ubuntu基于sealos搭建k8s集群,helm3安装配置自动化扩容Prometheus,grafana出图展示,以及动态web搭建
CSDN 2024-09-11 13:33:01 阅读 77
1.项目简介
大方向:k8s云原生方向,运维技术,配置问题解决
解决技术:ubuntu模板机安装,配置远程xshell连接ubuntu,设置静态ip,换ubuntu阿里云源,配置集群间域名解析,解决双IP冲突网络配置文件冲突问题,sealos安装与自动化配置k8s集群,sealos加入节点操作,nerdctl安装与配置以及优缺点,Dashboard安装pod,Prometheus监控安装pod,解决node镜像丢失问题,配置nfs网络文件系统实现自动化扩容(Prometheus与Grafana),服务外发操作,k8s动态网站部署以及遇到的问题。
2.模板机安装
2.1 安装ubuntu模板机
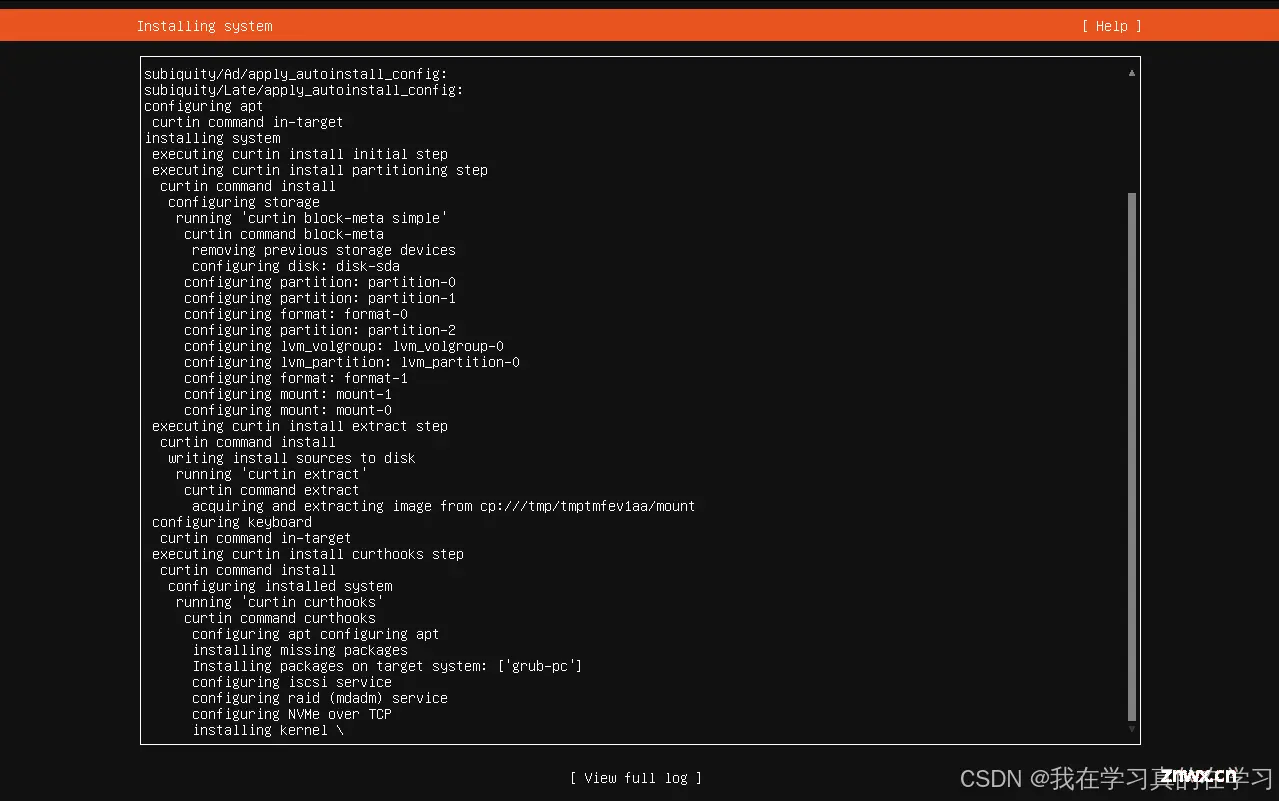
选用ubuntu24.04镜像制作模板机,配置里面面板选择最小化安装命令行页面,打开SSH连接,其余一概直接continue即可。等待最后一步安装完成,直到出现reboot now,进行重启。
2.2 查看ip add使用xshell连接
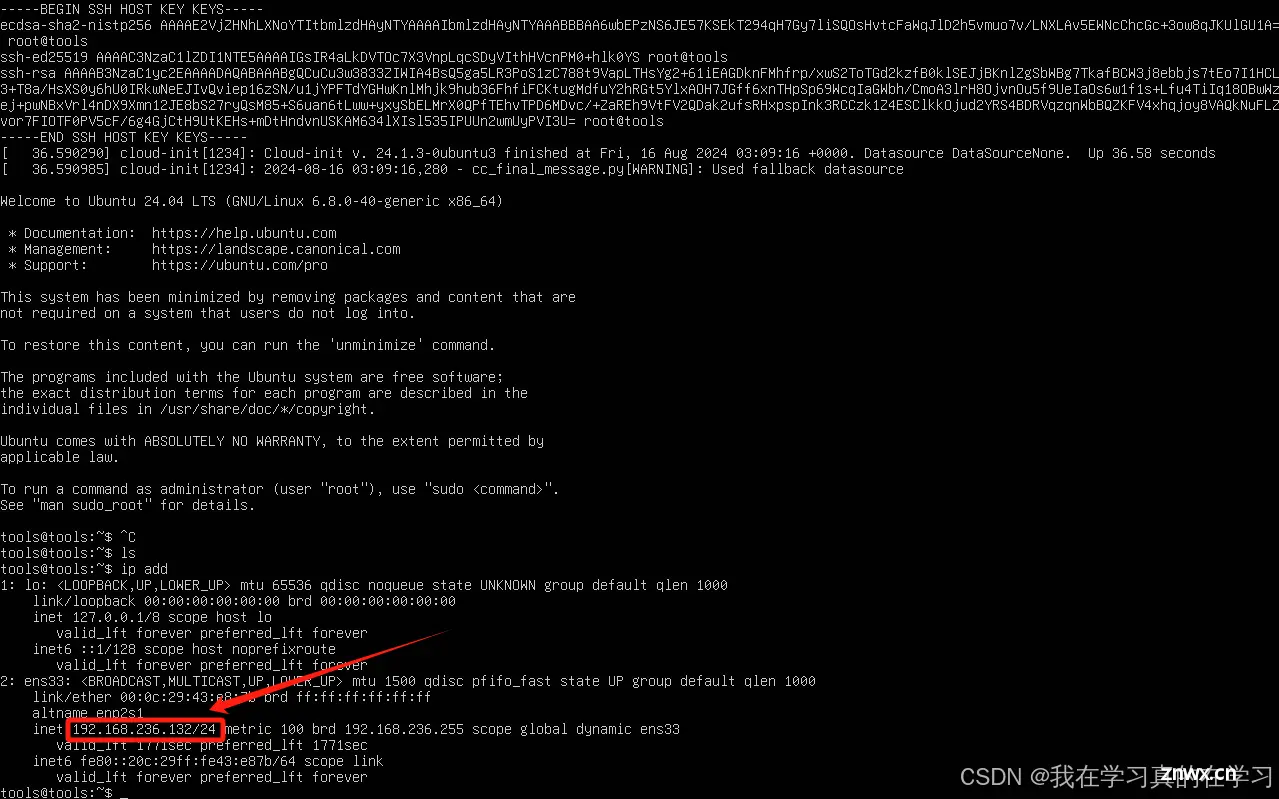
打开xshell,进行连接
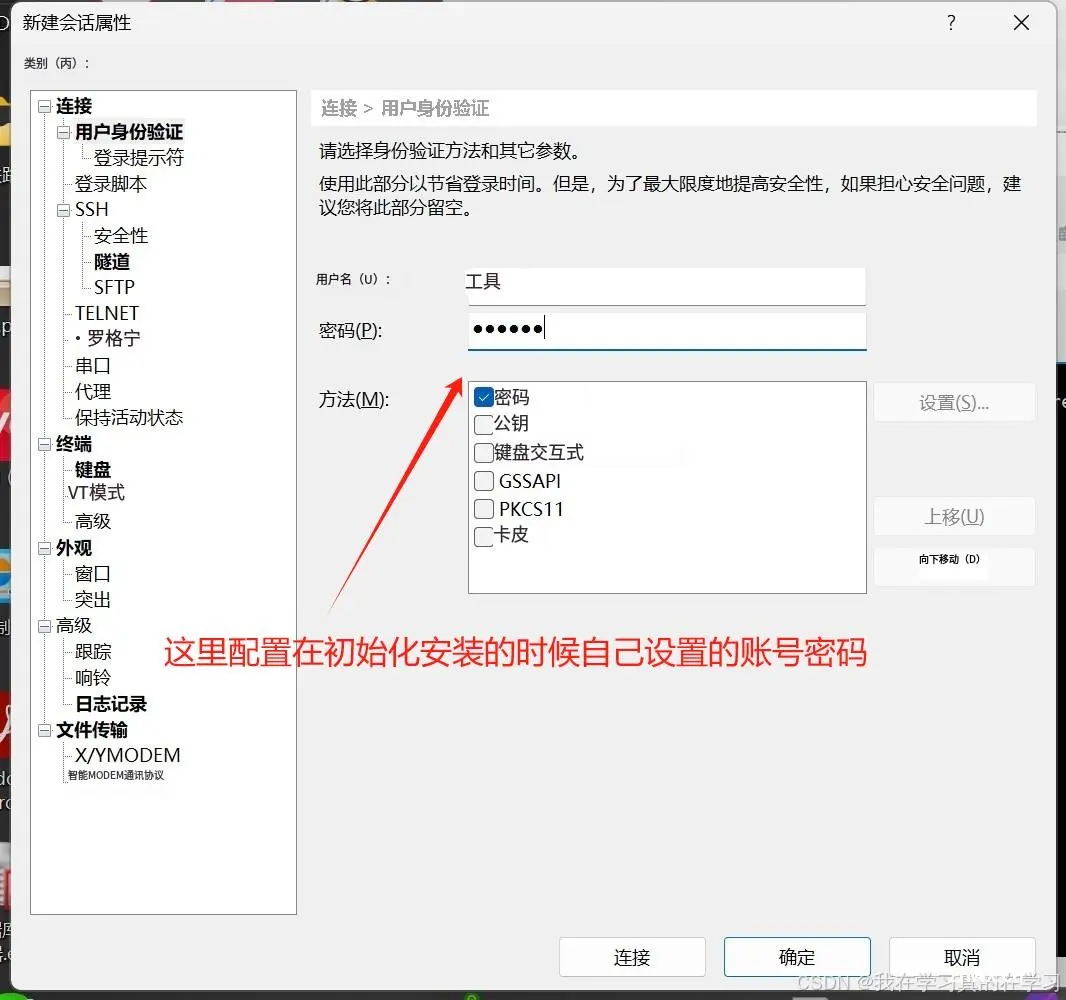
然后点击连接
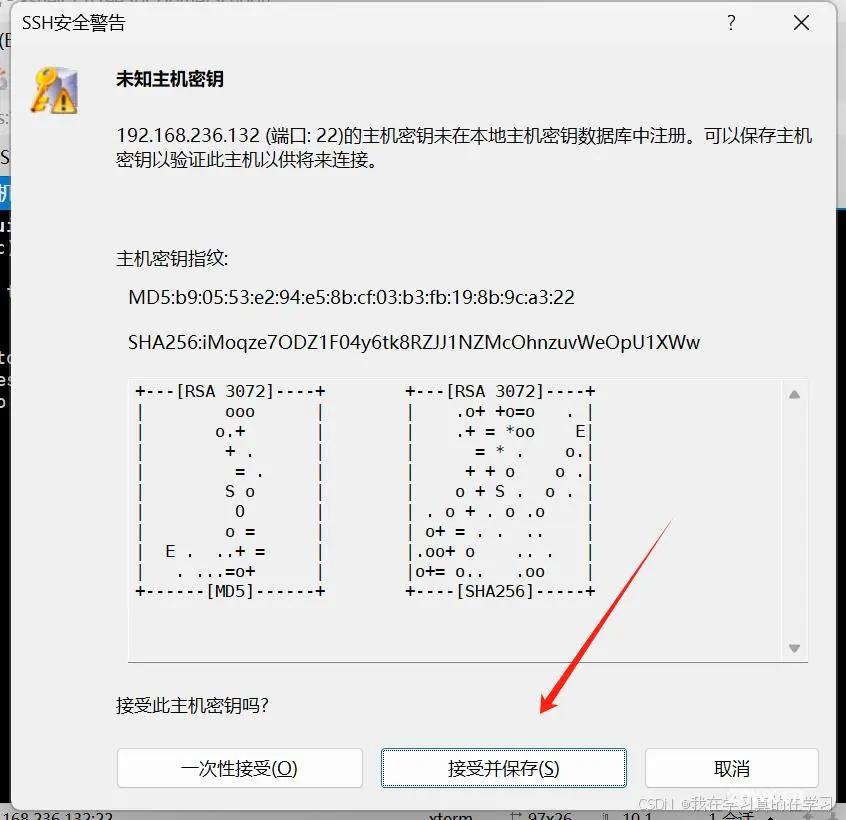
接收并保存
2.3 配置远程使用root用户登录ubuntu与静态IP
2.3.1 给root用户设置密码并切换到root用户
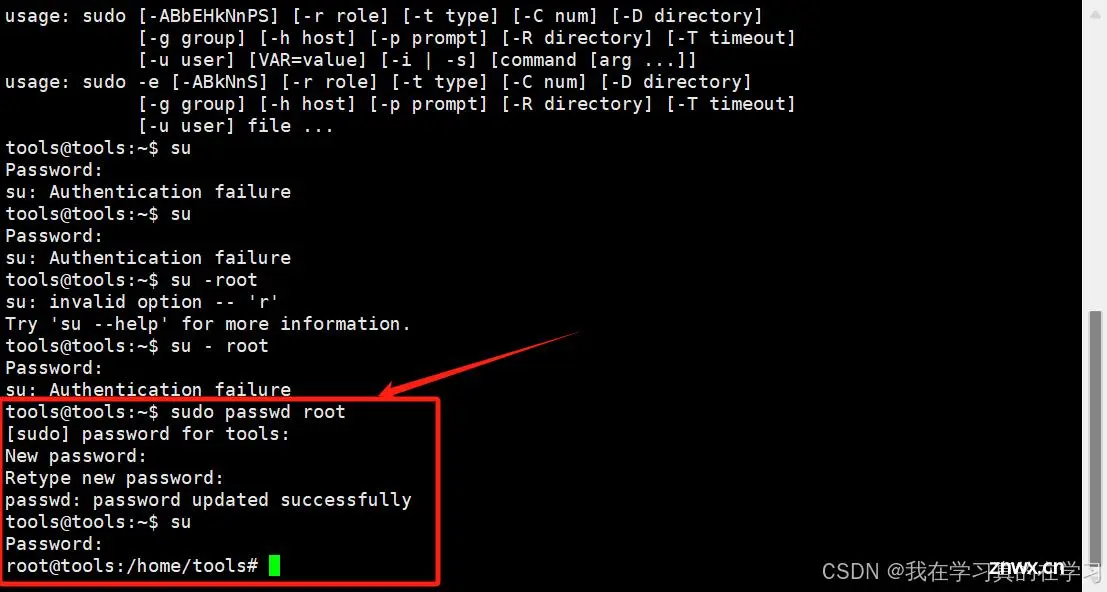
<code>sudo passwd root
[输入你的密码]
[再次输入你的密码]
su
# 切换到root用户
2.3.2 配置远程root用户连接
apt install vim -y
# 下载vim编辑器
vim /etc/ssh/sshd_config
# 编辑sshd连接配置文件
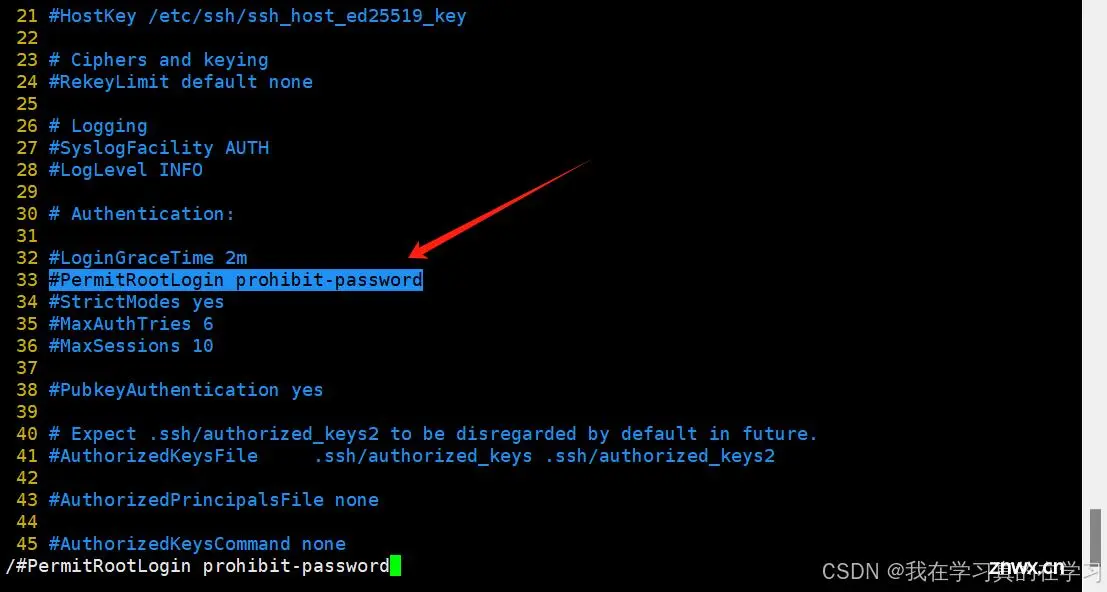
在第33行找到配置项将配置项更改为
<code>
PermitRootLogin yes
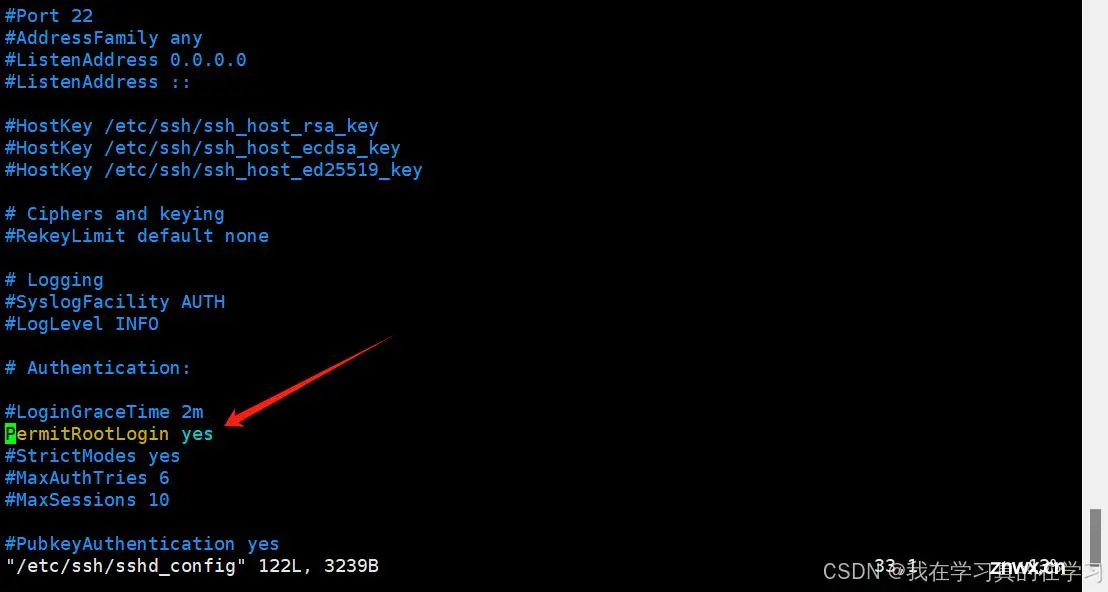
进入末行模式保存退出 ---> :wq
重启ssh服务
<code>sudo systemctl restart ssh
再次使用xshell使用root用户进行远程连接
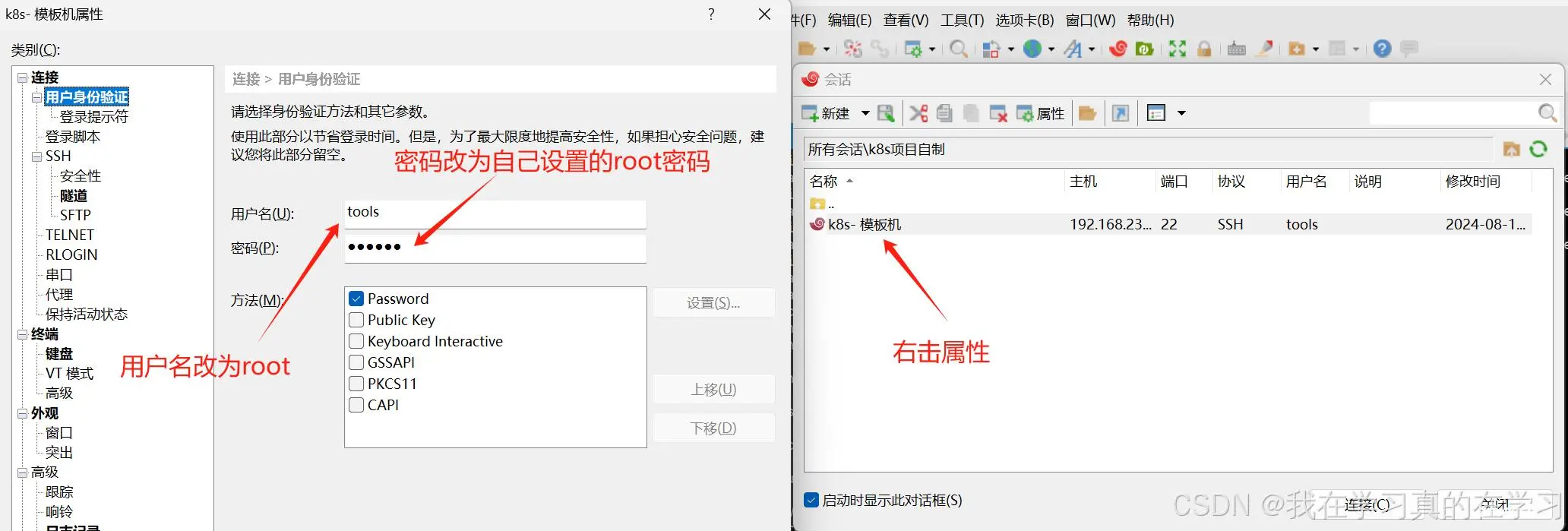
然后点击连接,连接上了
2.3.3 配置静态IP
<code>vim /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
ens33:
addresses: [192.168.236.132/24]
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
dhcp4: false
nameservers:
addresses: [114.114.114.114, 192.168.1.1]
version: 2
renderer: networkd
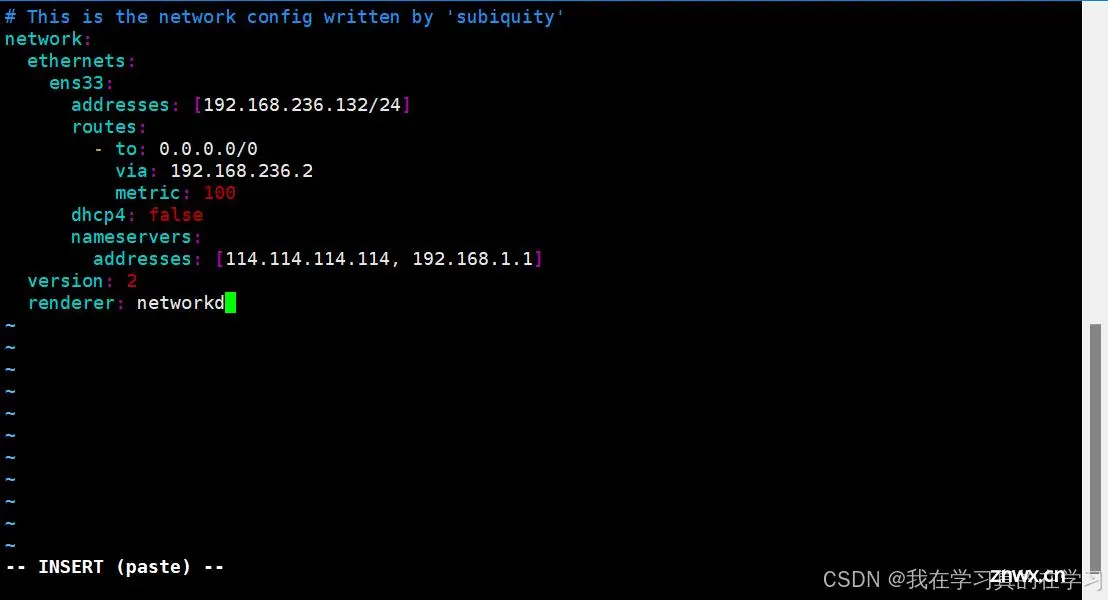
进行如上配置后保存退出
<code>netplan apply
# 应用静态ip配置服务
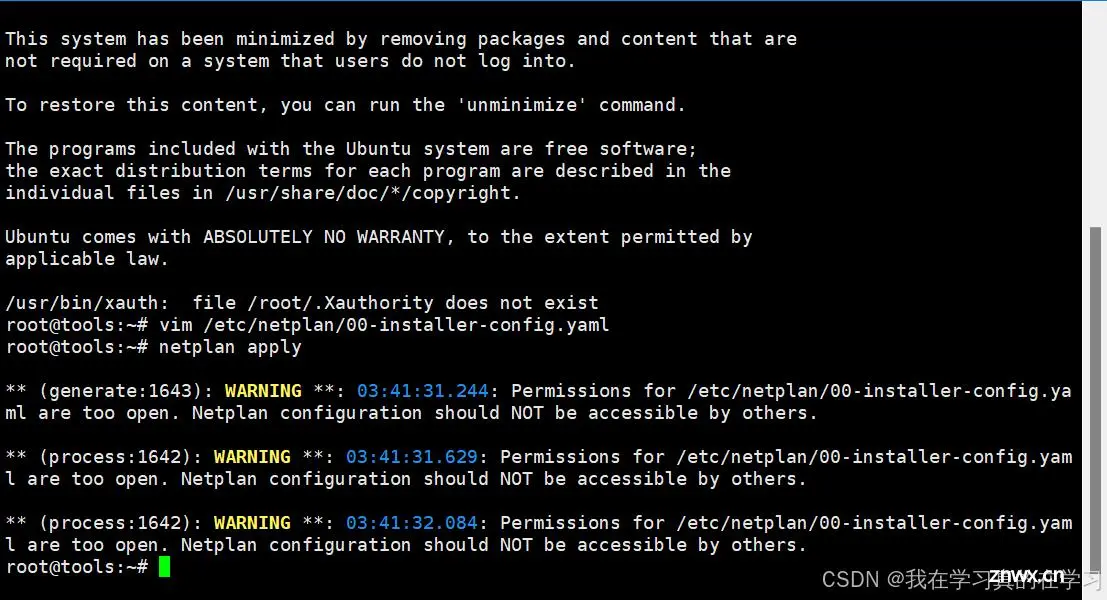
2.4 配置阿里云国内源
<code>cd /etc/apt/
# 切换到/etc/apt目录下
cp sources.list sources.list.bak
# 对源配置进行备份
vim sources.list
# 编辑源文件
# 将以下源全部添加到sources.list里去
# 阿里云Debian稳定版源
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
# 更新和安全更新
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
# 额外的软件包
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
# 安全更新
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
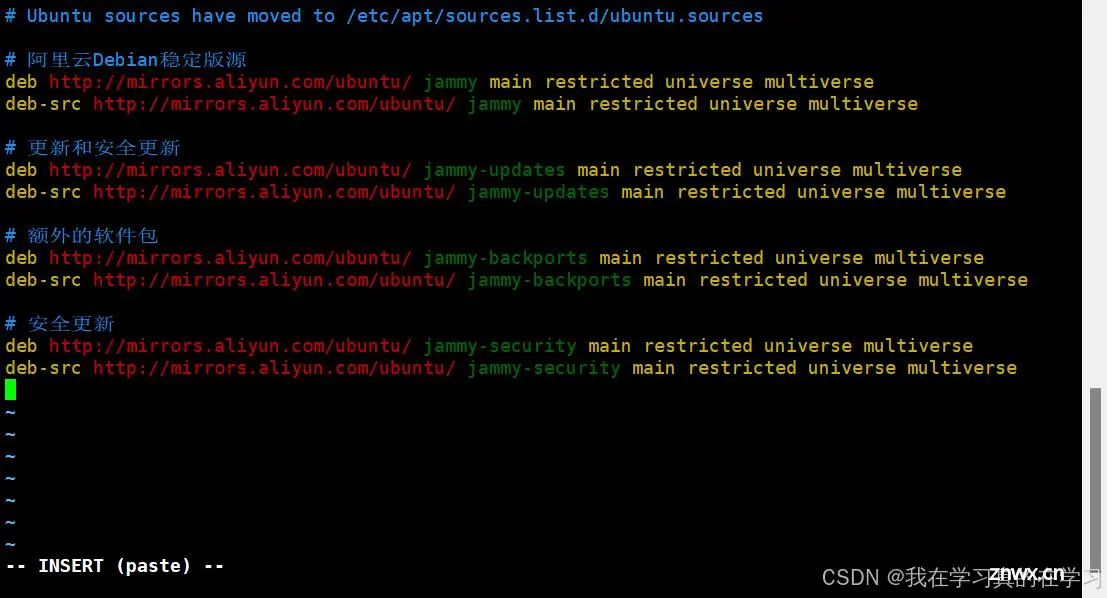
更新索引并验证
<code>apt update
# 如果没有任何错误提示且更新过程顺利完成,则说明已经成功切换到了阿里云的软件源。后续安装或升级软件时会从阿里云的服务器下载所需的软件包。这个过程可能需要3-5分钟左右
2.5 设置hostname
hostnamectl set-hostname [主机名字]
su
2.6 添加Hosts信息
vim /ect/hosts
192.168.236.133 master1
192.168.236.134 master2
192.168.236.135 node1
192.168.236.136 node2
# 添加解析记录
sudo apt install systemd iputils-ping net-tools -y
sudo apt update
# 下载一些网络检测工具
# hosts配置完成之后会立马生效不需要刷新
2.7 解决克隆双IP冲突的问题
暂时配置两台master两台node,后续加机器
# 注意:我们需要对克隆的每台机器一台一台开机配置,因为克隆之后所有机器的ip地址和模板机一样,会导致ip冲突
<code>遇到的问题: 双IP导致IP冲突
不知道什么原因导致每台机器会分配两个ip有一个动态获取的ip始终关不掉,尝试解决
(1)查看/etc/netplan/文件夹下的配置文件并备份
root@tools:/etc/netplan# ls
00-installer-config.yaml 01-netcfg.yaml 01-netcfg.yaml.save 50-cloud-init.yaml
(2)将现有的Netplan配置文件移动到备份文件夹中
sudo mkdir /etc/netplan/backup
sudo mv /etc/netplan/00-installer-config.yaml /etc/netplan/backup/
sudo mv /etc/netplan/01-netcfg.yaml /etc/netplan/backup/
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/backup/
(3)创建新的Netplan配置文件
sudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses:
- 192.168.236.135/24
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
nameservers:
addresses:
- 114.114.114.114
- 192.168.1.1
(4)应用新的Netplan配置
sudo netplan apply
以上彻底解决静态ip配置问题
配置操作:具体操作如下
master1:
sudo mkdir /etc/netplan/backup
sudo mv /etc/netplan/00-installer-config.yaml /etc/netplan/backup/
sudo mv /etc/netplan/01-netcfg.yaml /etc/netplan/backup/
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/backup/
sudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses:
- 192.168.236.133/24
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
nameservers:
addresses:
- 114.114.114.114
- 192.168.1.1
sudo netplan apply
master2:
sudo mkdir /etc/netplan/backup
sudo mv /etc/netplan/00-installer-config.yaml /etc/netplan/backup/
sudo mv /etc/netplan/01-netcfg.yaml /etc/netplan/backup/
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/backup/
sudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses:
- 192.168.236.134/24
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
nameservers:
addresses:
- 114.114.114.114
- 192.168.1.1
sudo netplan apply
node1:
sudo mkdir /etc/netplan/backup
sudo mv /etc/netplan/00-installer-config.yaml /etc/netplan/backup/
sudo mv /etc/netplan/01-netcfg.yaml /etc/netplan/backup/
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/backup/
sudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses:
- 192.168.236.135/24
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
nameservers:
addresses:
- 114.114.114.114
- 192.168.1.1
sudo netplan apply
node2:
sudo mkdir /etc/netplan/backup
sudo mv /etc/netplan/00-installer-config.yaml /etc/netplan/backup/
sudo mv /etc/netplan/01-netcfg.yaml /etc/netplan/backup/
sudo mv /etc/netplan/50-cloud-init.yaml /etc/netplan/backup/
sudo vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses:
- 192.168.236.136/24
routes:
- to: 0.0.0.0/0
via: 192.168.236.2
metric: 100
nameservers:
addresses:
- 114.114.114.114
- 192.168.1.1
sudo netplan apply
3.sealos配置kubelet集群
3.1 安装sealos命令行
sudo apt install wget -y
# 安装wget工具
curl -s https://api.github.com/repos/labring/sealos/releases | grep "tag_name" | head -n 10
# 查看网上有的sealos版本
wget https://github.com/labring/sealos/releases/download/v5.0.0/sealos_5.0.0_linux_amd64.tar.gz
# 拉取sealos
链接:https://pan.baidu.com/s/1t6PS9PWjppU3cQxU-JIpOA?pwd=jyp3
提取码:jyp3
--来自百度网盘超级会员V4的分享
# 因为拉取确实太慢了,我提供网盘链接可以直接下载,然后FTP传上去
tar xf sealos_5.0.0_linux_amd64.tar.gz
# 对压缩文件进行解压
sudo cp sealos /usr/local/bin/sealos
# 将可执行二进制文件复制到/usr/local/bin下面去
sealos version
# 查看sealos版本 , 验证是否安装好sealos
3.2 安装部署k8s集群
# 先安装所必须的工具,一定要先装完再用下面的一键部署,我直接给所有节点装了,怕出问题
sudo apt install iptables ebtables ethtool socat
sudo apt update
# 一条命令一键部署k8s集群
sudo sealos run registry.cn-shanghai.aliyuncs.com/labring/kubernetes:v1.27.10 registry.cn-shanghai.aliyuncs.com/labring/helm:v3.9.4 registry.cn-shanghai.aliyuncs.com/labring/cilium:v1.13.4 \
--masters 192.168.236.133 \
--nodes 192.168.236.135,192.168.236.136 -p '123456'
3.3 添加master2节点进入k8s集群
sealos add --masters 192.168.236.134
# 注意添加的前提是在每一台机器上都进行hosts解析了
3.4 添加node节点进入k8s集群
sealos add --nodes 192.168.236.137
# 注意添加的前提是在每一台机器上都进行hosts解析了
3.5 删除master节点
sealos delete --masters 192.168.236.134
3.6 删除node节点
sealos delete --nodes 192.168.236.137
3.7 给node分配角色
kubectl label node node1 node-role.kubernetes.io/worker=worker
kubectl label node node2 node-role.kubernetes.io/worker=worker
4.安装nerdctl
4.1 安装nerdctl
<code># 下载图示版本
wget https://github.com/containerd/nerdctl/releases/download/v1.7.6/nerdctl-1.7.6-linux-amd64.tar.gz
# 当然也可以用我的百度网盘链接
链接:https://pan.baidu.com/s/1PdR1Y69XAQE_KXKU7azHGQ?pwd=jyp3
提取码:jyp3
--来自百度网盘超级会员V4的分享
# 解压安装包到 /usr/local/bin 目录
sudo tar xzvf nerdctl-1.7.6-linux-amd64.tar.gz -C /usr/local/bin
# 确保 nerdctl 二进制文件具有执行权限
sudo chmod +x /usr/local/bin/nerdctl
# 验证安装
nerdctl --version
基本用法:
(1)容器管理
nerdctl ps -a
# 查看正在运行的容器(包括停止的)
nerdctl run -it --rm alpine
# 启动一个新容器
nerdctl run --rm alpine echo "Hello, World!"
# --rm 确保 alpine 容器在执行完 echo "Hello, World!" 命令后会被自动删除,而不需要手动执行 docker rm 或 nerdctl rm
# -d 后台运行
nerdctl stop <container_id>
# 停止一个正在运行的容器
nerdctl rm <container_id>
# 删除一个容器
(2)镜像管理
nerdctl images
# 查看所有镜像
nerdctl pull nginx
# 拉取镜像
nerdctl rmi nginx
# 删除镜像
(3)数据卷管理
nerdctl volume create my-volume
# 创建数据卷
nerdctl volume ls
# 列出数据卷
nerdctl volume rm my-volume
# 删除数据卷
(4)网络管理
nerdctl network create my-network
# 创建网络
nerdctl network ls
# 列出网络
nerdctl network rm my-network
# 删除网络
4.2对containerd配置文件进行换源
(1)编辑 containerd 配置文件
vim /etc/containerd/config.toml
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
oom_score = 0
[grpc]
address = "/run/containerd/containerd.sock"
uid = 0
gid = 0
max_recv_message_size = 16777216
max_send_message_size = 16777216
[debug]
address = "/run/containerd/containerd-debug.sock"
uid = 0
gid = 0
level = "warn"
[timeouts]
"io.containerd.timeout.shim.cleanup" = "5s"
"io.containerd.timeout.shim.load" = "5s"
"io.containerd.timeout.shim.shutdown" = "3s"
"io.containerd.timeout.task.state" = "2s"
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "sealos.hub:5000/pause:3.9"
max_container_log_line_size = -1
max_concurrent_downloads = 20
disable_apparmor = false
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
default_runtime_name = "runc"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
runtime_engine = ""
runtime_root = ""
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
mkdir /etc/containerd/certs.d/xdocker.io/
vim /etc/containerd/certs.d/xdocker.io/hosts.toml
server = "https://registry-1.docker.io"
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve", "push"]
(2)刷新服务
sudo systemctl restart containerd
(3)至此可以拉取镜像了
一键换位操作:
cd /etc/containerd/certs.d/
mv xdocker.io docker.io
cd /etc/containerd/certs.d/
mv docker.io xdocker.io
注意:这里有一个很离谱的问题,如下图所示,sealos.hub:5000文件夹一定要在xdocker.io前面,因为在这个文件夹里的文件nerdctl都会认为是本地文件,并且从前往后读取,而我们的scweb是本地文件如果不调试的话就拉不上去,当然当我们拉取网络镜像的时候也是同理的
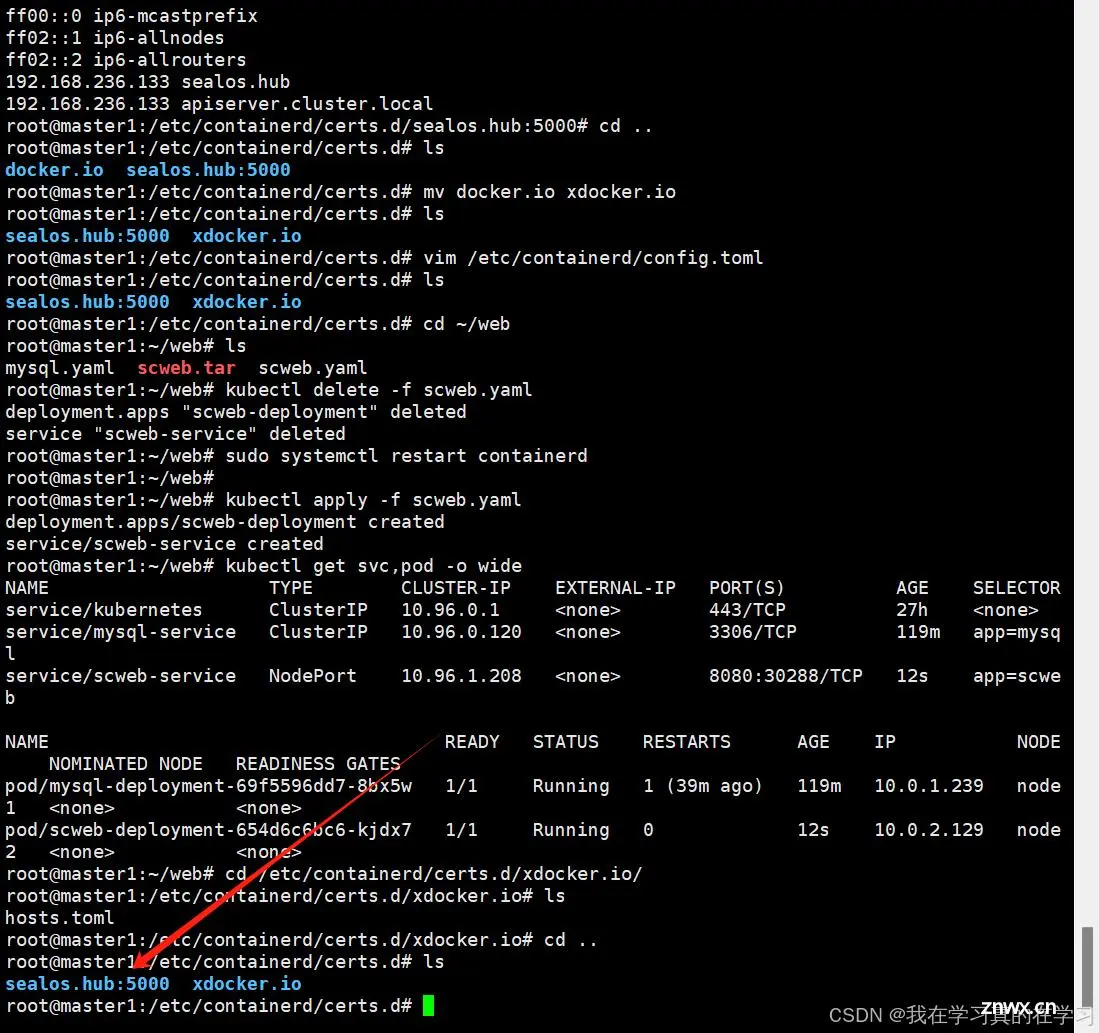
所以如果要拉取本地镜像和源里的镜像每次都要进行换顺序的操作,这一点我觉得很麻烦,如果有师傅能解决,多多斧正,感谢
5.安装Dashboard
<code>wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml\
# 修改Service部分,改为NodePort对外暴露端口
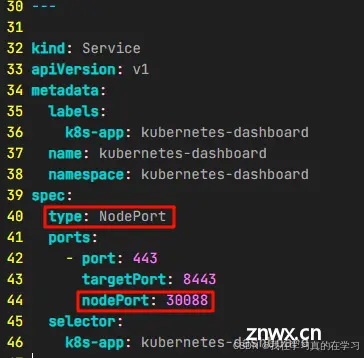
修改完图示两处后进行下面操作
<code>kubectl apply -f recommended.yaml
# 应用yaml文件
kubectl get pods,svc -n kubernetes-dashboard
# 查看dashboard状态
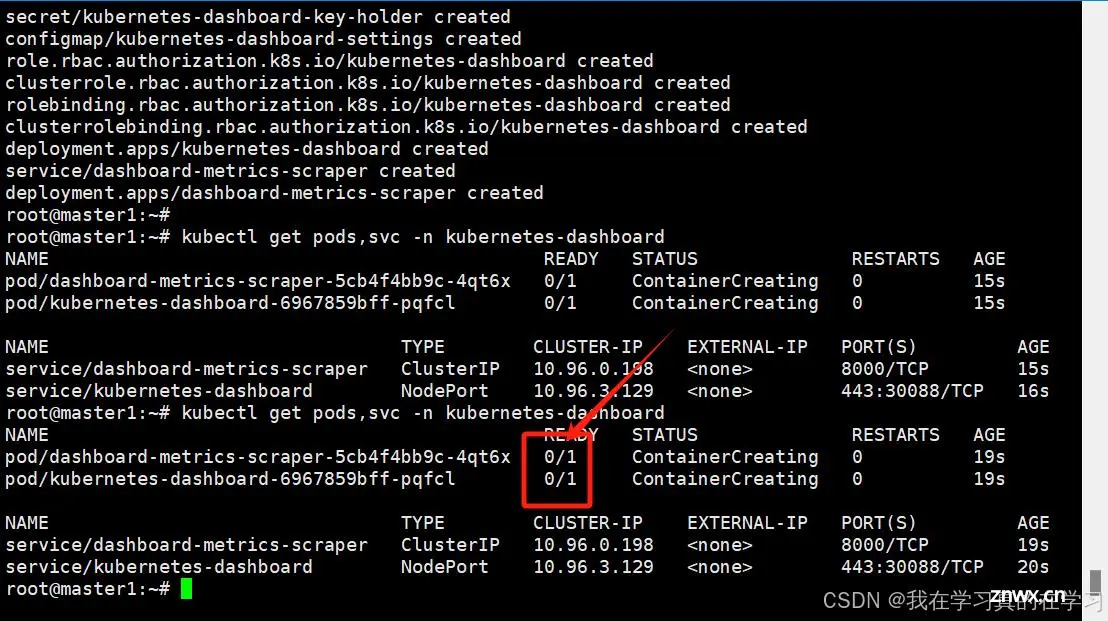
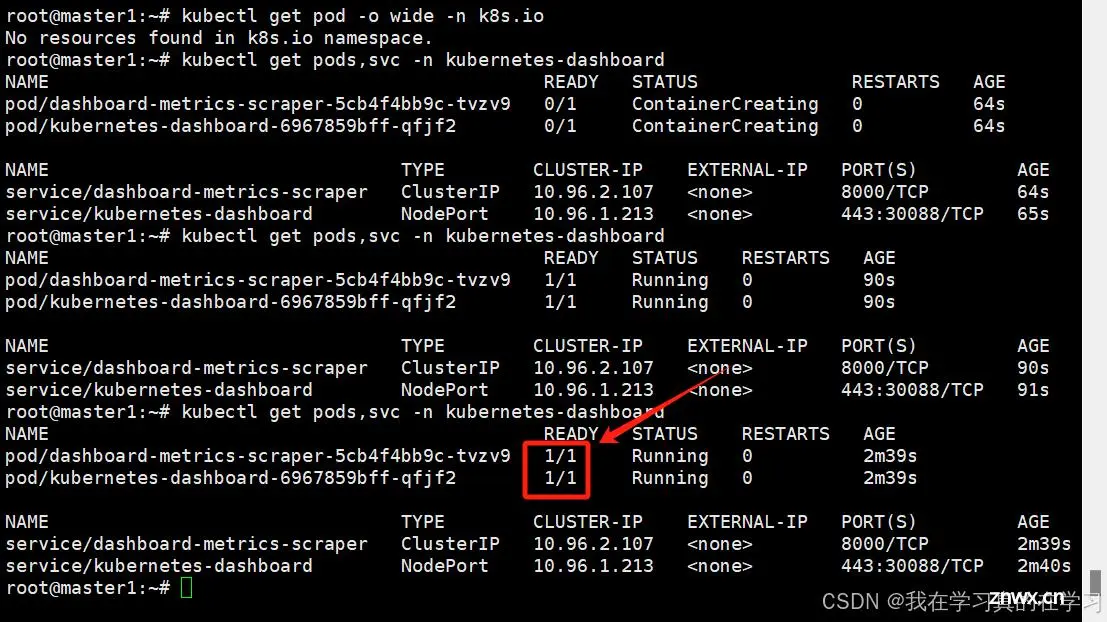
<code># 在node上
nerdctl pull kubernetesui/dashboard:v2.7.0
nerdctl pull kubernetesui/metrics-scraper:v1.0.8
创建dashboard-access-token.yaml文件
<code>vim dashboard-access-token.yaml
# Creating a Service Account
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
# Creating a ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
---
# Getting a long-lived Bearer Token for ServiceAccount
apiVersion: v1
kind: Secret
metadata:
name: admin-user
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "admin-user"
type: kubernetes.io/service-account-token
# Clean up and next steps
# kubectl -n kubernetes-dashboard delete serviceaccount admin-user
# kubectl -n kubernetes-dashboard delete clusterrolebinding admin-user
执行
kubectl apply -f dashboard-access-token.yaml
# 获取token
kubectl get secret admin-user -n kubernetes-dashboard -o jsonpath={".data.token"} | base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6Iko5SWR6QWF3SmZ4ZTh2dm5MdDhmWHJ3eFNnZnBsRTN2MjBQRTRGenc2RzQifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwZDU3NjkyOS02NmZlLTRhYTQtYTY5MS0zZWFjZTg3ODY0NjgiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.lIaqkCXSsmZn21uTxnHP4G_BjncitKxd7j6r7yAdB6xh8r4-XWohuC8P2EDGg23poxuq_tT6pRQwaWs2ry9xXwqWp-RwNhp0f3w-oayPYyDCWL80cTzRQZ1gHNBR4ot6GrMYrQRozjd6zfBBTON6jWXTQCxK-n5kgcMG7Y0NWw_X0VJciCccI-ffI1T0Y7J6h6u1WcJ-OGf0KD77esYjp8oXYz9IyXn8HW9M4i5B2OL2nqZP5HW_j8Fxm8pgZgG6915DXONX1HXHxfkbpTcxAG0wsbTbgMhRNCrNbJSSqoYvemWfNsz_Lp0epFvXBVmwjNJUTZNBD2JecVJ352MpHA
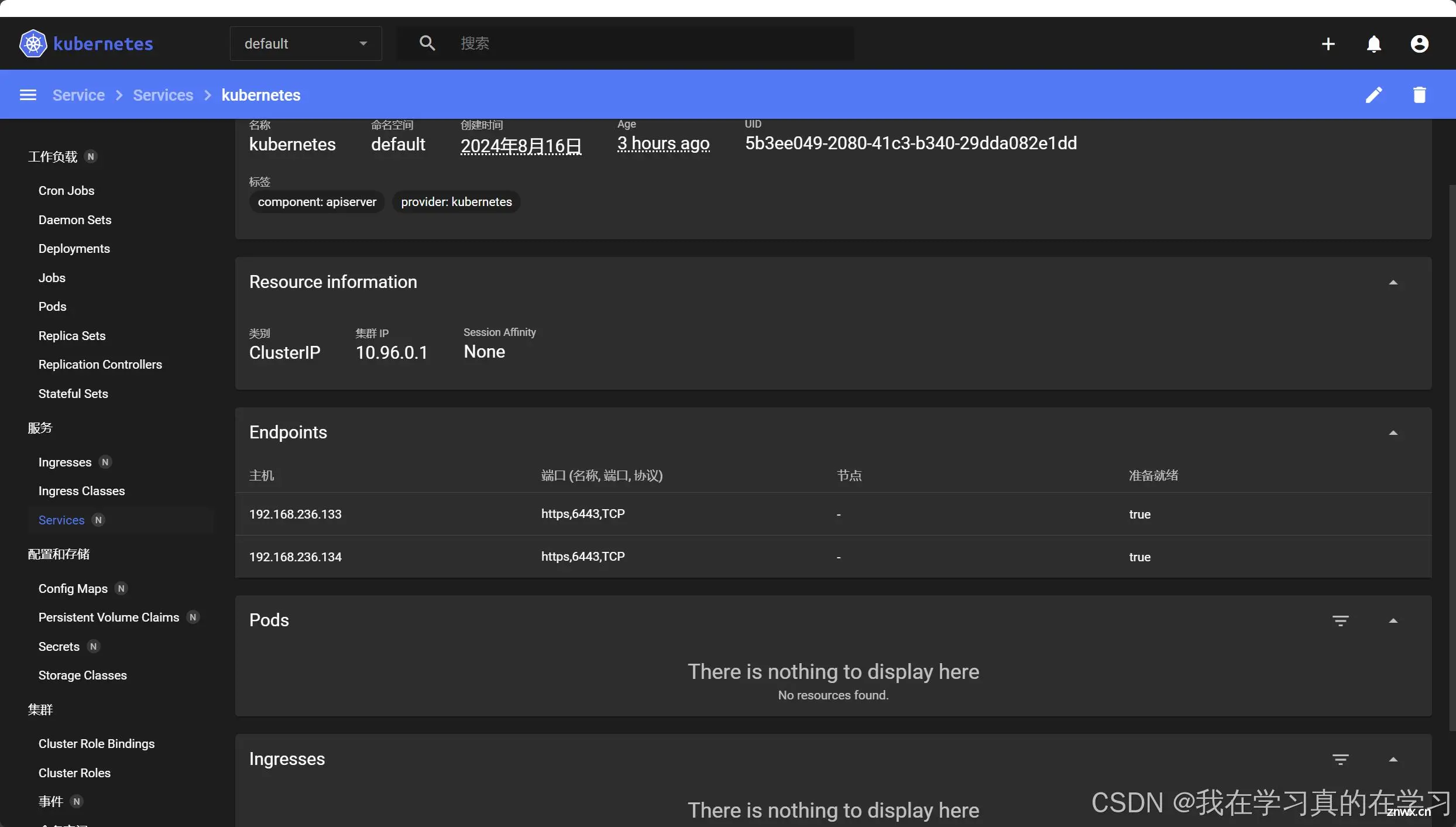
访问dashboard
URL: https://192.168.236.133:30088/
# 获取端口
kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.109.73.125 <none> 8000/TCP 3d23h
kubernetes-dashboard NodePort 10.101.254.225 <none> 443:30088/TCP 3d23h # 端口为30088
6.安装Prometheus监控k8s集群
我们使用helm工具安装Prometheus
6.1 安装helm
从官方拉取下来,建议用我的百度网盘
<code>链接:https://pan.baidu.com/s/1Qh32VN2PAxYM5OQ1SJ2agQ?pwd=jyp3
提取码:jyp3
--来自百度网盘超级会员V4的分享
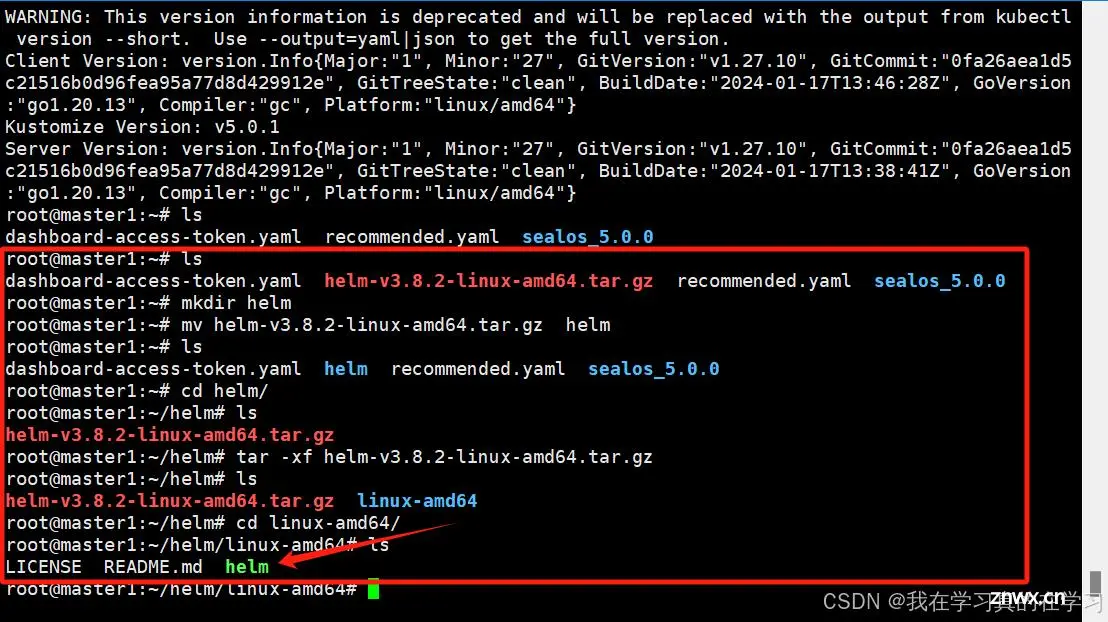
<code># 使用ftp将文件传入xshll
mkdir helm
mv helm-v3.15.4-linux-amd64.tar.gz helm
cd helm/
tar -xf helm-v3.15.4-linux-amd64.tar.gz
cd linux-amd64/
# 将二进制文件加入可执行文件路径
cp helm /usr/local/bin
# 验证helm是否成功加入路径
helm version
# 添加官方源
helm repo add bitnami https://charts.bitnami.com/bitnami
# 阿里云源
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 添加微软源
helm repo add stable http://mirror.azure.cn/kubernetes/charts/
# 查看有哪些源
helm repo list
6.2 安装Prometheus
参考:使用Helm 3在Kubernetes集群部署Prometheus和Grafana — Cloud Atlas beta 文档
# 添加Prometheus源
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 更新源
helm repo update
# 查看Prometheus版本
helm search repo prometheus-community/kube-prometheus-stack
output:
NAME CHART VERSIONAPP VERSIONDESCRIPTION
prometheus-community/kube-prometheus-stack61.9.0 v0.75.2 kube-prometheus-stack collects Kubernetes manif...
# 创建一个prometheus专用文件夹
mkdir prometheus
cd prometheus
# 安装Prometheus
helm install prometheus prometheus-community/prometheus
6.3 node1镜像丢失问题

查看状态时发现没镜像
<code>kubectl describe pod prometheus-kube-state-metrics-7f979f5c55-w7jv9
# 查看容器详情
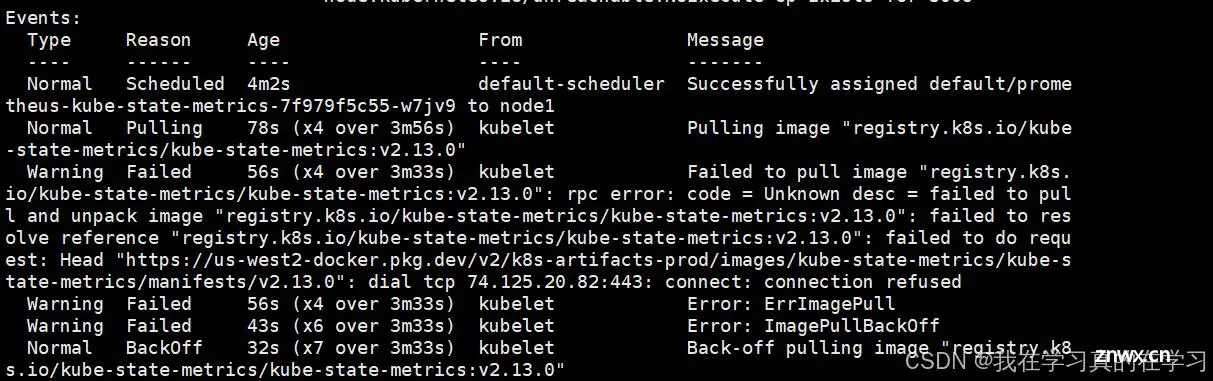
发现没有镜像
我们缺少这个镜像
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
从docker上拉取镜像保存下来
<code>docker pull registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
docker save -o kube-state-metrics.tar registry.k8s.io/kube-state-metrics/kube-state-metrics
# 使用ftp拉下来再传入node1上去
nerdctl load -i kube-state-metrics.tar
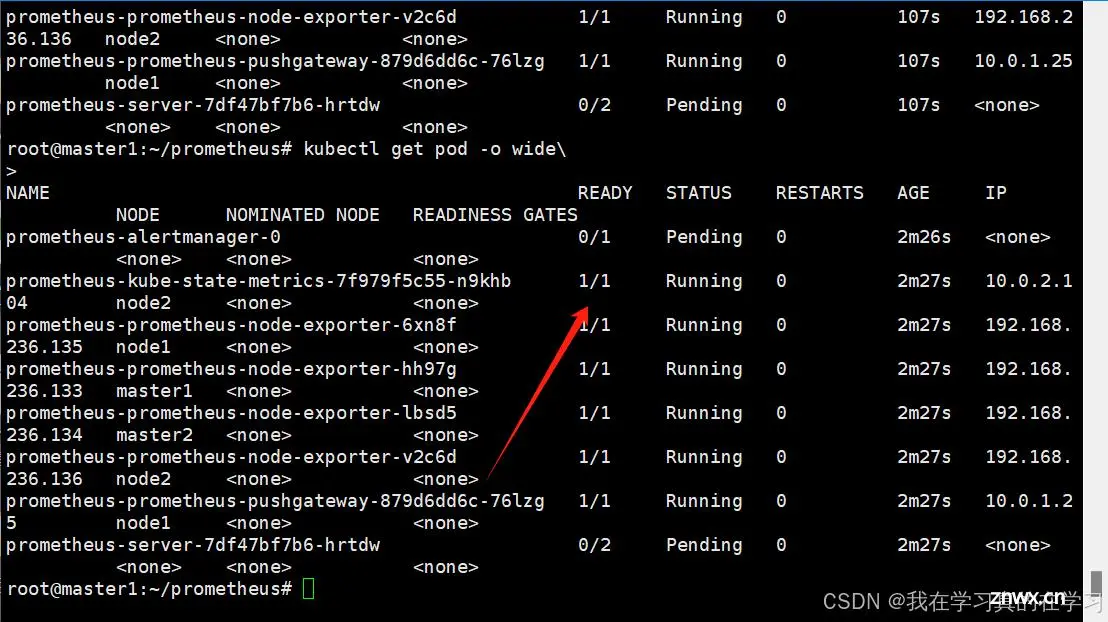
上传上去后等一会发现已经运行了
可以发现我们还有两个服务处于pending状态,原因是我们有pvc但是没有pv所以不能实现持久化挂载
6.4 实现自动扩容
<code>sudo mkdir -p /root/prometheus/prometheus-server
sudo mkdir -p /root/prometheus/alertmanager
sudo chown -R nobody:nogroup /root/prometheus/prometheus-server
sudo chown -R nobody:nogroup /root/prometheus/alertmanager
# 上面我们在家目录下创建了文件夹现在派上用场了
6.4.1 配置nfs环境
# 为每一台主机操作,安装nfs 客户端服务工具
sudo apt update
sudo apt install nfs-kernel-server nfs-common
# 设置nfs启动自运行
sudo systemctl enable nfs-kernel-server
# 创建文件夹并授予一定权限
sudo mkdir -p /web/data
sudo chown nobody:nogroup /web/data
sudo chmod 777 /web/data
# 修改/etc/exports文件,允许所有主机访问master1的/web/data
vim /etc/exports
/web/data *(rw,sync,all_squash)
# 刷新nfs服务
sudo exportfs -rav
sudo systemctl restart nfs-kernel-server
# 在另外一台机器上测试是否能够挂载nfs服务文件夹
sudo mount -t nfs 192.168.236.133:/web/data /mnt/webdata
# 创建文件夹后,再在挂载目录上创建一个文件
sudo touch /mnt/webdata/testfile
# 在nfs服务器上查看是否有testfile,有的话就是创建成功了
sudo ls -l /web/data
# 测试完成后取消挂载
sudo umount /mnt/webdata
6.4.2 查看集群环境
kubectl cluster-info
ubernetes control plane is running at https://apiserver.cluster.local:6443
CoreDNS is running at https://apiserver.cluster.local:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
6.4.3 创建SA账号
cd /root/prometheus
vim nfs.rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: dev
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: dev
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: dev
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: dev
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: dev
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
kubectl apply -f nfs.rbac.yaml
6.4.4 部署NFS-Subdir-External-Provisioner (启动一个nfs供应商)
vim nfs-provisioner-deploy.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
namespace: dev
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate #设置升级策略为删除再创建(默认为滚动更新)
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner #上一步创建的ServiceAccount名称
containers:
- name: nfs-client-provisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME # Provisioner的名称,以后设置的storageclass要和这个保持一致
value: storage-nfs
- name: NFS_SERVER # NFS服务器地址,需和valumes参数中配置的保持一致
value: 192.168.236.133
- name: NFS_PATH # NFS服务器数据存储目录,需和valumes参数中配置的保持一致
value: /web/data
- name: ENABLE_LEADER_ELECTION
value: "true"
volumes:
- name: nfs-client-root
nfs:
server: 192.168.236.133 # NFS服务器地址
path: /web/data # NFS共享目录
kubectl apply -f nfs-provisioner-deploy.yaml
6.4.5 创建NFS StorageClass(搭建存储类)
vim nfs-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
namespace: dev
name: nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "false" ## 是否设置为默认的storageclass
provisioner: storage-nfs ## 动态卷分配者名称,必须和上面创建的deploy中环境变量“PROVISIONER_NAME”变量值一致
parameters:
archiveOnDelete: "true" ## 设置为"false"时删除PVC不会保留数据,"true"则保留数据
mountOptions:
- hard ## 指定为硬挂载方式
- nfsvers=4 ## 指定NFS版本,这个需要根据NFS Server版本号设置
kubectl apply -f nfs-storageclass.yaml
6.4.6 将PVC配置挂载到storageclass
(1)备份原来的pvc配置
kubectl get pvc -o yaml
# 查看pvc的配置文件
vim pvc.backup.yaml
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: prometheus
creationTimestamp: "2024-08-17T01:52:26Z"
finalizers:
- kubernetes.io/pvc-protection
labels:
app.kubernetes.io/component: server
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: prometheus
app.kubernetes.io/version: v2.54.0
helm.sh/chart: prometheus-25.26.0
name: prometheus-server
namespace: prometheus
resourceVersion: "71611"
uid: ec9285c8-a54c-49b5-ba3a-9de9c1767fde
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
volumeMode: Filesystem
status:
phase: Pending
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: "2024-08-17T01:52:28Z"
finalizers:
- kubernetes.io/pvc-protection
labels:
app.kubernetes.io/instance: prometheus
app.kubernetes.io/name: alertmanager
name: storage-prometheus-alertmanager-0
namespace: prometheus
resourceVersion: "71705"
uid: dfb75c21-da24-4a88-8394-999bb16a8a8c
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
volumeMode: Filesystem
status:
phase: Pending
kind: List
metadata:
resourceVersion: ""
(2)删除原先的pvc配置
# 删除原来的pvc
kubectl delete pvc prometheus-server -n prometheus
kubectl delete pvc storage-prometheus-alertmanager-0 -n prometheus
# 确保已经删除看一下
kubectl get pvc -n prometheus
(3)配置新的pvc配置
vim pvc.new.yaml
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: prometheus
name: prometheus-server
namespace: prometheus
spec:
storageClassName: nfs-storage # 指定使用的 StorageClass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
volumeMode: Filesystem
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage-prometheus-alertmanager-0
namespace: prometheus
spec:
storageClassName: nfs-storage # 指定使用的 StorageClass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
volumeMode: Filesystem
kind: List
metadata:
resourceVersion: ""
# 这个时候会报警告但是无伤大雅
kubectl apply -f pvc.new.yaml

6.5 服务外发
我们于集群内部搭建了Prometheus,但是想要访问就需要服务外发
<code>kubectl expose deployment prometheus-server --type=NodePort --name=prometheus-service --port=9090 --target-port=9090
# 对server服务进行外发
kubectl get svc prometheus-service
# 查看服务状态
root@master1:~# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master1 Ready control-plane 20h v1.27.10 192.168.236.133 <none> Ubuntu 24.04 LTS 6.8.0-40-generic containerd://1.7.15
master2 Ready control-plane 20h v1.27.10 192.168.236.134 <none> Ubuntu 24.04 LTS 6.8.0-40-generic containerd://1.7.15
node1 Ready worker 20h v1.27.10 192.168.236.135 <none> Ubuntu 24.04 LTS 6.8.0-40-generic containerd://1.7.15
node2 Ready worker 20h v1.27.10 192.168.236.136 <none> Ubuntu 24.04 LTS 6.8.0-40-generic containerd://1.7.15
root@master1:~#
# 查看nodes
# 选择一个ip访问
http://<Node_IP>:32499
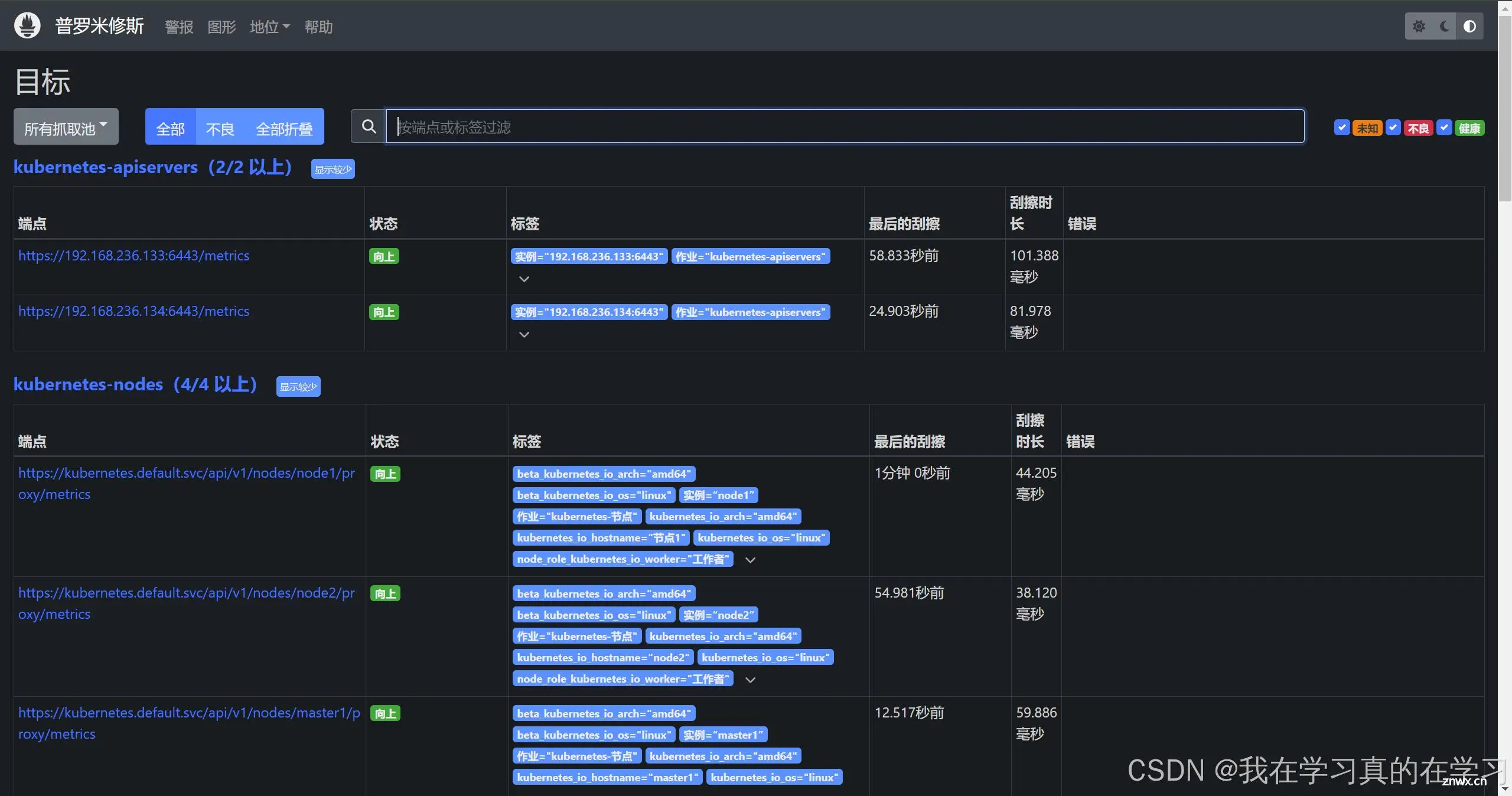
于此实现服务外发
7.安装Grafana
7.1 helm安装grafana
<code># 创建grafana命名空间
kubectl create namespace grafana
# 切换到grafana命名空间
kubens grafana
# 查找grafana版本
helm search repo grafana
# 选一个适配的版本安装
helm install grafana bitnami/grafana
# 查看helm list确保grafana已经安装
helm list
# 查看k8s服务确保grafana正常启动
kubectl get svc,pod -A |grep grafana
grafana service/grafana ClusterIP 10.96.1.13 <none> 3000/TCP 101s
grafana pod/grafana-678f4cfbf-gjjss 0/1 Pending 0 100s
root@master1:~# kubectl get svc,pod -A |grep grafana
grafana service/grafana ClusterIP 10.96.1.13 <none> 3000/TCP 102s
grafana pod/grafana-678f4cfbf-gjjss 0/1 Pending 0 101s
# 我也很无奈,又出现了和prometheus一样的问题
kubectl describe pod grafana-678f4cfbf-gjjss
Warning FailedScheduling 3m57s default-scheduler 0/4 nodes are available: pod has unbound immediate PersistentVolumeClaims. preemption: 0/4 nodes are available: 4 Preemption is not helpful for scheduling..
# 又是没有pv
我们直接拿着配置Prometheus的流程再走一遍
7.2 实现自动扩容
sudo mkdir -p /root/grafana
sudo chown -R nobody:nogroup /root/prometheus/alertmanager
# 上面我们在家目录下创建了文件夹现在派上用场了
7.2.1 查看集群环境
kubectl cluster-info
ubernetes control plane is running at https://apiserver.cluster.local:6443
CoreDNS is running at https://apiserver.cluster.local:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
7.2.2 创建SA账号
cd /root/grafana
vim nfs.rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: dev
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: dev
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: dev
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: dev
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: dev
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
kubectl apply -f nfs.rbac.yaml
7.2.3 部署NFS-Subdir-External-Provisioner (启动一个nfs供应商)
vim nfs-provisioner-deploy.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
namespace: dev
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate #设置升级策略为删除再创建(默认为滚动更新)
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner #上一步创建的ServiceAccount名称
containers:
- name: nfs-client-provisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME # Provisioner的名称,以后设置的storageclass要和这个保持一致
value: storage-nfs
- name: NFS_SERVER # NFS服务器地址,需和valumes参数中配置的保持一致
value: 192.168.236.133
- name: NFS_PATH # NFS服务器数据存储目录,需和valumes参数中配置的保持一致
value: /web/data
- name: ENABLE_LEADER_ELECTION
value: "true"
volumes:
- name: nfs-client-root
nfs:
server: 192.168.236.133 # NFS服务器地址
path: /web/data # NFS共享目录
kubectl apply -f nfs-provisioner-deploy.yaml
7.2.4 创建NFS StorageClass(搭建存储类)
vim nfs-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
namespace: dev
name: nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "false" ## 是否设置为默认的storageclass
provisioner: storage-nfs ## 动态卷分配者名称,必须和上面创建的deploy中环境变量“PROVISIONER_NAME”变量值一致
parameters:
archiveOnDelete: "true" ## 设置为"false"时删除PVC不会保留数据,"true"则保留数据
mountOptions:
- hard ## 指定为硬挂载方式
- nfsvers=4 ## 指定NFS版本,这个需要根据NFS Server版本号设置
kubectl apply -f nfs-storageclass.yaml
7.2.5 将PVC配置挂载到storageclass
(1)备份
kubectl get pvc -o yaml
# 查看原来的配置文件
vim pvc.backup.yaml
apiVersion: v1
items:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
meta.helm.sh/release-name: grafana
meta.helm.sh/release-namespace: grafana
creationTimestamp: "2024-08-17T03:38:01Z"
finalizers:
- kubernetes.io/pvc-protection
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/instance: grafana
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 11.1.4
helm.sh/chart: grafana-11.3.15
name: grafana
namespace: grafana
resourceVersion: "90425"
uid: e8f1e399-1cdd-48c5-82aa-974f03c941ea
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
volumeMode: Filesystem
status:
phase: Pending
kind: List
metadata:
resourceVersion: ""
(2)删除pvc
kubectl delete pvc grafana
# 删除原来的配置
(3)创建新的pvc
vim pvc.new.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc # 替换为适当的名称
namespace: grafana
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/instance: grafana
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 11.1.4
helm.sh/chart: grafana-11.3.15
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: nfs-storage
volumeMode: Filesystem
kubectl apply -f pvc.new.yaml
# kubectl get pvc 发现pvc 处于bonud状态
# kubectl get svc,pod -o wide 查看容器状态
# 发现pod处于pending状态
7.3 重新配置deploy
一次成功了我这里就不备份了,但是平常生活中记得备份
(1)删除原先的deploy
kubectl delete deploy grafana
(2)写grafana的yaml文件
vim grafana.deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: grafana
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:latest
volumeMounts:
- name: grafana-storage
mountPath: /var/lib/grafana
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
kubectl get deploy,pod -o wide
# 查看pod状态
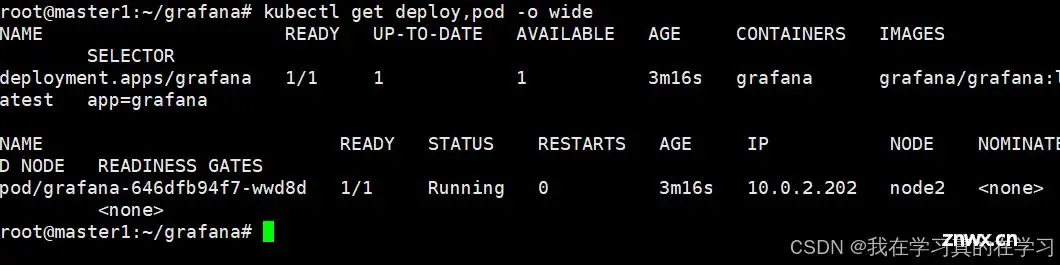
集群内部已经部署好grafana了,并且是一个自动化扩容的grafana
7.4 服务外发
<code>kubectl expose deployment grafana --type=NodePort --name=grafana-service --port=3000 --target-port=3000 --namespace=grafana
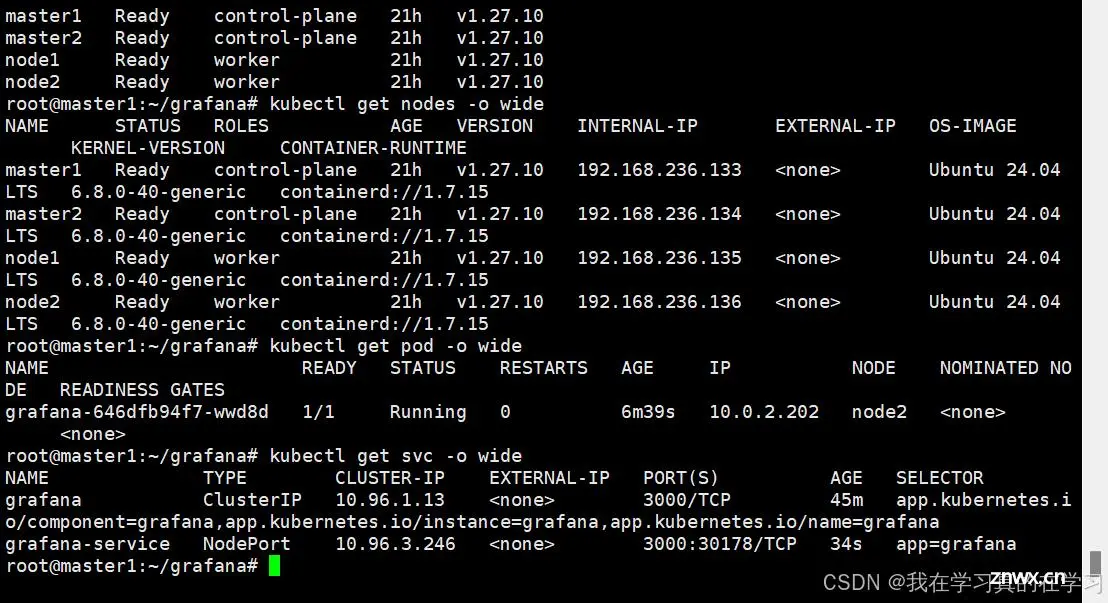
<code>kubectl gte svc
# 如上图所示 ,查看开放端口,这里发现30178端口开放
# 直接访问http://<Node_IP>:30178
7.5 Grafana 初始化配置
grafana默认用户名和密码是
账号:admin
密码:admin
进入之后会要求修改一个新密码我们改为123456
这是我们进去之后的基本页面
我们将要将我们的k8s集群加入上去
点击data source 添加数据源
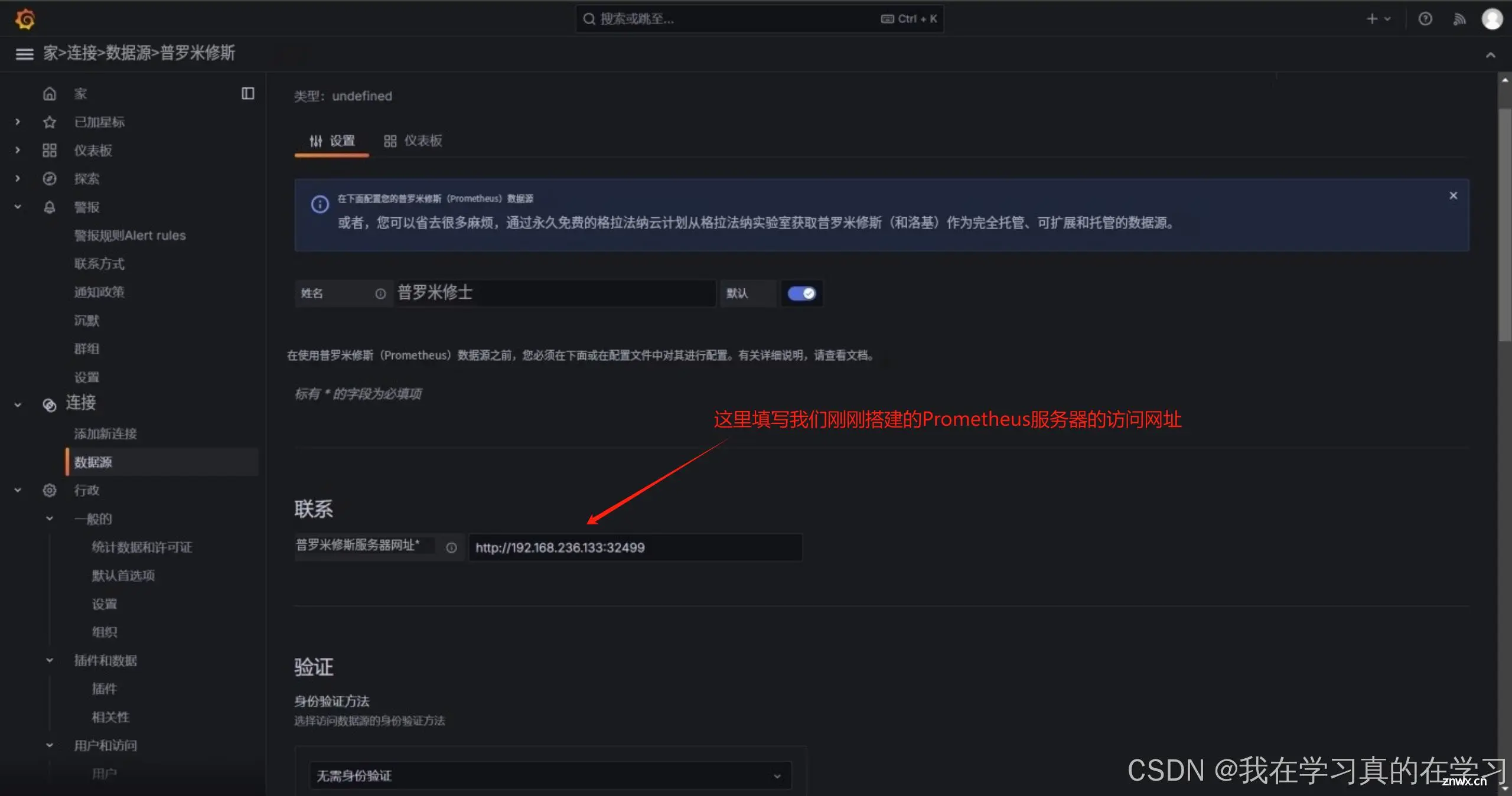
点击最下方保存并测试
回到data source页面

在侧边栏找到dashboard点击
点击import直接
导入模板
输入8919点击load
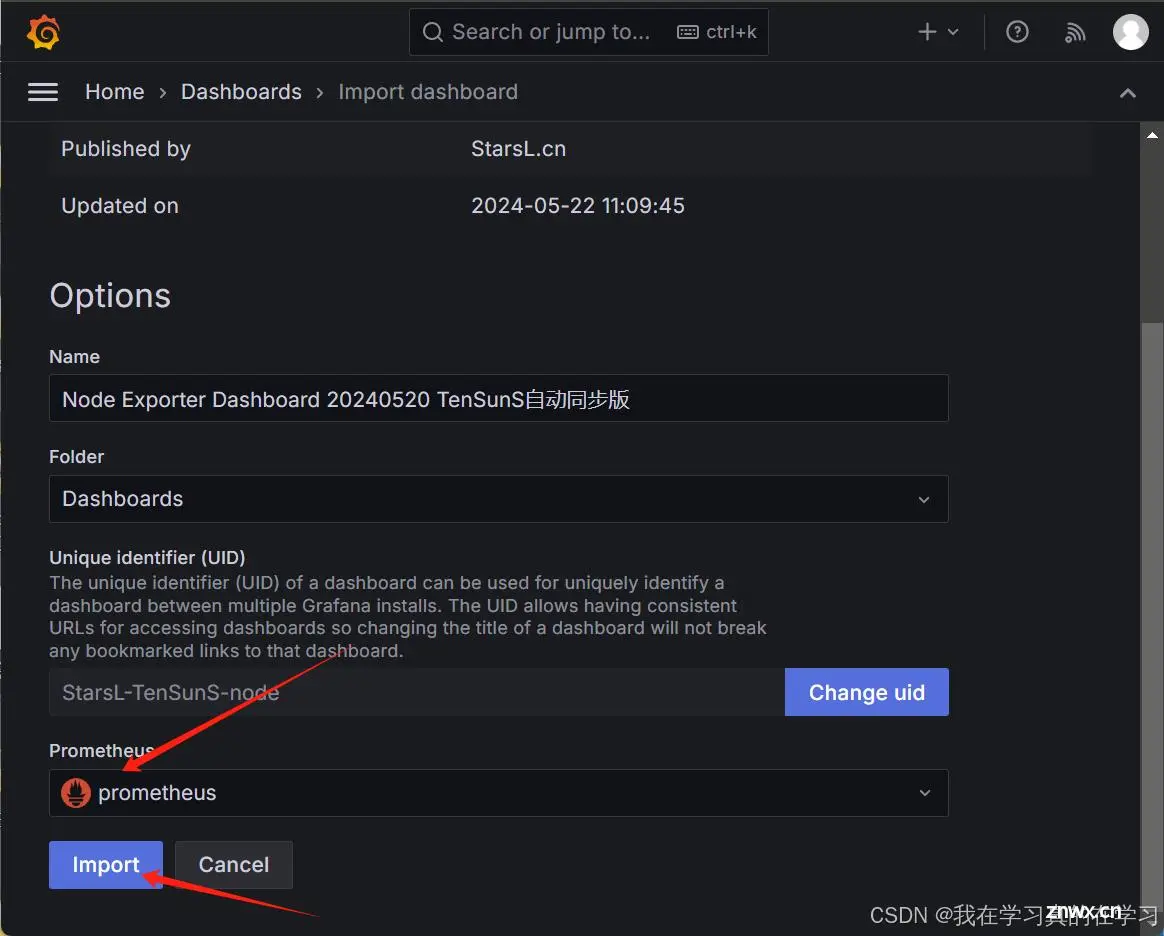
选择Prometheus后点击import
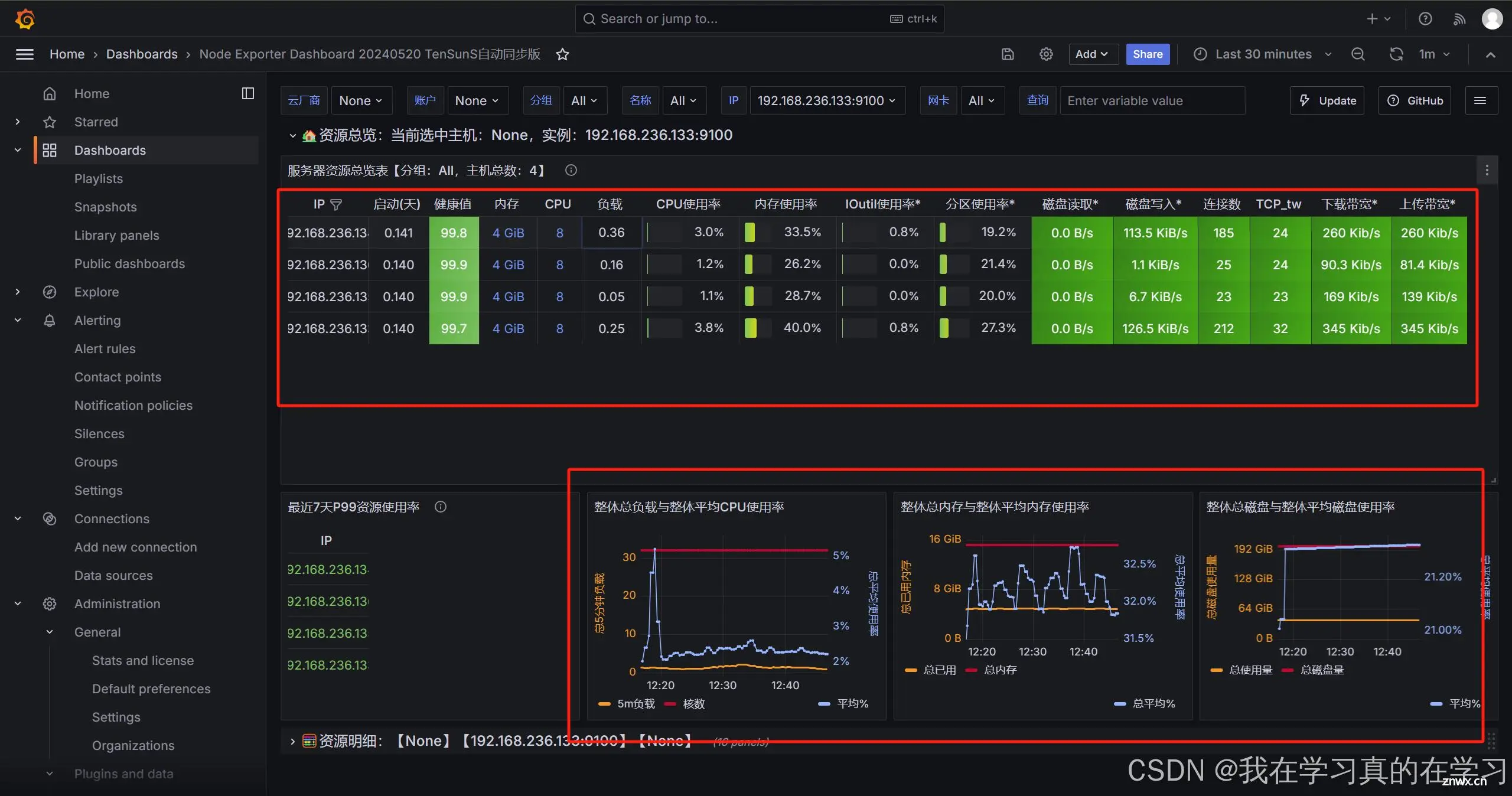
至此grafana搭建完成
8.k8s部署web页面
8.1 镜像制作
<code># 因为我们之前是使用sealos安装的所以k8s集群是基于containerd的,我们并没有docker环境,但是并不妨碍我们制作镜像
# 当然也会提供我的百度网盘拉取mysql镜像和制作镜像所需的文件
# 我这里使用VPS制作镜像主要原因是机器开不了第五台虚拟机了
链接:https://pan.baidu.com/s/1caRuss6FLELd7mEfxAz03A?pwd=jyp3
提取码:jyp3
--来自百度网盘超级会员V4的分享
# 使用ftp将我们的go文件传入vps
mkdir scweb
mv go+html+mysql+redis.zip scweb
cd scweb
unzip go+html+mysql+redis.zip
# 解压完成后会出现如下文件

<code>解析:
- **`server.go`**: Go 语言的核心程序代码文件,负责启动和管理 Web 服务器。
- **`Readme.md`**: 项目的说明文件,包含安装和使用指南。
- **`info.sql`**: 数据库的表结构和基础数据文件。
- **`static`**: 存放网站的 JavaScript 和 CSS 文件的目录。
- **`templates`**: 存放网站静态页面模板的目录。
- **`go.mod`**: Go 项目的模块依赖配置文件。
- **`go.sum`**: Go 项目中模块依赖的校验和文件,用于验证依赖的完整性。
# mod是包管理,sum是依赖关系管理
(1)部署golang环境
sudo apt update
sudo apt upgrade
sudo apt install golang -y
(2)初始化编译
# 我们这个包里面已经编译过了但是这里还是说一下
mv go.mod go.sum /root
# 把编译过的文件先弄走,直接删了也行
go mod init web
# 产生go.mod 生成网站所需要的依赖的库,写到go.mod文件里
go env -w GOPROXY=https://goproxy.cn,direct
# 配置一个国内的go语言下载库的代理网站
go mod tidy
# 获取依赖,生成go.sum
(3)修改源码并编译网站成二进制程序
const (
DB_USER = "root"
DB_PASSWORD = "123456"
DB_NAME = "root"
DB_HOST = "tcp(192.168.236.135:31377)/"
REDIS_HOST = "192.168.236.135:6379"
)
# 将server.go中的这一段配置根据自身情况进行修改
# 然后再build成可执行文件
go build -o server server.go
(4)部署docker环境
sudo apt install apt-transport-https ca-certificates curl software-properties-common -y
# 安装必要依赖包
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加docker官方GPG密钥
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 添加 Docker 的官方 APT 源
sudo apt update
# 更新 APT 包索引
sudo apt install docker-ce
# 安装docker engine
sudo systemctl start docker
sudo systemctl enable docker
# 启动docker服务
docker --version
# 验证docker安装
# 注意我是在香港的vps上做的,如果是国内服务器的话请参考文章
https://blog.csdn.net/qq_39500197/article/details/134754930?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522172387806016800180660345%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=172387806016800180660345&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-134754930-null-null.142^v100^control&utm_term=ubuntu%20docker%E5%AE%89%E8%A3%85%E6%8D%A2%E6%BA%90&spm=1018.2226.3001.4187
# 换镜像源的那一步请把镜像源换成https://docker.m.daocloud.io
(5)制作镜像
mkdir docker
cd docker/
cp ../server .
cp ../static/ . -r
cp ../templates/ . -r
最后我们的的docker文件夹下应该有这些文件

<code>docker load -i ubbuntu22.04
# 将我们centos7的镜像上传到images里
rm -rf ubuntu22.04
# 删除原先镜像
vim Dockerfile
# 编写镜像制作文件
FROM ubuntu:22.04
WORKDIR /go
COPY . /go
RUN chmod +x /go/server
ENTRYPOINT ["/go/server"]
docker build -t scweb:1.0 .
# 构建scweb镜像
docker save -o scweb.tar scweb:1.0
# 保存镜像并使用ftp从vps上拉取下来
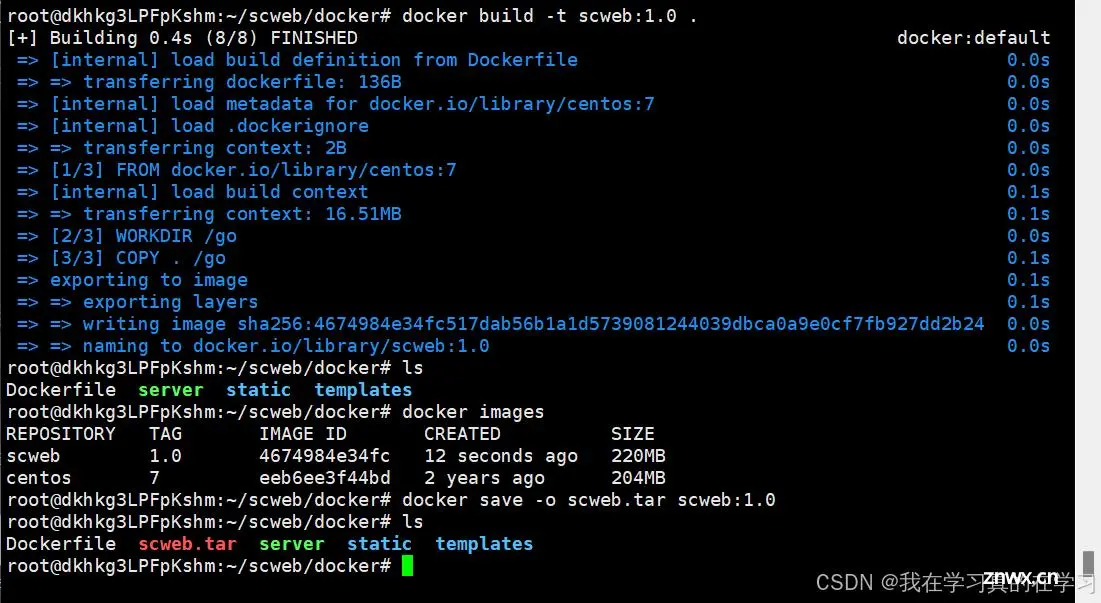
于此,镜像制作完成
8.2 网站搭建
8.2.1 mysql配置
<code>nerdctl load -i mysql:5.7.41
# 将我们的数据库镜像传入nerdctl images里面去
mkdir ~/web/mysql
cd ~/web/mysql
vim configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
namespace: default
data:
my.cnf: |
[mysqld]
default_authentication_plugin=mysql_native_password
bind-address = 0.0.0.0
vim mysql.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
namespace: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1 # 确保 MySQL 部署在名为 node1 的节点上
containers:
- name: mysql
image: mysql:5.7.41
env:
- name: MYSQL_ROOT_PASSWORD
value: '123456'
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-config-volume
mountPath: /etc/mysql/my.cnf
subPath: my.cnf
volumes:
- name: mysql-config-volume
configMap:
name: mysql-config
---
apiVersion: v1
kind: Service
metadata:
name: mysql-service
namespace: default
spec:
ports:
- port: 3306
targetPort: 3306
selector:
app: mysql
type: NodePort
kubectl apply -f mysql.yaml
8.2.2 scweb配置
使用ftp将我们刚做好的scweb传到master1节点上去
nerdctl load -i scweb.tar
# 将文件上传到nerdctl images里面去
mkdir ~/web/scweb
cd ~/web/scweb
vim scweb-Deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: scweb-deployment
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: scweb
template:
metadata:
labels:
app: scweb
spec:
containers:
- name: scweb
image: scweb:2.0
env:
- name: DB_USER
value: "root"
- name: DB_PASSWORD
value: "123456"
- name: DB_NAME
value: "root"
- name: DB_HOST
value: "192.168.236.133:31377" # 使用外部 IP 和 NodePort 端口
ports:
- containerPort: 8080
kubectl apply -f scweb-Deployment.yaml
vim scweb-service.yaml
apiVersion: v1
kind: Service
metadata:
name: scweb-service
namespace: default
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30288 # 曝露的 NodePort
selector:
app: scweb
kubectl apply -f scweb-service.yaml
kubectl get svc,pod -o wide
# 看我们开放的端口
访问网页http://<NODEIP>:30288

至此web页面不知完成,测试数据库是否能够使用,发现不能使用因为我们没有导入root表和数据
8.3 导入sql数据
<code>info.sql文件内容:
-- MySQL dump 10.14 Distrib 5.5.68-MariaDB, for Linux (x86_64)
--
-- Host: localhost Database: users
-- ------------------------------------------------------
-- Server version5.5.68-MariaDB
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;code>
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;code>
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `students`
--
DROP TABLE IF EXISTS `students`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `students` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`grade` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `students`
--
LOCK TABLES `students` WRITE;
/*!40000 ALTER TABLE `students` DISABLE KEYS */;
INSERT INTO `students` VALUES (1,'cali','2020级'),(2,'feng','2021级'),(3,'test4','2024级'),(4,'test5','2025级');
/*!40000 ALTER TABLE `students` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `users`
--
DROP TABLE IF EXISTS `users`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL,
`password` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `users`
--
LOCK TABLES `users` WRITE;
/*!40000 ALTER TABLE `users` DISABLE KEYS */;
INSERT INTO `users` VALUES (1,'cali','2022');
/*!40000 ALTER TABLE `users` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2024-06-10 0:37:41
(1)使用以下命令登录到 MySQL Pod
kubectl exec -it mysql-deployment-64fc9ddfcf-txbj7 -- mysql -uroot -p'123456'
(2)创建root数据库并使用
mysql> CREATE DATABASE IF NOT EXISTS root;
mysql> USE root;
(3)导入info.sql
exit
kubectl exec -it mysql-deployment-64fc9ddfcf-txbj7 -- mysql -uroot -p'123456' root < info.sql
(4)授予root用户权限
kubectl exec -it mysql-deployment-64fc9ddfcf-txbj7 -- mysql -uroot -p'123456'
-- 检查root用户权限
SHOW GRANTS FOR 'root'@'%';
-- 为 root 用户授予所有权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
-- 刷新权限,以使更改生效
FLUSH PRIVILEGES;
-- 查看用户与权限
SELECT user, host FROM mysql.user;
至此,以上步骤做完之后就可以使用了
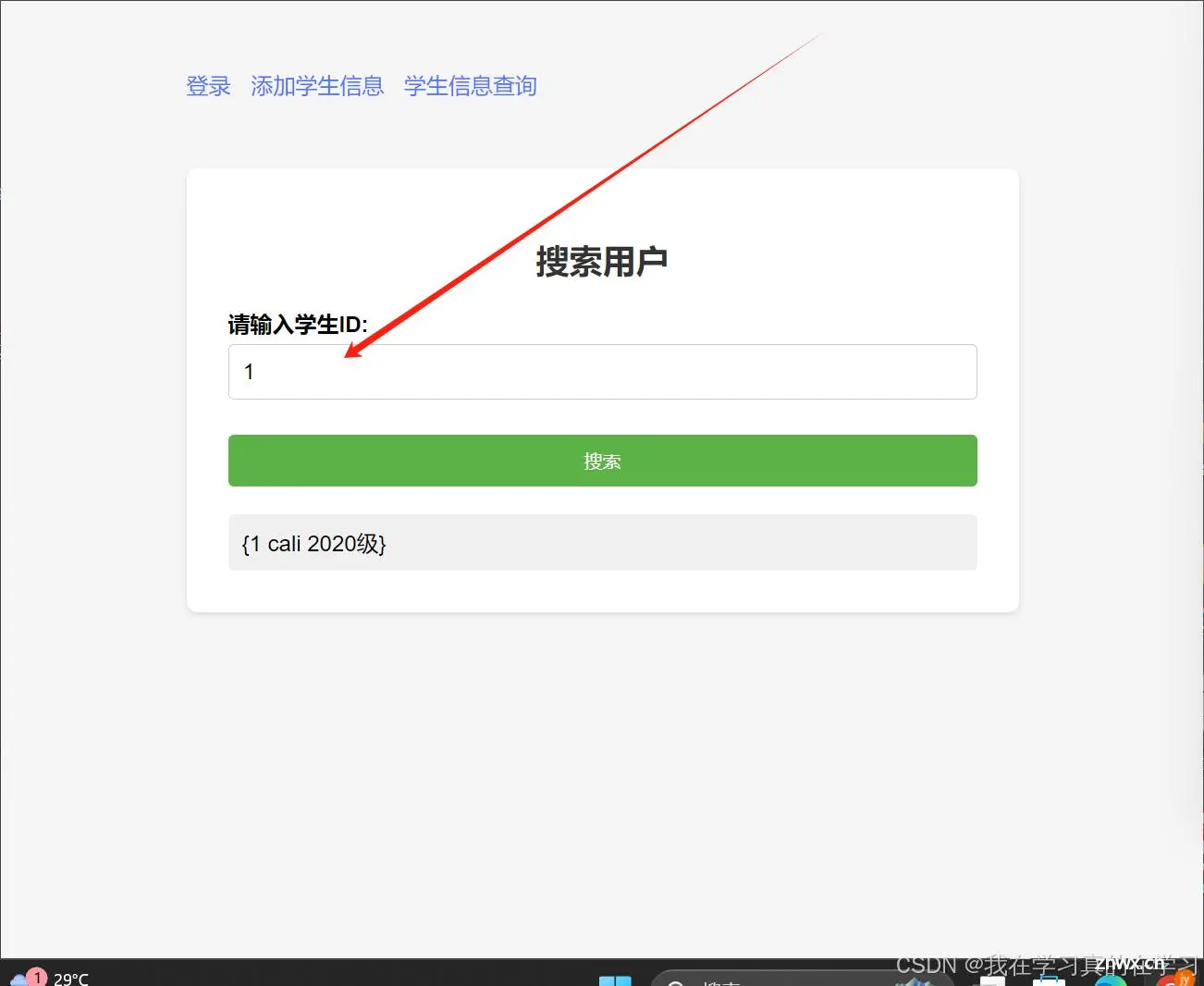
最终测试可以查询到即为成功。
9.心得体会
笔者也可以再次布置ansible自动化运维工具到上面去,但是目前正在研究怎么将scweb与mysql加入Prometheus使得其能进行监控,yaml文件写了很多但是最终测试还是无果,后续如有进展可能会将k8s中pod里的Prometheus监控pod里的动态web网页,与pod里的ansible自动化运维工具发出来。
人生从不是一帆风顺,正如这篇文章一样,当我做到使用helm拉取镜像却无一完全成功时,问题已经很难解决了,但是最终还是通过自己配置自动化扩容的方式解决了问题,运维最可怕的不是学了多少,而是解决了多少问题,积累了多少经验,于此,诸君共勉。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。