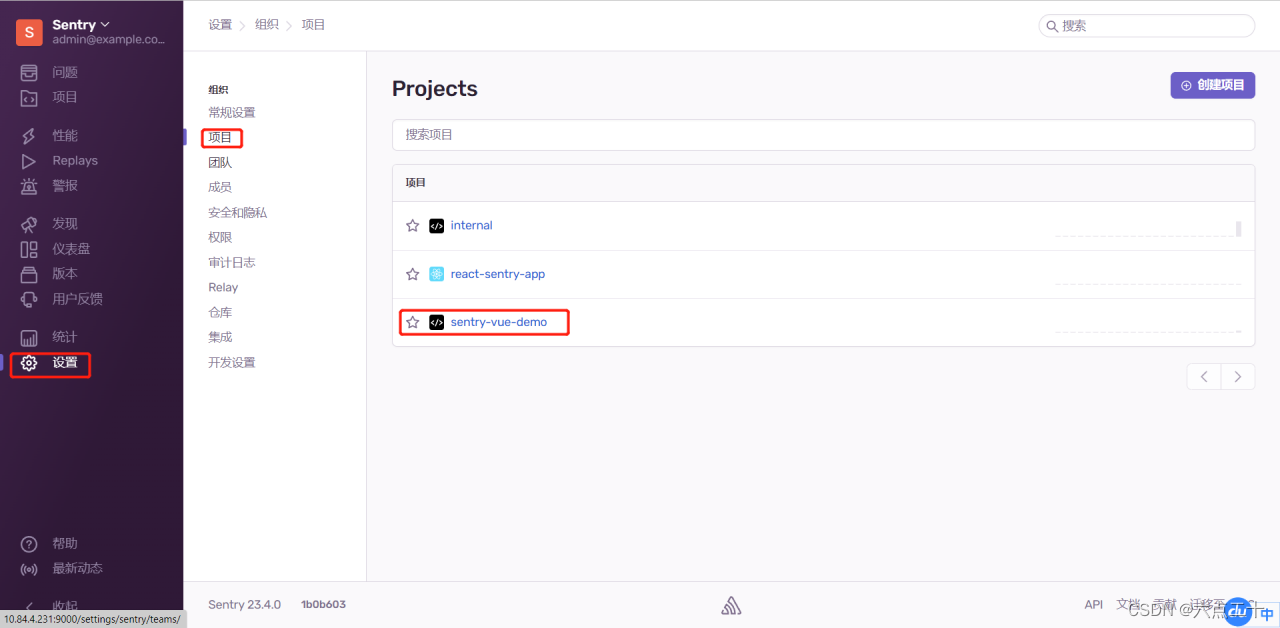
Sentry中项目接入的类型有很多,以Vue 项目示范:
创建对应团队和项目

选取平台语言创建团队和项目
接入sentry npm i @vue/cli -g # 初始化vue3项目 vue create vue3-sentry # 安装sentry插件 npm install --save @sentry/vue @sentry/tracing 查看当前项目绑定的 DSN(客户端秘钥)
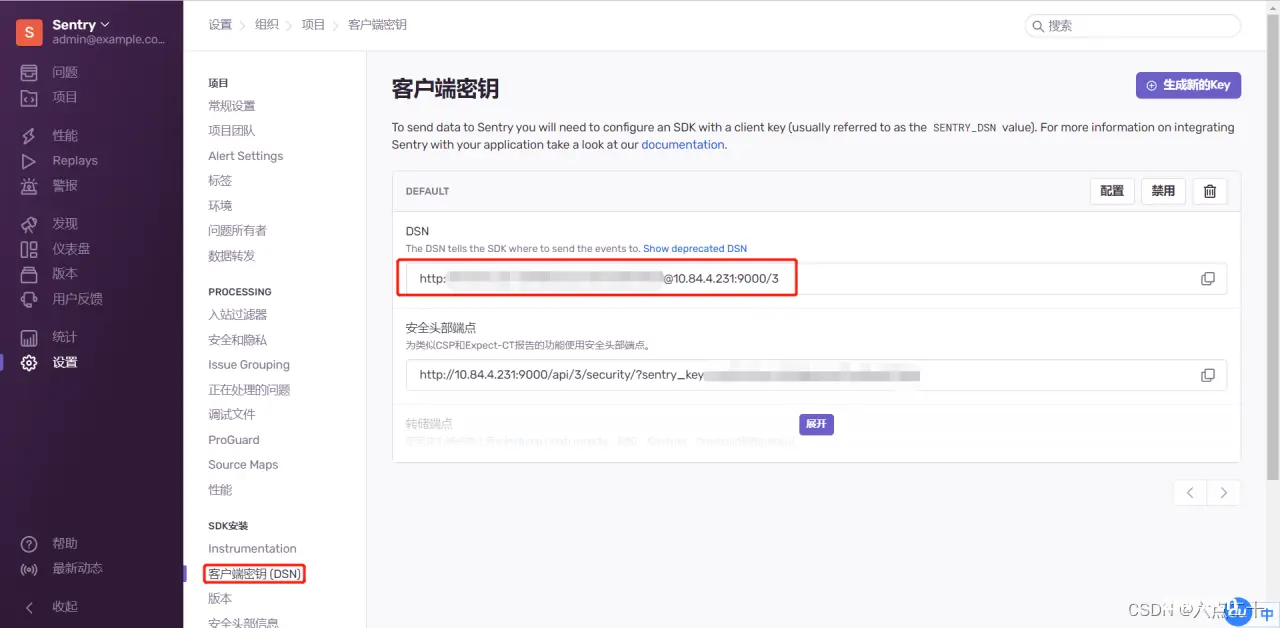
在入口文件main.js中初始化sentry import { createApp } from "vue"; import { createRouter } from "vue-router"; import * as Sentry from "@sentry/vue"; import { Integrations } from "@sentry/tracing"; const app = createApp({ // ... }); const router = createRouter({ // ... }); Sentry.init({ app, dsn: "http://61a3c1c2ac124286ae2a13e0bd0f3824@10.84.4.231:9000/3", integrations: [ new Integrations.BrowserTracing({ routingInstrumentation: Sentry.vueRouterInstrumentation(router), tracingOrigins: ["localhost", "my-site-url.com", /^\//], }), ], // Set tracesSampleRate to 1.0 to capture 100% // of transactions for performance monitoring. // We recommend adjusting this value in production tracesSampleRate: 1.0, }); app.use(router); app.mount("#app"); 手动模拟一个异常sentry控制台捕获错误 // ... <button @click="throwError">Throw error</button> // ... export default { // ... methods: { throwError() { throw new Error('Sentry Error'); } } }; 其他的功能,如报警配置、性能监控可以自行探索 域名解析配置示例
Nginx域名配置模板
upstream track-web { server ip:9000; keepalive 300; } server { listen 80; server_name track.reckfeng.com; access_log /data/logs/nginx/external/track.reckfeng.com/track.reckfeng.com.access.log.$log_date main; error_log /data/logs/nginx/external/track.reckfeng.com/track.reckfeng.com.error.log error; set $upstream 'track-web'; set $allow false; if ($http_x_forwarded_for ~* ^(101.227.90.131|101.227.90.132|211.144.205.2|101.227.90.208|223.252.222.16|101.37.117.138)) { set $allow true; } if ($allow = false) { return 403;} location / { proxy_set_header Connection ""; proxy_http_version 1.1; proxy_set_header Host $host; proxy_set_header X-real-ip $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://$upstream; } } 常见问题解决 在开发机管理平台上申请的服务器安装sentry提示访问http://deb.debian.org/debian超时
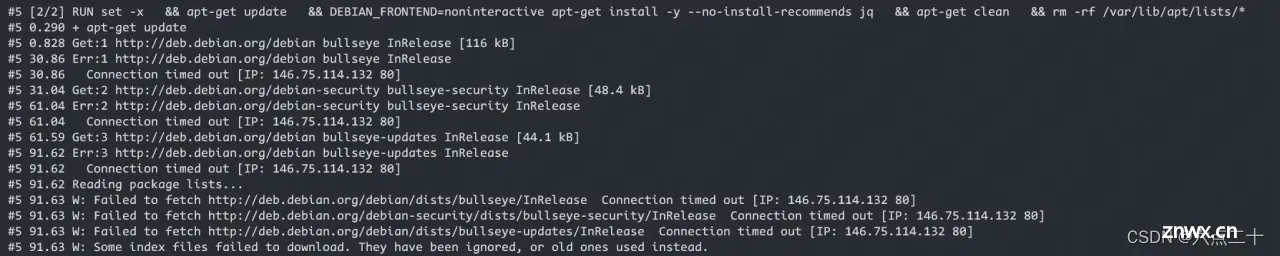
详细信息显示为执行dockerfile构建容器时在基础镜像上执行apt-get update更新失败

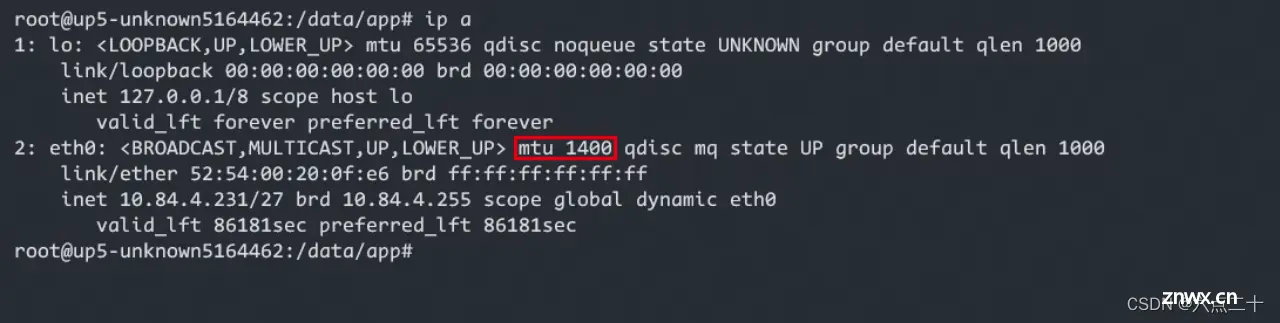
一般这种问题原因要么是出口ip不在公司白名单里,要么是网络不太对,比如mtu这些有点问题,ip不再白名单需要找it协助,针对原因二需要做以下修改来解决:
执行ip a查看本机eth0网卡mtu值

按下图提示修改相关配置重启docker后重新执行install.sh脚本
若未安装ifconfig可用以下命令代替
ip link set docker0 mtu 1400
参考文档:
OneTab - Shared tabs
上一篇: 全网最全stable diffusion webui API调用示例,包含controlneth和segment anything的API(附json示例)
下一篇: Web前端最全太厉害了!前端大牛熬夜把JavaScript面试题整理成了PDF文档,2024年最新我总结了24家大厂100份面试题英语翻译
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。