前端渲染页面的原理
前端-珊珊 2024-06-23 15:33:02 阅读 90
之前一直不愿意写一篇关于原理的,因为说起来实在是太繁杂,要写得细,码字梳理,计算下来起码都要差不多三周。以前一直躲避这个事情,现在反正有时间,为了不荒废自己,那就从头捋一遍。也方便自己后期回忆。
这篇文章总结就是带你了解:用户输入一个地址按回车到页面出现都发生了什么。
一、网络层知识补充
开始之前,先补充一下网络层协议的相关知识点,如下图:

这张图展示了网络层主要涉及到的传输协议,前端需要注重的是HTTP和TCP和SSL协议,当然要想了解IP传输协议也是可以的(你们自己去了解,每个字段代表什么,计算IP地址什么的,太多内容了,细讲有点占篇幅)。
1. HTTP协议的补充
提到HTTP协议,HTTP协议的发展史就不得不提了,毕竟涉及到HTTPS和HTTP的区别。那就走一波呗。
HTTP是怎么出现的呢?它是为了实现传输HTML而专门设计的协议。在HTML没有出来前,基本信息的录入都是人工读卡或者手动录入,这些信息需要共享或者校对都比较麻烦。懒的人都很擅长找解决方案,所以有两位帅哥就想能不能让这些数据在某个地方实现快速查找的同时又能共享数据,这样既减轻工作量又保证了信息准确性。于是HTML就产生了,产生了之后要传输,怎么办呢,没有传输的协议,我就创造一个呗,于是HTTP最初版本出现,第一版的HTTP协议很简单,没有版本号,只支持传输文本,只支持GET方法,简称0.X版本吧,它只支持返回指定路径里的数据。
1.1 HTTP1.0
随着发展,第一版的协议已经没有办法满足需求,所以HTTP1.0出现了。
HTTP1.0需要解决的问题及解决方案如下图:
| 问题 | 解决方案 | |
| 1.只支持HTML,没法实现更复杂的操作(如上传,下载文件) | 引入content-type字段,text/plain纯文本,text/html纯HTML格式,
application/octet-stream二进制数据流,application/x-www-form-urlencoded 等等 | |
| 2.没有缓存的概念,造成资源浪费 | 引入"Expires"和"Cache-Control"字段进行缓存控制 | |
| 3.传输的是文本,http0.x版本用的是ASCII码字集,没有进行压缩,文件 | 头部增加content-encoding:gizp字段,进行压缩传输 | |
| 4.没有错误处理机制 | 引入标准错误状态码提示:403,404,500等 | |
虽然HTTP1.0比HTTP0.X版本更灵活,但0.X版本遗留的部分问题并没有解决(比如请求一次建立一次TCP链接),HTTP1.0出现的缓存不够灵活等,所以HTTP1.1应运而生。
1.2 HTTP1.1
HTTP1.1需要解决的问题及解决方案如下图:
| 问题 | 解决方案 |
| 1.每一个请求都需要建立TCP连接,然后再释放,造成了极大的资源负担 | 建立长链接,一个TCP链接内运行多个请求和响应,提高了资源的利用 |
| 2.缓存上在短时间内(1s内)修改无法识别(last-modified) | 新增ETag"和"If-None-Match字段(这儿一两句说不明白,建议看相关文档,于我而已就这点突出些) |
| 3.请求头的method只有get,post,head方法 | 新增put,options,delete等字段,更灵活更准确 |
| 4.在不确定服务器是否会接收该资源就发送body,占用带宽 | 新增预检功能,先只发header确认服务器是否有权限请求,有再发送body,节约带宽 |
| 5.每台服务器绑定唯一的ip地址,造成资源浪费 | 增加host字段,引入虚拟主机概念,合理利用服务器资源 |
| 6.涉及到用户隐私数据时,有泄露信息的风险 | 引入ssl证书(后续多引入tls)用于保护数据的安全和用户的认证 |
目前国内大部分都在用HTTP1.1版本,那么怎么优化HTTP1.0存在的问题呢?
1.2.1 HTTP1.1的优化
1.使用CDN加速,静态资源放于CDN上,让资源更靠近用户,加快获取速度,减少延迟;
2.使用雪碧图,哈哈,这点不用说大家都知道,还不是为了减少请求,减少队头阻塞;
3.使用缓存机制,重复的资源自己从浏览器获取,减少服务器的压力;
4.启用Gzip压缩,减少传输数据的大小,减少网络传输的时间;
5.域名分片,将网站的资源分布在多个子域名下,实现更高的并发连接数(毕竟浏览器对不同域名没有限制)。
市面上目前常用的还是HTTP1.1版本,但HTTP1.1是最好的吗?当然不是,毕竟HTTP2.0早就出来啦。它解决什么问题呢?
1.3 HTTP2.0
HTTP2.0处理HTTP1.1的问题和解决方案:
| 问题 | 解决方案 |
| 1.每个tcp长连接里面处理http请求有限 | 引入多路复用概念。允许单个TCP连接并发处理多个请求,并且不再依赖tcp连接实现多流并行 |
| 2.客户端没有进行请求服务器不会主动推送资源给客户端 | 支持服务器主动推送,提前缓存可能需要的资源,从而减少延迟和提高性能,减少ssr的时候白屏时间,大大提升用户体验 |
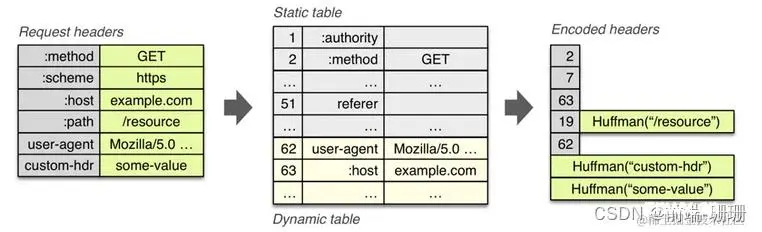
| 3.头部越来越重,即使开启Gzip压缩可以压缩body,头部字段过多的问题并没有办法解决 | 使用Hpack算法压缩,即静态字典+动态字典+Huffman编码(压缩方法)使得头部的体积也减小 |
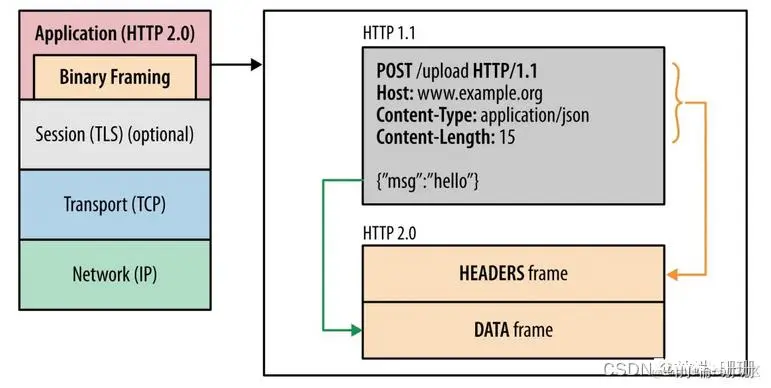
| 4.头部用的是纯文本传输,占较大的传输空间,并且有很多固定字段,如cookie,user-agent等,每次请求都会跟上,造成资源浪费。每个请求都带完整的header,即使后面两个请求都带一部分相同的header,造成了重复传输,浪费了带宽 | 用二进制分帧的形式,将header和body分为两个流,一个header frame,一个data frame。 |
| 5.队头阻塞,按顺序返回数据,没有优先级说法,谁先请求先响应谁 | 由于第四点引入了帧的概念,因为每个帧都包含一个特定的类型和标识符以及帧的有效载荷。多个帧会形成流stream,每个流有唯一的标识符。在发送请求时可以设置帧的优先级,帧可以交错的发送,也能进行流级别的流量控制 |
对比是写上了,那对应的HTTP2.0用的技术并没有体现怎么转的,那下面就引用一下参考的第一个链接作者的图吧
1.Hpack算法压缩展示如下图:
2.二进制分帧的形式与文本传输的区别如下图:
最后,是1.0到2.0之前的发展史,一目了然的图(不要问我为什么没有3,因为它没面世)

1.4 HTTP3.0
HTTP2.0看起来用流解决了很大的问题,但只是单纯的解决了HTTP协议上的头部问题,对于传输层的TCP协议的队头并没有优化,TCP协议的请求头依旧很繁重,而且建立起TCP握手时间长。基于这个因素,谷歌决定推出HTTP3.0版本,舍弃TCP协议。舍弃TCP转而使用UDP协议。
HTTP/3.0在基于UDP+迪菲赫尔曼算法(Diffie–Hellman)之上实现了QUIC协议(Quick UDP Internet Connections)
可能有人会说,UDP是不可靠传输,它只是尽最大努力交付,这样数据丢失的问题怎么解决?嗯,基于目前用的UDP当然是不足以替代TCP。但是它修改了呀,QUIC协议是在原UDP的基础上做了改造,使得它提供了和TCP类似的可靠性。它提供了数据包重传、拥塞控制、调整传输节奏以及其他一些TCP中存在的特性。即拥有无序并发字节流,又拥有稳定性,还能用TLS1.3新的安全协议,真的很让人期待啊。
思考了一下,单纯说TCP头部重,很多人没概念,那我就上张TCP头部的图吧(哈哈,上学的时候考试要标注,可以忽略写的文字哈!)

看上图就知道头部的臃肿度,舍弃TCP是明智的。
2.域名系统DNS
为什么要提DNS呢,主要是为了了解什么是根域名,什么是顶级域名,它们之间有什么关系,本地服务器是怎么走DNS解析拿到IP地址的。先上图:

看图能知道,根域名服务器→顶级域名服务器→权限域名服务器(权限下面又可以细分,如图二级域名,三级域名)
记得本地域名服务器不属于上图哦(本地域名服务器后面要用到的哦)
寻思了一下就先补充这些吧,后续需要补充的再加。
二、算法知识补充
这儿需要补充的是二叉树相关的知识点,只是简单了解,本文不会延申到深度遍历和广度遍历。
什么是树?树就是一个根,上面很多树杈子,这样就叫树,方便理解上张图:

注:图内画红圈可以忽略
二叉树是一种特殊的树形结构,它的特点是每个节点至多只有两棵子树。这儿要注意的是:二叉树的子树有左右之分,它的次序是不能任意颠倒的
二叉树又有几种类型:满二叉树、完全二叉树、非完全二叉树。怎么辨别呢,如下图:
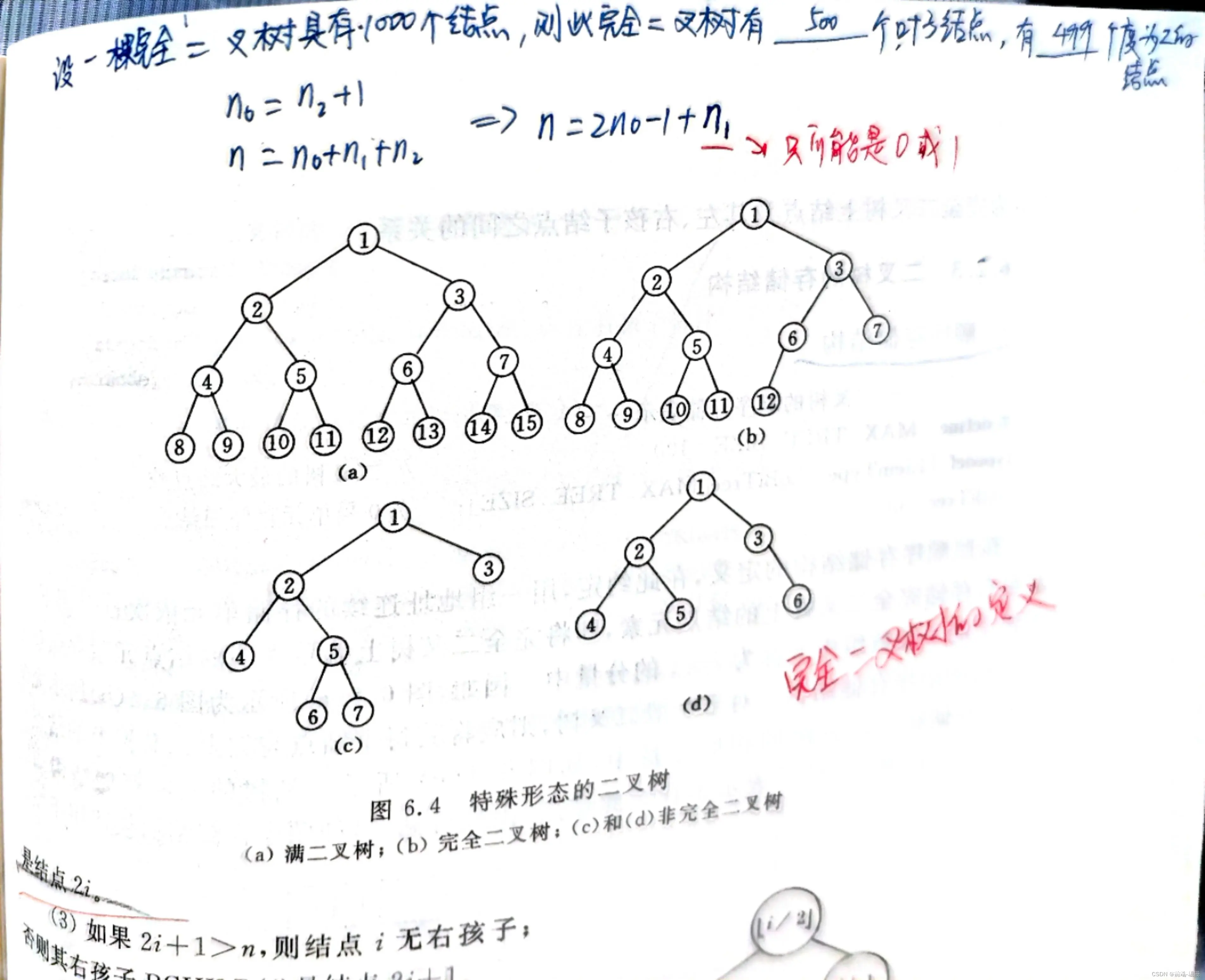
满二叉树最大的特点是每一层上的节点数都是最大的节点数(满二叉树的第i层上有2的i-1次方个结点)
完全二叉树:如果对满二叉树的结点进行编号, 约定编号从根结点起, 自上而下, 自左而右。则深度为k的, 有n个结点的二叉树, 当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时, 称之为完全二叉树
看上面两个定义应该能发现,满二叉树是完全二叉树的特殊形态
这里就了解这么多,知道什么是二叉树就好,至于广度遍历和深度遍历感兴趣的自行了解哈。
三、渲染原理
1 DNS解析IP地址
用户输入"y.abc.com"点击回车键开始,首先发生的第一步是将域名转为IP地址,如果本地域名服务器有缓存该域名的IP地址就会直接向IP请求,如果在本地域名服务器没有缓存,那么就要用到域名解析系统“DNS”,那么它是怎么从域名转为IP地址呢?看下图:

由上图可知,DNS解析有两种解析方式,一种是迭代查询,一种是递归查询。根域名和顶级域名的关系在上面网络层知识补充上有,有点懵的可以回头看哦。
单单看图可能有点不太理解,那我就详细写一下迭代查询的步骤:
(1)主机m.xyz.com先向其本地域名服务器的dns.xyz.com进行递归查询;
(2)本地域名服务器采用迭代查询。它先向一个根域名服务器查询;
(3)根域名服务器告诉本地域名服务器,下一次应查询的顶级域名服务器dns.com的IP地址;
(4)本地域名服务器向顶级域名服务器dns.com进行查询;
(5)顶级域名服务器dns.com告诉本地域名服务器,下一次应查询的权限域名服务器dns.abc.com的IP地址;
(6)本地域名服务器向权限域名服务器dns.abc.com进行查询;
(7)权限域名服务器dns.abc.com告诉本地域名服务器所查询的主机的IP地址;
(8)本地域名服务器最后把查询结果告诉主机m.xyz.com。
递归查询也是类似上面的步骤。上面两种方式具体选哪个主要是看本地域名服务器自己选哪个方案。
到这肯定有人会问,那每次本地每次都直接去根服务器去找,那根域名服务器压力得多大啊,全球也就13台根域名服务器(tips:不是说只有13台机器,比如一个m根服务器可以在多个地点安装根域名服务器)。嘿嘿,我们能想到的,别人怎么可能不早早就想到呢!为了提高DNS的查询效率,在域名服务器中广泛运用高速缓存域名服务器。用它存放最近查询过的域名以及从何处获得的域名映射信息的记录。例如:在不久前已经有用户查询过y.abc.com的IP地址,那么本地域名服务器就不必向跟域名服务器重新查询y.abc.com的IP地址,而是直接把高速缓存中存放的上次查询结果告诉用户。还有一种方式本地域名服务器的缓存没有y.abc.com的IP地址,但存放有顶级域名服务器dns.com的IP地址,那么本地域名服务器可以直接找顶级域名服务器查询请求报文,减少根域名服务器压力的同时也减少了DNS的查询请求和回答报文的数量。(写多了写多了,感兴趣的自己去百度吧)
2 浏览器与服务器建立TCP连接
拿到IP地址之后就是要进行TCP连接。连接的图如下:
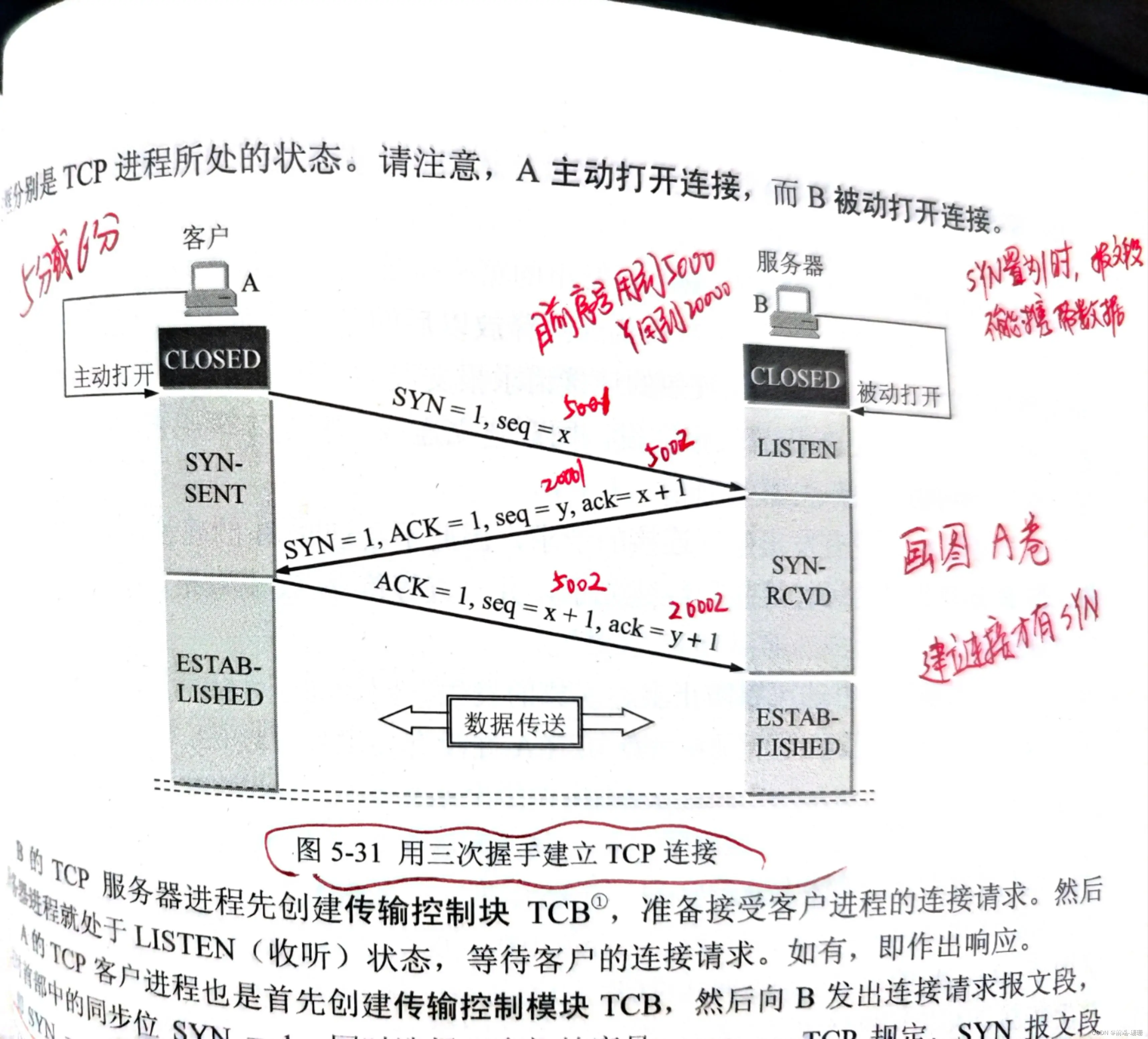
我懒得画图啦,直接就上计算机网络书本的图哈。
TCP三次握手建立连接需要注意哪些事项呢?
(1)客户端和服务器传的SYN都为1的时候双方建立起连接
(2)SYN=1时报文段不能携带数据
(3)为什么要确认一次呢(最后一次的ACK=1)为了防止已失效的连接请求报文段突然又传送到服务器。防止资源浪费的同时确认双方的收发能力。
TCP建立起连接后就要看输入的连接是HTTP还是HTTPS啦。
这儿提出个欠欠的问题:websocket是长连接,那么它经不经过三次握手呢?
嗯,在网络里面,传输的就TCP和UDP,UDP是出了名的不可靠传输(别拿http3说话昂,毕竟这玩意还在开发中,websocket可是早就有了),那只剩下TCP了,所以要建立起稳定可靠的,是不是必须经过TCP这点是不是一下子就清楚了?
3 建立起TCP连接后进行SSL连接
首先这步有没有主要看输入的地址有没有https(有才需要校验SSL证书),有才需要这一步,没有就跳过这一步。(这儿需要注意一下,http和https是两种不同的协议,它们一点关系都没有,http走的是80的端口,而https走的是443的端口)
写到这里了我都在犹豫要不要细写SSL建立的过程,算了,既然我自己做不了决定,那就写一版粗略的,写一版细的,看文的自己选择性看呗。
3.1粗略版SSL建立连接
下图是别的作者画的图(参考链接3的图),我引用一下,自己懒得画了(懒是程序员第一生产力,哈哈哈!)

这是粗略版的SSL的连接过程,这儿需要注意三个点:
(1)此时HTTP请求并没开始,记好咯,不要等会别人问ssl发生在http请求前还是请求后都回答错咯
(2)SSL证书也是有过期的说法的哦,具体看买几年的,一般小公司都是买一年然后续证的
(3)会存在中间人攻击,不过达成的条件是客户端也要有相关中间人证书,否则这个危险不会发生。
3.2详细版SSL建立连接
详细版,那就要从由来开始,一开始HTTP0.X协议,传输都是明文,是HTTP1.1后出现的加密(看HTTP补充1.3里三个协议的对比就知道加密在什么时候用了)。
由于是双方进行通讯,所以考虑的一般是能双方进行加解密的方式,所以选择上暂时只有对称加密和非对称加密
3.2.1对称加密
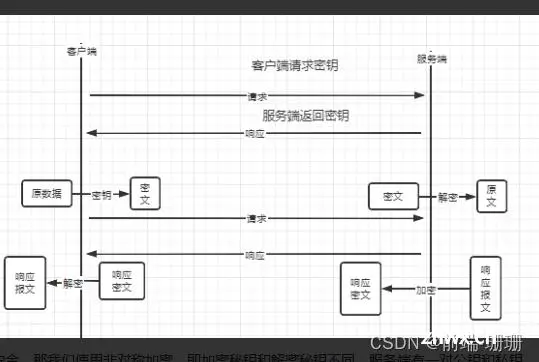
对称加密优势: 算法公开、计算量小、加密速度快、加密解密效率高,适合大量数据的加解密
对称加密的劣势:交易双方都使用同样钥匙,安全性得不到保证,容易遭受黑客攻击。
3.2.2非对称加密
由于对称加密安全性得不到保证,所以用非对称加密,加密密钥和解密密钥不同。服务端有
一对公钥和私钥,公钥用于加密,私钥解密;私钥用于加密,公钥解密。
第一种方案:直接用公钥加密,如下图:

请求的过程:
客户端请求公钥 → 使用公钥加密,传输数据 → 服务端使用私钥解密,获取到请求原文
响应的过程:
服务端使用私钥加密,返回加密数据 → 客户端使用公钥解密,获取响应报文。
存在的问题:
请求阶段,是公钥加密,公钥不能解密,所以请求是安全的。但响应阶段,黑客同样可以获取到公钥,在响应阶段,黑客介入,使用公钥对密文解密,响应是不安全的。
由上可知,直接用公钥私钥加密不够安全,那怎么办呢?第二种方案就出来了。
3.2.3 非对称加密+对称加密
第二个方案就是双方共同利用 random_c + random_s + pre-master生成随机master secret,后续都用这个加密的随机数进行通讯即可。在生成随机数进行沟通时走的是非对称加密,到后期双方用加密后的随机数进行通讯走的是对称加密
如下图(其实就是粗略版那张图):
这样是不是就安全了呢?嘿嘿,当然不是啦!不然怎么会有中间人攻击这个定义出来呢,对吧?如下图:
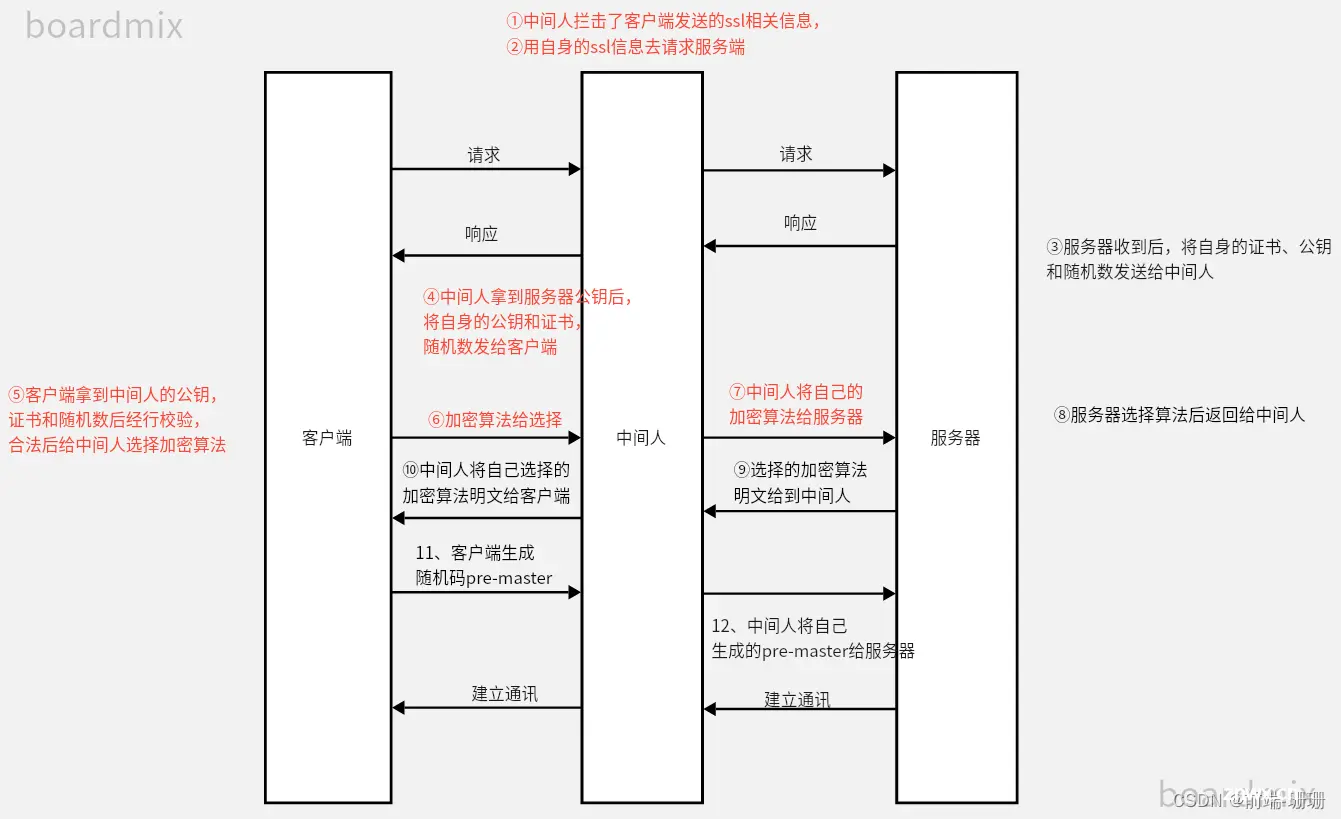
图上表明了中间人介入的情况,那么是不是中间人防不胜防呢?也不是的。主要有两点:
①中间人向客户端发送公钥时,客户端就会询问你:“此网站的证书存在问题,你确定要信任这个证书么。”所以从这个角度来说,其实 HTTPS 的整个流程还是没有什么问题,主要问题还是客户端不够安全。
②中间人攻击需要客户端也有相关中间人证书,否则也不会产生这个危险。
3.2.4 非对称加密+对称加密+ca公钥
中间人攻击主要是利用传递公钥做文章,那我们在传的时候可不可以不传公钥呢?嘿嘿,这时候强大的CA机构该出场啦!
首先操作系统内已经内嵌CA机构的公钥cpk。CA机构有一对公私钥cpk/csk。服务端也有一对公私钥pk/sk。服务端(花钱买的ca证书)把自己的公钥传递给CA机构,CA机构使用csk对pk进行加密得到ca.密文,CA把这个ca.密文返回给服务端,后面客户端请求服务器都传ca.密文,客户端得到这个ca.密文后,根据自己操作系统中内嵌的CA机构的公钥cpk就能解开这个ca.密文。这个思路看起来很安全是不是?但是不要忘记咯,ca的公钥cpk是公开的,黑客也知道,很容易的就能对ca.密文进行截胡,也就能够知道服务端公钥pk。所以还是会存在中间人攻击,如下图(参考资料4作者的图):

这么分析下来,还是有中间人攻击,怎么办呢?那能不能让CA机构直接对服务端进行认证一下是正牌服务端而不是伪服务端呢?答案是有的,毕竟安全无小事嘛!
3.2.5对称加密+非对称加密+CA证书
ca机构在上面的基础上,再加上对合法的服务端做认证,这样就安全了。怎么进行安全认证呢,当服务端把公钥给了ca机构,ca机构会对这个服务端做背景调查(域名、公司名、法人...),然后ca机构会向服务端下发证书。最重要的一点是服务端公钥和域名绑定。客户端浏览器访问服务器时,首先通过ssl协议443端口获取服务端证书,浏览器会对证书做校验(最重要的一点是校验服务端域名和服务端公钥绑定关系)
下面我们一起看看证书得示例(点击网址前的安全锁符号,进入详情),如下图:
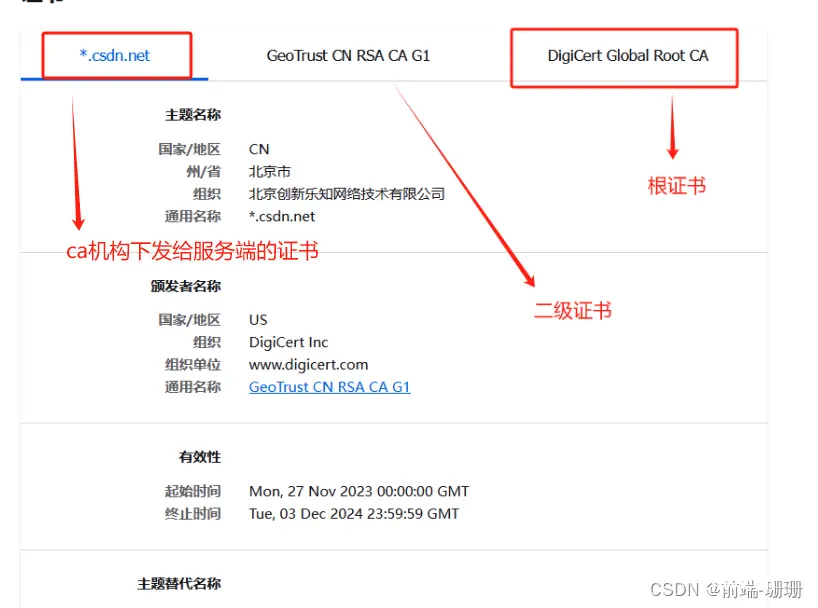
1、证书的签发过程:
(1)服务方 S 向第三方机构CA提交公钥、组织信息、个人信息(域名)等信息并申请认证;
(2)CA 通过线上、线下等多种手段验证申请者提供信息的真实性,如组织是否存在、企业是否合法,是否拥有域名的所有权等;
(3)如信息审核通过,CA 会向申请者签发认证文件-证书。
证书包含以下信息:申请者公钥、申请者的组织信息和个人信息、签发机构 CA 的信息、有效时间、证书序列号等信息的明文,同时包含一个签名;
签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用 CA 的私钥对信息摘要进行加密,密文即签名;
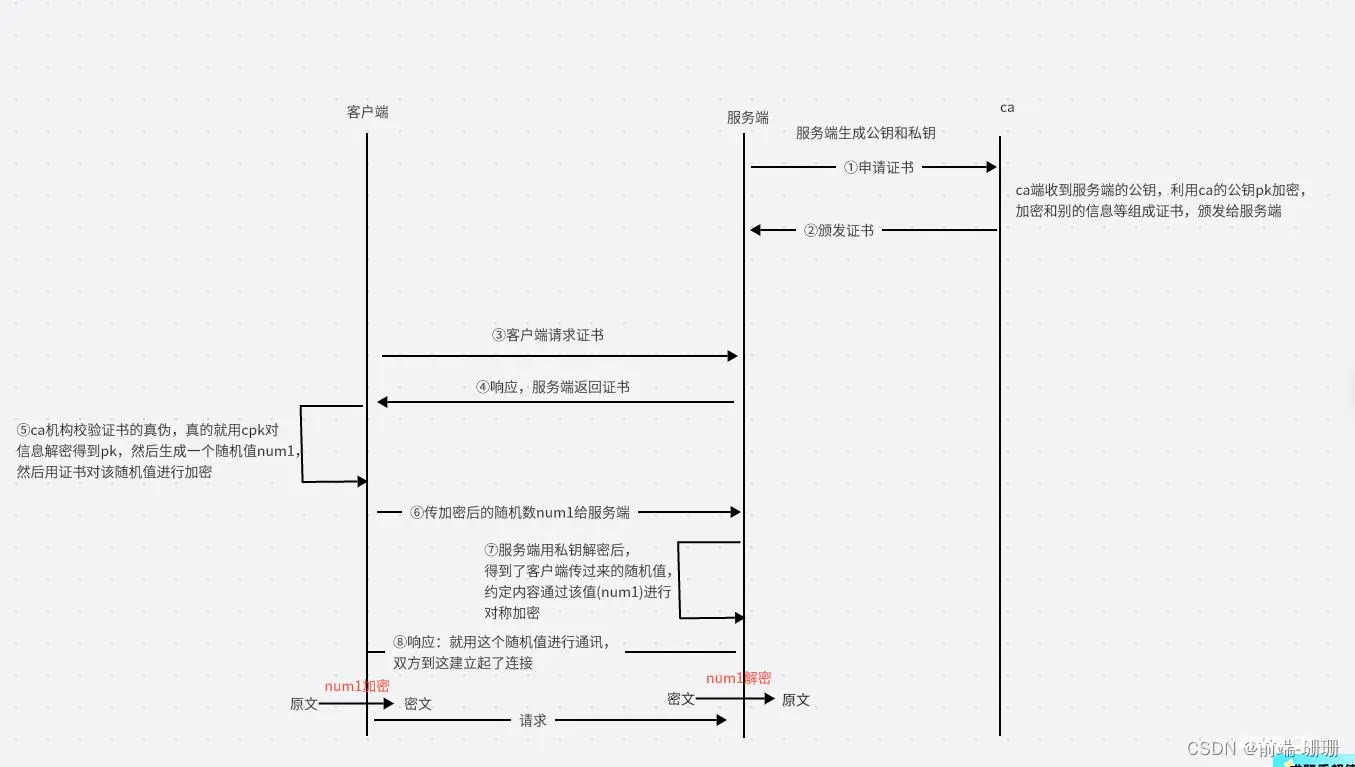
2、请求和响应的详细过程
步骤如下:
(1)申请证书
(2)颁发证书 (ca端收到服务端的公钥,域名之类的信息,利用ca的公钥pk加密,加密和别的信息等组成证书,颁发给服务端)
(3)客户端请求获取证书
(4)响应,服务器返回证书
(5)ca机构校验证书真伪,利用cpk解密得到pk,生成一个随机num1,传加密后的随机数num1给服务端
(6)传加密后的随机数num1给服务端
(7)服务端用私钥解密后,得到了客户端传过来的随机值,约定通过该值(num1)进行对称加密
(8)服务端响应客户端:就用这个随机值进行通讯,双方到这建立起了连接
(9)双方根据这个随机num1进行加密数据传输和解密获取数据
步骤描述如下图:
这儿可能有人会问,HTTP请求结束了,那ssl连接是不是也跟着断了呢?答案是否定的,ssl连接是跟TCP挂钩的,只要TCP不断,它就不会断。
4 建立HTTP请求,传输数据
TCP连接建立,安全链接也建立起来后,就可以到http的请求过程啦。http请求我觉得没有多少可说的,那就想到什么说什么吧。

如上图就是http的请求,general部分主要是请求的路径,请求的方法和返回请求的状态码。request headers就是设置部分固定参数,其实http知识补充部分就已经讲了一些固定的字段或者搭配,这儿值得再讲一讲的就是Connection:keep-alive。这代表这次请求完成后希望继续保持连接不断开。
下图为请求时候自己接口需要的参数。
嗯,其实http暂时觉得没有什么好讲的,要是有人觉得哪些值得讲讲的可以私我呀,我可以补充。
那么就讲讲 RESTful API 这个规则吧。RESTful API (Representational State Transfer API) 是基于 HTTP 协议的一种 Web API 设计风格,具体就如下:
使用 HTTP 方法处理资源:GET、POST、PUT、DELETE 等;使用 URI 标识资源;使用 MIME 类型(如 JSON 或 XML)传输数据;无状态性:每个请求都是独立的,服务器不会保存客户端的状态信息。
为什么需要RESTful API呢?因为这样我们可以一目了然的看见客户端和服务器之间传递数据,比如数据的增、删、改、查等操作。在构建 web 应用程序时,我们可以使用 RESTful API 来实现后台服务与前端页面之间的数据交互。具体例子如下:
(1) 设计资源和 URI:确定需要提供哪些资源以及每个资源的 URI,例如 /users 表示所有用户资源,/users/:id 表示单个用户资源。
(2)实现资源的 HTTP 方法:实现 GET、POST、PUT、DELETE 等 HTTP 方法,根据请求的 URI 执行相应的操作。例如:DELETE 方法,就是url + `/role/${roleId}`,GET获取列表
(3)返回数据:使用 MIME 类型(如 JSON 或 XML)返回数据,客户端使用这些数据进行展示和操作。
(4)安全性和认证:根据需要添加认证和授权机制,确保只有授权用户可以访问和操作资源。
讲了这个之后,想引出一个疑问:http的请求有限制吗?限制多少个请求?
答案:http请求没有限制,即使在一个tcp里面也不会限制http的请求,请求需要排队等待而已。
5 是否走缓存
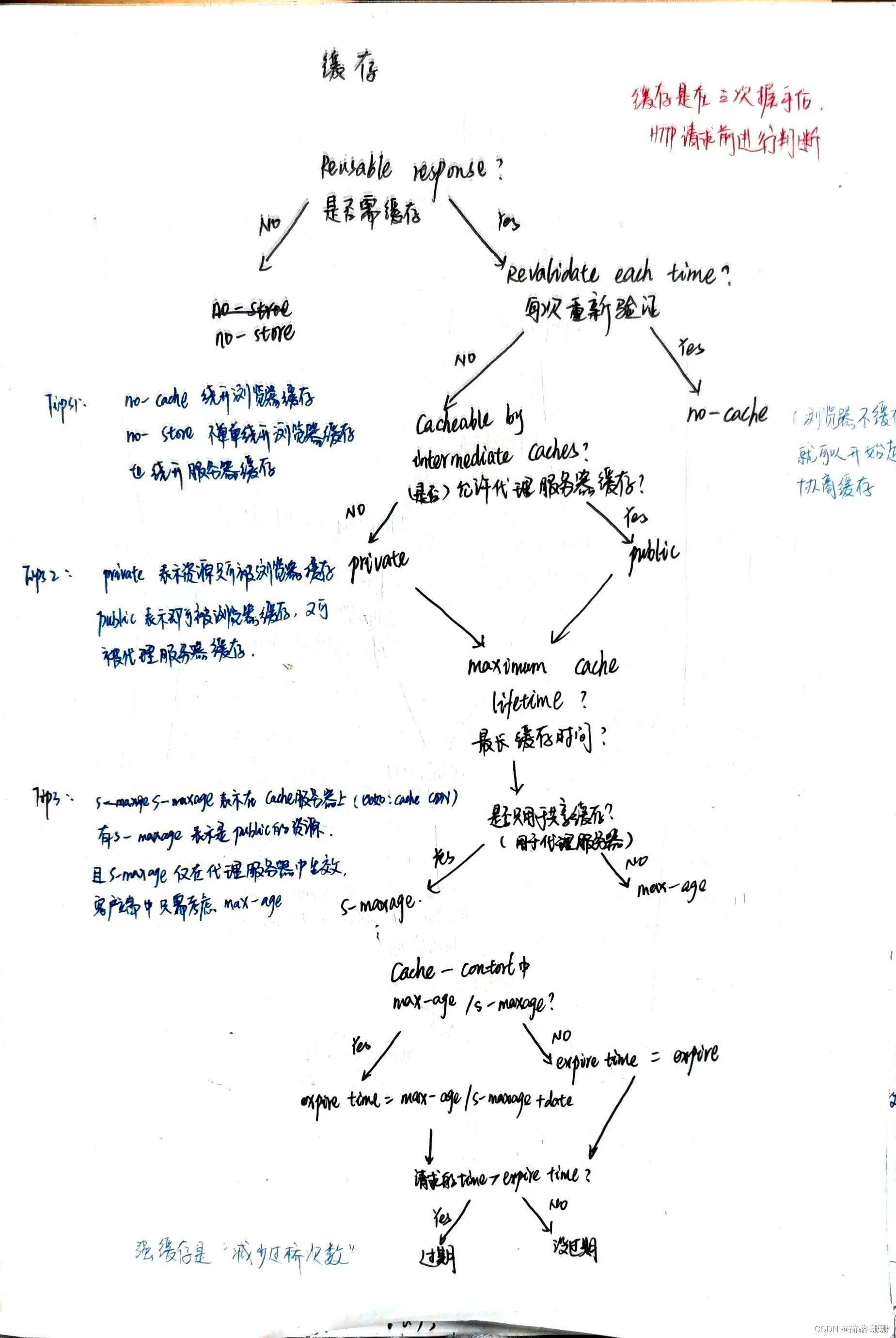
按理,缓存是在HTTP请求前讲的,因为在请求前就要判断是否有强缓存,强缓存的话是直接读取就好,但貌似目前用更多的是协商缓存,而协商缓存是经过HTTP的,所以将缓存放到HTTP建立后聊聊。以下是强缓存的全部内容,步骤如下:
(1)浏览器发送HTTP请求前,先访问浏览器缓存,是否需要缓存,如为否的话,就默认为no-store,不启用缓存,每次都直接走请求
(2)启用缓存的话,再判断是不是每次都重新验证,是的话就默认为no-cache,(不存缓存在浏览器,但可以进行协商缓存)
(3)不是每次都重新验证,就看看是否允许代理服务器缓存,不允许就只运行浏览器缓存,允许两者都缓存
(4)看看cache-control种的max-age或者s-maxage(这个字段是代理服务器特有的),还有expires,计算缓存时间是否过期,若过期则重新请求,没过期则直接拿强缓存的内容
看下图,注意事项也在下图,看图片也挺清晰的,懒得打字啦!
走完强缓存后,就到协商缓存。步骤如下:
(1)在上面步骤2,在no-cache的时候看看是否有协商缓存,没有的话直接进行请求,有的话判断缓存是否过期,没过期直接使用缓存的内容,返回相关内容
(2)已经过期的先判断ETag(资源的唯一标识字符串)是否存在,存在的话向服务器发送请求,并在头部携带if-none-match字段(值为1),服务器返回304则读取本地的资源,返回200则资源发生了变化,请求响应,协商缓存,最终都是返回需要展示的资源。
(3)如果ETag不存在,则去判断Last-modified存在吗,不存在直接向服务器发送请求获取资源,存在的话向服务器发送请求并在头部携带if-modified-since字段(值为1),服务器返回304则读取本地的资源,返回200则资源发生了变化,请求响应,协商缓存,最终都是返回需要展示的资源。
具体如下图:

由于这张图片的tips模块文字有点不太清晰,我写一遍
tips1:ETag的生成需要服务器的额外开销,会影响服务端的性能,所以使用ETag要审时度势
tips2:分布式系统尽量关闭ETag,每台机器生产的ETag都不一样,last-modified是必须保存一致的。
tips3:用ETag的原因是last-modified如果改动太快(100ms)而if-modified-since监听的是秒,会被误以为没有改动而导致该请求的没请求。或者是编辑了文件,因为文件内容没改变,仍通过最后编辑时间进行判断,产生不该请求的时候请求了。
6 数据获取后断开TCP连接
该从缓存取得资源取了,该通过HTTP请求获取资源的获取完成了,那么就到了断开连接的时候啦。
下图为四次挥手的过程:
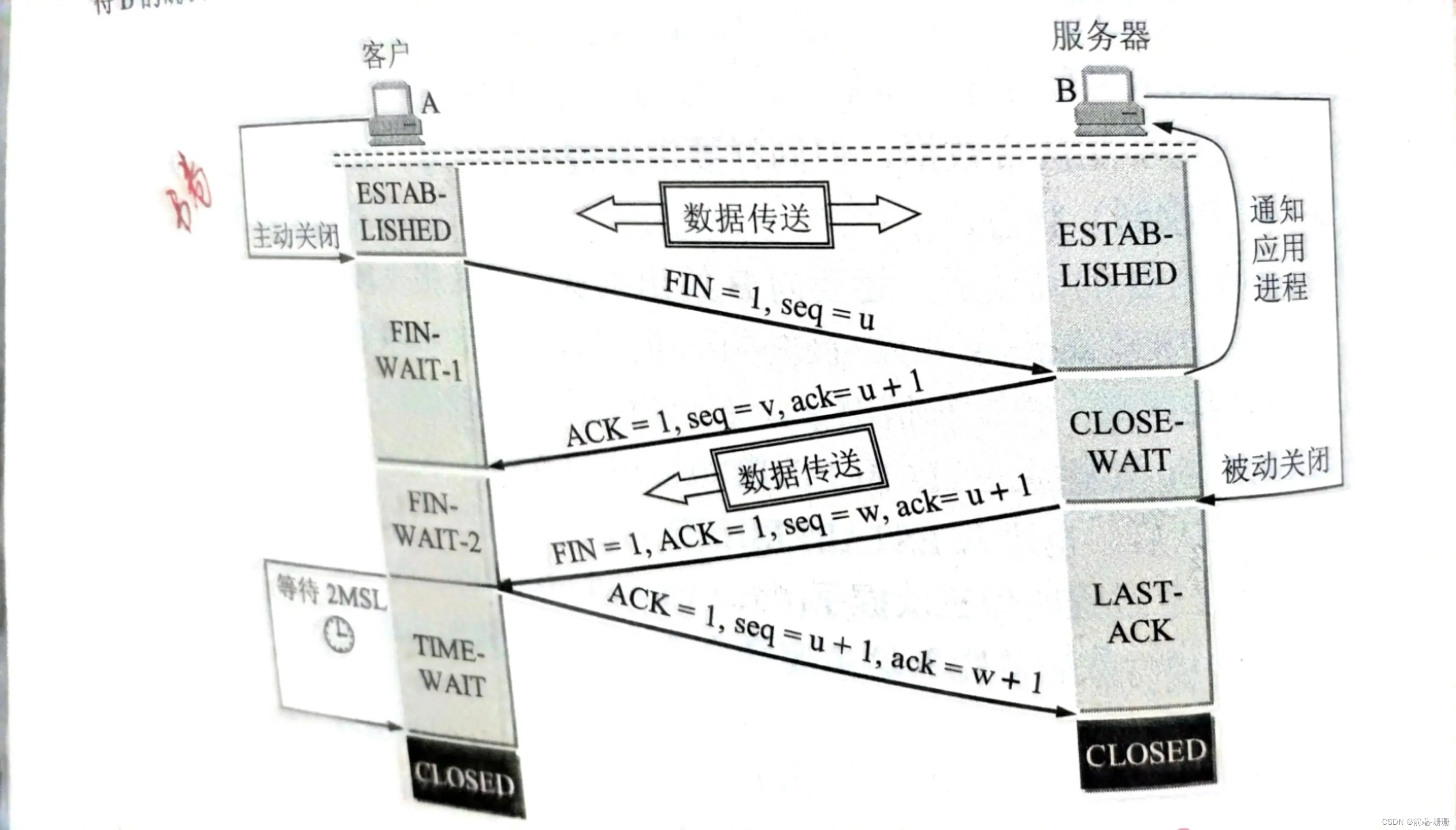
为什么要进行四次挥手?因为收到客户端发来的结束并不能立马结束,要等数据传完,确认接收完全才断连。
问:为什么要在等待2MSL(MSL:最长报文段寿命,RFC 793建议设为2分钟)的时间后再断开连接?
答:①为了保证客户端发送的最后一个ACK报文段能够到达服务端;②防止“已失效的连接请求报文段”出现在这次连接中。
对于保活计时器(服务器每次接收到数据就重置保活计算器)这儿不展开讲,需要了解的可以自行百度。主要是应用于刚刚建立起连接,然后客户端断连了,如果客户端2小时没发消息给服务器,服务器发送一次探测报文,之后每隔75分钟发一次,直到10次探测报文都没回复则中断连接。
下图是三次握手和四次挥手的状态流转,挺有意思的,贴出来有兴趣的可以看看
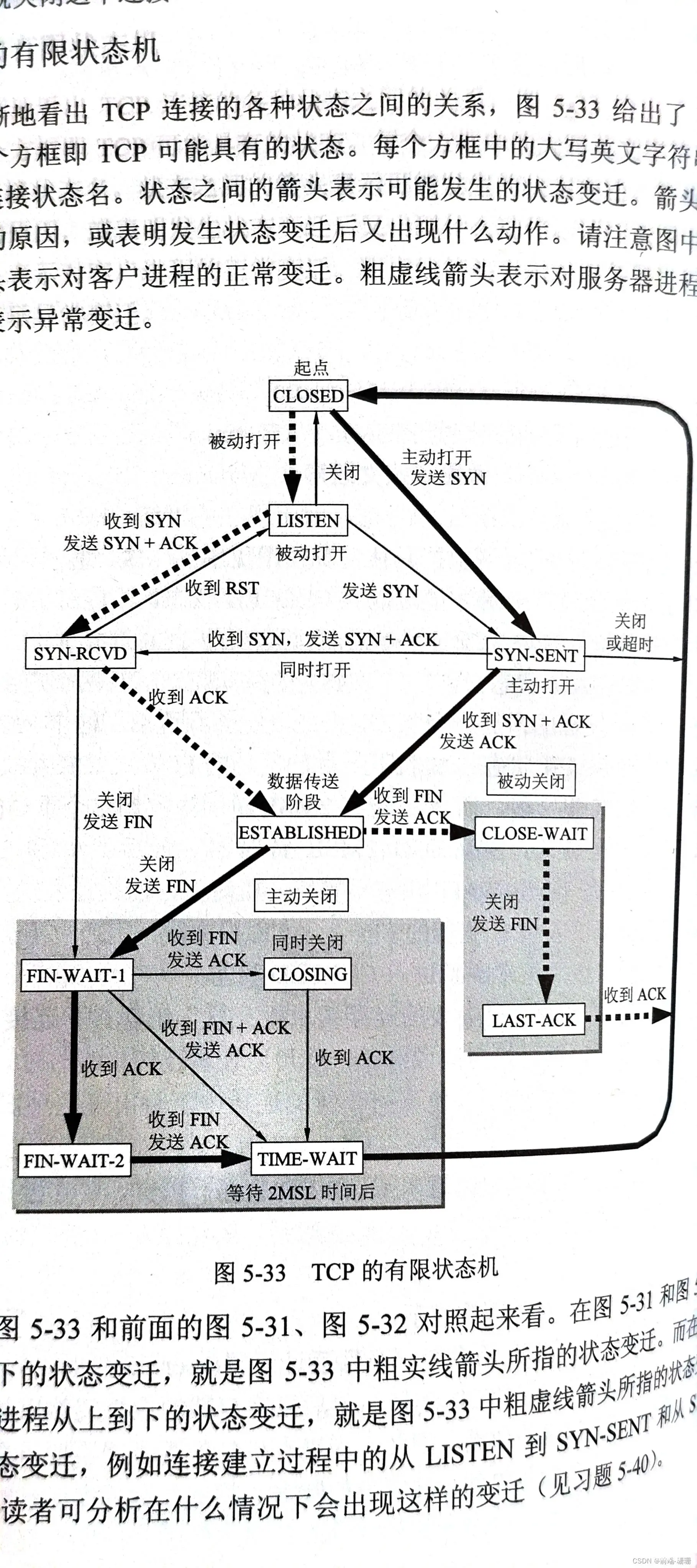
嗯,这儿会有人觉得,了解这么多有什么用呢?我只是前端,网络这块对前端开发或者在优化上说毫无意义。那到底这块有没有可以涉及到优化?
我的回答当然有,列举几点:
(1)CDN加速,就是在现有的Internet中增加一层新的CACHE(缓存)层,将网站的内容发布到最接近用户的网络”边缘“的节点,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。需要详细了解的可以看参考链接的内容(懒得看参考就往dns那块回看,看递归查询那个图,就会发现权限域名那儿做了优化,直接用智能调度的dns将cdn节点的ip返回给本地域名服务器,直接去cdn的ip获取内容,减少服务器的压力)。
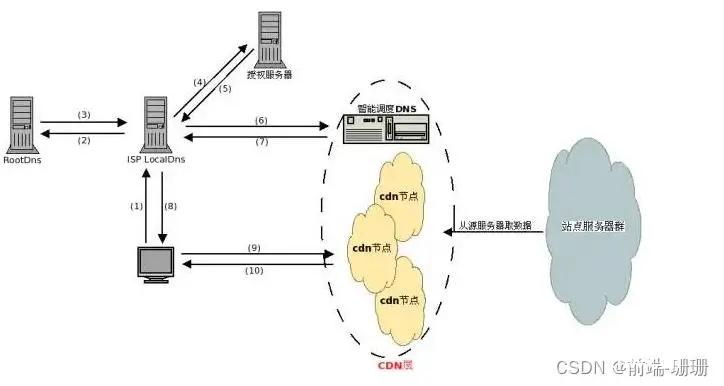
(2)缓存,这个就是上面提到的强缓存和协商缓存,强缓存减少过桥次数,达到速度的提升;协商缓存是减少过桥人数,减少服务器的压力(对应图片有写这句话哦,可以回头看看)
(3)雪碧图,原理也是减少请求次数,减少服务器压力
(4)开启gzip压缩,减少数据的大小,从而减轻服务器压力
(5)域名分片,将网站的资源分布在多个子域名下,实现更高的并发连接数
(6)使用HTTP2.0,多路复用,提高效率
嘿嘿,是不是总觉得有点熟悉感?那当然啦,在HTTP1.1优化那提到过,这儿只是再次重申,告诉小伙伴,网络这块的优化也很重要,不要只看渲染那块,要全面些的去了解。
那么至此,资源已经从网络上获取了,接下来就进入了渲染的过程。嘿嘿,你会不会觉得就剩渲染了,这么简单,三两笔就能搞定,没多少内容了?悄悄告诉你,可能还有一半呢,哈哈哈!不要放弃啊,坚持呀,我写都写了那么久,哪能让你一下子就看完的嘛!实在不行,去玩一阵回来再看呗。
7 浏览器渲染
7.1浏览器进程
开始往下讲前,先老生常谈,回顾一下浏览器的进程,浏览器是多进程的大家都知道,每开一个tab页面就相当开一个进程(别杠,某些情况可能会由于优化策略进行合并,另说),这个我想大家都知道哈。
浏览器进程主要有以下几个:
Browser进程:浏览器的主进程,负责协调、主控,只有一个,作用:
(1)负责浏览器界面的显示、与用户交互(如前进、后退、刷新等)
(2)负责各个页面的管理,创建和销毁其他进程;
(3)将渲染进程得到的内存中的栅格图绘制到用户界面上
(4)网络资源的管理和下载等
第三方插件进程: 顾名思义,就是在使用插件的时候才创建的;
GPU进程: 目前只有一个,一般用于3D的绘制;
浏览器渲染进程(前端最关心的模块啦):
默认每打开一个tab页面,就会启动一个渲染进程;主要负责页面的渲染,脚本的执行,事件的处理。
浏览器多线程主要是为了提高浏览器的稳定性(哈哈,总不可以这个页面崩了别的页面也崩了吧,那人也崩了,哈哈哈)
7.2 浏览器渲染进程
浏览器渲染进程是我们的重点关键对象,底层逻辑搞清楚了,做优化自然而然就会了。浏览器渲染进程主要有:GUI 渲染线程、 JavaScript引擎线程、 定时触发器线程、 事件触发线程、 异步http请求线程
1.GUI渲染线程
主要负责页面的渲染,解析HTML、CSS,构建DOM树,布局和绘制等。当界面需要重绘或者由于某种操作引发回流时,将执行该线程。该线程与JS引擎线程互斥,当执行JS引擎线程时,GUI渲染会被挂起,当任务队列空闲时,主线程才会去执行GUI渲染。
2.JS引擎线程
该线程当然是主要负责处理 JavaScript脚本,执行代码。也是主要负责执行准备好待执行的事件,即定时器计数结束,或者异步请求成功并正确返回时,将依次进入任务队列,等待 JS引擎线程的执行。当然,该线程与 GUI渲染线程互斥,当 JS引擎线程执行 JavaScript脚本时间过长,将导致页面渲染的阻塞。
3.定时器触发线程
负责执行异步定时器一类的函数的线程,如: setTimeout,setInterval。主线程依次执行代码时,遇到定时器,会将定时器交给该线程处理,当计数完毕后,事件触发线程会将计数完毕后的事件加入到任务队列的尾部,等待JS引擎线程执行。
4.事件触发线程
主要负责将准备好的事件交给 JS引擎线程执行。
比如 setTimeout定时器计数结束, ajax等异步请求成功并触发回调函数,或者用户触发点击事件时,该线程会将整装待发的事件依次加入到任务队列的队尾,等待 JS引擎线程的执行。
5.异步http请求线程
负责执行异步请求一类的函数的线程,如: Promise,axios,ajax等。主线程依次执行代码时,遇到异步请求,会将函数交给该线程处理,当监听到状态码变更,如果有回调函数,事件触发线程会将回调函数加入到任务队列的尾部,等待JS引擎线程执行。
在这里我只会重点讲GUI渲染线程和JS引擎线程(嗯,我先立flag,毕竟GUI渲染线程就有得我写的了,立了flag才有动力写JS引擎线程),JS引擎线程会包含后面3-4-5的线程结合聊。那么进入GUI渲染线程的主题吧!
7.2.1 页面绘制的流程
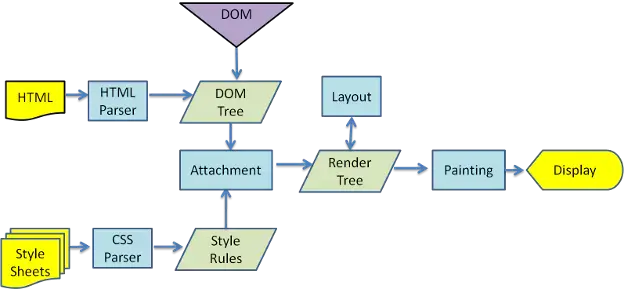
页面绘制的流程不同浏览器的步骤大同小异,图一为谷歌的渲染流程:
图二是Mozilla 的 Gecko 呈现引擎主流程:
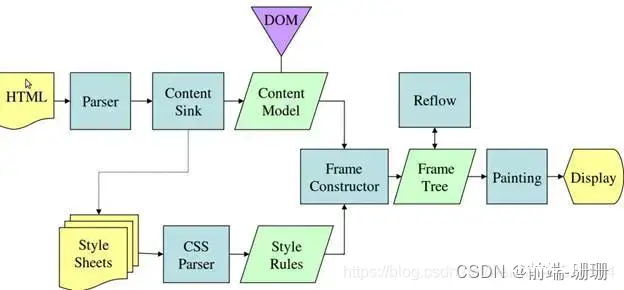
看上图,其实都是构建DOM树,构建CSS Rules,渲染树,布局,绘制,显示。面试的时候大部分人都这样回答过吧。如果年限是2-3年的这样回答,都很满意了,因为知道整个流程(不得不说现在培训出来的,大部分带着偏见,觉得会用三大框架足够,根本不需要了解这些,甚至也不屑于了解,觉得没用),如果年限上去了,那就再往深处走吧。
在开始下文前,需要知道的是请求回来的资源都需要经过Bytes转成对应的文件。
7.2.2 DOM的渲染
DOM的渲染首先是拿到HTML文件,按照规则进行解构。
<!DOCTYPE html><html><body> <div> <h1>My First Heading</h1> <p>My first paragraph.</p> </div></body></html>
上面代码块parse后就成为下图:
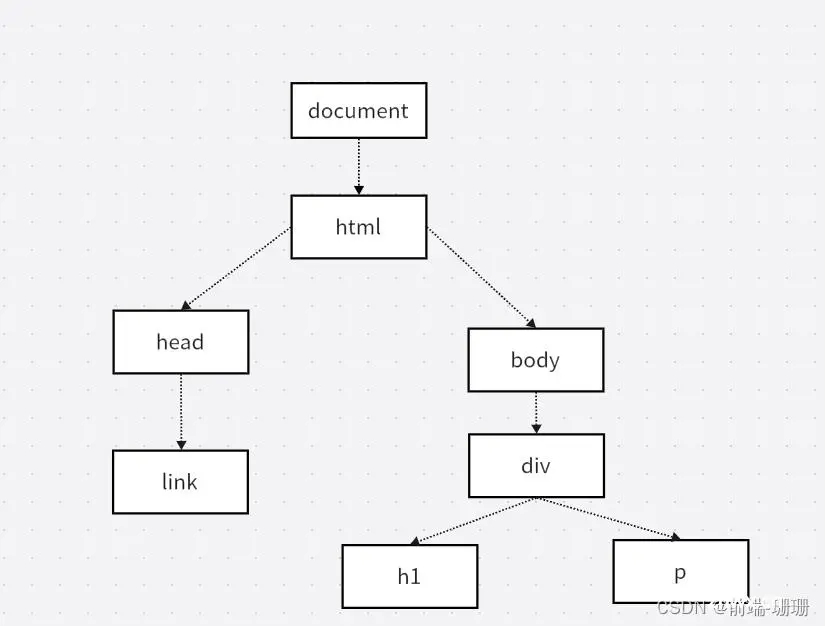
上图就是DOM(Document Object Model)树啦!
DOM是一棵树,是树就会有父子和邻居的关系,而且这棵树是暴露API给JS调用,JS可以查询和修改这棵树。JS引擎V8通过bindings的系统将DOM包装为DOM API供给Web开发者调用。
这儿有个注意点,一个文档里面可能包含多个DOM树,类似用的slot一样插入一个DOM树,最终都会在遍历树之后合成一棵树。
DOM树相对来说看起来比较简单,那,我们进阶一下?
思考一下:JS有AST抽象树,HTML是不是也有呢?嘿嘿,当然有,上图的代码抽象树如下:

h1的详细AST抽象树如下:
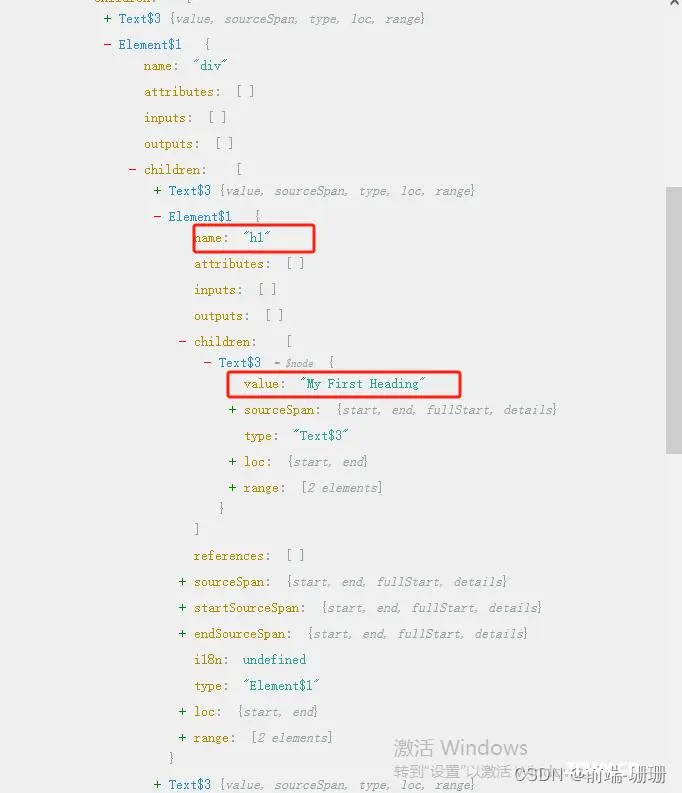
其实它跟JS的AST抽象树差不多,都是一个对象不断的展开,就是属性不太一样,比如它的Text$3代表的是文字,Element$1代表节点,节点的name是什么,attributes有哪些。
这儿有人会问为什么要了解这个?别着急呀,咱先看看目前流行的虚拟DOM结构
// 虚拟DOM节点的数据结构表示const virtualNode = { type: 'div', // 节点类型 props: { // 节点属性 id: 'textDiv', className: 'container' }, children: [ // 子节点 { type: 'h1', props: { textContent: 'Hello!' }, children: [] }, { type: 'p', props: { textContent: 'This is an example of virtual DOM.' }, children: [] } ]};
两者对比是不是相似度挺高的?当然的啦,毕竟虚拟DOM与真实DOM之间是一种映射关系。我记得有人纠结过虚拟DOM在vue中和react中是不是一样的,其实没必要纠结,VNnode就是模拟DOM节点的对象,它们无论是在vue和react中都是一样的。并没有因为框架的原因导致这对象不同,框架之间的不同在于diff算法的不同,vue是双指针而react是单指针。
虚拟DOM的出现是为了减少对DOM的操作从而提高性能,那么单纯的HTML怎么进行优化呢?这儿就不得不提回流了(虽然按理这个应该涉及到CSS再提的)。回流就是DOM结构发生了变化触发了浏览器重走整个7.2的所有流程。这个代价是巨大的。那么写好稳定结构的HTML就比较关键了。如下图:

这个结构怎么写?我看之前带的小伙伴是用float一左一右,当右边的选项边多的时候,结构就变形(排版错乱了),这样就引起了回流。最佳的解决方案就是在外面套个div用flex布局,左右两边固定宽度。稳定结构,即使是后期修改布局,也不至于删掉一个图标整个布局就垮掉。
再有就是在写原生的时候修改大面积的DOM时,先display:none,操作好了再加进来。或者是加入一段HTML节点的时候用document.createDocumentFragment(),减少频繁的操作DOM,从而提高性能。
7.2.3 CSS rules
DOM树在渲染的同时,CSS也同样在解析,下面是解析成CSS rules的步骤。
如下代码
@media screen and (min-width: 480px) { body { background-color: lightgreen; }}#main { border: 1px solid black;}.li-list {margin:5px}
将代码parse后就成下面的结构:
这儿已经写了结构,我就直接把CSS的AST搬出来了吧。
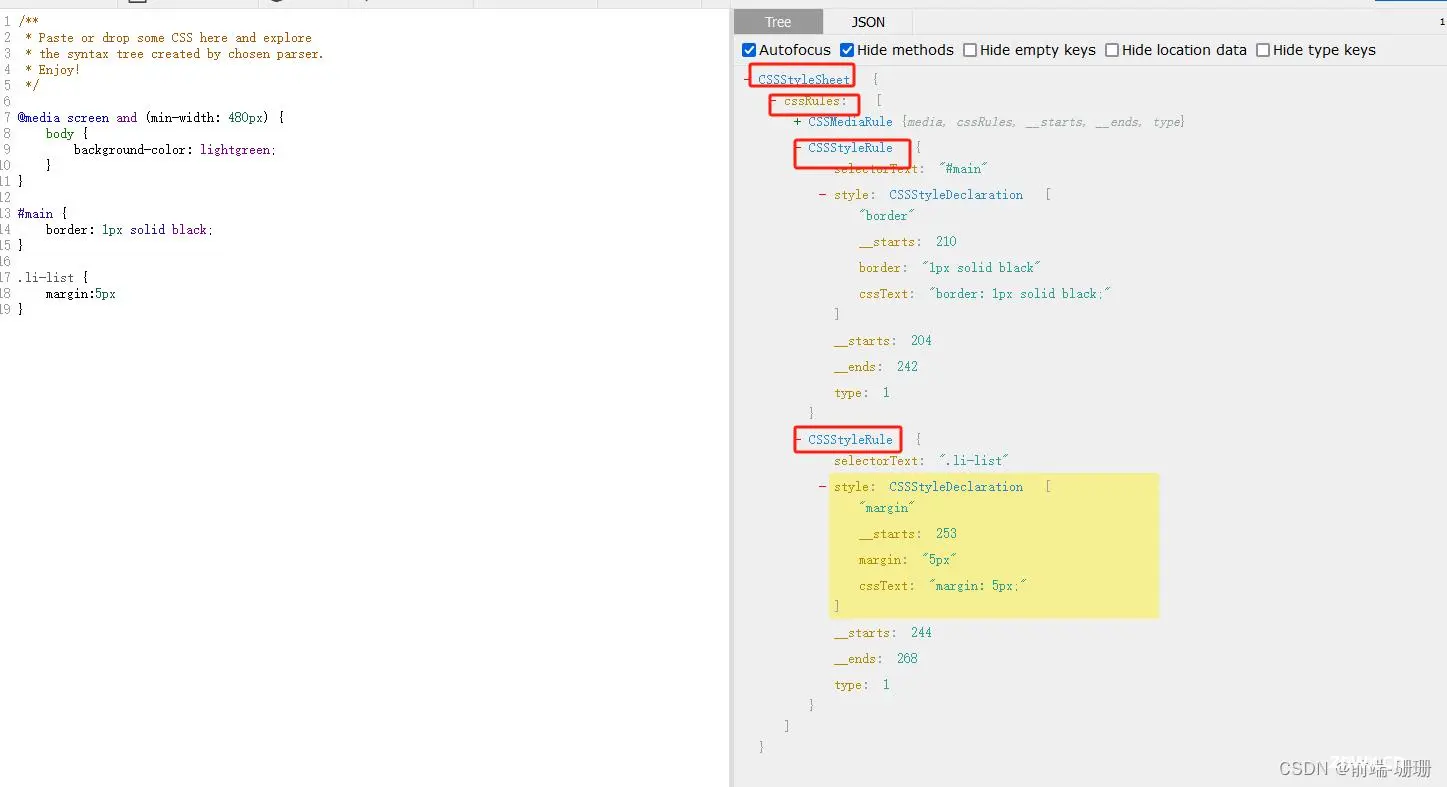
如果你想自己看某个网页的CSSRules直接输入
document.styleSheets[0].cssRules
就可以看见对应的结构。
这儿需要提一下,cssText这儿还会进行CSSPropertyValue的一个转换。比如:font-size:2em的2em会转换成32px。
这儿可能有人会问:为什么你总爱提AST抽象树?
因为AST本就是底层很重要的东西呀,只不过大部分人都只接触或者是只听到了JS的AST抽象树,实际HTML和CSS都是一样有抽象树,它的核心作用是什么?核心作用就是解析 - 转换 - 生成。Babel的作用大家都知道吧?先将es6语法转为AST抽象树,然后再将转换的AST抽象树转换成浏览器能识别的JS的AST抽象树,最后浏览器解析出来。
就像DOM树的AST一样,了解了它的结构,你一发散思维就能感悟到虚拟DOM怎么来的,为什么能从这个方面去优化。
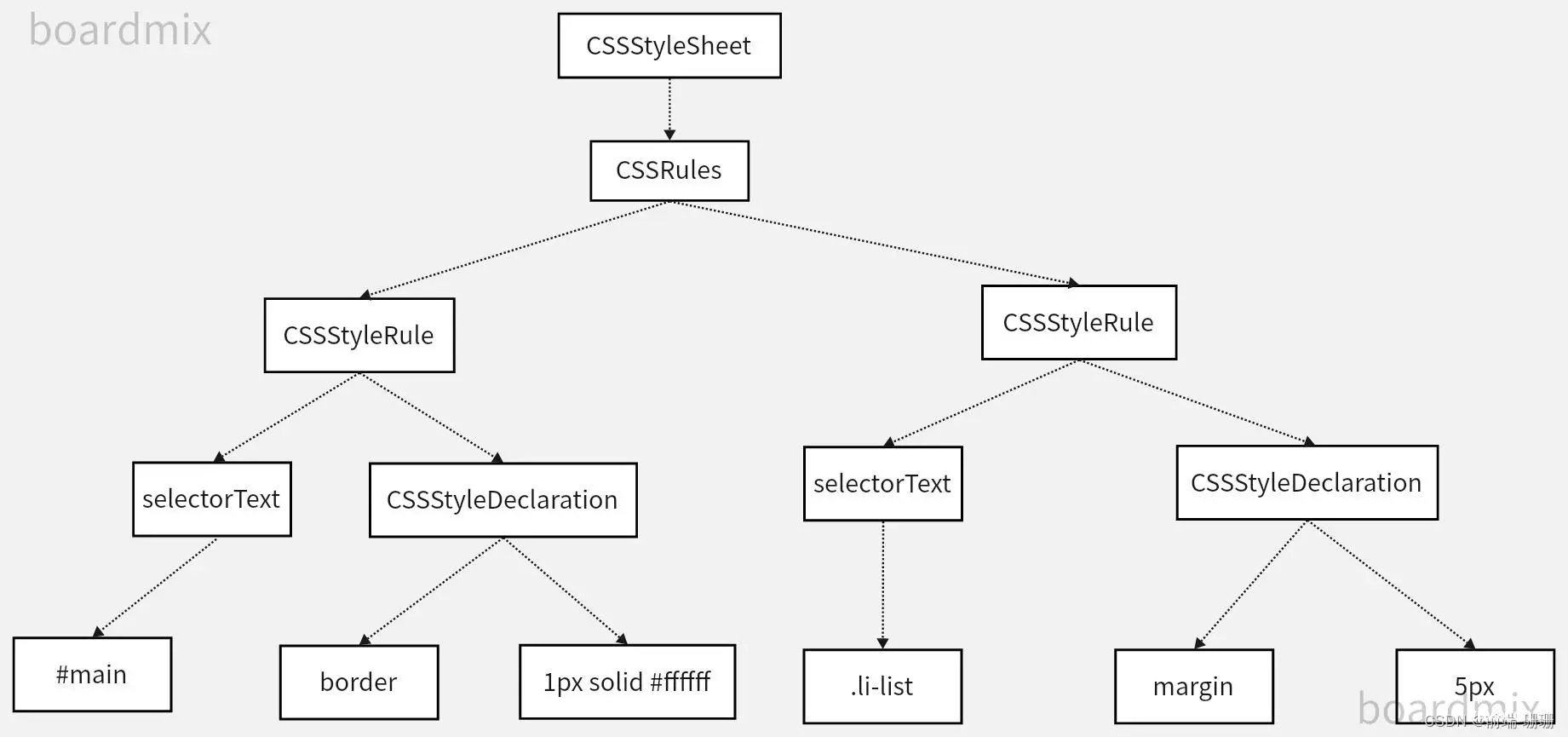
回归CSS主题,CSS文件解析成AST树后结构如下图:
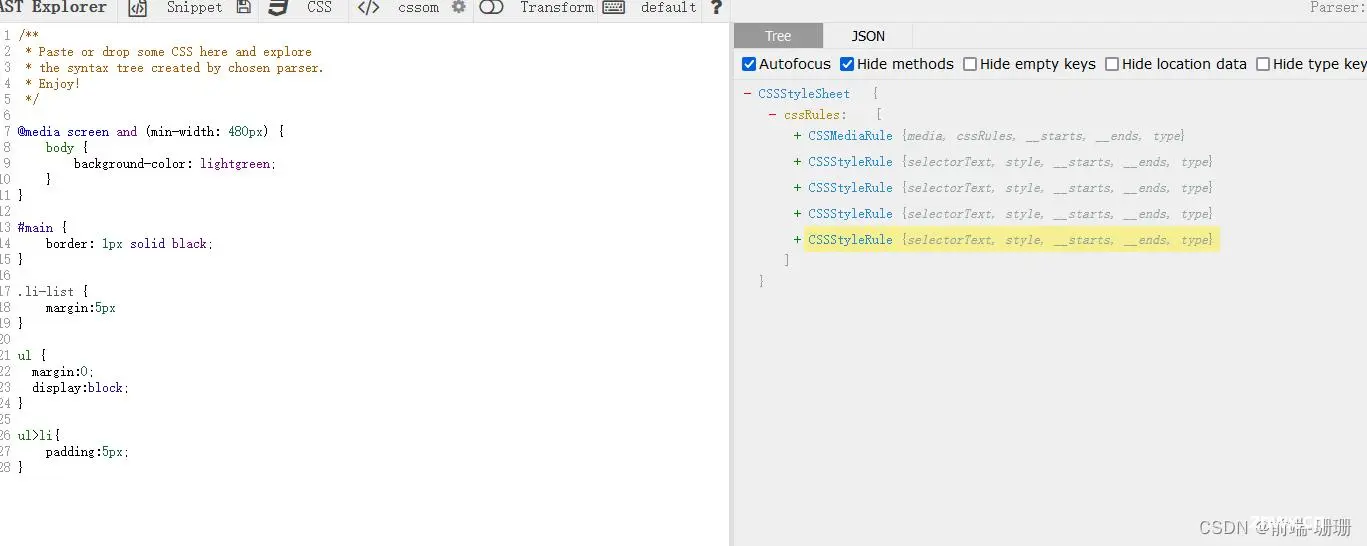
它会分成每个CSSStyleRule,而且这儿要注意,它不会根据你的层级去嵌套,DOM的AST抽象树是有子节点就嵌套在childrens里面,CSS Rules就不是,例如:ul就是一个单独的CSSStyleRule,ul>li又是一个单独的CSSStyleRule。
单纯的讲CSS的解析层面就是上面内容了,CSS通常需要结合DOM生成渲染树才有更多可扩展性的讲。
7.2.4 渲染树
DOM树和CSS Rules都已经分别生成好了。那怎么让他们对应上呢?咱回看7.2.1的两张图。在谷歌浏览器里面有一个Attachment的过程,火狐浏览器有 FrameConstructor这个过程。它们两者的作用是一样的,只不过用的方法不同而已,大概执行的内容如下图(图是偷的,哈哈哈):
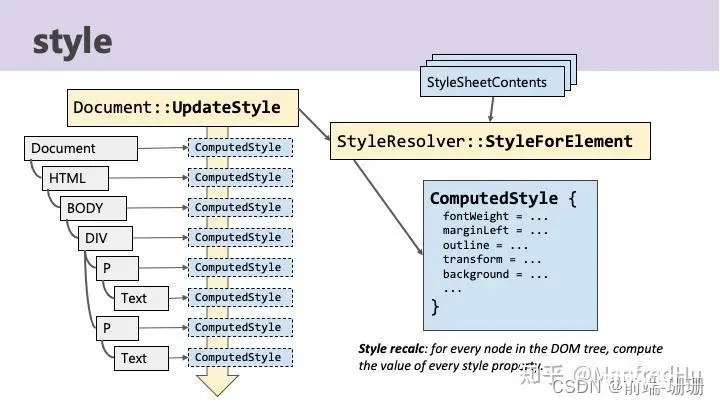
算法主要是将解析后的DOM树和CSS Rulse进行匹配,节点匹配对应的css样式,进行渲染,这个匹配过程提出来,主要是引出部分关于CSS的优化。
在面试中,我经常会问面试者:你写CSS的样式,会嵌套几层?
有些人会很不屑于回答我这个问题,那我问这个问题主要想考面试者什么呢?其实就是想问他是否了解css选择器是从右往左找节点匹配对应的DOM样式的。
为什么css的选择器不是从左向右找呢?比如:.list-li>li>.content{}
按从左到右,步骤如下:
先找到所有 div 节点。
在 div 节点内找到所有的子 div,并且是 class = “list-li”。
然后再依次匹配li .content等情况。
遇到不匹配的情况,就必须回溯到一开始搜索的 div 节点,然后去搜索下个节点,重复这样的过程。(嗯,就是广度遍历,不理解可以看补充知识的树那儿,节点一层层往下找,遍历的时间会比较长)
按从右往左步骤如下:
首先就查找到 class=“content” 的元素。
接着检测父节点是否为 li 元素,如果不是则进入同级其他节点的遍历,如果是则继续匹配父节点满足 class=“list-li” 的 div 容器。
这样就又减少了集合的元素,只有符合当前的子规则才会匹配再上一条子规则。
对比起来从右往左这样更快的找到节点,需要的时间就更短。
从这儿我又会延申问面试者:你写的less或者是scss一般写多少层嵌套?
如果我现在问屏幕前的你,你会怎么答?还是会说按照需求去嵌套多少层吗?我希望你在看完这篇文章后,别人问的时候你回答是:嵌套一般不超三层,因为按css选择器从右往左读的原则,越嵌套多,查找的时间越长。嵌套三层是相对更合适的。
在面试中我也会问为什么在日常中用class多过id的?有人会告诉我大家都用,好用。有些人也会回答到点上,只要渲染过一次class,再遇到一样class,结构一样的就可以直接复用,不需要浏览器再次渲染一次class样式。
那到底是怎么复用?复用的条件是什么?这儿就不得不提到computedStyle的高效共享这点啦。看下面代码:
<div class="content"> <p class="text">我是看不同的优化</p></div><div class="content"> <p class="text">我是看不同的优化2</p></div>--------------------------分割线-----------------<div class="content"> <p class="text" style="color:red">我是看不同的优化</p></div><div class="content"> <p class="text">我是看不同的优化2</p></div>--------------------------分割线-----------------<div class="content"> <p class="text" title="滑过可见" >我是看不同的优化</p></div><div class="content"> <p class="text" title="滑过可见" >我是看不同的优化2</p></div>
上面哪个是共享的?先思考,然后看computedStyle的高效共享的规则:
1、TagName和Class属性必须一样;
2、不能用style属性,哪怕属性是一样的都不共享;
3、不能使用sibling选择器,比如:first-child;
4、标签内的属性必须要相等。
上述答案就是1和3共享,2不共享。
computedStyle后,就组装渲染树。注意一点,形成渲染树的过程有布局同时进行,无论是谷歌的layout还是Gecko的reflow,都是在构建渲染树的同时在进行布局(图片在7.2.1)。
7.2.5 布局
布局中浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。大白话就是按照写的每一个CSS样式去布局一个div,比如它的宽高颜色字体等等属性。主要执行类似于下图(图还是偷的,哈哈哈):
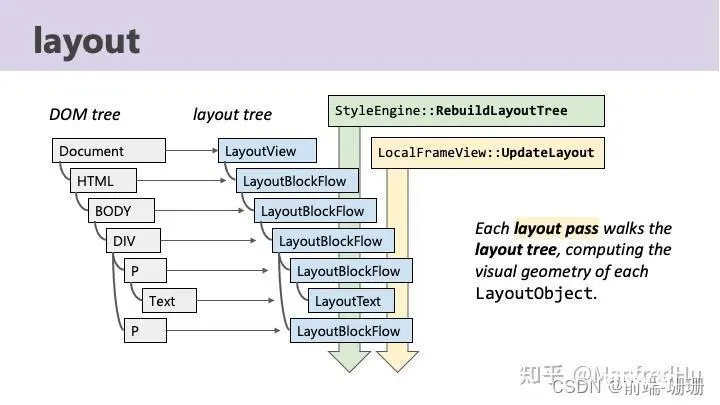
如图,通过遍历DOM树创建渲染树LayoutTree,节点一一对应。布局树中的节点实现布局算法。根据所需的布局行为,LayoutObject有不同的子类。比如LayoutBlockFlow就是块级Flow的文档节点。样式更新阶段也会构建布局树。
这儿提个点:伪类是作用在LayoutTree上的,如p::before{content:"Hi!"}也不在DOM里而是在Layout Tree上。可以理解DOM是本体,伪类是给本体的“化妆”,比如伪娘本体是男的,但是看着像女的
布局这块最值得提的可能就是涉及到怎么写css样式的最优方式。首先,抛出个问题,你在写一个class的时候,什么样式先写?有没有问过自己为什么这样写?ok,问完你我开始讲正题
.list-li{ display: block; width: 100px; height: 200px; position: absolute; left:8px;}//--------------------分割线--------------.list-li{ position: absolute; left:8px; display: block; width: 100px; height: 200px;}
上面两种样式有什么区别?哪种是优选?来,按第一种class来,因为浏览器是自上而下读取css布局的。那么首先读到是的它是块作用域,然后宽度是100像素,高度200像素,然后到定位这,浏览发现它给这个块划分的区域是不对的,因为这个定位属性让它脱离了文档流。那怎么办呢?浏览器只能重新排版,将其从文档流抽出,再进行布局。 那么这就说明了,这儿浏览器是浪费了一些时间在重新排版上的。ok,我们看第二个,首先就告诉浏览器,这个div是脱离文档流的,然后它向左边偏离8像素,然后宽是100像素,高是200像素。全程浏览器没有触发重新排版的。对比下来是不是第二种写法更优?
嗯,事实就是第二种写法更优,所以我们在写样式的时候也需要注意写的样式先后顺序。(你要是杠我,时间很短,可以忽略不记,那你可以不用看我文章,毕竟都是这种小细节的优化多)那么日常中怎么写顺序最优呢?下面是对应的列表:
| 名称 | 属性 |
| 定位属性 | position display float left top right bottom overflow clear z-index |
| 自身属性 | width height padding border margin background |
| 文字样式 | font-family font-size font-style font-weight font-varient color |
| 文本属性 | text-align vertical-align text-wrap text-transform text-indent text-decoration letter-spacing word-spacing white-space text-overflow |
| CSS3 中新增属性 | content box-shadow border-radius transform |
日常书写最好按照这个顺序写,如果你没有用别的css插件的话,养成好的习惯是很重要的,在css这步就避免部分的回流,这对程序员来说,不是一个很nice的点吗?
当然,现在项目中很多人用stylelint这个插件,stylelint里面的规则也有写属性按照什么顺序去排,具体如下图:

在布局这儿,我主要想表达的就是在这儿做css样式写的优化。 其次还有一个点就是在布局这儿还有LayerTree。LayerTree就是根据脱离文档流的内容进行分层布局。以下这些属性都可能让其分层的:position、css3的属性(如:transform属性)、video、canvas、css3的动画效果属性等。
7.2.6 绘制
绘制这儿先甩两张图
第一张,平面看到流程的,一个是主线程和一个非主线程:

一张能看见流转步骤的图(当然,这一看就不是我画的,哈哈哈) :

从上面两张图应该能看到,其实我们到了paint这个阶段了。
paint这个阶段其实说白了就是为每个图层生成绘制列表,并将其提交到合成线程。到这儿页面上实质上还是什么都没有的,因为这个阶段只是创建绘制指令paint op,如下图:
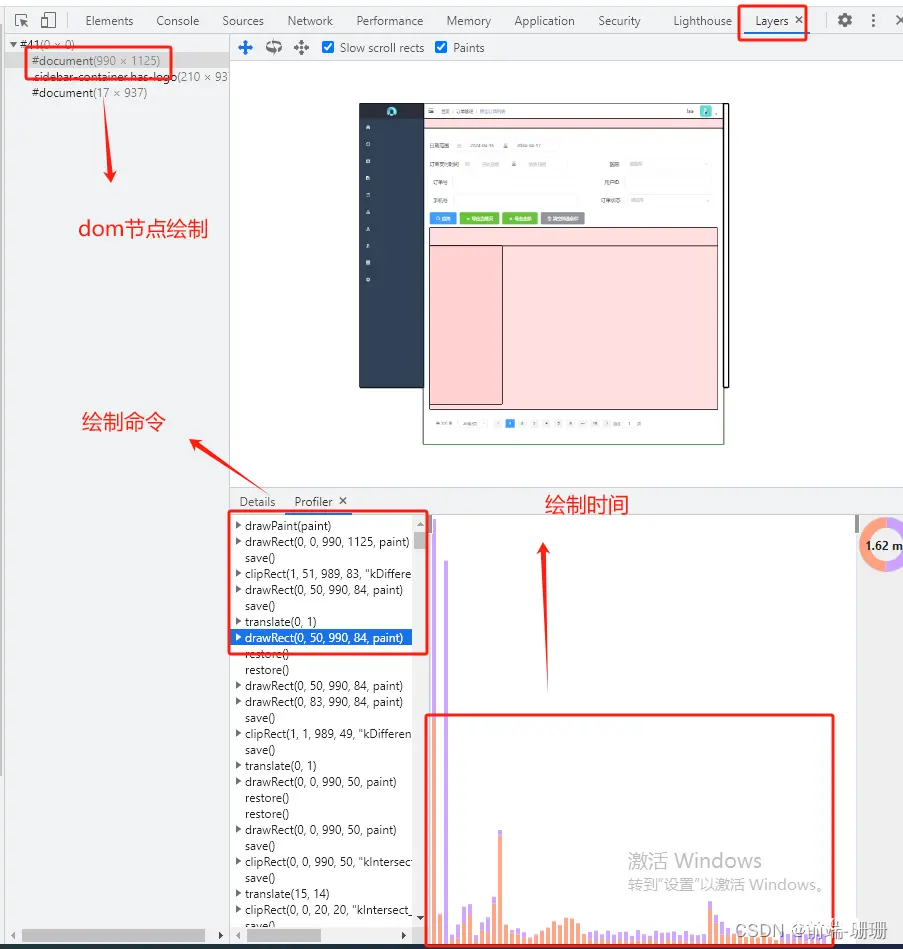
(图片的面板是谷歌工具栏设置按钮旁边的...然后选择more tools,找到Layers就可以看见啦)
绘制指令paint op 可以理解为某些坐标(x,y,w,h)画一个矩形,嗯,试着读一下上图的代码:drawPaint(paint),执行绘制开始,第二步drawRect(0,0,990,1125,paint),绘制一个矩形,坐标是(0,0,990,1125),第三步执行保存。 (嘿嘿,写过canvas的小伙伴这儿应该熟悉吧,这其实就是在画canvas呀)
由上图截图也可以看出前面说的,绘制出来的就是每个图层的绘制列表。绘制列表完成后就会把它提交到合成线程
1 tiles模块
tiles是什么东西?首先我们的页面是很大的,向下拉伸理论上是可以无限延长的。如果我们一次性加载,那用户得等疯了吧?所以浏览器不可能加载完再画。这时就延申出来了分块平铺的概念。分块平铺是什么意思呢?比如我们要铺一间房间的瓷砖,不能一下子就铺完吧?可以将房间划分为一块块区域,比如厕所一块区域,洗刷台一块区域,阳台一块区域,分区域来铺瓷砖。
分块平铺是发生在绘制后,栅格化前。根据视口viewport所在位置的不同,渲染进程合成器线程会选择靠近视口的图块tiles先进行渲染,将最后选择渲染的图块传递给GPU栅格化线程池里的单个栅格化线程执行栅格化,最后得到栅格化好后的tile图块。
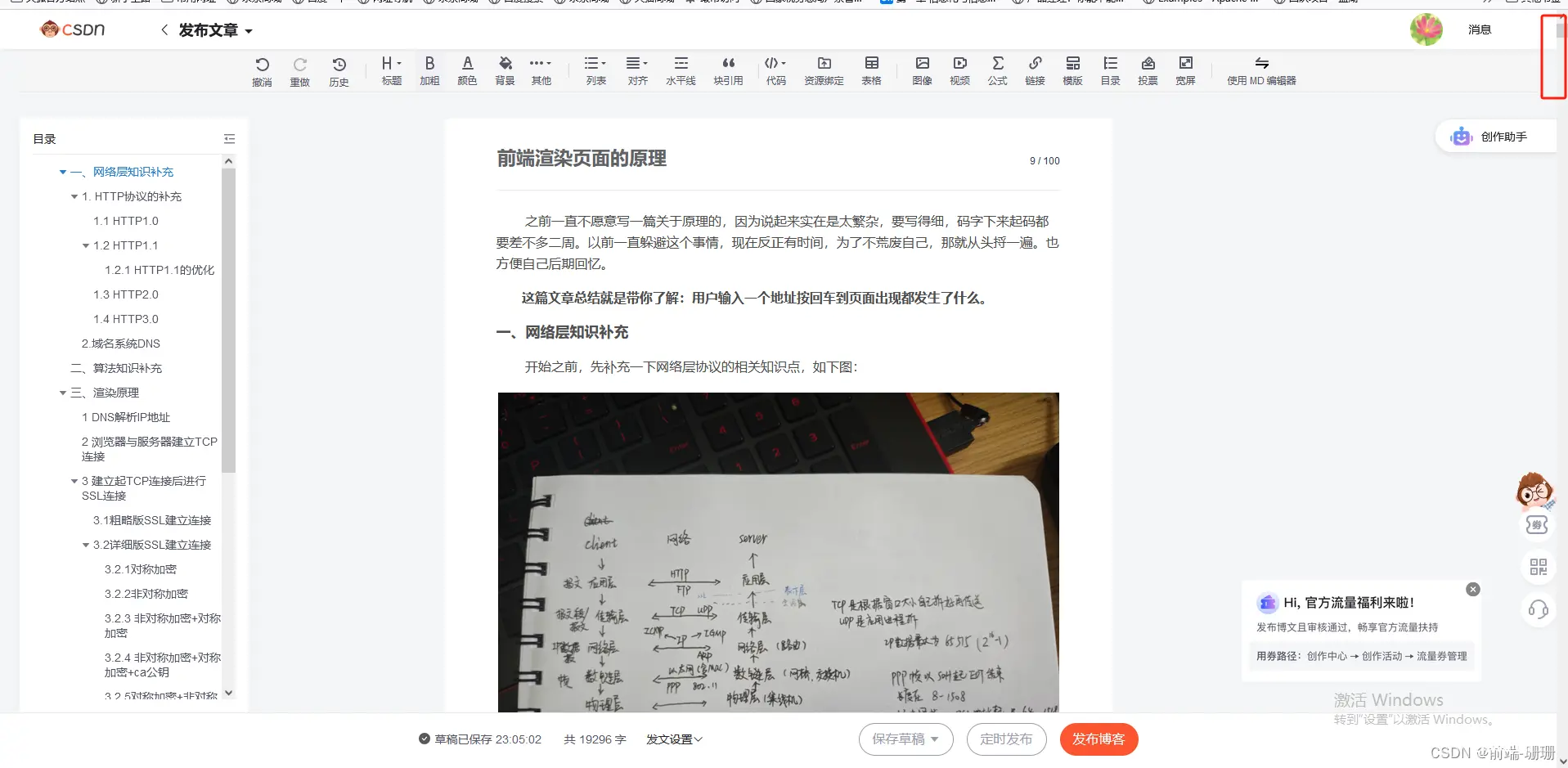
(上图就是可视窗口能看见的部分,优先渲染,滚动条后面是无线长的页面)
那么什么叫栅格化呢?往下看
2 raster模块
光栅化也称为栅格化,就是将绘制指令paint op转化为位图bitmap的过程,转化后每个像素点的rgba都确定。图块是栅格化的任务单位,一般是256*256或者是512*512,一个一个的转为bitmap,具体怎么实现,看下图:
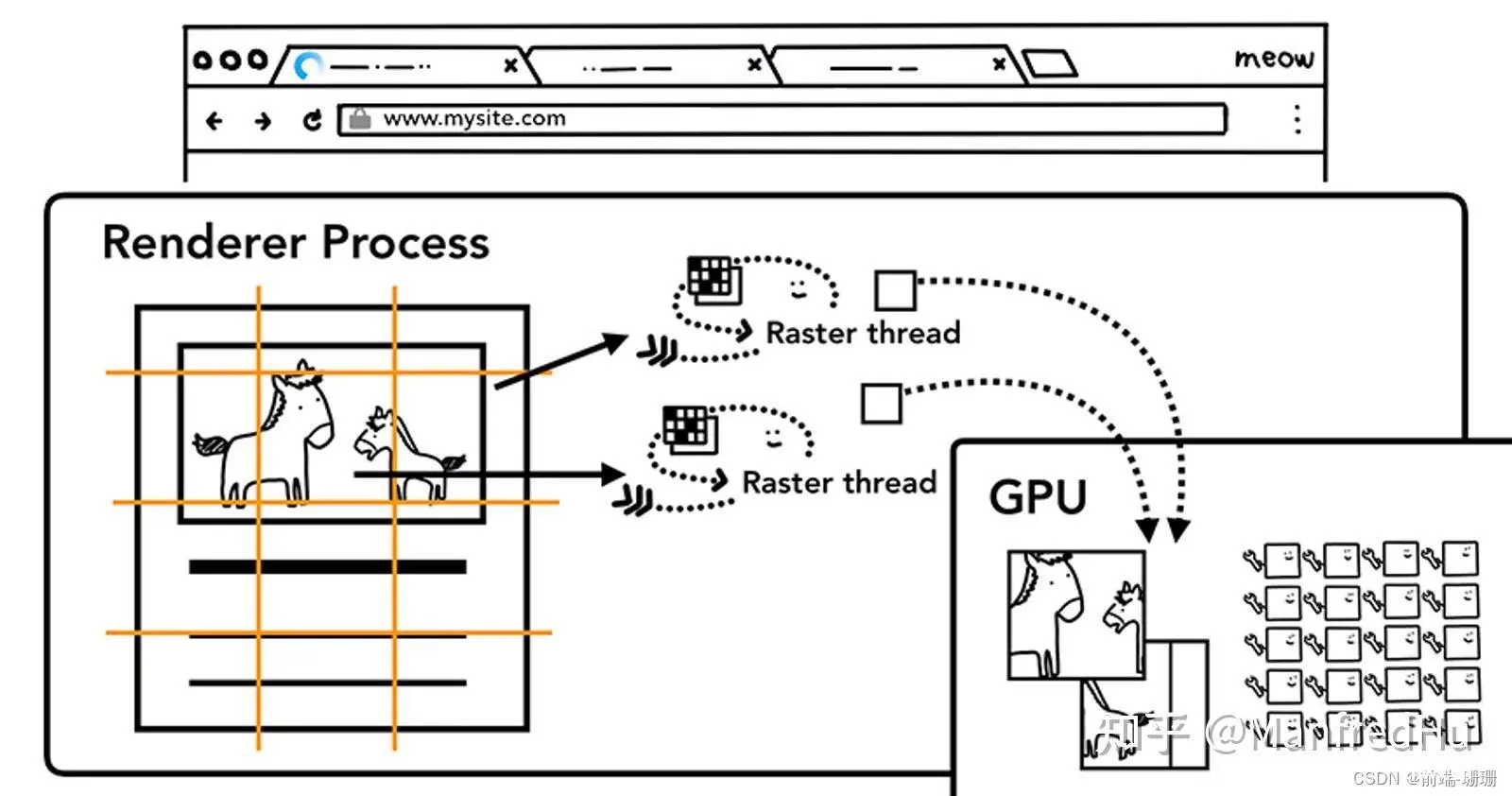
(GPU可以加速栅格化,这儿可以拓展一下,three的贴图,向量也是为了方便快速栅格化)
栅格化所有的图块tiles完成后,渲染进程的合成器线程收集tiles的draw quads信息创建CompositorFrame。可以理解为一个房间的瓷砖,由很多个小瓷砖组成。
3 draw quads
quad类似于在屏幕上特定位置绘制图块tile的指令,draw quads就是绘制图块们的意思。此时的quads是层树LayerTree在拿属性树经过一堆变换后的最终结果,每个quad都引用图块tiles在GPU内存里的栅格化输出结果。
很多个draw quads被包在CompositorFrame里面(这个是渲染进程最后的输出)
这儿按理是还有个activation的过程的,但是我自己理解得还不够透,暂时空着,具体可以看链接像素的一生
7.2.7 显示
看到绘制小节的第一张图可以看到,display是在GUI进程实现的。GUI进程的显示合成器会将CompositorFrame进行合并,处理后进行显示。
显示这儿我摸得还是不够透,就误导你们啦。
这儿提一下,当用js或者是css触发回流时,走的流程如下:
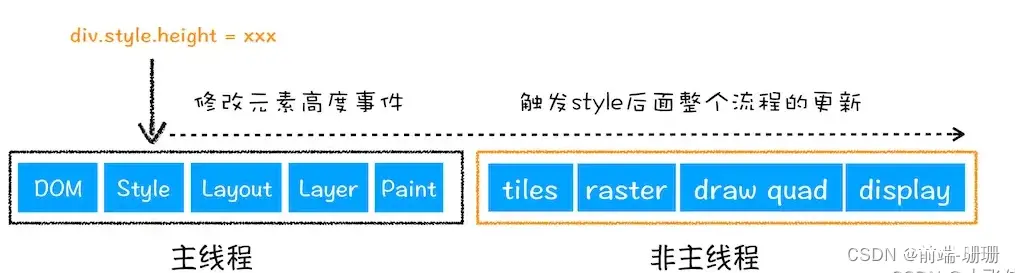
如果是触发重绘的话就直接跳过Layout和layer这两步,直接走Piant往后的步骤。
整篇文章暂时就先到这啦。JS引擎线程这块我会在6月底前补完。毕竟说了要顺带说JS引擎线程的,flag都立下了,哈哈哈。会完成的。如果感兴趣可以六月底再来看看哦。
参考文章:
http发展史:https://juejin.cn/post/7257740918433235000
content-type的类型:https://blog.csdn.net/qq_44741577/article/details/136507746
SSL协议运行过程:https://juejin.cn/post/7238619890993643575
https的原理,加密等:https://www.cnblogs.com/zhenjingcool/p/17255119.html
CDN加速:https://blog.csdn.net/weixin_42358261/article/details/113490522
浏览器渲染进程的线程出处:https://juejin.cn/post/6844903761949753352#heading-12
DOM树和CSS树,render树的原理:https://blog.csdn.net/weixin_56266471/article/details/126107903
CSS渲染以及优化策略:http://jartto.wang/2019/10/23/css-theory-and-optimization/
像素的一生:https://zhuanlan.zhihu.com/p/594398362
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。